
来源:Vecteezy
是的,线性回归不是唯一的一种,
快速命名五种机器学习算法。
您不太可能会命名许多回归算法。毕竟,唯一被广泛使用的回归算法是线性回归,这主要是由于其简单性。但是,线性回归通常不适用于真实数据,这是因为选择范围太有限,操纵自由度也很有限。它通常仅用作评估和与新研究方法进行比较的基准模型。Mail.ru云解决方案
团队翻译了一篇文章,作者描述了5种回归算法。它们与流行的分类算法(例如SVM,决策树和神经网络)一起在您的工具箱中值得拥有。
1.神经网络回归
理论
神经网络功能强大,但通常用于分类。信号通过神经元层传播,并被概括为几种类别之一。但是,通过更改最后一个激活函数,可以非常快速地将它们适应到回归模型中。
每个神经元通过激活函数传输先前连接的值,该函数用于泛化和非线性的目的。通常,激活函数类似于S型或ReLU(整流线性单元)函数。
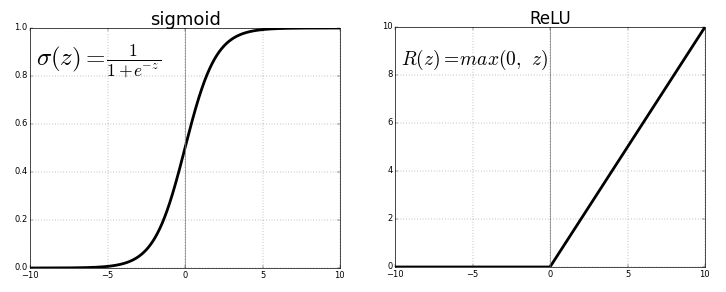
来源。免图像
但是,具有将最后的激活功能(输出神经元)线性一个激活功能后,输出信号可以映射到固定类别之外的许多值。因此,输出将不是将输入信号分配给任何一个类别的概率,而是神经网络固定其观测值的连续值。从这个意义上讲,我们可以说神经网络是线性回归的补充。
神经网络回归具有非线性(除了复杂性)的优点,可以在神经网络中较早地通过S型和其他非线性激活函数引入非线性。但是,过度使用ReLU作为激活函数可能意味着该模型倾向于避免输出负值,因为ReLU忽略了负值之间的相对差异。
这可以通过限制ReLU的使用并为相应的激活函数添加更多的负值来解决,也可以通过在训练之前将数据标准化为严格的正范围来解决。
实作
使用Keras,我们可以构建一个人工神经网络结构,尽管如果最后一层是具有线性激活的密集层或仅仅是具有线性激活的层,则可以使用卷积神经网络或其他网络来完成。(请注意,未列出Keras导入以节省空间)。
model = Sequential()
model.add(Dense(100, input_dim=3, activation='sigmoid'))
model.add(ReLU(alpha=1.0))
model.add(Dense(50, activation='sigmoid'))
model.add(ReLU(alpha=1.0))
model.add(Dense(25, activation='softmax'))
#IMPORTANT PART
model.add(Dense(1, activation='linear'))
神经网络的问题一直是它们的高方差和过度拟合的趋势。上面的代码示例中有许多非线性源,例如SoftMax或Sigmoid。
如果您的神经网络在纯线性结构的训练数据上做得很好,那么最好使用截断的决策树回归来模拟线性和高度分散的神经网络,但允许数据科学家更好地控制深度,宽度和其他属性以控制过度拟合。
2.决策树回归
理论
分类和回归中的决策树非常相似,因为它们通过构造具有yes / no节点的树来工作。但是,虽然分类叶节点产生单个类值(例如对于二进制分类问题为1或0),但是回归树最终以连续模式下的值(例如4593.49或10.98)结束。
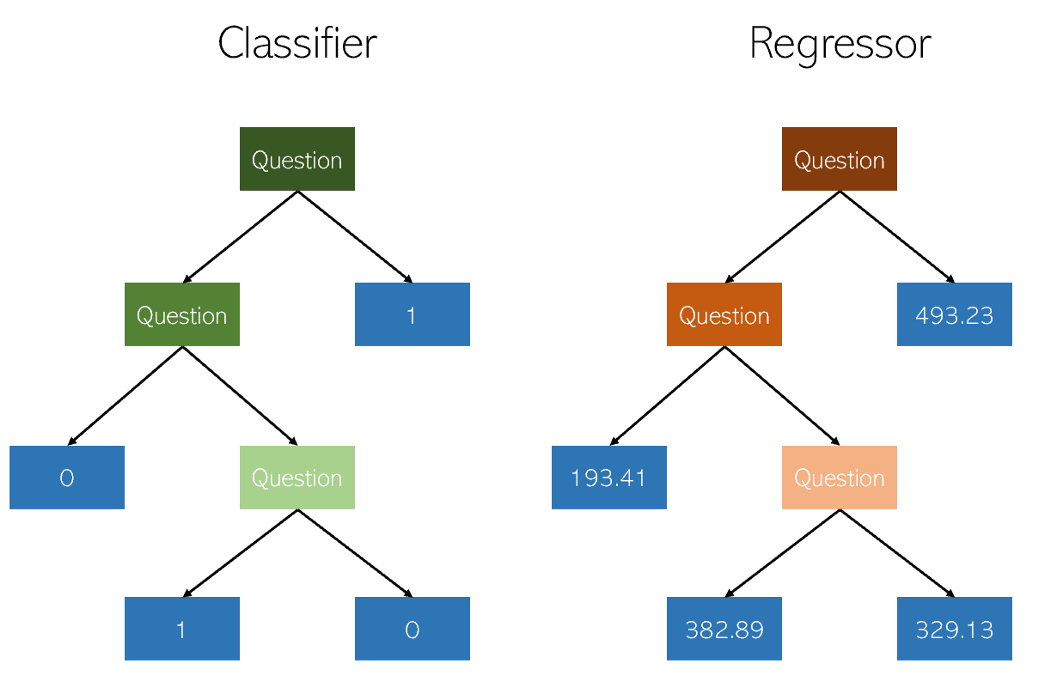
作者的插图
由于回归只是一个机器学习问题,而回归的特定性和高度分散的性质,应谨慎修剪决策树回归器。但是,回归方法是不规则的-它不是在连续范围内计算值,而是到达给定的末端节点。如果回归器的剪裁过多,则其叶节点太少,无法正确实现其目的。
因此,应修剪决策树,使其具有最大的自由度(回归的可能输出值是叶节点的数量),但不足以使其深度太深。如果不进行调整,由于回归的本质,已经高度分散的算法将变得过于复杂。
实作
决策树回归可以在以下位置轻松创建
sklearn:
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
model.fit(X_train, y_train)
由于决策树回归非常重要的参数,建议使用搜索引擎优化工具参数
GridCV自sklearn,发现此模型的正确建议。
在正式评估性能时,请使用测试
K-fold而不是标准测试train-test-split来避免后者的随机性,后者可能会违反高方差模型的敏感结果。
奖金:决策树的近亲(随机森林算法)也可以实现为回归器。由于树构建算法中冗余和不足之间的微妙平衡,随机森林回归器在回归方面的性能可能会好一些,也可能不会好于决策树(通常在分类方面会更好)。
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X_train, y_train)
3. LASSO回归
Lasso回归(LASSO,最小绝对收缩和选择算子)是线性回归的一种变体,特别适用于表现出强多重共线性(即要素之间具有很强相关性)的数据。
它可以自动执行部分模型选择,例如变量选择或参数排除。LASSO使用收缩率,这是一个数据值接近中心点(例如平均值)的过程。

作者的插图。压缩
过程的简化可视化压缩过程为回归模型增加了多个优点:
- 真实参数的估计更加准确和稳定。
- 减少抽样误差和抽样不足。
- 空间波动的平滑。
套索不是像高方差神经网络和决策树回归方法那样调整模型的复杂性来补偿数据的复杂性,而是尝试降低数据的复杂性,以便可以通过简单的回归方法来解决数据的复杂性,从而解决其所处的空间。在此过程中,套索以低方差方法自动帮助消除或扭曲高度相关和冗余的特征。
Lasso回归使用L1正则化,即根据错误的绝对值加权。而不是例如使用L2正则化,即通过误差的平方来加权误差,以便更强大地惩罚更重要的误差。
这种正则化通常导致具有较少系数的稀疏模型,因为某些系数可能变为零,因此从模型中排除。这样可以对其进行解释。
实作
该
sklearn回归套索带有其选择最有效的与不同的基本参数和学习路径的许多训练的模型,它可以自动,否则将必须手动执行任务交叉验证模型。
from sklearn.linear_model import LassoCV
model = LassoCV()
model.fit(X_train, y_train)
4.岭回归(ridge Ridge)
理论
Ridge回归或ridge回归与LASSO回归非常相似,因为它应用了压缩。两种算法都非常适合具有大量彼此不独立(共线性)的特征的数据集。
然而,它们之间最大的区别是,岭回归的用途转正L2,也就是没有系数不变成零,因为是套索回归。取而代之的是,这些系数越来越接近零,但是由于L2正则化的性质,几乎没有动力去实现它。
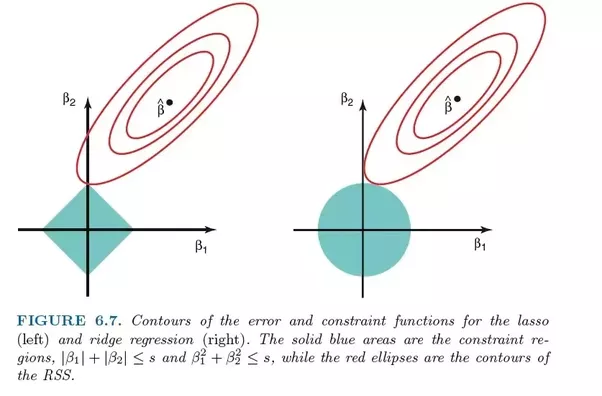
套索回归(左)和岭回归(右)中的误差比较。由于Ridge回归使用L2正则化,因此其面积类似一个圆形,而L1套索正则化则绘制直线。免费图片。源
在套索中,从错误5到错误4的改进与从4改进到3,从3改进为2,从2改进为1,从1改进为0的权重相同。因此,更多的系数达到零,并且消除了更多的特征。
但是,在岭回归中,从错误5到错误4的改善计算为5²-4²= 9,而从4到3的改善仅被加权为7。因此,减少了功能。
Ridge回归最适合需要优先处理大量变量的情况,每个变量的影响很小。如果您的模型需要考虑多个变量,每个变量都具有中等到较大的影响,则套索是最佳选择。
实作
Ridge回归
sklearn可以按以下方式实现(见下文)。与套索回归一样,sklearn有一种实现方法可以交叉验证许多训练有素的模型中最佳模型的选择。
from sklearn.linear_model import RidgeCV
model = Ridge()
model.fit(X_train, y_train)
5. ElasticNet回归
理论
ElasticNet的目标是通过结合L1和L2正则化来结合最佳的Ridge回归和Lasso回归。
套索和岭回归是两种不同的正则化方法。在这两种情况下,λ都是控制罚款金额的关键因素:
- λ = 0, , .
- λ = ∞, - . , , .
- 0 < λ < ∞, λ , .
在λ参数中,ElasticNet回归添加一个附加参数α,该参数测量正则化L1和L2应该如何“混合”。当α为0时,模型为纯岭回归;当α为1时,模型为纯套索回归。
“混合因子”α仅定义了在损失函数中应考虑多少L1和L2正则化。三种流行的回归模型(Ridge,Lasso和ElasticNet)均旨在减小其系数的大小,但是每个模型的行为都不同。
实作
可以使用sklearn的交叉验证模型来实现ElasticNet:
from sklearn.linear_model import ElasticNetCV
model = ElasticNetCV()
model.fit(X_train, y_train)
关于该主题还需要阅读什么: