
在本文中,我们将讨论各种JIT编译器的实现细节和操作以及优化策略。我们将进行足够详细的讨论,但是将省略许多重要的概念。也就是说,本文中没有足够的信息来比较实现和语言时无法得出合理的结论。
要基本了解JIT编译器,请阅读本文。
一个小注意事项:
, , , - . , JIT ( ), , . , , , , . - , , .
- Pypy
- GraalVM C
- OSR
- JIT
()
LuaJIT使用所谓的跟踪。 Pypy执行元跟踪,即,它使用系统生成跟踪和JIT解释器。 Pypy和LuaJIT并不是示例性的Python和Lua实现,而是独立的项目。我认为LuaJIT的速度惊人得惊人,它把自己描述为最快的动态语言实现之一-我绝对相信。
为了了解何时开始跟踪,解释器循环会寻找热循环(热代码的概念对于所有JIT编译器都是通用的!)。然后,编译器“跟踪”循环,记录可执行的操作,以编译经过优化的机器代码。在LuaJIT中,编译基于具有LuaJIT特有的指令式中间表示的跟踪。
如何在Pypy中实现跟踪
Pypy在1619次执行后开始跟踪该函数,在1039次执行后进行编译,也就是说,大约需要执行3000次该函数才能开始更快地运行。这些值是由Pypy团队精心选择的,并且在编译器世界中,通常会仔细选择许多常量。
动态语言使优化变得困难。可以使用更严格的语言静态删除以下代码,因为它
False始终为false。但是,在Python 2中,直到运行时才能保证。
if False:
print("FALSE")
对于任何智能程序,此条件始终为假。不幸的是,该值
False可以重新定义,并且表达式将处于循环中,可以在其他位置重新定义。因此,Pypy可以创建一个“后卫”。如果防御者失败,则JIT将退回到解释循环。然后,Pypy使用另一个称为跟踪渴望的常量(200)来决定是否在循环结束之前编译其余的新路径。此子路径称为桥。
另外,Pypy提供了这些常量作为参数,您可以在运行时自定义这些参数以及展开配置(即循环扩展和内联)!另外,它提供了挂钩,在编译完成后我们可以看到它们。
def print_compiler_info(i):
print(i.type)
pypyjit.set_compile_hook(print_compiler_info)
for i in range(10000):
if False:
pass
print(pypyjit.get_stats_snapshot().counters)
上面,我编写了一个带有编译钩子的纯Python程序,以显示所应用的编译类型。该代码还在末尾输出数据,该数据显示防御者的数量。对于此程序,我得到了一个循环编译和66个防御者。当我用
if简单的循环外传递替换表达式时for,只剩下59个防御者。
for i in range(10000):
pass # removing the `if False` saved 7 guards!
通过将这两行添加到循环中
for,我得到了两个编译,其中之一是“ bridge”类型的!
if random.randint(1, 100) < 20:
False = True
等一下,您在谈论元追踪!
迁移的想法可以描述为``编写解释器并免费获得编译器!''或``将解释器转换为JIT编译器!''编写编译器很困难,如果可以免费获得它,那么这个主意就很不错。 Pypy“包含”一个解释器和一个编译器,但是没有明确实现传统的编译器。
Pypy有一个RPython工具(为Pypy构建)。它是编写口译员的框架。它的语言是一种Python,并且是静态类型的。用这种语言,您需要编写一个解释器。该语言不适用于类型化的Python编程,因为它不包含标准库或程序包。任何RPython程序都是有效的Python程序。 RPython代码被转换为C,然后进行编译。因此,使用这种语言的元编译器作为已编译的C程序存在。
metatraces一词中的前缀“元”表示在解释器(而不是程序)运行时执行跟踪。它的行为或多或少与任何其他解释器类似,但是它可以跟踪其操作,并且旨在通过更新其路径来优化跟踪。随着进一步的跟踪,解释器路径变得更加优化。优化的解释器遵循特定的路径。通过编译RPython获得的该路径中使用的机器代码可以在最终编译中使用。
简而言之,Pypy中的“编译器”会编译您的解释器,这就是为什么Pypy有时称为元编译器的原因。它不会编译您正在执行的程序作为优化解释器的路径。
元跟踪的概念似乎令人困惑,因此出于说明目的,我编写了一个仅理解
a = 0和的非常差的程序a++to。
# interpreter written with RPython
for line in code:
if line == "a = 0":
alloc(a, 0)
elif line == "a++":
guard(a, "is_int") # notice how in Python, the type is unknown, but after being interpreted by RPython, the type is known
guard(a, "> 0")
int_add(a, 1)
如果我运行此热循环:
a = 0
a++
a++
曲目可能如下所示:
# Trace from numerous logs of the hot loop
a = alloc(0) # guards can go away
a = int_add(a, 1)
a = int_add(a, 2)
# optimize trace to be compiled
a = alloc(2) # the section of code that executes this trace _is_ the compiled code
但是编译器不是一些特殊的单独模块,而是内置在解释器中。因此,解释周期将如下所示:
for line in code:
if traces.is_compiled(line):
run_compiled(traces.compiled(line))
continue
elif traces.is_optimized(line):
compile(traces.optimized(line))
continue
elif line == "a = 0"
# ....
JVM简介
我在基于Graal的TruffleRuby中写了四个月,然后爱上了它。
热点(如此命名是因为它搜索热斑)是标配安装的Java虚拟机。它包含几个用于实现多级编译的编译器。Hotspot的250,000行代码库已打开,并具有三个垃圾收集器。在某些基准测试中,开发人员可以处理JIT编译,它的性能比C ++的效果更好(在这种情况下,
Hotspot中使用的策略启发了后来的JIT编译器,语言虚拟机框架,尤其是Javascript引擎的许多作者。热点还催生了一波JVM语言,例如Scala,Kotlin,JRuby和Jython。 JRuby和Jython是Ruby和Python的有趣实现,它们将源代码编译为JVM字节码,然后由Hotspot执行。所有这些项目在没有实现所有工具的情况下都可以成功地加速Python和Ruby语言(Ruby比Python更快),就像Pypy一样。热点也很独特,因为它是动态性较低的语言的JIT(尽管从技术上讲它是JVM字节码而不是Java的JIT)。

GraalVM是带有Java代码段的JavaVM。它可以运行任何JVM语言(Java,Scala,Kotlin等)。它还支持本机映像,以通过Substrate VM与AOT编译代码一起使用。 Twitter的Scala服务中有很大一部分都运行在Graal上,这说明了虚拟机的质量,尽管它是用Java编写的,但在某些方面它要比JVM更好。
不仅如此! GraalVM还提供Truffle:通过创建AST(抽象语法树)解释器来实现语言的框架。当像常规JVM语言一样生成JVM字节码时,Truffle中没有明确的步骤。相反,松露将仅使用解释器并与Graal进行对话,从而通过概要分析和所谓的部分评分直接生成机器代码。简而言之,部分评估超出了本文的范围:此方法遵循“编写解释器,免费获取编译器!”的方法,但是,元跟踪的方法也有所不同。
TruffleJS — Truffle- Javascript, V8 , , V8 , Google , . TruffleJS «» V8 ( JS-) , Graal.
JIT-
C
JIT实现通常存在支持C扩展的问题。 Lua,Python,Ruby和PHP等标准解释器具有C语言API,允许用户以该语言构建软件包,从而大大加快了执行速度。许多软件包都是用C语言编写的,例如numpy,如标准库函数
rand。所有这些C扩展对于快速提高解释语言至关重要。
由于多种原因,C扩展很难维护。最明显的原因是API在设计时考虑了内部实现。而且,当解释器用C编写时,支持C扩展会更容易,因此JRuby无法支持C扩展,但是它确实具有Java扩展的API。 Pypy最近发布了一个对C扩展的支持的beta版本,尽管由于Hyrum定律我不确定它是否有效。 LuaJIT支持C扩展,包括其C扩展中的其他功能(LuaJIT真棒!)
Graal使用Sulong解决了这个问题,Sulong是一种在GraalVM上执行LLVM字节码并将其转换为Truffle的引擎。 LLVM是一个工具箱,我们只需要知道C可以编译为LLVM字节码(Julia也具有LLVM后端!)。这很奇怪,但是解决方案是采用一种具有四十多年历史的优秀编译语言并对其进行解释!当然,它的运行速度不如正确编译的C快,但是它确实有很多好处。
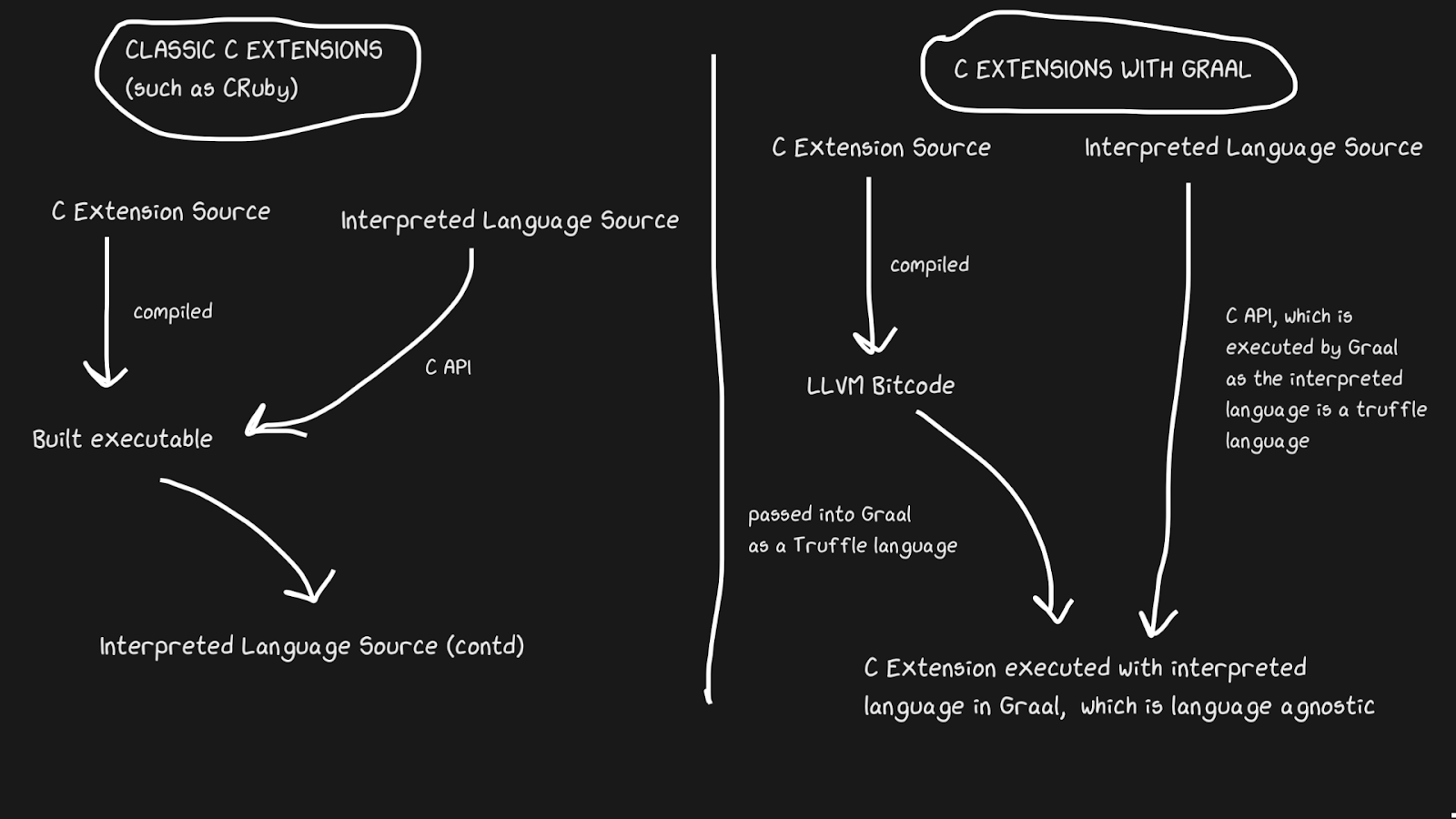
LLVM字节码已经是很底层的了,也就是说,将JIT应用于这种中间表示的效率不如C。效率的部分补偿是因为字节码可以与Ruby程序的其余部分一起进行优化,但是我们无法优化编译的C程序。 ...所有这些内存条,内联,无效块等等都可以应用于C和Ruby代码,而不用从Ruby代码中调用C二进制文件。 TruffleRuby C扩展在某些方面比CRuby C扩展快。
为了使该系统正常工作,您需要知道Truffle完全独立于语言,并且在Graal中在C,Java或任何其他语言之间切换的开销将降至最低。
Graal与Sulong合作的能力是其多种语言功能的一部分,该功能可以实现高度的语言互换性。这不仅对编译器有益,而且还证明您可以在一个``应用程序''中轻松使用多种语言。
回到解释的代码,它更快
我们知道JIT包含一个解释器和一个编译器,并且它们从解释器转移到编译器以加快处理速度。尽管从Graal和Hotspot的角度来看,Pypy是去优化的,但Pypy为返回路径创建了桥梁。我们不是在谈论完全不同的概念,但是通过去优化,我们的意思是作为有意识的优化返回到解释器,而不是动态语言的必然性的解决方案。 Hotspot和Graal大量使用了反优化,尤其是Graal,因为开发人员对编译有严格的控制,并且为了优化起见(与Pypy相比)需要对编译进行更多控制。在JS引擎中也使用了去优化,我将在这里进行很多讨论,因为Chrome和Node.js中的JavaScript依赖于它。
为了快速应用去优化,确保尽快在编译器和解释器之间切换非常重要。在最幼稚的实现中,解释器将不得不“赶上”编译器以执行去优化。额外的复杂性与异步流的去优化有关。 Graal创建一组框架并将其与生成的代码进行匹配以返回到解释器。使用安全点,您可以暂停Java线程并说:“您好,垃圾收集器,我需要停止吗?”因此,线程处理不需要很多开销。事实证明这是相当粗糙的,但是它运行得足够快,以至于取消优化成为一个好的策略。
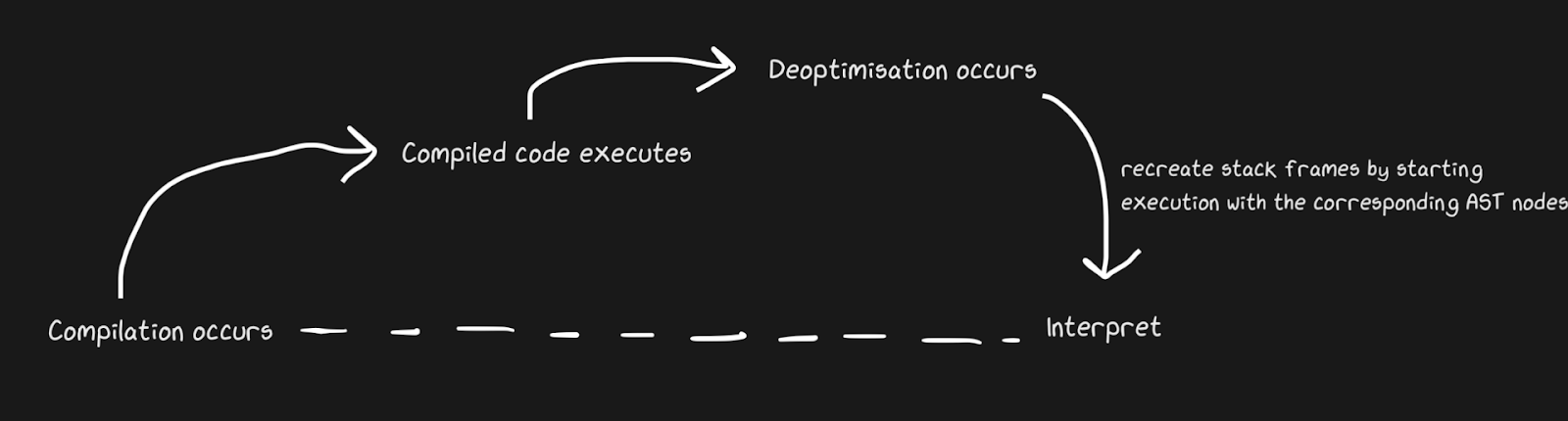
类似于Pypy桥接示例,功能的猴子修补也可以取消优化。这样做更优雅,因为我们不是在防御者失败时添加反优化代码,而是在应用游击补丁时添加反优化代码。
JIT取消优化的一个很好的例子:转换溢出是一个非正式的术语。我们正在谈论一种情况,其中某种类型(例如
int32)在内部表示/分配,但需要将其转换为int64。 TruffleRuby像V8一样通过取消优化来实现这一点。
说,如果您在Ruby中询问
var = 0,您会得到int32(Ruby将其称为Fixnum和Bignum,但我将使用表示法int32和int64)。执行操作var,您需要检查是否发生值溢出。但这是一回事,处理溢出的代码昂贵,尤其是考虑到数字运算的频率。
甚至不用看编译的指令,您就可以了解这种非优化如何减少代码量。
int a, b;
int sum = a + b;
if (overflowed) {
long bigSum = a + b;
return bigSum;
} else {
return sum;
}
int a, b;
int sum = a + b;
if (overflowed) {
Deoptimize!
}
在TruffleRuby中,仅对特定操作的第一次运行进行了优化,因此我们不会在每次操作溢出时都浪费资源。
WET代码是快速代码。内联和OSR
function foo(a, b) {
return a + b;
}
for (var i = 0; i < 1000000; i++) {
foo(i, i + 1);
}
foo(1, 2);
在V8中,甚至连这些触发器之类的琐事都没有进行优化!使用诸如
--trace-deoptand之类的选项,--trace-opt您可以收集有关JIT的大量信息,也可以修改行为。 Graal有一些非常有用的工具,但是我将使用V8,因为已经安装了许多V8。
取消优化由
foo(1, 2)令人费解的最后一行()开始,因为此调用是在循环中进行的!我们将收到一条消息“呼叫类型反馈不足”(此处显示了取消优化的原因的完整列表,其中有一个“无原因”的有趣原因)。这将创建一个显示文字1和的输入框2。
那么为什么要取消优化呢? V8足够聪明,可以进行类型转换:
i输入时integer,文字也会被传递integer。
要了解这一点,让我们用替换最后一行
foo(i, i +1)。但是仍然应用去优化,只是这次消息有所不同:“二进制操作的类型反馈不足”。为什么?!毕竟,这是在循环中执行的完全相同的操作,具有相同的变量!
我的朋友,答案就在于堆栈替换(OSR)。内联是功能强大的编译器优化(不仅仅是JIT),在该优化中,函数不再是函数,而内容将传递到调用位置。 JIT编译器可以通过在运行时更改代码来内联以提高速度(编译语言只能静态内联)。
// partial output from printing inlining details
[compiling method 0x04a0439f3751 <JSFunction (sfi = 0x4a06ab56121)> using TurboFan OSR]
0x04a06ab561e9 <SharedFunctionInfo foo>: IsInlineable? true
Inlining small function(s) at call site #49:JSCall
因此,V8将进行编译
foo,确定它可以内联并与OSR内联。但是,引擎仅对循环内的代码执行此操作,因为这是一条热路径,并且内联时最后一行尚未在解释器中。因此,V8尚未对函数的类型提供足够的反馈foo,因为不是在循环中使用它,而是在其内联版本中使用它。如果应用--no-use-osr,则无论我们通过什么字面值或,都不会进行非优化i。但是,如果没有内联,即使是很小的百万次迭代,运行速度也会明显变慢。 JIT编译器实际上体现了“无解决方案只能折衷”的原则。取消优化的成本很高,但无法与寻找方法和内联的成本进行比较,在这种情况下,这是首选。
内联非常有效!我用两个额外的零运行了上面的代码,并且关闭了内联,运行速度慢了四倍。

尽管本文是关于JIT的,但内联在编译语言中也有效。所有的LLVM语言都主动使用内联,因为LLVM也会使用内联,尽管Julia在内联中没有LLVM,但这是她的本性。可以使用运行时启发法来内联JIT,并且可以使用OSR在非内联模式和内联模式之间进行切换。
关于JIT和LLVM的说明
LLVM提供了许多与编译相关的工具。朱莉娅使用LLVM(请注意,这是一个很大的工具箱,每种语言使用它的方式都不同),就像Rust,Swift和Crystal一样。可以这么说,尽管LLVM没有大量的内置动态JIT,但它也支持JIT,这是一个庞大而出色的项目。 JavaScriptCore编译的第四级使用LLVM后端有一段时间,但不到两年前就被替换了。从那时起,该工具包就不太适合动态JIT,主要是因为它不是为在动态环境中工作而设计的。 Pypy尝试了5-6次,但选择了JSC。使用LLVM,分配接收和代码移动受到限制。也不可能使用功能强大的JIT功能(例如范围推断)(就像强制转换一样,但是具有已知的值范围)。但是更重要的是,使用LLVM,很多资源都花在了编译上。
如果我们有一个可以自我修改的大型图形,而不是基于指令的中间表示,该怎么办?
我们讨论了LLVM字节码和Python / Ruby / Java字节码作为中间表示。它们都看起来像某种形式的指令形式的语言。Hotspot,Graal和V8使用``节点之海''中间表示形式(在Hotspot中引入),这是较低级别的AST。这是一种有效的视图,因为概要分析的很大一部分是基于很少使用(或在某些模式下重叠)的特定路径的概念。请注意,这些AST编译器不同于AST解析器。
通常,我坚持“尝试在家中做!”的立场,但是考虑到图形非常困难,尽管它非常有趣,并且对于理解编译器的工作通常非常有用。例如,不仅由于知识不足,而且由于大脑的计算能力,我无法读取所有图形(编译器选项可以帮助摆脱我不感兴趣的行为)。
对于V8,我们将使用带有flag的D8工具
--print-ast。对于Graal来说会的--vm.Dgraal.Dump=Truffle:2。文本将显示在屏幕上(格式化以获取图形)。我不知道V8开发人员如何生成可视图形,但是Oracle具有上图所示的“理想图形可视化工具”。我没有能力重新安装IGV,所以我从由Seafoam生成的Chris Seaton那里获取了图表,该源现已关闭。
好的,让我们看一下JavaScript AST!
function accumulate(n, a) {
var x = 0;
for (var i = 0; i < n; i++) {
x += a;
}
return x;
}
accumulate(1, 1)
d8 --print-ast test.js尽管我们只对该功能感兴趣,但
我还是运行了这段代码accumulate。看到我只调用过一次,也就是说,我不必等待编译就可以获取AST。
这是AST的样子(我删除了一些不重要的行):
FUNC at 19
. NAME "accumulate"
. PARAMS
. . VAR (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VAR (0x7ff535815798) (mode = VAR, assigned = false) "a"
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
. FOR at 43
. . INIT at -1
. . . BLOCK NOCOMPLETIONS at -1
. . . . EXPRESSION STATEMENT at 56
. . . . . INIT at 56
. . . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . . . LITERAL 0
. . COND at 61
. . . LT at 61
. . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . VAR PROXY parameter[0] (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . BODY at -1
. . . BLOCK at -1
. . . . EXPRESSION STATEMENT at 77
. . . . . ASSIGN_ADD at 79
. . . . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . . . VAR PROXY parameter[1] (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . NEXT at 67
. . . EXPRESSION STATEMENT at 67
. . . . POST INC at 67
. . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. RETURN at 91
. . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
很难解析它,但是它看起来像解析器的AST(并非对所有程序都是如此)。然后使用Acorn.js生成下一个AST,
一个明显的区别是变量的定义。在解析器的AST中,没有显式定义参数,并且循环声明隐藏在node中
ForStatement。在编译器级AST中,所有声明都按地址和元数据分组。
编译器AST也使用此愚蠢的表达式
VAR PROXY。由于变量的提升(提升),评估(评估)和其他原因,解析器的AST无法确定名称和变量(按地址)之间的关系。因此,编译器的AST使用的变量PROXY后来与实际变量关联。
// This chunk is the declarations and the assignment of `x = 0`
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
这就是使用Graal获得的相同程序的AST的样子!
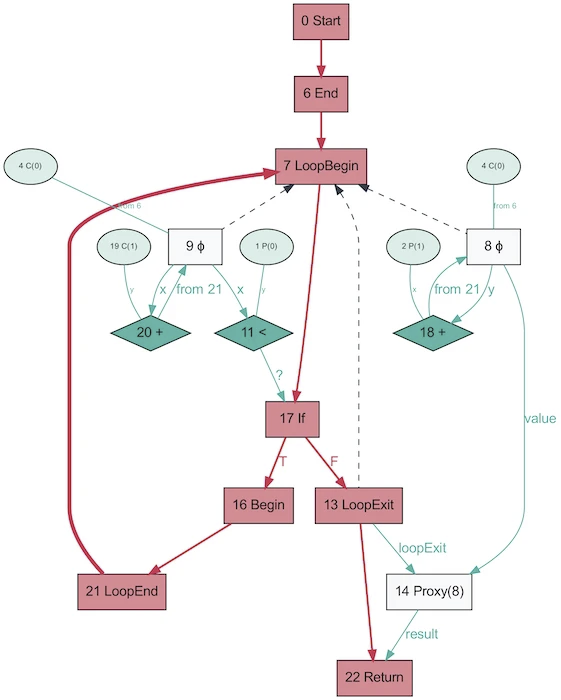
看起来更简单。红色表示控制流,蓝色表示数据流,箭头表示方向。请注意,尽管此图比V8中的AST更简单,但这并不意味着Graal可以更好地简化程序。它只是基于Java生成的,而Java的动态性要差得多。从Ruby生成的相同的Graal图将更接近第一个版本。
有趣的是,Graal中的AST会根据代码的执行情况而改变。当使用随机参数重复调用该函数时,该图是在OSR禁用和内联的情况下生成的,因此未对其进行优化。转储将为您提供一堆图形! Graal使用专门的AST来优化程序(V8进行了类似的优化,但不在AST级别)。在Graal中保存图形时,您会获得十多个具有不同优化级别的方案。重写节点时,它们将自己替换(专门化)为其他节点。
上图是动态类型化语言专业化的一个很好的例子(从One VM拍摄到Rule Them All,2013年的照片)。该过程存在的原因与部分评估的工作方式密切相关-全部与专业有关。
Hooray JIT编译了代码!让我们再次编译!然后再次!
上面我提到了“多层”,让我们来谈谈。这个想法很简单:如果我们还没有准备好创建完全优化的代码,但是解释仍然很昂贵,那么当我们准备生成更多优化的代码时,我们可以进行预编译然后最终编译。
热点是具有两个编译器C1和C2的分层JIT。 C1进行快速编译并运行代码,然后进行完整的分析以获取使用C2编译的代码。这可以帮助解决许多热身问题。无论如何,未优化的编译代码比解释要快。同样,C1和C2不会编译所有代码。如果函数看起来足够简单,则C2很有可能对我们没有帮助,甚至无法运行(我们还将节省分析时间!)。如果C1忙于编译,则分析可以继续,C1的工作将中断,并开始使用C2进行编译。
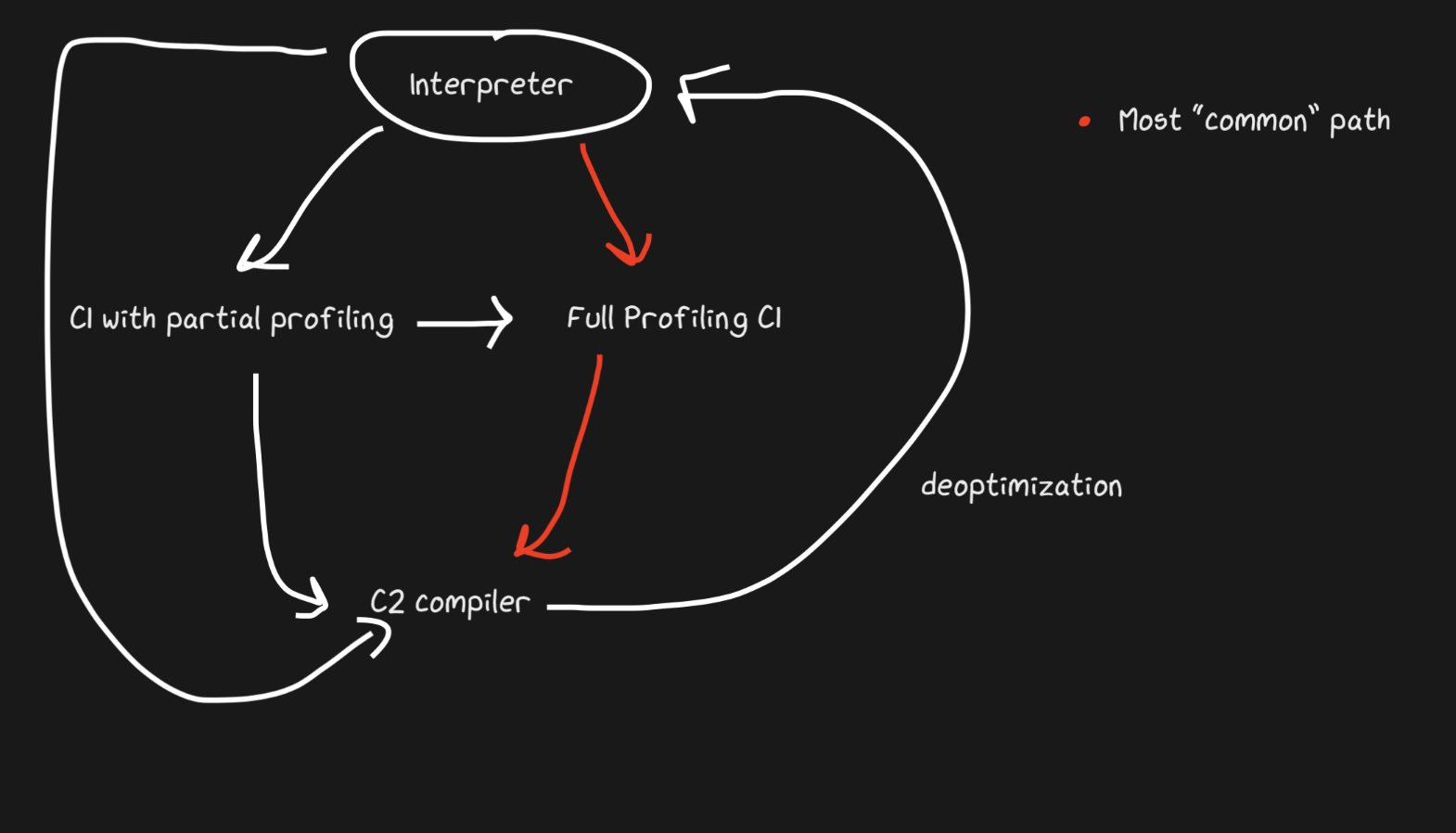
JavaScript Core甚至还有更多级别!实际上,有三个JIT。 JSC解释器进行一些灯光分析,然后转到“基线” JIT,然后是DFG(数据流图)JIT,最后是FTL(“比光速”)JIT。级别如此之多,去优化的含义不再局限于从编译器到解释器的过渡,去优化可以从DFG开始并以Baseline JIT结束(在Hotspot C2-> C1中不是这种情况)。使用OSR(堆栈覆盖)执行所有取消优化和转换到下一个级别。
基准JIT在大约执行100次后连接,而DFG JIT在大约执行1000次后连接(有些例外)。这意味着JIT获得编译代码的速度比同一个Pypy(大约需要执行3000次)要快得多。分层允许JIT尝试将代码执行的持续时间与其优化持续时间相关联。在每个级别上都有很多技巧,执行什么样的优化(内联,转换等),因此该策略是最佳的。
有用的资料
- Mike Pall编写的LuaJIT的跟踪编译器如何工作
- 元跟踪对VM的影响Laurie Tratt
- Pypy转义分析
- 为什么用户对虚拟机不满意?
- 关于JS引擎:
- 关于取消优化:
- Graal:
- :
- :