但是对象跟踪到底如何工作?有很多针对此问题的深度学习解决方案,今天我想谈谈一个常见的解决方案及其背后的数学原理。
因此,在本文中,我将尝试用简单的单词和公式告诉您:
- YOLO是出色的物体检测器
- 卡尔曼滤波器
- 马氏距离
- 深层排序
YOLO是出色的物体检测器
您需要立即记住一个非常重要的注意事项-对象检测不是对象跟踪。对于许多人来说,这不是新闻,但人们常常会混淆这些概念。用简单的话说:“
对象检测”只是定义图片/帧中的对象。也就是说,算法或神经网络定义对象并记录其位置和边界框(对象周围矩形的参数)。到目前为止,还没有其他框架的讨论,该算法仅适用于一个框架。
例如:
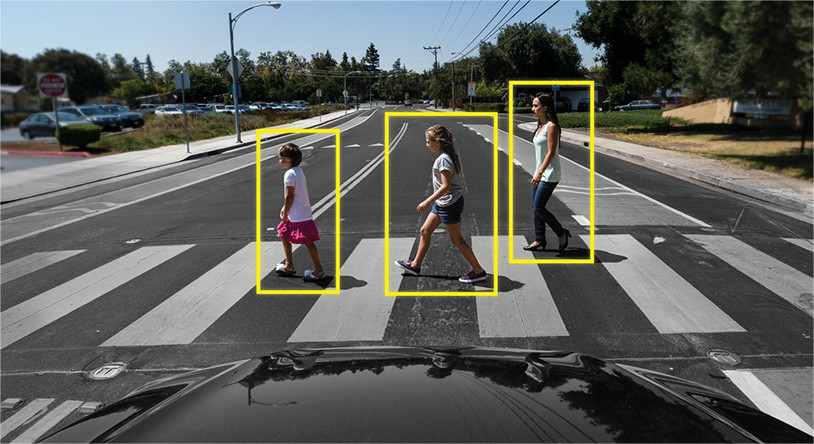
对象跟踪完全是另一回事。这里的任务不仅是识别帧中的对象,而且还以不丢失对象或使其唯一的方式链接来自先前帧的信息。
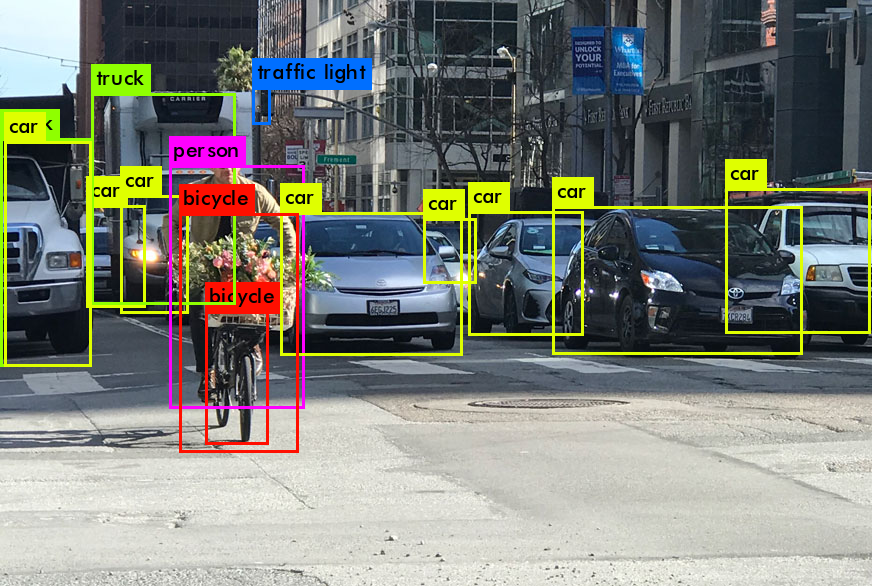
例:

即,对象跟踪器包括用于确定对象的对象检测,以及用于理解新帧上的哪个对象属于先前帧中的哪个的其他算法。
因此,对象检测在跟踪任务中起着非常重要的作用。
为什么选择YOLO?是的,因为YOLO被认为比许多其他算法更有效地识别对象。这是与YOLO的创建者进行比较的一幅小图:
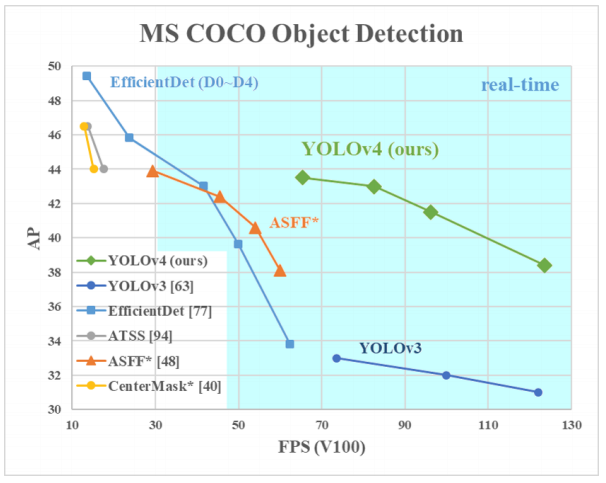
在这里,我们看的是YOLOv3-4,因为它们是最新版本,并且比以前的版本更有效。
不同对象检测器的架构
因此,有几种设计用于定义对象的神经网络体系结构。它们通常分为“两层”,例如RCNN,快速RCNN和更快的RCNN,以及“单层”,例如YOLO。
上面列出的“两层”神经网络使用图片中的所谓区域来确定特定对象是否在该区域中。
通常看起来像这样(对于更快的RCNN,这是列出的两层系统中最快的):
- 图片/帧馈入输入
- 该框架通过CNN运行以形成特征图
- 单独的神经网络定义了在其中找到对象的可能性很高的区域
- 然后使用RoI池压缩这些区域并将其馈送到神经网络,该神经网络确定区域中对象的类别

但是,这些神经网络有两个关键问题:它们不能看整个画面,而只能看单个区域,而且速度相对较慢。
YOLO有什么好酷的?该架构从上面没有两个问题,并且已经反复证明了其有效性。
通常,第一个块中的YOLO体系结构在“块逻辑”方面与其他检测器的差别不大,也就是说,将图片馈送到输入端,然后使用CNN创建特征图(尽管YOLO使用其自己的称为Darknet-53的CNN),然后这些特征图将以某种方式进行分析(稍后会对此进行详细介绍),并给出边界框的位置和大小以及它们所属的类。

但是,脖子,密集预测和稀疏预测是什么?
我们早些时候处理过稀疏预测-这只是对两层算法工作原理的重申:它们分别定义区域,然后对这些区域进行分类。
颈部(或“颈部”)是一个单独的块,创建该块是为了汇总来自先前块的单独层中的信息(如上图所示),以提高预测的准确性。如果对此感兴趣,则可以使用Google术语“路径聚合网络”,“空间注意模块”和“空间金字塔池”。
最后,YOLO与所有其他架构的区别是一个称为(在上图中的)密集预测的块。我们将重点放在它上面,因为这是一个非常有趣的解决方案,它使YOLO成为对象检测效率方面的领导者。
YOLO(只看一次)的哲学是只看一次图片,然后进行一次查看(即通过一个神经网络运行一幅图片)以进行所有必要的对象定义。这是怎么发生的?
因此,在YOLO工作结束时,我们通常希望这样
做:YOLO从数据中学习时的功能(简单来说):
步骤1:通常,在训练神经网络之前,图片将被重塑为416x416的大小,以便可以分批添加图片(以加速学习) )。
步骤2:将图片(暂时而言)划分为大小为a x a的像元。在YOLOv3-4中,习惯上将其划分为13x13大小的单元(稍后我们将讨论不同的比例以使其更清晰)。

现在,让我们集中讨论将图片/帧划分为的这些单元格。这些单元称为网格单元,是YOLO理念的核心。每个单元格都是一个“锚”,其上装有边界框。也就是说,围绕单元格绘制了几个矩形以定义对象(由于尚不清楚矩形最适合哪种形状,因此会立即以几种不同的形状绘制它们),并相对于此单元格的中心计算其位置,宽度和高度。
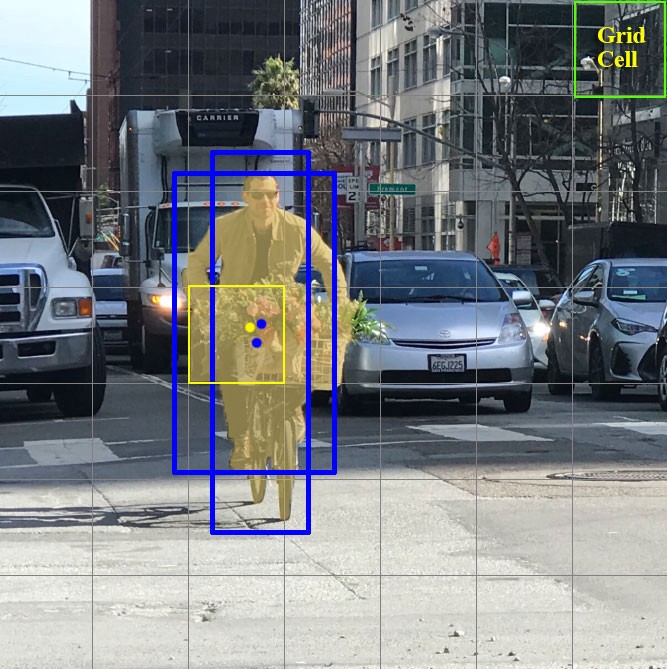
这些包围盒如何在笼子周围绘制?如何确定其大小和位置?这就是锚框技术(翻译为-锚框或“锚矩形”)发挥作用的地方。它们是由用户自己设置的,或者是根据YOLO将在其上训练的数据集中的边界框的大小确定它们的大小的(K均值聚类和IoU用于确定最合适的大小)。通常,将在一个单元周围(或内部)绘制3个不同的锚框:

为什么要这样做?现在,我们讨论YOLO的学习方式将变得很清楚。
步骤3.来自数据集的图片通过我们的神经网络运行(请注意,除了训练数据集中的图片之外,我们还必须具有对象上真实边界框的位置和大小。这称为“注释”,并且大部分是手动完成的)。
现在让我们考虑我们需要在输出中得到什么。
对于每个单元格,我们需要了解两个基本知识:
- 笼子周围绘制的3个锚定框中的哪一个最适合我们,我们如何对其进行一些调整,使其与对象完美契合
- 锚框内有什么物体,根本没有
那么YOLO的输出应该是什么?
1.在每个单元的输出处,我们希望获得:

2.输出应包含以下参数:
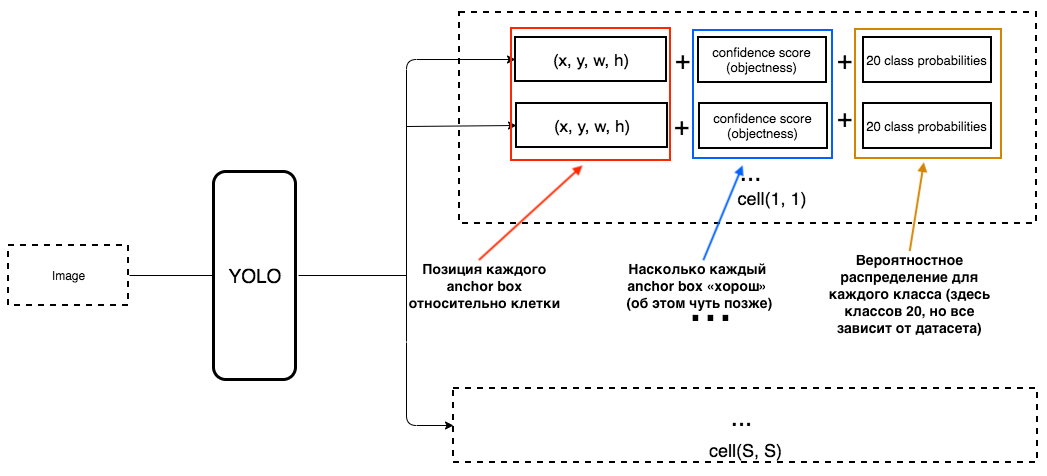
如何确定客观性?实际上,该参数是在训练过程中使用IoU指标确定的。 IoU指标的工作方式如下:
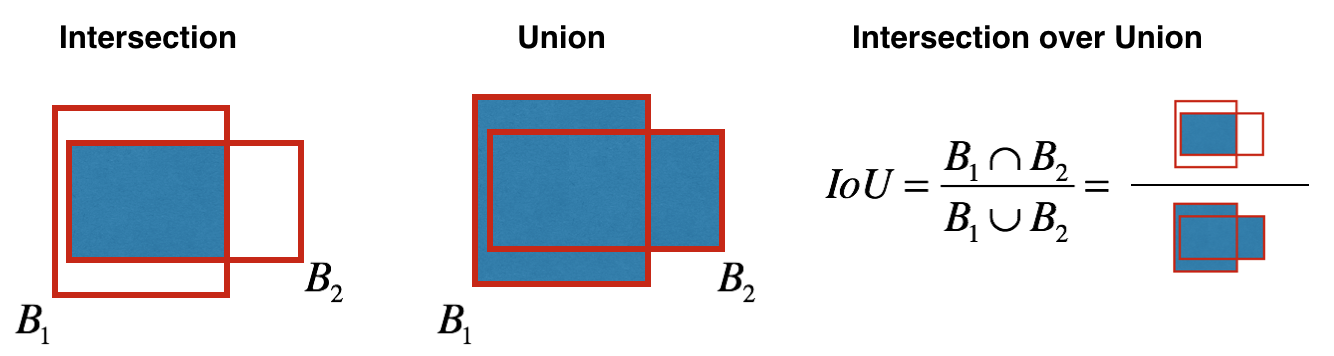
首先,您可以为此指标设置一个阈值,如果预测的边界框高于此阈值,则其对象度等于1,所有其他具有较低对象度的边界框将被排除。在为每个特定对象计算总体置信度得分(在多大程度上确保这是我们需要的对象位于预测的矩形内)时,我们将需要此客观性值。
现在,乐趣开始了。假设我们是YOLO的创造者,我们需要培训她以识别相框/图片中的人物。我们将图像从数据集中输入到YOLO,在开始时进行特征提取,最后获得CNN层,该层告诉我们“划分”图像的所有单元格。并且如果该层告诉我们有关图片中细胞的“谎言”,那么我们必须具有较大的损失,以便以后可以将以下图片输入到神经网络中时减少损失。
很清楚,关于YOLO如何创建最后一层的示意图非常简单:
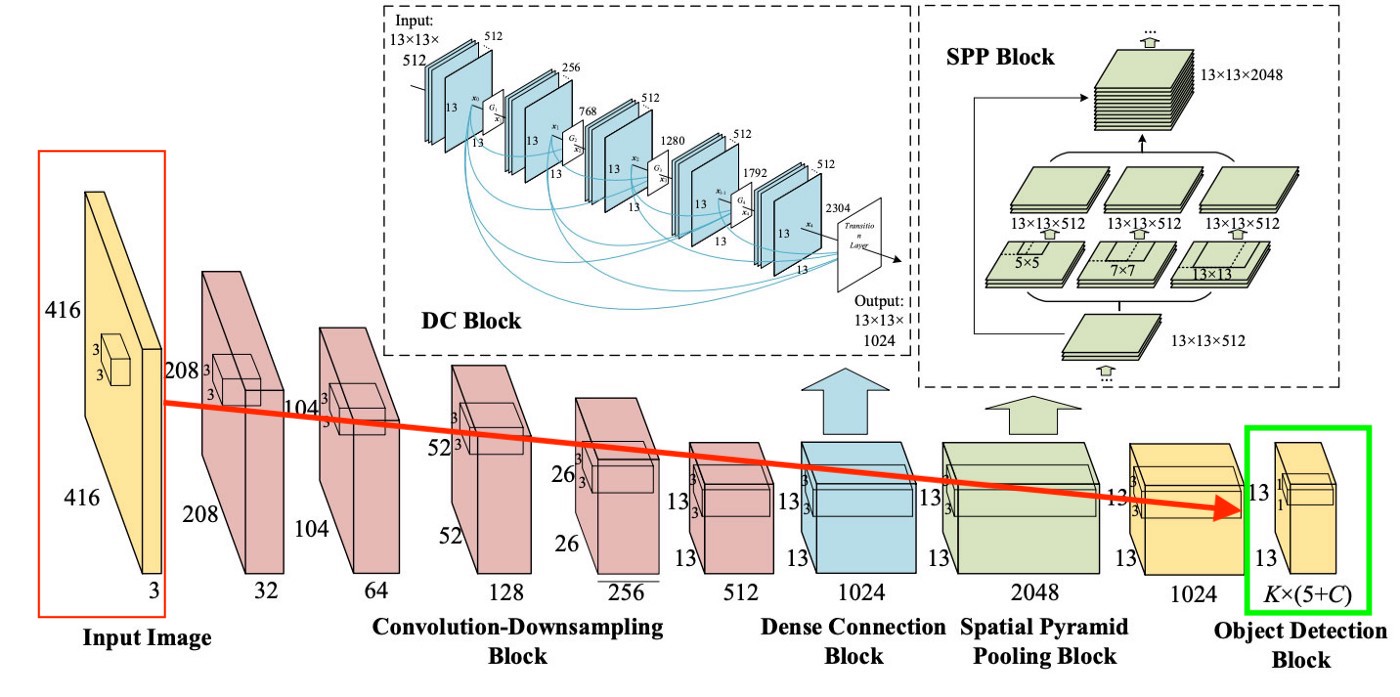
从图片中我们可以看到,为了谈论图片中的“每个单元格”,该层为13x13(图片的原始大小为416x416)。从最后一层,获得我们想要的信息。
YOLO预测了5个参数(对于特定单元格的每个锚定框):

为了更易于理解,该主题有一个很好的可视化效果:

正如您可以从这张图片中了解到的那样,YOLO的任务是尽可能准确地预测这些参数,以便尽可能准确地确定图片中的对象。为每个预测边界框确定的置信度分数是一种过滤器,用于过滤出完全不准确的预测。对于每个预测的边界框,我们将其IoU乘以这是某个对象的概率(概率分布是在训练神经网络期间计算的),我们采用所有可能的最佳概率,并且如果相乘后的数量超过某个阈值,则可以保留此预测图片中的边框。
此外,当我们仅预测具有高置信度得分的边界框时,我们的预测(如果可视化)可能类似于以下内容:

现在,我们可以使用NMS(非最大抑制)技术来过滤边界框,以便一个对象中只有一个预测的边界框。

您还应该知道YOLOv3-4可以在3种不同的尺度上进行预测。即,图片被分为64个网格单元,256个单元和1024个单元,以便也看到小的物体。对于每组细胞,该算法在预测/学习过程中重复上述必要的动作。
YOLOv4中使用了许多技术来提高模型精度,而又不会损失太多速度。但是对于预测本身,“密集预测”与YOLOv3中的相同。如果您对作者为提高准确性而不损失速度而神奇地所做的事情感兴趣,那么有一篇关于YOLOv4的精彩文章。
我希望我能够传达一些有关YOLO总体工作原理的信息(更确切地说,是后两个版本,即YOLOv3和YOLOv4),这将唤醒您将来使用此模型的愿望,或者进一步了解它的工作。
现在,我们已经找到了最佳的对象检测神经网络(就速度/质量而言),让我们最后继续探讨如何在视频帧之间关联特定YOLO对象的信息。程序如何理解前一帧中的人与新帧中的人相同?
深层排序
要了解这项技术,您必须首先了解几个数学方面-Mahalonobis距离和Kalman滤波器。
马氏距离我们来看
一个非常简单的例子,以直观地理解马氏距离是什么以及为什么需要它。许多人可能知道欧几里得距离是多少。通常,这是在欧几里得空间中从一个点到另一个点的距离:
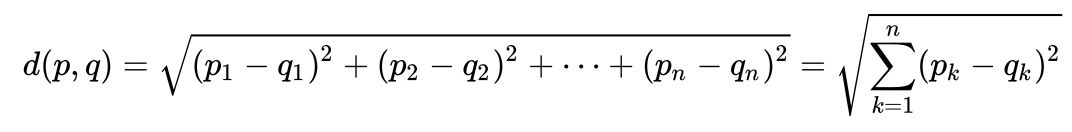

假设我们有两个变量-X1和X2。对于他们每个人,我们都有许多维度。
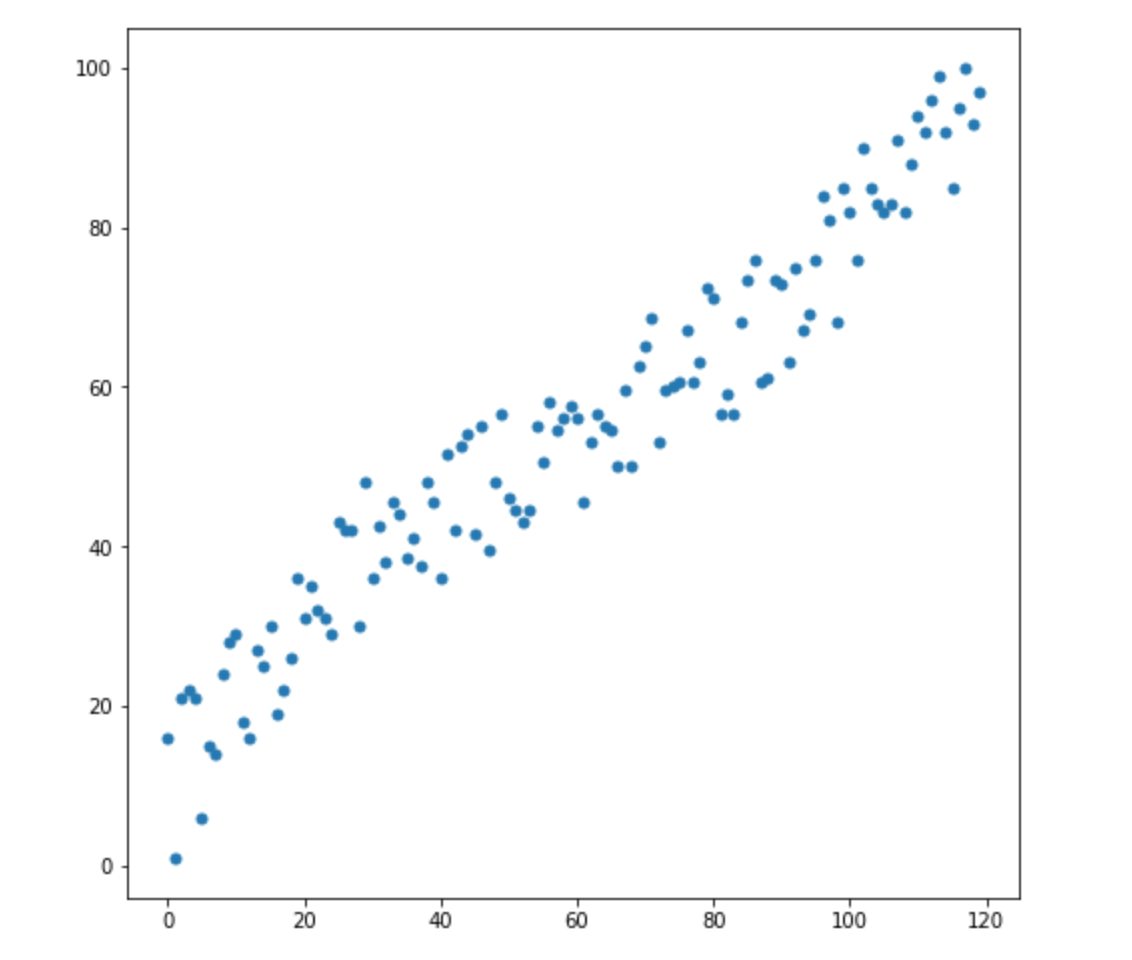
现在,我们有2个新维度:
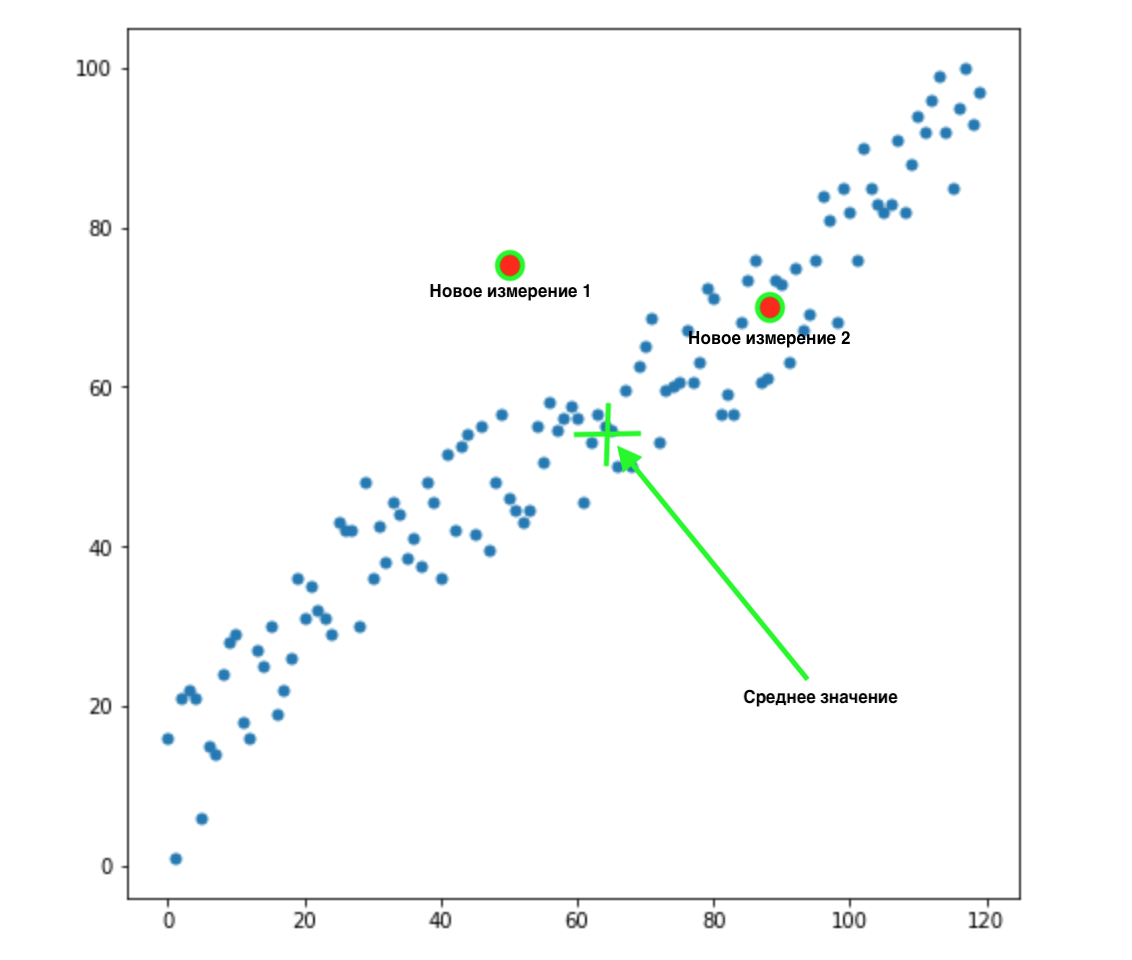
我们怎么知道这两个值中的哪一个最适合我们的分布?一切都是显而易见的-第2点适合我们。但是两个点到均值的欧几里得距离是相同的。因此,到均值的简单欧几里得距离对我们不起作用。
从上图可以看出,变量之间具有很强的相关性。如果它们彼此不相关或相关性更小,我们可以闭上眼睛,对某些任务应用欧几里得距离,但是在这里我们需要校正相关性并考虑在内。
Mahalonobis的距离正好可以解决这个问题。由于数据集中通常有两个以上的变量,因此我们将使用协方差矩阵而不是相关性:
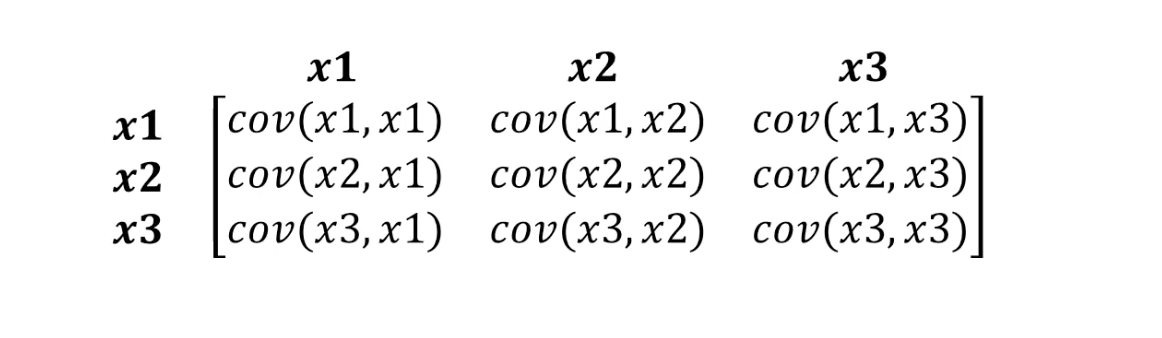
马氏距离实际上是做什么的:
- 摆脱变量协方差
- 使变量的方差等于1
- 然后,它将通常的欧几里德距离用于转换后的数据。
让我们看一下如何计算马氏距离的公式:

让我们看看公式中各成分的含义:
- 这种差异是我们的新观点与每个变量的均值之间的差异。
- S是我们之前讨论的协方差矩阵。
从公式中可以理解很重要的一点。实际上,我们乘以倒数协方差矩阵。在这种情况下,变量之间的相关性越高,我们越可能缩短距离,因为我们将乘以较大值的倒数,即较小的数字(如果用简单的话)。
我们可能不会讨论线性代数的细节,我们需要了解的是,我们以考虑变量的方差和变量之间的协方差的方式来测量点之间的距离。
卡尔曼滤波器
要意识到这是一件很酷的,经过验证的产品,可以在许多领域中使用,只需知道卡尔曼滤波器是在1960年代使用的就足够了。是的,是的,我在暗示这一点-飞往月球。它已在多个地方应用,包括使用往返飞行路径。卡尔曼滤波器还经常用于金融市场的时间序列分析,工厂,企业和许多其他地方的各种传感器的指标分析中。希望我能引起您的兴趣,我们将简要介绍卡尔曼滤波器及其工作原理。如果您想了解更多有关哈伯的信息,我也建议您阅读此文章。
卡尔曼滤波器
, . , , .
, . 4 . , 72 .
3 :
1) (Kalman Gain):

, - ( ).
2) , ( , ), , .

3) (), :
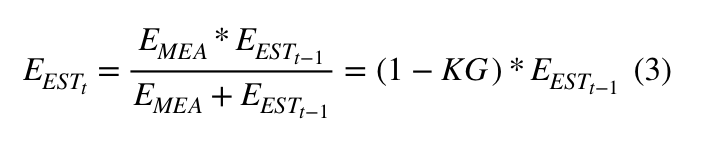
, :
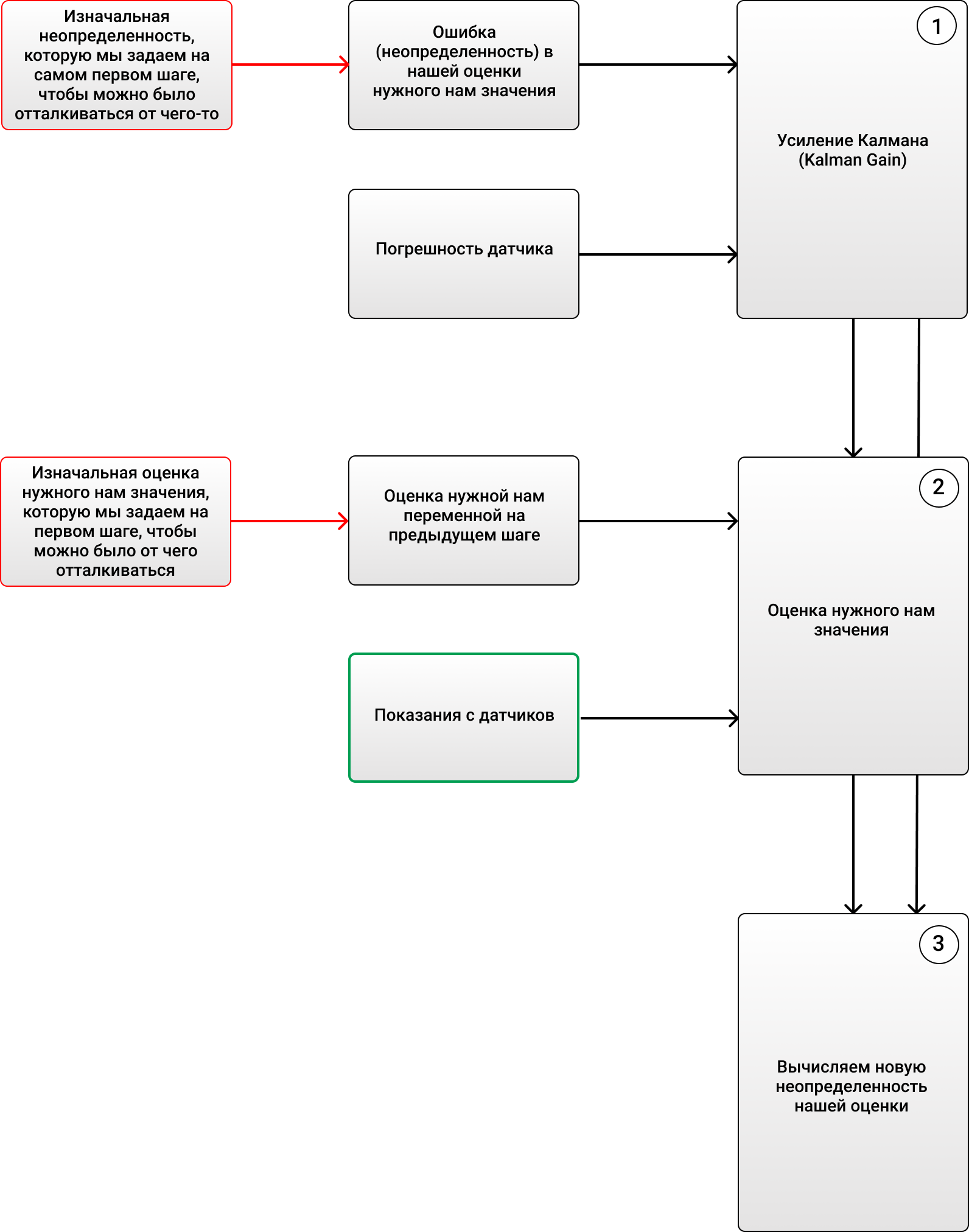
, 69 ( ), 2 . , , 4 (, , ), KG (1) 2/(2+4) = 0.33. ( ), . 70 (), . (2), , 68+0.33(70-68)=68.66. (3) (1-0.33)2 = 1.32. , , , . :
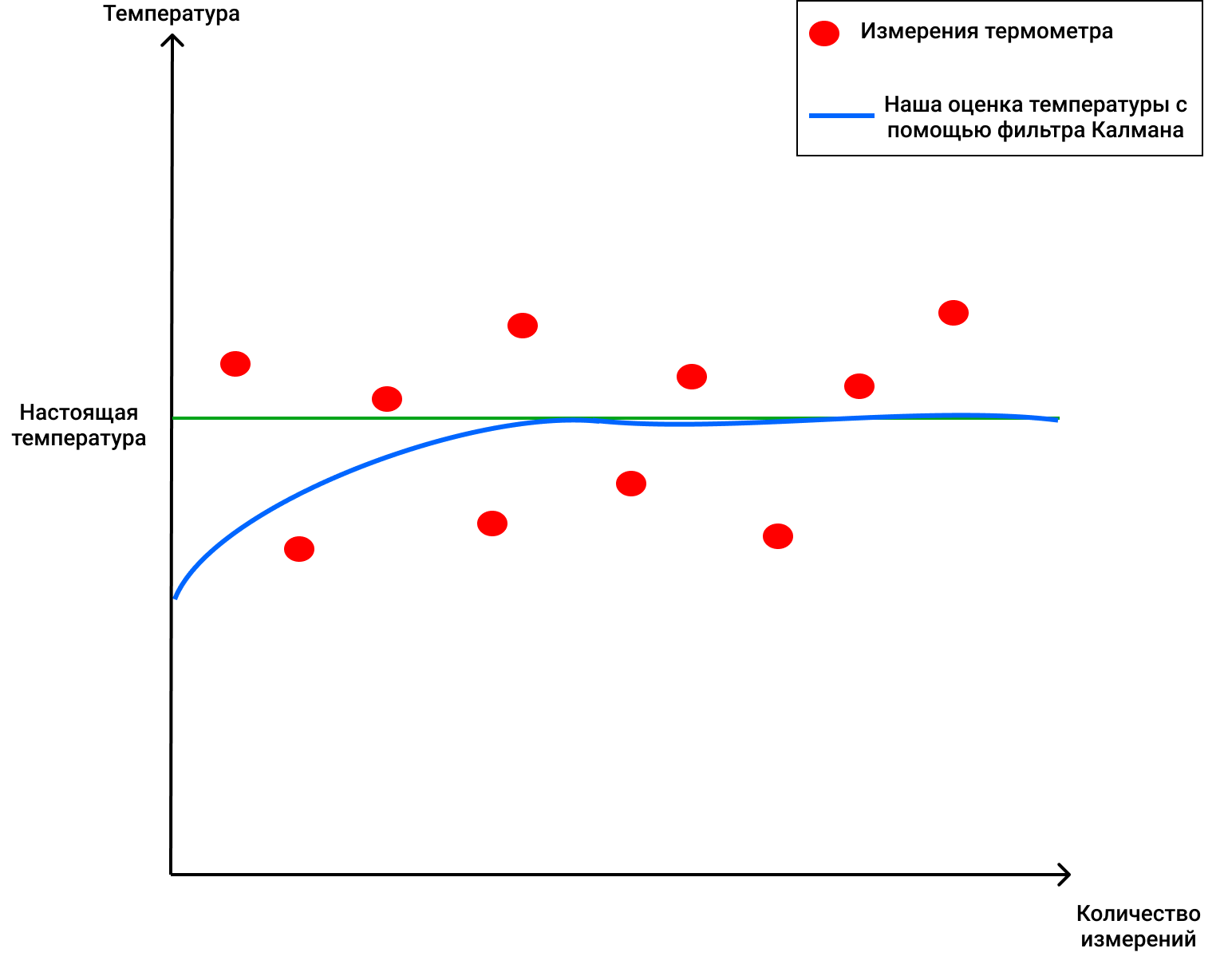
, !
, , , , , ( , ).
, . 4 . , 72 .
3 :
1) (Kalman Gain):
, - ( ).
2) , ( , ), , .
3) (), :
, :
, 69 ( ), 2 . , , 4 (, , ), KG (1) 2/(2+4) = 0.33. ( ), . 70 (), . (2), , 68+0.33(70-68)=68.66. (3) (1-0.33)2 = 1.32. , , , . :
, !
, , , , , ( , ).
DeepSORT-终于!
因此,我们现在知道卡尔曼滤波器和马哈洛诺比斯距离。 DeepSORT技术将这两个概念简单地链接在一起,以便将信息从一帧传输到另一帧,并添加了一个称为外观的新指标。首先,使用对象检测来确定一个边界框的位置,大小和类别。然后,原则上,您可以应用匈牙利算法将某些对象与先前在框架上并使用卡尔曼过滤器进行跟踪的对象ID相关联-就像原始SORT中的一切一样,它们将是超级的...但是,DeepSORT技术可以提高检测精度并减少对象之间的切换次数,例如,当帧中的一个人短暂地阻塞了另一个人,而现在被阻塞的人被视为一个新对象时。她是怎么做到的?
她为她的作品添加了一个很酷的元素-出现在框架中的人的所谓“外观”(外观)。这种外观是由DeepSORT的作者创建的一个单独的神经网络训练的。他们使用了来自1000多个不同人的大约1,100,000张图片,以使神经网络正确预测。原始的SORT存在一个问题-由于此处未使用对象的外观,因此,实际上,当对象覆盖多个框架(例如,另一个人或建筑物内的一列)时,该算法将为该人分配另一个ID-结果因此,原始SORT中对象的所谓“内存”是短暂的。
因此,现在对象具有两个属性-运动的动力学和外观。对于动力学,我们具有使用卡尔曼滤波器过滤和预测的指标-(u,v,a,h,u',v',a',h'),其中u,v是预测矩形的X位置, Y,a是预测矩形的长宽比,h是矩形的高度,以及相对于每个值的导数。为了外观,训练了一个神经网络,其结构如下:
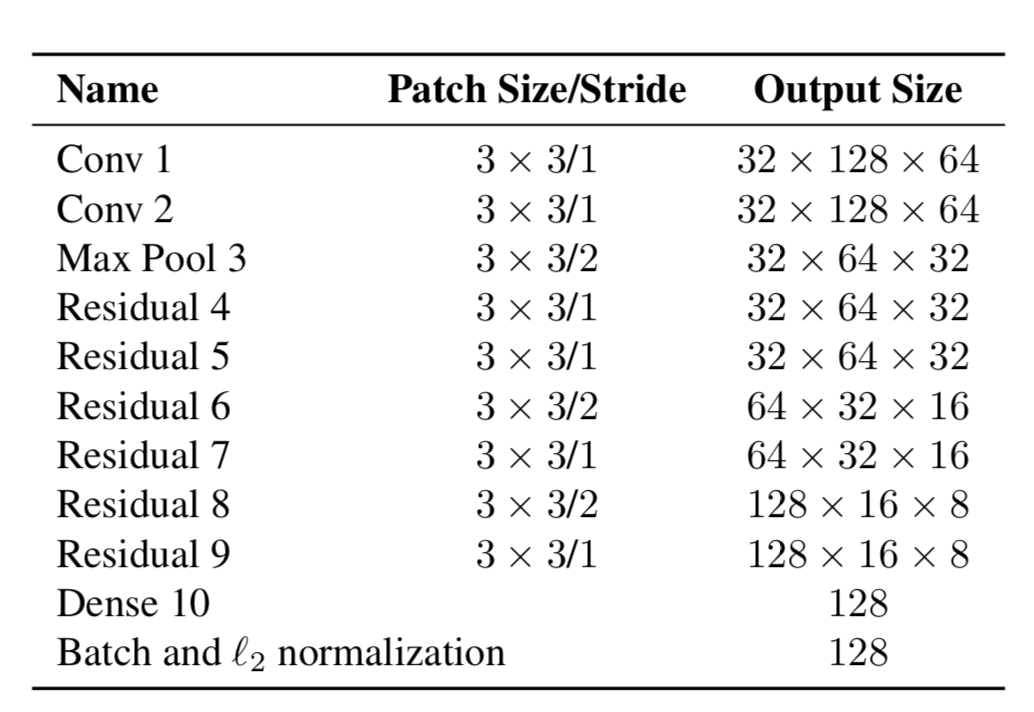
最后,它产生了一个特征向量,大小为128x1。然后,作者创建了一个新的度量标准来计算距离,而不是使用YOLO计算某些对象与我们已经在框架中跟随的对象之间的距离,然后仅使用Mahalonobis距离分配特定ID。这两种预测均使用卡尔曼滤波器进行,还有“余弦距离”(否则称为Otiai系数)。
结果,从某个YOLO对象到由卡尔曼滤波器预测的对象(或已经在之前的帧中观察到的对象中)的距离为:

其中Da是外部相似距离,Dk是Mahalonobis距离。此外,在匈牙利算法中使用了此混合距离,以便正确地对具有现有ID的某些对象进行排序。
因此,一个简单的附加度量Da有助于创建一种新的,优雅的DeepSORT算法,该算法可用于许多问题,并且在对象跟踪问题中非常流行。
感谢那些读到最后的人,这篇文章非常重要!希望我能告诉您一些新知识,并帮助您了解对象跟踪在YOLO和DeepSORT上的工作方式。