从Linux实用程序到专门的服务,有许多有用的工具可以帮助您监视服务器负载。
简单的Linux实用程序显示每个进程的当前内存消耗,CPU负载,可用磁盘空间和流量统计信息。
此外,还有收费和免费服务,它们可以全天候监视服务器的状态,注册服务器运行或网络可用性方面的故障以及检查应用程序的性能。
内容
Linux实用程序
资源使用
最佳
用于检查进程资源使用情况的最强大的工具之一。该实用程序
top会生成一个包含当前资源消耗的简单表格,其中最高负载的过程显示在顶部。
top - 14:45:52 up 29 min, 1 user, load average: 0.10, 0.09, 0.06
Tasks: 56 total, 1 running, 55 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.3%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1019600k total, 393756k used, 625844k free, 11136k buffers
Swap: 0k total, 0k used, 0k free, 316748k cached
PID %MEM VIRT SWAP RES CODE DATA SHR nFLT nDRT S PR NI %CPU COMMAND
832 1.3 32364 18m 12m 896 11m 1688 1 0 S 20 0 0.0 bash
820 0.4 89456 83m 4008 488 948 3040 12 0 S 20 0 0.0 sshd
812 0.3 49948 46m 2828 488 616 2216 0 0 S 20 0 0.0 sshd
1 0.2 24192 21m 2108 152 868 1300 23 0 S 20 0 0.0 init
400 0.1 243m 242m 1420 344 216m 1084 0 0 S 20 0 0.0 rsyslogd该表之前会提供一些常规统计信息,包括最近一分钟,5分钟和15分钟的平均CPU负载。它还显示内存消耗,页面文件消耗和进程状态。
该列表是实时更新的:您可以将其显示在第二台显示器上,并不断观看。
停止
尽管该实用程序
top几乎随每个发行版一起提供,但大多数存储库中也可以下载改进版本htop。在Ubuntu上
安装
htop:
apt-get install htop在这里,我们看到几乎相同的输出,但是具有不同的颜色和更具交互性的输出:
CPU[| 0.7%] Tasks: 21, 3 thr; 1 running
Mem[||||||||||||| 64/995MB] Load average: 0.00 0.02 0.05
Swp[ 0/0MB] Uptime: 00:37:37
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
2752 root 20 0 25660 1876 1364 R 0.0 0.2 0:00.06 htop
1 root 20 0 24192 2108 1300 S 0.0 0.2 0:00.55 /sbin/init
312 root 20 0 17224 640 444 S 0.0 0.1 0:00.04 upstart-udev-brid
314 root 20 0 21592 1360 760 S 0.0 0.1 0:00.04 /sbin/udevd --dae
394 messagebu 20 0 23808 688 436 S 0.0 0.1 0:00.01 dbus-daemon --sys
401 syslog 20 0 243M 1420 1084 S 0.0 0.1 0:00.07 rsyslogd -c5
402 syslog 20 0 243M 1420 1084 S 0.0 0.1 0:00.00 rsyslogd -c5上半部分在这里更清晰,组织更好。
以下是一些更好使用的键
htop:
- M:按内存使用情况对进程进行排序
- P:按CPU使用率对进程进行排序
- ?:参考
- k:终止当前/标记的进程
- F2:设置(您可以在此处选择要显示的选项)
- /:搜索进程
帮助和设置中列出了许多其他选项。值得从这两部分开始对该程序的研究。
网络流量
网络猪
nethogs是查看每个服务有多少流量的最简单的实用程序。在Ubuntu上,使用以下命令安装该实用程序:
apt-get install nethogs然后就可以不用键启动它了。问题很简单:
PID USER PROGRAM DEV SENT RECEIVED
3379 root /usr/sbin/sshd eth0 0.485 0.182 KB/sec
820 root sshd: root@pts/0 eth0 0.427 0.052 KB/sec
? root unknown TCP 0.000 0.000 KB/sec
TOTAL 0.912 0.233 KB/sec仅有几种更改输出的选项:
- m:在kb / s,kb,b,mb之间切换
- r:按收到的流量排序。
- s:按发送流量排序
- q:退出
尽管这是一个简单的实用程序,但对于快速查看哪些应用程序正在产生流量非常有用。
IPTraf
IPTraf-监视网络流量的另一种方法,有很多选择。在Ubuntu上安装:
apt-get install iptraf该实用程序提供选择以下交互式界面之一:
???????????????????????????????????
? IP traffic monitor ?
? General interface statistics ?
? Detailed interface statistics ?
? Statistical breakdowns... ?
? LAN station monitor ?
???????????????????????????????????
? Filters... ?
???????????????????????????????????
? Configure... ?
???????????????????????????????????
? Exit ?
???????????????????????????????????例如,要查看所有网络流量,请选择第一个菜单项:
? TCP Connections (Source Host:Port) ?????????? Packets ??? Bytes Flags Iface ?
??192.241.xxx.xxx:22 > 369 82420 -PA- eth0 ?
??72.43.xxx.xxx:49488 > 381 19860 --A- eth0 ?
? ?
? ?为了将IP地址解析为域,您需要在配置中选择“反向DNS查找”项。
除了按端口查看流量外,还有一个选项可以按服务查看流量(选项“ TCP / UDP服务名称”)。启用两个选项后,输出将如下所示:
TCP Connections (Source Host:Port) ?????????? Packets ??? Bytes Flags Iface ?
??192.241.xxx.xxx:ssh > 151 34924 -PA- eth0 ?
??rrcs-72-43-xxx-xxx.nyc.biz.rr.co:49488 > 155 8108 --A- eth0 ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? TCP: 1 entries ???????????????????????????????????????????????? Active ??
????????????????????????????????????????????????????????????????????????????????
? UDP (72 bytes) from 192.241.xxx.xxx:43463 to 8.8.8.8:domain on eth0 ?
? UDP (66 bytes) from 192.241.xxx.xxx:53140 to 8.8.8.8:domain on eth0 ?
? UDP (135 bytes) from 8.8.8.8:domain to 192.241.xxx.xxx:41429 on eth0 ?
? UDP (119 bytes) from 8.8.8.8:domain to 192.241.xxx.xxx:43463 on eth0 ?
? UDP (110 bytes) from google-public-dns-a.googl:domain to 192.241.xxx.xxx:531 ?您还可以自行学习其他一些界面。
netstat
该实用程序
netstat是用于收集网络信息的非常灵活且功能强大的工具。
默认情况下,它
netstat提供了一个打开的套接字列表:
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 192.241.187.204:ssh ip223.hichina.com:50324 ESTABLISHED
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
Active UNIX domain sockets (w/o servers)
Proto RefCnt Flags Type State I-Node Path
unix 5 [ ] DGRAM 6559 /dev/log
unix 3 [ ] STREAM CONNECTED 9386
unix 3 [ ] STREAM CONNECTED 9385
. . .如果添加选项
-a,它将显示所有端口的列表:
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ACC ] STREAM LISTENING 6195 @/com/ubuntu/upstart
unix 2 [ ACC ] STREAM LISTENING 7762 /var/run/acpid.socket
unix 2 [ ACC ] STREAM LISTENING 6503 /var/run/dbus/system_bus_socket
. . .分别标记
-t或-u过滤TCP或UDP连接。该标志-s显示统计信息。要不断更新输出,您需要使用key运行命令-c。
磁盘空间
df
用于查看有关已安装分区的信息的标准实用程序是
df。它显示已连接设备的列表以及有关已占用空间的信息。
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/vda 31383196 1228936 28581396 5% /
udev 505152 4 505148 1% /dev
tmpfs 203920 204 203716 1% /run
none 5120 0 5120 0% /run/lock
none 509800 0 509800 0% /run/shm默认情况下,输出以字节为单位,这不是很方便。该参数
-h以兆字节和千兆字节为单位激活输出:
Filesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm要查看所有磁盘上的整个空间,请添加选项
--total。
杜
该实用程序
df使您可以快速获得一般概述。有关更多详细信息,更适合使用du分析当前目录和任何子目录的程序。默认输出如下所示:
4 ./.cache
8 ./.ssh
28 .再次,通过key启用了更具可读性的输出
-h。
查看文件和目录的大小可以通过标志启用
-a,总计可以通过标志-c(详细信息和金额)和-s(仅金额)来启用。
改良版
df和du的改进版本称为pydf和ncdu,并使用
apt-get install pydf和命令安装在Ubuntu上apt-get install ncdu。他们在伪图形中用颜色来组织漂亮的结果:
pydf -a
dev/vda 30G 1200M 27G 3.9 [........] /
udev 493M 4096B 493M 0.0 [........] /dev
devpts 0 0 0 - [........] /dev/pts
proc 0 0 0 - [........] /proc
tmpfs 199M 204k 199M 0.1 [........] /run
none 5120k 0 5120k 0.0 [........] /run/lock
none 498M 0 498M 0.0 [........] /run/shm
. . .ncdu
--- /root ----------------------------------------------------------------------
8.0KiB [##########] /.ssh
4.0KiB [##### ] /.cache
4.0KiB [##### ] .bashrc
4.0KiB [##### ] .profile
4.0KiB [##### ] .bash_history在这里,您可以使用箭头键浏览文件系统。
内存使用情况
自由
查看当前RAM使用情况的最简单方法是使用命令
free。不带选项的输出如下所示:
total used free shared buffers cached
Mem: 12286456 11715372 571084 0 81912 6545228
-/+ buffers/cache: 5088232 7198224
Swap: 24571408 54528 24516880使用键启动将
-m生成兆字节的输出。
中间行
-/+ buffers/cache显示已用内存量减去缓冲区/高速缓存的总和,可用内存量再加上缓冲区/高速缓存的总和。
事实是,与大多数现代OS一样,Linux尝试将可用RAM的最大数量用于缓冲区和缓存。因此,第二行很重要,如果我们忽略缓冲区和缓存,则它显示了应用程序潜在可用RAM的实际数量。如果应用程序需要,此空间将自动释放。
虚拟机
该命令
vmstat显示有关系统的各种信息,包括内存,页面文件,I / O操作和CPU负载。
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 2828 407616 335348 5511476 0 0 26 268 41 27 28 30 42 0 0第一列
r显示活动进程的数量,第二列-处于不间断等待状态的进程数量。
列
si和分别so显示从页面文件读取和写入页面文件的内存量。
下面显示了已接收或发送到块I / O设备的块数(bi,bo),每秒中断数(包括计时器)(in),每秒上下文切换数(cs)和CPU统计信息:处理所用时间的百分比用户空间(us)中的代码,用于处理内核代码(sy),处于睡眠状态(id)并等待I / O(wa),以及从虚拟机(st)“窃取”的时间,即虚拟CPU在管理程序为另一个虚拟处理器提供服务时,等待实际的CPU起作用。
该标志
-S M激活兆字节的传送。使用该选项运行将-s显示常规统计信息。
监控服务
如果您需要全天候监视服务器状态(内存,CPU,可用空间,性能,响应时间等),则可以使用免费或付费的监视服务。有很多这样的服务,以下是按字母顺序排列的一小列:
- 安图里斯
- AppDynamics
- AppNeta
- 阿泰拉
- 大熊猫
- 已收集
- 数据狗
- eG创新
- 神经节
- Icinga(Nagios Core的免费改编版)
- 器乐
- 逻辑监控器
- ManageEngine OpManager
- 莫尼提斯
- 元数据
- Nagios XI(免费版本称为Nagios Core)
- Navicat显示器
- 忍者
- Op5显示器
- OpenNMS
- 潘多拉FMS
- Panopta
- PRTG网络监控器
- 海狮
- 服务器密度
- Site24x7
- SolarWinds服务器和应用程序监视器
- Spiceworks网络监视器(免费)
- 堆叠
- WhatsUpGold
- Zabbix(免费系统监视器)
一些监视器更适合小型企业,而其他监视器则更适合大型公司。有些专门监视云系统。有些服务仅在Linux服务器上运行。系统在可伸缩性,功能集和自动化级别方面有所不同。几个监视器是分布式开源的。
例如,考虑三种相对流行的监视服务。
SolarWinds服务器和应用程序监视器
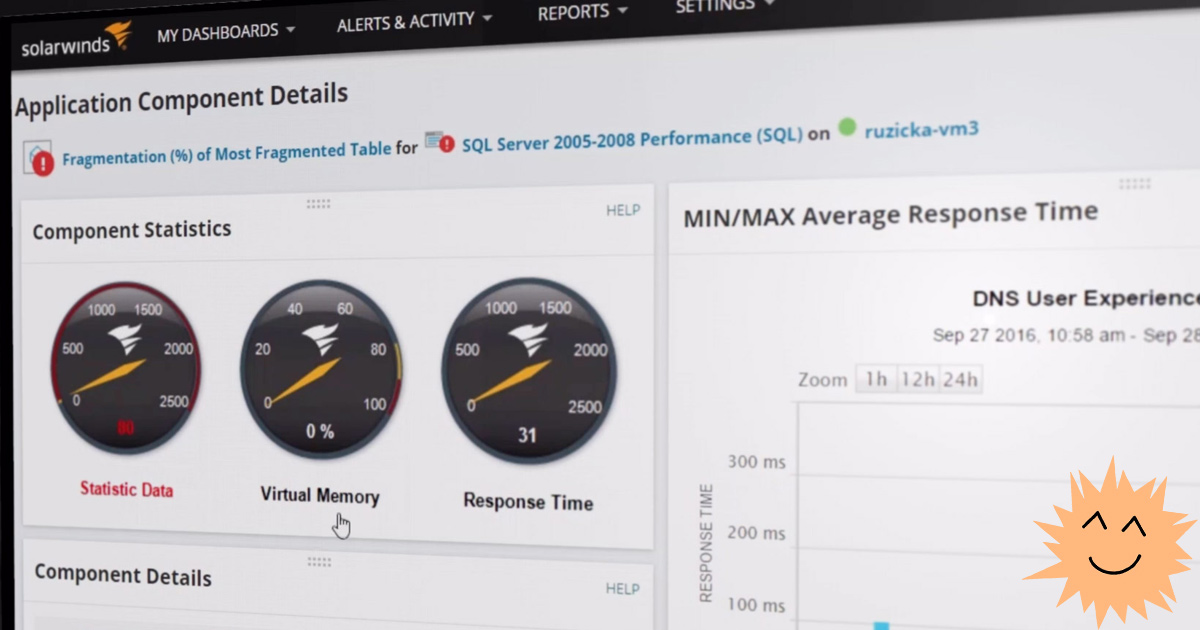
市场上最先进的服务器监视器之一是SolarWinds服务器和应用程序监视器(SAM)。尽管该工具仅安装在Windows Server 2016+上,但它可以跟踪任何硬件,包括Linux服务器。
该监视器监视服务器性能,报告问题并提供一些管理功能:它允许您重新启动服务器,拍摄进程和重新启动服务,也就是说,它不仅是监视工具,而且是管理工具。

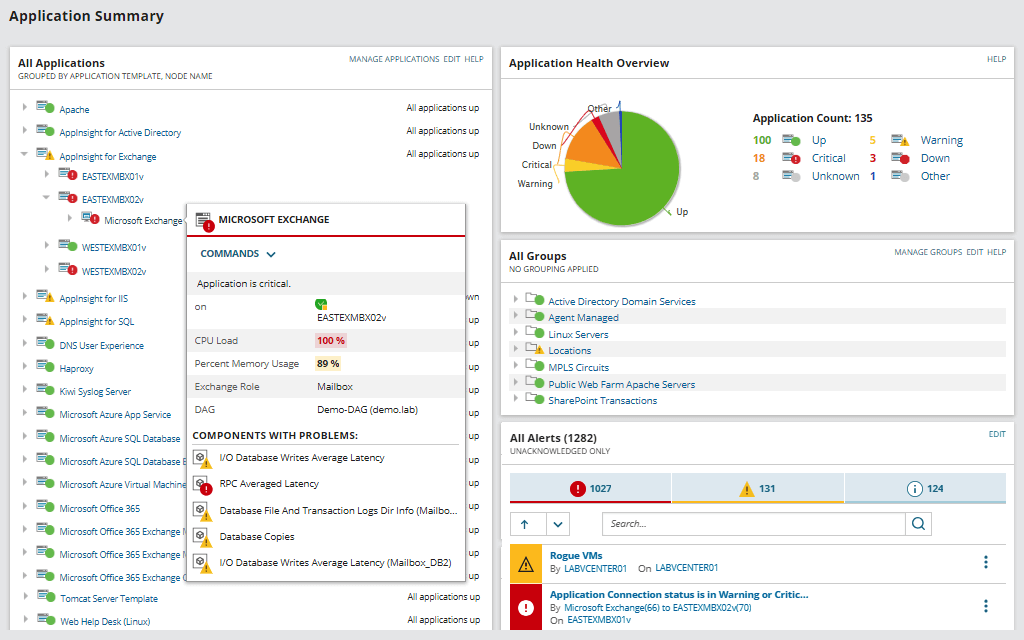
该程序更适合大型公司。宣布与Dell PowerEdge,HP ProLiant,IBM eServer xSeries,Dell PowerEdge Blade,HP BladeSystem,Microsoft Windows Server和VMware vSphere兼容。 SAM还监视AWS和Azure云实例。
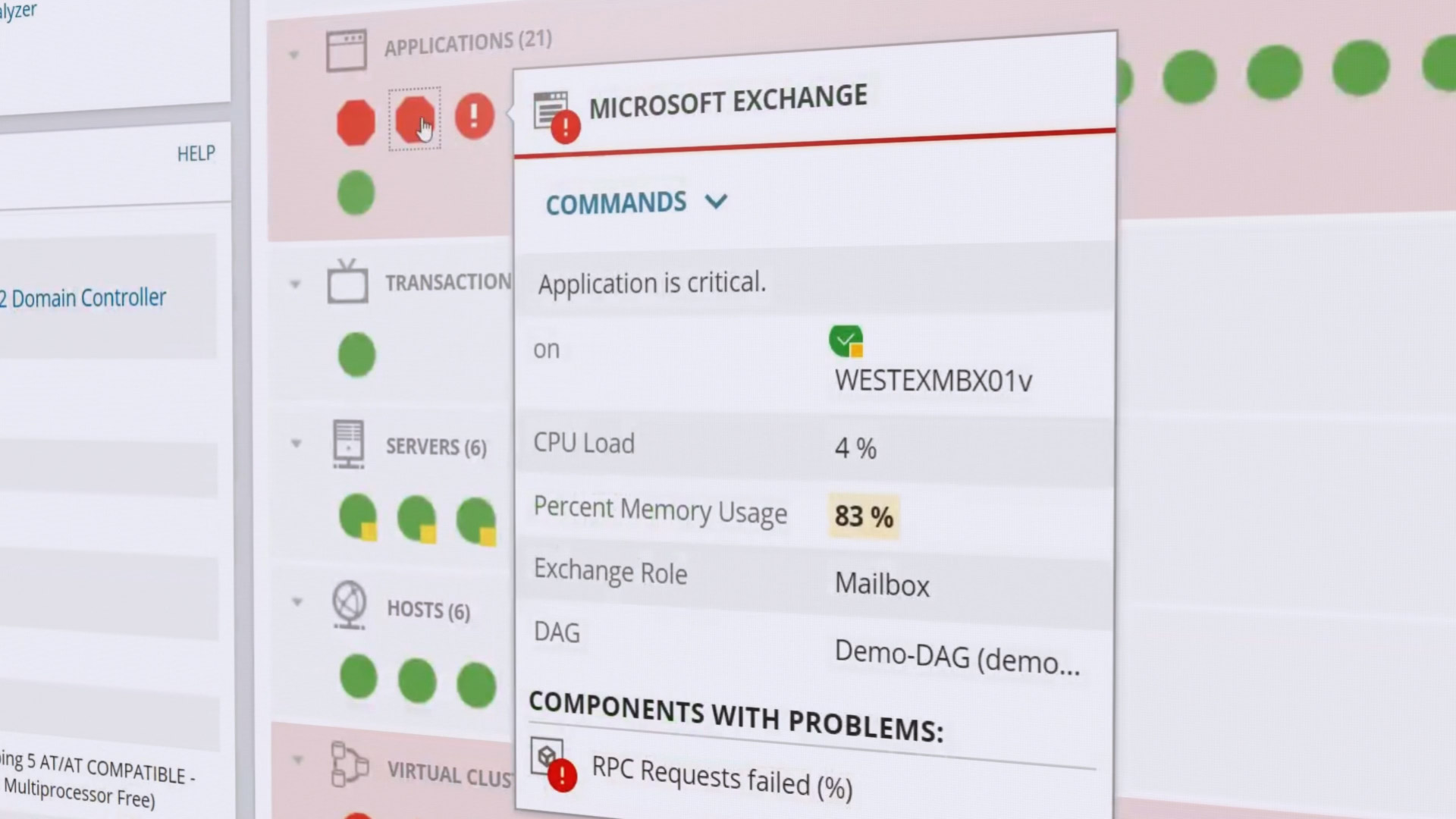
它显示有关响应时间,CPU负载,内存等的统计信息。监视各个应用程序的性能:内置对1200多种不同应用程序的支持。还检查硬件状态:CPU使用率,磁盘负载,电源,风扇状态等。状态以绿色从红色到红色进行颜色编码,使您一眼就能评估系统的运行状况。
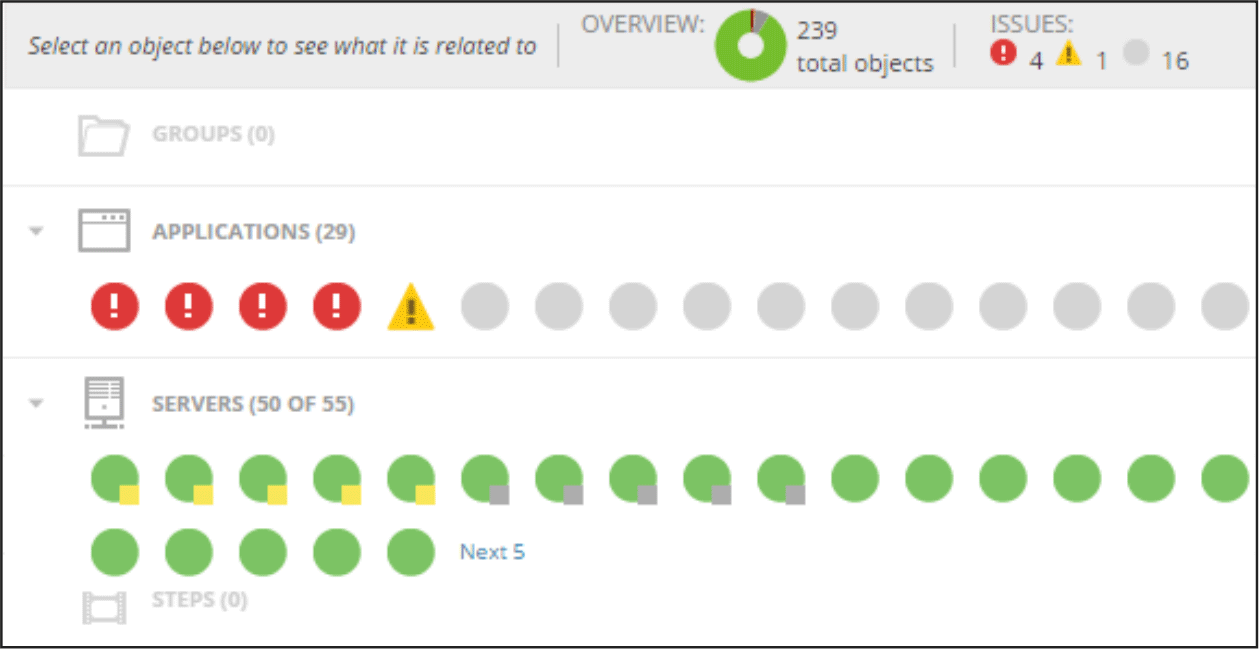
监控器会自动检测群集中的新硬件和软件,然后将其立即添加到仪表板中。这是SAM的主要功能之一,也是最大程度的自动化-为自动执行常规监视和维护任务准备的模板,报告和通知的模板。
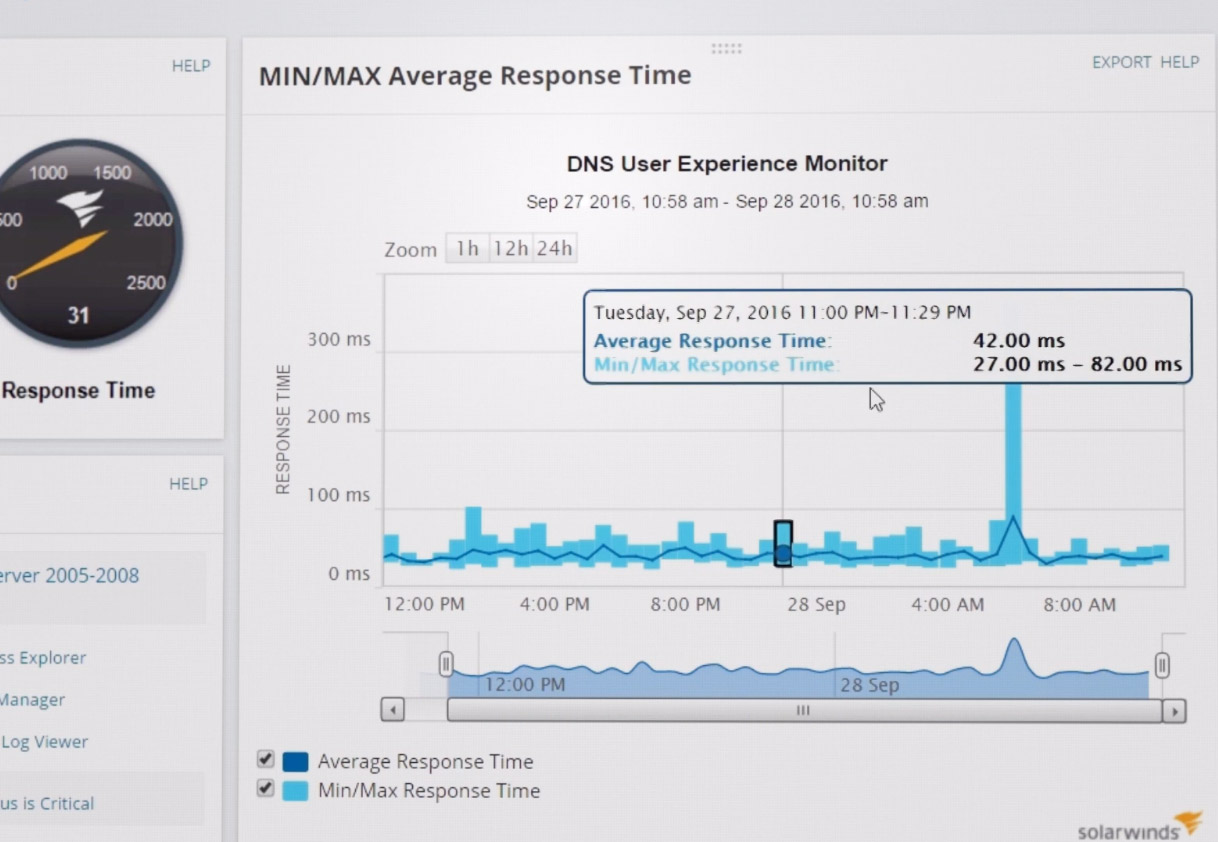
通常,此类服务有免费试用期,其成本可能取决于所使用功能的集合。这里还有一个试用期,SolarWinds Server和Application Monitor的最低功能起价为1275欧元。
Navicat显示器
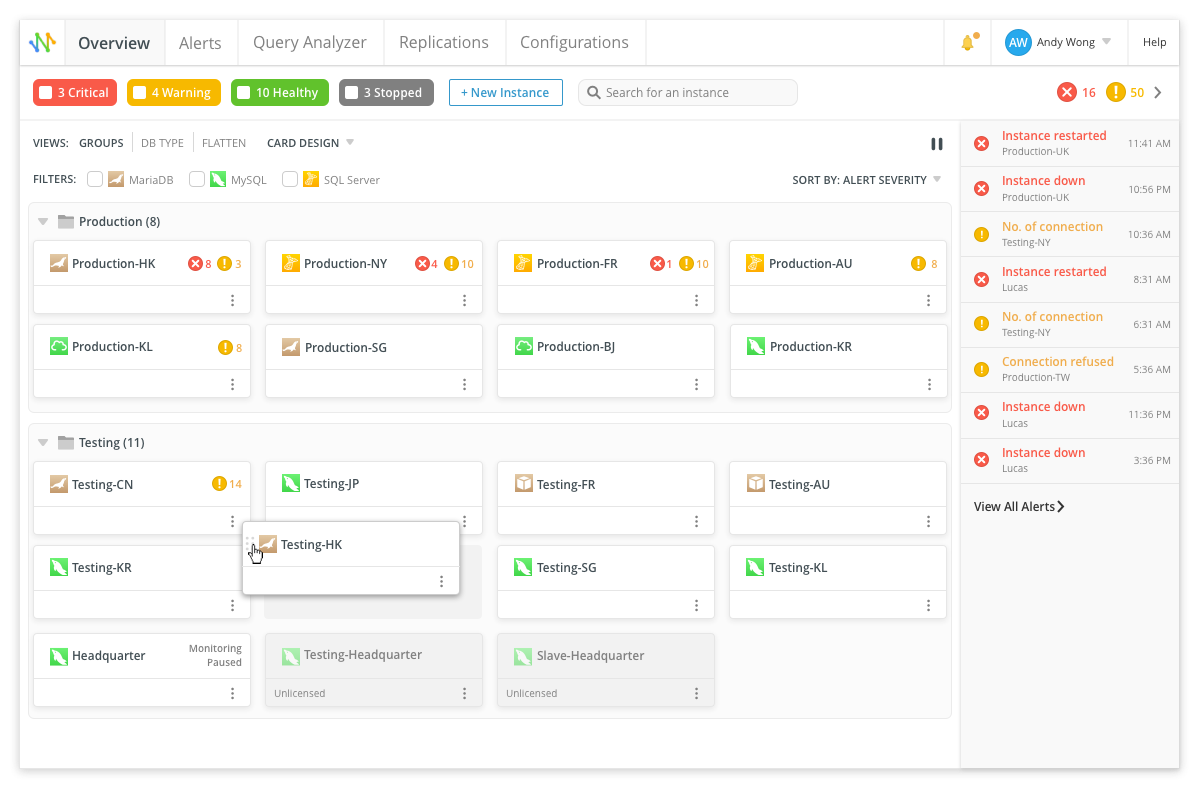
另一个例子是Navicat Monitor,它专门从事数据库监视。它支持MySQL,MariaDB,SQL Server以及基于云的DBMS,例如Amazon RDS,Amazon Aurora,Oracle Cloud,Google Cloud和Microsoft Azure。

标准视图
紧凑视图
监视器通过以指定间隔运行特定查询来跟踪特定查询的执行时间。

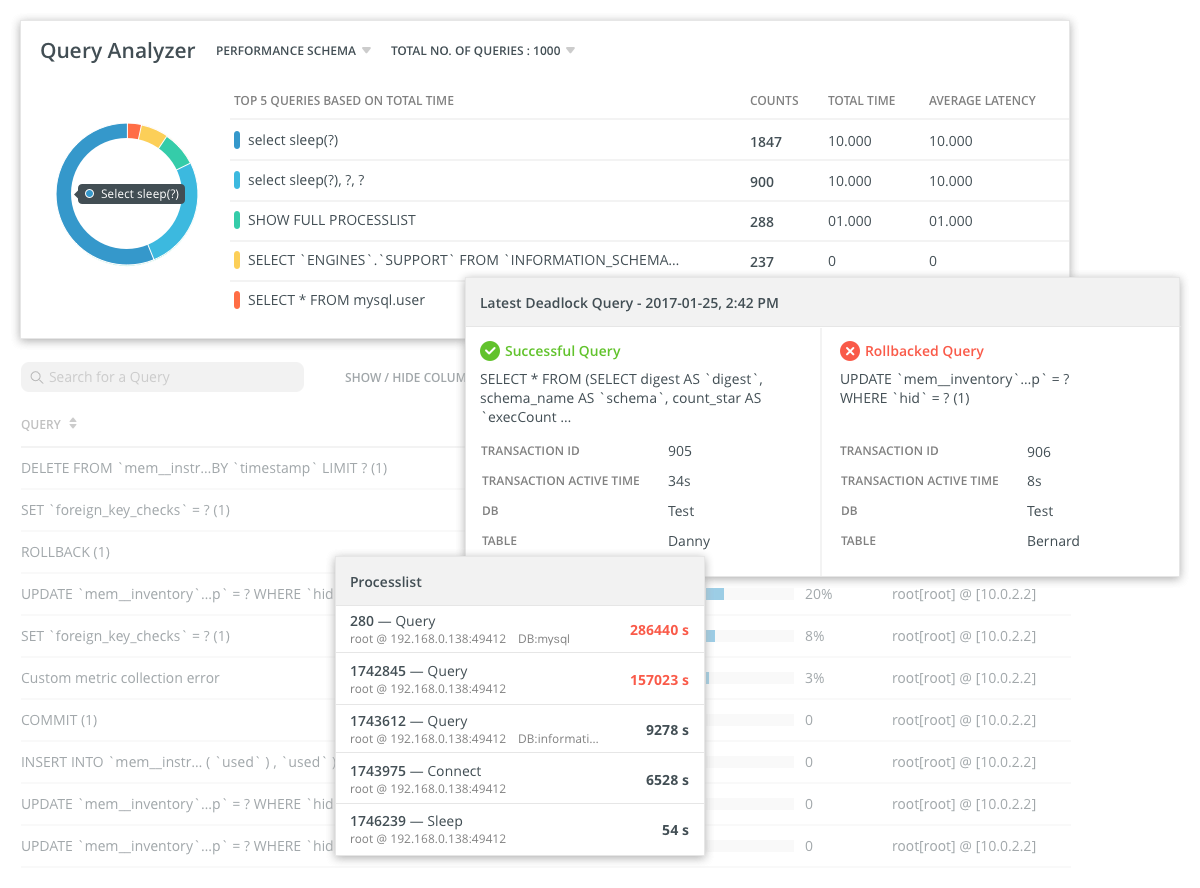
除了查询数据库外,其他查询也定期发送到服务器,以监视I / O系统,网络等的性能指标。收集有关CPU利用率,内存利用率和其他标准指标的统计信息。
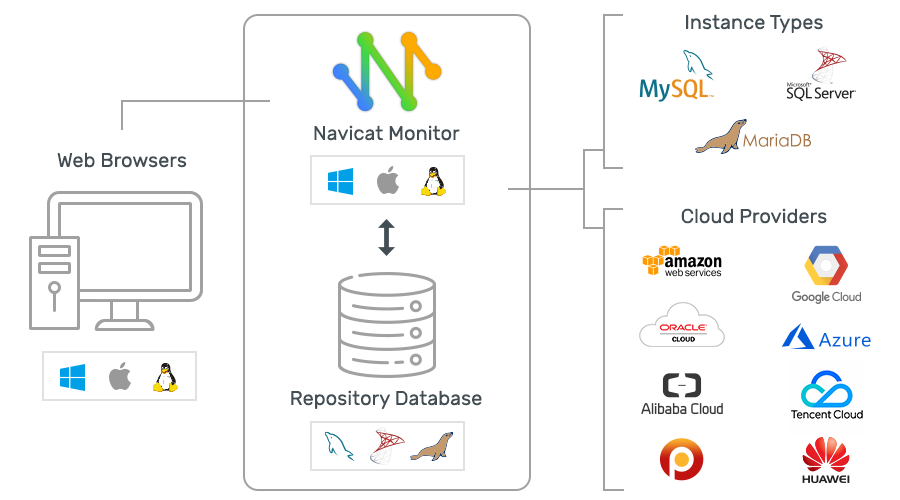
Navicat Monitor体系结构不提供在监视对象上的软件安装
Navicat Monitor的最低价格为每个令牌每月32.99美元(一个令牌对应于监视一台服务器或四个Azure基础)。有一个功能齐全的14天试用版。
扎比克斯
Zabbix是一个免费的开源工具,可以监视网络,应用程序和服务器本身的运行状况。带有现成的模板,用于监视流行的服务器和操作系统,包括HP,IBM,Lenovo,Dell,Linux服务器,Ubuntu和Solaris。多年来,Zabbix社区已经为各种场景准备了模板。
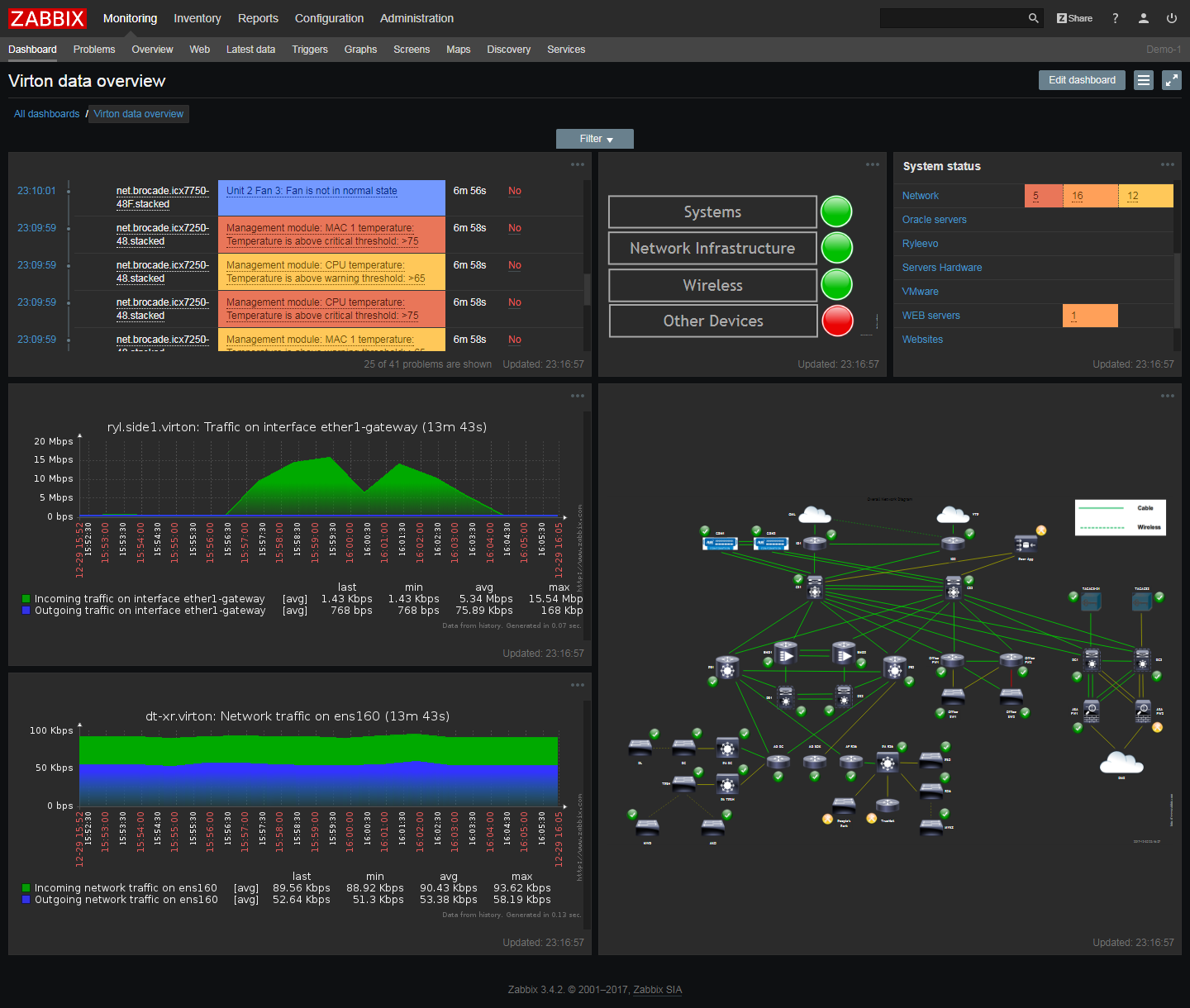
关键的Zabbix模块监视CPU负载,内存使用,I / O错误率,可用磁盘空间,风扇状态,温度和电源系统特性。网络模块检查流量,网络可用性,丢包率,TCP连接质量和路由器吞吐量。
Zabbix会维护已安装软件和固件版本的列表,以表示未经授权的软件安装。

系统管理员可以在Zabbix中为任意条件编写通知程序,也可以更改活动通知的重要性。在控制面板上,您可以添加用户-并向每个用户发送某些类型的通知,自动化脚本允许您自动启动任务并将其分配给员工。
由于具有远程访问和管理功能,Zabbix可以称为良好的服务器管理工具。
只有这个系统的缺点是,如果你已经增加了大约1000台服务器以上的监测,则由于大量消息和加密程序,的zabbix开始缓慢响应命令,所以这个工具不是很适合于非常大的公司。
服务器监控系统在功能上有所不同... 并非每个人都可以监视单个应用程序的运行状况,服务器性能和响应时间。但是,可以使用其他工具来纠正这些缺点:例如,分析和日志监视系统。
可靠的租金服务器和正确的费率计划选择将使您不必再因令人不快的监视通知而分心-一切都会顺利进行,并且正常运行时间非常长!
