所有实现都在一个头文件.h文件中:[fast_mem_pool.h]
芯片,为什么此分配器比数百个类似的分配器要好-削减了。
这就是我的自行车的工作方式。
1)在Release版本中,没有互斥体,也没有原子的等待周期-但是分配器是循环的,并在线程释放资源时不断重新生成资源。他是怎么做到的?
FastMemPool通过fmalloc分配的RAM分配实际上对于一个标头来说更多:
struct AllocHeader {
// : tag_this = this + leaf_id
uint64_t tag_this { 2020071700 };
// :
int size;
// :
int leaf_id { -2020071708 };
};
通过从指针(res_ptr)sizeof(AllocHeader)倒退,始终可以从用户拥有的指针中获取此标头:

通过AllocHeader标头的内容,ffree(void * ptr)方法识别其分配并找出返回圆形缓冲存储器的哪几页:
void ffree(void *ptr)
{
char *to_free = static_cast<char *>(ptr)
- sizeof(AllocHeader);
AllocHeader *head = reinterpret_cast<AllocHeader *>(to_free);
当要求分配器分配内存时,它会查看工作表数组中的当前工作表,以查看是否可以切断所需的大小+标头sizeof(AllocHeader)的大小。
在分配器中,Leaf_Cnt内存表被预先保留,每个表的大小为Leaf_Size_Bytes(此处一切都是传统的)。为了寻找分配机会,fmalloc(std :: size_tlocation_size)方法将在leaf_array数组的叶子上循环,如果所有地方都很忙,则在启用Do_OS_malloc标志的情况下,它将从操作系统获取的内存大于sizeof(AllocHeader)所需的大小-外部内存是从内部循环缓冲区或OS中获取的,分配器始终创建带有服务信息的标头。如果分配器的内存不足并且Do_OS_malloc == false标志,则fmalloc将返回nullptr-此行为对于控制负载很有用(例如,当帧处理模块无法跟上摄像机的FPS时,请跳过摄像机的帧)。
如何实施循环
循环分配器设计用于循环任务-任务不应永远持续下去。例如,可以是:
- 用户会话分配
- 处理视频流帧以进行视频分析
- 游戏中战斗部队的生活
由于leaf_array数组中可以有任意数量的存储表,因此在极限情况下可以为游戏中理论上可能的战斗单元数创建一个页面,因此在单元丢失的情况下,我们可以保证获得免费的存储表。实际上,对于视频分析来说,通常我需要16张大纸,当初始化检测器时,其中的前几张纸将捐赠给长期的非循环分配。
如何实现线程安全
分配表的数组没有互斥量。...针对“数据争用”类型的错误的保护措施如下:
char *buf;
// available == offset
std::atomic<int> available { Leaf_Size_Bytes };
// allocated ==
std::atomic<int> deallocated { 0 };
每个内存表都有2个计数器:
-可用Leaf_Size_Bytes的大小初始化。每次分配时,此计数器都会减少,并且相同的计数器将用作相对于内存工作表开头的偏移量==从缓冲区末尾开始分配内存:
result_ptr = leaf_array[leaf_id].buf + available_after;
-释放的初始化为{0}为零,并且在该工作表上的每个释放(我从AllocHeader了解到要在哪个工作表或OS上处理)后,计数器都会按释放的数量增加:
const int deallocated = leaf_array[head->leaf_id].deallocated.fetch_add(real_size, std::memory_order_acq_rel) + real_size;
一旦这样的计数器(已释放的==(Leaf_Size_Bytes-可用))匹配,这意味着已分配的所有内容现在都已释放,您可以将叶子重置为其原始状态,但这是一个微妙的地方:如果在决定重置叶子之后会发生什么回到原始状态,有人从工作表中分配了另一小块内存。要排除此情况,请使用compare_exchange_strong检查:
if (deallocated == (Leaf_Size_Bytes - available))
{ // ,
// , , Leaf
if (leaf_array[head->leaf_id].available
.compare_exchange_strong(available, Leaf_Size_Bytes))
{
leaf_array[head->leaf_id].deallocated -= deallocated;
}
}
仅当在复位时保持可用计数器的相同状态(即在决定时)时,才将存储表复位到其初始状态。塔达!
一个不错的好处是,您可以使用每个分配的AllocHeader标头捕获以下错误:
- 重新分配
- 释放别人的记忆
- 缓冲区溢出
- 访问其他人的存储区
在这些机会上实现第二个功能。
2) Debug编译提供了在重定位期间先前取消分配的确切信息:文件名,代码行号,方法名。这是通过围绕基本方法的装饰器形式实现的(fmallocd,ffreed,check_accessd-方法的调试版本在末尾带有d):
/**
* @brief FFREE - free
* @param iFastMemPool - FastMemPool
* @param ptr - fmaloc
*/
#if defined(Debug)
#define FFREE(iFastMemPool, ptr) \
(iFastMemPool)->ffreed (__FILE__, __LINE__, __FUNCTION__, ptr)
#else
#define FFREE(iFastMemPool, ptr) \
(iFastMemPool)->ffree (ptr)
#endif
使用预处理器宏:
- __FILE__-C ++源文件
- __LINE__-C ++源文件中的行号
- __FUNCTION__-发生此情况的函数的名称
此信息作为分配指针与分配信息之间的对应关系存储在介体中:
struct AllocInfo {
// : , , :
std::string who;
// true - , false - :
bool allocated { false };
};
std::map<void *, AllocInfo> map_alloc_info;
std::mutex mut_map_alloc_info;
由于速度对于调试不是很重要,因此使用了互斥锁来保护标准std :: map。模板参数(布尔Raise_Exeptions = DEF_Raise_Exeptions)影响是否在错误时引发异常。
对于那些希望在Release版本中获得最大舒适度的用户,可以设置DEF_Auto_deallocate标志,然后将写入所有OS malloc分配(已经在std :: set <>中的互斥锁下)并在FastMemPool析构函数中释放(用作分配跟踪器)。
3)为了避免出现诸如“缓冲区溢出”之类的错误,我建议在开始使用分配的内存之前使用FastMemPool :: check_access检查。虽然操作系统仅在您进入其他人的RAM时抱怨,但check_access函数(或FCHECK_ACCESS宏)通过AllocHeader标头计算给定分配是否溢出:
/**
* @brief check_access -
* @param base_alloc_ptr - FastMemPool
* @param target_ptr -
* @param target_size - ,
* @return - true FastMemPool
*/
bool check_access(void *base_alloc_ptr, void *target_ptr, std::size_t target_size)
// :
if (FCHECK_ACCESS(fastMemPool, elem.array,
&elem.array[elem.array_size - 1], sizeof (int)))
{
elem.array[elem.array_size - 1] = rand();
}
知道了初始分配的指针后,您总是可以获取标头,从标头中找出分配的大小,然后计算目标元素是否在初始分配内。在开始处理周期之前,以理论上最大的可能访问次数检查一次就足够了。极限值很可能会突破分配边界(例如,在计算中,由于过程的物理性,假设某些变量只能在一定范围内移动,因此您无需检查打破分配边界)。
检查一次总比杀死一个星期后偶尔发现有人向您的结构偶尔写入随机数据的人要好
。4)在编译时通过CMake设置默认模板代码。
CmakeLists.txt包含可配置的参数,例如:
set(DEF_Leaf_Size_Bytes "65536" CACHE PATH "Size of each memory pool leaf")
message("DEF_Leaf_Size_Bytes: ${DEF_Leaf_Size_Bytes}")
set(DEF_Leaf_Cnt "16" CACHE PATH "Memory pool leaf count")
message("DEF_Leaf_Cnt: ${DEF_Leaf_Cnt}")
这使得在QtCreator:

或CMake GUI中编辑参数非常方便:

然后在编译过程中将参数传递给代码,如下所示:
set(SPEC_DEFINITIONS
${CMAKE_SYSTEM_NAME}
${CMAKE_BUILD_TYPE}
${SPEC_BUILD}
SPEC_VERSION="${Proj_VERSION}"
DEF_Leaf_Size_Bytes=${DEF_Leaf_Size_Bytes}
DEF_Leaf_Cnt=${DEF_Leaf_Cnt}
DEF_Average_Allocation=${DEF_Average_Allocation}
DEF_Need_Registry=${DEF_Need_Registry}
)
#
target_compile_definitions(${TARGET} PUBLIC ${TARGET_DEFINITIONS})
并在代码中覆盖默认值中的模板值:
#ifndef DEF_Leaf_Size_Bytes
#define DEF_Leaf_Size_Bytes 65535
#endif
template<int Leaf_Size_Bytes = DEF_Leaf_Size_Bytes,
int Leaf_Cnt = DEF_Leaf_Cnt,
int Average_Allocation = DEF_Average_Allocation,
bool Do_OS_malloc = DEF_Do_OS_malloc,
bool Need_Registry = DEF_Need_Registry,
bool Raise_Exeptions = DEF_Raise_Exeptions>
class FastMemPool
{
// ..
};
因此,可以通过打开/关闭CMake参数的复选框,用鼠标舒适地调整分配器模板。
5)为了能够在同一.h文件的STL容器中使用分配器,在FastMemPoolAllocator模板中部分实现了std :: allocator的功能:
// compile time :
std::unordered_map<int, int, std::hash<int>,
std::equal_to<int>,
FastMemPoolAllocator<std::pair<const int, int>> > umap1;
// runtime :
std::unordered_map<int, int> umap2(
1024, std::hash<int>(),
std::equal_to<int>(),
FastMemPoolAllocator<std::pair<const int, int>>());
可以在此处找到用法示例:test_allocator1.cpp和test_stl_allocator2.cpp。
例如,构造函数和析构函数在分配上的工作:
bool test_Strategy()
{
/*
* Runtime
* ( )
*/
using MyAllocatorType = FastMemPool<333, 33>;
// instance of:
MyAllocatorType fastMemPool;
// inject instance:
FastMemPoolAllocator<std::string,
MyAllocatorType > myAllocator(&fastMemPool);
// 3 :
std::string* str = myAllocator.allocate(3);
// :
myAllocator.construct(str, "Mother ");
myAllocator.construct(str + 1, " washed ");
myAllocator.construct(str + 2, "the frame");
//-
std::cout << str[0] << str[1] << str[2];
// :
myAllocator.destroy(str);
myAllocator.destroy(str + 1);
myAllocator.destroy(str + 2);
// :
myAllocator.deallocate(str, 3);
return true;
}
6)有时,在大型项目中,您需要制作某种模块,并对其进行全面测试-它的工作原理类似于瑞士手表。您的模块已包含在“检测器”中,进行了战斗-有时,每天一次,库开始陷入垃圾堆。在调试器上运行转储,您发现在指针的循环遍历之一而不是nullptr中,有人将8写入了指针-通过转到该指针,您自然会激怒操作系统。
我们如何缩小可能的罪魁祸首的范围?将您的建筑物从犯罪嫌疑人中排除非常简单-必须将它们移至RAM的另一个位置(破坏者不炸弹的地方):
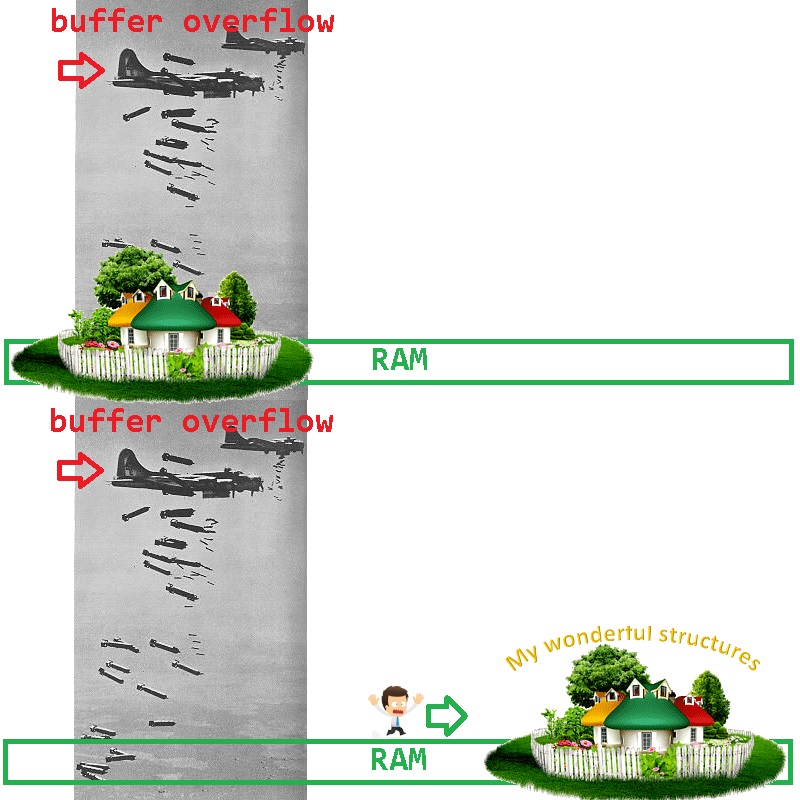
如何使用FastMemPool轻松完成此操作?这很简单:在FastMemPool中,分配是通过从内存页面的末尾开始进行的-通过请求一个比工作所需更多的内存页面,您可以确保内存页面的开头仍然是越野轰炸的试验场。例如:
FastMemPool<100000000, 1, 1024, true, true> bulletproof_mempool;
void *ptr = bulletproof_mempool.fmalloc(1234567);
// ..
// - c ptr
// ..
bulletproof_mempool.ffree(ptr);
如果在新的地方有人在轰炸您的建筑物,那么很可能是您自己...
否则,如果图书馆稳定下来,团队将立即收到几笔礼物:
- 您的算法再次像瑞士手表一样工作
- 一个有故障的编码器现在可以安全地轰炸一个空的存储区域(每个人都在寻找它),库是稳定的。
- 可以监视轰炸范围以更改内存-以便在越野车编码器上设置陷阱。
总体而言,这款特殊自行车的优点是:
- ( / )
- , Debug ,
- , /
- , ( nullptr), — , ( FPS , FastMemPool -).
在我们公司中,安装金属板的3D几何分析需要对视频帧(50FPS)进行多线程处理。图纸通过相机下方,并在激光的反射下建立图纸的3D地图。 FastMemPool用于确保最大的内存速度和安全性。如果流无法处理传入的帧,则以常规方式保存帧以供将来处理时,会导致RAM的消耗不受控制。使用FastMemPool时,如果发生溢出,则将在分配过程中简单地返回nullptr并将跳过该帧-在最终的3D图像中,这种在步骤中以跳跃形式出现的缺陷表明有必要在处理中添加CPU线程。
具有循环内存分配器和任务堆栈的线程的无互斥量操作使得可以非常快速地处理传入的帧,而不会丢失帧且不会导致RAM溢出。现在,此代码在AMD Ryzen 9 3950X CPU上的16个线程中运行,在FastMemPool类中没有发现故障。
可以在源代码test_memcontrol1.cpp中看到带有RAM溢出控制的视频分析过程的简化示例图。
对于甜点:在相同的示例方案中,使用非互斥堆栈:
using TWorkStack = SpecSafeStack<VideoFrame>;
//..
// Video frames exchanger:
TWorkStack work_stack;
//..
work_staff->work_stack.push(frame);
//..
VideoFrame * frame = work_staff->work_stack.pop();
gihub上 有一个包含所有消息源的可运行演示台。