首先,我们将简短地熟悉遍历图形的方法,编写实际的寻路方法,然后再转到最美味的方法:优化性能和内存成本。理想情况下,您应该开发一种在使用时根本不产生垃圾的实现。
当表面搜索没有给我一个很好的C#中的A *算法的良好实现而不使用第三方库时,我就感到惊讶(这并不意味着没有)。因此,该伸展您的手指了!
我正在等待想要了解寻路算法工作的读者以及算法专家来熟悉其优化的实现和方法。
让我们开始吧!
历史之旅
二维网格可以表示为图形,其中每个顶点都有8条边:
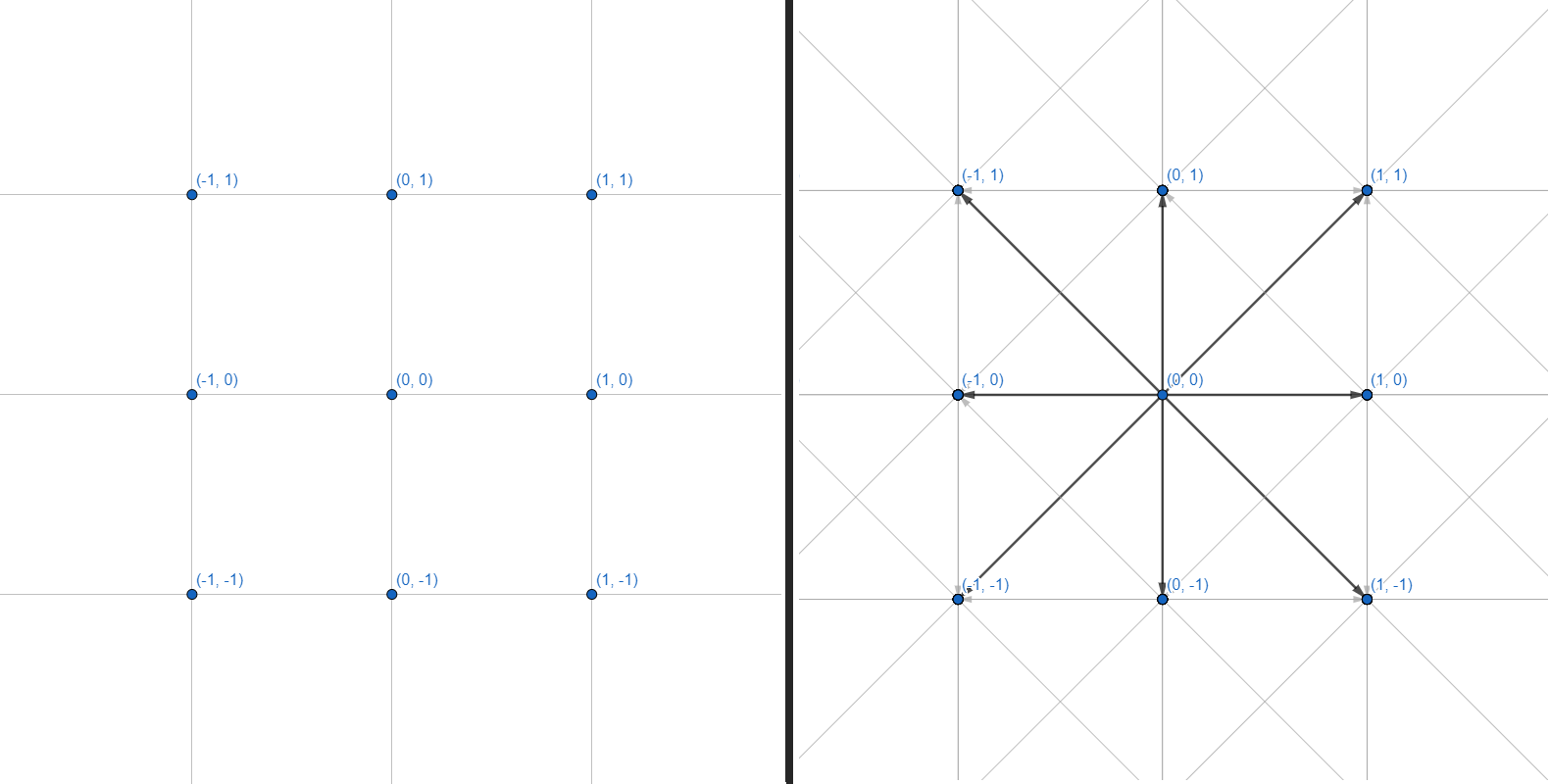
我们将使用图形。每个顶点是一个整数坐标。每个边都是相邻坐标之间的直线或对角线过渡。我们将不做坐标网格和障碍物几何的计算-我们将自己限制在一个接受几个坐标作为输入并返回一组用于构建路径的点的接口:
public interface IPath
{
IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles);
}首先,请考虑遍历图形的现有方法。
深度搜索
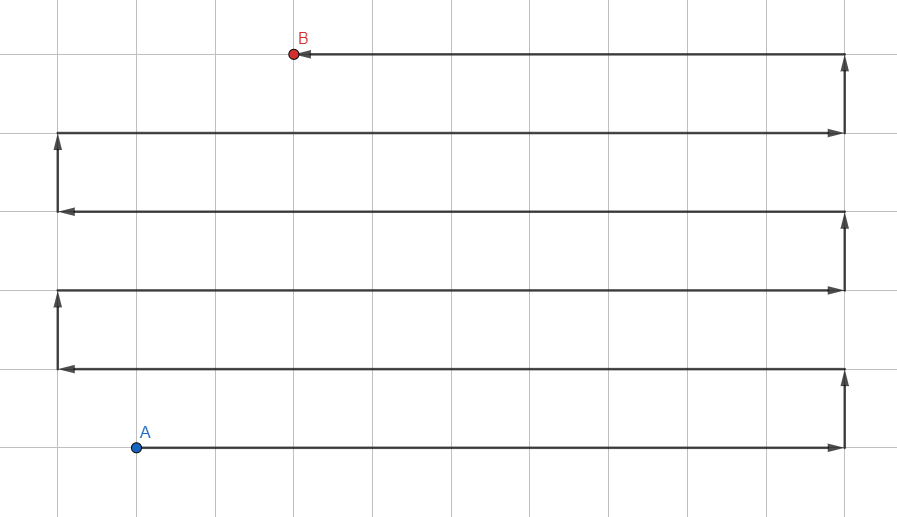
最简单的算法:
- 将当前顶点附近的所有未访问顶点添加到堆栈中。
- 从堆栈移到第一个顶点。
- 如果顶点是所需顶点,则退出循环。如果走不通,那就回去。
- 转到1。
看起来像这样:
, Node , .
private Node DFS(Node first, Node target)
{
List<Node> visited = new List<Node>();
Stack<Node> frontier = new Stack<Node>();
frontier.Push(first);
while (frontier.Count > 0)
{
var current = frontier.Pop();
visited.Add(current);
if (current == target)
return Node;
var neighbours = current.GenerateNeighbours();
foreach(var neighbour in neighbours)
if (!visited.Contains(neighbour))
frontier.Push(neighbour);
}
return default;
}, Node , .
它以LIFO(后进先出)格式组织,其中首先分析新添加的顶点。必须监视顶点之间的每个过渡,以便沿过渡构建实际路径。
这种方法永远不会(几乎)返回最短路径,因为它会在随机方向上处理图形。它更适合于小型图形,以便毫不费力地确定是否至少有一些到达所需顶点的路径(例如,所需链接在技术树中是否存在)。
在导航网格和无限图的情况下,这种搜索将无限地朝一个方向前进,并且浪费了计算资源,从未达到期望的地步。这可以通过限制算法运行的区域来解决。我们仅分析距初始点不超过N步的点。因此,当算法到达该区域的边界时,它将展开并继续分析指定半径内的顶点。
有时无法准确确定区域,但是您不想随意设置边框。迭代式深度优先搜索可以解决:
- 设置DFS的最小区域。
- 开始寻找。
- 如果找不到该路径,请将搜索区域增加1。
- 转到2。
该算法将一遍又一遍地运行,每次覆盖一个较大的区域,直到最终找到所需的点。
在稍大的半径处重新运行该算法似乎是浪费能量(无论如何,在上一次迭代中已经对大部分区域进行了分析!),但是没有:随着半径的增加,顶点之间的过渡数量以几何方式增长。半径大于所需半径比沿着小半径走几圈要贵得多。
这样的搜索很容易收紧计时器限制:它将精确搜索半径不断扩大的路径,直到指定时间结束为止。
广度优先搜索
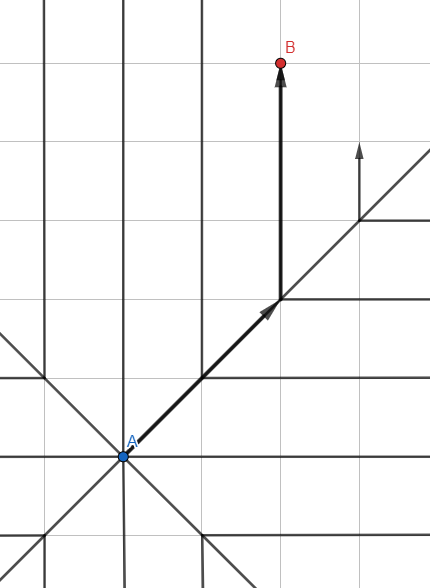
插图可能类似于“跳转搜索” -但这是常用的wave算法,并且这些线表示删除了中间点的搜索传播路径。
与使用堆栈(LIFO)的深度优先搜索相反,让我们采用队列(FIFO)处理顶点:
- 将所有未访问的邻居添加到队列中。
- 从队列转到第一个顶点。
- 如果顶点是所需顶点,请退出循环,否则转到1。
看起来像这样:
, Node , .
private Node BFS(Node first, Node target)
{
List<Node> visited = new List<Node>();
Queue<Node> frontier = new Queue<Node>();
frontier.Enqueue(first);
while (frontier.Count > 0)
{
var current = frontier.Dequeue();
visited.Add(current);
if (current == target)
return Node;
var neighbours = current.GenerateNeighbours();
foreach(var neighbour in neighbours)
if (!visited.Contains(neighbour))
frontier.Enqueue(neighbour);
}
return default;
}, Node , .
这种方法提供了最佳路径,但是有一个陷阱:由于该算法处理各个方向的顶点,因此在长距离上以及具有强分支的图形上它的工作非常缓慢。这只是我们的情况。
在这里,算法的操作区域不受限制,因为在任何情况下它都不会超出半径到所需的点。需要其他优化方法。
一种 *
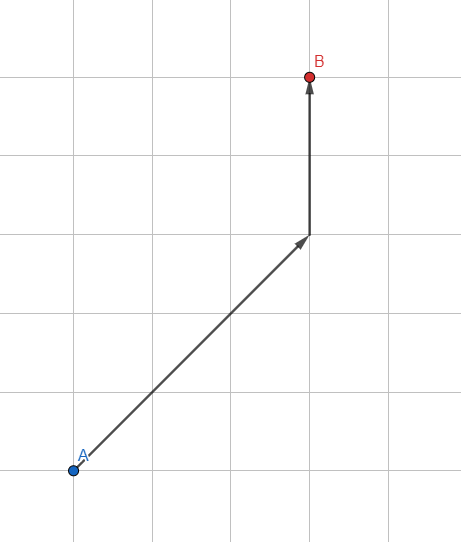
让我们修改标准的广度优先搜索:我们不使用常规队列存储顶点,而是使用基于启发式的排序队列-预期路径的近似估计。
如何估算预期路径?最简单的是从处理的顶点到所需点的矢量长度。向量越小,该点越有希望,并且越接近队列的开始。该算法将优先考虑位于目标方向上的那些顶点。
因此,由于需要进行额外的计算,算法内部的每次迭代将花费更长的时间,但是通过减少用于分析的顶点数量(仅处理最有前途的顶点),我们实现了算法速度的极大提高。
但是仍然有很多处理过的顶点。查找向量的长度是一项昂贵的操作,涉及计算平方根。因此,我们将对启发式算法使用简化的计算。
让我们创建一个整数向量:
public readonly struct Vector2Int : IEquatable<Vector2Int>
{
private static readonly double Sqr = Math.Sqrt(2);
public Vector2Int(int x, int y)
{
X = x;
Y = y;
}
public int X { get; }
public int Y { get; }
/// <summary>
/// Estimated path distance without obstacles.
/// </summary>
public double DistanceEstimate()
{
int linearSteps = Math.Abs(Math.Abs(Y) - Math.Abs(X));
int diagonalSteps = Math.Max(Math.Abs(Y), Math.Abs(X)) - linearSteps;
return linearSteps + Sqr * diagonalSteps;
}
public static Vector2Int operator +(Vector2Int a, Vector2Int b)
=> new Vector2Int(a.X + b.X, a.Y + b.Y);
public static Vector2Int operator -(Vector2Int a, Vector2Int b)
=> new Vector2Int(a.X - b.X, a.Y - b.Y);
public static bool operator ==(Vector2Int a, Vector2Int b)
=> a.X == b.X && a.Y == b.Y;
public static bool operator !=(Vector2Int a, Vector2Int b)
=> !(a == b);
public bool Equals(Vector2Int other)
=> X == other.X && Y == other.Y;
public override bool Equals(object obj)
{
if (!(obj is Vector2Int))
return false;
var other = (Vector2Int) obj;
return X == other.X && Y == other.Y;
}
public override int GetHashCode()
=> HashCode.Combine(X, Y);
public override string ToString()
=> $"({X}, {Y})";
}用于存储一对坐标的标准结构。在这里,我们看到平方根缓存,因此只能计算一次。IEquatable接口将使我们能够相互比较向量,而不必将Vector2Int转换为对象和对象。这将大大加快我们的算法的速度,并消除不必要的分配。
DistanceEstimate()用于通过计算直线和对角线过渡的数量来估计到目标的近似距离。一种替代方法是常见的:
return Math.Max(Math.Abs(X), Math.Abs(Y))该选项将更快地工作,但这可以通过对角线距离估计的低精度来弥补。
现在,我们有了用于处理坐标的工具,让我们创建一个代表图形顶部的对象:
internal class PathNode
{
public PathNode(Vector2Int position, double traverseDist, double heuristicDist, PathNode parent)
{
Position = position;
TraverseDistance = traverseDist;
Parent = parent;
EstimatedTotalCost = TraverseDistance + heuristicDist;
}
public Vector2Int Position { get; }
public double TraverseDistance { get; }
public double EstimatedTotalCost { get; }
public PathNode Parent { get; }
}在父级中,我们将记录每个新顶点的先前顶点:这将有助于按点构建最终路径。除了坐标外,我们还存储行进的距离和路径的估计成本,以便我们可以选择最有希望的顶点进行处理。
该课程要求改进,但我们稍后会再讲。现在,让我们开发一种方法来生成顶点的邻居:
internal static class NodeExtensions
{
private static readonly (Vector2Int position, double cost)[] NeighboursTemplate = {
(new Vector2Int(1, 0), 1),
(new Vector2Int(0, 1), 1),
(new Vector2Int(-1, 0), 1),
(new Vector2Int(0, -1), 1),
(new Vector2Int(1, 1), Math.Sqrt(2)),
(new Vector2Int(1, -1), Math.Sqrt(2)),
(new Vector2Int(-1, 1), Math.Sqrt(2)),
(new Vector2Int(-1, -1), Math.Sqrt(2))
};
public static IEnumerable<PathNode> GenerateNeighbours(this PathNode parent, Vector2Int target)
{
foreach ((Vector2Int position, double cost) in NeighboursTemplate)
{
Vector2Int nodePosition = position + parent.Position;
double traverseDistance = parent.TraverseDistance + cost;
double heuristicDistance = (position - target).DistanceEstimate();
yield return new PathNode(nodePosition, traverseDistance, heuristicDistance, parent);
}
}
}NeighborsTemplate-用于创建所需点的线性和对角线邻居的预定义模板。它还考虑到对角线过渡的成本增加。
GenerateNeighbors-生成器,该生成器遍历NeighborsTemplate并为所有八个相邻边返回新的顶点。
可以在PathNode内部使用该功能,但感觉上有点违反SRP。而且我也不想在算法本身内部添加第三方功能:我们将使类尽可能紧凑。
是时候解决主要的寻路课程了!
public class Path
{
private readonly List<PathNode> frontier = new List<PathNode>();
private readonly List<Vector2Int> ignoredPositions = new List<Vector2Int>();
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles) {...}
private bool GenerateNodes(Vector2Int start, Vector2Int target,
IEnumerable<Vector2Int> obstacles, out PathNode node)
{
frontier.Clear();
ignoredPositions.Clear();
ignoredPositions.AddRange(obstacles);
// Add starting point.
frontier.Add(new PathNode(start, 0, 0, null));
while (frontier.Any())
{
// Find node with lowest estimated cost.
var lowest = frontier.Min(a => a.EstimatedTotalCost);
PathNode current = frontier.First(a => a.EstimatedTotalCost == lowest);
ignoredPositions.Add(current.Position);
if (current.Position.Equals(target))
{
node = current;
return true;
}
GenerateFrontierNodes(current, target);
}
// All nodes analyzed - no path detected.
node = null;
return false;
}
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
foreach (PathNode newNode in parent.GenerateNeighbours(target))
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
var node = frontier.FirstOrDefault(a => a.Position == newNode.Position);
if (node == null)
frontier.Add(newNode);
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < node.TraverseDistance)
{
frontier.Remove(node);
frontier.Add(newNode);
}
}
}
}GenerateNodes与两个集合一起使用:frontier(其中包含用于分析的顶点队列)和ignorePositions(已添加已处理的顶点)。
循环的每次迭代都会找到最有前途的顶点,检查是否到达终点,并为该顶点生成新的邻居。
所有这些美丽适合50条线。
仍然需要实现接口:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles, out PathNode node))
return Array.Empty<Vector2Int>();
var output = new List<Vector2Int>();
while (node.Parent != null)
{
output.Add(node.Position);
node = node.Parent;
}
output.Add(start);
return output.AsReadOnly();
}GenerateNodes返回最终顶点,由于我们为每个顶点都创建了一个父节点,因此足以遍历所有父节点直到初始顶点,我们将获得最短路径。一切都很好!
或不?
算法优化
1. PathNode
让我们开始简单。让我们简化PathNode:
internal readonly struct PathNode
{
public PathNode(Vector2Int position, Vector2Int target, double traverseDistance)
{
Position = position;
TraverseDistance = traverseDistance;
double heuristicDistance = (position - target).DistanceEstimate();
EstimatedTotalCost = traverseDistance + heuristicDistance;
}
public Vector2Int Position { get; }
public double TraverseDistance { get; }
public double EstimatedTotalCost { get; }
}这是一个常见的数据包装器,也经常创建。每次我们编写new时,都没有理由使其成为类并加载内存。因此,我们将使用struct。
但是有一个问题:结构不能包含对其自身类型的循环引用。因此,与其将父对象存储在PathNode中,还需要另一种方法来跟踪顶点之间路径的构造。很简单-让我们向Path类添加一个新集合:
private readonly Dictionary<Vector2Int, Vector2Int> links;我们稍微修改了邻居的生成:
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
foreach (PathNode newNode in parent.GenerateNeighbours(target))
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
if (!frontier.TryGet(newNode.Position, out PathNode existingNode))
{
frontier.Enqueue(newNode);
links[newNode.Position] = parent.Position; // Add link to dictionary.
}
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < existingNode.TraverseDistance)
{
frontier.Modify(newNode);
links[newNode.Position] = parent.Position; // Add link to dictionary.
}
}
}我们不将父代写到顶点本身,而是将过渡写到字典中。另外,该词典可以直接与Vector2Int一起使用,而不能与PathNode一起使用,因为我们只需要坐标,就不需要其他任何东西。
在Calculate中生成结果的过程也得到了简化:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles))
return Array.Empty<Vector2Int>();
var output = new List<Vector2Int> {target};
while (links.TryGetValue(target, out target))
output.Add(target);
return output.AsReadOnly();
}2. NodeExtensions
接下来,让我们处理邻居的产生。IEnumerable尽管有其所有优点,但在许多情况下都会产生大量的垃圾。让我们摆脱它:
internal static class NodeExtensions
{
private static readonly (Vector2Int position, double cost)[] NeighboursTemplate = {
(new Vector2Int(1, 0), 1),
(new Vector2Int(0, 1), 1),
(new Vector2Int(-1, 0), 1),
(new Vector2Int(0, -1), 1),
(new Vector2Int(1, 1), Math.Sqrt(2)),
(new Vector2Int(1, -1), Math.Sqrt(2)),
(new Vector2Int(-1, 1), Math.Sqrt(2)),
(new Vector2Int(-1, -1), Math.Sqrt(2))
};
public static void Fill(this PathNode[] buffer, PathNode parent, Vector2Int target)
{
int i = 0;
foreach ((Vector2Int position, double cost) in NeighboursTemplate)
{
Vector2Int nodePosition = position + parent.Position;
double traverseDistance = parent.TraverseDistance + cost;
buffer[i++] = new PathNode(nodePosition, target, traverseDistance);
}
}
}现在,我们的扩展方法不再是生成器:它只是填充作为参数传递给它的缓冲区。缓冲区存储为Path中的另一个集合:
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];它的用法如下:
neighbours.Fill(parent, target);
foreach(var neighbour in neighbours)
{
// ...3. HashSet
我们不使用List,而使用HashSet:
private readonly HashSet<Vector2Int> ignoredPositions;当处理大型集合时,此方法效率更高,由于调用频率高,ignorePositions.Contains()方法非常占用资源。简单更改集合类型将显着提高性能。
4. BinaryHeap
在我们的实现中,有一个地方使算法的运行速度降低了十倍:
// Find node with lowest estimated cost.
var lowest = frontier.Min(a => a.EstimatedTotalCost);
PathNode current = frontier.First(a => a.EstimatedTotalCost == lowest);List本身是一个糟糕的选择,使用Linq会使情况更糟。
理想情况下,我们想要一个具有以下功能的集合:
- 自动分类。
- 渐进复杂度的低增长。
- 快速插入操作。
- 快速拆卸操作。
- 轻松浏览元素。
SortedSet似乎是一个不错的选择,但它不知道如何包含重复项。如果我们按EstimatedTotalCost编写排序,那么将消除价格相同(但坐标不同!)的所有顶点。在障碍物少的空旷地区,这并不可怕,而且它可以加快算法的速度,但是在狭窄的迷宫中,结果将是路线不正确且结果为假阴性。
因此,我们将实现我们的集合-二进制堆!经典实现满足5个需求中的4个,并且进行少量修改将使该集合非常适合我们的情况。
集合是部分排序的树,插入和删除操作的复杂度等于log(n)。
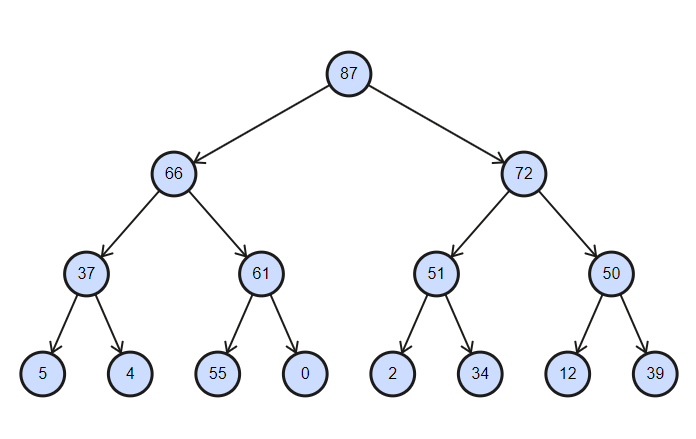
二进制堆按降序排序
internal interface IBinaryHeap<in TKey, T>
{
void Enqueue(T item);
T Dequeue();
void Clear();
bool TryGet(TKey key, out T value);
void Modify(T value);
int Count { get; }
}让我们写一个简单的部分:
internal class BinaryHeap : IBinaryHeap<Vector2Int, PathNode>
{
private readonly IDictionary<Vector2Int, int> map;
private readonly IList<PathNode> collection;
private readonly IComparer<PathNode> comparer;
public BinaryHeap(IComparer<PathNode> comparer)
{
this.comparer = comparer;
collection = new List<PathNode>();
map = new Dictionary<Vector2Int, int>();
}
public int Count => collection.Count;
public void Clear()
{
collection.Clear();
map.Clear();
}
// ...
}我们将使用IComparer对顶点进行自定义排序。IList实际上是我们将使用的顶点存储。我们需要IDictionary来跟踪顶点的索引以便快速删除它们(二进制堆的标准实现使我们可以仅使用top元素方便地工作)。
让我们添加一个元素:
public void Enqueue(PathNode item)
{
collection.Add(item);
int i = collection.Count - 1;
map[item.Position] = i;
// Sort nodes from bottom to top.
while(i > 0)
{
int j = (i - 1) / 2;
if (comparer.Compare(collection[i], collection[j]) <= 0)
break;
Swap(i, j);
i = j;
}
}
private void Swap(int i, int j)
{
PathNode temp = collection[i];
collection[i] = collection[j];
collection[j] = temp;
map[collection[i].Position] = i;
map[collection[j].Position] = j;
}每个新元素都添加到树的最后一个单元格中,然后从下到上进行部分排序:按照从新元素到根的节点进行排序,直到最小的元素尽可能高。由于不是对整个集合进行排序,而是仅对顶部和最后一个之间的中间节点进行排序,因此该操作的复杂度为log(n)。
获取物品:
public PathNode Dequeue()
{
if (collection.Count == 0) return default;
PathNode result = collection.First();
RemoveRoot();
map.Remove(result.Position);
return result;
}
private void RemoveRoot()
{
collection[0] = collection.Last();
map[collection[0].Position] = 0;
collection.RemoveAt(collection.Count - 1);
// Sort nodes from top to bottom.
var i = 0;
while(true)
{
int largest = LargestIndex(i);
if (largest == i)
return;
Swap(i, largest);
i = largest;
}
}
private int LargestIndex(int i)
{
int leftInd = 2 * i + 1;
int rightInd = 2 * i + 2;
int largest = i;
if (leftInd < collection.Count
&& comparer.Compare(collection[leftInd], collection[largest]) > 0)
largest = leftInd;
if (rightInd < collection.Count
&& comparer.Compare(collection[rightInd], collection[largest]) > 0)
largest = rightInd;
return largest;
}与添加类似:将根元素删除,并将最后一个元素放在其位置。然后,从上到下的部分排序会交换项目,以便最小的项目在顶部。
之后,我们实现对元素的搜索并更改它:
public bool TryGet(Vector2Int key, out PathNode value)
{
if (!map.TryGetValue(key, out int index))
{
value = default;
return false;
}
value = collection[index];
return true;
}
public void Modify(PathNode value)
{
if (!map.TryGetValue(value.Position, out int index))
throw new KeyNotFoundException(nameof(value));
collection[index] = value;
}这里没有什么复杂的事情:我们通过字典搜索元素的索引,然后直接访问它。
堆的通用版本:
internal class BinaryHeap<TKey, T> : IBinaryHeap<TKey, T> where TKey : IEquatable<TKey>
{
private readonly IDictionary<TKey, int> map;
private readonly IList<T> collection;
private readonly IComparer<T> comparer;
private readonly Func<T, TKey> lookupFunc;
public BinaryHeap(IComparer<T> comparer, Func<T, TKey> lookupFunc, int capacity)
{
this.comparer = comparer;
this.lookupFunc = lookupFunc;
collection = new List<T>(capacity);
map = new Dictionary<TKey, int>(capacity);
}
public int Count => collection.Count;
public void Enqueue(T item)
{
collection.Add(item);
int i = collection.Count - 1;
map[lookupFunc(item)] = i;
while(i > 0)
{
int j = (i - 1) / 2;
if (comparer.Compare(collection[i], collection[j]) <= 0)
break;
Swap(i, j);
i = j;
}
}
public T Dequeue()
{
if (collection.Count == 0) return default;
T result = collection.First();
RemoveRoot();
map.Remove(lookupFunc(result));
return result;
}
public void Clear()
{
collection.Clear();
map.Clear();
}
public bool TryGet(TKey key, out T value)
{
if (!map.TryGetValue(key, out int index))
{
value = default;
return false;
}
value = collection[index];
return true;
}
public void Modify(T value)
{
if (!map.TryGetValue(lookupFunc(value), out int index))
throw new KeyNotFoundException(nameof(value));
collection[index] = value;
}
private void RemoveRoot()
{
collection[0] = collection.Last();
map[lookupFunc(collection[0])] = 0;
collection.RemoveAt(collection.Count - 1);
var i = 0;
while(true)
{
int largest = LargestIndex(i);
if (largest == i)
return;
Swap(i, largest);
i = largest;
}
}
private void Swap(int i, int j)
{
T temp = collection[i];
collection[i] = collection[j];
collection[j] = temp;
map[lookupFunc(collection[i])] = i;
map[lookupFunc(collection[j])] = j;
}
private int LargestIndex(int i)
{
int leftInd = 2 * i + 1;
int rightInd = 2 * i + 2;
int largest = i;
if (leftInd < collection.Count && comparer.Compare(collection[leftInd], collection[largest]) > 0) largest = leftInd;
if (rightInd < collection.Count && comparer.Compare(collection[rightInd], collection[largest]) > 0) largest = rightInd;
return largest;
}
}现在,我们的寻路速度相当快,几乎没有垃圾产生。即将完成!
5.可重复使用的集合
该算法的开发着眼于每秒调用数十次的能力。从根本上说,任何垃圾的生成都是不可接受的:加载的垃圾收集器会(并且将会!)导致性能定期下降。
创建类时,除输出外,所有集合都已声明一次,我们还将在其中放置最后一个集合:
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];
private readonly IBinaryHeap<Vector2Int, PathNode> frontier;
private readonly HashSet<Vector2Int> ignoredPositions;
private readonly IList<Vector2Int> output;
private readonly IDictionary<Vector2Int, Vector2Int> links;
public Path()
{
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap(comparer);
ignoredPositions = new HashSet<Vector2Int>();
output = new List<Vector2Int>();
links = new Dictionary<Vector2Int, Vector2Int>();
}public方法采用以下形式:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles))
return Array.Empty<Vector2Int>();
output.Clear();
output.Add(target);
while (links.TryGetValue(target, out target))
output.Add(target);
return output.AsReadOnly();
}这不仅仅是创建收藏!集合填充后会动态更改其容量;如果路径较长,则调整大小将发生数十次。这是非常占用内存的。当我们清除集合并在不声明新集合的情况下重复使用它们时,它们将保留其容量。初始化集合并更改其容量时,第一个路径构造会产生大量垃圾,但是后续调用在没有任何分配的情况下都可以正常工作(前提是每个计算路径的长度为正负相同,并且没有明显的失真)。因此,下一点是:
6.(奖金)公布馆藏规模
立即出现许多问题:
- 最好是将负载分担给Path类的构造函数,还是在第一次调用pathfinder时保留?
- 有什么能力养活这些收藏品?
- 立即宣布更大的容量还是让产品系列自己扩展会更便宜?
可以立即回答第三个问题:如果我们有成千上万个用于查找路径的单元,那么立即为我们的集合分配一定的大小绝对便宜。
其他两个问题更难回答。需要针对每个用例凭经验确定这些问题的答案。如果我们仍然决定将负载移到构造函数中,那么该是对算法的步骤数添加限制的时候了:
public Path(int maxSteps)
{
this.maxSteps = maxSteps;
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap(comparer, maxSteps);
ignoredPositions = new HashSet<Vector2Int>(maxSteps);
output = new List<Vector2Int>(maxSteps);
links = new Dictionary<Vector2Int, Vector2Int>(maxSteps);
}在GenerateNodes内部,更正循环:
var step = 0;
while (frontier.Count > 0 && step++ <= maxSteps)
{
// ...
}因此,将立即为集合分配等于最大路径的容量。一些集合不仅包含遍历的节点,还包含其相邻节点:对于此类集合,您可以使用比指定节点大4-5倍的容量。
这似乎有点太多,但是对于接近声明的最大值的路径,集合大小的分配所花费的内存比动态扩展少一半至三倍。另一方面,如果为maxSteps值分配非常大的值并生成短路径,则这样的创新只会有害。哦,您不应该尝试使用int.MaxValue!
最佳解决方案是创建两个构造函数,其中一个用于设置集合的初始容量。然后,我们的类可以在两种情况下使用,而无需对其进行修改。
你还能做什么?
- .
- XML-.
- GetHashCode Vector2Int. , , , .
- , . .
- IComparable PathNode EqualityComparer. .
- : , . , , .
- 在我们的界面中更改方法签名以更好地体现其本质:
bool Calculate(Vector2Int start, Vector2Int target, IReadOnlyCollection<Vector2Int> obstacles, out IReadOnlyCollection<Vector2Int> path);
因此,该方法清楚地显示了其操作的逻辑,而原始方法应这样调用:CalculateOrReturnEmpty。
Path类的最终版本:
/// <summary>
/// Reusable A* path finder.
/// </summary>
public class Path : IPath
{
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];
private readonly int maxSteps;
private readonly IBinaryHeap<Vector2Int, PathNode> frontier;
private readonly HashSet<Vector2Int> ignoredPositions;
private readonly List<Vector2Int> output;
private readonly IDictionary<Vector2Int, Vector2Int> links;
/// <summary>
/// Creation of new path finder.
/// </summary>
/// <exception cref="ArgumentOutOfRangeException"></exception>
public Path(int maxSteps = int.MaxValue, int initialCapacity = 0)
{
if (maxSteps <= 0)
throw new ArgumentOutOfRangeException(nameof(maxSteps));
if (initialCapacity < 0)
throw new ArgumentOutOfRangeException(nameof(initialCapacity));
this.maxSteps = maxSteps;
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap<Vector2Int, PathNode>(comparer, a => a.Position, initialCapacity);
ignoredPositions = new HashSet<Vector2Int>(initialCapacity);
output = new List<Vector2Int>(initialCapacity);
links = new Dictionary<Vector2Int, Vector2Int>(initialCapacity);
}
/// <summary>
/// Calculate a new path between two points.
/// </summary>
/// <exception cref="ArgumentNullException"></exception>
public bool Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles,
out IReadOnlyCollection<Vector2Int> path)
{
if (obstacles == null)
throw new ArgumentNullException(nameof(obstacles));
if (!GenerateNodes(start, target, obstacles))
{
path = Array.Empty<Vector2Int>();
return false;
}
output.Clear();
output.Add(target);
while (links.TryGetValue(target, out target)) output.Add(target);
path = output;
return true;
}
private bool GenerateNodes(Vector2Int start, Vector2Int target, IReadOnlyCollection<Vector2Int> obstacles)
{
frontier.Clear();
ignoredPositions.Clear();
links.Clear();
frontier.Enqueue(new PathNode(start, target, 0));
ignoredPositions.UnionWith(obstacles);
var step = 0;
while (frontier.Count > 0 && step++ <= maxSteps)
{
PathNode current = frontier.Dequeue();
ignoredPositions.Add(current.Position);
if (current.Position.Equals(target)) return true;
GenerateFrontierNodes(current, target);
}
// All nodes analyzed - no path detected.
return false;
}
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
neighbours.Fill(parent, target);
foreach (PathNode newNode in neighbours)
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
if (!frontier.TryGet(newNode.Position, out PathNode existingNode))
{
frontier.Enqueue(newNode);
links[newNode.Position] = parent.Position;
}
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < existingNode.TraverseDistance)
{
frontier.Modify(newNode);
links[newNode.Position] = parent.Position;
}
}
}
}链接到源代码