技术界已经接受了新的炒作-GPT-3。
巨大的语言模型(例如GPT-3)以其功能不断给我们带来惊喜。尽管企业对它们的信心不足以将其展示给客户,但这些模型证明了智能的开端,将加速自动化的发展以及“智能”计算系统的功能。让我们从GPT-3中获取神秘的光环,并了解它的学习方式和作用方式。
受过训练的语言模型会生成文本。我们还可以将一些文本发送到模型的输入,并查看输出如何变化。后者是根据模型在训练期间通过分析大量文本而获得的信息而生成的。
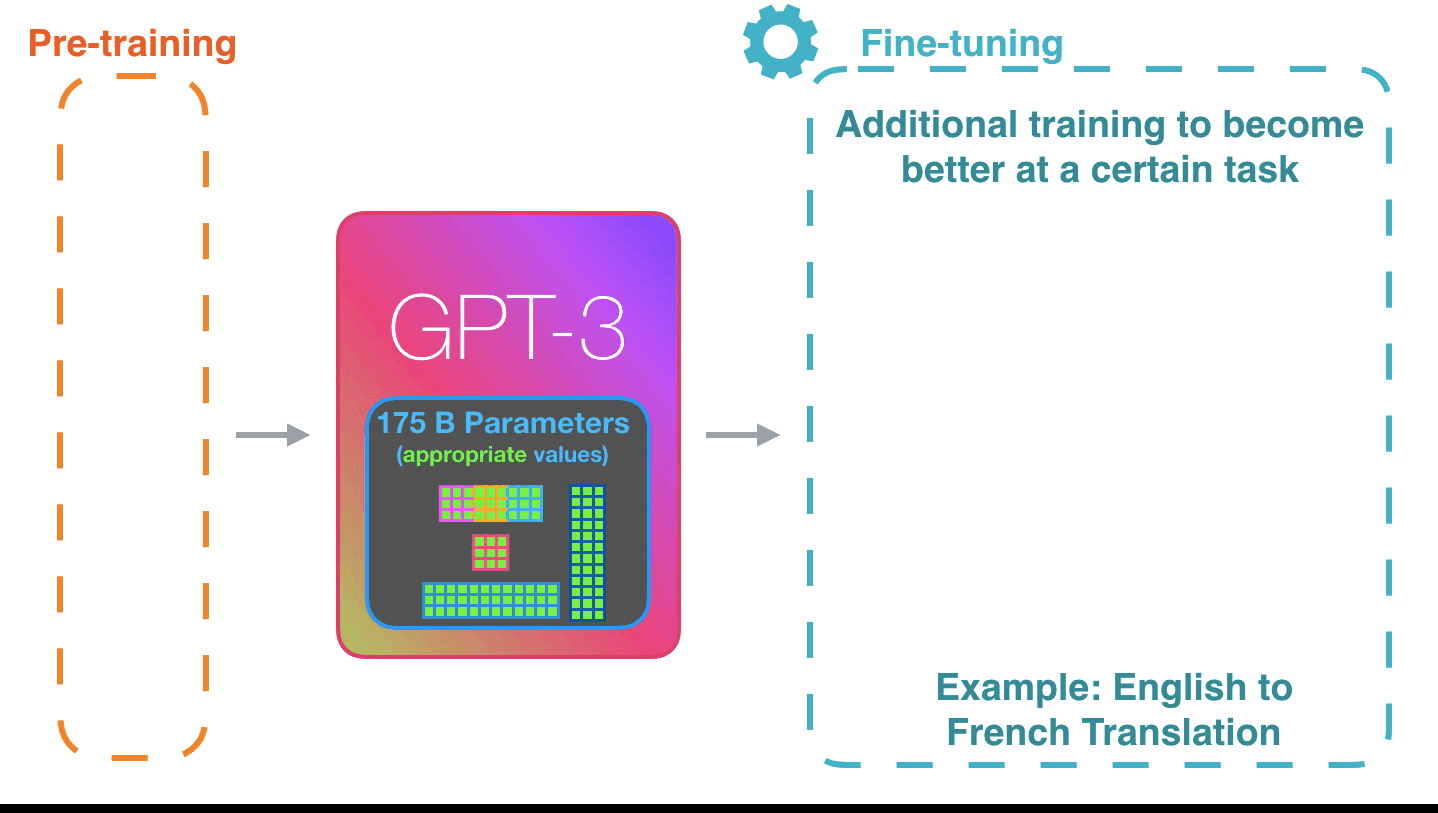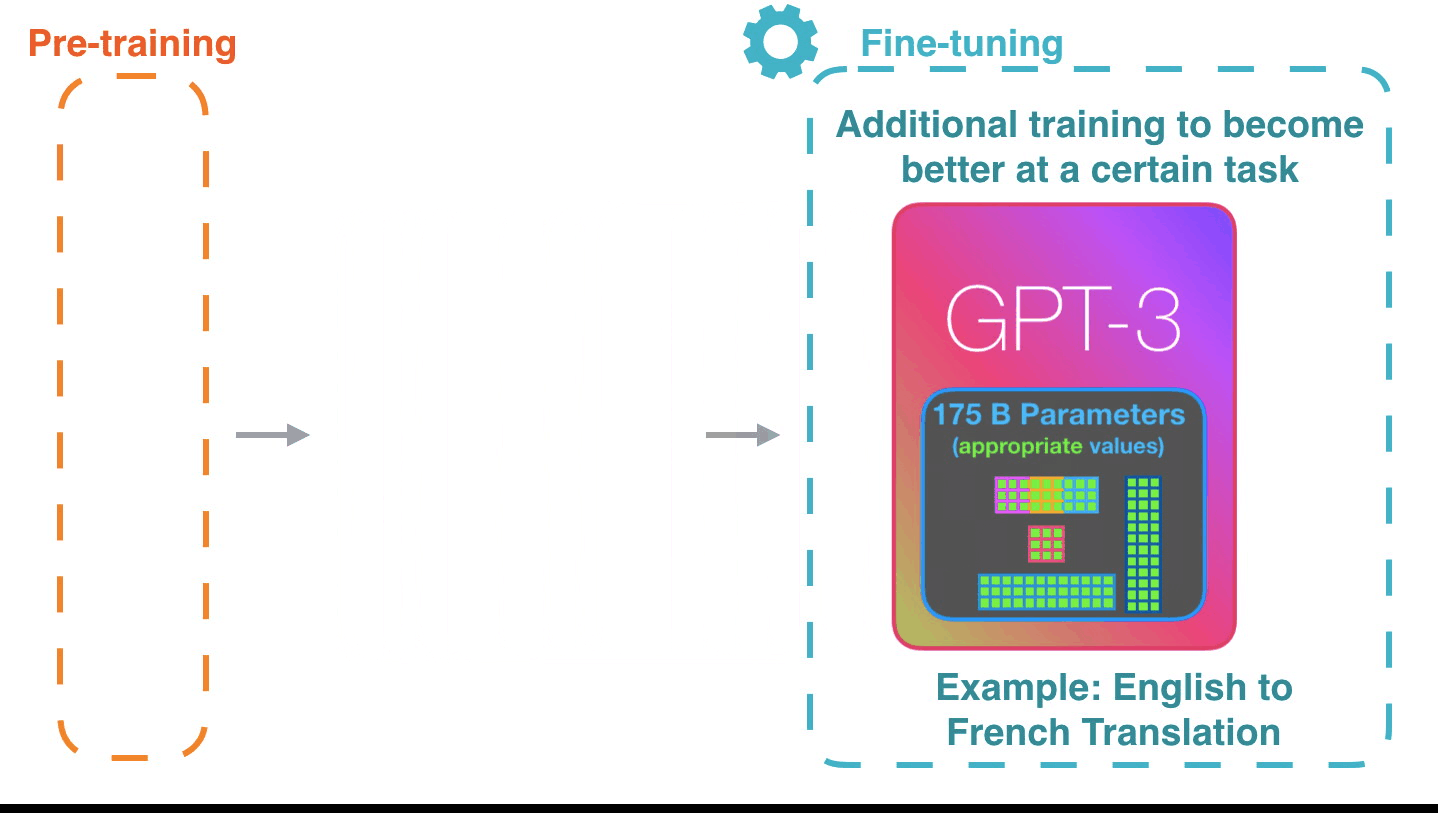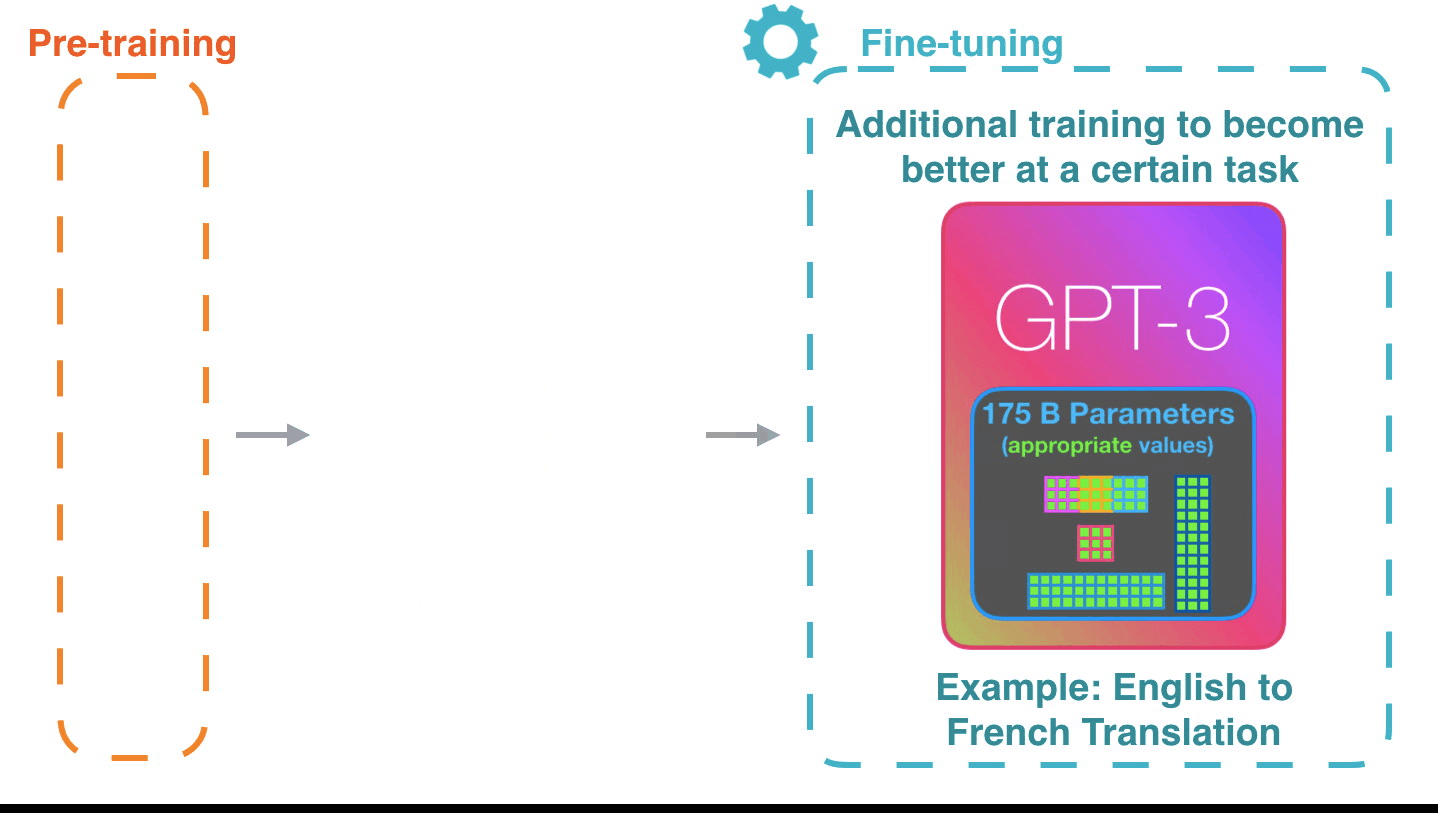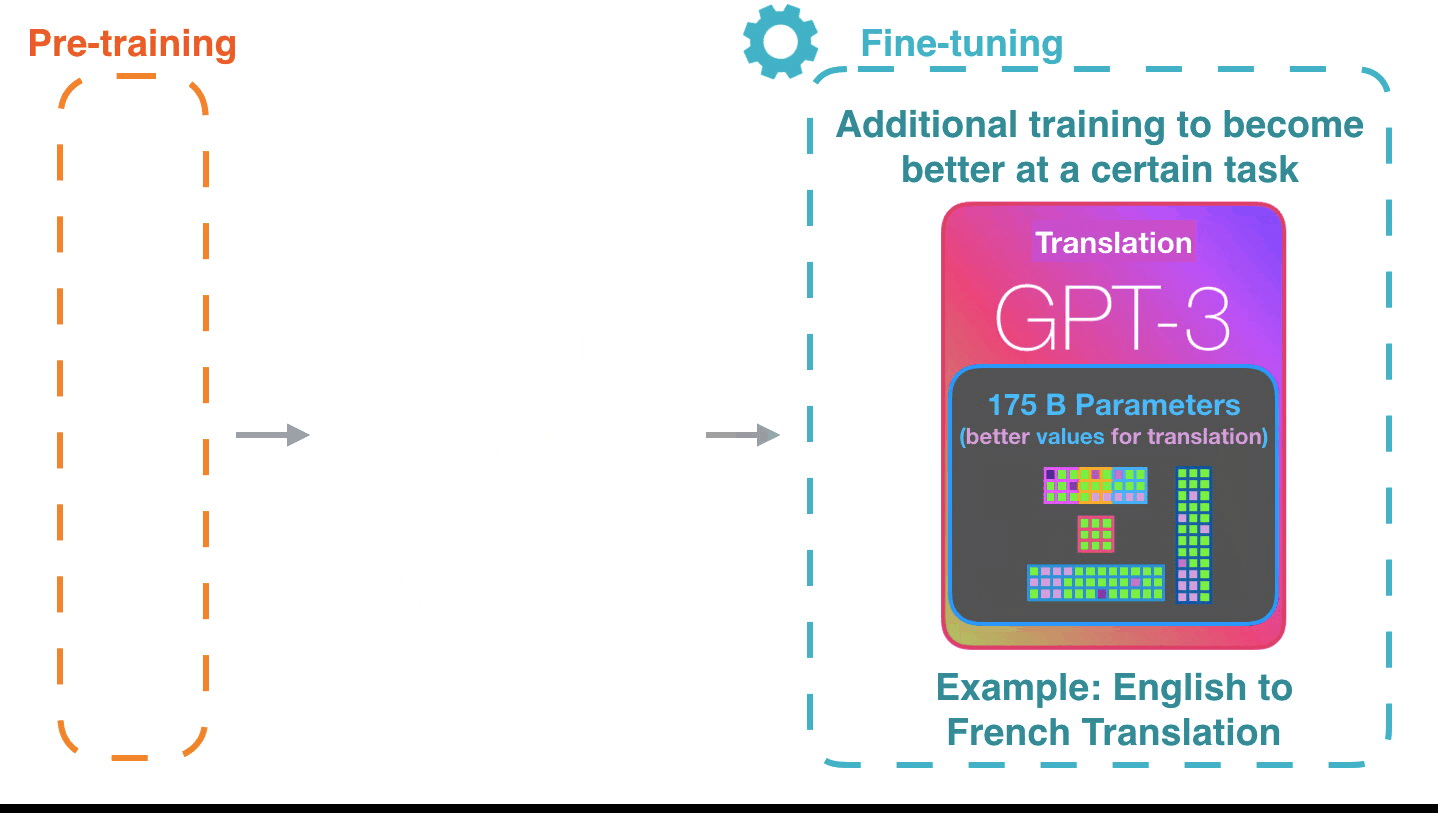
学习是将大量文本传输到模型的过程。对于GPT-3,此过程已完成,您可以看到的所有实验都在已经训练好的模型上运行。据估计,培训需要355年的GPU时间(在单个图形卡上进行355年的培训),费用为460万美元。
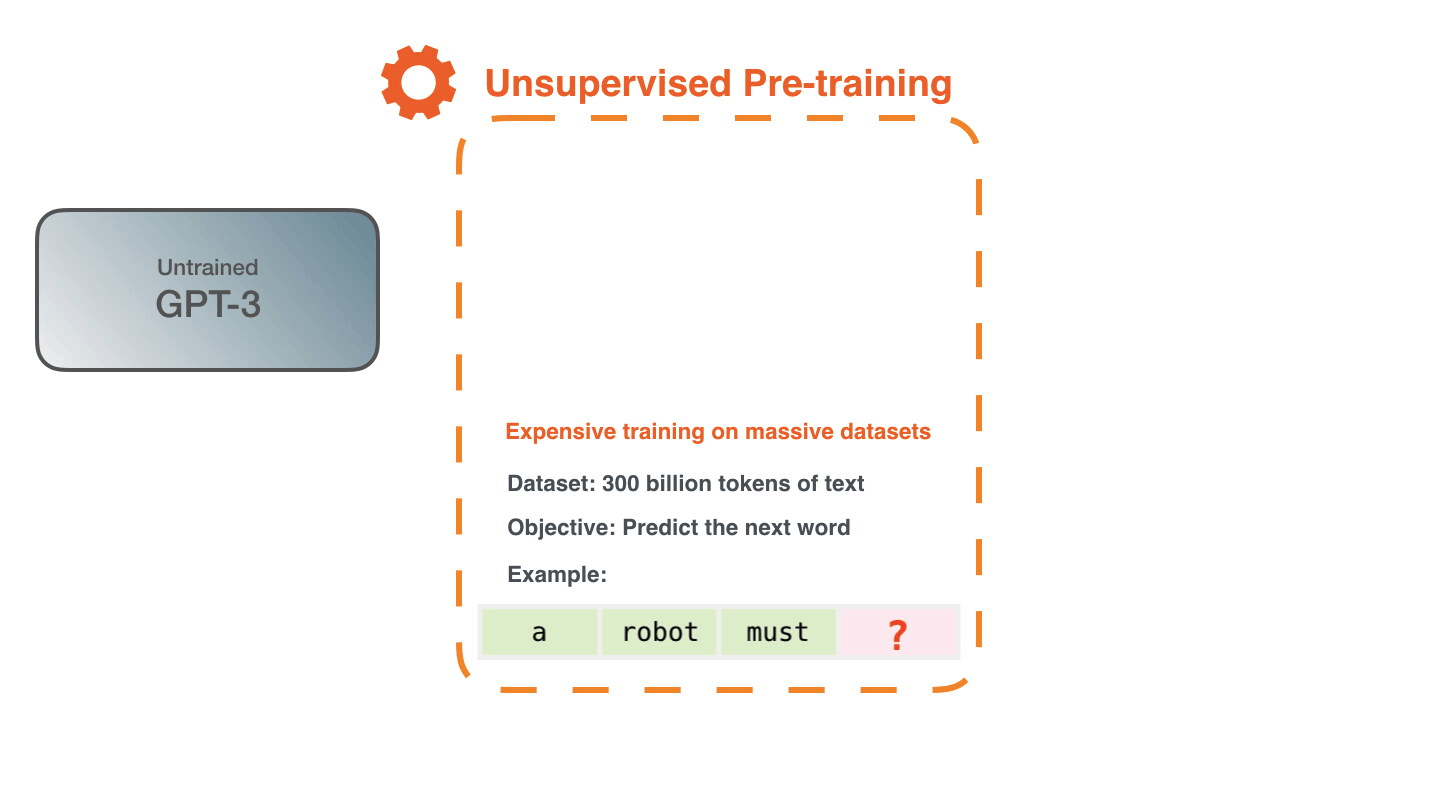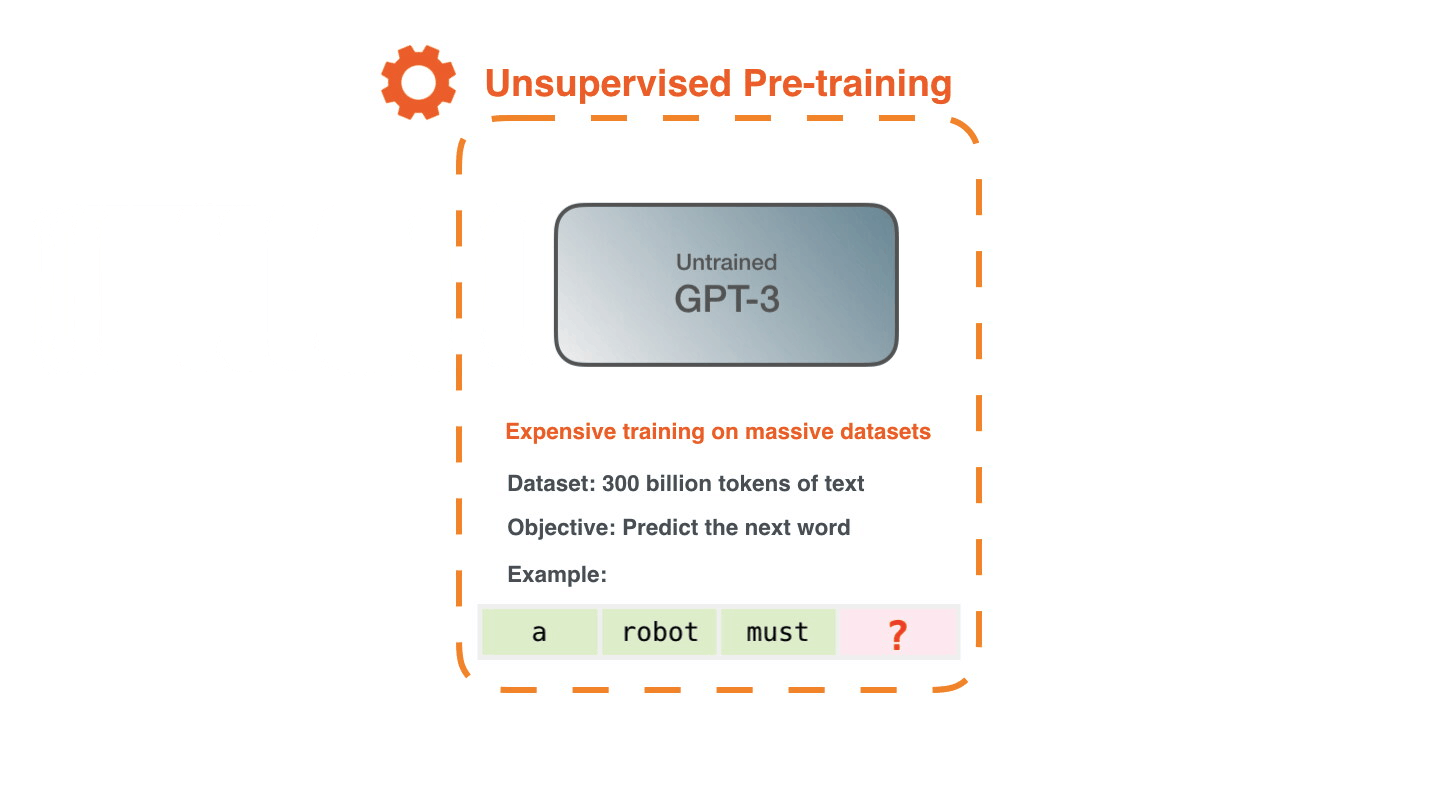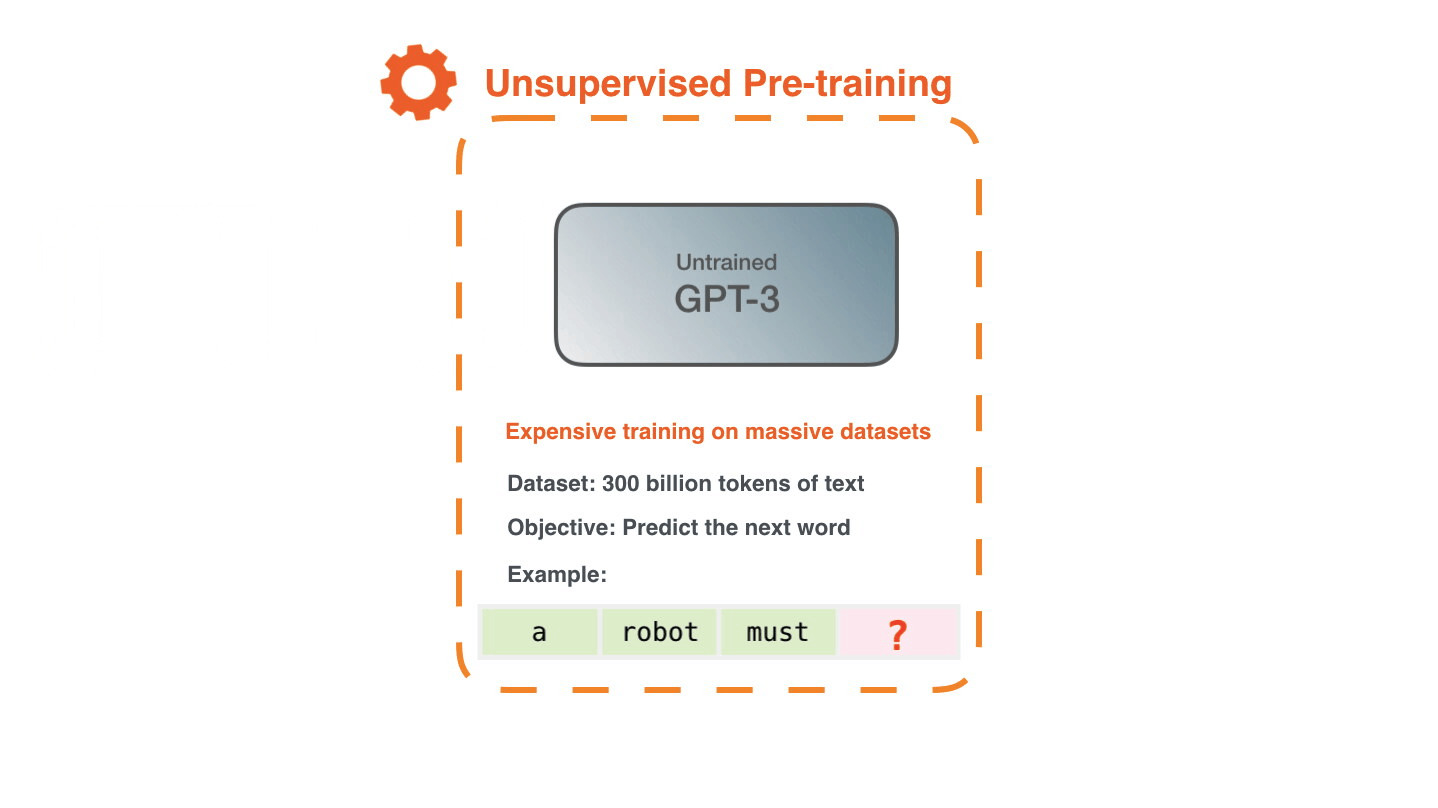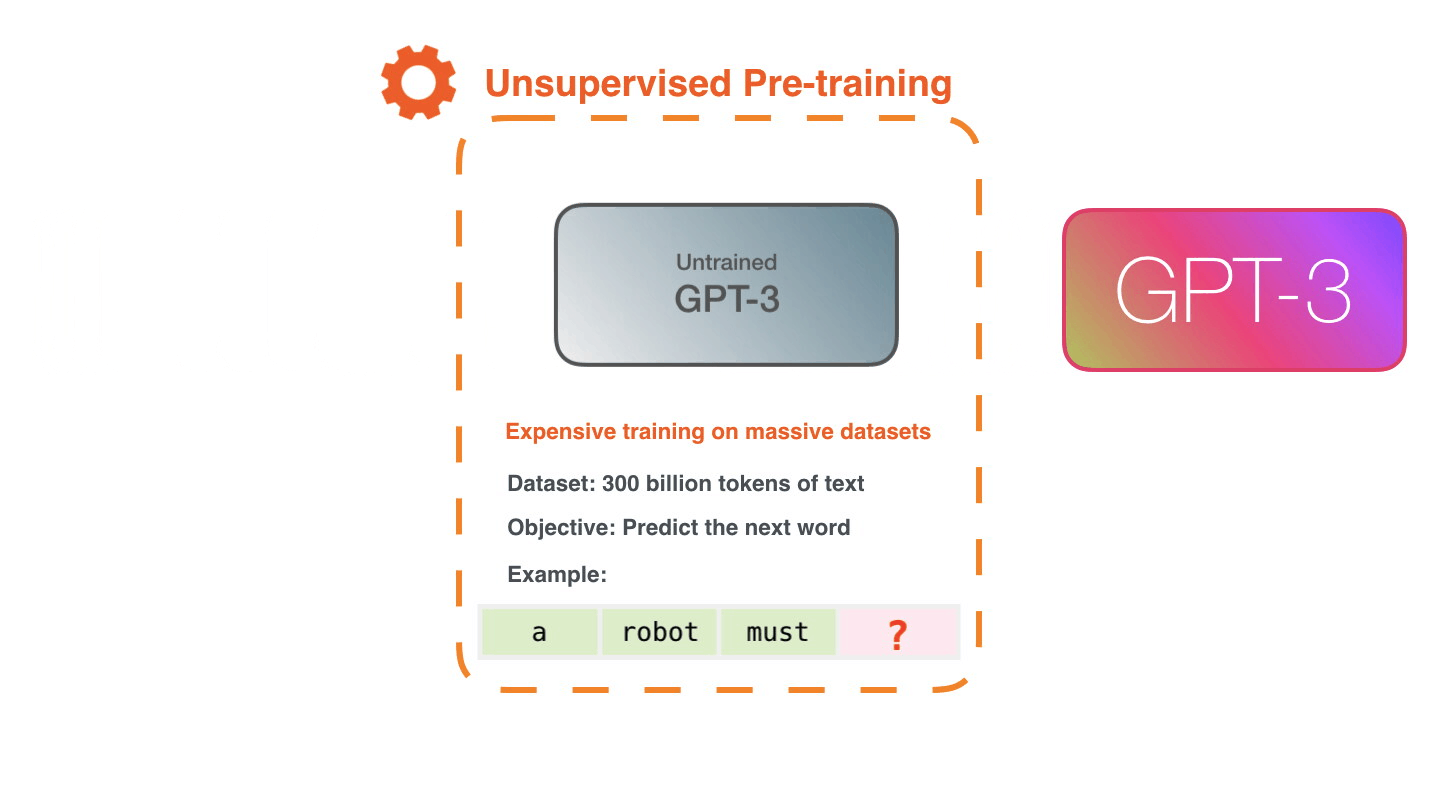
使用3000亿个文本令牌的数据集来生成用于训练模型的示例。例如,这是从上面的一个句子派生的三个训练示例的样子。
, , .
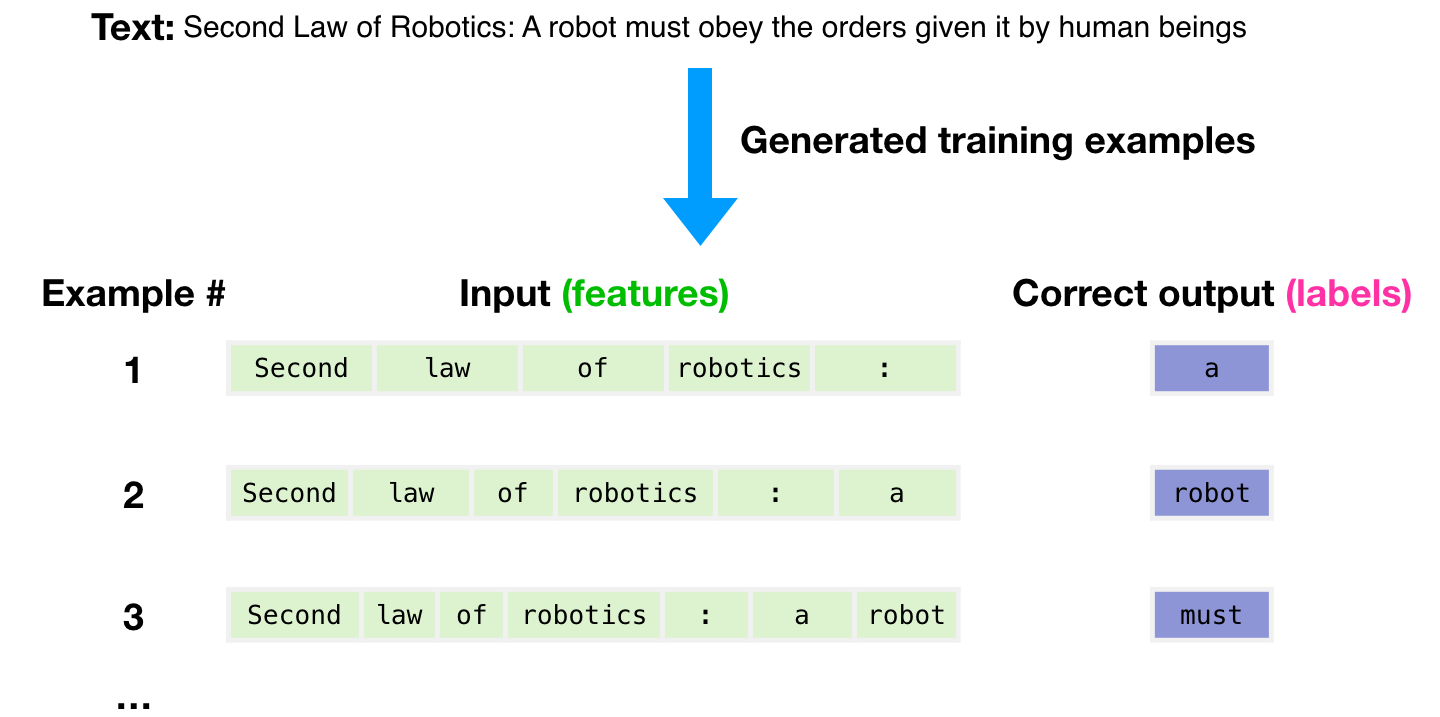
( ) .
. , .
.

.
GPT-3 ( , – ).

GPT-3 . , , 175 ( ). .
, , .
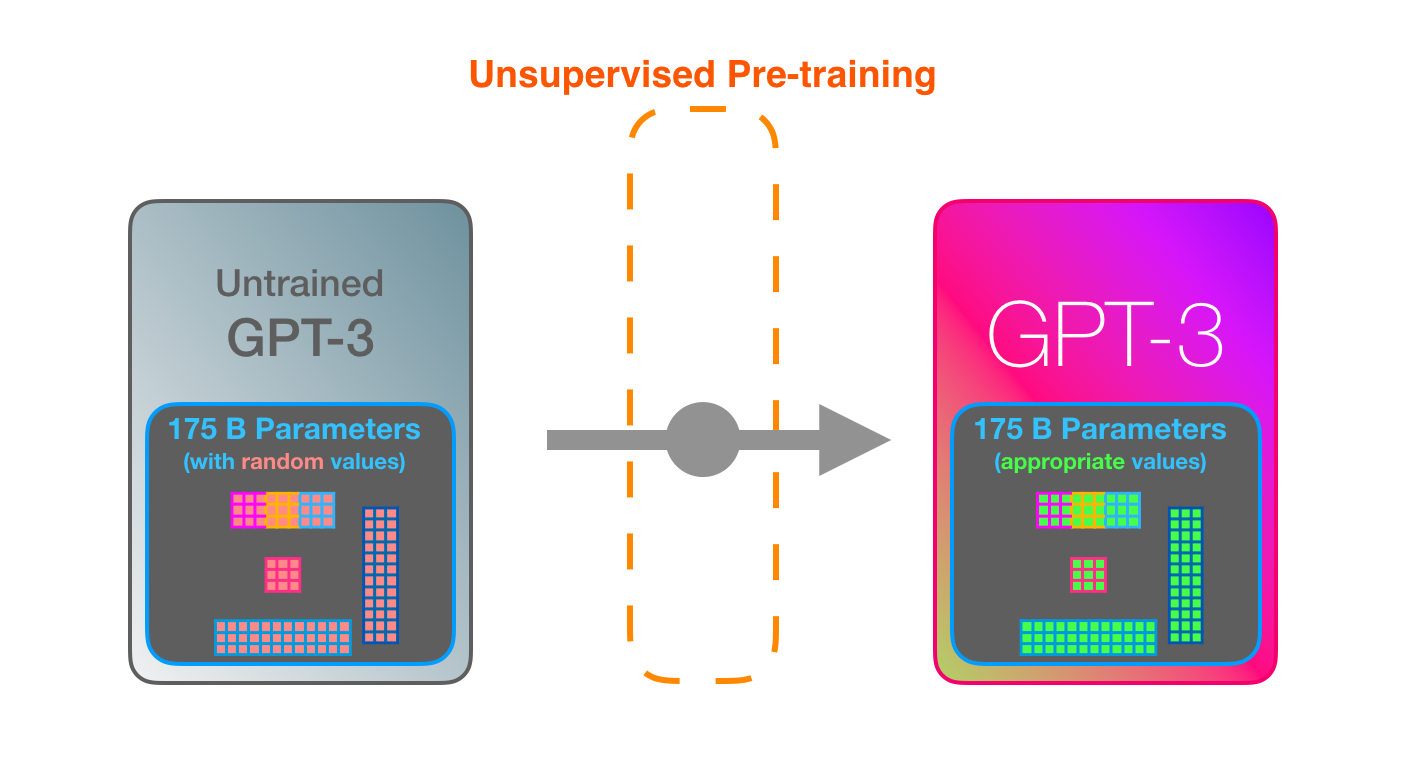
– , – , .
« Youtube» – 175- .
, , .
GPT-3 2048 – « », 2048 , .
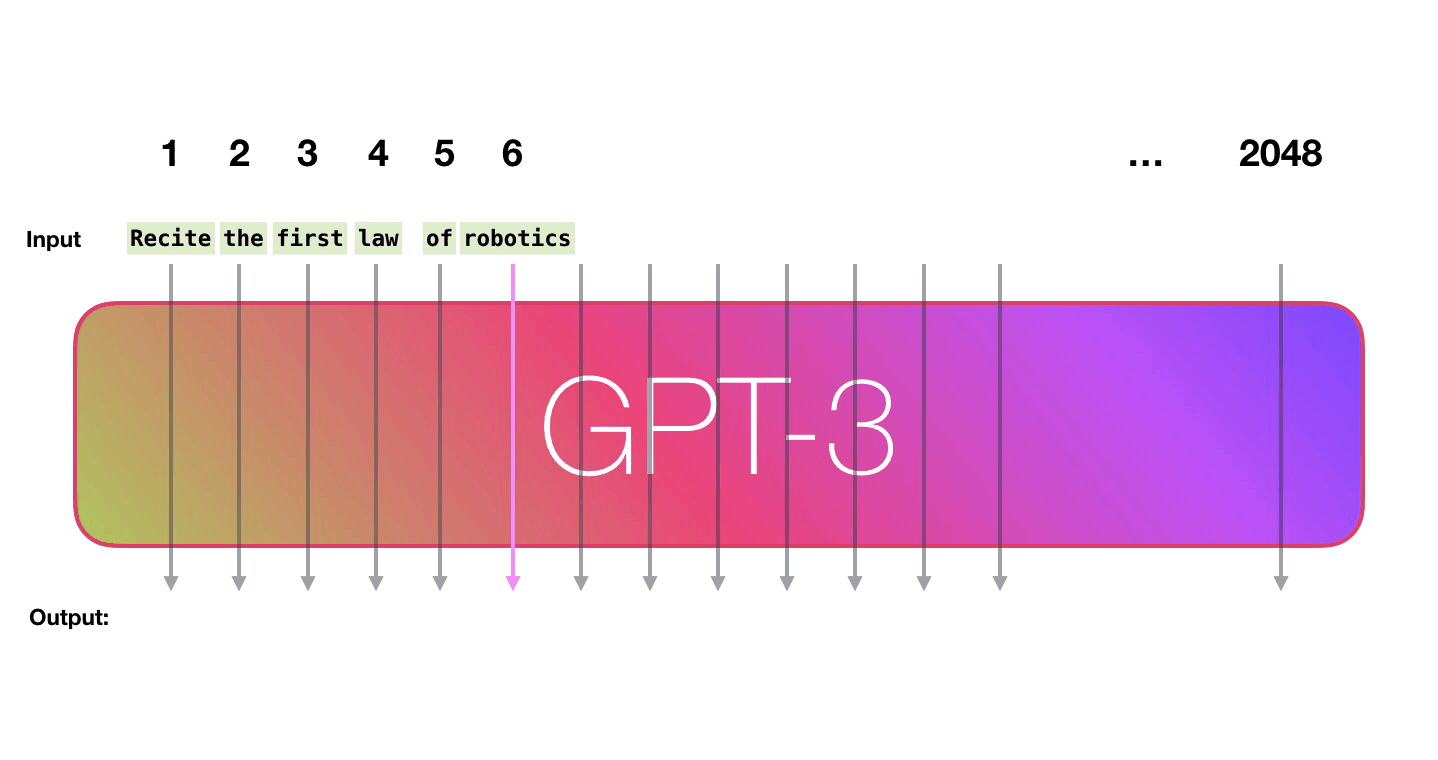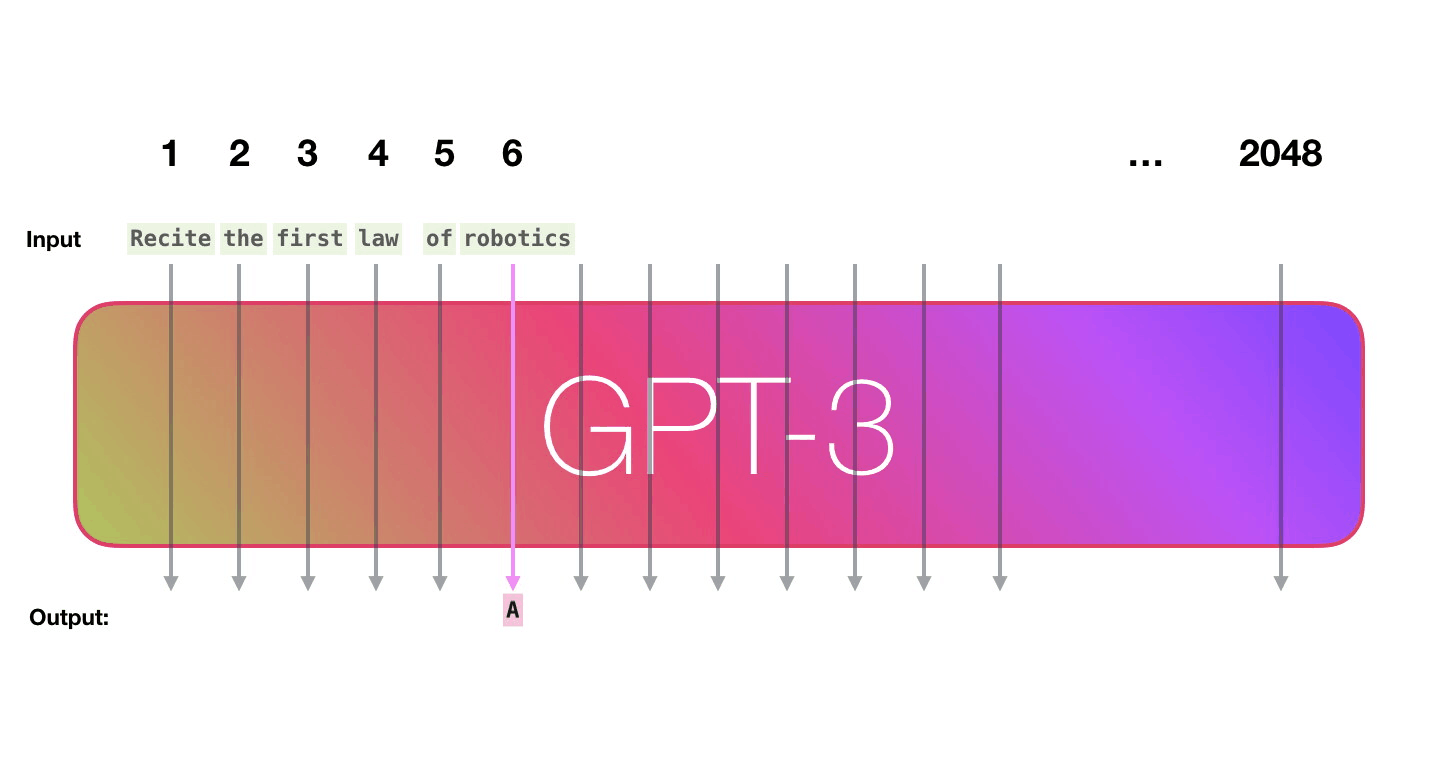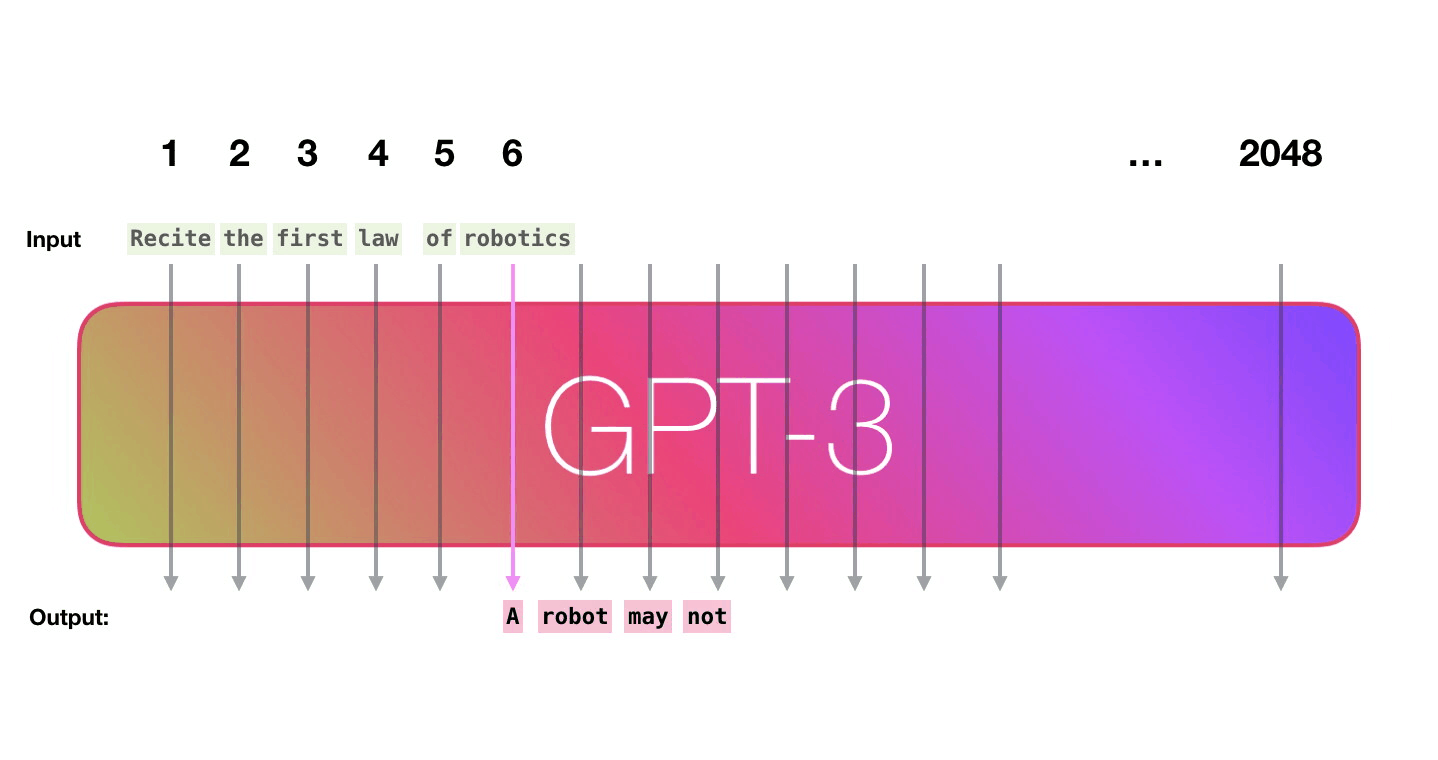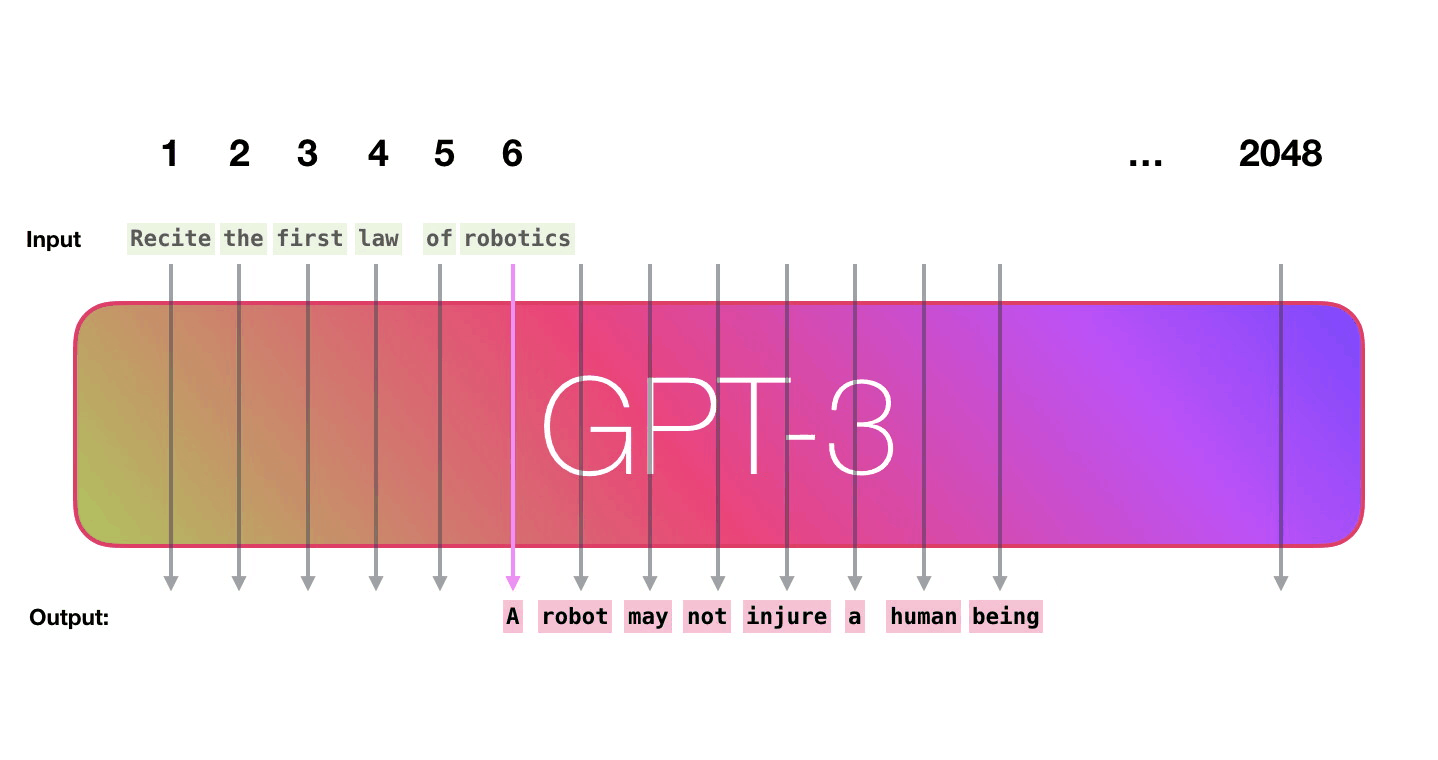
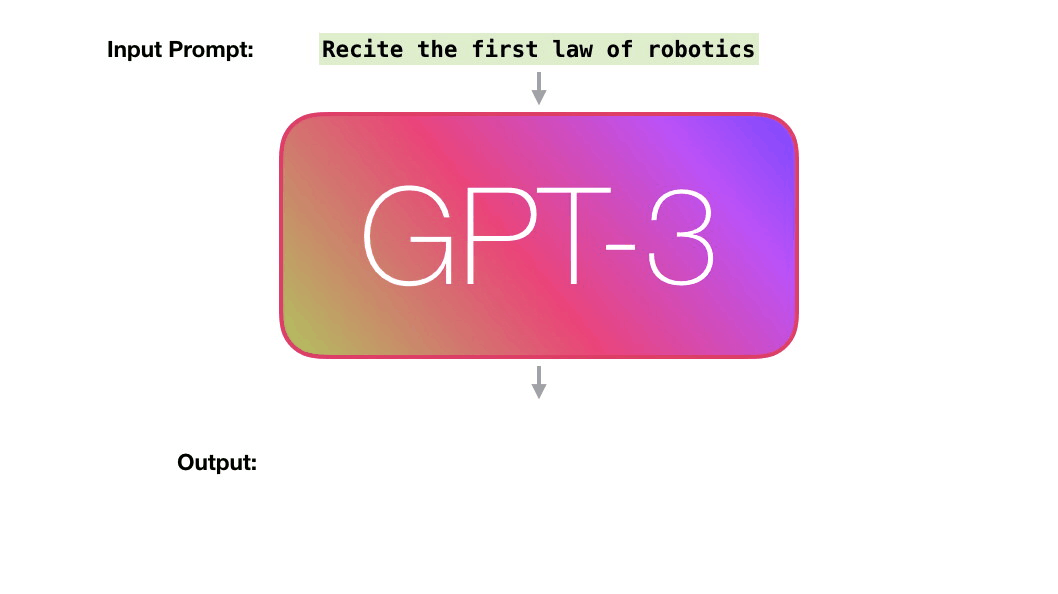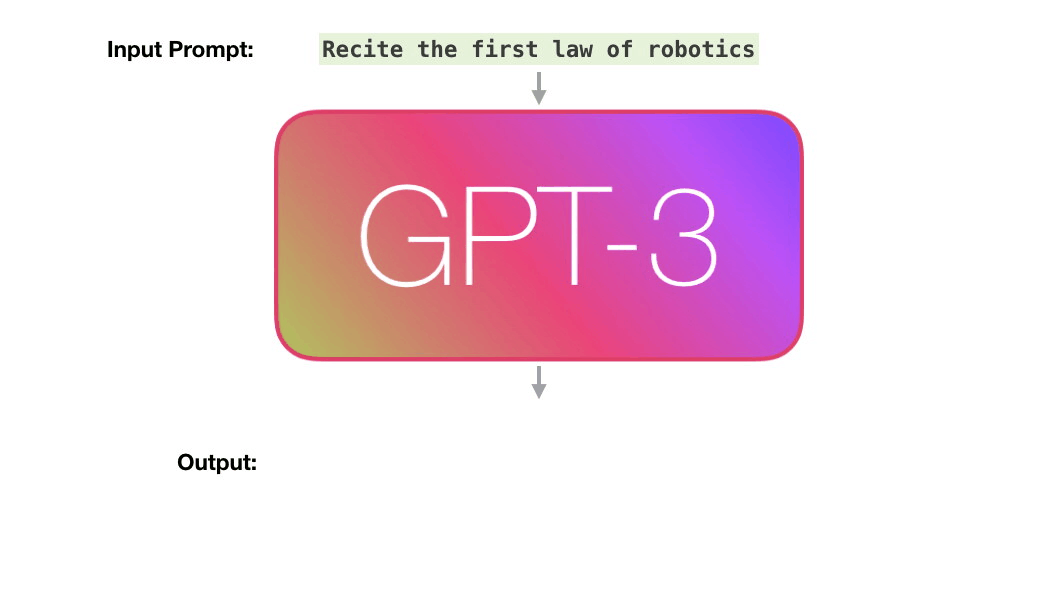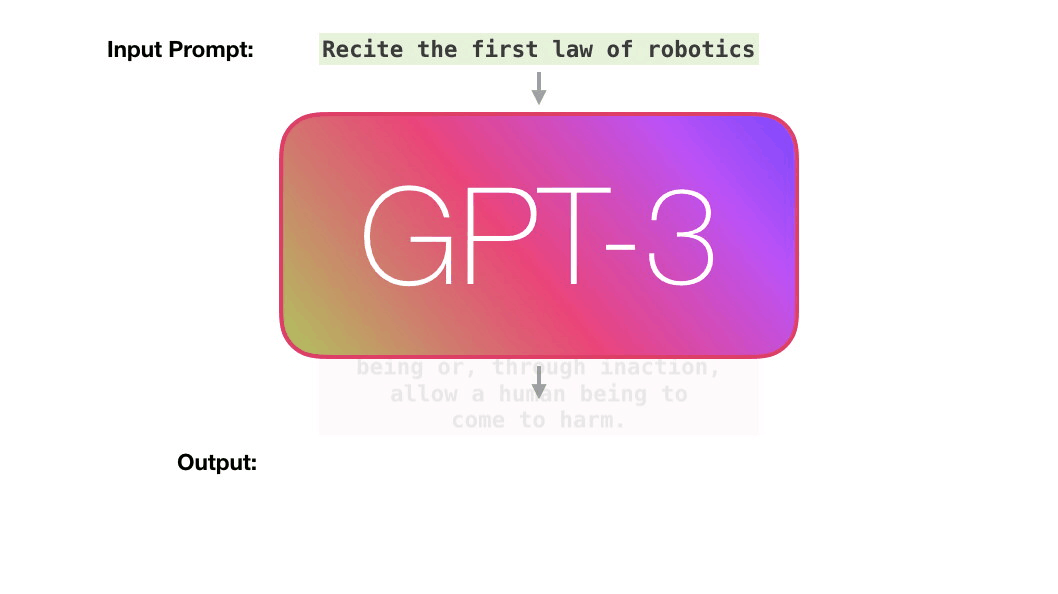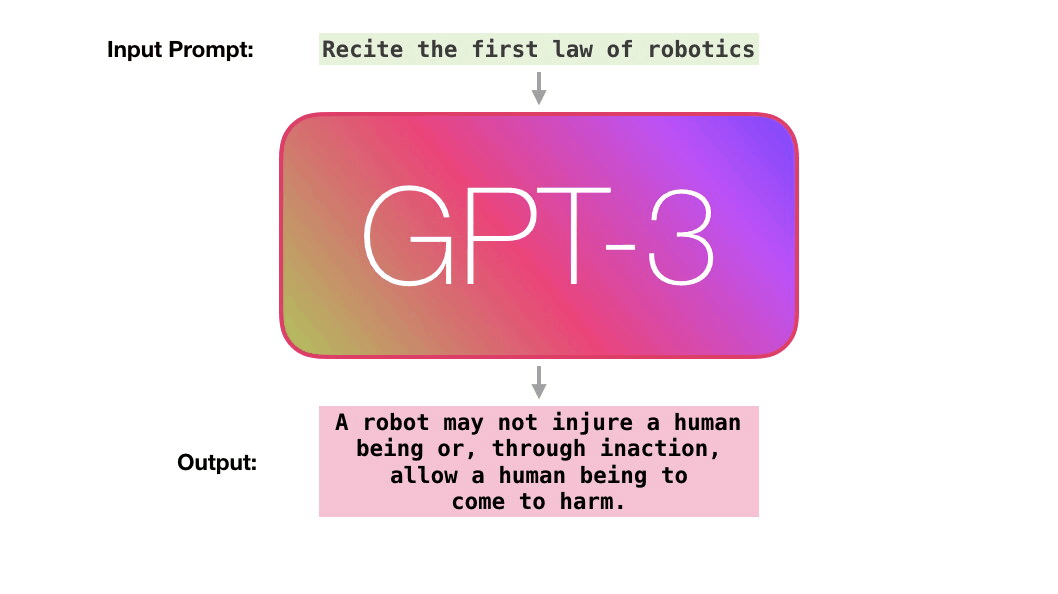
. «robotics» «A»?
:
- ( ).
- .
- .
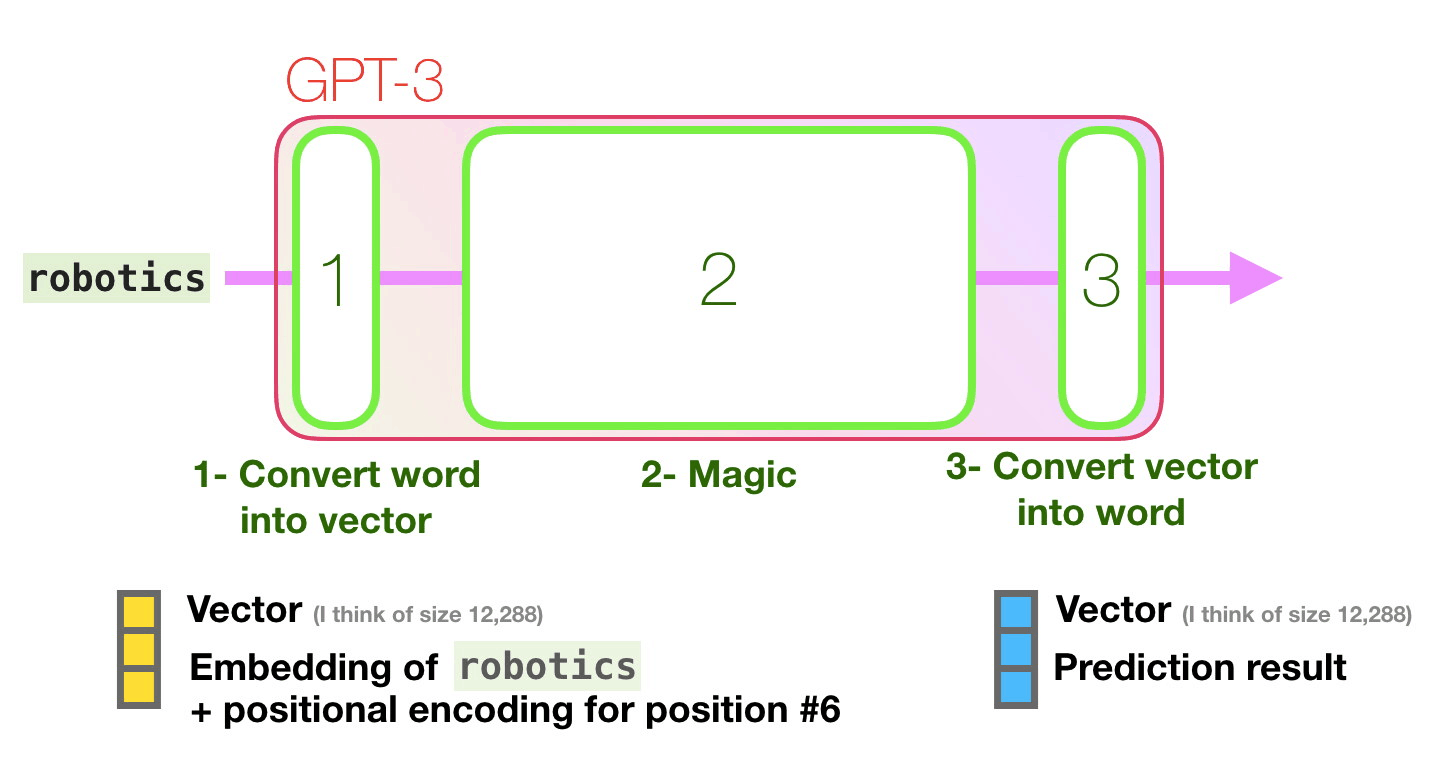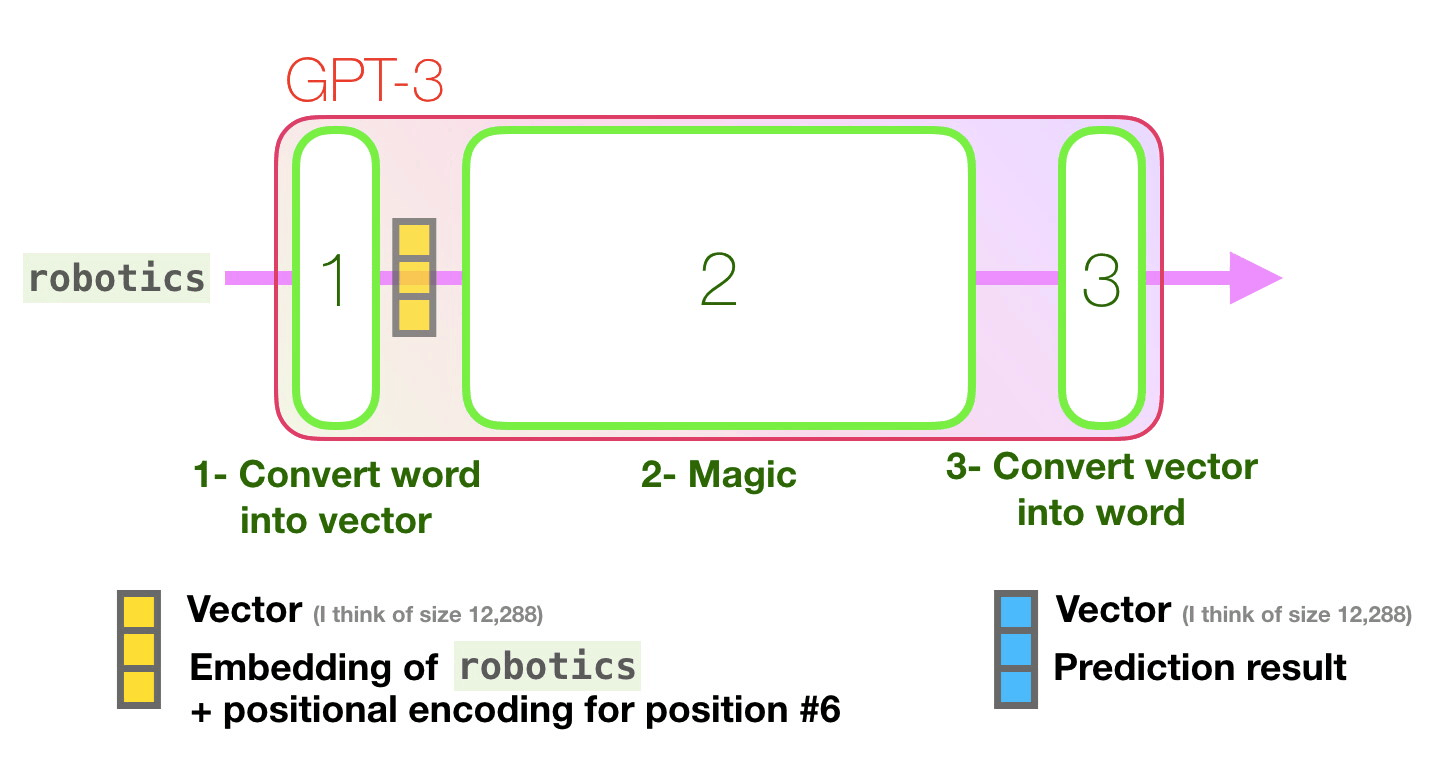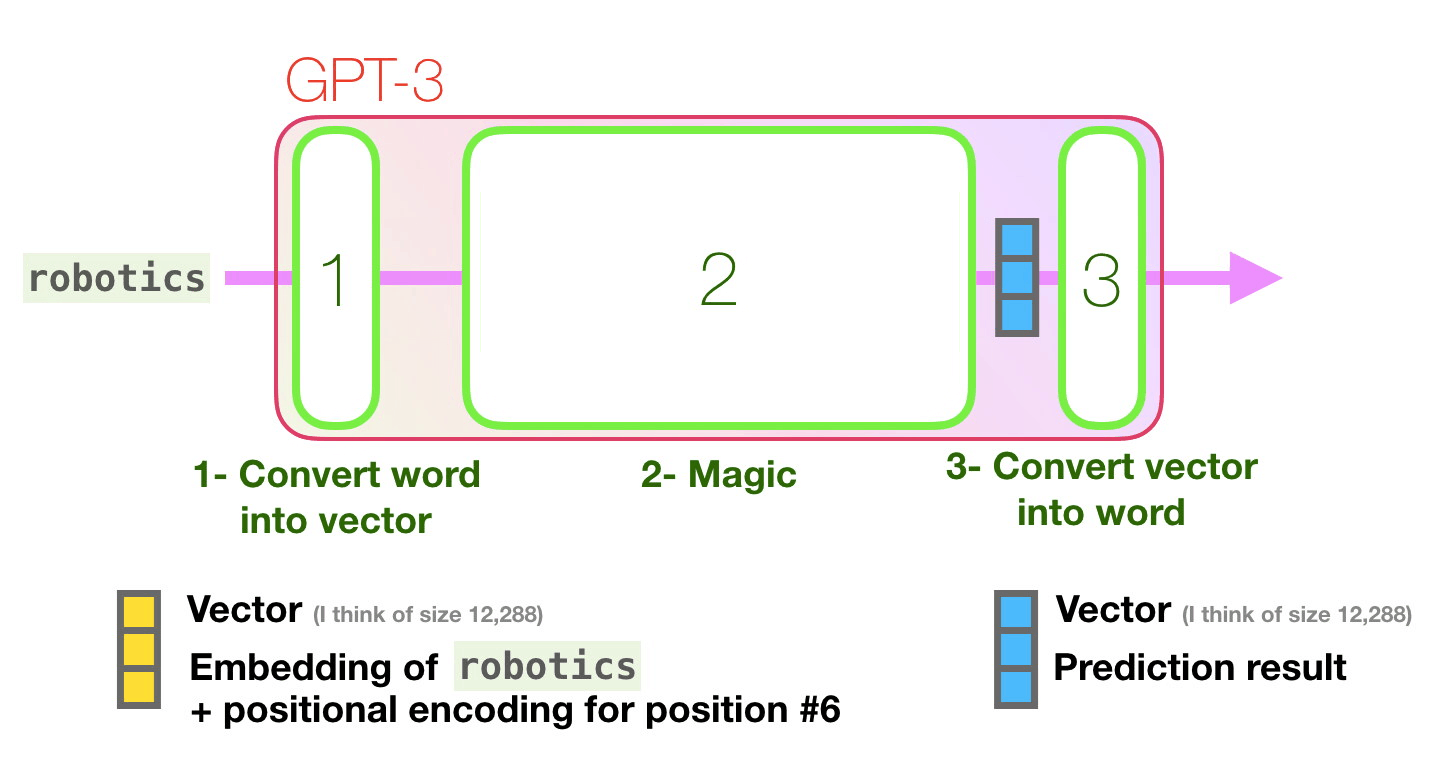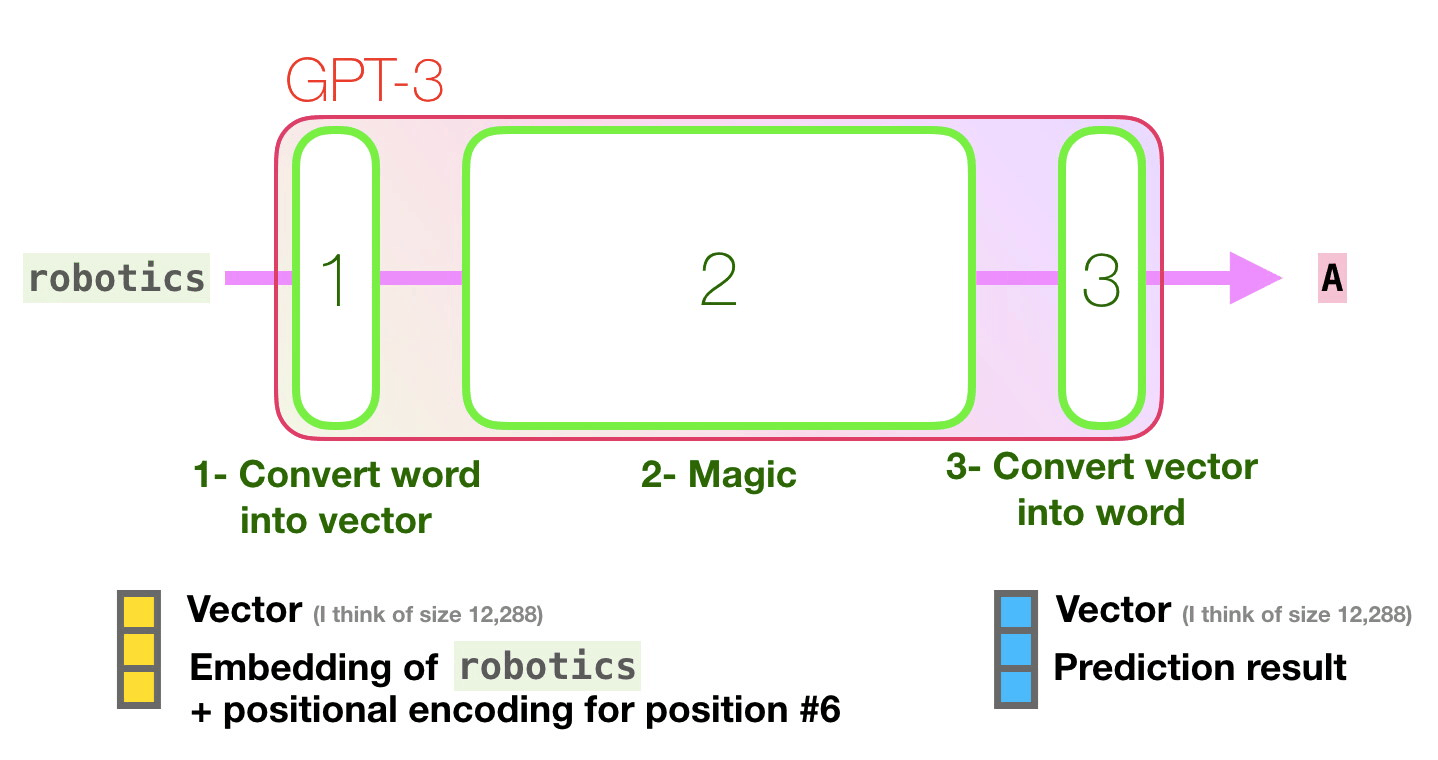
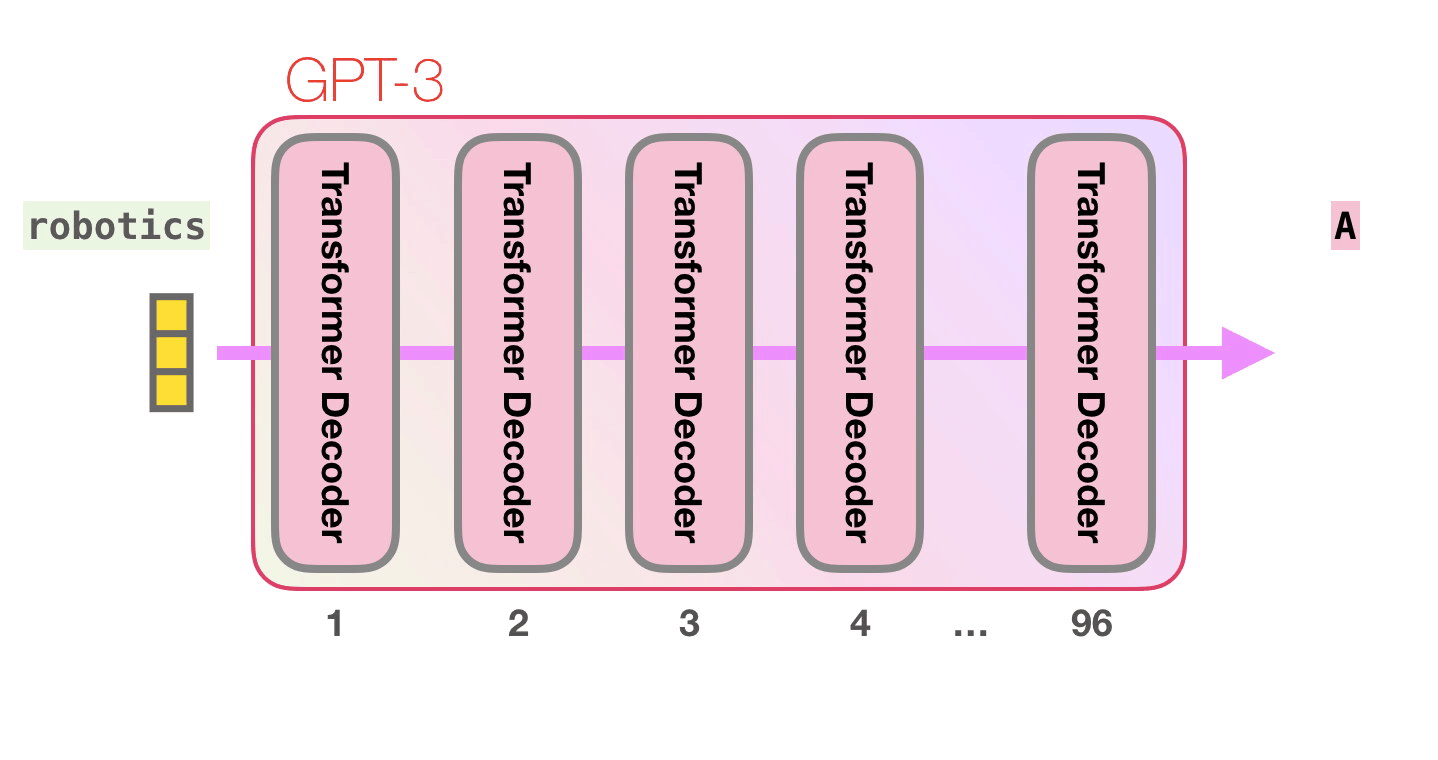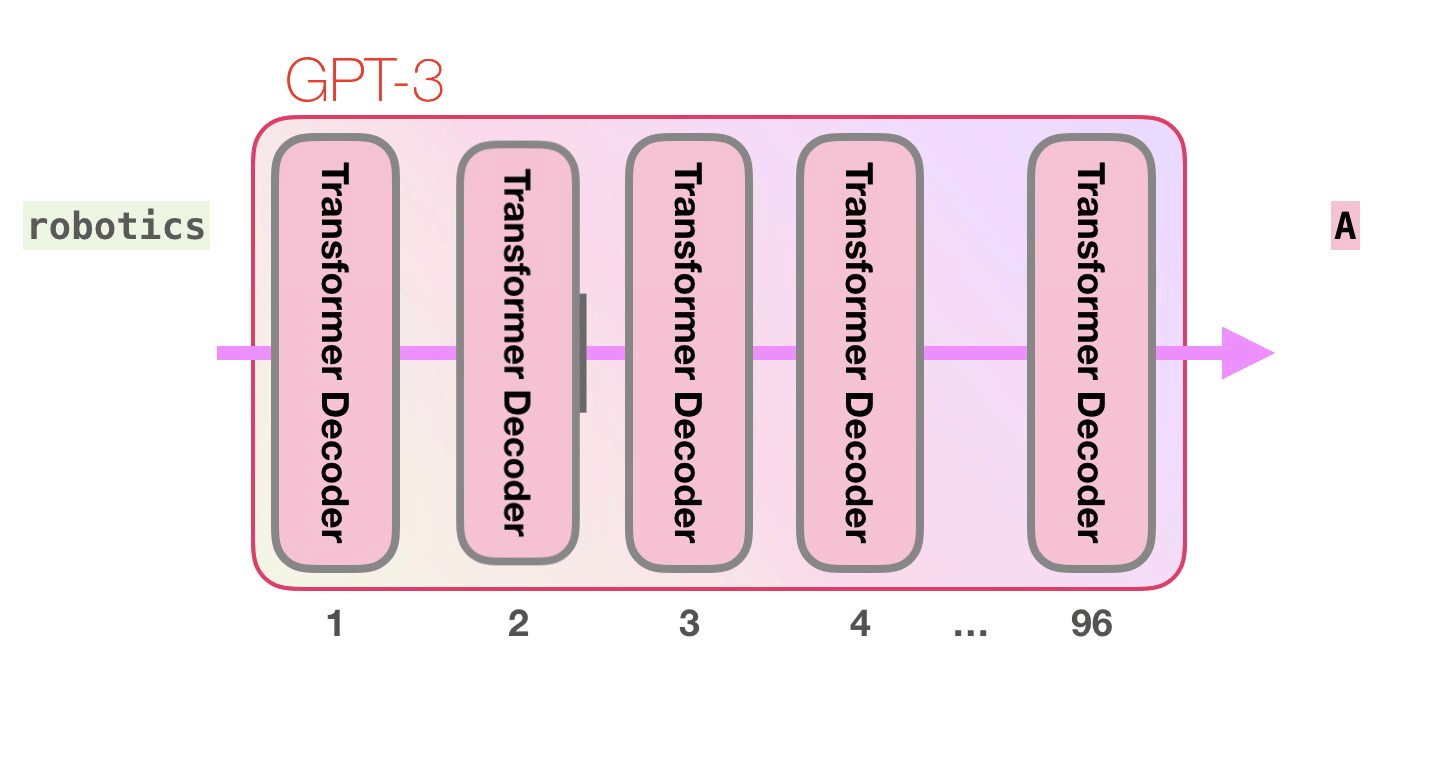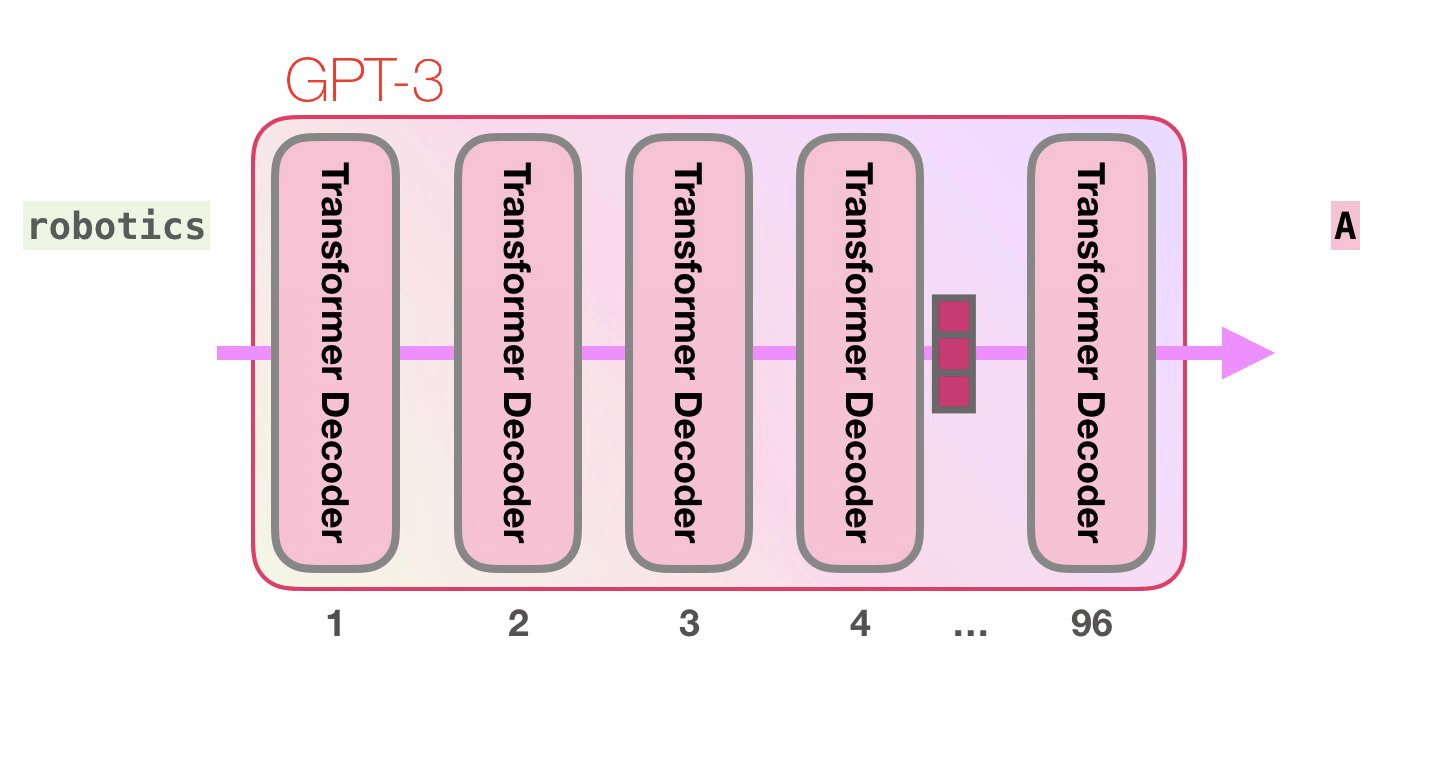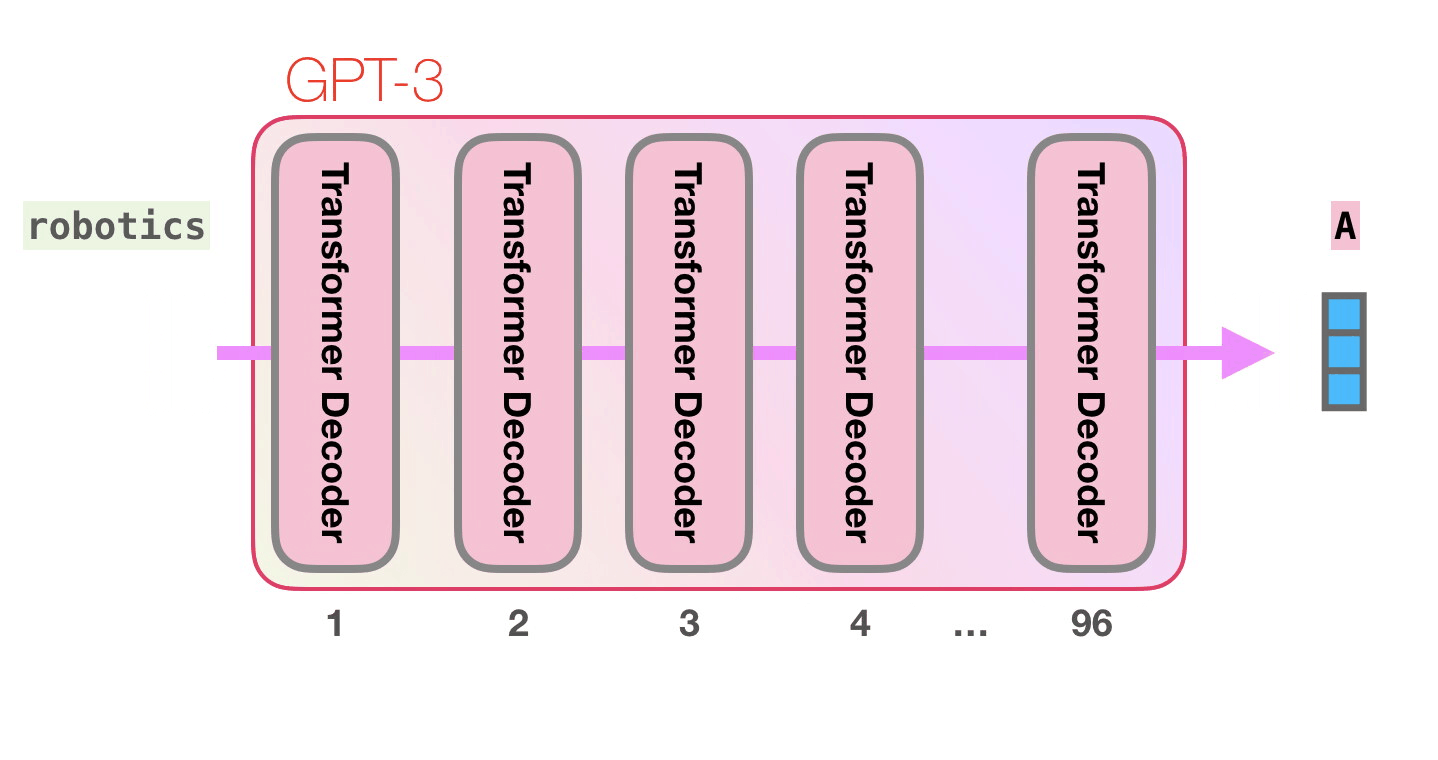
GPT-3 96 .
? «» « » (deep learning).
1.8 . «». :
, , GTP-2 .
GPT-3 (dense) (sparse) (self-attention).
«Okay human» GPT-3. , . : , . .
React ( ), , => . React , , .
可以假设将初始示例和描述以及添加到模型输入中的特殊标记添加到了模型的输入中。

它的工作方式令人印象深刻。您只需要等待GPT-3微调完成即可。可能性将更加惊人。
调整只是更新模型权重,以提高其对特定任务的性能。
作者
- 原作者-杰伊·阿拉曼(Jay Alammar)
- 翻译-叶卡捷琳娜·斯米尔诺娃
- 编辑和排版-谢尔盖Shkarin