
开始:组装,输入系统,显示。
续:驱动器,电池,声音。
第7部分:文字
现在我们已经完成了Odroid Go的代码层,我们可以开始构建游戏本身了。
让我们从在屏幕上绘制文本开始,因为这将是对将来有用的几个主题的简要介绍。
这部分与之前的部分略有不同,因为在Odroid Go上运行的代码很少。大部分代码将用于我们的第一个工具。
瓷砖
在渲染系统中,我们将使用tile。我们将320x240的屏幕划分为一个瓦片网格,每个瓦片包含16x16像素。这将创建一个20瓦宽和15瓦高的网格。
静态元素(例如背景和文本)将使用图块系统进行渲染,而动态元素(例如sprite)将以不同的方式进行渲染。这意味着背景和文本只能放置在固定的位置,而子画面可以放置在屏幕上的任何位置。
如上所述,一个320x240的帧可以包含300个图块。黄线显示图块之间的边界。每个图块将具有纹理符号或背景元素。

单个图块的缩放图像显示了由灰线分隔的256个组成像素。
字形
通常,在桌面上渲染字体时会使用TrueType字体。字体由代表字符的字形组成。
要使用字体,请使用库(例如FreeType)加载它,并创建一个包含所有字形的位图栅格化版本的字体图集,然后在渲染时对其进行采样。这通常是事先发生的,不是在游戏本身中发生的。
在游戏中,GPU内存使用光栅化字体和代码描述存储一个纹理,该描述可让您确定所需字形在纹理中的位置。文本渲染过程包括将带有字形的纹理的一部分渲染到简单的2D四边形上。
但是,我们采用了不同的方法。与创建TTF文件和库不同,我们将创建自己的简单字体。
传统字体系统(如TrueType)的要点是能够以任何大小或分辨率呈现字体而无需修改原始字体文件。这是通过用数学表达式描述字体来实现的。
但是我们不需要这种多功能性,我们知道所需的显示分辨率和字体大小,因此我们可以手动光栅化自己的字体。
为此,我创建了一个简单的39个字符的字体。每个符号占用一个16x16瓦片。我不是专业的字体设计师,但结果非常适合我。

原始图像为160x64,但是在这里,我将缩放比例增加了一倍,以方便查看。
当然,这将阻止我们使用不使用英文字母的26个字母的语言编写文本。...
编码字形

查看“ A”字形的示例,我们可以看到它的长度为16行,每行16个像素。在每行中,一个像素处于打开或关闭状态。我们可以使用此功能对字形进行编码,而不必以传统方式将字体位图加载到内存中。
一行中的每个像素都可以被视为一位,即一行包含16位。如果像素打开,则该位打开,反之亦然。即,指板编码可以存储为16个16位整数。
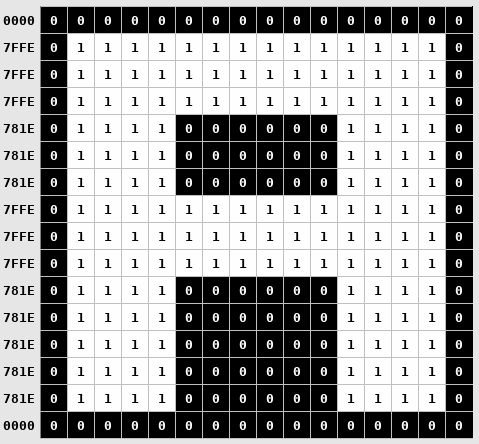
在此方案中,字母“ A”被编码为上面显示的图像。左侧的数字表示16位字符串值。
完整的字形被编码为32个字节(每行2个字节x 16行)。它需要1248个字节来编码所有39个字符。
解决该问题的另一种方法是将图像文件保存到Odroid Go SD卡,在初始化时将其加载到内存中,然后在渲染文本时引用它以查找所需的字形。
但是图像文件必须每个像素至少使用一个字节(0x00或0x01),因此(未压缩)最小图像大小为10240字节(160 x 64)。
除了节省内存外,我们的方法还允许我们对字体字形的字节数组直接进行简单地编码为源代码,这样就不必从文件中加载它们了。
我非常确定ESP32可以将图像加载到内存中并在运行时引用它,但是我喜欢将磁贴直接编码成这样的数组的想法。它与在NES上的实现方式非常相似。
书写工具的重要性
游戏必须以至少每秒30帧的频率实时执行。这意味着游戏中的所有内容都应在1/30秒(约33毫秒)内处理。
为了帮助实现此目标,最好尽可能对数据进行预处理,以便可以在游戏中使用数据而无需进行任何处理。它还可以节省内存和存储空间。
通常,会有某种资源管道来获取从内容创建工具导出的原始数据,并将其转换为更适合在游戏中玩的形式。
就我们的字体而言,我们在Aseprite中创建了一个字符集可以将其导出为160x64图像文件。
无需在游戏开始时将图像加载到内存中,我们可以创建一个工具来将数据转换为上一部分中介绍的针对空间和运行时进行了优化的形式。
字体处理工具
我们必须将原始图像的39个字形中的每一个转换为描述其组成像素状态的字节数组(例如在带有“ A”字符的示例中)。
我们可以将预处理字节数组放入标头文件中,该标头文件将被编译到游戏中并写入其闪存驱动器。 ESP32的闪存比RAM多得多,因此我们可以通过将尽可能多的信息编译到游戏二进制文件中来利用此优势。
第一次,我们可以手动进行像素到字节的转换,这将是非常可行的(尽管很无聊)。但是,如果我们要添加新的字形或更改旧的字形,则该过程将变得单调,冗长且容易出错。
这是创建工具的好机会。
该工具将加载一个图像文件,为每个角色生成一个字节数组,然后将它们写入可编译到游戏中的头文件中。如果要更改字体的字形(我已经做过多次)或添加新的字形,则只需重新运行该工具即可。
第一步是以一种易于阅读的格式从Aseprite导出字形集。我们使用BMP文件格式,因为它具有简单的标头,不压缩图像并允许以每个像素1字节的格式编码图像。
在Aseprite中,我创建了带有索引调色板的图像,因此每个像素都是一个字节,代表仅包含黑色(索引0)和白色(索引1)颜色的调色板索引。导出的BMP文件将保留此编码:禁用的像素的字节为0x0,而启用的像素的字节为0x1。
我们的工具将收到五个参数:
- 从Aseprite导出的BMP
- 描述字形方案的文本文件
- 生成的输出文件的路径
- 每个字形的宽度
- 每个字形的高度
需要字形模式描述文件,才能将图像的视觉信息映射到代码中的字符本身。
导出的字体图像的描述如下所示:
ABCDEFGHIJ
KLMNOPQRST
UVWXYZ1234
567890:!?
它必须与图像中的模式匹配。
if (argc != 6)
{
fprintf(stderr, "Usage: %s <input image> <layout file> <output header> <glyph width> <glyph height>\n", argv[0]);
return 1;
}
const char* inFilename = argv[1];
const char* layoutFilename = argv[2];
const char* outFilename = argv[3];
const int glyphWidth = atoi(argv[4]);
const int glyphHeight = atoi(argv[5]);我们要做的第一件事是简单的验证和命令行参数的解析。
FILE* inFile = fopen(inFilename, "rb");
assert(inFile);
#pragma pack(push,1)
struct BmpHeader
{
char magic[2];
uint32_t totalSize;
uint32_t reserved;
uint32_t offset;
uint32_t headerSize;
int32_t width;
int32_t height;
uint16_t planes;
uint16_t depth;
uint32_t compression;
uint32_t imageSize;
int32_t horizontalResolution;
int32_t verticalResolution;
uint32_t paletteColorCount;
uint32_t importantColorCount;
} bmpHeader;
#pragma pack(pop)
// Read the BMP header so we know where the image data is located
fread(&bmpHeader, 1, sizeof(bmpHeader), inFile);
assert(bmpHeader.magic[0] == 'B' && bmpHeader.magic[1] == 'M');
assert(bmpHeader.depth == 8);
assert(bmpHeader.headerSize == 40);
// Go to location in file of image data
fseek(inFile, bmpHeader.offset, SEEK_SET);
// Read in the image data
uint8_t* imageBuffer = malloc(bmpHeader.imageSize);
assert(imageBuffer);
fread(imageBuffer, 1, bmpHeader.imageSize, inFile);
int imageWidth = bmpHeader.width;
int imageHeight = bmpHeader.height;
fclose(inFile);首先读取图像文件。
BMP文件格式具有一个描述文件内容的标头。尤其是,图像的宽度和高度以及图像数据开始处文件中的偏移量对我们很重要。
我们将创建一个描述此标头架构的结构,以便可以加载标头并可以通过名称访问所需的值。的编译指示包线确保了没有填充字节添加到该结构使得当头部被从文件中读取,它正确地匹配。
BMP格式有点奇怪,因为偏移量后的字节可能会根据所使用的BMP规范而发生很大变化(Microsoft对其进行了多次更新)。与headerSize我们检查使用的是哪个版本的标题。
我们检查标头的前两个字节是否等于BM,因为这意味着它是一个BMP文件。接下来,我们检查位深度为8,因为我们希望每个像素为一个字节。我们还检查头文件是否为40个字节,因为这意味着BMP文件是我们想要的版本。
在调用fseek之后,将图像数据加载到imageBuffer中,以导航至offset指示的图像数据的位置。
FILE* layoutFile = fopen(layoutFilename, "r");
assert(layoutFile);
// Count the number of lines in the file
int layoutRows = 0;
while (!feof(layoutFile))
{
char c = fgetc(layoutFile);
if (c == '\n')
{
++layoutRows;
}
}
// Return file position indicator to start
rewind(layoutFile);
// Allocate enough memory for one string pointer per row
char** glyphLayout = malloc(sizeof(*glyphLayout) * layoutRows);
assert(glyphLayout);
// Read the file into memory
for (int rowIndex = 0; rowIndex < layoutRows; ++rowIndex)
{
char* line = NULL;
size_t len = 0;
getline(&line, &len, layoutFile);
int newlinePosition = strlen(line) - 1;
if (line[newlinePosition] == '\n')
{
line[newlinePosition] = '\0';
}
glyphLayout[rowIndex] = line;
}
fclose(layoutFile);我们将字形模式描述文件读入下面需要的字符串数组中。
首先,我们计算文件中的行数,以了解需要为这些行分配多少内存(每行一个指针),然后将文件读入内存。
换行符被截断,以免增加字符行的长度。
fprintf(outFile, "int GetGlyphIndex(char c)\n");
fprintf(outFile, "{\n");
fprintf(outFile, " switch (c)\n");
fprintf(outFile, " {\n");
int glyphCount = 0;
for (int row = 0; row < layoutRows; ++row)
{
int glyphsInRow = strlen(glyphLayout[row]);
for (int glyph = 0; glyph < glyphsInRow; ++glyph)
{
char c = glyphLayout[row][glyph];
fprintf(outFile, " ");
if (isalpha(c))
{
fprintf(outFile, "case '%c': ", tolower(c));
}
fprintf(outFile, "case '%c': { return %d; break; }\n", c, glyphCount);
++glyphCount;
}
}
fprintf(outFile, " default: { assert(NULL); break; }\n");
fprintf(outFile, " }\n");
fprintf(outFile, "}\n\n");我们生成了一个名为GetGlyphIndex的函数,该函数接受一个字符并在字形图中返回该字符的数据索引(稍后将生成)。
该工具迭代遍历先前读取的架构描述,并生成将字符与索引匹配的switch语句。它允许您将小写和大写字符绑定到相同的值,并在尝试使用不是字形映射字符的字符时生成一个断言。
fprintf(outFile, "static const uint16_t glyphMap[%d][%d] =\n", glyphCount, glyphHeight);
fprintf(outFile, "{\n");
for (int y = 0; y < layoutRows; ++y)
{
int glyphsInRow = strlen(glyphLayout[y]);
for (int x = 0; x < glyphsInRow; ++x)
{
char c = glyphLayout[y][x];
fprintf(outFile, " // %c\n", c);
fprintf(outFile, " {\n");
fprintf(outFile, " ");
int count = 0;
for (int row = y * glyphHeight; row < (y + 1) * glyphHeight; ++row)
{
uint16_t val = 0;
for (int col = x * glyphWidth; col < (x + 1) * glyphWidth; ++col)
{
// BMP is laid out bottom-to-top, but we want top-to-bottom (0-indexed)
int y = imageHeight - row - 1;
uint8_t pixel = imageBuffer[y * imageWidth + col];
int bitPosition = 15 - (col % glyphWidth);
val |= (pixel << bitPosition);
}
fprintf(outFile, "0x%04X,", val);
++count;
// Put a newline after four values to keep it orderly
if ((count % 4) == 0)
{
fprintf(outFile, "\n");
fprintf(outFile, " ");
count = 0;
}
}
fprintf(outFile, "},\n\n");
}
}
fprintf(outFile, "};\n");最后,我们为每个字形生成自己的16位值。
我们从上到下,从左到右遍历描述中的字符,然后通过遍历图像中的每个像素为每个字形创建16个16位值。如果启用了像素,则代码将写入该像素1的位位置,否则将写入-0。
不幸的是,由于对fprintf的多次调用,此工具的代码相当丑陋,但我希望其中的含义是清楚的。
然后可以运行该工具来处理导出的字体图像文件:
./font_processor font.bmp font.txt font.h 16 16并生成以下(缩写)文件:
static const int GLYPH_WIDTH = 16;
static const int GLYPH_HEIGHT = 16;
int GetGlyphIndex(char c)
{
switch (c)
{
case 'a': case 'A': { return 0; break; }
case 'b': case 'B': { return 1; break; }
case 'c': case 'C': { return 2; break; }
[...]
case '1': { return 26; break; }
case '2': { return 27; break; }
case '3': { return 28; break; }
[...]
case ':': { return 36; break; }
case '!': { return 37; break; }
case '?': { return 38; break; }
default: { assert(NULL); break; }
}
}
static const uint16_t glyphMap[39][16] =
{
// A
{
0x0000,0x7FFE,0x7FFE,0x7FFE,
0x781E,0x781E,0x781E,0x7FFE,
0x7FFE,0x7FFE,0x781E,0x781E,
0x781E,0x781E,0x781E,0x0000,
},
// B
{
0x0000,0x7FFC,0x7FFE,0x7FFE,
0x780E,0x780E,0x7FFE,0x7FFE,
0x7FFC,0x780C,0x780E,0x780E,
0x7FFE,0x7FFE,0x7FFC,0x0000,
},
// C
{
0x0000,0x7FFE,0x7FFE,0x7FFE,
0x7800,0x7800,0x7800,0x7800,
0x7800,0x7800,0x7800,0x7800,
0x7FFE,0x7FFE,0x7FFE,0x0000,
},
[...]
// 1
{
0x0000,0x01E0,0x01E0,0x01E0,
0x01E0,0x01E0,0x01E0,0x01E0,
0x01E0,0x01E0,0x01E0,0x01E0,
0x01E0,0x01E0,0x01E0,0x0000,
},
// 2
{
0x0000,0x7FFE,0x7FFE,0x7FFE,
0x001E,0x001E,0x7FFE,0x7FFE,
0x7FFE,0x7800,0x7800,0x7800,
0x7FFE,0x7FFE,0x7FFE,0x0000,
},
// 3
{
0x0000,0x7FFE,0x7FFE,0x7FFE,
0x001E,0x001E,0x3FFE,0x3FFE,
0x3FFE,0x001E,0x001E,0x001E,
0x7FFE,0x7FFE,0x7FFE,0x0000,
},
[...]
// :
{
0x0000,0x0000,0x3C00,0x3C00,
0x3C00,0x3C00,0x0000,0x0000,
0x0000,0x0000,0x3C00,0x3C00,
0x3C00,0x3C00,0x0000,0x0000,
},
// !
{
0x0000,0x3C00,0x3C00,0x3C00,
0x3C00,0x3C00,0x3C00,0x3C00,
0x3C00,0x3C00,0x0000,0x0000,
0x3C00,0x3C00,0x3C00,0x0000,
},
// ?
{
0x0000,0x7FFE,0x7FFE,0x7FFE,
0x781E,0x781E,0x79FE,0x79FE,
0x01E0,0x01E0,0x0000,0x0000,
0x01E0,0x01E0,0x01E0,0x0000,
},
};, switch , GetGlyphIndex O(1), , , 39 if.
, . - .
, .
-, char c int, .
用字形字节数组填充font.h文件后,就可以开始将它们绘制到屏幕上了。
static const int MAX_GLYPHS_PER_ROW = LCD_WIDTH / GLYPH_WIDTH;
static const int MAX_GLYPHS_PER_COL = LCD_HEIGHT / GLYPH_HEIGHT;
void DrawText(uint16_t* framebuffer, char* string, int length, int x, int y, uint16_t color)
{
assert(x + length < MAX_GLYPHS_PER_ROW);
assert(y < MAX_GLYPHS_PER_COL);
for (int charIndex = 0; charIndex < length; ++charIndex)
{
char c = string[charIndex];
if (c == ' ')
{
continue;
}
int xStart = GLYPH_WIDTH * (x + charIndex);
int yStart = GLYPH_HEIGHT * y;
for (int row = 0; row < GLYPH_HEIGHT; ++row)
{
for (int col = 0; col < GLYPH_WIDTH; ++col)
{
int bitPosition = 1U << (15U - col);
int glyphIndex = GetGlyphIndex(c);
uint16_t pixel = glyphMap[glyphIndex][row] & bitPosition;
if (pixel)
{
int screenX = xStart + col;
int screenY = yStart + row;
framebuffer[screenY * LCD_WIDTH + screenX] = color;
}
}
}
}
}由于我们将主要负载转移到了我们的工具上,因此文本呈现代码本身将非常简单。
要渲染字符串,我们将遍历其组成字符,如果遇到空格,则跳过一个字符。
对于每个非空格字符,我们获取字形图中的字形索引,以便获取其字节数组。
要检查字形中的像素,我们循环遍历256个像素(16x16),并检查每行中每个位的值。如果该位为开,那么我们将该像素的颜色写入帧缓冲区。如果未启用,则我们什么也不做。
通常不值得将数据写入头文件,因为如果该头文件包含在多个源文件中,则链接器将抱怨多个定义。但是font.h只包含在text.c文件的代码中,因此不会引起问题。
演示版
我们将通过渲染著名的pangram (测试用棕色的狐狸跳过懒狗)来测试渲染文本,该字体使用字体支持的所有字符。
DrawText(gFramebuffer, "The Quick Brown Fox", 19, 0, 5, SWAP_ENDIAN_16(RGB565(0xFF, 0, 0)));
DrawText(gFramebuffer, "Jumped Over The:", 16, 0, 6, SWAP_ENDIAN_16(RGB565(0, 0xFF, 0)));
DrawText(gFramebuffer, "Lazy Dog?!", 10, 0, 7, SWAP_ENDIAN_16(RGB565(0, 0, 0xFF)));我们将DrawText调用三遍,以使线条出现在不同的线条上,并为每条线条增加Y磁贴,以便将每条线条绘制在上一行的下方。我们还将为每行设置不同的颜色以测试颜色。
现在,我们手动计算字符串的长度,但是在将来,我们将摆脱这种麻烦。
链接
第8部分:图块系统
如前所述,我们将使用图块创建游戏背景。背景前面的动态对象将是精灵,稍后我们将对其进行介绍。精灵的例子有敌人,子弹和玩家角色。
我们将在320x240的屏幕上以20x15的固定网格放置16x16的图块。在任何给定时间,我们将能够在屏幕上显示多达300个图块。
平铺缓冲区
要存储图块,我们应该使用静态数组,而不是动态内存,以免担心malloc和free,内存泄漏以及分配内存时内存不足(Odroid是内存量有限的嵌入式系统)。
如果我们要在屏幕上存储图块的布局,并且总图块为20x15,则可以使用20x15数组,其中每个元素都是“地图”中的图块索引。tilemap包含瓦片图形本身。
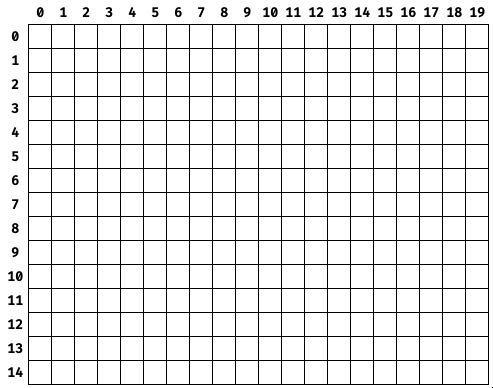
在此图中,顶部的数字代表图块的X坐标(以图块为单位),而左侧的数字代表图块的Y坐标(以图块为单位)。
在代码中,可以这样表示:
uint8_t tileBuffer[15][20];该解决方案的问题在于,如果我们要更改屏幕上显示的内容(通过更改图块的内容),则播放器将看到图块的替换。
这可以通过扩展缓冲区来解决,以便在屏幕外时可以对其进行写入,并且在显示时看起来是连续的。

灰色正方形表示在图块缓冲区中的可见“窗口”,该窗口在屏幕上呈现。当屏幕显示灰色方块中的内容时,可以更改所有白色方块的内容,以便播放器看不到它。
在代码中,可以认为它是X大小的两倍的数组。
uint8_t tileBuffer[15][40];选择一个调色板
现在,我们将使用四个灰度值的调色板。
在RGB888格式下,它们看起来像:
- 0xFFFFFF(白色/ 100%值)。
- 0xABABAB (- / 67% )
- 0x545454 (- / 33% )
- 0x000000 ( / 0% )
我们暂时不使用颜色,因为我仍在提高自己的艺术水平。通过使用灰度,我可以专注于对比度和形状,而不必担心颜色理论。即使是很小的调色板也需要良好的艺术品味。
如果您对2位灰度颜色的强度有疑问,可以考虑Game Boy,它的调色板中只有四种颜色。第一个Game Boy屏幕为绿色,因此四个值以绿色阴影显示,但Game Boy Pocket将它们显示为真实灰度。
下图为《塞尔达传说:连环的觉醒》显示,如果你有一个好的艺术家,仅用四个价值就可以实现多少目标。
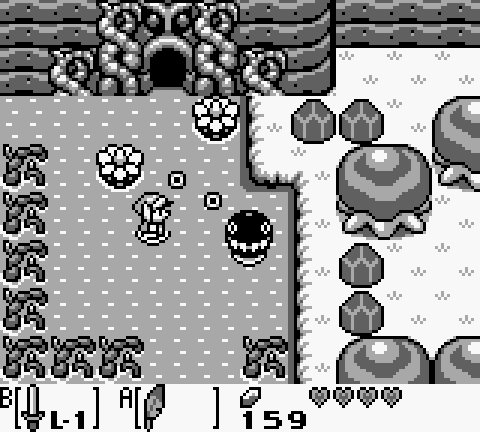
目前,磁贴图形将看起来像四个正方形,外部有一个像素边框,且角被截断。每个方块将具有调色板中的一种颜色。
截断角是一个很小的变化,但是它使您能够区分各个图块,这对于渲染网格很有用。

调色板工具
我们将以JASC Palette文件格式存储该调色板,该文件格式易于阅读,易于使用工具解析并且受Aseprite支持。
调色板看起来像这样
JASC-PAL
0100
4
255 255 255
171 171 171
84 84 84
0 0 0在每个PAL文件中都可以找到前两行。第三行是调色板中的项目数。其余的线是调色板的红色,绿色和蓝色元素的值。
调色板工具读取文件,将每种颜色转换为RGB565,反转字节顺序,并将新值写入包含数组的调色板的头文件中。
用于读取和写入文件的代码与第七篇文章中使用的代码相似,并且颜色处理如下所示:
// Each line is of form R G B
for (int i = 0; i < paletteSize; ++i)
{
getline(&line, &len, inFile);
char* tok = strtok(line, " ");
int red = atoi(tok);
tok = strtok(NULL, " ");
int green = atoi(tok);
tok = strtok(NULL, " ");
int blue = atoi(tok);
uint16_t rgb565 =
((red >> 3u) << 11u)
| ((green >> 2u) << 5u)
| (blue >> 3u);
uint16_t endianSwap = ((rgb565 & 0xFFu) << 8u) | (rgb565 >> 8u);
palette[i] = endianSwap;
}该strtok的功能根据分隔符拆分字符串。三个颜色值由单个空格分隔,因此我们使用它。然后,就像在本文的第三部分中所做的那样,通过移位位并反转字节顺序来创建RGB565值。
./palette_processor grey.pal grey.h该工具的输出如下所示:
uint16_t palette[4] =
{
0xFFFF,
0x55AD,
0xAA52,
0x0000,
};瓷砖加工工具
我们还需要一个工具,以游戏所需的格式输出图块数据。BMP文件中每个像素的值是一个调色板索引。我们将保留这种间接表示法,以便16x16(256)字节的图块每个像素占用一个字节。在程序执行期间,我们会在调色板中找到瓷砖的颜色。
该工具读取文件,遍历像素,并将其索引写入标头中的数组。
用于读取和写入文件的代码也类似于字体处理工具中的代码,并且在此处创建相应的数组:
for (int row = 0; row < tileHeight; ++row)
{
for (int col = 0; col < tileWidth; ++col)
{
// BMP is laid out bottom-to-top, but we want top-to-bottom (0-indexed)
int y = tileHeight - row - 1;
uint8_t paletteIndex = tileBuffer[y * tileWidth + col];
fprintf(outFile, "%d,", paletteIndex);
++count;
// Put a newline after sixteen values to keep it orderly
if ((count % 16) == 0)
{
fprintf(outFile, "\n");
fprintf(outFile, " ");
count = 0;
}
}
}从BMP文件中的像素位置获取索引,然后将其作为16x16数组元素写入文件。
./tile_processor black.bmp black.h该工具在处理黑色图块时的输出如下所示:
static const uint8_t tile[16][16] =
{
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,3,3,3,3,3,3,3,3,3,3,3,3,0,0,
0,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0,
0,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0,
0,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0,
0,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0,
0,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0,
0,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0,
0,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0,
0,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0,
0,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0,
0,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0,
0,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0,
0,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0,
0,0,3,3,3,3,3,3,3,3,3,3,3,3,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
};如果仔细观察,您可以仅通过索引来了解图块的外观。每3表示黑色,每0表示白色。
框架窗
例如,我们可以创建一个简单(且非常短)的“级别”来填充整个图块缓冲区。我们有四个不同的图块,而不必担心图形,我们仅使用一种方案,其中四个图块中的每个图块具有不同的灰度颜色。

我们在40x15的水平网格中排列四个图块以测试我们的系统。
上面的数字表示帧缓冲区的列索引。下面的数字是框架窗口列的索引。左边的数字是每个缓冲区的行(没有垂直窗口移动)。
对于播放器,一切将如上面的视频所示。当窗口向右移动时,播放器会看到背景向左移动。
演示版
左上角的数字是图块缓冲区窗口左边缘的列号,右上角的数字是图块缓冲区窗口右边缘的列号。
资源
整个项目的源代码位于此处。