因此,在每个单独的过程中,都没有并行代码执行,锁定,竞争条件等传统的“奇怪”问题,而且DBMS本身的开发令人愉悦且简单。
但是同样的简单性也带来了很大的限制。由于进程内只有一个工作线程,因此它最多可以使用一个CPU内核来执行请求-这意味着服务器的速度直接取决于单独内核的频率和体系结构。
在我们终结“兆赫兹种族”和胜利的多核和多处理器系统的时代,这种行为是无法接受的奢侈和浪费。因此,从PostgreSQL 9.6开始,在处理查询时,某些操作可以同时由多个进程执行。
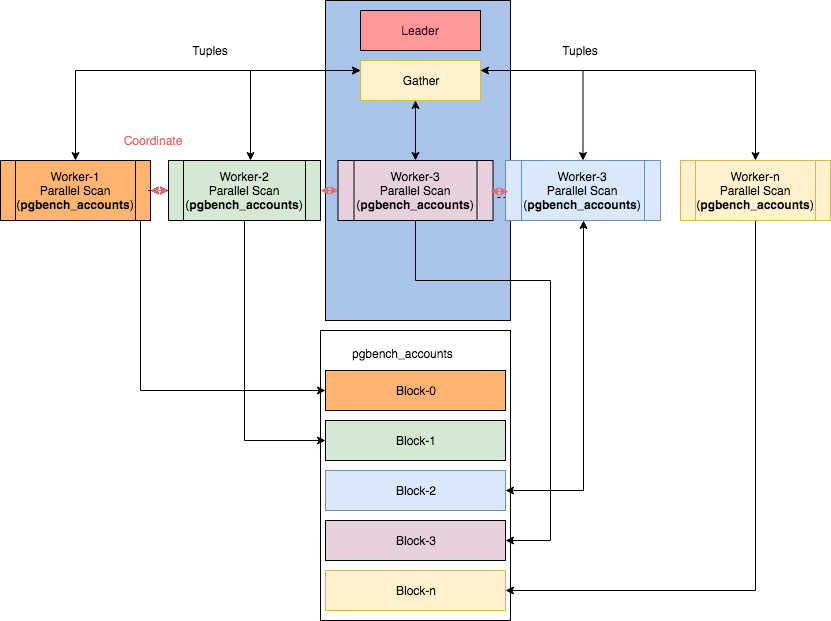
某些并行节点可以在Ibrar Ahmed的文章“ PostgreSQL中的并行性”中找到,该图像取自该图像。但是,在这种情况下,阅读计划变得……很简单。
简而言之,并行执行计划操作的时间顺序如下所示:
- 9.6-基本功能:Seq扫描,联接,汇总
- 10-索引扫描(用于btree),位图堆扫描,哈希联接,合并联接,子查询扫描
- 11 -组操作:哈希联接共用哈希表,追加(UNION)
- 12-计划节点上的基本按工统计
- 13-详细的按工统计
因此,如果您使用的是最新的PostgreSQL版本,那么在计划中看到它的机会就
Parallel ...很高。他们和他一起来...
随着时间的流逝
让我们从PostgreSQL 9.6开始做一个计划:
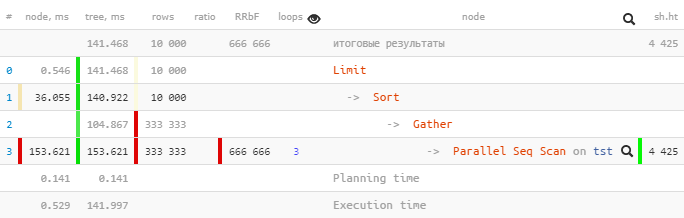
[看一下explain.tensor.ru ]在一个子树中,
只有一个
Parallel Seq Scan执行了153.621 ms,并且Gather与所有子节点一起执行-只有104.867 ms。
为何如此?“上楼”的总时间是否变少了...
让我们更
Gather详细地看一下-node:
Gather (actual time=0.969..104.867 rows=333333 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4425Workers Launched: 2告诉我们,除了树下的主要流程之外,还涉及另外2个流程-共有Gather3个流程。因此,子树内发生的所有事情都是一次3个流程的总创造力。
现在,让我们看看里面有什么
Parallel Seq Scan:
Parallel Seq Scan on tst (actual time=0.024..51.207 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425啊哈!
loops=3是所有3个过程的摘要。并且,平均每个这样的周期花费了51.207ms。也就是说,完成此节点需要花费服务器51.207 x 3 = 153.621毫秒的处理器时间。也就是说,如果我们想了解“服务器正在做什么”,那么这个数字将有助于我们理解。
请注意,要了解“实际”执行时间,您需要将总时间除以工作人员数-即[actual time] x [loops] / [Workers Launched]。
因此,在我们的示例中,每个工作人员仅通过节点执行一个循环
153.621 / 3 = 51.207。是的,现在不足为奇的是,只有Gather在“更少的时间”内完成头脑中的流程。
总计:请查看explain.tensor.ru, 以了解(所有进程)节点的总时间,以了解服务器正在处理的负载类型,并优化查询的哪一部分值得花费时间。
从这个意义上讲,相同的explain.depesz.com的行为(一次显示“实际平均”时间)对于调试目的似乎不太有用:
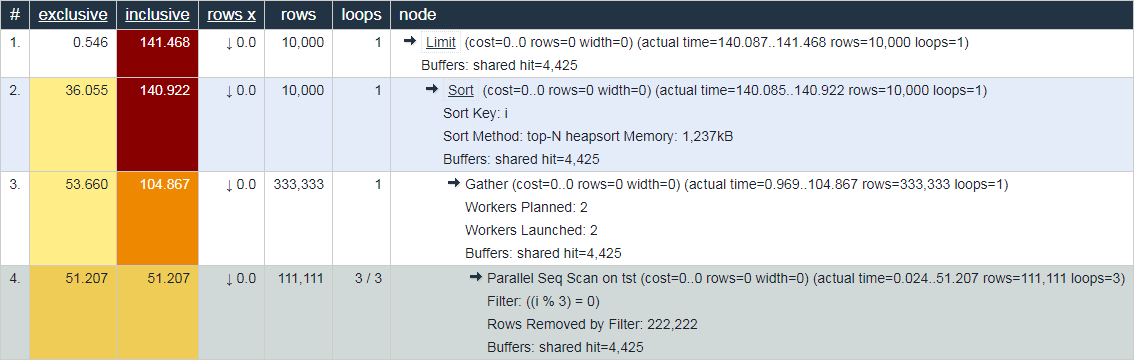
不同意吗?欢迎发表评论!
Gather Merge失去了一切
现在让我们对PostgreSQL 10版本执行相同的查询:
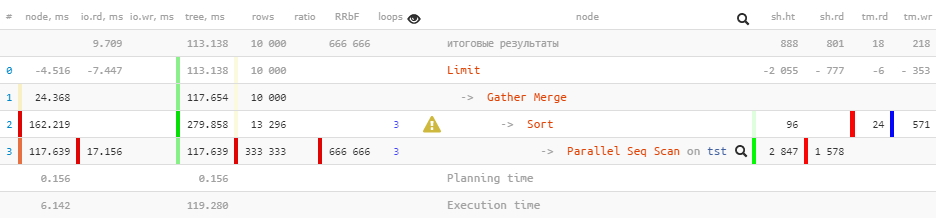
[看一下explain.tensor.ru]
注意,我们
Gather现在在计划中有一个节点而不是一个节点Gather Merge。这是手册对此的说明:
当节点在计划的并行部分上方Gather Merge而不是时Gather,这意味着执行并行计划的部分的所有进程都按已排序的顺序输出元组,并且领先进程正在执行顺序保留的合并。Gather另一方面,该节点从子流程中以方便的任意顺序接收元组,这违反了可能存在的排序顺序。
但是,丹麦王国并非一帆风顺:
Limit (actual time=110.740..113.138 rows=10000 loops=1)
Buffers: shared hit=888 read=801, temp read=18 written=218
I/O Timings: read=9.709
-> Gather Merge (actual time=110.739..117.654 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=2943 read=1578, temp read=24 written=571
I/O Timings: read=17.156在传递属性
Buffers并向I/O Timings上传递树时,一些数据不合时宜地丢失了。我们可以估计这种损失的大小约为2/3,这是由辅助过程形成的。
las,在计划本身中,没有地方可以获取此信息-因此,上级节点上的“缺点”。而且,如果您在PostgreSQL 12中查看此计划的进一步发展,那么它并没有根本改变,只是为
Sort-node上的每个工作程序添加了一些统计信息:
Limit (actual time=77.063..80.480 rows=10000 loops=1)
Buffers: shared hit=1764, temp read=223 written=355
-> Gather Merge (actual time=77.060..81.892 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4519, temp read=575 written=856
-> Sort (actual time=72.630..73.252 rows=4278 loops=3)
Sort Key: i
Sort Method: external merge Disk: 1832kB
Worker 0: Sort Method: external merge Disk: 1512kB
Worker 1: Sort Method: external merge Disk: 1248kB
Buffers: shared hit=4519, temp read=575 written=856
-> Parallel Seq Scan on tst (actual time=0.014..44.970 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Planning Time: 0.142 ms
Execution Time: 83.884 ms总计:不信任上面的节点数据
Gather Merge。