从处理大量信息和更有效地使用机器学习算法的能力到可以改善新药设计,蛋白质结构预测,生物有机体各种过程分析的定量(定性和定量)计算的量子建模算法,以及等等这些令人难以置信的观点今天受到了压倒性的信息炒作,这意味着重要的是要突出这种新技术的警告和挑战。
警告:本评论基于来自英国和瑞士的一组欧洲研究人员的文章(Carlos Outeiral,Martin Strahm,Jiye Shi,Garrett M. Morris,Simon C. Benjamin和Charlotte M. Deane。“计算分子生物学中的量子计算的前景”, WIREs计算分子科学,由Wiley Periodicals LLC出版,2020年。与复杂的数学模型相关的文章中最困难的部分将不包括在本评论中。但是材料起初很复杂,要求读者具备数学和量子物理学的知识。
但是,如果您打算开始研究量子技术在生物信息学中的应用,那么为了首先进入该话题,建议听M&S Decisions高级研究员Viktor Sokolov的简短演讲,其中概述了药物建模的一些现代问题:
介绍
自从高性能计算问世以来,算法和数学模型已用于解决生物科学中的问题-从研究人类基因组的复杂性到对生物分子的行为进行建模。今天,通常使用计算方法来分析和提取生物学实验中的重要信息,以及预测生物学对象和系统的行为。实际上,在25篇引用最多的科学论文中,有10篇涉及生物学中使用的计算算法[cf. 这里],包括量子建模[这里,这里,这里和这里],序列比对[这里,这里和这里]这里],计算遗传学[参见。此处]和数据处理中的X射线衍射[cf.在这里和这里]。
尽管取得了这些进展,但从使用现有计算技术解决问题的角度来看,生物学中的许多问题仍然无法解决。诸如预测蛋白质折叠,计算配体与大分子的结合亲和力或寻找最佳的大规模基因组比对等任务的最佳算法,需要的计算资源甚至超出了当今最强大的超级计算机。
这些问题的解决方案可能在于计算技术的范式转变。理查德·费曼(Richard Feynman)独立于1980年代[这里]和尤里·马宁[参见。这里]建议用量子力学效应,以创建一个新的,更强大的代计算机。
事实证明,量子理论是对物理现实的非常成功的描述,自20世纪初问世以来,它就引领了激光,晶体管和半导体微处理器等技术的发展。量子计算机使用最有效的算法,使用经典机器无法实现的操作。量子处理器的运行速度没有传统计算机快,但它们的工作方式完全不同,从而实现了空前的加速,避免了不必要的计算。例如,使用常规算法在任何现代超级计算机上计算平均药物分子的总电子波函数,所需的时间将比我们整个宇宙的时间更长。这里],即使是小型量子计算机也可以在几天内解决此问题。受到这样的量子优势承诺的鼓舞,工程师和科学家正在继续寻求量子处理器。但是,制造,管理和保护量子系统方面的技术难题异常复杂,并且最初的原型仅在最近十年出现。
重要的是要注意,建造量子计算机的技术问题并未阻止量子计算算法的发展。即使在没有硬件的情况下,也可以对算法进行数学分析,并且高性能量子计算机模拟器的出现以及过去几年中的早期原型已经使进一步的研究得以发展。
这些算法中的几种已经显示出有希望的生物学潜在应用。例如,一种用于估计量子相位的算法可以更快地指数计算特征值[请参阅。[这里],可用于了解蛋白质各部分之间的大规模相关性或确定图在生物网络中的中心位置。量子Harrow-Hasidim-Lloyd(HHL)算法[cf. [这里]可以比任何已知的经典算法更快地指数化某些线性系统,并且还可以应用统计学习方法,其自适应过程快得多,并且能够管理大量数据。
量子优化算法在蛋白质折叠和构象异构体选择领域以及与寻找最小值或最大值有关的问题中具有广泛的应用[参见。在这里]。最后,最近开发了一种技术来模拟量子系统,该系统有望例如产生对药物-受体相互作用的准确预测[参见参考资料]。此处]或参加对光合作用等复杂过程和化学机制的研究和理解[请参见。在这里]。量子计算可以像传统计算时代一样,极大地改变生物学的方法。
Google最近宣称具有量子至上性[cf.这里],尽管IBM对此有异议[cf. [这里]表示量子计算时代已经到来。有望在未来十年内使用量子效应执行经典计算机技术无法完成的计算的首批处理器[请参见参考资料]。在这里]。
在这篇评论中,我们将分解量子计算对计算生物学有希望的关键点。这些评论分析了量子计算在包括机器学习在内的各个领域的潜在影响。这里,这里和这里],量子化学[cf.这里,这里和这里]和药物合成[参见。在这里]。最近发表的还有NIMH生命科学中的量子计算研讨会的报告[请参见第10页。在这里]。
在这篇综述中,我们首先简要介绍量子计算的含义,并简要介绍量子信息处理的原理。然后,我们讨论了计算生物学的三个主要领域,其中量子计算已经显示出有希望的算法发展:统计方法,电子结构计算和优化。一些重要的话题将被搁置一旁,例如,可能影响序列分析的字符串算法。在这里],医学成像算法[参见。这里],微分方程的数值算法[[这里]和其他数学问题或分析生物网络的方法[这里]。最后,我们讨论了中长期量子计算对计算生物学的潜在影响。
1.量子信息处理
量子计算机有望解决生物科学中的问题,例如预测蛋白质-配体相互作用或了解蛋白质中氨基酸的共同进化。而且解决起来并不容易,但是要比使用任何现代计算机所能想象的快得多。但是,这种范式转换要求我们的思维方式发生根本变化:量子计算机与经典计算机大不相同。构成量子优势的物理现象通常是不合逻辑和违反直觉的,使用量子处理器需要对我们对编程的理解进行根本性的改变。在本节中,我们介绍了量子信息的原理以及如何对其进行处理以进行计算。
我们将解释信息在量子系统中的工作原理(以量子位存储)如何发生变化,以及如何使用量子门来操纵信息。像编程语言中的变量和函数一样,量子位和量子门定义了任何算法的基本元素。我们还将研究为什么在技术上建造量子计算机是一个极其困难的过程,以及有望在未来几年中使用的早期原型可以实现的目标。本介绍仅涵盖要点;要进行全面研究,请阅读Nielsen和Chuang的书[此处]。
1.1。量子算法的要素
1.1.1。量子信息:量子比特简介
表示量子计算的第一个问题是了解其如何处理信息。在量子处理器中,信息通常存储在量子位中,量子位是经典位的量子模拟。量子位是受磁场限制的物理系统,例如离子。此处]或偏振光子[请参见。这里],但通常是摘要中提到的内容。像薛定ding的猫一样,量子位不仅可以采用状态0或1,还可以采用两种状态的任意组合。当直接观察到一个量子位时,它将不再处于折叠成可能状态之一的叠加状态,就像打开盒子后薛定ding的猫死了还是活着一样。这里]。更重要的是,当多个量子位组合在一起时,它们可以变得相互关联,并且与其中任何一个的相互作用都会对整个集体状态产生影响。多个量子位之间的相关现象称为量子纠缠,是量子计算的基本资源。
在经典信息中,信息的基本单位是位,这是一个具有两个可识别状态的系统,通常表示为0和1。量子模拟(量子位)是一个两个状态的系统,其状态分别标记为|0⟩和|1⟩。我们使用狄拉克表示法,其中| *⟩表示量子态。经典信息和量子信息之间的主要区别在于,量子位可以处于状态的任何叠加|0⟩和|1⟩:
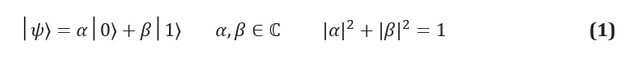
复数系数α和β被称为状态幅度,它们与量子力学中的另一个关键概念有关:物理尺寸的影响。由于量子位是物理系统,因此您始终可以提出一个协议来测量其状态。例如,如果状态|0⟩和|1⟩对应于磁场中电子的自旋状态,那么测量qubit的状态就是测量系统的能量。量子力学的假设规定,如果系统处于可能的测量结果的叠加中,则测量行为必须改变状态本身。叠加系统将在测量阶段崩溃。因此,测量破坏了量子位中振幅所携带的信息。
当我们考虑可能经历量子纠缠的多个量子位的系统时,就会产生重要的计算含义。纠缠是一种现象,其中一组量子位相关,并且对这些量子位中的一个进行任何操作都会影响所有量子位的整体状态。量子纠缠的一个典型例子是1935年提出的爱因斯坦-波多尔斯基-罗森悖论[cf.在这里]。考虑一个由两个量子位组成的系统,由于每个单独的量子位可以采用状态{|0⟩和|1⟩}的任何叠加,因此复合系统可以采用状态{|00⟩,|01⟩,|10⟩,| 11的任何叠加。 (}(因此,N个量子比特的系统可以采用二进制字符串,从{| 0 ...0⟩到| 1 ...1⟩}。系统的可能叠加之一是所谓的贝尔状态,其中的一种具有以下形式: 如果我们对第一个量子位进行测量,则只能观察到|0⟩或|1⟩,每个概率为1/2。对于单个量子位情况,这不会进行任何更改。如果第一个量子位的结果为|0⟩,则系统将崩溃为系统|01⟩,因此,对第二个量子位的任何测量将以概率1给出|1⟩。类似地,如果第一个量度为|1⟩,则第二个量子位的量度将为|0⟩。应用于第一个量子位的操作(在这种情况下,结果为“ 0”的测量)会影响随后测量第二个量子位时可以看到的结果。

纠缠的存在是有用的量子计算的基础。已经证明,任何不使用纠缠的量子算法都可以应用于经典计算机,而速度没有明显的差异。在这里和这里]。从直觉上讲,原因是量子计算机可以操纵的信息量。如果N量子位系统没有纠缠,则可以通过每个一位状态的幅度(即2N幅度)来描述其状态的2 N个幅度。但是,如果系统纠缠在一起,则所有振幅将是独立的,并且量子位寄存器将形成维向量。量子计算机通过多种操作来操纵大量信息的能力是量子算法的主要优势之一,并且比传统计算机技术以指数方式更快地解决了问题。
1.1.2。量子门
使用称为量子门的特殊操作来处理存储在量子位中的信息。量子门是物理操作,例如指向离子量子位的激光脉冲,或光子量子位必须通过的一组反射镜和分束器。但是,门通常被视为抽象操作。量子力学的假设对封闭系统中的量子门的性质施加了一些严格的条件,这使它们可以以unit矩阵的形式表示,unit矩阵是保持量子系统归一化的线性运算。
特别地,应用于N个量子位的纠缠寄存器的量子门相当于将矩阵相乘×每个输入向量2 N。量子计算机存储和执行大量信息的计算能力约为通过操纵N阶的多个元素,构成了其提供优于传统计算机的指数优势的能力的基础。
本质上,量子门是量子位系统中任何允许的操作。量子力学的假设对量子门的形状施加了两个严格的限制。量子算子是线性的。线性是一种数学条件,但它对量子系统的物理以及因此如何将其用于计算具有深远的影响。如果将线性算子应用于状态叠加,结果是各个国家,这是由运营商影响的叠加。在一个qubit中,这意味着: 线性运算符可以表示为矩阵,它们是简单的表,指示线性运算符对每个基本状态的影响。图1(c,d)显示了两个量子位和两个一位门之一的矩阵表示。 但是,并非每个矩阵都代表真实的量子门。我们期望应用于一组量子位的量子门将给出一组不同的实际量子位,特别是归一化的量子位(例如,在等式(3)中,我们希望
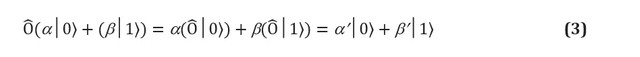
× 是完全有效的N量子比特量子门。
在经典计算中,一位只有一个非平凡的门:NOT门,它将0转换为1,反之亦然。在量子计算中,存在无限数量的2×2 ary矩阵,并且它们中的任何一个都是可能的单量子位量子门。量子计算的早期成功之一是发现,通过影响一个和两个量子位的一组通用门,可以实现多种可能性。这里]。换句话说,在给定任意量子门的情况下,有一个1比特位和2量子位的门电路可以任意精度驱动它。不幸的是,这并不意味着近似有效。大多数量子门只能由我们的通用集中的指数门数来近似。即使这些门可以用来解决有用的问题,它们的实现也将花费成倍的时间,并且会抵消任何量子优势。图1 (a)比较经典比特与量子比特或“量子比特”。虽然经典位只能采用0或1这两个状态之一,但是量子位可以采用以下形式的任何状态:

...通常使用Bloch球面表示法描绘单个量子位,其中θ和understood被理解为单位半径球面中的方位角和极角。(b)离子阱量子位的示意图,这是实验量子计算中最常用的方法之一。离子(通常)通过电磁场保持在高真空中,并暴露于强磁场中。根据塞曼效应将超精细能级分开,并将两个选定的能级选择为状态|0⟩和|1⟩。量子门是由适当的激光脉冲产生的,通常涉及其他电子能级。该图改编自[参见。在这里]。(c)实现X或受控负量子(CNOT)的量子电路图。
显示了布洛赫球面的表示形式和变化。(d)产生贝尔状态的量子电路使用Hadamard门和CNOT(受控否定)门。轮廓中间的虚线表示应用Hadamard阀后的状态。
1.2。量子硬件
量子算法只有在正确的量子硬件上运行,才能解决有趣的问题。关于基于俘获离子的量子处理器的创建,有许多竞争性提议[请参见。这里],超导电路[参见。这里]和光子设备[请参见。这里]。但是,它们都面临一个共同的问题:可能从字面上破坏计算过程的计算错误。量子计算的基础之一是发现可以用量子纠错码消除这些误差。不幸的是,这些代码还要求极大地增加量子位的数量,因此需要显着的技术改进以实现容错能力。
有许多错误源可能会影响量子处理器。例如,量子位与其环境的连接会导致系统崩溃为经典状态之一-这一过程称为退相干。... 微小的波动可以改变量子门,最终将导致与预期不同的结果。迄今为止,最容易出错的门已被记录在离子阱处理器中,每错误发生一次的频率一个单比特的门,两个比特的门的错误率为0.1%[此处和此处]。为了进行比较,谷歌最近的一项工作报告说,在超导处理器中,单量子位门的保真度为0.1%,两量子位门的保真度为0.3%[请参见参考资料]。在这里]。考虑到一个网关的故障会破坏计算,因此很容易看到,错误的传播会使经过一小部分元素的计算变得毫无意义。
量子计算的主要方向之一是量子纠错码的发展。在1990年代,几个研究小组证明,只要门错误率低于某个阈值(取决于代码),这些代码就可以实现容错计算。这里,这里,这里和这里]。表面编码是最流行的方法之一,可以以接近1%的错误率运行[请参见参考资料]。在这里]。
不幸的是,量子纠错码需要大量的实际物理量子位来对用于计算的抽象逻辑量子位进行编码,并且这种开销随误差率而增加。例如,用于素数分解的量子算法[参见。[这里]可以使用约4000 qubit悄悄地分解2000位数字,并且在16 GHz下,此过程大约需要一天的工作。假设错误率为0.1%,使用表面代码纠正环境错误的相同算法将花费数百万个量子位和相同的时间[参见。这里]。考虑到受控可编程量子处理器的当前记录为53量子比特[请参见。在这里],在这个研究方向上还有很长的路要走。
许多小组都在努力开发可在所谓的中型噪声量子处理器上运行的算法。在这里]。例如,变分算法将经典计算机与小型量子处理器结合在一起,执行大量的短量子计算,这些运算可以在噪声变得明显之前完成。
这些算法通常使用参数化的量子电路来执行特别困难的任务,并使用经典计算机来优化参数。解决方法是一个减少错误的区域,在该区域中,除了实现容错能力外,还尝试以最小的努力来最小化错误,以驱动较大的栅极电路。有许多方法,包括使用其他操作来丢弃有错误的运行[请参见。此处]或操纵错误率以推断出正确的结果[cf.这里和这里]。尽管主要应用将需要非常大的容错量子计算机;未来十年内可用的设备有望解决这些问题[请参见 在这里]。
2.统计方法和机器学习
在计算生物学中,目标通常是收集大量数据,统计学方法和机器学习是关键技术。例如,在基因组学中,隐马尔可夫模型(HMM)被广泛用于注释有关基因的信息[参见。在这里];在药物发现中,已经开发出广泛的统计模型来评估分子特性或预测配体-蛋白质结合[参见。在这里];在结构生物学中,深层神经网络已被用来预测蛋白质的连接[参见。这里]和二级结构[见。这里],以及最近的三维蛋白质结构[请参见。在这里]。
训练和开发此类模型通常需要大量计算。机器学习最新进展的主要催化剂是认识到通用图形处理单元(GPU)可以极大地加快学习速度。通过为机器学习提供指数级更快的算法,量子计算模型可以在关注科学问题的应用中引起类似的兴趣。
在本节中,我们将解释量子计算如何加速许多统计学习方法。
2.1。量子机器学习的优缺点
我们首先看一看量子计算机为机器学习带来的好处。除了理想的例子,量子计算机最多只能学习经典计算机[cf. 在这里]。但是,从原则上讲,它们可以比传统的同类产品更快,并且能够处理更多的数据。例如,人类基因组包含30亿个碱基对,可以存储在1.2×经典位-大约1.5 GB。N个量子位的寄存器包括幅度,每个幅度都可以通过使用适当的归一化因子将第k个幅度设置为0或1来代表经典位。因此,人类基因组可以约34个量子位存储。虽然无法从量子计算机中提取此信息,但是在准备好某种状态之前,可以在其上执行某些机器学习算法。更重要的是,将寄存器大小增加一倍至68量子位,就为存储世界上每个活人的完整基因组留出了足够的空间。如此大量的数据的呈现和分析甚至与小型容错量子计算机的功能也完全一致。
处理此信息的操作也可以成倍地加快。例如,多种机器学习算法仅限于协方差矩阵的长期求反。在矩阵的尺寸上 但是,由Harrow,Hassidim和Lloyd提出的算法[cf. 在这里],可以将矩阵反转为在某些情况下。关键的见解是,与图形加速器不同,图形加速器通过大规模并行性来加速计算,而量子算法则具有直接使用的计算算法复杂的优势。在某些情况下,特别是在当前指数加速的情况下,中型量子计算机可以解决仅适用于当今最大的经典超级计算机的学习问题。
改进的数据存储和处理具有第二个好处。神经网络的优势之一是它们能够找到简明的数据表示形式[参见。这里]。由于量子信息比经典信息更通用(毕竟,经典位的状态可细分为本征态|0⟩和|1⟩或一个量子位),因此量子机器学习模型比经典模型可以更好地吸收信息... 另一方面,具有对数时间复杂度的量子算法也可以提高数据机密性[参见。在这里]。由于训练模型需要和 需要进行矩阵重建,对于足够大的数据集,虽然仍然可以对模型进行有效的训练,但无法恢复大部分信息。在生物医学研究的背景下,这可以在确保机密性的同时促进数据交换。
不幸的是,尽管纸上的量子机器学习算法可以大大优于传统的机器学习算法,但仍然存在实际困难。量子算法通常是将输入转换为输出的子例程。问题恰好出现在这两个阶段:如何准备足够的输入以及如何从输出中提取信息[请参见。在这里]。例如,假设我们正在使用HHL算法[请参见。这里]求解形式的线性系统... 在子程序的末尾,则该算法将输出该量子位处于以下状态寄存器: 这里
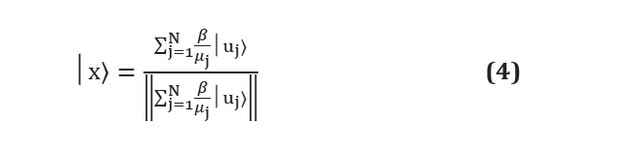
和 是A的特征向量和特征值 -第j个系数 用A的特征向量来表示,分母只是一个归一化常数。可以看出,这对应于系数,它们以各种状态的幅度存储为 并且不能直接访问。量子位寄存器的测量将导致其陷入本征向量状态之一,并重新估计每个状态的幅度。 需要测量 ,这首先超过了量子算法的任何优势。
HHL和许多其他算法仅对计算解决方案的全局属性(例如期望值)有用。换句话说,除非我们只对解决方案的整体性质感兴趣,否则HHL无法为方程系统提供对数解或以对数时间求矩阵求逆,可以通过使用几个物理上可观察的测量结果来获得该性质。这限制了某些子例程的使用,但是有很多建议可以解决此问题。
将信息输入量子计算机是一个更大的问题。大多数量子机器学习算法都假设量子计算机可以访问叠加状态的数据集。例如,有一个qubit寄存器,其形式为: --bin(j)是充当索引的状态,并且

是相应的幅度。例如,这可用于存储向量或矩阵的元素。原则上,有一个量子电路可以通过以例如| 0 ...0⟩状态起作用来准备该状态。但是,它的实现可能非常困难,因为我们预计随机量子态的近似将成指数级困难,并将破坏任何可能的量子优势。
大多数量子算法都假定访问量子随机存取存储器(QRAM)[请参见。这里],它是一种能够构造此叠加的黑匣子设备。尽管已经提出了一些图纸[参见。这里和这里],据我们所知,尚无工作装置。而且,即使有这样的设备可用,也无法保证它不会产生超过量子算法优势的瓶颈。例如,最近针对QRAM的基于架构的建议[cf. [这里]显示了不可避免的线性状态代价,它超过了任何登录时间算法。最后,即使QRAM不增加任何成本,仍将需要进行经典的预处理-对于基因组示例,将需要访问12艾字节的经典存储。
最后,我们必须强调,量子机器学习算法并非没有实际应用中最常见的问题之一:缺少相关数据。大量数据的可用性对于AI在分子科学中的许多实际应用(例如从头分子开发)的成功至关重要。在这里]。但是,随着科学技术的发展,例如自我管理实验室的出现,量子算法的功能可能会很有用。在这里]提供越来越多的数据。
量子机器学习具有改变我们处理和分析生物学数据的方式的潜力。但是,当前实施量子技术的实际问题仍然很重要。
2.2。量子机器学习算法
2.2.1。没有老师学习
无监督学习包括从无标签数据集中提取信息的几种技术。在生物学中,新一代测序和国际合作的兴起刺激了数据的收集,这些方法已得到广泛应用,例如,用于鉴定生物分子家族之间的关系[参见。此处]或注释的基因组[参见。在这里]。
最受欢迎的无监督学习算法之一是主成分分析(PCA),它试图通过找到最大化方差的特征的线性组合来降低数据的维数。这里]。此方法广泛用于各种高维数据集,包括RNA微阵列和质谱数据[请参见。在这里]。一组研究人员提出了一种PCA的量子算法[请参见。在这里]。基本上,此算法在量子计算机中建立数据协方差矩阵,并使用称为量子相位估计的子例程以对数时间计算特征向量。算法的输出是 以下形式的叠加状态:

是第j个主要成分,并且 -对应的特征值。由于PCA对大特征值感兴趣,大特征值是方差的主要成分,因此最终状态测量将以高概率给出合适的主成分。多次重复该算法将提供一组核心组件。该过程能够减小可存储在量子计算机中的大量信息的维数。
还提出了一种量子算法,用于分析拓扑数据的一种特定方法,即稳定的同源性[参见。在这里]。拓扑数据分析尝试使用数据集几何中的拓扑属性来提取信息;例如,在数据聚合研究中就使用了它。这里]和网络分析[请参见。在这里]。不幸的是,最好的经典算法在问题的维度上具有指数依赖性,这限制了它的应用。Lloyd等人的算法。还使用量子相位估计例程以指数方式加速矩阵对角化,从而达到复杂性... 进行拓扑分析的有效算法的存在可以刺激其在生物科学问题分析中的应用。
2.2.2。监督学习
监督学习是指可用于基于标记数据进行预测的一组方法。目标是建立一个可以分类或预测不可见示例属性的模型。监督学习在生物学中被广泛使用,以解决诸如预测配体对蛋白质的结合亲和力等各种问题[参见。此处]和使用计算机诊断疾病[请参见。在这里]。让我们看一下三种监督学习方法。
支持向量机(英语支持向量机-SVM)是一种机器学习算法,可找到最佳的超平面分离数据类。SVM已在制药行业中广泛用于对小分子数据进行分类[cf. 在这里]。根据内核,SVM培训通常需要 之前 ... 伦贝斯特[见。[在这里]提出了一种量子算法,该算法可以用多项式核训练SVM。,后来又扩展到了径向基函数(RBF)的核心[请参见。在这里]。不幸的是,鉴于量子运算仅限于线性运算,因此尚不清楚如何实现在SVM中广泛使用的非线性运算。另一方面,量子计算机允许其他类型的原子核无法在经典计算机中实现。在这里]。
高斯过程回归(GP)是一种通常用于构建替代模型的技术,例如在贝叶斯优化中[请参见第134页。在这里]。 GP还广泛用于创建药物特性的定量构效关系(QSAR)模型。此处],最近还用于对分子动力学建模[请参见。在这里]。 GP回归的缺点之一是高价值协方差矩阵的求逆。赵和同事[参见。在这里]建议对线性系统使用HHL算法对该矩阵求逆,以实现指数加速(只要矩阵稀疏且条件良好)-这通常是通过协方差矩阵实现的。更重要的是,此算法已扩展为计算极限可能性的对数[cf.这里],这是超参数优化的重要步骤。
计算生物学中最常用的方法之一是隐马尔可夫模型(HMM),它广泛用于计算基因注释和序列比对[cf.这里]。该方法包含许多隐藏状态,每个隐藏状态都与一个马尔可夫链相关联。隐藏状态之间的转换导致基础分布的变化。基本上,HMM无法直接在量子计算机中实现:采样需要某种会破坏系统的测量。但是,有一种关于开放量子系统的表述,即与环境接触的量子系统,它允许使用马尔可夫系统。在这里]。虽然尚未提出用于训练HMM的经典Baum-Welch算法的改进建议,但已发现量子HMM具有更高的表达力:它们可以再现具有较少隐藏状态的分布[cf.这里]。这可能导致该方法在计算生物学中的广泛应用。
2.2.3。神经网络与深度学习
发现多层人工神经网络可以检测原始数据中的复杂结构,刺激了机器学习的最新发展。在这里]。深度学习已开始渗透到每一个科学领域,并且在计算生物学中,其进步包括对蛋白质键的准确预测。这里],改善了某些疾病的诊断[参见。这里],分子设计[cf. 这里]和建模[请参见。在这里和这里]。
鉴于神经网络研究的重大进展,为开发可以推动技术进一步发展的量子类似物所做的大量工作已经完成。
人工神经网络的名称通常是指神经网络的多层感知器,其中每个神经元均采用其输入的加权线性组合,并通过非线性激活函数返回结果。开发量子模拟的主要挑战是如何使用线性量子门实现非线性激活函数。最近有很多建议,一些想法包括度量[cf.这里,这里和这里],耗散量子门[这里],具有连续变量的量子计算[此处]以及用于构造模拟非线性的线性门的附加量子位的介绍[请参见。在这里]。这些方法旨在实现一种量子神经网络,该量子神经网络由于量子信息的强大功能而有望比传统神经网络更具表现力。尽管重点放在这些模型的可能增强的表达能力上,但在量子计算机中按比例缩放多层感知器训练的优缺点尚不清楚。
最近的大量工作集中在Boltzmann机器上,这是可以用作生成模型的递归神经网络。训练后,他们可以生成类似于训练集的新模式。
生成模型具有重要的应用,例如,在分子设计从头[cf.在这里和这里]。尽管Boltzmann机器功能非常强大,但必须解决从Boltzmann分布中采样的复杂问题才能计算梯度并进行训练,这限制了它们的实际应用。已经使用D-Wave机器提出了量子算法[请参见。此处,此处和此处]或电路算法[请参见。在这里]; 来自Boltzmann分布的样本比经典样本中的样本快两倍。在这里]。
最近,基于系统的热化,提出了一种启发式算法,用于有效训练量子玻尔兹曼机。在这里]。此外,在某些工作中,提出了生成对抗网络(GAN)的量子实现[参见。这里,这里和这里]。这些发展涉及随着量子计算硬件的发展而改进生成模型。
3.量子系统的有效仿真
根据这些模型,化学反应受电子转移的调节。化学反应以及化学实体之间的相互作用也受电子分布及其形成的自由能态的控制。诸如预测配体与蛋白质的结合或了解酶的催化途径之类的问题归结为了解电子环境。不幸的是,对这些过程进行建模非常困难。计算电子系统能量的最有效算法是完全配置相互作用(FCI),它随电子数量成指数比例增长,甚至具有几个碳原子的分子也几乎无法用于计算研究[参见。这里]。尽管有许多近似方法,但在密度泛函理论的出版物中有深入而广泛的描述[请参见。这里和这里],他们可以不精确且在许多感兴趣的情况下,如瞬态响应状态的模拟[比照竟然硬生生失败在这里]。用于研究电子结构的准确而有效的算法将提供对生物过程的更好理解,也为开发下一代生物相互作用开辟了机会。
最初,提出了量子计算机作为对量子系统进行更有效建模的方法。在1996年,塞思·劳埃德(Seth Lloyd)证明了某些类型的量子系统是可能的[这里],而十年后,阿伦·阿斯普鲁·古斯克和他的同事发现,化学系统是这样的一个情况下[点击这里]。在过去的二十年中,对化学系统的微调建模方法进行了大量研究,可以计算出研究兴趣的性质。
3.1。量子模拟的优缺点
原则上,量子计算机能够有效地解决完全相关的电子结构问题(FCI方程),这将是准确估计结合能以及模拟化学系统动力学的第一步。古典计算化学几乎只专注于近似方法,例如,这些方法可用于估算小分子的热化学量[在此]],但是对于与断开或形成键相关的过程可能还不够。相反,量子处理器可以通过直接对角化FCI矩阵来解决电子问题,从而在一定的基础范围内给出准确的结果,从而解决由于分子过程物理学的不正确描述(例如配体极化)而引起的许多问题。 ...此外,尽管最初的假设仍然很重要,但与经典方法不同,它们不一定需要迭代过程。
尽管没有对量子计算机进行深入研究,但它们也克服了经典计算中所需的极限近似。例如,在不存在Born-Oppenheimer近似[此处]的情况下,现实空间中的量子模拟公式自动考虑了核波函数。这使人们能够研究已知对DNA突变很重要的某些系统的非绝热作用[参见。这里]和许多酶[的作用机制在这里。量子计算在相对论系统建模中的应用也已经提出[参见。[这里],对于研究出现在许多酶活性中心的过渡金属非常有用。
在Reicher和同事的一篇文章中[请参阅此处]揭示了用于在量子计算机中计算电子结构的时标的概念。作者考虑了固氮酶的辅因子FeMo,其固氮机理尚未研究,而且过于复杂,无法使用现代计算方法进行研究。 FeMoCo的最低基准FCI计算将花费几个月的时间,并且要达到当今最高等级的大约2亿量子比特。但是,这些估计必须随着技术的飞速发展而改变。自发布以来的三年中,算法的进步已经将时间要求减少了几个数量级[参见。这里]。除了更强大的电子结构方法外,最近还研究了现代近似方法的快速版本[cf.在这里和这里]可以大大加快原型制作的速度,这可能是有用的,例如,在研究酶促反应的反应坐标时,这是计算酶学的一个问题[这里]。此外,通过更好地了解通过访问完全相关的计算或访问可改善参数化的更快带宽所催化的分子间相互作用,量子建模可以显着改善非量子建模技术,例如力场。
需要注意的最后一点是,与其他算法研究领域(例如,使用量子机学习)不同,有许多短期量子仿真算法可以在不需要的,预先存在的硬件上运行。全世界许多实验小组都报告了这些算法的成功演示[此处,此处,此处和此处]。
不幸的是,量子系统建模也有一些缺点。如上所述,从量子计算机提取信息非常困难。重建整个波动函数比以经典方式计算它要困难得多。这是化学问题的重要缺点,在化学问题中,基于电子结构的争论是理解的主要来源。但是,与机器学习相比,优点远大于缺点,并且量子模拟有望成为实用量子计算的第一个有用的应用之一。在这里]。
3.2。容错量子计算
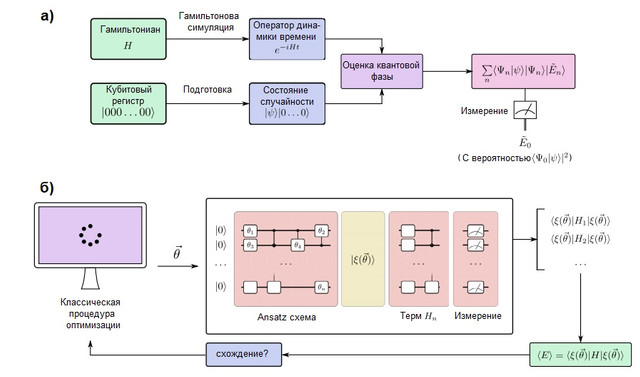
图2. (a)容错量子计算机中的量子模拟算法。量子位分为两个寄存器:一个在状态下准备,类似于目标波函数,而另一个保持状态 ... 量子相位估计(QPE)算法用于查找时间演化算子的特征值,这是使用汉密尔顿建模方法制备的。在进行QPE之后,量子计算机的测量给出了基态能量的概率所以准备猜测的状态很重要 与真波函数具有非零重叠。(b)短期量子计算机中的变分量子模拟算法。该算法将量子处理器与经典的优化例程结合在一起,可以执行几个足够快的短期运行,从而避免错误。量子计算机准备猜测状态取决于多个参数的量子ansatz链... 哈密顿量的各个项是一个接一个地测量的(或使用更高级的策略在通勤组中测量),从而给出了特定参数向量的预期能量的估计值。然后,通过经典优化过程对参数进行优化,直到收敛为止。除量子模拟外,变分方法已扩展到许多算法问题。
可以模拟大型化学系统的量子计算机必须具有容错性,以便能够执行任意深度的算法而不会出错。这种量子计算机能够通过将其电子的行为映射到其量子位和量子门的行为来模拟化学系统。量子建模过程从概念上讲非常简单,如图2(a)所示。我们将准备一个可以存储波动函数并实现哈密顿量unit演化的量子位寄存器使用哈密尔顿建模方法,将在下面进行讨论。有了这些元素,称为量子相位估计的量子子程序便能够找到系统的特征向量和特征值。即,如果qubit寄存器最初处于状态|0⟩,则最终状态将是: 换句话说,最终状态是特征值的叠加

和特征向量 系统。然后以概率测量基态...为了最大程度地提高这种可能性,将基线设置为易于准备但也希望与实际基态相似的物理激励状态。一个典型的例子是Hartree-Fock状态,尽管对于强相关的系统还探索了其他想法[请参见参考资料]。在这里]。
有一个分子代表电子的两种常用方法:基于网格和轨道或基本方法(见麦卡德尔和同事们一个完整的故障[这里])。在基集方法中,电子波函数表示为电子轨道的Slater行列式之和,可以直接与qubit寄存器进行比较[此处和在这里]。这需要选择基础和电子积分的初步计算。另一方面,在网格方法中,该问题被公式化为网格中常微分方程的解。基于网格的建模的优点是不需要Bourne-Oppenheimer逼近或基集。但是,它们并不是自然反对称的,这是量子力学的Pauli原理所要求的,因此有必要使用排序过程提供反对称性[此处]。在化学动力学模拟的背景下已经讨论了基于网格的方法[cf.此处]并计算热速率常数[参见。这里]。尽管存在差异,但量子建模工作流程是相同的,如图2所示。
还有几种构造运算符的方法... 我们将介绍最简单的技术Trotterization,也称为产品配方[p。在这里]; 有关完整概述,请参见[此处和此处]。小量化的前提是分子哈密顿量可以作为描述一电子和二电子相互作用的项之和而分裂。如果是这样,那么操作员可以在使用罗特在哈密顿每个术语对应的运营商的角度来实施-铃木式[这里]: 例如,在第二量化,在该表达式中的每个术语将具有形式或,其中是湮没和产生算符,分别。Whitfield和他的同事已经给出了表示这些术语的显式,详细的模式构造。在这里]。计算成员后
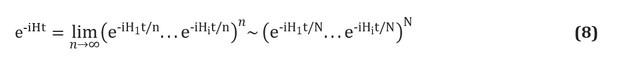

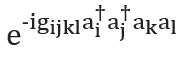
 和 被称为电子积分,数量完全确定。您也可以使用更高阶的Trotter – Suzuki公式来减少错误。还有许多其他汉密尔顿建模技术。强大而复杂的技术的例子有肘形化[这里]和量子信号处理[请参见参考资料]。[这里],它具有最佳渐近缩放比例,尽管尚不清楚这是否会带来更好的实际应用。
和 被称为电子积分,数量完全确定。您也可以使用更高阶的Trotter – Suzuki公式来减少错误。还有许多其他汉密尔顿建模技术。强大而复杂的技术的例子有肘形化[这里]和量子信号处理[请参见参考资料]。[这里],它具有最佳渐近缩放比例,尽管尚不清楚这是否会带来更好的实际应用。
4.优化问题
计算生物学和其他学科中的许多问题都可以表述为找到复杂的多维函数的全局最小值或最大值。例如,据信蛋白质的天然结构是其自由能超表面的整体最小值[参见。在这里]。在另一个领域,在相互作用蛋白或生物物体的网络中识别基团等同于找到节点的最佳子集。这里]。不幸的是,除了一些简单的系统之外,优化问题通常非常复杂。尽管有用于找到近似解的启发式方法,但它们通常仅给出局部最小值,并且在许多情况下,甚至启发式方法也无法确定。已经详细研究了量子计算机加快解决此类优化问题或找到更好解决方案的能力。
量子计算机中的优化主题很复杂,因为量子计算机是否可以提供任何类型的加速通常并不明显。在本节中,我们将概述一些量子优化的思想。但是,与例如量子模拟相比,改进的保证尚不十分明确,从长远来看,这是有益的。
4.1。量子处理器中的优化
由于D-Wave机器的存在,量子绝热优化是最流行的优化方法之一。这里]最初实现此方法。绝热量子计算[此处]基于量子力学的绝热定理[cf.这里]。根据该定理,如果系统准备成哈密顿量的基态,并且该哈密顿量变化很慢,则该系统将始终保持其瞬时基态。通过将问题(例如我们希望最小化的评分函数)编码为哈密顿量,然后从可以在其基态下简单准备的某些原始系统逐步发展为该哈密顿量,可以将其用于执行计算。在一般情况下,绝热演化表示如下: 这里

和 -这样的功能 和 持续一定时间T。例如,我们可以考虑使用 和 ...已经有很多论文专门讨论了绝热算法的执行时间,但是一般的启发是绝热演化过程中执行时间与最小光谱间隙(基态和第一激发态之间的最小能量差)的平方成反比。...人们认为,绝热量子计算(以及一般而言,量子计算)无法有效解决一类NP完全问题,或者至少这些方法都没有经过严格的测试[请参见参考资料]。在这里]。
原则上,绝热量子计算等效于通用量子计算[cf.在这里]。只有当进化允许非随机性时,这种普遍性才会发生,这意味着哈密顿量在进化的某个点具有非负的非对角线元素。D-Wave Systems Inc.商业化的绝热量子计算的最受欢迎的实验实现。,使用随机哈密顿量,因此不是通用的。在专业文献中,人们可能会担心这种量子计算的变化可能会被经典地模拟[此处],这意味着指数加速可能是不可能的。尽管存在这些担忧,但该技术已被广泛用作元启发式优化技术,并且最近显示出其性能优于模拟退火[请参见参考资料]。在这里]。
已经在绝热模型之外研究了量子优化。 e量子近似优化算法(QAOA)[cf.这里,这里和这里是一种量子计算机中的变分优化算法,在文献中引起了极大的兴趣。 QAOA已经在量子处理器中进行了几种实验性的实现,例如[参见。这里]图3.图3 (a)中执行简化的蛋白质折叠问题的绝热量子计算机的仿真描述这里]。颜色编码特定二进制字符串的十进制对数概率。在计算结束时,两个最低能量的解决方案的测量概率接近0.5。进化永远不会在有限的时间内完全绝热,而其他二进制字符串具有剩余的测量概率。(b)

量子计算的绝热过程的描述。驱动量子位的电势变化缓慢,导致其旋转。请注意,Bloch球面表示不完整,因为它没有显示量子优势所需的不同量子位之间的相关性。在演化的最后,量子位系统处于经典状态(或经典状态的叠加),表示具有最低能量的解决方案。(c)绝热量子演化过程中的能级。确保准绝热进化所需的时间由水平之间的最小能量差决定,这由虚线表示
4.2。蛋白质结构预测
没有基质的蛋白质结构的预测仍然是计算生物学中一个主要的未解决的问题。该问题的解决方案将在分子工程和药物设计中得到广泛应用。根据蛋白质折叠假说,蛋白质的天然结构被认为是其自由能的整体最小值[参见。这里],尽管有许多反例。考虑到即使是小的肽也可利用的巨大构象空间,详尽的经典模拟是无法解决的。但是,许多人想知道量子计算是否可以帮助解决这个问题。
量子计算文献集中在蛋白质晶格模型上,其中肽被建模为自推式晶格结构,尽管最近还开始在计算实践中应用其他几种模型[cf.在这里]。每个晶格位点对应一个残基,空间相邻位点之间的相互作用有助于能量功能。能量接触有几种方案,但在量子应用中仅使用了两种方案:疏水极性模型[参见。这里],只考虑两类氨基酸,以及Miyazawa-Jernigan模型[cf.这里],包含每对残基的相互作用。尽管这些模型明显简化了,但它们对蛋白质折叠提供了实质性的见解。在此],并已被建议作为研究构象空间的粗略工具,然后再进行进一步详细的细化[参见。在这里和这里]。
几乎所有的工作都集中在绝热量子计算上,因为即使模型肽也需要大量的量子位,而D-Wave量子机器是当今最大的量子设备。
但是,在Fingerhat及其同事最近发表的一篇文章中[请参见这里试图描述QAOA算法的使用。如果蛋白质晶格问题被编码为汉密尔顿算子,则这两种方法都具有相似的特性。 Perdomo首先考虑了这种方法[请参见。这里],建议使用qubit寄存器编码具有N边的D维立方格上的N个氨基酸的直角坐标,能量函数以哈密顿量表示,该术语包含奖励与蛋白质接触的术语:保留一级结构并避免氨基酸匹配。在这篇具有里程碑意义的文章之后不久,又出现了另一篇文章,讨论了二维晶格的更有效位模型的构建[cf.在这里]。
这些编码在2012年Perdomo及其同事[参见。这里]在D-Wave量子机器上计算了PSVKMA肽的最低能量构象。最近,Babay的研究团队为3D模型扩展了旋转和菱形编码,并引入了算法改进,从而降低了汉密尔顿编码的复杂性和移动速度。在这里]。他们使用D-Wave 2000Q处理器确定方格上Higoline(10个残基)和立方格上色氨酸(8个残基)的基态,这是迄今为止研究的最大肽。这些实验实施方案使用其中一部分肽被固定的方法。由于研究的可能性,这允许将大问题引入量子计算机研究的问题参数的数量。
在晶格模型中找到最低能量的构象是一个困难的NP问题[cf.这里和这里],这意味着在标准假设没有用于解决没有经典算法。另外,目前认为量子计算机不能为NP完全和更复杂的问题提供指数加速[cf.这里],虽然它们可以提供升频了在文献中称为“受约束的量子加速度”已知的好处[比照这里]。最近,Outerel的研究小组运用数值模拟研究了这一事实,认为有证据表明量子加速度有限,尽管该结果可能要求绝热机器在容错通用机器中使用误差校正或量子模拟。在这里]。
尽管许多文献都集中在蛋白质晶格模型上,但最近的一篇文章[此处]尝试使用量子退火对Rosetta能量函数中的旋转异构体进行采样[参见参考资料]。在这里]。作者使用D-Wave 2000Q处理器以找到与经典模拟退火相比几乎恒定的缩放比例。Marchand小组提出了一种非常相似的方法[请参见。在这里]的构想者的选择。
结论
量子计算机可以存储和操纵大量信息,并且以比任何传统计算技术都快得多的速度执行算法。即使是小型量子计算机的潜力也可以安全地超过当今现有的最佳超级计算机,最终在某些任务的框架内,可以对计算生物学产生变革性的影响,有望将问题从无法解决的问题转移到困难和复杂的常规问题上。有望在未来十年内出现首批能够解决有用问题的量子处理器。因此,了解量子计算机可以做什么和不能做什么是每个计算科学家的首要任务。
尽管我们刚刚进入实用的量子计算时代,但我们已经可以看到未来几十年新的量子计算生物学的轮廓。我们希望这篇评论能引起计算生物学家对可能很快改变他们的实验和研究领域的技术的兴趣。反过来,量子计算专家将能够帮助生物学家显着提高计算生物学和生物信息学的水平,由此有望为全人类带来许多重大成果。