
我一直着迷于系统故障及其行为的怪异之处,尤其是当它们在正常条件下运行时。最近,我在Ian Goodfellow的演示文稿中看到了一张幻灯片,觉得很有趣。随机的视觉噪声被馈送到训练有素的神经网络,她将其识别为她知道的物体之一。这里立即出现许多问题。不同训练有素的神经网络会看到相同的物体吗?神经网络对该随机噪声确实是可识别对象的最大置信度是多少?神经网络实际上在那里看到了什么?
由于我对此的好奇心,此条目诞生了。幸运的是,使用PyTorch可以轻松进行此类实验。... 为了可视化为什么神经网络以某种方式对对象进行分类,我使用了Captum模型可解释性框架。可以从Github下载该代码。
问题的重要性
您可能会问为什么这些问题很重要。在许多情况下,开发人员不会从头开始构建模型。他们从模型动物园中选择平台和预先训练的网络作为起点。这样可以节省时间-您无需收集数据并进行神经网络的初始训练。但是,这也意味着在意想不到的地方可能会出现意想不到的问题。根据使用此模型的方式,过程中可能会出现安全问题。
预训练模型
预训练的模型易于入门,可以快速提交数据进行分类。在这种情况下,您无需定义模型并进行训练-所有这些都已经在您完成之前完成,并且可以在部署后立即使用。从Torchvision库预训练的模型被训练从一组图像Imagenet数据库,分为1000类...重要的是要记住,该培训涉及识别图片中的单个对象,而不是解析包含各种对象的复杂图像。在第二种情况下,您也可以获得有趣的结果,但这是一个完全不同的主题。从Torchvision库下载经过预训练的模型非常容易。您只需要通过将预训练参数设置为True来导入所选模型。我还在模型中包括了评估模式,因为测试过程中没有学习曲线。
首先,我有一行代码选择使用cuda或cpu,这取决于GPU是否可用。对于这种简单的测试,不需要GPU,但是由于我有一个,所以我使用它。
device = "cuda" if torch.cuda.is_available() else "cpu"
import torchvision.models as models
vgg16 = models.vgg16(pretrained=True)
vgg16.eval()
vgg16.to(device)
可在此处找到Torchvision的预训练模型列表。我不想使用所有预先训练的神经网络,这已经太多了。我选择了以下五个:
- vgg16
- 网路18
- 亚历克斯网
- 密集网
- 起始
我没有使用任何特殊的方法来选择神经网络。例如,Vgg16和Inception通常在不同的示例中使用,并且都不同。
如何创建带有噪点的图像
我们将需要一种自动生成包含噪声的图像的方法,该图像可以馈入神经网络。为此,我结合使用了Numpy库和PIL库,并编写了一个小函数来返回充满随机噪声的图像。
import numpy as np
from PIL import Image
def gen_image():
image = (np.random.standard_normal([256, 256, 3]) * 255).astype(np.uint8)
im = Image.fromarray(image)
return im
您最终会得到如下内容:

转换影像
之后,我们需要将图像转换为张量并将其标准化。以下代码不仅可以用于随机噪声,还可以用于我们想要馈入预训练的神经网络的任何图像(这就是代码使用Resize和CenterCrop值的原因)。
def xform_image(image):
transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
new_image = transform(image).to(device)
new_image = new_image.unsqueeze_(0)
return new_image我们得到预测
准备好转换后的图像后,很容易从展开的模型中获得预测。在这种情况下,假定xform_image函数返回image_xform。在我用于测试的代码中,我将工作分解为这两个功能,但是在这里我将它们放在一起以方便参考。我们本质上需要将转换后的图像馈送到网络,运行softmax函数,使用topk函数获得分数,并获得最佳结果的预测标签ID。
with torch.no_grad():
vgg16_res = vgg16(image_xform)
vgg16_output = F.softmax(vgg16_res, dim=1)
vgg16score, pred_label_idx = torch.topk(vgg16_output, 1)
结果
好了,现在我们看看如何生成嘈杂的图像并将其馈送到预先训练的网络。那么结果如何呢?对于此测试,我决定生成1000张带噪图像,通过5个选定的经过预训练的网络运行它们,并将其填充到Pandas数据框中以进行快速分析。结果很有趣,有些出乎意料。
| vgg16 | 网路18 | 亚历克斯网 | 密集网 | 起始 | |
|---|---|---|---|---|---|
| 计数 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 |
| 意思 | 0.226978 | 0.328249 | 0.147289 | 0.409413 | 0.020204 |
| 性病 | 0.067972 | 0.071808 | 0.038628 | 0.148315 | 0.016490 |
| 分 | 0.074922 | 0.127953 | 0.061019 | 0.139161 | 0.005963 |
| 25% | 0.178240 | 0.278830 | 0.120568 | 0.291042 | 0.011641 |
| 50% | 0.223623 | 0.324111 | 0.143090 | 0.387705 | 0.015880 |
| 75% | 0.270547 | 0.373325 | 0.171139 | 0.511357 | 0.022519 |
| 最高 | 0.438011 | 0.580559 | 0.328568 | 0.868025 | 0.198698 |
如您所见,某些神经网络已确定该噪声实际上代表着相当高的置信度。 Resnet18和densitynet均达到50%的峰值。一切都很好,但是这些网络在噪声中究竟能“看到”什么?有趣的是,不同的网络在那里“找到”了不同的对象。 每个网络看到的都是不同的东西。 Resnet18 100%地确定它是水母,相反,Inception对预测的信心很小,尽管与此同时,她看到的物体比其他任何网络都要多。
Vgg16:
978
14
7
1
Resnet18:
1000
Alexnet:
942
58
Densenet:
893
37
33
20
16
1
Inception:
155
123
102
85
83
81
69
32
26
25
24
18
16
16
12
12
11
9
9
8
7
5
5
5
- 5
4
4
4
4
3
3
3
3
3
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
只是为了好玩,我决定看看微软将在噪点图像下添加什么样的签名,我将它带到了本文的开头。对于测试,我决定采用最简单的方法,并从Office 365中使用PowerPoint。结果很有趣,因为不同于试图识别单个对象的imagenet模型,PowerPoint试图识别多个对象以创建图像的准确描述。
该图显示了大象,人,大的球。
结果并没有让我失望。从我的角度来看,噪音的图像被认为是马戏团。
观点
这引出了另一个问题-神经网络看到了什么,使其认为噪声是物体?在寻找答案时,我们可以使用模型解释工具,该工具将使我们能够大致了解网络“所见”。 Captum是PyTorch的模型解释框架。我在这里没有做任何特别的事情,我只是使用了他们网站上教程中的代码。我刚刚添加了internal_batch_size参数,其值为50,因为没有它,我的GPU很快就会耗尽内存。
对于可视化,我使用了两个基于梯度的归因和一个基于遮挡的归因。通过这些可视化,我们尝试了解对分类器而言重要的内容,因此可以“看到”网络看到的内容。我还使用了预先训练的resnet模型,但是您可以更改代码并使用任何其他预先训练的模型。
在进入噪声之前,我以洋甘菊的图像作为渲染过程的演示,因为它的标志很容易识别。
result = resnet18(image_xform)
result = F.softmax(result, dim=1)
score, pred_label_idx = torch.topk(result, 1)
integrated_gradients = IntegratedGradients(resnet18)
attributions_ig = integrated_gradients.attribute(image_xform, target=pred_label_idx,
internal_batch_size=50, n_steps=200)
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(image_xform, n_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx, internal_batch_size=50)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)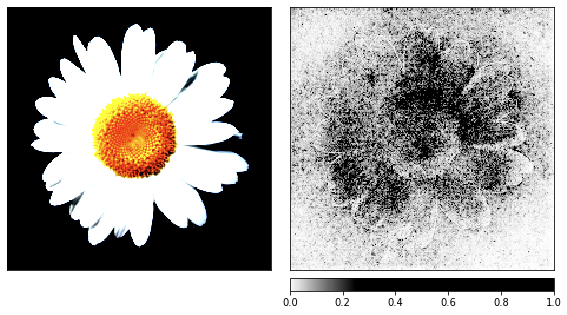
occlusion = Occlusion(resnet18)
attributions_occ = occlusion.attribute(image_xform,
strides = (3, 8, 8),
target=pred_label_idx,
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
show_colorbar=True,
outlier_perc=2,
)

噪声可视化
我们基于洋甘菊生成了以前的图像,现在是时候看看事物如何在随机噪声下工作。
我正在使用经过预训练的resnet18网络,使用此图像,她可以确定自己看到水母40%。我不会重复该代码,用于渲染的代码与上面给出的代码相同。


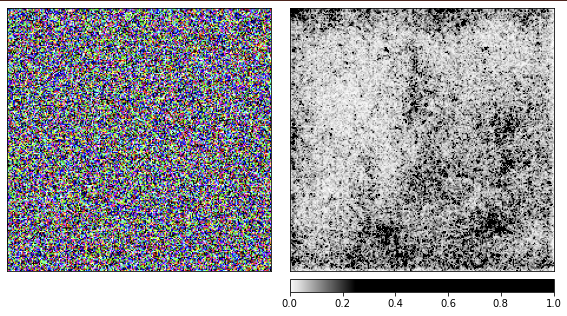

从可视化中可以明显看出,我们人类永远无法理解为什么网络在这里看到水母。图像的某些区域被标记为更重要,但它们根本不像我们在洋甘菊示例中看到的那样定义。与洋甘菊不同,水母是无定形的,透明度不同。
您可能想知道处理水母真实图像的渲染效果如何?我的代码发布在Github上,借助它的帮助,很容易找到该问题的答案。
结论
根据此记录,很容易看到通过向神经网络提供意外的输入来使其变得愚蠢。值得称赞的是,我们会说他们做了自己的工作,并尽了最大的努力。从工作结果还可以看出,在这种情况下仅靠低置信度过滤掉选项是不够的,因为某些选项具有很高的置信度。我们需要警惕现实世界中的系统如此容易失效的情况。进入系统的意外数据不应令我们感到惊讶-这是安全专家已经进行了相当长的时间了。