
我叫Alexander Deulin,我在MegaFon自己开发的“微服务工厂”的开发部门工作。我想告诉您有关公司环境中Tarantool高速缓存出现的棘手路径,以及我们如何从Oracle实现复制。我将立即说明,在这种情况下,高速缓存意味着具有数据库的应用程序。
Tarantool缓存
我们已经讨论了如何在MegaFon实施统一账单,我们不会对此进行详细介绍,但是现在该项目处于完成阶段。因此,仅提供一些统计信息:
完成任务后:
- 8000万订户;
- 3亿订户资料;
- 每天有20亿笔交易事件会改变余额;
- 250 TB的活动数据;
- > 8 PB档案;
- 所有这些都位于不同数据中心的5000台服务器上。
也就是说,我们正在谈论一个高负载的系统,其中每个子系统开始为8000万订户提供服务。如果之前有7个实例和条件水平缩放,那么现在我们切换到域。曾经有一个整体,但现在我们有了DDD。该API很好地覆盖了系统,分为子系统,但并不是到处都有缓存。现在,我们面临着这样一个事实,子系统会产生越来越大的负载。此外,出现了新的渠道,要求他们在95%的情况下,每个操作每秒向他们提供5000个请求,且延迟为50毫秒,并确保99.99%的可用性。
同时,我们开始创建微服务架构。

我们有一个单独的缓存层,每个子系统的数据都被放入其中。这使得组装复合物和将主系统与繁重的阅读工作隔离开来变得容易。
如何为封闭子系统建立缓存?
我们决定需要自己创建缓存,而不要依赖供应商。统一计费是一个封闭的生态系统。它包含许多微服务模式,这些模式具有大量API和自己的数据库。但是,由于封闭的性质,无法修改任何内容。
我们开始考虑如何处理主系统。当我们从某种总线接收数据时,事件驱动设计是一种非常流行的方法:这是一个Kafka主题,或者交换RabbitMQ。您还可以从Oracle获取数据:使用CQN(Oracle的免费工具)或Golden Gate,通过触发器获取数据。由于我们无法集成到应用程序中,因此无法使用直写和后写选项。
从消息分派器总线接收数据
我们真的很喜欢带有队列和消息管理器的选项。RabbitMQ和Kafka已在“统一帐单”中使用。我们试用了其中一种系统,并获得了出色的结果。我们从RabbitMQ接收所有事件并进行冷加载,数据量不是很大。
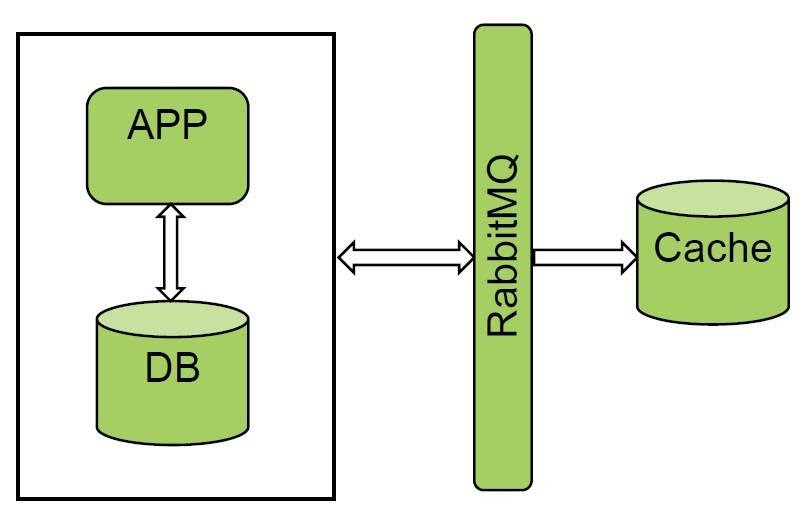
该解决方案效果很好,但并非所有系统都可以通知总线,因此此选项对我们不起作用。
从数据库检索数据:触发器
仍然存在一种从数据库中获取数据以填充缓存的方法。
最简单的选项是触发器。但是它们不适用于高负载应用程序,因为首先,我们修改了主系统本身,其次,这是另一个失败点。如果触发器突然无法写入某些临时板,则我们将完全退化,包括主系统。

从数据库检索数据:CQN
从数据库获取数据的第二个选项。我们使用Oracle,并且供应商目前仅支持一种免费工具-CQN,用于从数据库中检索数据。
该机制允许您订阅DDL或DML操作更改通知。那里的一切都很简单。有JDBC和PL / SQL样式通知。
JDBC意味着我们通知高级队列,并且此事件被发送到外部系统。实际上,需要一个外部OSI连接器。我们不喜欢该选项,因为如果我们失去与Oracle的连接,我们将无法读取消息。
我们选择PL / SQL是因为它允许我们拦截通知并将其存储在同一Oracle数据库中的临时表中。也就是说,通过这种方式,您可以提供一些事务完整性。
一切从一开始就运转良好,直到我们试用了相当多的基础。出现以下缺点:
- 基础上的事务负载。当我们从通知队列中截取消息时,需要将其放在基础中。即,写负载加倍。
- 它还使用内部高级队列。而且,如果您的主系统也使用它,则可能会争用队列。
- 我们在分区表上遇到了一个有趣的错误。如果一个提交关闭了100多个更改,则CQN不会捕获此类更改。我们在Oracle中打开了一张票,更改了系统参数-并没有帮助。
对于繁重的应用,CQN绝对不适合。对于小型安装,与某种词典一起使用,参考数据非常有用。
从数据库检索数据:Golden Gate
好老的金门仍然存在。最初,我们不想使用它,因为它是一种老式的解决方案,所以我们对系统本身的复杂性感到震惊。

在GG本身中,需要维护另外两个实例,而我们对Oracle的了解并不多。最初,这非常困难,尽管我们真的很喜欢该解决方案的可能性。
SCN + XID组合使我们能够监视事务完整性。事实证明该解决方案是通用的,它对可以接收所有事件的主系统影响很小。尽管该解决方案需要购买许可证,但是由于许可证已经可用,因此这对我们来说不是问题。而且,该解决方案的缺点包括复杂的实现以及GG是附加子系统的事实。
结论
从以上可以得出什么结论?
如果系统是封闭的,则需要研究负载的性质和使用方法,然后选择适当的解决方案。我们认为,最佳方案是事件驱动的设计,当我们在Kafka中通知主题时,消息代理将成为主系统。主题是黄金记录,其余数据由系统获取。对于我们领域中的封闭系统,GG是最成功的解决方案。
PIM-食品展示柜
现在,使用其中一种产品的示例,我将告诉您我们如何应用此解决方案。PIM是基于SID的产品展示。也就是说,这些都是当前与订户连接的所有订户产品。在此基础上计算费用并建立工作逻辑。
建筑
让我提醒您,在本文中,“缓存”表示应用程序和数据库的组合,这是Tarantool的主要使用模式。
PIM项目的特点是原始的Oracle主系统“很小”,只有100亿条记录。必须阅读。我们解决的最大问题是缓存预热。
我们从哪里开始?

前10张表给出了100亿条记录。我们想直接阅读它们。由于我们仅将热数据提交到缓存,而Oracle除其他外存储历史数据,因此我们必须设置where子句并提取这100亿个非平凡的任务。Oracle告诉我们不应该这样做:将处理器负载提高到100%。我们决定走另一条路。
但是首先,关于集群架构的几句话。
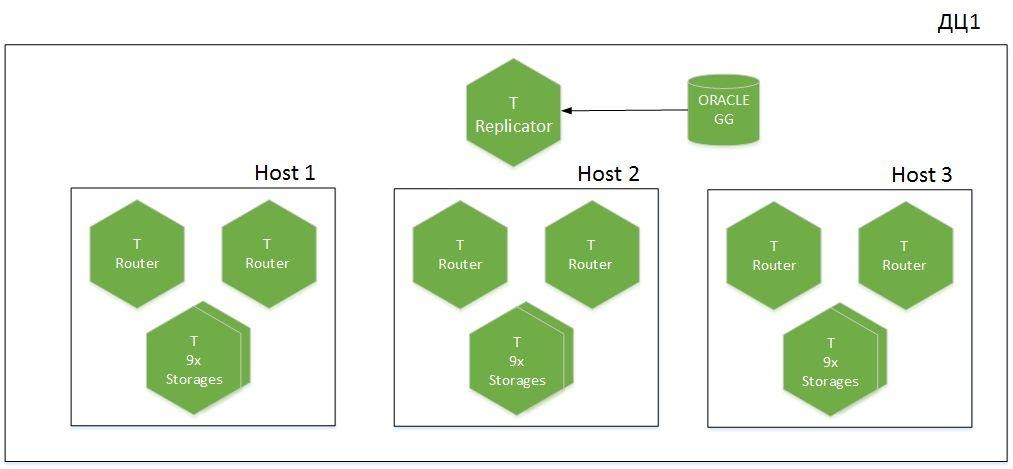
这是一个分片应用程序,分布在两个数据中心中的6个主机中有9个分片。我们有担当Replicator角色的Tarantool,该角色从Oracle接收数据,另一个名为Importer的实例用于冷启动。缓存中总共增加了1.1 TB的热数据。
冷启动
我们如何解决冷启动问题?事实证明一切都很微不足道。

整个机制如何运作?我们删除了where子句并阅读了所有内容。首先,我们启动重做日志流以实际从数据库接收在线更改。通过全面扫描,我们遍历了各个小节,并通过归一化和过滤批量获取了数据。我们保存更改,同时开始冷预热缓存,并将所有内容上传到CSV文件。缓存中运行着10个Importer实例,这些实例从Oracle中读取后,便将数据发送到Tarantool实例。为此,每个导入器都会计算所需的碎片并将数据本身放入必要的存储中,而无需加载路由器。
从Oracle加载所有数据后,我们将播放GG在这段时间内积累的线索流。当SCN + XID在主系统中达到可接受的值时,我们认为缓存已预热,并包括从外部系统读取的负载。
一些统计。在Oracle,我们大约有2.5 TB的原始数据。我们阅读了5个小时,然后将它们导入CSV。通过过滤和规范化加载到Tarantool中需要8个小时。在六个小时内,我们播放了从小径传来的累积日志。峰值速度从60万条记录/秒开始。最高可达一百万Tarantool以200K记录/秒的速度插入1.1 TB数据。
现在,对我们来说,冷预热大容量缓存已变得司空见惯,因为我们对Oracle的影响不大。

我们将加载I / O和网络,而不是基础负载,因此我们必须首先确保我们有足够的网络带宽裕度,在峰值时达到400 Mbps。
从Oracle到Tarantool的复制链如何工作
在设计缓存时,我们决定节省内存。我们删除了所有冗余,将五个表合并为一个表,并获得了一个非常紧凑的存储方案,但是却失去了对一致性的控制。我们得出的结论是,有必要重复Oracle的DDL。这使我们可以通过将SCN + XID存储在每个板的单独技术空间中来控制它们。通过定期检查它们,我们可以了解复制中断的位置,并且在出现问题的情况下,我们可以重新读取归档日志。
分片
关于逻辑数据存储的一些知识。为了消除Map Reduce,我们不得不引入额外的数据冗余并将字典分解到我们自己的存储中。我们故意这样做是因为我们的缓存主要用于读取。我们无法将其集成到主系统中,因为此应用程序将外部通道的负载与主系统隔离开来。我们从一个存储读取订户上的所有数据。在这种情况下,我们的写性能会下降,但是这对我们来说并不重要,字典不经常更新。
最后怎么着了?
我们为封闭系统创建了一个缓存。有一些过滤错误,但我们已经解决了。我们为出现新的高负载消费者做好了准备。去年夏天,出现了一个新系统,该系统每秒增加5万至1万个请求,我们没有将此加载到“统一帐单”中。我们还学习了如何准备从Oracle到Tarantool的复制,解决了在不加载主系统的情况下传输大量数据的问题。
我们还需要做什么?
这些主要是操作方案:
- 自动控制数据一致性。
- 制定Oracle Active-Standby切换方案,包括切换和故障转移。
- 从GG播放存档日志。
- — DDL- -. , DDL , .
- «»: ? https://habr.com/ru/article/470842/
- : Tarantool https://habr.com/ru/company/mailru/blog/455694/
- Telegram Tarantool https://t.me/tarantool_news
- Tarantool - https://t.me/tarantoolru