哈Ha!在本文中,我将向您展示如何对现代俄语Internet语言进行频率分析并使用它来解密文本。谁在乎,欢迎下切!

俄语互联网语言的频率分析
社交网络Vkontakte被用作来源,您可以从中获取大量使用现代Internet语言的文本,或更准确地说,这些是对该网络各个社区中出版物的评论。我选择了真正的足球作为社区。为了解析注释,我使用了Vkontakte API:
def get_all_post_id():
sleep(1)
offset = 0
arr_posts_id = []
while True:
sleep(1)
r = requests.get('https://api.vk.com/method/wall.get',
params={'owner_id': group_id, 'count': 100,
'offset': offset, 'access_token': token,
'v': version})
for i in range(100):
post_id = r.json()['response']['items'][i]['id']
arr_posts_id.append(post_id)
if offset > 20000:
break
offset += 100
return arr_posts_id
def get_all_comments(arr_posts_id):
offset = 0
for post_id in arr_posts_id:
r = requests.get('https://api.vk.com/method/wall.getComments',
params={'owner_id': group_id, 'post_id': post_id,
'count': 100, 'offset': offset,
'access_token': token, 'v': version})
for i in range(100):
try:
write_txt('comments.txt', r.json()
['response']['items'][i]['text'])
except IndexError:
pass结果是大约200MB的文本。现在我们考虑遇到哪个字符多少次:
f = open('comments.txt')
counter = Counter(f.read().lower())
def count_letters():
count = 0
for i in range(len(arr_letters)):
count += counter[arr_letters[i]]
return count
def frequency(count):
arr_my_frequency = []
for i in range(len(arr_letters)):
frequency = counter[arr_letters[i]] / count * 100
arr_my_frequency.append(frequency)
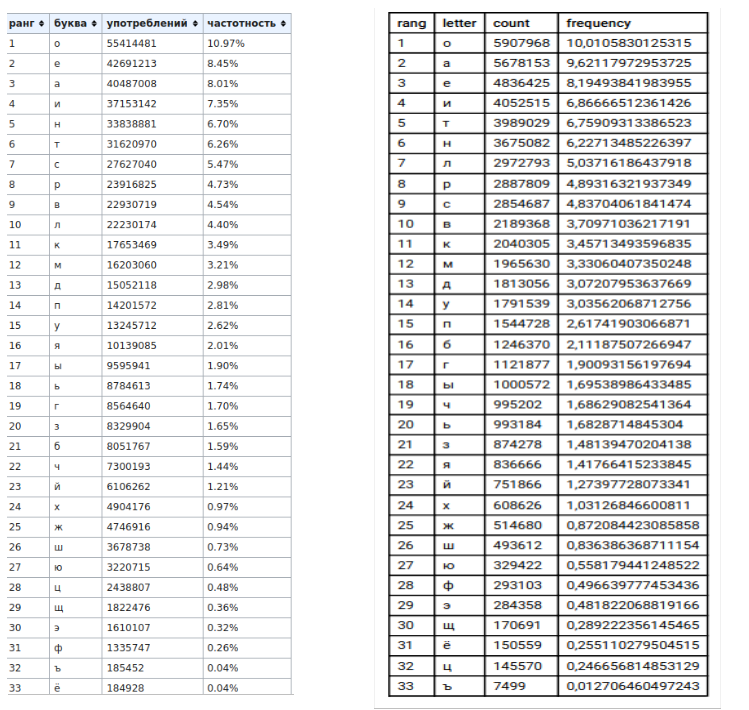
return arr_my_frequency可以将获得的结果与Wikipedia的结果进行比较,并显示为:
1)比较表
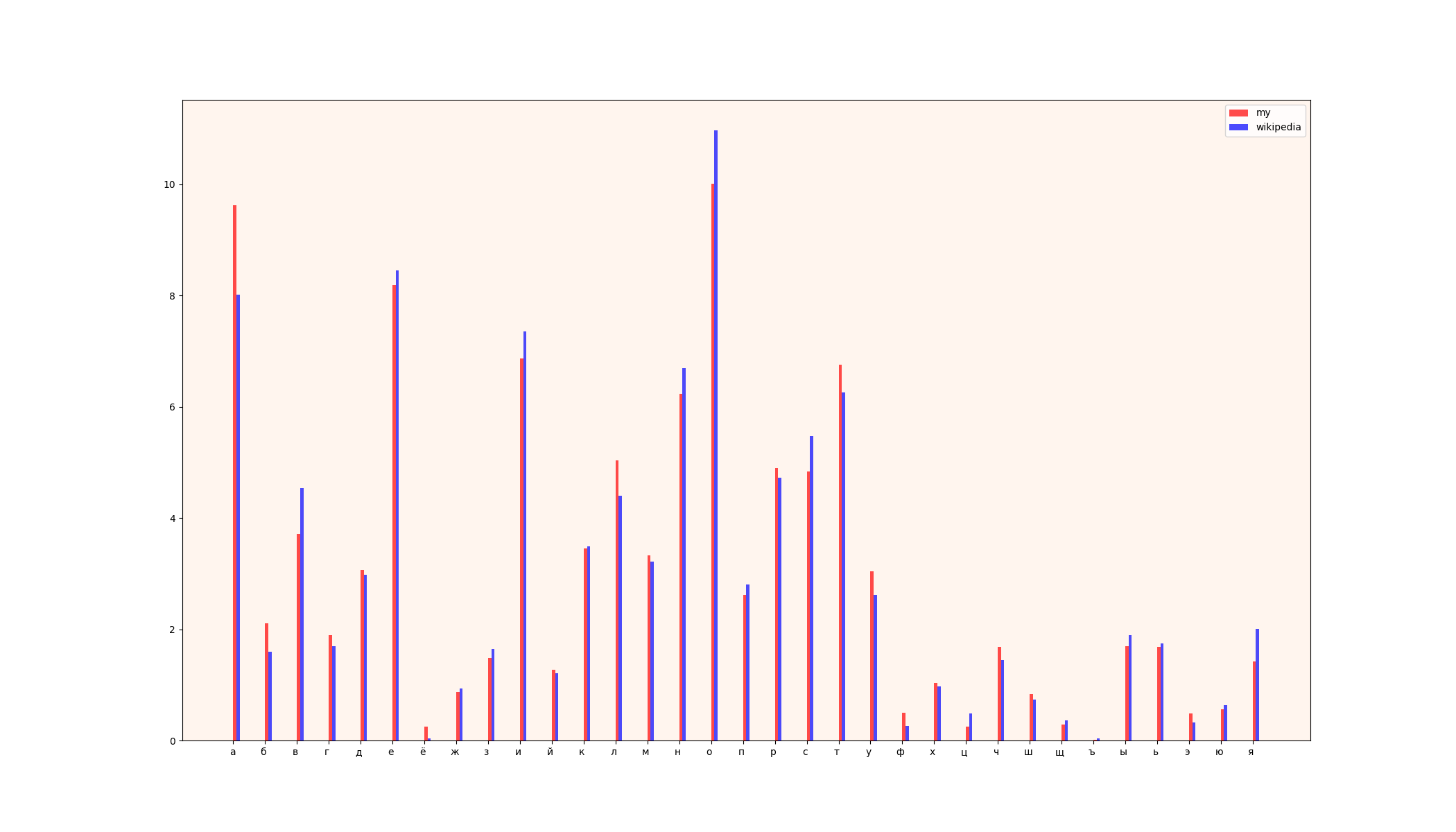
2)表格(左-维基百科数据,右-我的数据)
, , , «» «».
, , 2-4 :

, , , , , , , , ,
- . , — , , :
def caesar_cipher():
file = open("text.txt")
text_for_encrypt = file.read().lower().replace(',', '')
letters = ''
arr = []
step = 3
for i in text_for_encrypt:
if i == ' ':
arr.append(' ')
else:
arr.append(letters[(letters.find(i) + step) % 33])
text_for_decrypt = ''.join(arr)
return text_for_decrypt
:
def decrypt_text(text_for_decrypt, arr_decrypt_letters):
arr_encrypt_text = []
arr_encrypt_letters = [' ', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '',
'', '', '']
dictionary = dict(zip(arr_decrypt_letters, arr_encrypt_letters))
for i in text_for_decrypt:
arr_encrypt_text.append(dictionary.get(i))
text_for_decrypt = ''.join(arr_encrypt_text)
print(text_for_decrypt)
如果您查看解密后的文本,则可以猜出我们的算法出了什么问题:打架→确实如此,视频→广播,东宝→加法,压倒性→人。因此,可以解密整个文本,至少可以掌握文本的含义。我还想指出,此方法仅对解密使用对称加密方法加密的长文本有效。完整的代码可在Github上找到。