部分第2
部分第3部分
在本文中,您将学习:
- 什么是转移学习及其运作方式
- 什么是语义/实例分割及其工作原理
- 关于什么是对象检测及其工作原理
介绍
有两种方法可以执行对象检测任务(请参阅源和更多详细信息,在这里):
- 两阶段方法,它们也是“基于区域的方法”(英文,基于区域的方法)-一种分为两个阶段的方法。在第一阶段,通过选择性搜索或使用神经网络的特殊层来选择感兴趣区域(RoI),这些区域很有可能在其中包含对象。在第二阶段,分类器考虑选择的区域以确定原始类的归属,而回归器则确定边界框的位置。
- 单阶段方法(Engl单阶段方法)-一种方法,不使用单独的算法来生成区域,而是预测坐标以一定数量的具有不同特征(例如分类结果和置信度)的边界框,并进一步调整位置框架。
本文讨论了一步方法。
转移学习
转移学习是一种训练神经网络的方法,其中我们采用已经对某些数据进行训练的模型,以进行进一步的额外训练来解决另一个问题。例如,我们有一个在ImageNet数据集(1000个类)上训练的EfficientNet-B5模型。现在,在最简单的情况下,我们更改其最后一个分类器层(例如,对10个类的对象进行分类)。
看一下下面的图片:
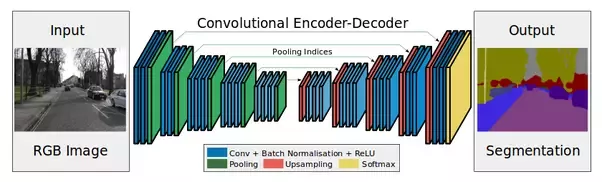
编码器-这些是子采样层(卷积和池)。
替换代码中的最后一层是这样的(框架-pytorch,环境-Google colab):
加载经过训练的EfficientNet-b5模型并查看其分类器层:

将该层更改为另一层:
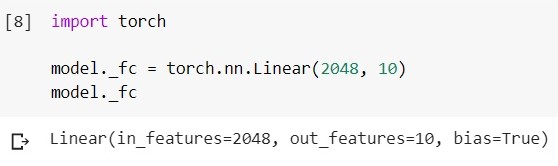
特别是在分段任务中需要解码器(关于此)进一步)。
转移学习策略
应该添加的是,默认情况下,我们要进一步训练的模型的所有层都是可训练的。我们可以“冻结”某些图层的权重。
冻结所有层:

我们训练的层越少,训练模型所需的计算资源就越少。这种技术总是合理的吗?
根据我们要训练网络的数据量以及训练网络的数据,开发用于迁移学习的事件有4个选项(在“小”和“很多”下,您可以将条件值设为10k):
- 您的数据很少,它类似于之前训练网络的数据。您可以尝试仅训练最后几层。
- , , . . , , , .. .
- , , . , .
- , , . .
Semantic segmentation
语义分割是当我们将图像作为输入时,在输出时我们想要得到类似的东西:

更正式地说,我们想对输入图像的每个像素进行分类-以了解其属于哪个类。
这里有很多方法和细微差别。 ResNeSt-269网络仅是什么架构:)
直觉-在输入图像(h,w,c),在输出处我们想要获得一个掩码(h,w)或(h,w,c),其中c是类数(取决于数据和模型)。现在,让我们在编码器之后添加一个解码器并对其进行训练。
解码器将特别包含上采样层。您可以简单地通过一步或一步“拉伸”特征图的高度和宽度来增加尺寸。拉动时可以使用双线性插值(在代码中将只是方法参数之一)。
Deeplabv3 +网络架构:
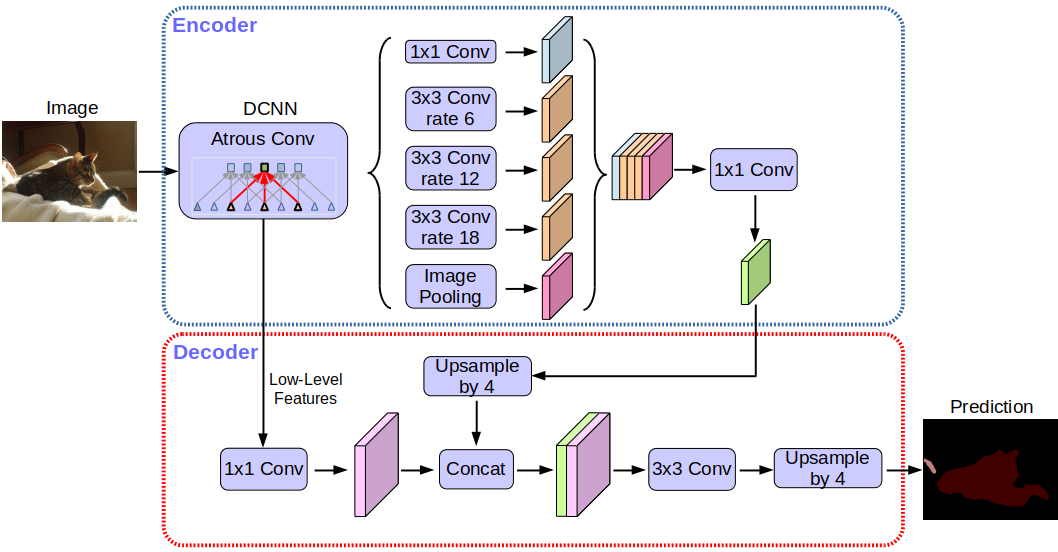
无需赘述,您会注意到网络使用编码器-解码器架构。
U-net网络的体系结构是一个更经典的版本:
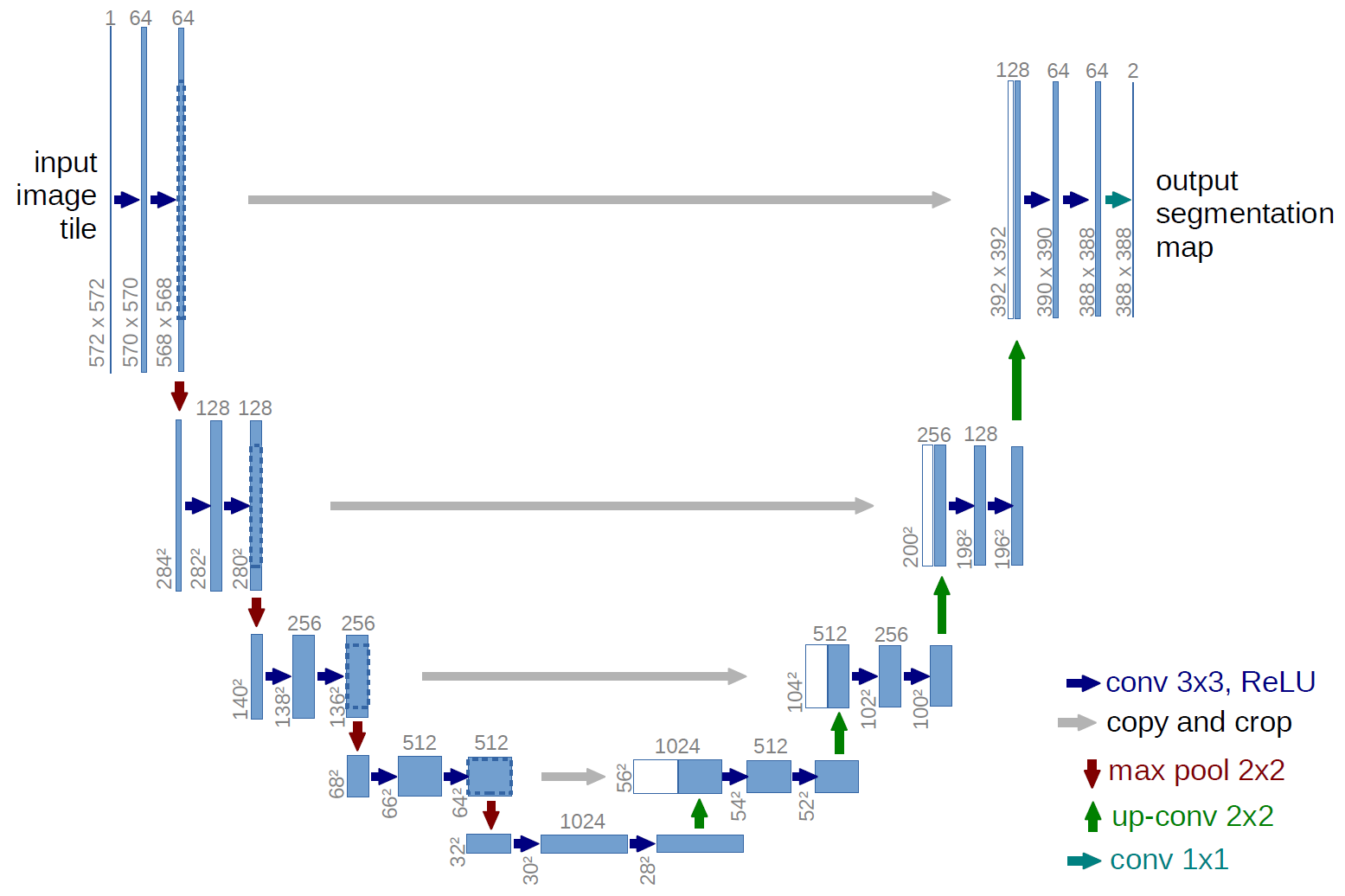
这些灰色箭头是什么?这些就是所谓的跳过连接。关键是编码器对输入的有损图像进行“编码”。为了最大程度地减少此类损失,他们使用跳过连接。
在此任务中,我们可以使用转移学习-例如,我们可以使用已经训练有素的编码器建立网络,添加解码器并对其进行训练。
目前,什么数据和哪些模型在此任务中表现最佳-您可以在此处查看...
实例细分
细分问题的更复杂版本。其实质是我们不仅要对输入图像的每个像素进行分类,而且要以某种方式选择同一类的不同对象:
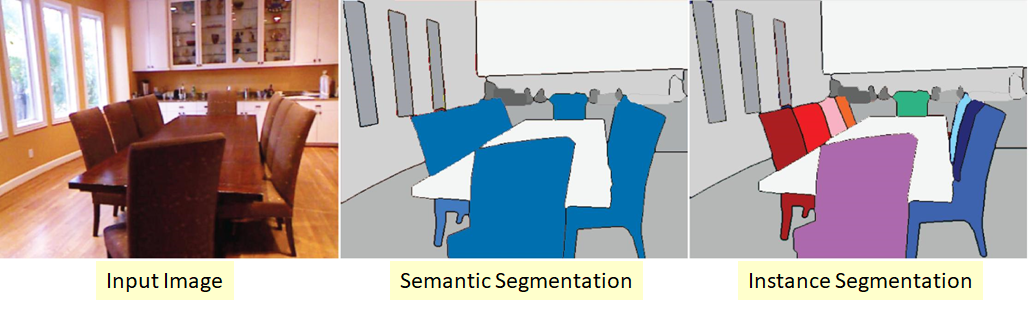
碰巧这些类是“粘性”的,或者它们之间没有可见的边界,但是我们想界定同一类的对象分开。
这里也有几种方法。最简单,最直观的是我们训练两个不同的网络。我们教第一个对某些类的像素进行分类(语义分割),第二个对类对象之间的像素进行分类。我们得到两个口罩。现在我们可以从第一个中减去第二个,然后得到我们想要的:)目前,
什么数据和哪些模型在此任务中表现最佳-您可以在此处看到...
Object detection
我们将图像发送到输入端,然后在输出端看到类似以下内容

的东西:可以做的最直观的事情是用不同的矩形``遍历''图像,并使用已经训练有素的分类器来确定该区域是否有我们感兴趣的对象。有这样一种方案,但显然不是最佳方案。我们确实有卷积层,它们以某种方式解释了特征图“之后”(B)中的特征图“之前”(A)。在这种情况下,我们知道卷积滤波器的尺寸=>我们知道哪些像素从A转换为哪个像素B。
让我们看一下YOLO v3:
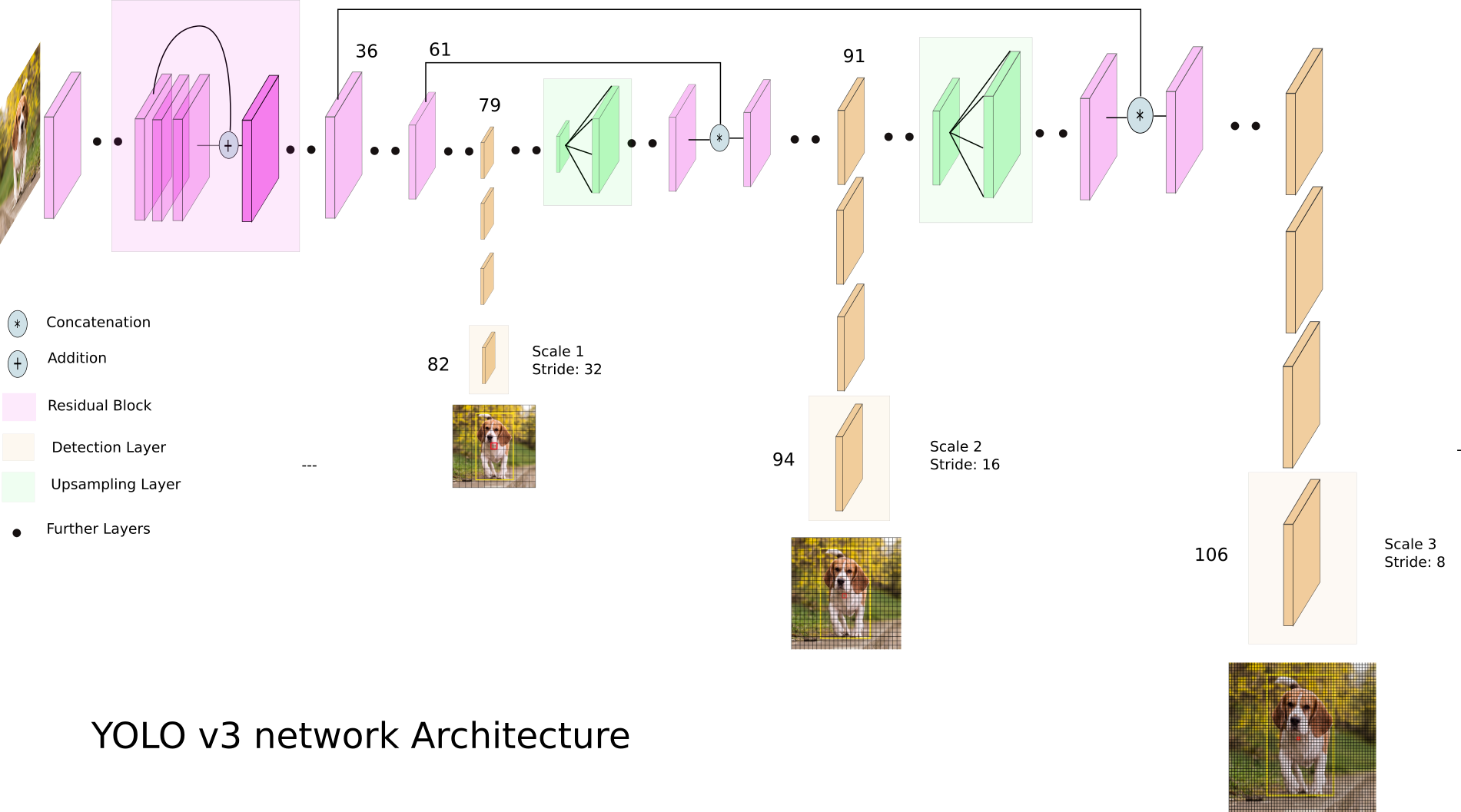
YOLO v3使用不同的尺寸特征图。这样做尤其是为了正确地检测不同大小的物体。
接下来,将所有三个音阶连接在一起:
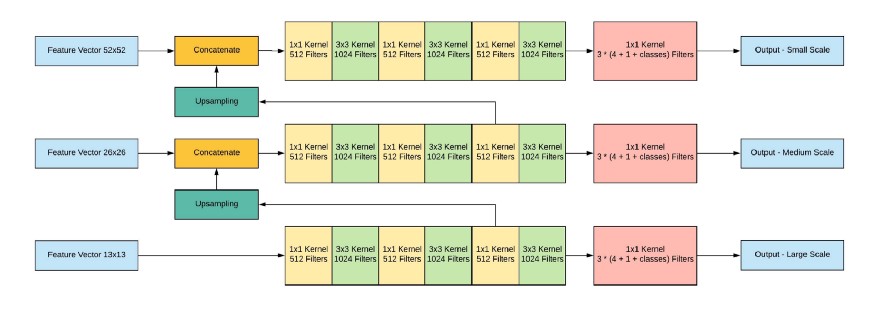
网络输出,输入图像为416x416、13x13x(B *(5 + C)),其中C是类数,B是每个区域的盒子数(YOLO v3有3个)。5-这些是参数,例如:Px,Py-对象中心的坐标,Ph,Pw-对象的高度和宽度,Pobj-对象在该区域中的概率。
让我们看一下图片,这样会更清楚一些:

YOLO首先根据客观性得分将某个值(通常为0.5-0.6),然后通过非最大抑制过滤掉预测数据。
关于什么数据和什么模型目前在此任务中表现最佳-您可以在这里看到。
结论
如今,有许多不同的模型和方法可用于对象的分割和定位任务。有某些想法,理解后,将更容易拆卸那种模型和方法的动物园。我试图在本文中表达这些想法。
在接下来的文章中,我们将讨论样式转换和GAN。