最近,“车间”中的同事开始独立地问我:如何从一个SDR接收器同时获取所有蓝牙通道?带宽允许存在SDR,其输出带宽为80 MHz或更高。您当然可以在FPGA上完成,但是开发时间会很长。很长时间以来,我就知道在GPU上执行此操作非常容易,仅此而已!
蓝牙标准定义了两个版本的物理层:经典和低能耗。规格在这里。该文档非常大;完整阅读文档对于大脑来说是危险的。幸运的是,大型仪器公司可以创建有关主题的可视文档。例如,泰克和National Instruments。就材料展示的质量而言,我绝对没有机会与他们竞争。如果您有兴趣,请点击链接。
我需要了解的有关创建多通道滤波器的物理层的唯一信息是频率网格阶跃和调制率。它们列在指定的文档之一中:
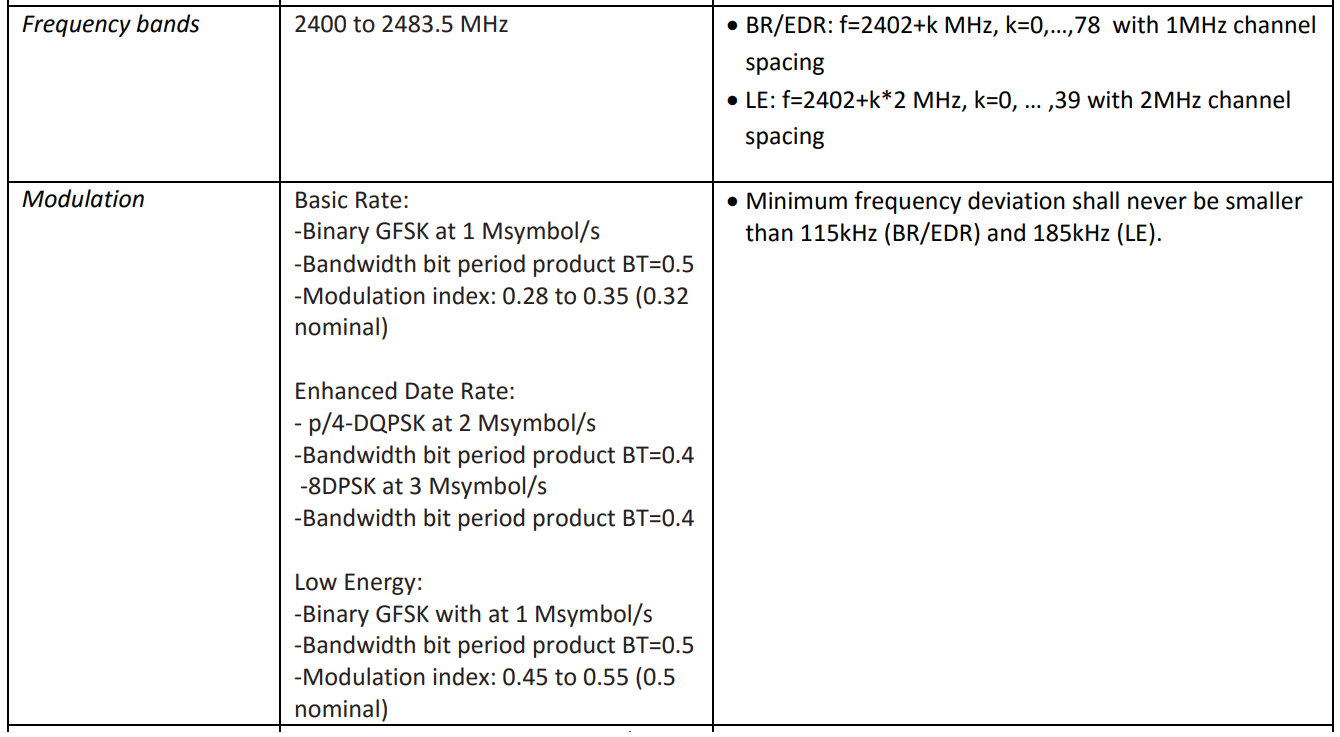
, 80 79 1 , , 40 2 . 1 2 , .
, .
Bluetooth Classic Bluetooth Low Energy. , . , "" . . , .
1 ( ) 500 , 480 . 2 1 240 , . . filterDesigner -header:
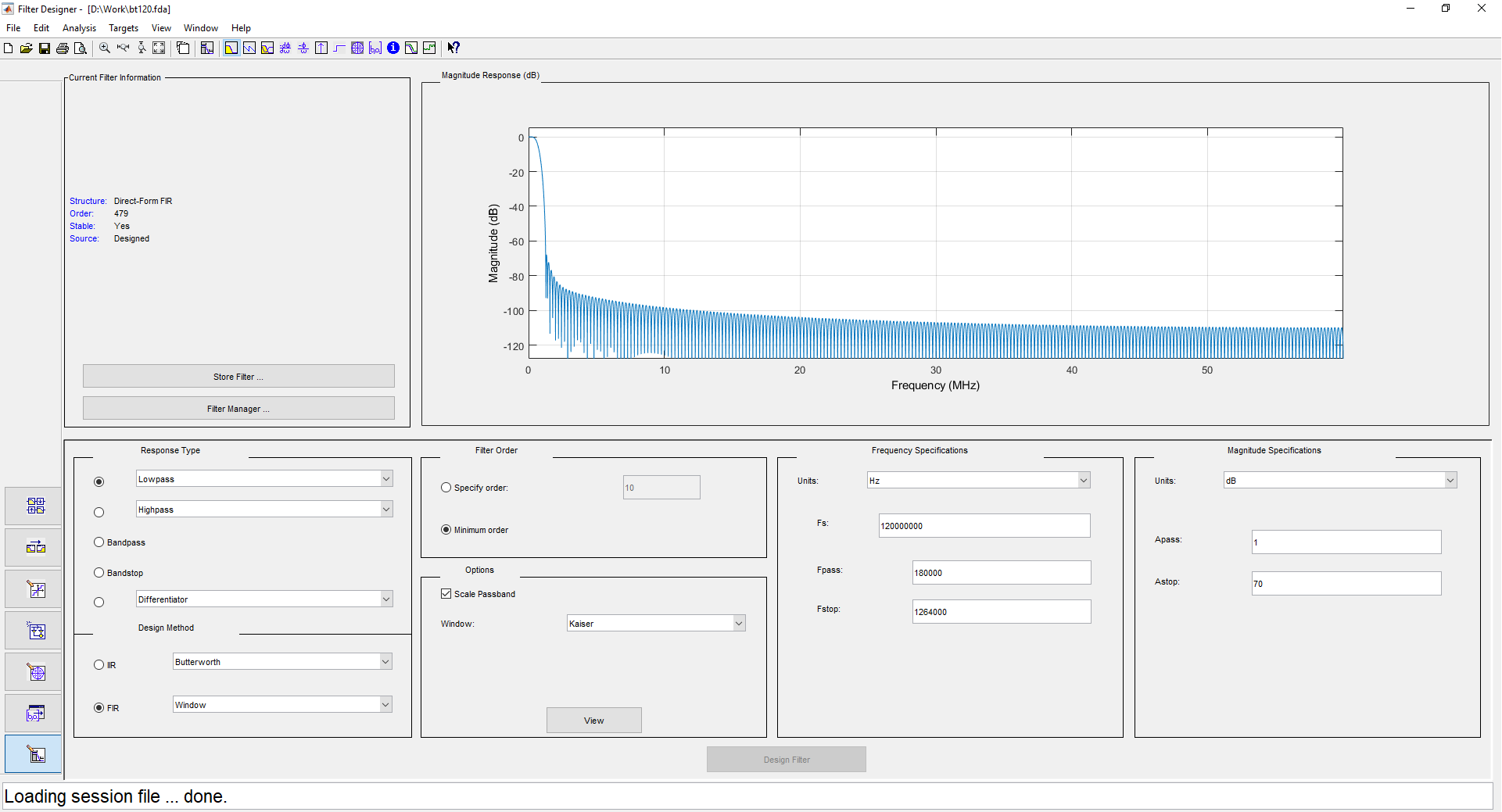
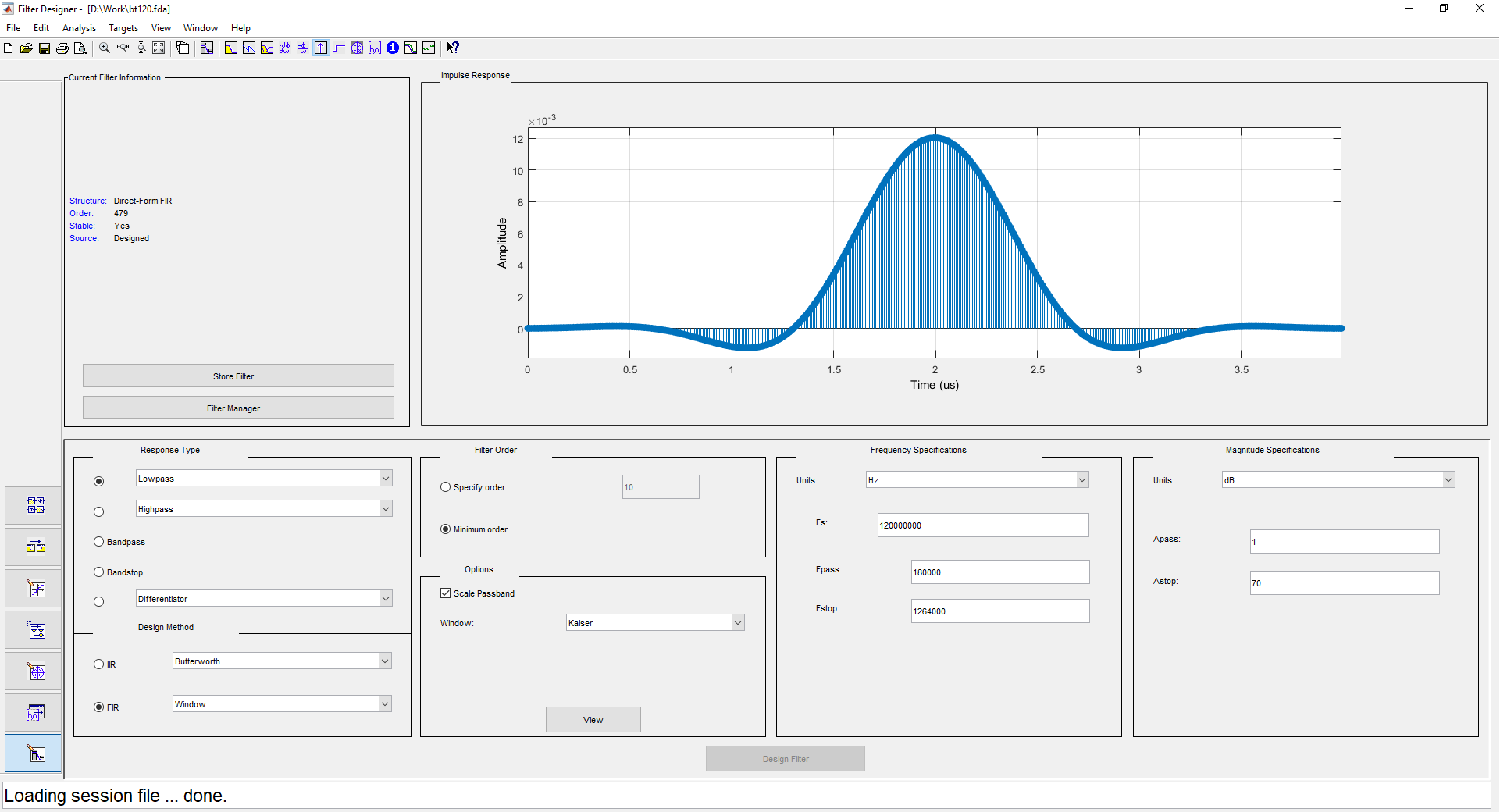
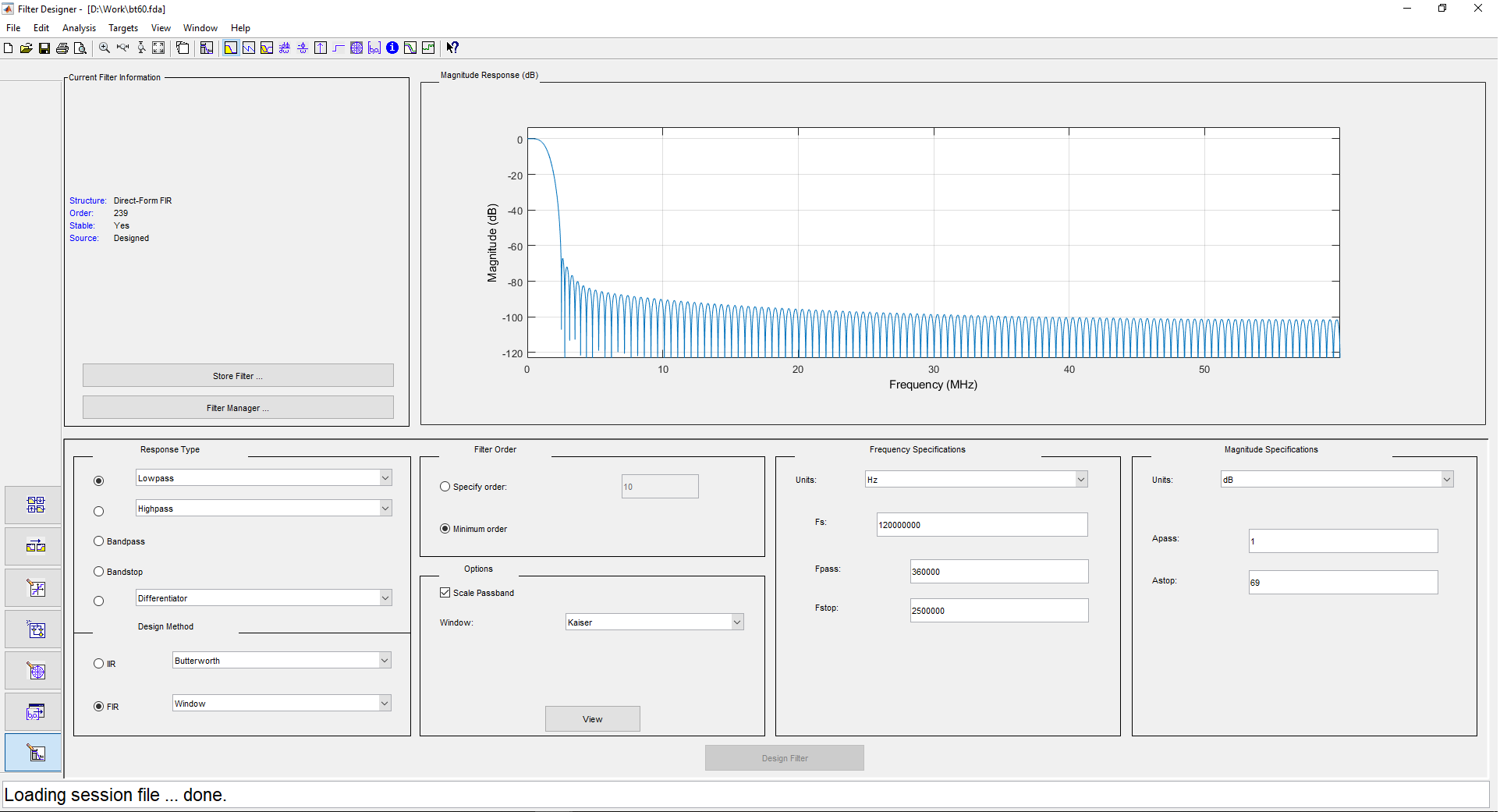
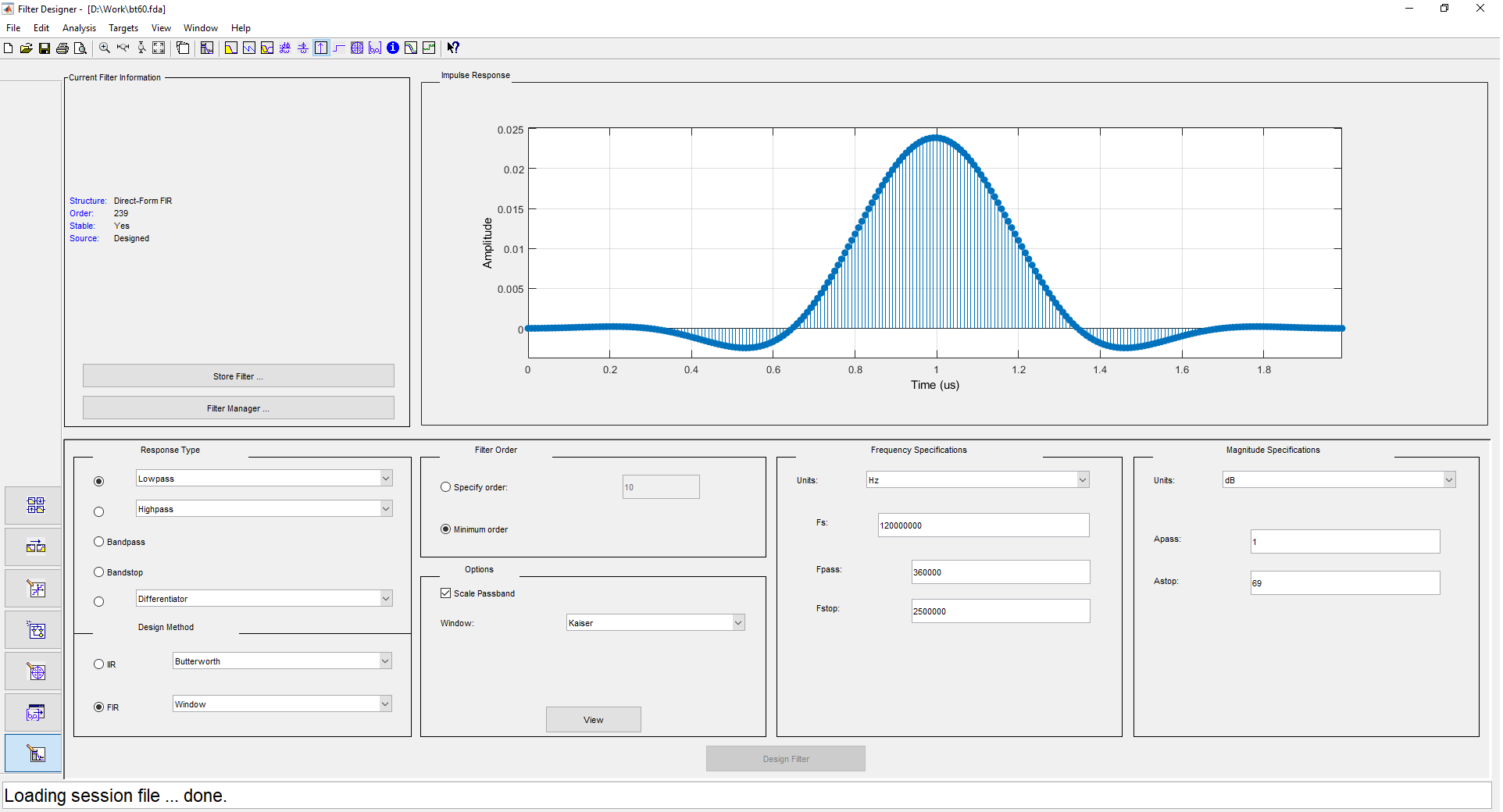
: DDC (Digital Down Converter). , . — - . .
GPU : , CUDA . Polyphase or WOLA (Weight, Overlap and Add) FFT Filterbank. . , 11 ( ), :
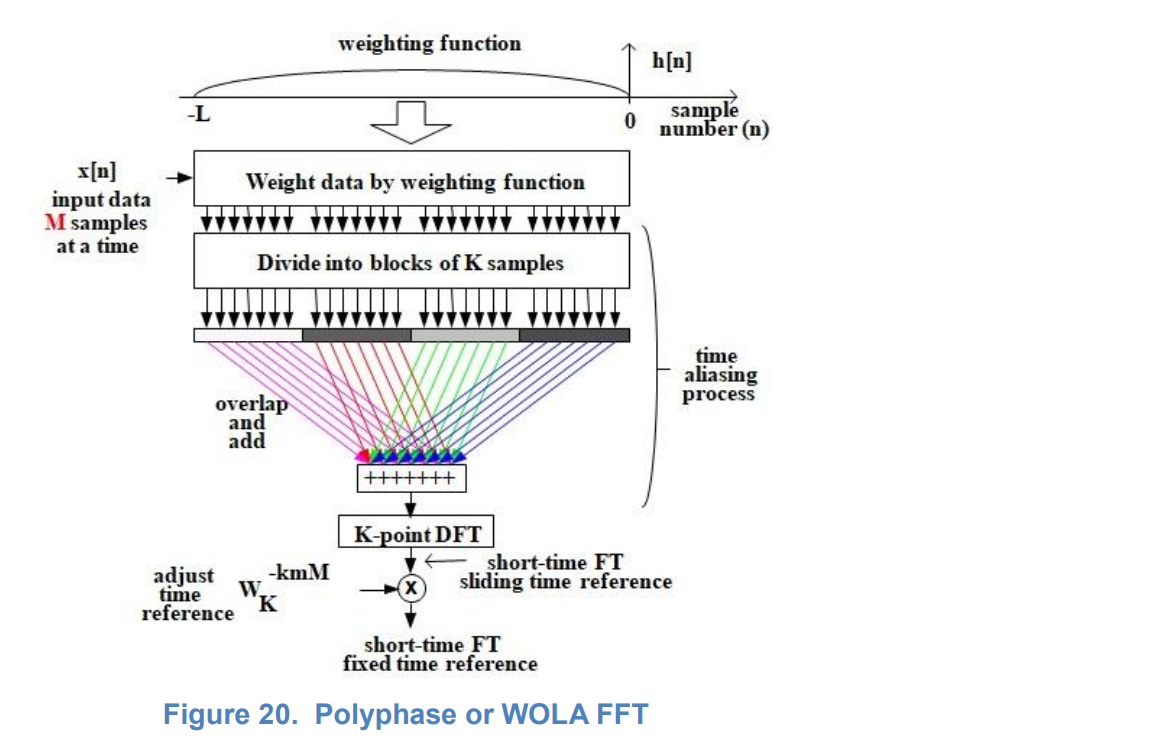
. , . , , . , . , , . . , ( ), . , . , , ,
, , .
, . " " FMC126P. . FMC AD9371 100 . .
- GPU GTX 1050. (, : , , ). .
, - . GPU. , .
, , :
__global__ void cuComplexMultiplyWindowKernel(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result) {
__shared__ cuComplex multiplicationResult[480];
multiplicationResult[threadIdx.x] = cuComplexMultiplyFloat(data[threadIdx.x + windowSize / 4 * blockIdx.x], window[threadIdx.x]);
__syncthreads();
cuComplex sum;
sum.x = sum.y = 0;
if (threadIdx.x < windowSize / 4) {
for(int i = 0; i < 4; i++) {
sum = cuComplexAdd(sum, multiplicationResult[threadIdx.x + i * windowSize / 4]);
}
result[threadIdx.x + windowSize / 4 * blockIdx.x] = sum;
}
}
cudaError_t cuComplexMultiplyWindow(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result, size_t dataSize, cudaStream_t stream) {
size_t windowStep = windowSize / 4;
cuComplexMultiplyWindowKernel<<<dataSize / windowStep - 3, windowSize, 1024, stream>>>(data, window, windowSize, result);
return cudaGetLastError();
}
, , , , .
. AD9371 2450 , .
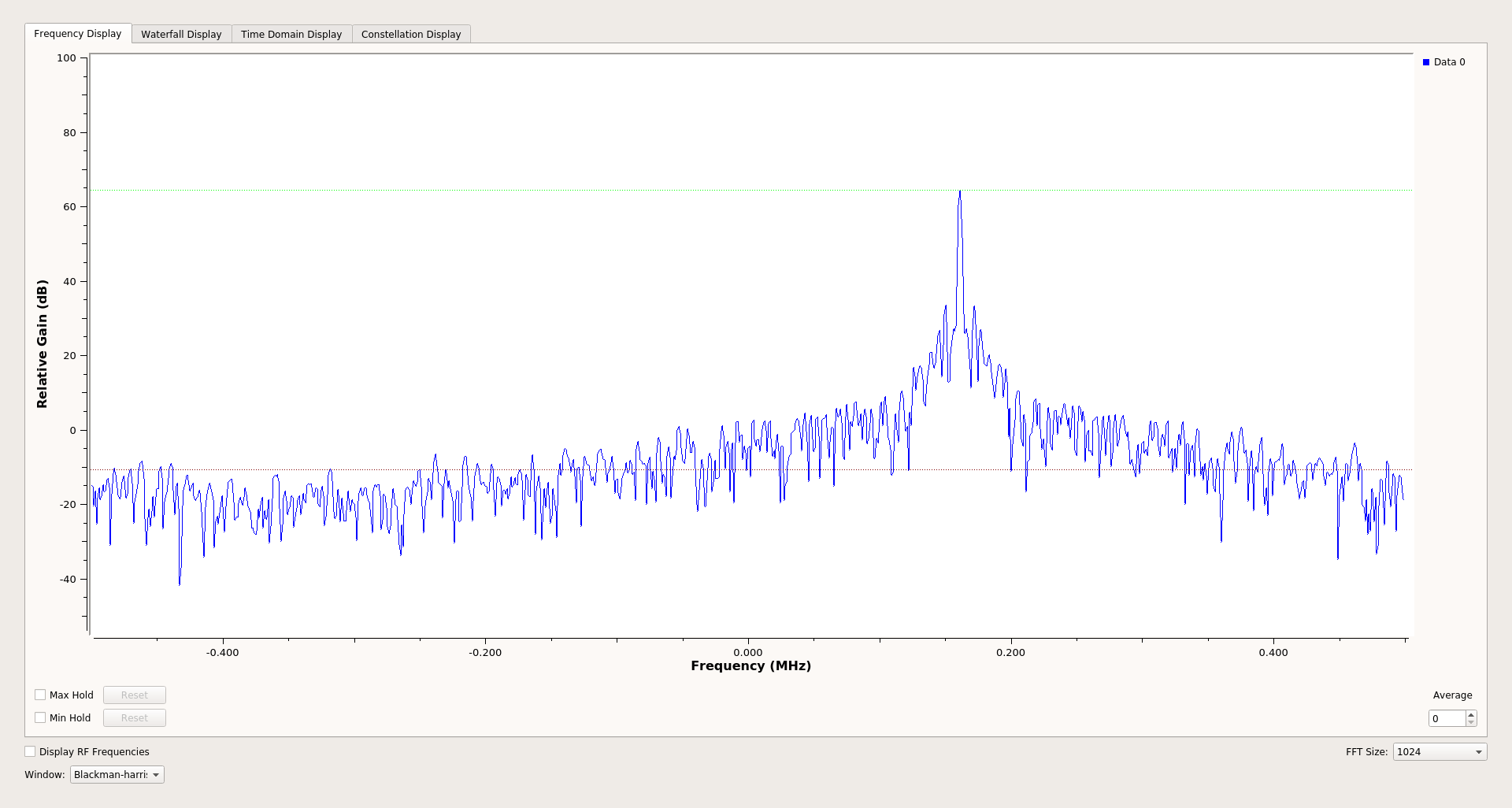
: XRTX , - .
gaudima, !