如果您已经设计了一段时间的后端应用程序或数据库,那么您可能已经编写了执行分页查询的代码。例如-这样:
SELECT * FROM table_name LIMIT 10 OFFSET 40
事情是这样的?
但是,如果这是您进行分页的方式,那么我很遗憾地说您没有以最有效的方式进行分页。
你想和我吵架吗?您 不必 浪费 时间。Slack,Shopify和Mixmax已经在使用我今天要谈论的技巧。
至少说出一个开发商后端,这从来没有使用过
OFFSET,并LIMIT与分页执行查询。在MVP(最小可行产品,最小可行产品)和使用少量数据的项目中,此方法非常适用。可以这么说。
但是,如果您需要从头开始创建可靠而高效的系统,则应事先注意对此类系统中使用的数据库的查询效率。
今天,我们将讨论与分页查询执行引擎的广泛使用(很抱歉)实现相关的问题,以及在执行此类查询时如何实现高性能。
OFFSET和LIMIT有什么问题?
前面已经提到,
OFFSET和LIMIT他们完美地展示自己在你不需要工作,大量数据的项目。
当数据库增长到不再适合服务器内存的大小时,就会出现问题。但是,在使用此数据库时,必须使用分页查询。
为了使此问题表现出来,有必要出现一种情况,即在执行带有分页的每个查询时,DBMS会采取效率低下的全表扫描操作(同时可能发生数据插入和删除操作) ,并且我们不需要过时的数据!)。
什么是“全表扫描”(或“顺序表扫描”,即顺序扫描)?在此操作期间,DBMS顺序读取表的每一行(即表中包含的数据),并对照给定条件对其进行检查。已知这种类型的表扫描是最慢的。事实是,执行该命令后,会执行许多使用服务器的磁盘子系统的I / O操作。与处理存储在磁盘上的数据相关的延迟会加剧这种情况,并且将数据从磁盘传输到内存是一项资源密集型操作。
例如,您有100,000,000个用户的记录,并且正在使用该构造运行查询
OFFSET 50000000... 这意味着DBMS将必须加载所有这些记录(并且我们甚至不需要它们!),将它们放置在内存中,并且仅在那之后,才收到20条报告的结果LIMIT。
假设它看起来像是“从100,000中选择50,000至50020行”。也就是说,系统将首先需要加载50,000行才能执行查询。看看她要做多少不必要的工作?
如果您不相信我,请看一下我使用db-fiddle.com创建的示例。

db-fiddle.com
上的示例在字段的左侧,
Schema SQL有代码将100,000行插入数据库,在字段的右侧,显示了Query SQL两个查询。第一个很慢,看起来像这样:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
第二个是对相同问题的有效解决方案,例如:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
为了满足这些要求,只需单击
Run页面顶部的按钮。完成此操作后,让我们比较有关查询执行时间的信息。原来,低效查询的执行时间比第二次查询的执行时间至少长30倍(此时间因启动而异,例如,系统可能会报告第一个请求需要37毫秒才能完成,并且秒的执行-1毫秒)。
而且,如果有更多的数据,那么一切都会看起来更糟(为了验证这一点,请看我的示例,其中有1000万行)。
我们刚刚讨论的内容将使您对如何实际处理数据库查询有一些了解。
请记住,价值越大
OFFSET -请求将花费的时间更长。
应该使用什么代替OFFSET和LIMIT的组合?
除了组合之外
OFFSET,LIMIT值得使用根据以下方案构建的结构:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
它是基于游标的分页查询的执行。
代替本地存储当前电流
OFFSET并将LIMIT其发送到每个请求,有必要存储最后接收到的主键(通常是-a ID)和LIMIT,结果将提示类似于上述状态。
为什么?事实是,通过显式指定最后一个读取行的标识符,您可以告诉DBMS从何处开始寻找所需的数据。而且,由于使用了键,搜索将被有效地执行,系统将不必被超出指定范围的线分散注意力。
让我们看一下以下不同查询的性能比较。这是一个无效的查询。
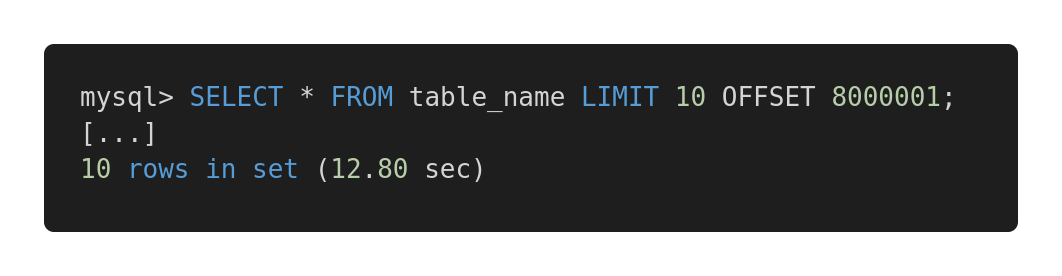
慢查询
这是此查询的优化版本。

快速查询
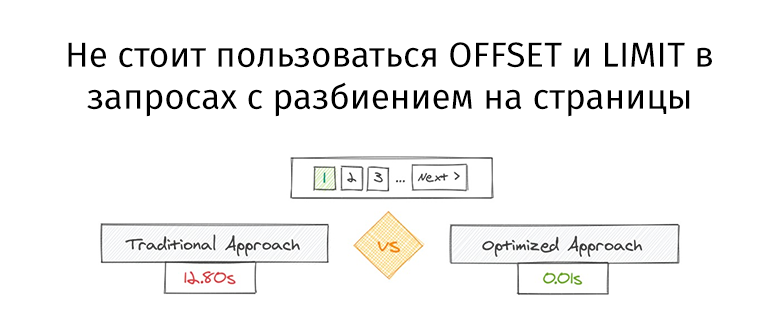
这两个查询返回的数据量完全相同。但是第一个花费12.80秒,第二个花费0.01秒。你觉得有什么不同吗?
可能的问题
为了使提出的查询执行方法有效地工作,表必须具有包含唯一顺序索引(例如整数标识符)的一列(或多列)。在某些特定情况下,这可以确定使用此类查询是否成功以提高使用数据库的速度。
自然,在设计查询时,您需要考虑表的体系结构的特殊性,并选择最能在现有表上显示的机制。例如,如果你需要在大量相关数据的查询工作,你可能会发现这条有趣的。
如果我们面临缺少主键的问题,例如,如果我们有一个具有多对多关系的表,那么使用
OFFSET和的传统方法肯定会LIMIT为我们工作。但是其应用程序可能导致执行潜在的缓慢查询。在这种情况下,即使您只需要使用它来组织分页的查询,我也建议您使用自动递增的主键。
如果您对此主题感兴趣-在这里,这里和这里-一些有用的材料。
结果
我们可以得出的主要结论是,无论数据库的大小如何,始终有必要分析查询的执行速度。在我们这个时代,解决方案的可伸缩性非常重要,如果您从某个系统的工作开始就正确地设计了所有内容,那么将来,这可以使开发人员免于遇到许多问题。
您如何分析和优化数据库查询?
