
日记是只有在它们中断时才记住的事情之一。这根本不是批评。关键是原木不能赚钱。他们提供了有关哪些程序正在执行(或正在执行)的见解,从而有助于保持使我们赚钱的东西运转。在小规模(或开发期间),只需在以下位置显示消息即可获得必要的信息
stdout... 但是,一旦您进入分布式系统,就需要立即聚合这些消息并将其发送到某个中央存储库,这些存储库将带来最大的收益。如果您要在像Kubernetes这样的平台上处理容器,该平台上的进程和本地存储是短暂的,则此需求就更加重要。
熟悉的日志处理方法
自容器诞生之初和十二因子清单的发布以来,在处理由容器生成的日志时就形成了某种一般模式:
- 处理输出消息到
stdout或stderr, -
containerd(Docker)将标准流重定向到容器外部的文件, - 和日志转发器尾读取这些文件(即,从它们得到的最后几行),并将数据发送到数据库。
流行的日志转发器fluentd是CNCF项目(如集装箱运输)。随着时间的推移,它已成为读取,转换,传输和索引日志的事实上的标准。在连接了Cloud Logging(以前称为Stackdriver)的GKE上创建Kubernetes集群时,您将获得几乎相同的模式-仅具有Google流畅的风格。 正是这种模式出现在Olark (文章作者所在的公司-大约翻译)时。
最初是在四年前开始将服务迁移到G8(即GKE)。当我们超过了日志记录即服务的模式时,便遵循了这种模式,创建了我们自己的日志聚合系统,该系统能够在峰值负载下每秒处理15-20万行。
这种方法行之有效的原因还有十二要素原则为什么直接建议将日志输出到标准流。事实是,它使应用程序不必担心日志路由,并使容器在开发或生产过程中易于“观察” (我们在谈论可观察性)。而且,如果您的日志记录系统搞砸了,那么至少有可能日志会保留在群集节点的主机磁盘上。
这种方法的缺点是,拖尾日志在CPU使用率方面相对昂贵。在日志系统的下一个优化过程中,我们发现流利的文件消耗了生产中全部CPU请求配额的1/8之后,我们开始关注这一点:
- 这部分是由于群集拓扑结构造成的:fluentd托管在每个节点上以尾随本地文件(例如K8s语言中的DaemonSet),您具有四核节点,并且必须保留50%的内核以用于处理日志,并且...嗯,您就明白了。
- 资源的另一部分用于文字处理,我们也将其分配给fluentd。确实,谁会放弃清理混淆日志条目的机会?
- 剩下的去inotifywait,它监视磁盘上的文件,处理读取并进行跟踪。
我们想知道这一切要花多少钱:还有其他方法可以使日志流畅地发送。例如,你可以使用正端口(这是对使用的类型
forward中source- 。Ca的Perevi)。会便宜吗?
实际实验
为了隔离使用拖尾获取日志行的成本,我整理了一个小型测试台。它包括以下组件:
- Python程序,用于创建一定数量的日志编写器,并具有可配置的消息频率和大小;
- docker compose运行的文件:
- 熟练处理日志,
- 负责监控流利容器的顾问,
- Prometheus用于收集cAdvisor指标,
- 用于Prometheus中数据可视化的Grafana。
关于此图的注释:
- 日志编写器以统一的JSON格式(容器也使用该格式)生成消息,并且可以将它们写入文件或将其转发到流利的转发端口。
- 写入文件时,使用一个类
RotatingFileHandler来更好地模拟群集条件。 - Fluentd被配置为“通过”所有记录
null,而不处理正则表达式或根据标签检查记录。因此,他的主要工作将是获取日志行。 - , Prometheus cAdvisor, fluentd.
用于比较的参数的选择相当主观地进行。我编写了另一个实用程序,用于估计由集群中的节点生成的日志量。毫不奇怪,它变化很大:从每秒几十条线到最繁忙的节点上的500条或更多。
这是问题的另一个来源:如果使用DaemonSet,则必须配置fluentd来处理集群中最繁忙的节点。原则上,可以通过为主日志生成器分配适当的标签并使用软的反亲和性规则均匀地分配它们来避免这种不平衡,但这不在本文的讨论范围之内。最初,我计划比较日志“传递”的不同机制使用1到10个日志写入器以每秒500/1000行的速度加载。
检测结果
早期测试表明,无论我们观察到多少日志文件,每秒行数都是造成尾部CPU使用率的主要因素。下面的两个图比较了一个日志写入器和10个日志写入器在1000 p / s下的负载。可以看出它们几乎是相同的:
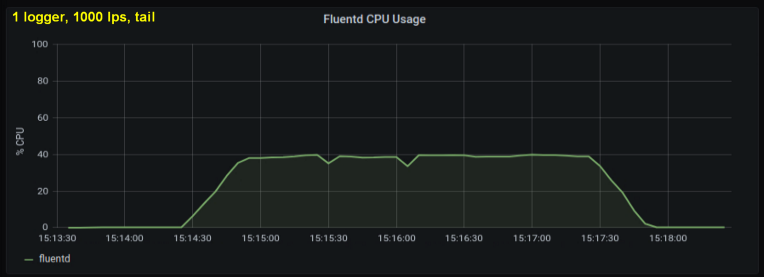
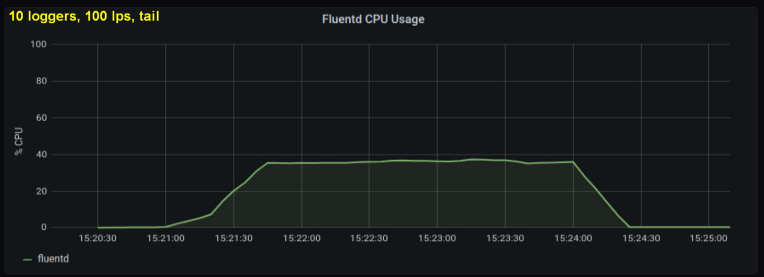
一个小题外话:我没有在此处包括相应的图,但是在我的机器上却发现有十个日志进程每秒写入100行比单个进程每秒写入1000行具有更高的总吞吐量。这可能是由于我的代码的细节-我没有刻意研究这个问题。
无论如何,我都希望打开日志文件的数量是一个重要因素,但事实证明,它并不会真正影响结果。另一个这样的无关紧要的变量是字符串的长度。上面的测试使用了100个字符的标准字符串长度。我的运行时间长了十倍,但这在测试过程中对处理器负载没有明显影响,在所有情况下均为180秒。
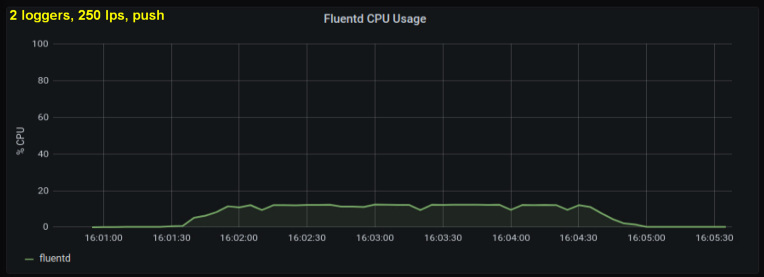
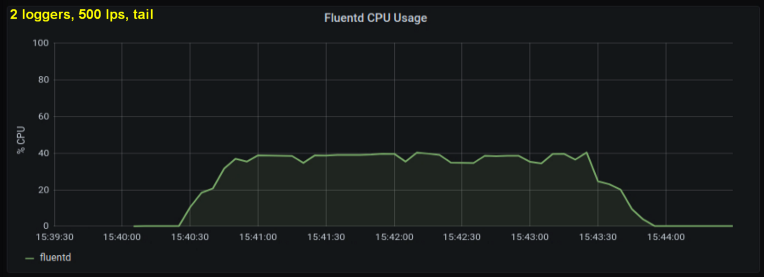
考虑到上述情况,我决定测试2位作者,因为在我看来,一个过程正在达到内部极限。另一方面,也不需要更多的过程。以每秒500和1000行的速度进行测试。以下一组图形显示了尾文件和前向端口的结果:


结论
在一周的过程中,我以许多不同的方式进行了这些测试,最终得出两个关键结论:
- 与从相同大小的日志文件中读取行相比,使用前向套接字的方法始终消耗30-50%的处理能力。一种可能的解释(至少部分观察到的差异)是通过序列化messagepack中的数据 - fluentd. fluentd , messagepack. , Python- forward-, . , : , fluentd, .
- , CPU , . tailing', forward-. , (1000 writer' 10 writer'), forward-:


这些结果是否意味着我们都应该将日志而不是文件写入套接字?显然,这并不是那么简单...
如果我们可以如此轻松地更改收集日志的方式,那么大多数现有问题就不会成为问题。输出日志
stdout使在开发过程中监视和使用容器变得更加容易。根据上下文,以两种方式输出日志将大大增加复杂性-类似地,在开发过程中配置流利的渲染日志(例如,使用输出插件stdout)会增加它的复杂性。
对这些结果的更实际的解释也许是建议扩大结点...由于必须将fluentd配置为与最繁忙(最嘈杂)的节点一起使用,因此减少节点的数量是有意义的。结合使用反亲和力机制(该机制将平均分配主要日志生成器),这将是一个不错的策略。 nodes,调整节点大小涉及许多细微差别和折衷,这远远超出了日志记录系统的需求。
规模显然也很重要...在小规模上,不便和增加的复杂性可能是不切实际的。另外,通常还有更紧迫的问题。如果您只是入门,而工程过程中没有“新鲜油漆”的气味消失,则可以提前使用套接字方法来标准化日志记录格式,并通过使用套接字方法削减成本,而不会使开发人员不知所措。
对于那些从事大型项目的人来说,本文的结论是不合适的,因为像Google这样的公司已经对该问题进行了更为彻底和知识密集的分析(与我的相比)。以这种规模,很明显,您正在部署自己的集群,并且可以使用日志记录管道完成任何您想做的事情(换句话说,利用这两种方法)。
最后,让我预料几个问题并提前回答。首先,“这篇文章不是真的吗?它与Kubernetes通常有什么关系?“ ... 这个问题双方的答案都是:“好吧,也许吧。”
- 以我的一般理解和经验,当您在具有大量磁盘I / O的情况下在Linux中拖尾文件时,通常会使用此工具。我还没有使用另一个日志转发器(例如Logstash)进行测试,但是查看结果会很有趣。
- Kubernetes, CPU, , . , , . , Kubernetes, tailing' Kubernetes-as-a-Service.
最后,谈谈另一种消耗性资源存储器。最初,我将把它包括在文章中:为它专门准备的仪表板显示fluentd的内存使用情况。但最后证明这一因素并不重要。根据测试结果,已使用的最大内存量不超过85 MB,各个测试之间的差异很少超过10 MB。相当低的内存消耗显然是由于我没有使用缓冲输出插件。更重要的是,两种方法的结果几乎相同。而且这篇文章已经变得太过冗长...
应该注意的是,如果您想进行更多的深入测试,可以考虑更多的“角落”。例如,您可以找出fluentd大部分时间都花在哪个处理器状态和系统调用上,但是要做到这一点,您必须为其做适当的包装。
译者的PS
另请参阅我们的博客: