
本文收集了一些常见的模式,以帮助工程师使用数百万用户所要求的大规模服务。
根据作者的经验,这不是详尽的清单,而是真正有效的技巧。所以,让我们开始吧。
在Mail.ru云解决方案的支持下进行了翻译。
第一级
下面列出的措施相对容易实施,但回报率很高。如果您以前没有尝试过,那么您将对重大改进感到惊讶。
基础架构即代码
第一条建议是将基础结构实现为代码。这意味着您必须以编程方式来部署整个基础架构。听起来很复杂,但实际上我们正在谈论以下代码:
部署100个虚拟机
- 与Ubuntu
- 每个2 GB RAM
- 他们将具有以下代码
- 具有这样的参数
您可以使用源代码控制来快速跟踪并还原到基础结构更改。
我中的现代主义者说,您可以使用Kubernetes / Docker来完成上述所有操作,他是对的。
或者,您可以通过Chef,Puppet或Terraform提供自动化。
持续集成和交付
要创建可伸缩服务,为每个拉取请求建立并测试管道很重要。即使测试是最简单的,它也将至少确保您部署的代码能够编译。
每次在此阶段,您都会回答以下问题:我的程序集是否可以编译并通过测试,是否有效?听起来好像很低,但是它解决了很多问题。
没有比看到这些复选框更美丽的东西了,
对于这种技术,您可以查看Github,CircleCI或Jenkins。
负载均衡器
因此,我们想启动一个负载均衡器来重定向流量,并确保所有节点上的负载相等,或者在发生故障时该服务能够正常工作:
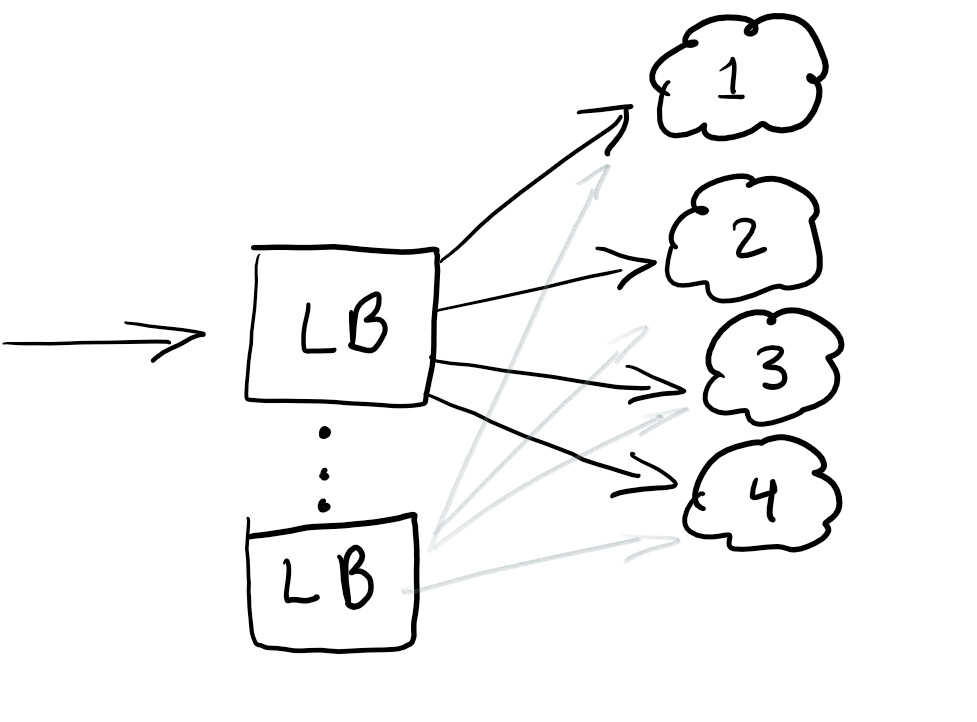
负载平衡器通常擅长帮助分配流量。最佳实践是过度平衡,这样就不会出现单点故障。
通常,负载均衡器是在您使用的云中配置的。
请求的RayID,关联ID或UUID
您是否曾在应用程序中遇到如下错误消息:“出了点问题。保存此ID并将其发送给我们的支持团队”?
唯一标识符,相关性ID,RayID或任何变体是唯一标识符,可让您在请求的整个生命周期中对其进行跟踪。这使您可以在日志中跟踪请求的整个路径。
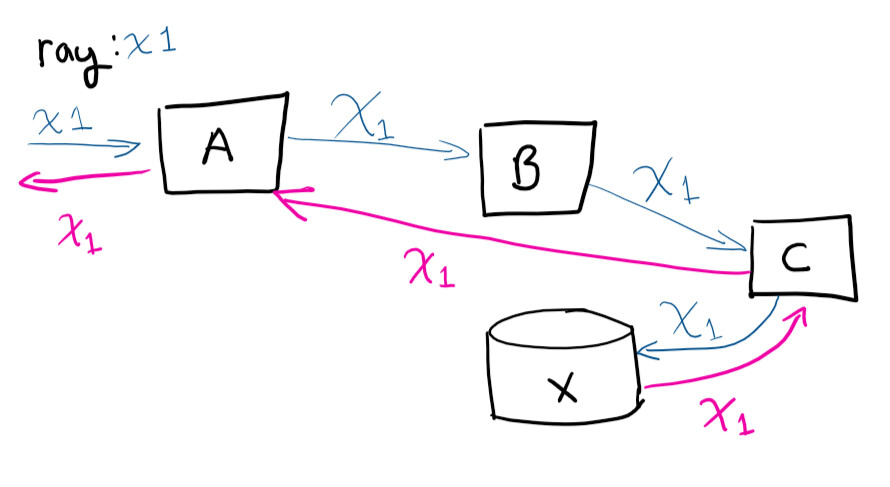
用户向系统A发出请求,然后向A的B联系人(与C的联系人)保存到X,然后该请求返回给A。
如果您要远程连接到虚拟机并尝试跟踪请求路径(并手动关联正在发生的呼叫),你会发疯的。拥有唯一的标识符会使生活变得更加轻松。随着服务的增长,这是节省时间的最简单的操作之一。
中等水平
这里的建议比以前的建议更复杂,但是正确的工具使任务变得更容易,甚至为中小型公司提供了投资回报。
集中记录
恭喜你!您已经部署了100个虚拟机。第二天,首席执行官来了,并抱怨他在测试服务时收到的错误。它报告了我们在上面讨论的相应标识符,但是您将不得不浏览100台计算机的日志以查找导致崩溃的计算机。她需要在明天的演讲之前找到。
虽然这听起来像是一次有趣的冒险,但最好确保您能够从一个地方搜索所有杂志。我使用ELK堆栈的内置功能解决了集中日志的问题:它支持可搜索的日志收集。这将确实有助于解决查找特定日志的问题。另外,您可以创建图表和类似的其他有趣的东西。
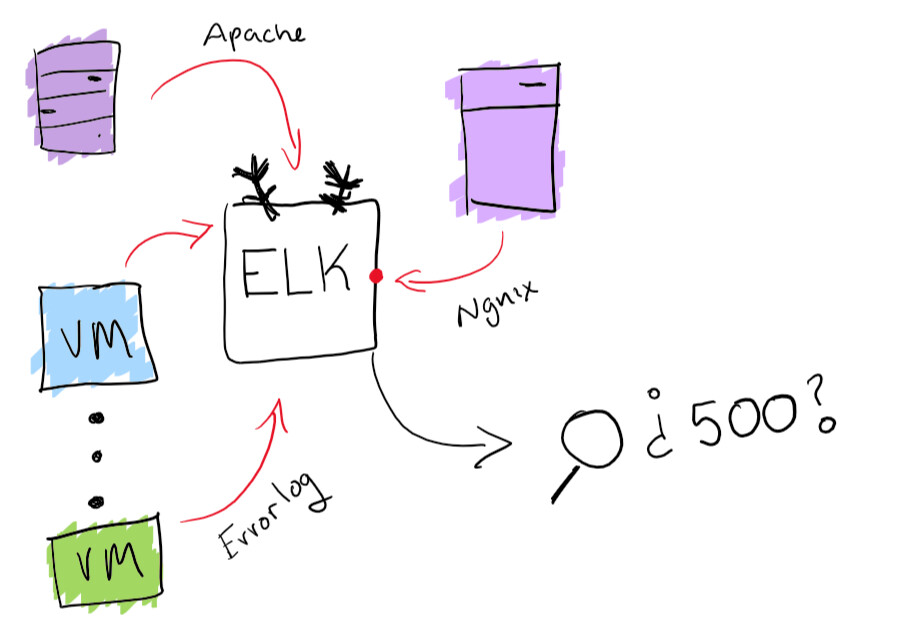
ELK堆栈功能
监控代理
现在您的服务已启动并正在运行,您需要确保其运行平稳。最好的方法是运行多个并行运行的代理,并验证其是否已启动并针对基本操作正在运行。
此时,您确认正在运行的程序集运行良好并且工作正常。
对于中小型项目,我建议使用Postman来监视和记录API。但通常,您只需要确保有一种方法可以知道何时发生故障并及时接收警报。
根据负载自动缩放
非常简单 如果您有一个虚拟机正在处理请求,并且正在接近80%的内存使用量,则可以增加其资源或向群集中添加更多虚拟机。这些操作的自动执行非常适合负载下的弹性功率变化。但是,您应该始终谨慎花费多少钱并设置合理的限制。
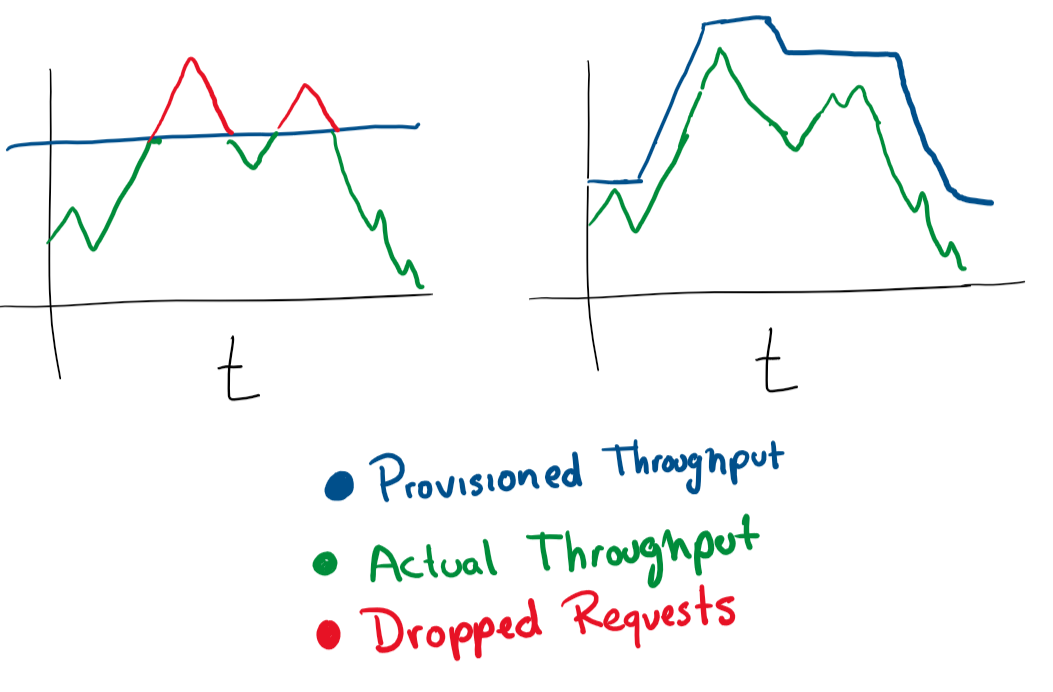
在大多数云服务中,您可以使用更多服务器或功能更强大的服务器配置自动扩展。
实验系统
安全部署更新的一种好方法是能够在一小时内为1%的用户测试某些东西。您肯定已经看到了这样的机制在起作用。例如,Facebook向部分观众显示不同的颜色或更改字体大小,以查看用户如何看待更改。这称为A / B测试。
甚至发布一个新功能都可以作为实验来运行,然后找出如何发布它。考虑到导致服务质量下降的功能,您还可以即时“记住”或更改配置。
先进的水平
这里有一些很难实现的技巧。您可能需要更多的资源,因此对于中小型公司而言,将很难处理。
蓝绿色部署
这就是我所说的“ Erlang”部署方法。当电话公司出现时,Erlang被广泛使用。软交换机已用于路由电话呼叫。这些交换机上软件的主要重点是在系统升级期间不会掉线。 Erlang有一个很好的方式来加载新模块而不会导致前一个模块崩溃。
此步骤取决于负载均衡器的存在。假设您的软件版本为N,然后要部署版本N + 1。
您可以停止服务并在对用户方便的时候部署下一个版本,并获得一些停机时间。但是假设你有真正严格的SLA条款。因此,SLA 99,99%意味着您每年只能脱机52分钟。
如果确实要实现此目的,则需要同时进行两个部署:
- 现在的那个(N);
- 下一版本(N +1)。
您告诉负载均衡器自己主动跟踪回归时将一定百分比的流量重定向到新版本(N + 1)。
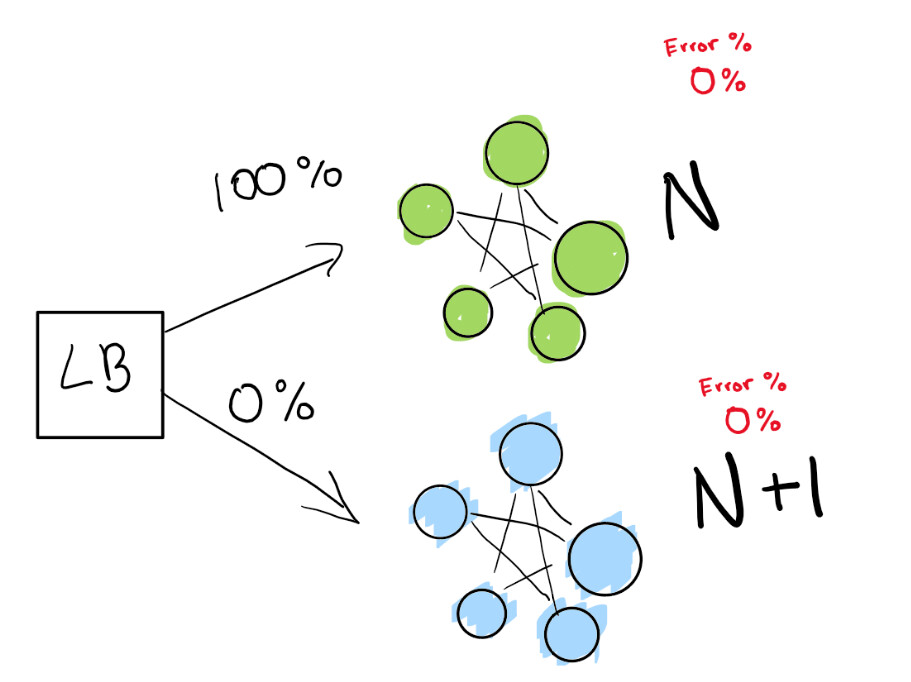
在这里,我们有一个绿色的部署N,可以正常工作。我们正在尝试转到该部署的下一个版本
首先,我们发送一个非常小的测试,以查看我们的N + 1部署是否在很少的流量下工作:
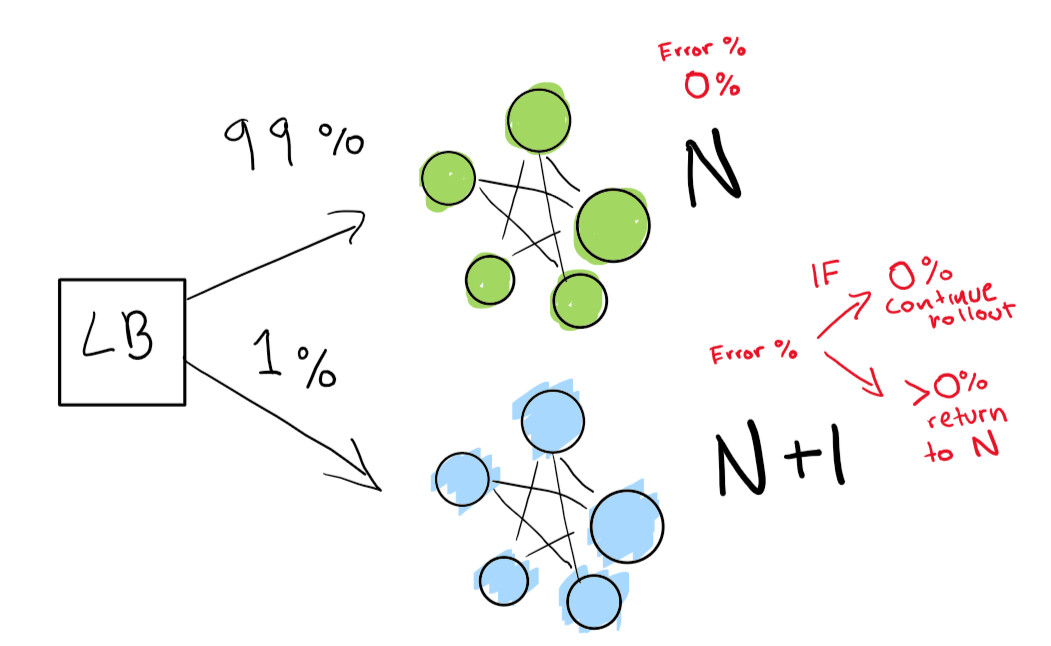
最后,我们有一组自动检查,这些检查最终将运行直到部署完成。如果您非常非常小心,则还可以永久保留N部署,以便在发生不良回归时快速回滚:
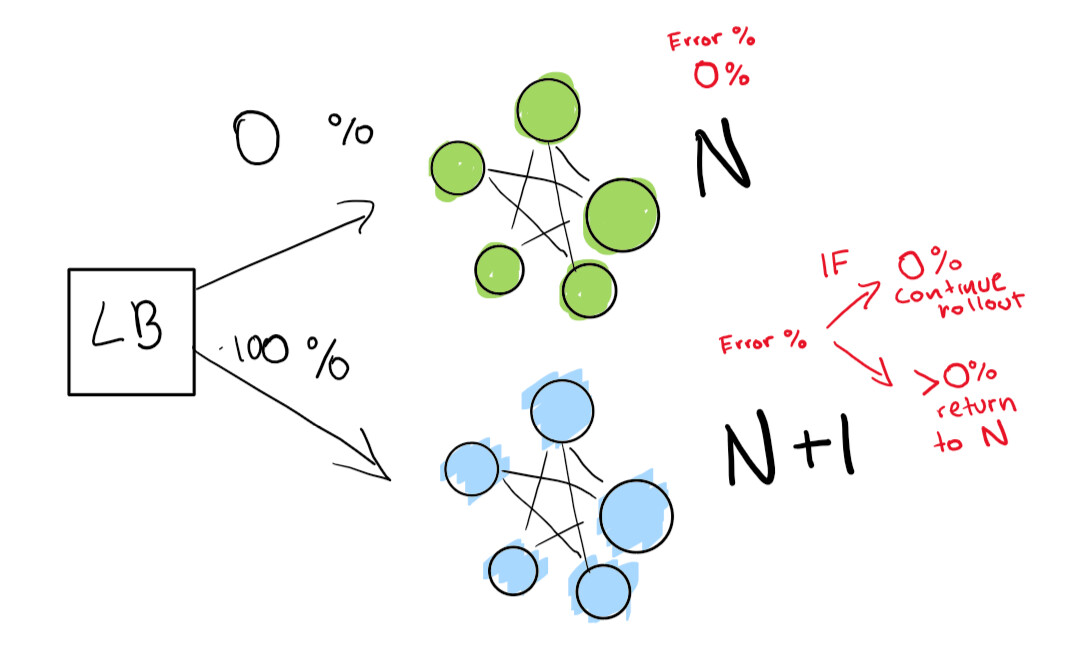
如果您想达到更高的水平,请自动执行蓝绿色部署中的所有操作。
异常检测和自动缓解
鉴于您具有集中式日志记录和良好的日志收集,您已经可以设置更高的目标。例如,主动预测故障。在监视器和日志中,会跟踪功能并构建各种图表-您可以提前预测出什么问题:
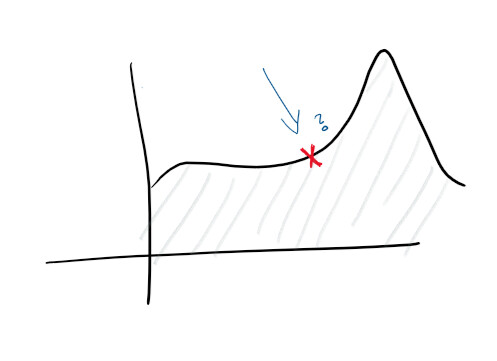
随着异常的发现,您开始研究服务发出的一些线索。例如,CPU使用率的峰值可能表明硬盘驱动器出现故障,而请求的峰值则意味着您需要扩展。这种统计数据使我们能够主动提供服务。
借助这种见解,您可以在任何维度上进行扩展,从而主动和被动地更改计算机,数据库,连接和其他资源的特征。
就这样!
如果要启动云服务,此优先级列表将为您节省很多麻烦。
原始文章的作者邀请读者发表评论并进行更改。本文以开源形式发布,作者在Github上接受拉取请求。
关于该主题还需要阅读什么: