X5 Retail Group也使用了360性能评估方法。今天,我们将向您介绍BigData X5进行深度HR分析的最佳实践。

显然,这种方法的准确性虽然可以通过对不同意见进行平均来提高,但仍取决于人们填写问卷的开放性和热情,对规模的理解,团队的实力,团队的氛围等等。
这种系统操作的一个重要方面是与填写调查表的交互。如果一个人不加思索地给每个人五分钱,他们需要与他一起工作,解释这一过程的重要性。在俄罗斯,以五分制为基础对成绩有一定的态度,据此,一名C级学生是一个平常的人,一个好人是正常的,但是一个优秀的学生是一个表现良好的人,这是值得称赞的。失败者仍然是第二年,确实是“失败者不多,而我在公司中从未见过”-这就是经理们通常对他们的团队的回答。 “某处”,但不在这里。因此,如果您认为该员工是好员工,则给他四个,因为C ...好吧,那里是C,如果您是朋友,则可以放一个A-毫不犹豫。这导致评分出现偏差,在调查中五分之二的比例很高,退化为几乎两点:四分和五分。
评估人员的教学是一个缓慢而悲伤的过程(很好,但并不总是悲伤),包括以下解释:仪器的工作方式;如何正确地评估一个人,而不是对一次互动的结果表示钦佩,或对一封粗鲁的信件的结果表示否定;分级量表的外观与学校使用的分级表不同;概述审阅者的典型错误,等等。让人们放松,摆脱他们对流程的另一种无聊的工具的认识,摆脱对评估会影响同事财务业绩的担心,非常重要。在这里,从根本上重要的是不要草率做出人事决定,不要在新的轨道上调整指挥人员。
但从人力资源员工的角度分析过程的声明在布局很好的文本我强烈建议阅读Avito的文章。球员们观察到对良好的强烈偏见,四分之三(“高于预期”)与三分之二(“达到预期”)相似。尽管我们使用自己设计的比例,但我们也遇到了有关“善与恶”的争论。
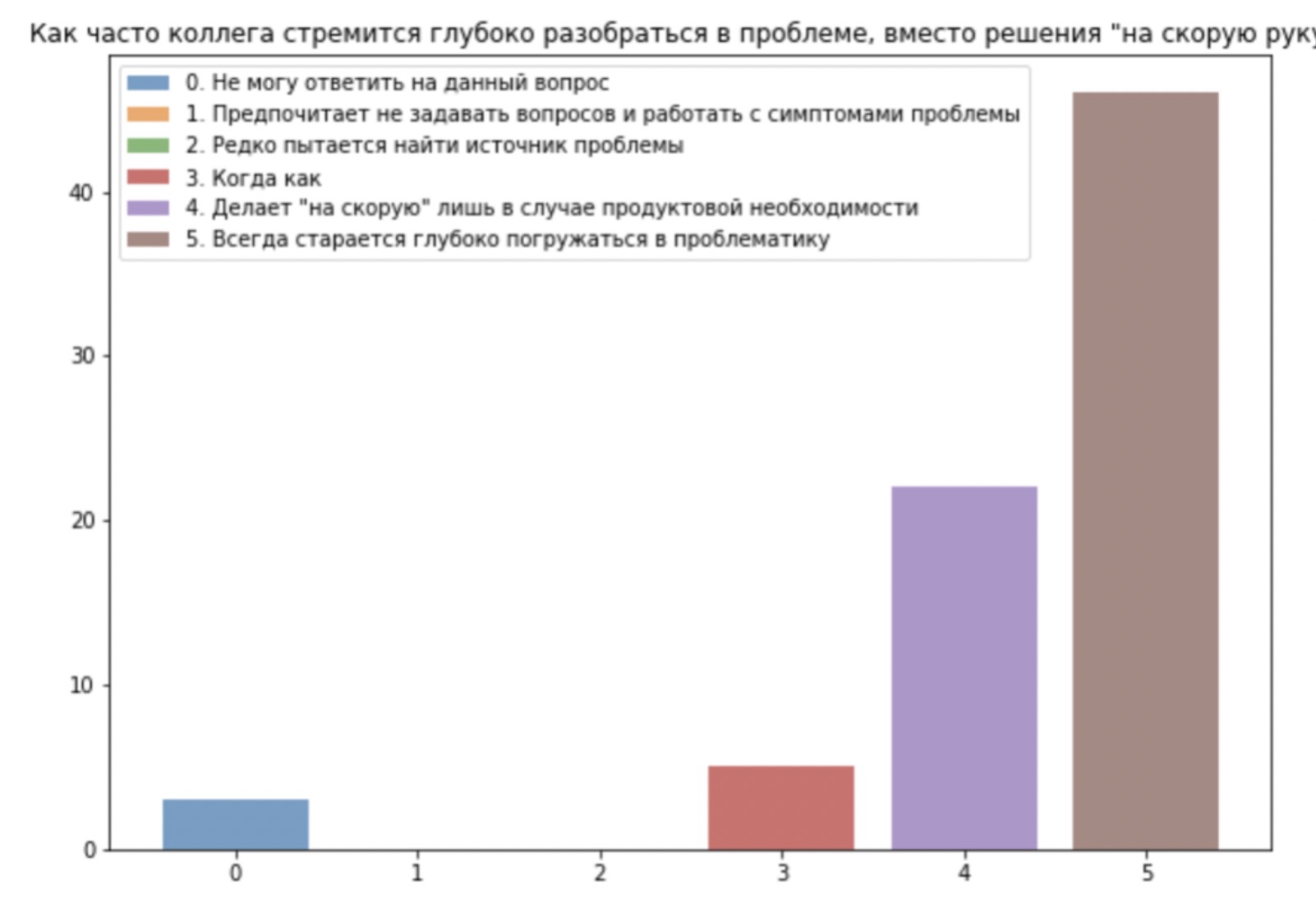
此外,声音被分开了。这是一支强大的友好团队,还是两件事之一。因此,我们很快就对另一个团队进行了第二次审核,
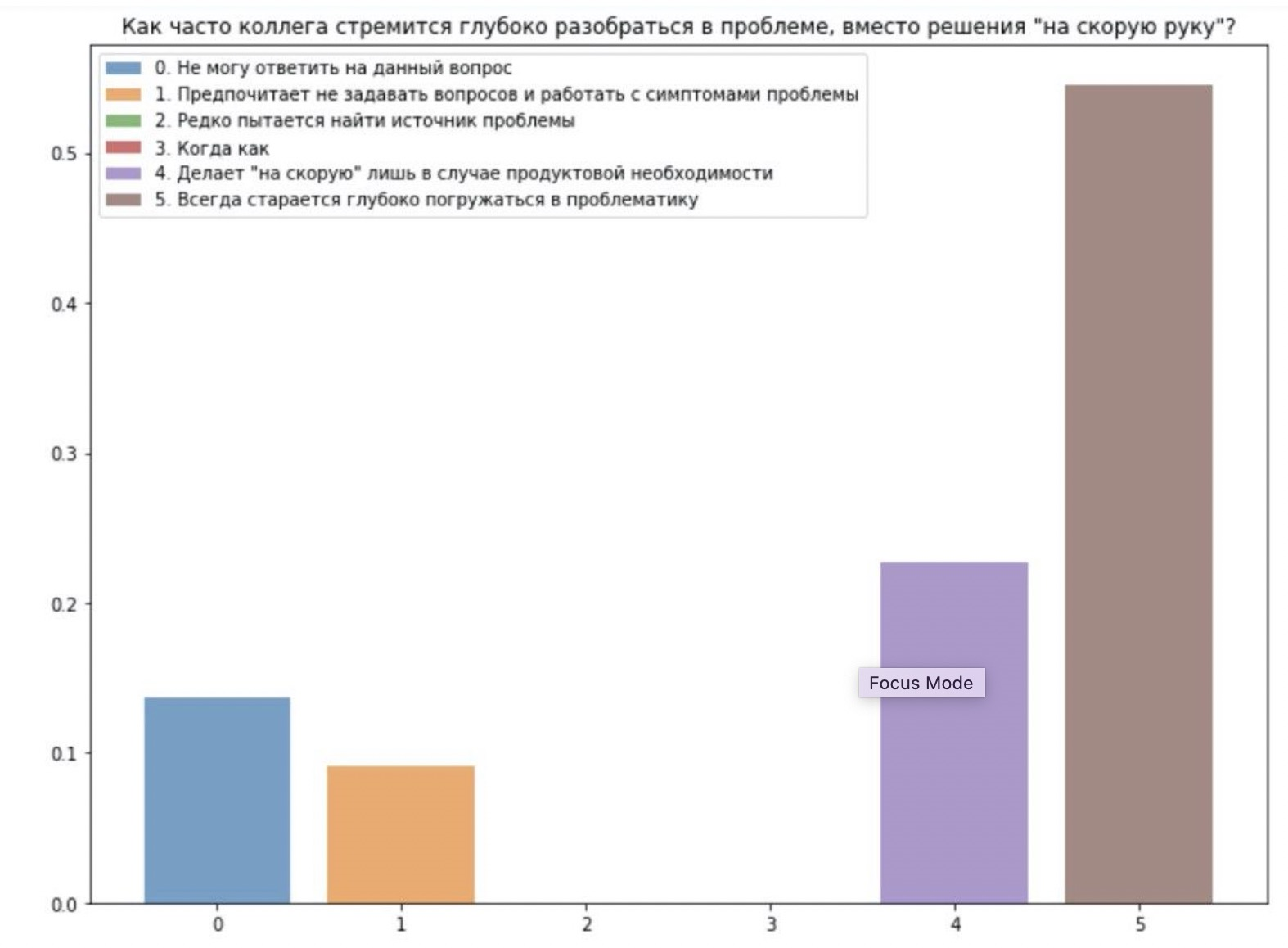
并确保有时无需进行其他工作来澄清规模和校准估计值,就可以获得具有较大差异的数据。也就是说,您需要与人们合作,并考虑“客观”评估的有机倾向。或者也许这是团队内部的分歧,通常来说,了解也是有用的。
360分通常用于两个目的:员工发展和绩效分析。重要的是要理解,输出可能会有所不同,具体取决于提供反馈的人员的准备程度和开放程度。当我们创建增强员工发展能力的工具时,对于我们而言,重要的是要提供来自各种来源的匿名反馈,以帮助他了解他的长处和短处,泵技术,发展缺失的素质。该调查着重于与工作职责的履行以及组织的价值观紧密相关的能力或行为。当我们启动这样的工具时,我们必须向参与者表明我们不是我们将把结果用于人事决定。我们的故事将是关于使用360审查方法来发展员工的故事。
需要员工发展数据来评估发展优势和领域,而不是就奖金/人才变化做出决策。对于公司而言,了解一个人的价值观与公司价值观之间的关系也很重要。 360结果总是与员工及其经理共享。
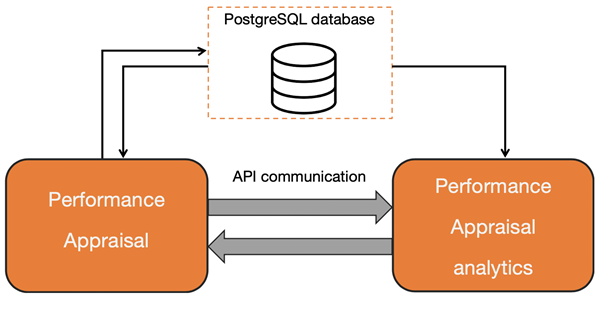
360个调查得分和结果是可用于提供见解和分析的数据宝库。这些数据是计算“校正”因素所需要的,这些因素将有助于获得更可靠的结果,并通过能力,技能,编制各个团队的“资料”等对员工进行聚类。所有这些计算都需要额外的功能和框架,我们决定将其转移到单独的微服务中。因此,我们从逻辑上将用户看到的部分(来自HR部门)与“分析”部分分开,在该部分上执行了所有其他分析计算。这种方法允许独立开发这些服务,并实现其他计算分离。分析服务没有自己的数据库,所有计算均基于主服务数据库中的数据进行,并使用REST-API进行交互。
分析服务是用Flask编写的独立服务器,主要服务是使用PostgreSQL数据库在NodeJS中实现的。这个毫无疑问的困难的交互方案如下所示:
考虑一个评估其他团队中的调查的示例,我们将其称为团队A和团队B。想象一下这样一种情况:在团队A中,员工很友善,彼此相处融洽,因此,平均分可能会很高。与团队A相比,假设团队B由更关键的人员组成,他们诚实地仅向表现良好的员工提供高分。
我们如何比较团队A和团队B的两名员工?为了比较不同团队的员工,我们使用特殊的“团队”校准来获取员工相对于其团队中平均得分的得分。您不能在这里没有公式。
假设我们有一个x得分为0.9的员工x来自A团队,其平均得分为0.85,而一个y得分为b的员工y来自B团队,其平均得分为0.5。减去团队的平均分数后,我们得到员工的“校准”分数:
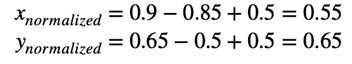
因此,我们看到员工y的校准分数高于员工x的校准分数。
相同示例适用于团队内部归一化。所有员工都是不同的,他们对同事的评价也往往不同。例如,有一个员工x对待所有同事的态度很好,给每个人的平均分数为0.8,还有一个员工y对其他人的评价更为严格,对其他员工的平均得分为0.5。当员工x和y对员工z进行评分时,他们可以在他自己的价值体系中对他进行相同(或相同或差)的评分,因此,在对团队中的平均得分进行平均时,我们减去根据历史数据计算得出的每个员工的平均值。假设员工x对员工z的评分为0.9,而员工y对0.7的评分,则平均得分将相等。
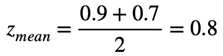
但是,如果减去历史上平均作者的评分,则得出
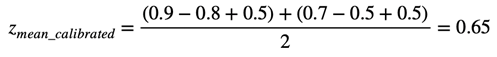
进行此校准后,我们得到的度量标准考虑了每个员工的“价值体系”,因此更加“诚实”。
重要的是,在定义一个人的个人资料时,我们可以权衡不同系数的审阅者的评分。有许多证据表明,管理人员在评估人员时往往更准确,更公正(事实上,这也是他们最终选择原籍的原因),这很可能是由于经验丰富。
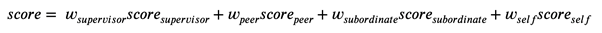
权重的默认值是0.25,也就是说,在当前版本中,我们不优先考虑任何类别的受访者,但是正如在一个古老的轶事中所说的那样,``该工具已存在''。
换句话说,在收集了经过作者校准的估计值之后,我们试图将它们推向全球“坐标系”,以便能够从数据中提取正确的见解。否则,由于评估有偏见,我们可以发现一些确实不存在的惊人规律性,而有什么好处,我们将开始朝着与雇员相反的方向发展雇员。
愿我们成功,我们已经汇编了代表员工胜任力特征的向量。此外,还有来自同事,经理,下属和自尊的向量。我们将所有这些收集到一个多维数据集中(确切地说,是一个平行六面体,但是我将类似于OLAP多维数据集使用术语“多维数据集”)。
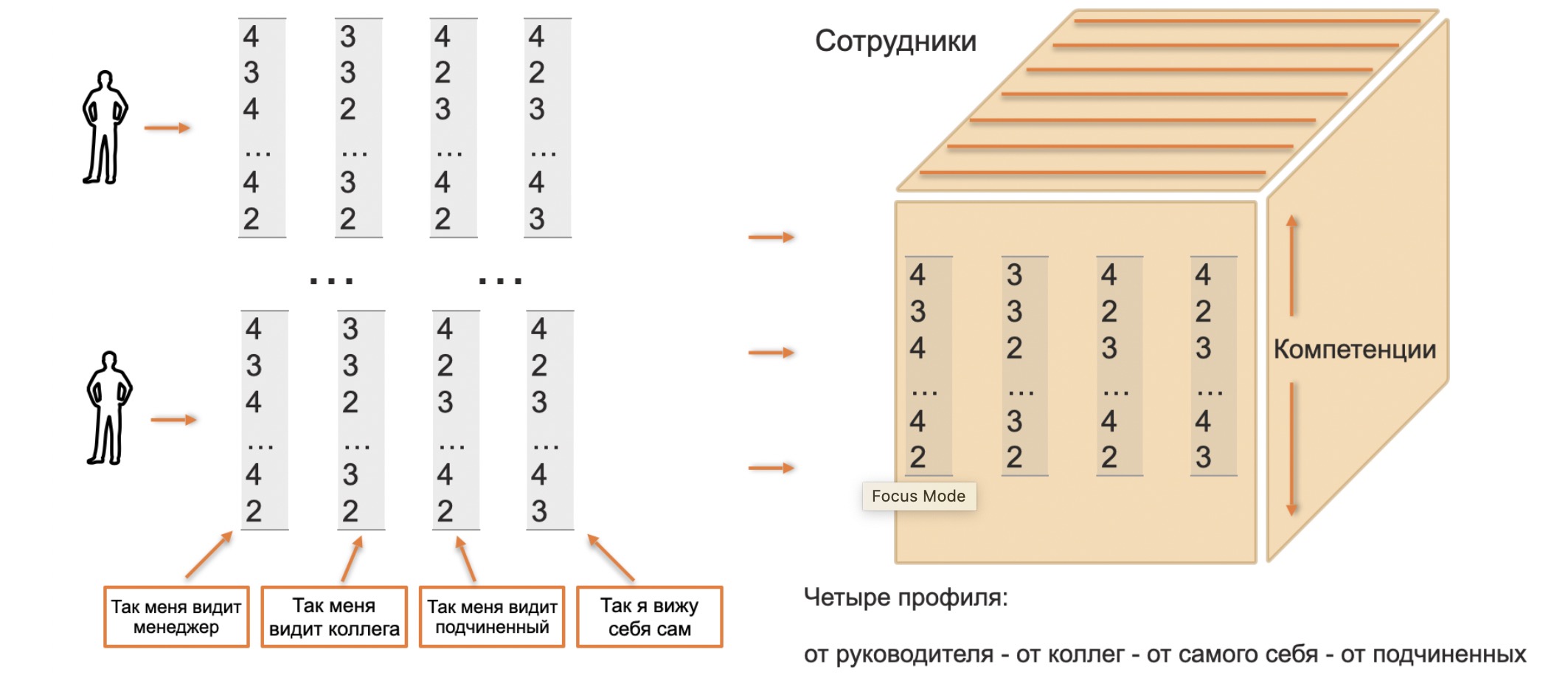
但是现在,通过沿不同的轴剖分多维数据集,我们可以获得各种分析依赖性。例如,让我们修复能力并查看其在整个组织中的分布情况,作为一个整体或跨组织的团队。或者,在经理评级的最右列中,内部查看评级的差异,以查看是否有任何令人惊讶的发现。
通过开发这种逻辑,可以获取团队内部和属于不同部门的员工的比较图,即所谓的蜘蛛网;但是有可能在同一张图上给出团队中能力的平均值,并为特定的人了解他相对于团队以及朝哪个方向被淘汰的情况您可以选择另一个团队,而不是雇员所在的团队,并将其平均能力与一个人的能力进行比较。为什么,如果摇摆不定,就可以将团队与另一个团队进行比较,那就是一个有趣的游戏。
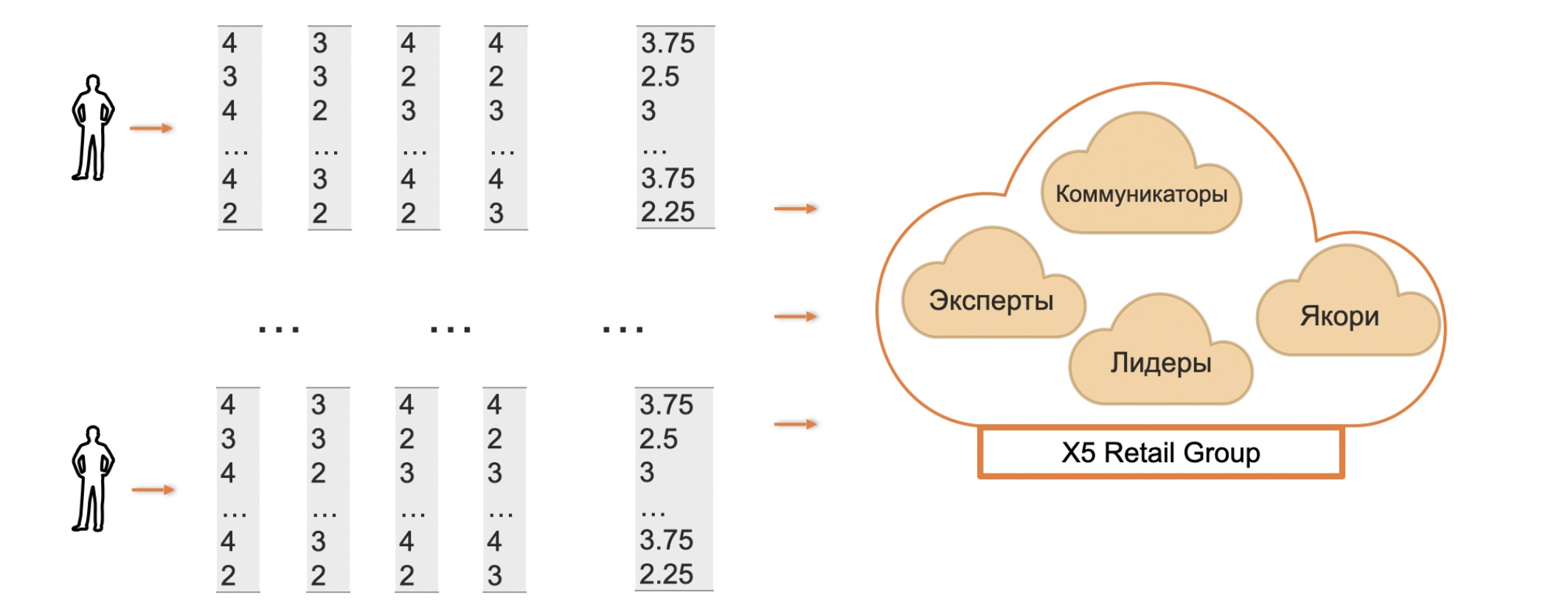
还可以分析组织中某些类型的集群,以找到可能是有效的沟通者或专家,他们以解决问题的深入方法而闻名。
分析上更简单的发现也是可能的,尽管同样有趣。特别是,在同事间进行调查时,其中一名员工的评分存在很大差异,这可能表明对他的同事有极好的看法。
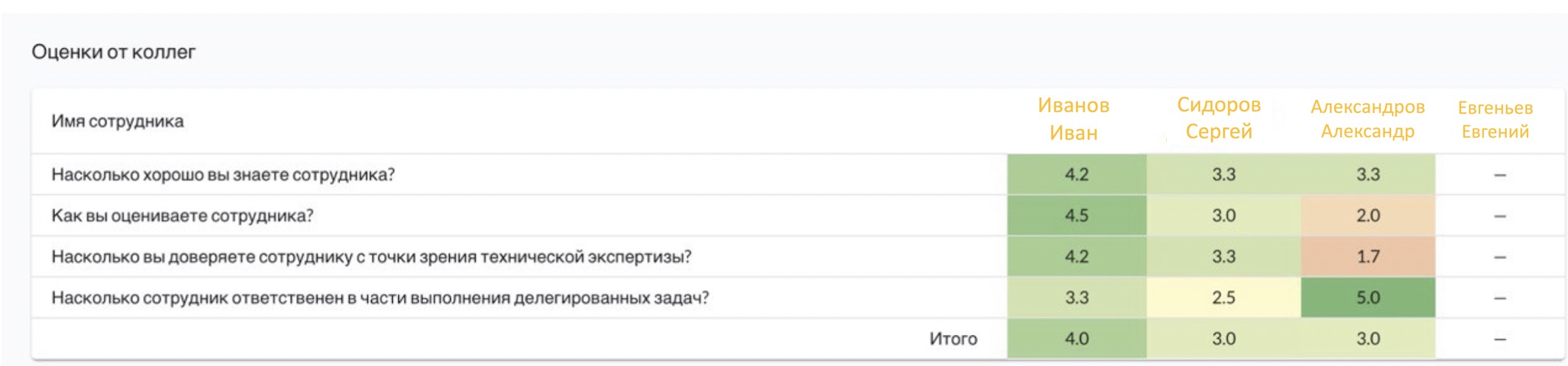
如果比较同事和经理的评分时方差高怎么办?同事和经理对员工的评价是否有很大不同?也许,在这里您可能想知道他是什么样的领导者,以及他对团队成员的态度是否太严格(反之亦然,不挑剔)。或者,如果其他团队重复类似的模式,则可以得出关于组织中管理人员的根本超客观性的结论。
对任何员工的大量缺失评估很可能表明该人与同事的互动很少。同时,对于X5中的某些团队来说,这是一种惯常的操作方式,这也不足为奇,但是很显然,对于某些团队而言,这将指示工作过程中需要进行更改。
将来,我们希望在研究形式中形成更微妙的问题,以消除现阶段的评分偏差,避免与服务用户进行手动操作,以及对如何选择正确的评分及其含义的无休止的解释。我们有几个想法,它们正在验证中,我们一定会与您分享结果。除了沿轴切割和聚类之外,我们还希望将更多狡猾技术应用于数据多维数据集。在这里,我们尝试使用不同的线性和非线性自动编码器,以查找沿不同坐标轴的视图之间的交叉连接。通常,有很多工作 要做,数据不听话,而且建立系统也不容易:)
作者:
Evgeniy Makarov
Valery Babushkin
Svyatoslav Oreshin
Daniil Pavlyuchenko
叶夫根尼·莫洛金(Evgeny Molodkin)