
语音检查的任务之一是确定录音的真实性和真实性,换句话说,就是确定录音的编辑,失真和更改的迹象。为了确定记录的真实性,我们有进行记录的任务-确定对记录没有影响。但是,如何分析成千上万的录音呢?
AI方法以及用于处理音频的实用程序为我们提供了帮助,我们在NewTechAudit网站“使用FFMPEG处理音频”上的文章中谈到了这种方法。
音频变化如何出现?如何从未修改的文件中分辨出已修改的文件?
有几种这样的标志,最简单的是识别有关编辑文件并分析其修改日期的信息。这些方法可以通过OS本身轻松实现,因此我们不再赘述。但是,可以由更有资格的用户进行更改,他们可以隐藏或更改有关编辑的信息,在这种情况下,将使用更复杂的方法,例如:
- 轮廓移动;
- 更改已录制音频的频谱轮廓;
- 出现停顿;
- 还有很多其他
所有这些复杂的发声方法都是由受过专门训练的专家-声音学家使用诸如Praat,语音分析仪SIL,ELAN之类的专用软件执行的,其中大多数都是有偿的,并且需要足够高的资格才能使用和解释结果。
专家使用频谱曲线(即通过分析其倒频谱系数)来分析音频。我们将利用专家的经验,同时使用现成的代码,使其适应我们的任务。
因此,可以进行很多更改,我们如何选择?
在可以对音频文件进行的更改的可能类型中,我们感兴趣的是从音频中切出一部分,或者切出一部分,然后用相同持续时间的片段替换原始部分-所谓的剪切/复制更改。在降低噪音,更改音频频率等方面编辑文件不会带来隐藏信息的风险。
以及我们将如何识别这些相同的剪切/副本?是否应该将它们与某些东西进行比较?
这非常简单-借助FFmpeg实用程序,我们将从文件中剪切出一部分随机持续时间,然后在随机位置中进行比较,然后我们将比较原始文件和“剪切”文件的小倒谱图。
显示它们的代码:
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
def make_spek(audio):
n_fft = 2048
y, sr = librosa.load(audio)
ft = np.abs(librosa.stft(y[:n_fft], hop_length = n_fft+1))
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max)
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(mel_spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time');
plt.title('Mel Spectrogram');
plt.colorbar(format='%+2.0f dB');
plt.show();
make_spek('./audio/original.wav')# './audio/original.wav' 我们从源准备数据集,并使用FFmpeg实用程序命令剪切文件:
ffmpeg -i oroginal.wav -ss STARTTIME -to ENDTIME -acodec copy cut.wav 其中STARTTIME和ENDTIME是剪切片段的开始和结束。并使用命令:
ffmpeg -iconcat:"part_0.wav|part_1.wav |part_2.wav" -codeccopyconcat.wav将文件的一部分连接起来,以将part_1.wav与原始部分一起插入(有关将FFmpeg命令包装在python中的信息,请参见FFmpeg上的文章)。
这里是原始文件,其中粉笔频谱已经被切出的0.2-2.5秒的音频,而且已经被切出的0.2-2.5秒的音频,然后插入到该音频文件的相同期限的音频片段文件的粉笔谱图:
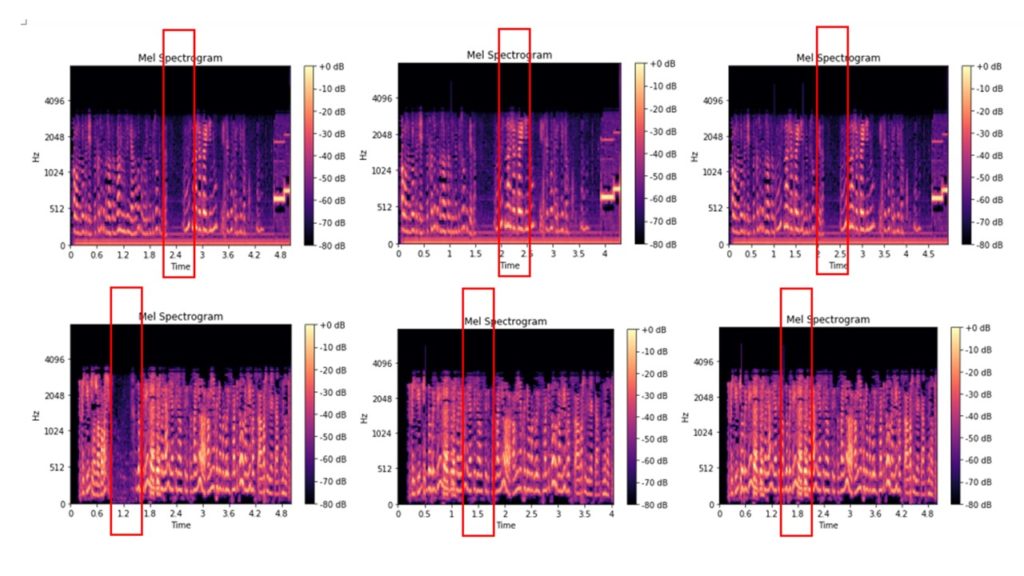
一些图像即使在视觉上也可以区分,其他图像几乎相同。我们将生成的图像分发到文件夹中,并将它们用作训练图像分类模型的输入数据。资料夹结构:
model.py #
/input/train/original/ #
/input/train/cut_copy/ # 对于我们来说,是对修改后的音频文件进行补充还是缩短都没有什么不同-我们将所有结果分为好结果,即没有更改的文件和坏的文件。因此,我们解决了经典的二进制分类问题。我们将使用神经网络进行分类,我们将从使用Keras软件包的示例中获取用于神经网络的代码。
#
from keras.models import Sequential
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
#
classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Flatten())
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 1, activation = 'sigmoid'))
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
#
from keras.preprocessing.image import ImageDataGenerator as img
train_datagen = img(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = img(rescale = 1./255)
training_set = train_datagen.flow_from_directory('input/train',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
test_set = test_datagen.flow_from_directory('input/test',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
classifier.fit_generator(
training_set,
steps_per_epoch = 8000,
epochs = 25,
validation_data = test_set,
validation_steps = 2000)此外,在模型训练后,我们将在其帮助下进行分类
import numpy as np
from keras.preprocessing import image
test_image = image.load_img('dataset/prediction/original_or_corrupt.jpg', target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
ifresult[0][0] == 1:
prediction = 'original'
else:
prediction = 'corrupt'在输出中,我们获得音频文件分类-'原始'/'损坏',即 该文件保持不变,并对其进行更改。
我们再次证明,看似复杂的事情可以轻松完成-我们没有使用最困难的AI方法机制,现成的解决方案,并检查了音频是否有变化。好吧,我们是侦探的专家。