
今天,我将告诉您一些有关tarantool /墨盒故障转移的想法。首先,说说什么是弹药筒:这是一段lua代码,可在tarantool中使用,并将狼蛛彼此结合成一个有条件的“聚类”。这是由于两件事:
- 每个狼蛛都知道所有其他狼蛛的网络地址;
- 狼蛛定期通过UDP相互“ ping”,以了解谁在世,谁不在世。在这里,我故意进行一些简化,但ping算法不仅比请求响应还要复杂,但这对于解析不是很重要。如果有兴趣-谷歌的SWIM算法。
在集群中,通常将所有内容分为有状态(主/副本)和无状态(路由器)狼蛛。无状态的狼蛛负责存储数据,无状态的狼蛛负责路由请求。
这就是图中的样子:
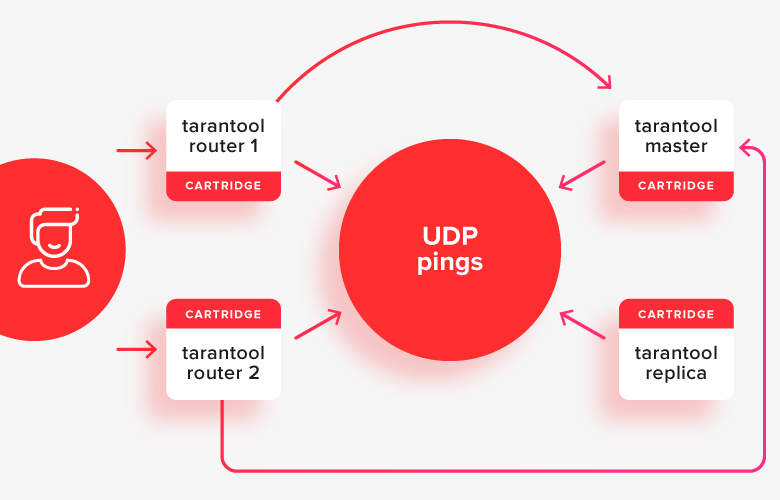
客户端向任何活动的路由器发出请求,然后它们将请求重定向到其中一个存储,即现在的活动主服务器。在图片中,这些路径以箭头显示。
现在,我不想复杂化,也不会在选择领导者的对话中引入分片,但是与他的处境几乎没有什么不同。唯一的区别是路由器仍然需要从存储中决定要使用哪个副本集。
首先,让我们谈谈节点如何学习彼此的地址。为此,每个磁盘上都有一个具有群集拓扑的yaml文件,即有关所有成员的网络地址以及谁是谁(有状态或无状态)的信息。加上可能进行的其他自定义,但就目前而言,我们暂且不谈。配置文件包含整个群集的整体设置,并且每个狼蛛的设置都相同。如果对其进行了更改,则将对所有狼蛛进行同步更改。
现在可以通过集群中任何狼蛛的API进行配置更改:它将连接到其他所有人,向他们发送新版本的配置,每个人都将应用它,并且到处都会有新版本,再次相同。
方案-节点故障,切换
在路由器发生故障的情况下,一切或多或少都变得很简单:客户端只需要转到任何其他活动路由器,然后它将请求发送到所需的存储。但是,例如,如果某个Storaja的主人倒下了怎么办?
现在,对于这种情况,我们已经实现了“幼稚”算法,该算法依赖于UDP ping。如果副本在短时间内没有“看到”主服务器对ping的响应,则认为该主服务器已掉落,成为主服务器本身,从只读模式切换到读写模式。路由器的行为方式相同:如果它们看不到来自主机的ping响应时间,则会将流量切换到副本。
在简单情况下,这比较有效,除了裂脑情况外,当一半的节点由于某种网络问题而彼此分离时:
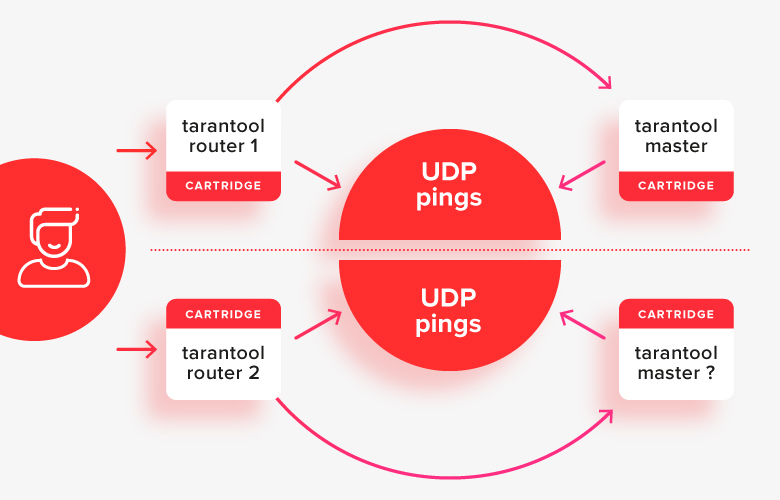
在这种情况下,路由器将看到群集的“另一半”不可用,并且会将其另一半视为主要的一半,结果是系统中同时存在两个主节点。这是要解决的第一个重要案例。
方案-失败时编辑配置
另一个重要方案是用新的群集替换群集中出现故障的狼蛛,或在副本或路由器之一不可用时向群集添加节点。
在正常运行期间,当集群中的所有内容都可用时,我们可以通过API连接到任何节点,要求它编辑配置,并且如上所述,该节点会将新配置“推出”到整个集群。
但是,当某人不可用时,将无法应用新配置,因为当这些节点再次变为可用时,将不清楚群集中的哪些节点具有正确的配置,而哪些节点没有正确的配置。节点之间的不可访问性仍然意味着它们之间存在裂脑。而且,编辑配置完全是不安全的,因为您可能会在不同的情况下以不同的方式错误地对其进行编辑。
由于这些原因,我们现在禁止在没有人可用时通过API编辑配置。只能通过文本文件在磁盘上(手动)进行更正。在这里,您必须清楚地了解自己在做什么,并且要非常小心:自动化不会以任何方式为您提供帮助。
这使操作不方便,这是第二个要解决的情况。
方案-稳定的故障转移
天真的故障转移模型的另一个问题是,在主节点发生故障的情况下,从主节点切换到副本节点不会记录在任何地方。所有节点都决定自行切换,当主节点变为活动状态时,流量将再次切换到该节点。
这可能是问题,也可能不是问题。在打开母版之前,母版将“追上”副本中的事务日志,因此很可能不会出现大数据延迟。仅在网络出现问题且数据包丢失的情况下才会出现问题:然后最有可能会定期出现主设备“闪烁”(拍打)的情况。
解决方案是“强大”的协调员(etcd / consul / tarantool)
为了避免出现大脑裂开的问题,并使得在群集部分不可用时可以编辑配置,我们需要一个能够抵抗网络分段的强大协调器。协调器应分布在3个数据中心中,以便在其中任何一个发生故障时都可以正常运行。
现在有2个基于RAFT的流行协调员,他们为此使用etcd和consul。当同步复制出现在tarantool中时,它也可以用于此目的。
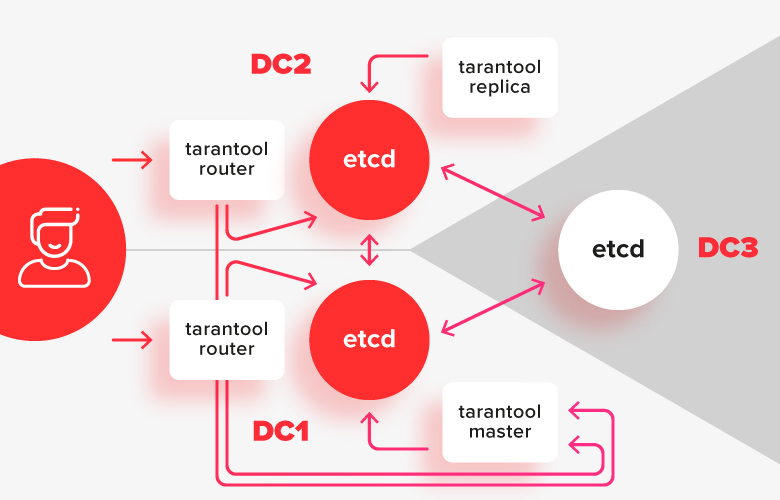
在此方案中,狼蛛安装分为两个数据中心,并连接到其本地etcd安装。第三个数据中心中的etcd实例充当仲裁器,以便在其中一个数据中心发生故障的情况下,准确地说出其中的大部分。
强大的协调员进行配置管理
就像我在上面说的那样,在没有协调者和狼蛛之一失败的情况下,我们无法集中编辑配置,因为那样就无法说出哪个节点正确。
在强大的协调器的情况下,一切都变得更加简单:我们可以将配置存储在协调器上,并且狼蛛的每个实例都将在其文件系统上包含此配置的缓存。成功连接到协调器后,它将更新其配置副本到协调器中的副本。
编辑配置也变得更加容易:可以通过任何狼蛛的API来完成配置。它将获得协调器中的锁,在配置中替换所需的值,等到所有节点都应用它,然后释放锁。好吧,或者作为最后的选择,您可以在etcd中手动编辑配置,它将应用于整个集群。
即使某些狼蛛不可用,也可以编辑配置。最主要的是,大多数协调器节点都可用。
具有强大协调员的故障转移
由于除了配置之外,我们还将在协调器中存储有关谁是副本中的当前主服务器以及在何处进行切换的信息,因此解决了使用协调器可靠切换节点的问题。
故障转移算法的变化如下:
- «» .
- UDP-, - , .
- , .
- .
- , read-only read-write.
- , , .
使用协调器,还可以进行拍打保护。在协调器中,您可以记录整个切换的历史记录,如果在最近的X分钟内主服务器切换到副本,则反向切换仅由管理员明确进行。
另一个要点是所谓的“击剑”。与其他数据中心断开连接(或与失去多数连接的协调器连接)的狼蛛应该假设,失去访问权限的群集其余部分很可能具有多数。这意味着,在一定时间内,与多数节点断开的所有节点都必须变为只读。
协调器不可用问题
当我们与协调员讨论工作方法时,我们收到了一个请求,以确保如果协调员摔倒了,但所有狼蛛都完好无损,请不要将整个集群转换为只读。
最初,这样做似乎不太现实,但是后来我们记住,群集本身通过UDP ping来监视其他节点的可用性。这意味着,如果通过UDP ping可以确定整个副本集仍然存在,我们就可以将它们作为目标,而不会触发重新选择副本集内的主机。
这种方法将帮助您减少对协调器可用性的担心,尤其是在您需要重新启动协调器以进行更新时。
实施计划
现在,我们正在收集反馈并开始实施。如果您有话要说-在评论中或以个人名义写。
该计划是这样的:
- 在tarantool中支持etcd [完成]
- 使用etcd作为协调器的故障转移,有状态[完成]
- 使用狼蛛作为协调器进行故障转移,锁定[完成]
- 将配置存储在etcd中[进行中]
- 编写用于集群修复的CLI工具[进行中]
- 将配置存储在狼蛛中
- 当部分集群不可用时的集群管理
- 击剑
- 拍击保护
- 使用领事作为协调者的故障转移
- 将配置存储在领事中
将来,我们几乎可以肯定会在没有强大协调员的情况下完全放弃集群。这很可能与狼蛛中基于RAFT的同步复制实现相吻合。
致谢
感谢Mail.ru开发人员和管理员提供的反馈,批评和测试。