在我们公司中,我们正在积极地进行文档的自动提取,本文未包含所有详细信息和代码,但使用中性数据集示例描述了主要方法和结果:从Sport-Express信息门户网站收集了30,000个足球体育新闻文章。
因此,摘要可以定义为自动创建原始摘要(标题,摘要,注释)。有两种方法可以解决此问题:抽取式和抽象式。
提取摘要
提取方法包括从源文本中提取最“重要”的信息块。块可以是单个段落,句子或关键字。

该方法的方法的特征在于存在信息块的重要性的评估函数。通过按重要性顺序对这些块进行排序并选择先前指定的数量,我们形成了文本的最终摘要。
让我们继续一些提取方法的描述。
基于常见单词出现的提取求和
该算法非常易于理解和进一步实现。在这里,我们仅处理源代码,并且基本上不需要训练任何提取模型。就我而言,检索到的信息块将代表某些文本句子。
因此,在第一步中,我们将输入文本分解为句子,然后将每个句子分解为标记(单独的单词),对它们进行词形化(将单词转换为“规范”形式)。为了使算法组合含义相同但词形不同的词,此步骤是必需的。
然后,我们为每对句子设置相似度函数。它将根据两个句子中找到的常用单词数与其总长度之比来计算... 结果,我们获得了每对句子的相似系数。
先前已经消除了与其他人没有共同词的句子,我们构建了一个图,其中顶点是句子本身,它们之间的边缘表明其中存在共同词。
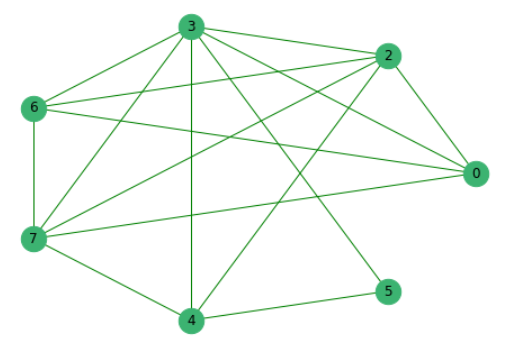
接下来,我们将根据所有提案的重要性对其进行排名。

选择几个系数最高的句子,然后按文本中出现的次数对它们进行排序,得到最终的摘要。
基于训练矢量表示的求和
先前收集的全文新闻数据用于构建下一个算法。
我们将所有文本中的单词分成标记,然后将它们组合成一个列表。这些文本总共包含2,270,778个单词,其中114,247个是唯一的。
使用流行的Word2Vec模型,我们将找到每个唯一单词的向量表示形式。该模型为每个单词分配随机向量,然后在学习的每个步骤“研究上下文”中校正其值。向量的维数可以“记住”单词的特征,可以设置任何维数。根据可用数据集的数量,我们将采用由100个数字组成的向量。我还注意到Word2Vec是可重新训练的模型,它使您可以向输入提交新数据,并在它们的基础上更正单词的现有矢量表示形式。
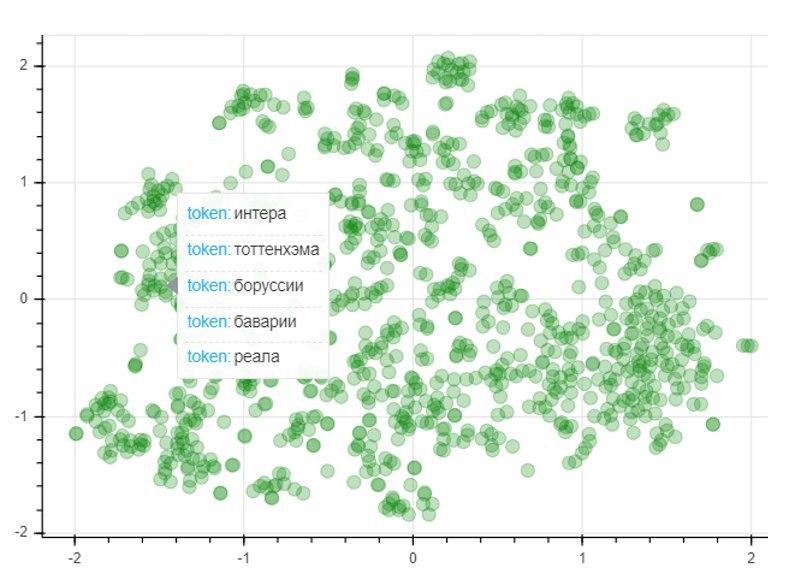
为了评估模型的质量,我们将应用T-SNE降维方法,该方法将1000个最常用词的向量映射迭代地构建到二维空间中。生成的图形表示点的位置,每个点对应于某个单词,其含义类似的单词彼此靠近,而不同的单词则相反。因此,该图的左侧是足球俱乐部的名称,左下角的点代表足球运动员和教练的名称和姓氏:
在获得训练有素的单词向量表示之后,您可以继续进行算法本身。与前面的情况一样,在输入处我们有一个文本,可以分成句子。通过标记每个句子,我们为它们组成向量表示。为此,我们采用句子中每个单词的向量之和与句子本身长度之比。以前受过训练的单词向量可以在这里为我们提供帮助。如果词典中没有单词,则将零向量添加到当前句子向量。因此,我们抵消了不在词典中的新单词的出现对句子一般矢量的影响。
接下来,我们组成一个句子相似度矩阵,该矩阵对每对句子都使用余弦相似度公式。
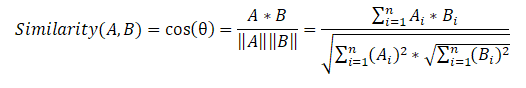
在最后阶段,基于相似度矩阵,我们还创建了一个图,并根据重要性对句子进行排名。与以前的算法一样,我们根据句子在文本中的重要性来获得排序句子的列表。

最后,我将示意性地描绘并再次描述算法实现的主要阶段(对于第一个提取算法,其动作顺序是完全相同的,只是我们不需要找到单词的向量表示形式,并且每对句子的相似度函数都是基于共同的出现来计算的话):

- 将输入文本拆分为单独的句子并进行处理。
- 搜索每个句子的向量表示。
- 计算并存储矩阵中句子向量之间的相似度。
- 将生成的矩阵转换为具有顶点形式的句子和边缘形式的相似性估计的图形,以计算句子的等级。
- 选择得分最高的提案作为最终简历。
提取算法的比较
使用Flask微框架(一种用于创建简约Web应用程序的工具),开发了一个测试Web服务,以各种来源新闻文本为例,直观地比较提取模型的输出。我分析了两个模型针对100篇不同的体育新闻文章生成的摘要(检索了2个最重要的句子)。

根据比较两个模型确定最相关要约的结果,我可以提供以下使用算法的建议:
- . , . , .
- . , , , . , , , .
抽象总结
抽象方法与以前的方法有很大不同,在于生成摘要和生成新文本,从而有意义地总结了原始文档。
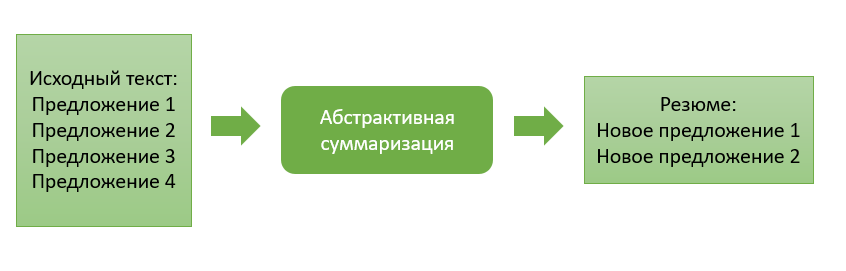
这种方法的主要思想是该模型能够生成一个完全唯一的摘要,其中可能包含原始文本中没有的单词。模型推断是文本的重述,更接近于人为文本摘要的手动编译。
学习阶段
我不会详细讨论该算法的数学依据,我所知道的所有模型都是基于“编码器-解码器”架构的,该架构又是使用递归LSTM层构建的(您可以在此处阅读有关其工作原理的信息)。我将简要描述解码测试序列的步骤。
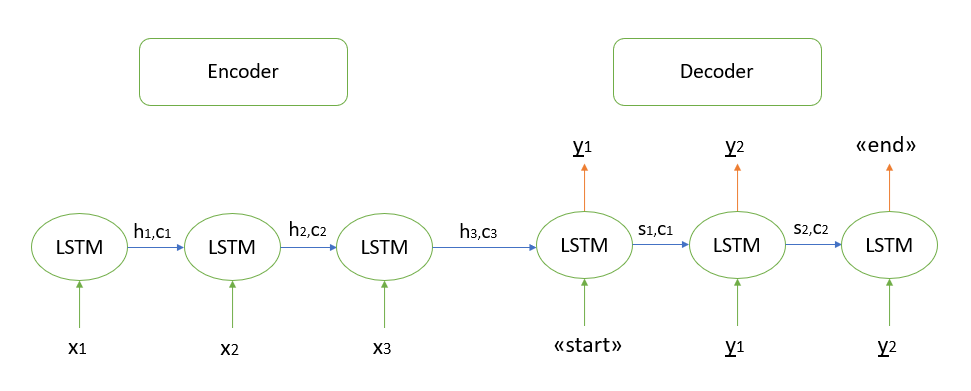
- 我们对整个输入序列进行编码,并使用编码器的内部状态初始化解码器
- 将“开始”令牌作为输入传递给解码器
- 我们以一个时间步长以编码器的内部状态启动解码器,结果得到下一个单词的概率(具有最大概率的单词)
- 在下一时间步将选定的单词作为输入传递给解码器,并更新内部状态
- 重复步骤3和4,直到生成“结束”令牌
可以在此处找到有关“编码器-解码器”体系结构的更多详细信息。
实施抽象总结
要构建用于提取摘要内容的更复杂的抽象模型,将需要完整的新闻文本及其标题。新闻标题将作为摘要,因为该模型“记不太清”长文本序列。
清理数据时,我们使用小写转换并丢弃非俄语语言字符。单词的词法化,介词,名词和其他非信息性词的去除将对模型的最终输出产生负面影响,因为句子中单词之间的关系将会丢失。
接下来,我们将文本及其标题按9:1的比例分为训练样本和测试样本,然后将它们转换为向量(随机)。
在下一步中,我们将创建模型本身,该模型将读取传递给它的单词的向量,并使用LSTM编码器的3个循环层和解码器的1个层进行处理。
初始化模型后,我们使用交叉熵损失函数训练模型,该函数显示实际目标标题与模型预测的标题之间的差异。

最后,我们输出训练集的模型结果。如您在示例中所见,由于在构建模型之前丢弃了稀有单词(由于“简化学习”而将其丢弃),因此源文本和摘要中存在不准确之处。

在此阶段的模型输出还有很多不足之处。该模型“成功记住”了一些俱乐部的名称和足球运动员的名称,但实际上并没有抓住上下文本身。
尽管采用了更现代的恢复提取方法,但该算法仍然不如以前创建的提取模型。尽管如此,为了提高模型的质量,您可以在更大的数据集上训练模型,但是在我看来,为了获得真正好的模型输出,有必要更改或可能完全更改所用神经网络的架构。
那么哪种方法更好呢?
总结本文,我将列出摘录摘要的方法的主要利弊:
1.摘录方法:
优点:
- 该算法的本质是直观的
- 相对容易实施
缺点:
- 在许多情况下,内容质量可能会比人类手写内容差
2.抽象方法:
优点:
- 实施良好的算法能够产生最接近手动简历编写的结果
缺点:
- 难以理解算法的主要理论思想
- 算法实施中的人工成本高
对于哪种方法最好地构成最终简历,没有确切的答案。这完全取决于用户的特定任务和目标。例如,提取算法最有可能更适合于生成多页文档的内容,其中相关句子的提取确实可以正确传达大文本的想法。
在我看来,未来属于抽象算法。尽管目前它们发展不佳且在一定的输出质量水平上只能用于生成较小的摘要(1-2个句子),但值得等待神经网络方法的突破。将来,他们可以为任何大小的文本形成内容,而且最重要的是,内容本身将尽可能接近特定领域的专家手动草拟的简历。
Veklenko Vlad,
食品法典联盟系统分析师