
的内心世界之光Mail.ru云解决方案团队翻译了Kevin Wu的节略文章,讨论了制药和医疗保健行业已经通过人工智能和机器学习取得了什么成就,以及何时新技术将有助于寻找药物从所有疾病。
为什么似乎没有进展
有人对这样的生活表示沮丧:“如果这是未来,那我的喷气背包在哪里?”乍一看,在无处不在的计算,可编程单元和复兴的太空探索时代,对复古未来的渴望似乎很奇怪。但是,对于某些人来说,这种怀旧的未来主义令人惊讶地流行。他们坚持认为在回顾中看起来很奇怪的预测,而忽略了没人能预料到的惊人现实。
谁会想到,借助深度学习,我们可以预测尚不存在的药物的性质?这对制药业非常重要。
关于人工智能,抱怨听起来可能是这样的:“自从AlexNet神经网络发明以来,已经过去了近八年的时间。译者:2012年,亚历山大·克里热夫斯基(Aleksey Krizhevsky)发布了AlexNet卷积神经网络的设计,该设计大获全胜ImageNet竞赛],那么我的自动驾驶汽车在哪里?”确实,似乎没有达到2010年代中期的期望。在悲观主义者中,对AI研究的下一轮停滞的预测正在增长。
本文的目的是讨论机器学习在现实世界中的药物发现挑战中的重大进展。我想提醒您,这是AI研究人员的另一句老话。稍微改写一下,听起来像是这样:“ AI被称为AI,直到它起作用,然后才是软件。”
直到几年前,才被认为是机器学习中最前沿的基础研究,现在通常被称为“公正的数据科学”(甚至是分析),并且正在彻底改变制药行业。将深度学习应用到药物发现中,很有可能会极大地改变我们的生活。
生物医学成像中的计算机视觉和深度学习
科学家们一旦能够使用计算机并有机会在计算机上上传图像,他们便立即尝试对其进行处理。基本上,我们在谈论生物医学图像:射线照片,超声和MRI结果。早在老式AI良好的时代,处理通常意味着根据轮廓和亮度等简单属性手动推断逻辑语句。
1980年代,人们转向有监督的机器学习算法,但它们仍然依赖于手持标签。在由SIFT(尺度不变特征变换)和HOG(有向梯度直方图)等算法提取的特征上训练简单的监督学习模型(例如线性回归或多项式逼近)。数十年前就已经开始导致今天的深度学习实际应用的发展不足为奇。
1995年,Law及其同事首次将卷积神经网络用于生物医学图像分析提出了一种通过荧光图识别肺部癌性肿瘤的模型。他们的方法与我们今天使用的方法略有不同,结果的推导花费了大约15秒钟,但是概念基本相同-通过反向传播一直学习到神经网络的卷积核。他们的模型涉及两个隐藏层,而当今流行的深度网络体系结构通常具有一百或更多层。
快进到2012年。卷积神经网络随着AlexNet系统的出现而引起轰动,这导致了现在著名的ImageNet数据集的性能飞跃。 AlexNet的成功在机器学习中非常有名,以至于人们现在都在谈论“ImageNet的时刻“在机器学习和AI的不同领域”。
例如,“随着2018年大型变压器的发展,自然语言处理可能已经没有ImageNet的时机了”或“强化学习仍在等待其ImageNet的时机”。
自AlexNet以来已经过去了近十年。计算机视觉和深度学习模型正在逐步改善。应用程序已经超出了分类范围。今天,他们已经学会了如何分割图像,估计深度以及如何从多个2D图像中自动重建3D场景。这不是其功能的完整列表。
用于生物医学成像分析的深度学习已成为研究的热点。副作用是不可避免的噪声增加。发表于2019约17,000篇关于深度学习的科学文章。当然,并非所有人都值得一读。许多研究人员可能在其适度的数据集上过度拟合了模型。
他们中的大多数人没有对基础科学或机器学习做出任何贡献。对深度学习的热情已经吸引了以前没有兴趣的学术研究人员,这是有充分理由的。它可以完成传统计算机视觉算法的工作(请参阅Tsybenko和Hornik的通用逼近定理),并且通常做得更快,更好,从而使工程师免于每个新应用程序的繁琐手动设计。
与“被忽视的”疾病作斗争的难得机会
这使我们成为当今药物发现的话题,这个行业正处于良好的变革之中。制药公司及其承包商喜欢重申将新药推向市场的巨大成本。这些费用主要是由于许多药物在消耗之前需要花费很长时间进行研究和测试。
开发新药的成本可能高达25亿美元甚至更多。有时,由于成本高和利润率相对较低,某些类药物的许多工作都被归于后台。
它还导致恰当地命名为“被忽视疾病”的类别激增,其中包括数量不成比例的热带疾病。这种疾病折磨着最贫穷国家的人们,被认为不利于治疗;罕见病发病率低。每个人患病的人相对较少,但患有所有罕见疾病的总人数相当多。估计约有3亿人。而且由于专家的阴郁评估,甚至这个数字也可能被低估了:患有罕见疾病的人中大约30%的人不到5岁。
“长尾»罕见疾病具有改善大量人们生活的巨大潜力,而这正是机器学习和大数据得以拯救的地方。没有经过官方批准的治疗的罕见(孤儿)疾病的盲点,为小规模的生物学家和机器学习开发人员团队的创新提供了机会。
犹他州盐湖城的一家这样的初创公司正试图做到这一点。Recursion Pharmaceuticals的创始人将缺乏治疗罕见疾病的药物视为制药行业的空白。他们通过分析显微镜和实验室测试的结果来接收大量数据。借助神经网络,可以识别疾病特征并寻求治疗方法。
到2019年底,该公司已进行了数千次实验,并收集了超过4 PB的信息。他们为NeurIps 2019竞赛发布了这些数据的一小部分(46 GB),您可以从RxRx网站下载并自己玩。
本文中描述的工作流程主要基于Recursion Pharmaceuticals白皮书[ pdf ]中的信息,但是这种方法很可能会为其他领域提供灵感。
该领域的其他初创公司包括Bioage Labs(老龄化疾病),Notable Labs(肿瘤学)和TwoXAR。(没有治疗选择的各种疾病)。通常,年轻的初创公司从事创新的数据处理技术,除了使用计算机视觉进行深度学习之外,还采用了各种机器学习方法。
接下来,我将描述图像分析过程以及深度学习如何适应稀有疾病药物发现工作流程。我们将研究适用于多种其他药物发现领域的高级过程。
例如,它可以很容易地用于筛选抗癌药物对肿瘤细胞形态的影响。甚至可以分析特定患者的细胞对不同药物选择的反应。该方法使用了非线性主成分分析的概念,语义哈希[ pdf ]和良好的旧卷积神经网络图像分类。
形态噪声分类
生物学是一团糟。因此,高通量多参数显微镜检查是细胞生物学家不断挫折的根源。从一个实验到下一个实验,生成的图像差异很大。温度,暴露时间,试剂量等的波动会导致与所研究的表型或药物作用无关的变化,从而导致所得结果的错误。
也许在夏季和冬季,实验室的气候控制工作有所不同?将幻灯片插入显微镜之前,也许有人在幻灯片旁边吃了午餐?培养基成分之一的供应商是否已更改?供应商是否已更改其自己的供应商?大量变量会影响实验的结果。跟踪和突出意外噪声是数据驱动药物发现中的主要挑战之一。
在相同的实验中,显微图像可能会非常不同。图像的亮度,细胞的形状,细胞器的形状以及许多其他特征会由于相应的生理效应或随机误差而发生变化。
因此,下图中的图像是从相同的由Scott Wilkinson和Adam Marcus编写的一组公开的转移性癌细胞显微照片。饱和度和形态的变化应反映实验数据的不确定性。通过在处理中引入失真来创建它们。它是增强的一种类似物,研究人员用来对分类问题中的深度神经网络进行正则化。因此,毫不奇怪,将大型模型推广到大型数据集的能力是在嘈杂的海洋中寻找具有生理意义的特征的逻辑选择。
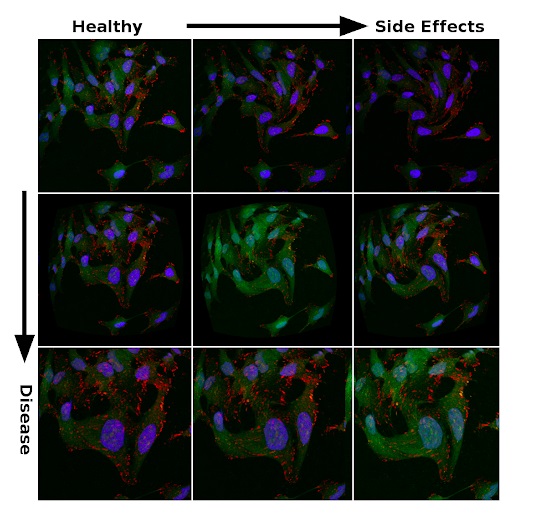
嘈杂数据中治疗效果和副作用的迹象
罕见疾病的主要原因通常是遗传突变。为了建立寻找这些疾病的治疗方法的模型,有必要了解各种突变的影响及其与不同表型的关系。为了有效比较特定罕见疾病的可能治疗方法,基于数千种不同的突变训练了神经网络。
这些突变可以通过使用小分子干扰RNA抑制基因表达来模拟(siRNA)。这有点像婴儿抓住脚踝:即使跑得快,但侄女或侄子悬在每条腿上,速度也会急剧下降。 siRNA的工作原理大致相同:一小串干扰RNA粘在特定基因的信使RNA的相应部分,从而阻止了它们的完整表达。
通过从成千上万的突变中学习,而不是从特定疾病的单细胞模型中学习,神经网络学会了在多维隐藏空间中对表型进行编码。生成的代码可以通过使疾病表型更接近健康表型的能力来评估药物,每种表型都由多维坐标集表示。同样,药物的副作用可以嵌入到表型的编码表示中,并且不仅要评估药物在疾病症状消失方面的作用,而且还要将药物的有害副作用降到最低。

该图显示了治疗对疾病的细胞模型的影响(用红点表示)。治疗是使编码表型向健康表型(蓝点)移动。这是多维隐藏空间中表型编码的简化3D表示形式。
用于此工作流的深度学习模型与大型数据集的其他分类问题非常相似,尽管如果您习惯于处理少量类别,如CIFAR-10数据集和CIFAR-100,您将不会立即适应数千种不同的分类标记。
而且,这种基于图像的药物发现方法可与具有数百层的相同DenseNet或ResNet架构很好地配合使用,从而在ImageNet等数据集上提供最佳性能。
多维空间中编码的层激活值反映了表型,疾病发病机理,治疗之间的关系,副作用和其他疾病。因此,所有这些因素都可以通过在编码空间中的位移来分析。可以对该表型代码进行特殊的正则化(例如,通过最小化层的不同激活之间的协方差)以减少编码相关性或用于其他目的。
下图显示了简化模型。黑色箭头表示卷积+合并的操作。蓝线表示紧密连接。为简单起见,减少了层数,未显示剩余连接。
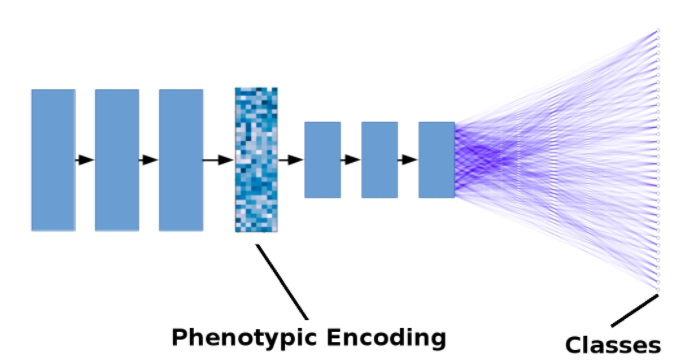
药物发现深度学习模型的简化图示
药物发现和制药行业中深度学习的未来
将新药推向市场的高昂成本已导致制药公司经常选择市场冲击,而不是研究用于治疗严重疾病的药物。新兴企业中规模较小的数据分析团队在此领域的创新能力更强,而被忽视和罕见的疾病为进入市场并展示机器学习的价值提供了机会。
这种方法的有效性已得到证明。我们看到了重大的研究进展,几种药物已经在临床试验的第一阶段。例如,仅由Recursion Pharmaceuticals等公司的几百名科学家和工程师组成的团队就可以实现这一目标。其他新兴公司也在附近:TwoXAR有几种候选药物正在其他疾病类别中进行临床前试验。
可以预期,用于药物开发的深度学习和计算机视觉方法将对大型制药公司和总体医疗保健产生重大影响。我们很快就会看到这将如何影响对常见疾病(包括心脏病和糖尿病)的新疗法的开发,以及至今仍不可见的罕见疾病。
关于该主题还需要阅读什么: