我是Dependency Injector的创建者。这是Python的依赖项注入框架。
这是使用Dependency Injector构建应用程序的权威指南。过去的教程包括如何建立一个与瓶的Web应用程序,REST API与Aiohttp,并监视守护进程ASYNCIO使用依赖注入。
今天,我想展示如何构建控制台(CLI)应用程序。
另外,我准备了常见问题的答案,并将发布其后记。
该手册包括以下部分:
可以在Github上找到完成的项目。
首先,您必须具备:
- Python 3.5+
- 虚拟环境
并且希望对依赖注入的原理有一个一般的了解。
我们要建造什么?
我们将构建一个用于查找电影的CLI(控制台)应用程序。我们称其为Movie Lister。
Movie Lister如何工作?
- 我们有一个电影数据库
- 以下是有关每部电影的信息:
- 名称
- 发行年份
- 董事姓名
- 数据库以两种格式分发:
- CSV文件
- SQLite数据库
- 该应用程序使用以下条件搜索数据库:
- 董事姓名
- 发行年份
- 将来可能会添加其他数据库格式
Movie Lister是Martin Fowler的文章中有关依赖项注入和控制反转的示例应用程序。
Movie Lister应用程序的类图
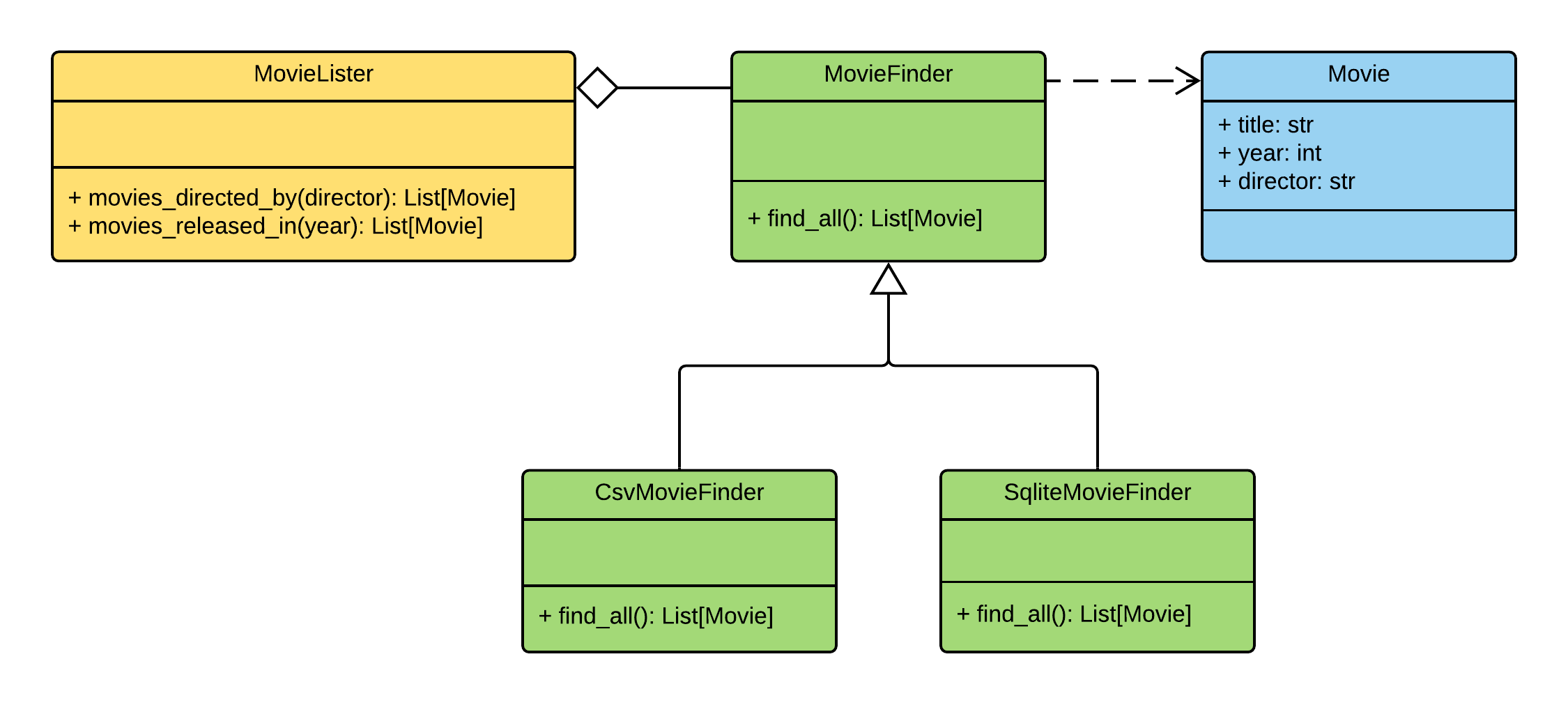
如下所示:类之间的职责分配如下:
MovieLister-负责搜索MovieFinder-负责从数据库中提取数据Movie-实体类“电影”
准备环境
让我们从准备环境开始。
首先,我们需要创建一个项目文件夹和一个虚拟环境:
mkdir movie-lister-tutorial
cd movie-lister-tutorial
python3 -m venv venv
现在让我们激活虚拟环境:
. venv/bin/activate
环境已准备就绪。现在让我们进入项目的结构。
项目结构
在本节中,我们将组织项目的结构。
让我们在当前文件夹中创建以下结构。现在将所有文件留空。
初始结构:
./
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
安装依赖
是时候安装依赖项了。我们将使用如下软件包:
dependency-injector-依赖注入框架pyyaml-用于解析YAML文件的库,用于读取配置pytest-测试框架pytest-cov-帮助库,用于测试测试的代码覆盖率
让我们在文件中添加以下几行
requirements.txt:
dependency-injector
pyyaml
pytest
pytest-cov
并在终端中执行:
pip install -r requirements.txt
依赖项的安装完成。移动到灯具。
治具
在本节中,我们将添加灯具。测试数据称为夹具。
我们将创建一个脚本,该脚本将创建测试数据库。在项目的根
目录中添加目录
data/,并在其中添加文件fixtures.py:
./
├── data/
│ └── fixtures.py
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
接下来,编辑
fixtures.py:
"""Fixtures module."""
import csv
import sqlite3
import pathlib
SAMPLE_DATA = [
('The Hunger Games: Mockingjay - Part 2', 2015, 'Francis Lawrence'),
('Rogue One: A Star Wars Story', 2016, 'Gareth Edwards'),
('The Jungle Book', 2016, 'Jon Favreau'),
]
FILE = pathlib.Path(__file__)
DIR = FILE.parent
CSV_FILE = DIR / 'movies.csv'
SQLITE_FILE = DIR / 'movies.db'
def create_csv(movies_data, path):
with open(path, 'w') as opened_file:
writer = csv.writer(opened_file)
for row in movies_data:
writer.writerow(row)
def create_sqlite(movies_data, path):
with sqlite3.connect(path) as db:
db.execute(
'CREATE TABLE IF NOT EXISTS movies '
'(title text, year int, director text)'
)
db.execute('DELETE FROM movies')
db.executemany('INSERT INTO movies VALUES (?,?,?)', movies_data)
def main():
create_csv(SAMPLE_DATA, CSV_FILE)
create_sqlite(SAMPLE_DATA, SQLITE_FILE)
print('OK')
if __name__ == '__main__':
main()
现在让我们在终端中执行:
python data/fixtures.py
该脚本应
OK在成功时输出。
我们验证这些文件
movies.csv,并movies.db出现在目录data/:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
夹具被创建。让我们继续。
容器
在本节中,我们将添加应用程序的主要部分-容器。
容器允许您以声明式描述应用程序的结构。它将包含所有应用程序组件及其依赖性。将明确指定所有依赖项。提供程序用于将应用程序组件添加到容器。提供者控制组件的生命周期。创建提供程序时,不会创建任何组件。我们告诉提供者如何创建对象,它将在必要时立即创建它。如果一个提供者的依赖关系是另一个提供者,则将沿依赖关系链调用它,依此类推。
让我们编辑
containers.py:
"""Containers module."""
from dependency_injector import containers
class ApplicationContainer(containers.DeclarativeContainer):
...
容器仍然是空的。我们将在下一部分中添加提供程序。
让我们添加另一个函数
main()。她的责任是运行该应用程序。目前,她只会创建一个容器。
让我们编辑
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
if __name__ == '__main__':
main()
容器是应用程序中的第一个对象。它用于获取所有其他对象。
使用CSV
现在,让我们添加使用csv文件所需的所有内容。
我们需要:
- 精华
Movie - 基类
MovieFinder - 其实施
CsvMovieFinder - 类
MovieLister
添加每个组件后,我们将其添加到容器中。在包中
创建文件:
entities.pymovies
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ └── entities.py
├── venv/
├── config.yml
└── requirements.txt
并在其中添加以下几行:
"""Movie entities module."""
class Movie:
def __init__(self, title: str, year: int, director: str):
self.title = str(title)
self.year = int(year)
self.director = str(director)
def __repr__(self):
return '{0}(title={1}, year={2}, director={3})'.format(
self.__class__.__name__,
repr(self.title),
repr(self.year),
repr(self.director),
)
现在我们需要
Movie在容器中添加工厂。为此,我们需要一个providers来自的模块dependency_injector。
让我们编辑
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import entities
class ApplicationContainer(containers.DeclarativeContainer):
movie = providers.Factory(entities.Movie)
别忘了删除省略号(...)。该容器已经包含提供者,不再需要。
让我们继续进行创建
finders。在包中
创建文件:
finders.pymovies
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ └── finders.py
├── venv/
├── config.yml
└── requirements.txt
并在其中添加以下几行:
"""Movie finders module."""
import csv
from typing import Callable, List
from .entities import Movie
class MovieFinder:
def __init__(self, movie_factory: Callable[..., Movie]) -> None:
self._movie_factory = movie_factory
def find_all(self) -> List[Movie]:
raise NotImplementedError()
class CsvMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
delimiter: str,
) -> None:
self._csv_file_path = path
self._delimiter = delimiter
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with open(self._csv_file_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=self._delimiter)
return [self._movie_factory(*row) for row in csv_reader]
现在让我们添加
CsvMovieFinder到容器中。
让我们编辑
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
您
CsvMovieFinder对工厂有依赖性Movie。CsvMovieFinder需要一个工厂,因为它将Movie在从文件读取数据时创建对象。为了通过工厂,我们使用属性.provider。这称为提供者委托。如果我们将工厂指定movie为依赖项,则在csv_finder创建工厂时将调用它,CsvMovieFinder并且将对象作为注入传递Movie。将该属性.provider用作注入将由提供程序本身传递。
它还
csv_finder依赖于几个配置选项。我们添加了一个提供程序onfiguration来传递这些依赖关系。
在设置它们的值之前,我们使用了配置参数。这是提供者工作的原则Configuration。
首先我们使用,然后设置值。
现在,让我们添加配置值。
让我们编辑
config.yml:
finder:
csv:
path: "data/movies.csv"
delimiter: ","
值设置为配置文件。让我们更新该函数
main()以指示其位置。
让我们编辑
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
if __name__ == '__main__':
main()
我们去吧
listers。在包中
创建文件:
listers.pymovies
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ ├── finders.py
│ └── listers.py
├── venv/
├── config.yml
└── requirements.txt
并在其中添加以下几行:
"""Movie listers module."""
from .finders import MovieFinder
class MovieLister:
def __init__(self, movie_finder: MovieFinder):
self._movie_finder = movie_finder
def movies_directed_by(self, director):
return [
movie for movie in self._movie_finder.find_all()
if movie.director == director
]
def movies_released_in(self, year):
return [
movie for movie in self._movie_finder.find_all()
if movie.year == year
]
我们更新
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=csv_finder,
)
创建所有组件并将其添加到容器中。
最后,我们更新函数
main()。
让我们编辑
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
lister = container.lister()
print(
'Francis Lawrence movies:',
lister.movies_directed_by('Francis Lawrence'),
)
print(
'2016 movies:',
lister.movies_released_in(2016),
)
if __name__ == '__main__':
main()
全部都准备好了。现在启动应用程序。
让我们在终端中执行:
python -m movies
你会看见:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
我们的应用程序可使用中的电影数据库
csv。我们还需要添加格式支持sqlite。我们将在下一部分中处理。
使用sqlite
在本节中,我们将添加另一个类型
MovieFinder- SqliteMovieFinder。
让我们编辑
finders.py:
"""Movie finders module."""
import csv
import sqlite3
from typing import Callable, List
from .entities import Movie
class MovieFinder:
def __init__(self, movie_factory: Callable[..., Movie]) -> None:
self._movie_factory = movie_factory
def find_all(self) -> List[Movie]:
raise NotImplementedError()
class CsvMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
delimiter: str,
) -> None:
self._csv_file_path = path
self._delimiter = delimiter
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with open(self._csv_file_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=self._delimiter)
return [self._movie_factory(*row) for row in csv_reader]
class SqliteMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
) -> None:
self._database = sqlite3.connect(path)
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with self._database as db:
rows = db.execute('SELECT title, year, director FROM movies')
return [self._movie_factory(*row) for row in rows]
将提供程序添加
sqlite_finder到容器中,并将其指定为提供程序的依赖项lister。
让我们编辑
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=sqlite_finder,
)
该提供程序
sqlite_finder依赖于我们尚未定义的配置选项。让我们更新配置文件:
编辑
config.yml:
finder:
csv:
path: "data/movies.csv"
delimiter: ","
sqlite:
path: "data/movies.db"
做完了 让我们检查。
我们在终端执行:
python -m movies
你会看见:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
我们的应用程序支持两种数据库格式:
csv和sqlite。每次我们需要更改格式时,都必须更改容器中的代码。我们将在下一部分中对此进行改进。
提供者选择器
在本节中,我们将使我们的应用程序更灵活。
您将不再需要更改代码即可在
csv和sqlite格式之间切换。我们将基于环境变量实现一个开关MOVIE_FINDER_TYPE:
- 当
MOVIE_FINDER_TYPE=csv应用程序使用时csv。 - 当
MOVIE_FINDER_TYPE=sqlite应用程序使用时sqlite。
提供者将为此提供帮助
Selector。它根据配置选项(文档)选择提供程序。
让我们编辑
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
finder = providers.Selector(
config.finder.type,
csv=csv_finder,
sqlite=sqlite_finder,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=finder,
)
我们创建了一个提供程序,
finder并将其指定为该提供程序的依赖项lister。提供程序finder在提供程序之间csv_finder和sqlite_finder运行时之间进行选择。选择取决于开关的值。
开关是配置选项
config.finder.type。csv提供者从密钥使用它的值时csv。同样适用于sqlite。
现在我们需要
config.finder.type从环境变量中读取值MOVIE_FINDER_TYPE。
让我们编辑
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
container.config.finder.type.from_env('MOVIE_FINDER_TYPE')
lister = container.lister()
print(
'Francis Lawrence movies:',
lister.movies_directed_by('Francis Lawrence'),
)
print(
'2016 movies:',
lister.movies_released_in(2016),
)
if __name__ == '__main__':
main()
做完了
在终端中运行以下命令:
MOVIE_FINDER_TYPE=csv python -m movies
MOVIE_FINDER_TYPE=sqlite python -m movies
每个命令的输出将如下所示:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
在本节中,我们熟悉了提供者
Selector。使用此提供程序,可以使您的应用程序更灵活。开关值可以从任何来源设置:配置文件,字典,其他提供程序。
提示:
从另一个提供程序覆盖配置值使您可以在应用程序中实现配置重载而无需热重启。
为此,您需要使用提供者委托和.override()。
在下一节中,我们将添加一些测试。
测验
最后,让我们添加一些测试。在包中
创建文件:
tests.pymovies
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ ├── finders.py
│ ├── listers.py
│ └── tests.py
├── venv/
├── config.yml
└── requirements.txt
并添加以下几行:
"""Tests module."""
from unittest import mock
import pytest
from .containers import ApplicationContainer
@pytest.fixture
def container():
container = ApplicationContainer()
container.config.from_dict({
'finder': {
'type': 'csv',
'csv': {
'path': '/fake-movies.csv',
'delimiter': ',',
},
'sqlite': {
'path': '/fake-movies.db',
},
},
})
return container
def test_movies_directed_by(container):
finder_mock = mock.Mock()
finder_mock.find_all.return_value = [
container.movie('The 33', 2015, 'Patricia Riggen'),
container.movie('The Jungle Book', 2016, 'Jon Favreau'),
]
with container.finder.override(finder_mock):
lister = container.lister()
movies = lister.movies_directed_by('Jon Favreau')
assert len(movies) == 1
assert movies[0].title == 'The Jungle Book'
def test_movies_released_in(container):
finder_mock = mock.Mock()
finder_mock.find_all.return_value = [
container.movie('The 33', 2015, 'Patricia Riggen'),
container.movie('The Jungle Book', 2016, 'Jon Favreau'),
]
with container.finder.override(finder_mock):
lister = container.lister()
movies = lister.movies_released_in(2015)
assert len(movies) == 1
assert movies[0].title == 'The 33'
现在开始测试并检查覆盖范围:
pytest movies/tests.py --cov=movies
你会看见:
platform darwin -- Python 3.8.3, pytest-5.4.3, py-1.9.0, pluggy-0.13.1
plugins: cov-2.10.0
collected 2 items
movies/tests.py .. [100%]
---------- coverage: platform darwin, python 3.8.3-final-0 -----------
Name Stmts Miss Cover
------------------------------------------
movies/__init__.py 0 0 100%
movies/__main__.py 10 10 0%
movies/containers.py 9 0 100%
movies/entities.py 7 1 86%
movies/finders.py 26 13 50%
movies/listers.py 8 0 100%
movies/tests.py 24 0 100%
------------------------------------------
TOTAL 84 24 71%
我们使用了.override()提供者方法finder。提供者被模拟覆盖。与提供商联系时,finder将返回覆盖的模拟。
工作完成了。现在让我们总结一下。
结论
我们使用依赖注入原理构建了一个CLI应用程序。我们使用了依赖注入器作为依赖注入框架。
Dependency Injector带来的好处是容器。
当您需要了解或更改应用程序的结构时,容器便开始发挥作用。使用容器,这很容易,因为应用程序的所有组件及其依赖项都在一个地方明确定义:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
finder = providers.Selector(
config.finder.type,
csv=csv_finder,
sqlite=sqlite_finder,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=finder,
)
一个容器,作为您的应用程序的映射。您总是知道什么取决于什么。
PS:问题与解答
在对上一教程的评论中,提出了一些很酷的问题:“为什么这是必要的?”,“我们为什么需要一个框架?”,“该框架如何帮助实现?”
我已经准备好答案:
什么是依赖注入?
- 这是减少耦合并增加内聚力的原理
为什么要使用依赖注入?
- 您的代码变得更加灵活,易于理解和可测试
- 当您需要了解其工作原理或进行更改时,您遇到的问题就会更少
我如何开始应用依赖注入?
- 您开始按照依赖注入原理编写代码
- 您将所有组件及其依赖项注册在容器中
- 需要组件时,可以从容器中获取组件
为什么我需要一个框架?
- 您需要一个框架以免创建自己的框架。对象创建代码将重复并且难以更改。为避免这种情况,您需要一个容器。
- 该框架为您提供了一个容器和提供者
- 提供者控制对象的生存期。您将需要工厂,单例和配置对象
- 容器充当提供者的集合
我要支付什么价格?
- 您需要在容器中明确指定依赖项
- 这是额外的工作
- 当项目开始增长时,它将开始支付股息
- 或完成后两周(当您忘记所做的决定以及项目的结构时)
依赖注入器概念
另外,我将把依赖注入器的概念描述为一个框架。
依赖项注入器基于两个原理:
- 显式优于隐式(PEP20)。
- 不要对您的代码做任何魔术。
Dependency Injector与其他框架有何不同?
- 没有自动链接。该框架不会自动链接依赖关系。内省,不按参数名称和/或类型链接。因为“显式优于隐式(PEP20)”。
- 不会污染您的应用程序代码。您的应用程序不了解并且独立于依赖项注入器。没有
@inject装饰器,注释,补丁或其他魔术。
Dependency Injector提供了一个简单的合同:
- 您向框架展示了如何收集对象
- 框架收集它们
依赖注入器的优势在于其简单性和直接性。它是实现强大原理的简单工具。
下一步是什么?
如果您有兴趣,但犹豫不决,我的建议是:
尝试这种方法2个月。他不直观。需要时间来适应和感觉。当该项目在一个容器中扩展到30多个组件时,收益将变得显而易见。如果您不喜欢它,也不要损失太多。如果您喜欢它,将获得显着优势。
- 在GitHub上了解有关Dependency Injector的更多信息
- 退房在阅读文档的文档
我很高兴收到反馈并在评论中回答问题。