我目前在ManyChat工作。实际上,这是一家初创公司-新兴,雄心勃勃且发展迅速。当我刚进入公司时,出现了一个经典的问题:“一个年轻的创业公司现在应该从DBMS和数据库市场中拿走什么?”
在本文中,基于我在RIT ++ 2020在线音乐节上的讲话,我将回答这个问题。该报告的视频版本可在YouTube上获得。
2020年知名数据库
到了2020年,我环顾四周,看到了三种类型的数据库。
第一种是经典的OLTP数据库:PostgreSQL,SQL Server,Oracle,MySQL。它们是很久以前写的,但是仍然有用,因为它们对开发人员社区很熟悉。
第二种类型-从“零”开始。他们试图通过添加内联分片和其他吸引人的功能来摆脱SQL,传统结构和ACID,从而摆脱传统模式。例如,这些是Cassandra,MongoDB,Redis或Tarantool。所有这些解决方案都希望从根本上为市场提供一些新产品并占据其利基市场,因为在某些任务中,它们被证明非常方便。这些基础将由总称NOSQL表示。
从零开始,“零”结束了,他们已经习惯了NOSQL数据库,从我的角度来看,世界已经迈出了下一步-托管数据库。这些数据库与经典OLTP数据库或新的NoSQL数据库具有相同的核心。但是他们不需要DBA和DevOps,它们可以在云中的托管硬件上运行。对于开发人员来说,这只是在某些地方起作用的“基础”,但是,如何在服务器上安装它,如何配置服务器以及谁对其进行更新,无人问津。
此类基础的示例:
- AWS RDS是PostgreSQL / MySQL的托管包装。
- DynamoDB是基于文档的数据库的AWS类似物,类似于Redis和MongoDB。
- Amazon Redshift是托管分析基础。
从根本上讲,这些都是古老的基础,但是可以在托管环境中进行升级,而无需使用硬件。
注意。这些示例适用于AWS环境,但它们的对应版本也存在于Microsoft Azure,Google Cloud或Yandex.Cloud中。

那么什么是新的?在2020年,这些都不是。
无服务器概念
无服务器或无服务器解决方案是2020年市场上真正真正的新功能。
我将使用常规服务或后端应用程序的示例来解释这意味着什么。
要部署常规后端应用程序,我们购买或租用服务器,将代码复制到该服务器,在外部发布端点,并定期支付租金,电费和数据中心服务费用。这是标准布局。
还有其他办法吗?借助无服务器服务,您可以。
这种方法的重点是:没有服务器,云中甚至没有虚拟实例租约。要部署服务,请将代码(功能)复制到存储库,然后将端点发布到外部。然后,我们只需为每次调用此函数付费,而完全忽略了执行该函数的硬件。
我将尝试在图片中说明这种方法。
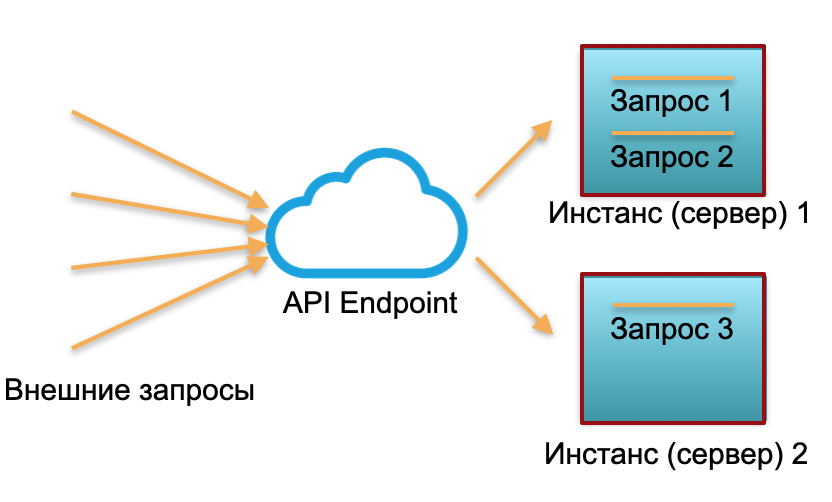
经典部署。我们有一定负载的服务。我们提出了两个实例:物理服务器或AWS中的实例。外部请求将发送到这些实例并在那里进行处理。
如您在图片中看到的,服务器的使用方式不同。一个是100%的利用率,有两个请求,一个只有50%的部分空闲。如果不是三个请求,而是三个,那么整个系统将无法应付负载,并且将开始变慢。

无服务器部署...在无服务器环境中,此类服务没有实例或服务器。这里有大量的热身资源-带有部署功能代码的小型预备Docker容器。系统接收外部请求,无服务器框架为每个请求创建一个带有代码的小容器:它处理此特定请求并杀死该容器。
一个请求-一个提升的容器,1000个请求-1000个容器。在铁服务器上进行部署已经是云提供商的工作。它由无服务器框架完全隐藏。在这个概念中,我们为每次通话付费。例如,一天打来一个电话-我们为一个电话付费,一分钟打了一百万个电话-我们为一百万付费。或在一秒钟内,这也会发生。
发布无服务器功能的概念适用于无状态服务。并且,如果您需要(状态)全状态服务,则将数据库添加到该服务。在这种情况下,当涉及到使用状态和状态时,每个statefull函数都会简单地从数据库中写入和读取数据。此外,从本文开头描述的三种类型中的任何一种的数据库中获取。
所有这些基础的共同限制是什么?这些是经常使用的云或铁服务器(或多台服务器)的成本。无论我们使用经典数据库还是托管数据库,是否有Devops和管理员,都没有关系,我们仍需支付24/7的硬件,电力和数据中心租金。如果我们有一个经典的基础,我们将为主人和奴隶付费。如果分片库负载很高-我们为10、20或30台服务器付费,并且我们不断付款。
在成本结构中永久保留服务器的存在以前被认为是必不可少的。普通数据库还存在其他困难,例如连接数限制,扩展限制,地理分布共识-它们可以在某些数据库中以某种方式解决,但不是一次就能解决,也不是很理想。
无服务器数据库-理论
2020问题:数据库也可以做成无服务器吗?每个人都听说过无服务器后端……但是让我们也尝试使数据库也无服务器吗?
这听起来很奇怪,因为数据库是有状态的服务,不适用于无服务器基础架构。同时,数据库的状态非常大:分析数据库中的千兆字节,太字节甚至PB级。将其提升到轻量级Docker容器中并非易事。
另一方面,几乎所有现代数据库都是大量的逻辑和组件:事务,完整性协商,过程,关系依赖关系和许多逻辑。很多数据库逻辑是一个相当小的状态。千兆字节和太字节仅由与直接执行查询相关联的数据库逻辑的一小部分直接使用。
因此,我们的想法是:如果逻辑的一部分允许无状态执行,为什么不将基础分为有状态和无状态部分。
OLAP无服务器解决方案
让我们看一下将数据库分为有状态和无状态部分的实际示例。
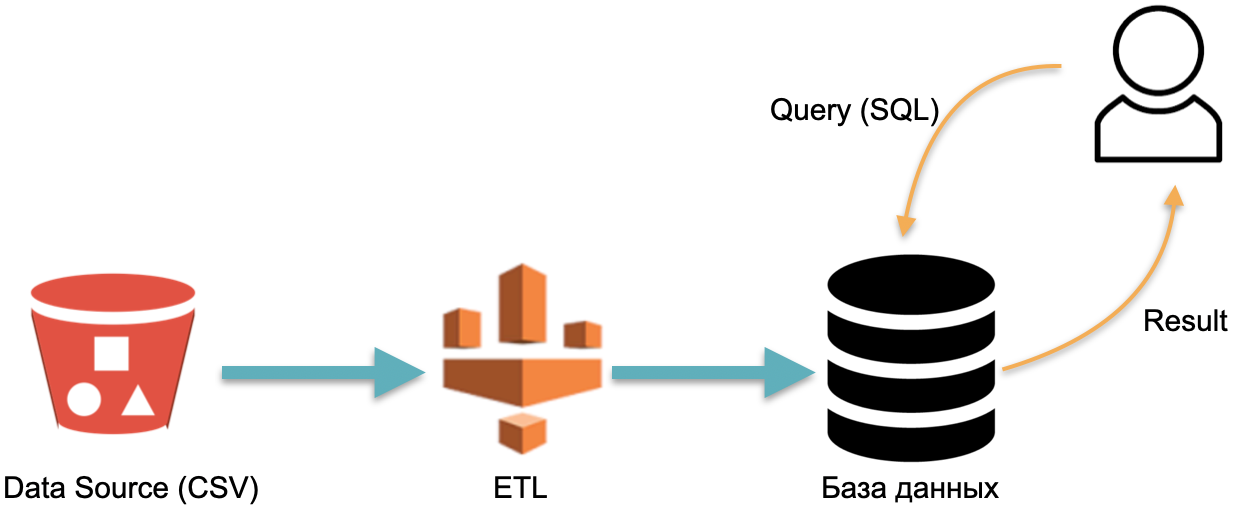
例如,我们有一个分析数据库:外部数据(左侧的红色圆柱体),将数据加载到数据库中的ETL流程以及将SQL查询发送到数据库的分析人员。这是数据仓库工作的经典方式。
在此方案中,按照惯例,ETL仅执行一次。然后,您需要花费所有时间为运行数据库的服务器上的ETL数据泛滥,以便您可以抛出请求。
考虑在AWS Athena Serverless中实现的替代方法。没有永久专用的硬件,无法存储已下载的数据。代替这个:
- SQL- Athena. Athena SQL- (Metadata) , .
- , , ( ).
- SQL- , .
- , .
在这种架构中,我们只为请求执行过程付费。没有要求-没有费用。
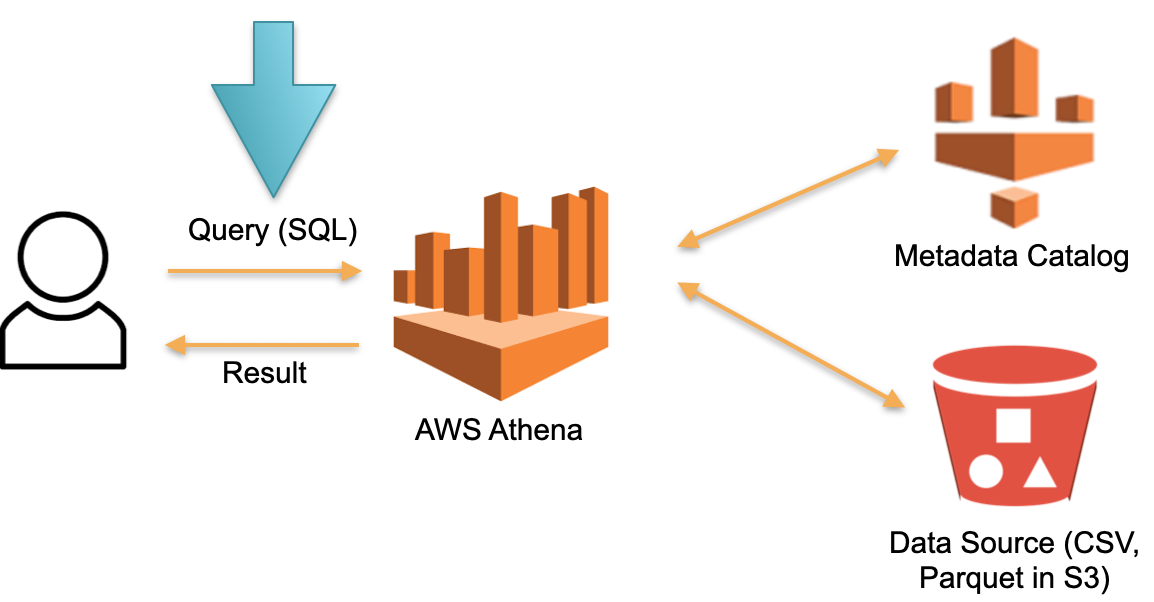
这是一种可行的方法,不仅在Athena Serverless中实现,而且在Redshift Spectrum(在AWS上)中实现。
Athena的示例表明,无服务器数据库可以处理具有数十和数百TB数据的真实查询。数百兆兆字节将需要数百台服务器,但是我们不必为它们付费-我们为请求付费。与Vertica这样的专门分析数据库相比,每个请求的速度(非常)慢,但是我们不为停机支付费用。
这样的数据库对于罕见的临时分析查询很有用。例如,当我们自发决定对大量数据进行假设检验时。雅典娜非常适合这些情况。对于常规查询,这种系统很昂贵。在这种情况下,请在某些专用解决方案中缓存数据。
OLTP解决方案的无服务器
在前面的示例中,考虑了OLAP任务(分析)。现在让我们看一下OLTP任务。
想象一下可伸缩的PostgreSQL或MySQL。让我们以最少的资源提出一个常规的托管实例PostgreSQL或MySQL。当更多负载到达实例时,我们将连接其他副本,并将部分读取负载分配给这些副本。如果没有请求且没有负载,我们将关闭副本。第一个实例是主实例,其余实例是副本。
这个想法在名为Aurora Serverless AWS的数据库中实现。原理很简单:代理团队接受来自外部应用程序的请求。看到负载增加,它从预热的最小实例中分配计算资源-连接速度尽可能快。断开实例是相同的。
在Aurora中,存在ACU的Aurora容量单位的概念。 (有条件地)这是一个实例(服务器)。每个特定的ACU可以是主机或从机。每个容量单元都有自己的RAM,处理器和最小磁盘。因此,一个主机,其余为只读副本。
这些运行中的Aurora容量单位的数量是可配置的。最小数量可以为1或0(在这种情况下,如果没有请求,则基数不起作用)。

当基地收到请求时,代理团队将提高Aurora CapacityUnits,从而增加系统的生产资源。增加和减少资源的能力使系统可以“调整”资源:自动显示单个ACU(用新的ACU代替),并对已删除的资源进行所有相关的更新。
Aurora无服务器基础可以扩展读取负载。但是文档没有直接说出来。可能感觉他们可能正在筹集多名硕士。没有魔术。
该基础非常适合在访问不可预测的系统上不花费大量资金。例如,在建立MVP或名片营销网站时,我们通常不会带来稳定的负载。因此,在无法访问的情况下,我们不支付实例费用。当出现意外负载时,例如,在会议或广告活动之后,很多人访问该站点,并且负载急剧增加,Aurora Serverless会自动接管此负载并迅速连接丢失的资源(ACU)。然后会议继续进行,每个人都忘记了原型,服务器(ACU)停产了,成本降为零-这很方便。
该解决方案不适用于稳定的高高负载,因为它无法缩放写入负载。所有这些资源的连接和断开都发生在所谓的“扩展点”的时刻,即事务不保留数据库时,不保留临时表的时刻。例如,一周之内可能不会发生扩展点,并且该基础使用相同的资源并且根本无法扩展或缩小。
没有魔术-这是正常的PostgreSQL。但是添加汽车和断开连接的过程是部分自动化的。
无服务器设计
Aurora Serverless是为云重写的旧基础,以利用Serverless的个人优势。现在,我将向您介绍无服务器方法的基础,该基础最初是为云编写的。它是在没有假定它在物理服务器上运行的前提下立即开发的。
这个基地叫雪花。它具有三个关键块。
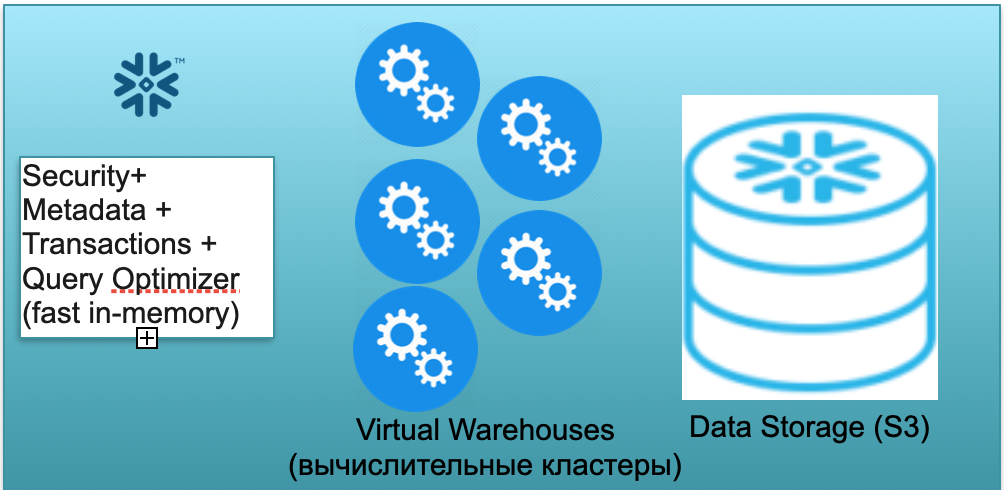
第一个是元数据块。它是一种快速的内存服务,可解决安全性,元数据,事务,查询优化等问题(如左图所示)。
第二个块是一组用于计算的虚拟计算集群(在图中-一组蓝色圆圈)。
第三块是基于S3的存储系统。S3是AWS的无量纲对象存储,类似于企业的无量纲Dropbox。
让我们看一下雪花在冷启动假设下如何工作。也就是说,数据库在那里,数据已加载到其中,没有有效的查询。因此,如果没有对数据库的查询,那么我们提出了一种快速的内存中元数据服务(第一个块)。而且我们有S3存储(用于存储表数据),该存储分为所谓的微分区。为简单起见:如果表格中包含交易,那么微手交易就是交易日。每天都是一个单独的微批处理,一个单独的文件。当数据库以这种模式工作时,您只需支付数据所占用的空间。此外,每个座位的比率非常低(尤其是考虑到很大的压缩)。元数据服务也可以持续工作,但是您不需要大量资源来优化查询,因此该服务可以视为共享软件。
现在,让我们想象一个用户来到我们的数据库并抛出一个SQL查询。 SQL查询立即发送到元数据服务进行处理。因此,在接收到请求后,此服务将分析请求,可用数据,用户凭据,如果一切正常,则将制定处理该请求的计划。
接下来,服务启动计算集群的启动。计算集群是执行计算的服务器集群。也就是说,此群集可以包含1个服务器,2个北向服务器,4个,8个,16个,32个-任意数量。您引发一个请求,该集群的启动立即在其下启动。真的需要几秒钟。
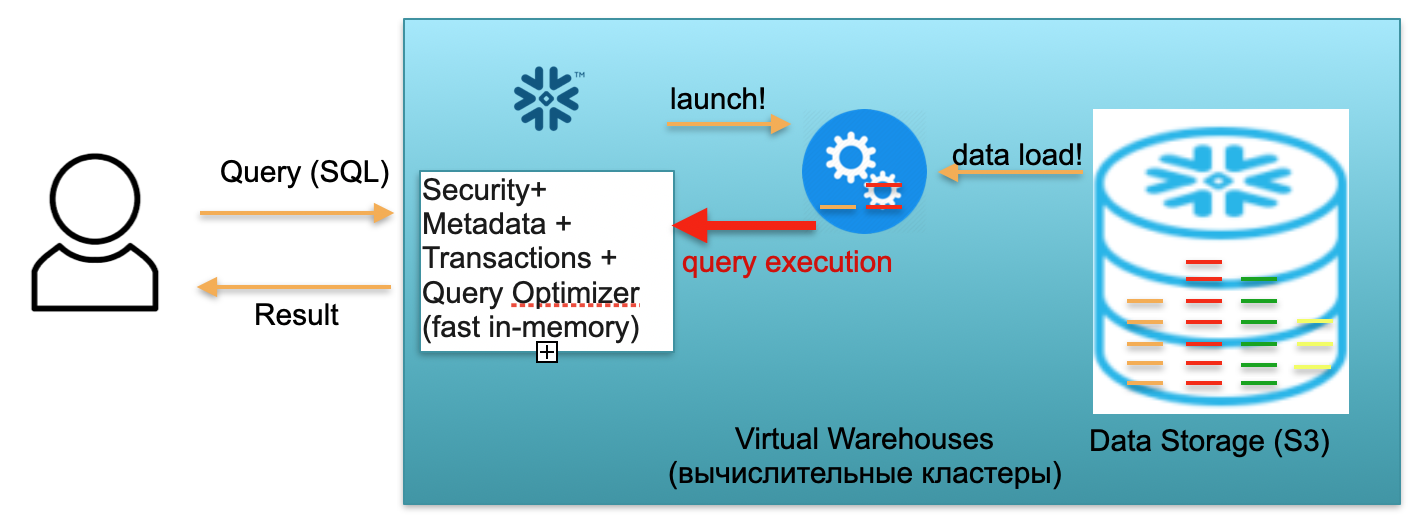
此外,在群集启动之后,将微分区从S3复制到群集,这是处理您的请求所必需的。也就是说,假设要执行SQL查询,您需要一个表中的两个分区,而第二个表中的一个分区。在这种情况下,只有三个必要的分区将被复制到集群,而不是整个表都被复制。这就是为什么并且正是因为所有内容都在一个数据中心的框架内并且通过非常快的通道进行连接,所以整个抽取过程非常迅速:几秒钟内(很少)-几分钟内(如果我们不是在谈论一些奇怪的请求) ...因此,将微分区复制到计算群集,并在完成后在此计算群集上执行SQL查询。该查询的结果可以是一行,几行或一张表-它们被发送给用户,以便可以下载,在其BI工具中显示或以其他方式使用它。
每个SQL查询不仅可以从以前加载的数据中读取聚合,还可以在数据库中加载/形成新数据。也就是说,它可以是一个查询,例如,将新记录插入另一个表中,从而导致在计算群集上出现新分区,该分区又自动存储在单个S3存储中。
从用户的到达到提升集群,加载数据,执行查询,获取结果的上述场景都是以使用提升的虚拟计算集群,虚拟仓库的每分钟速率支付的。费率因AWS区域和群集大小而异,但平均每小时为几美元。四辆汽车的集群的价格是两辆汽车的集群的两倍,而八辆汽车的集群则是两倍。根据请求的复杂程度,有16、32辆车的可用选项。但是您只需为集群实际工作的时间付费,因为当没有请求时,您会放开手,等待5-10分钟(可配置参数)后,集群将自行消失,释放资源并变得自由。
当您提出一个请求时,这种情况是很真实的。相对而言,集群在一分钟内弹出,又是一分钟,然后是五分钟才能关闭,因此您需要为该集群的运行时间支付7分钟,而不是数月和数年。
第一个方案描述了在单用户方案中使用Snowflake。现在让我们想象有很多用户,这更接近实际情况。
假设我们有很多分析师和Tableau报告,它们不断使用大量简单的分析SQL查询轰炸我们的数据库。
另外,假设我们有一些精巧的数据科学家,他们试图对数据进行处理,处理数十兆兆字节的数据,分析数十亿和数万亿行数据。
对于上述两种类型的负载,Snowflake允许您提升几个不同容量的独立计算集群。此外,这些计算集群独立运行,但具有共同的一致数据。
对于大量的轻量查询,您可以提出2-3个小型集群,按常规大小,每个集群2台。除其他外,使用自动设置可以实现此行为。也就是说,您说:“雪花,举起一个小集群。如果其上的负载增长超过某个参数,则增加类似的第二,第三。当负载开始减少时-消除多余的负载。”因此,无论有多少分析师来开始查看报告,每个人都有足够的资源。
同时,如果分析师睡着了并且没人在看报告,那么集群可以完全消失,而您不必为它们付费。
同时,对于繁重的查询(来自数据科学家),您可以在每32个条件计算机上引发一个非常大的集群。当您的巨型请求在该群集中运行时,该群集也将仅按分钟和小时计费。
上述功能不仅可以将群集分为2类,而且还可以将更多类型的负载(ETL,监视,报告的实现等)分为几类。
让我们总结一下雪花。该基地结合了一个美丽的想法和可行的实施。在ManyChat,我们使用Snowflake分析我们拥有的所有数据。如示例中所示,我们没有三个集群,但是有5到9个大小不同的集群。我们有条件的16机,2机,还有一些任务的超小型1机。他们成功地分配了负载,使我们节省了很多。
该基地成功地扩展了读写工作量。与仅拉动读取负载的同一个“ Aurora”相比,这是一个巨大的差异和巨大的突破。 Snowflake允许这些计算群集扩展和写入工作负载。也就是说,正如我提到的,我们在ManyChat中使用了几个群集,小型和超小型群集主要用于ETL,以加载数据。而且分析人员已经生活在绝对不受ETL负载影响的中型集群上,因此他们可以非常快速地工作。
因此,该基础非常适合OLAP任务。同时,不幸的是,它还不适用于OLTP工作负载。首先,这个基础是柱状的,随之而来的是所有后果。其次,这种方法本身会在需要时为每个请求增加一个计算集群并将其与数据一起溢出,但是不幸的是,对于OLTP工作负载,它仍然不够快。等待OLAP任务的秒数是正常的,但是对于OLTP任务,这是不可接受的,100毫秒会更好,甚至更好-10毫秒。
结果
通过将数据库分为无状态部分和有状态部分,可以实现无服务器数据库。您必须已经注意到,在给出的所有示例中,相对而言,有状态部分是在S3中存储微分区,而无状态是一种优化器,使用元数据处理可作为独立轻量级对象提出的安全性问题。无状态服务。
执行SQL查询也可以被认为是可以在无服务器模式下弹出的轻型服务,例如Snowflake计算集群,仅下载所需数据,执行查询并外出。
无服务器生产级数据库已经可以使用,并且正在运行。这些无服务器数据库已经准备好处理OLAP任务。不幸的是,由于存在局限性,它们被用于OLTP任务。一方面,这是一个负数。但是,另一方面,这是一个机会。也许有些读者会找到一种使OLTP基础完全无服务器的方法,而不受Aurora的限制。
希望您发现它有趣。无服务器是未来:)