
延续有关数据科学中实际问题的注释循环,今天我们将处理一个生活中的问题,并观察一路等待着什么问题。
例如,除了数据科学,我很喜欢运动,很长一段时间以来,我的目标之一就是马拉松。那里的马拉松比赛在哪里,问题是-要跑多少?通常,这个问题的答案是肉眼给出的-“好吧,他们平均在奔跑”或“这是X好时光”!
今天,我们将处理一个重要问题-我们将在现实生活中应用数据科学并回答以下问题:
莫斯科马拉松赛的数据告诉我们什么?
更准确地说,如开始时从表中已经很清楚的那样-我们将收集数据,弄清楚谁跑了以及如何跑。同时,这将帮助我们了解我们是否应该干预并允许我们明智地评估自己的优势!
TL; DR:我收集了2018/2019年莫斯科马拉松比赛的数据,分析了参赛者的时间和表现,并公开了代码和数据。
数据采集
通过快速谷歌搜索,我们找到了过去两年,2019年和2018年的结果。
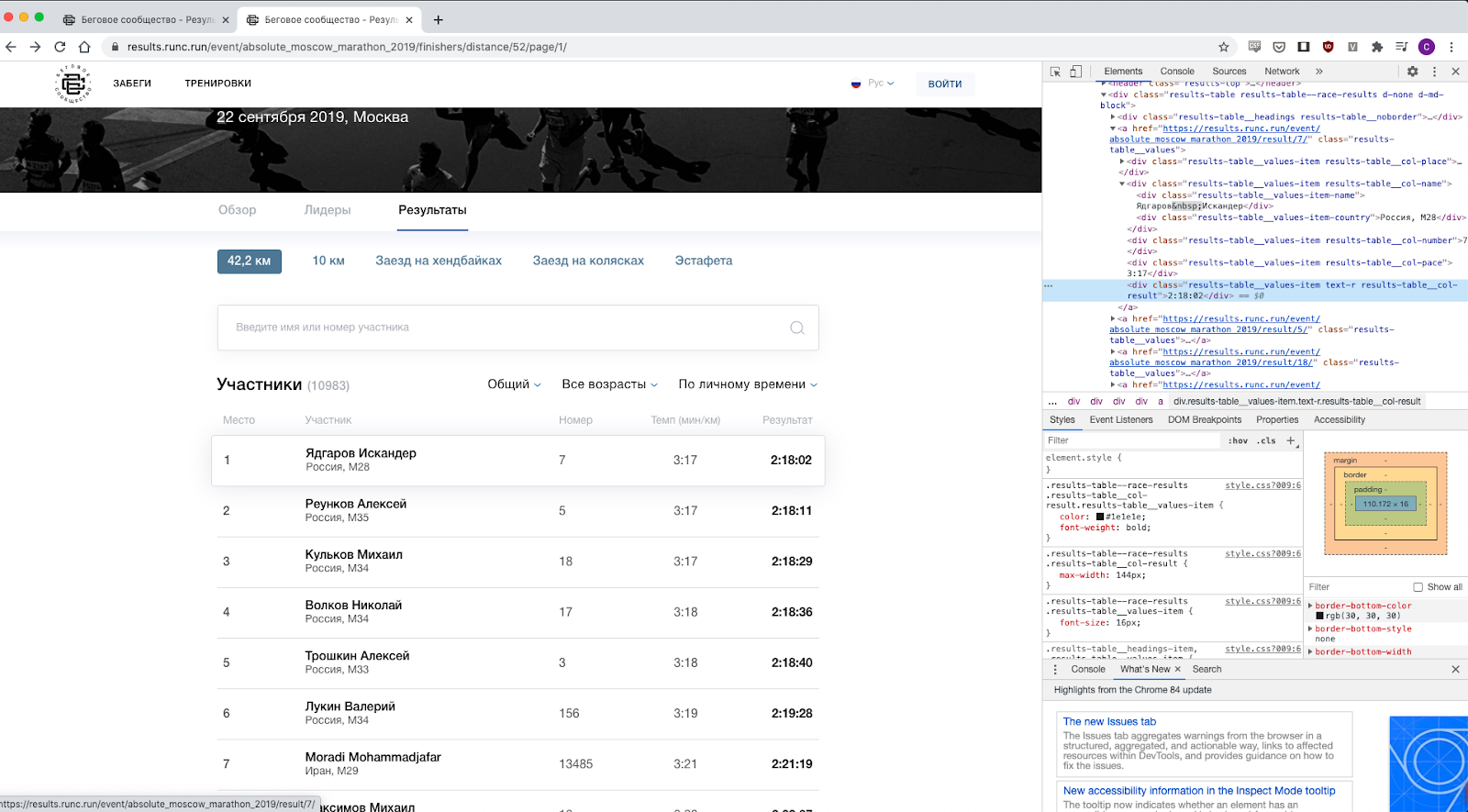
我仔细查看了网页,很明显,数据很容易获得-您只需要弄清楚哪个类负责什么,例如,“ results-table__col-result”类,当然还有结果等。
仍然需要了解如何从那里获取所有数据。
事实证明,这并不困难,因为直接分页,并且我们实际上遍历了整个数字段。宾果游戏,我在这里发布了2019年和2018年收集的数据,如果有人对进一步的分析感兴趣,那么可以在这里下载数据:此处和此处。
我要修补什么?
- — - , , - (, ).
- - , — « ».
- Url- — - , url — , — .
- — — 2016, 2017… , 2019 — , — , — , , .
- NA: DNF, DQ, "-" — , , .
- 数据类型:时间是一个时间增量,但是由于重新启动和无效值,我们必须使用过滤器并清除时间值,以便我们使用纯时间结果来计算平均值-这里的所有结果都是对那些谁有有效时间。
如果有人决定继续收集有趣的运行数据,这是剧透代码。
解析器代码
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm
def main():
for year in [2018]:
print(f"processing year: {year}")
crawl_year(year)
def crawl_year(year):
outfilename = f"results_{year}.txt"
with open(outfilename, "a") as fout:
print("name,result,place,country,category", file=fout)
# parametorize year
for i in tqdm(range(1, 1100)):
url = f"https://results.runc.run/event/absolute_moscow_marathon_2018/finishers/distance/1/page/{i}/"
html = requests.get(url)
soup = BeautifulSoup(html.text)
names = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__values-item-name"}),
)
)
results = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-result"}),
)
)[1:]
categories = list(
map(
lambda x: x.text.strip().replace(" ",""),
soup.find_all("div", {"class": "results-table__values-item-country"}),
)
)
places = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-place"}),
)
)[1:]
for name, result, place, category in zip(names, results, places, categories):
with open(outfilename, "a") as fout:
print(name, result, place, category, sep=",", file=fout)
if __name__ == "__main__":
main()
```
时间和结果分析
让我们继续分析数据和实际比赛结果。
二手熊猫,numpy,matplotlib和seaborn-均为经典。
除了所有阵列的平均值之外,我们还将分别考虑以下几组:
- 男人-由于我属于这一类,因此这些结果对我来说很有趣。
- 女人是为了对称。
- 35 — «» , — .
- 2018 2019 — ?.
首先,让我们快速浏览一下下表-再次在这里,以免滚动:参与者更多,平均95%的人到达终点线,并且大多数参与者是男性。好的,这意味着我平均属于主要人群,平均数据应该代表我的平均时间。让我们继续。
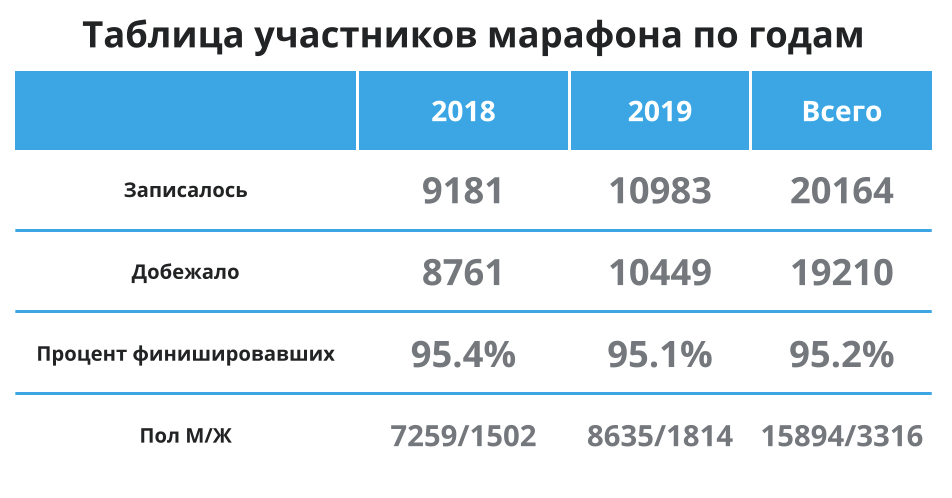

我们可以看到,2018年和2019年的平均水平几乎没有变化-2019年跑步者的速度快了1.5分钟左右。我感兴趣的组之间的差异可以忽略不计。
让我们继续进行整个发行。首先是比赛的总时间。
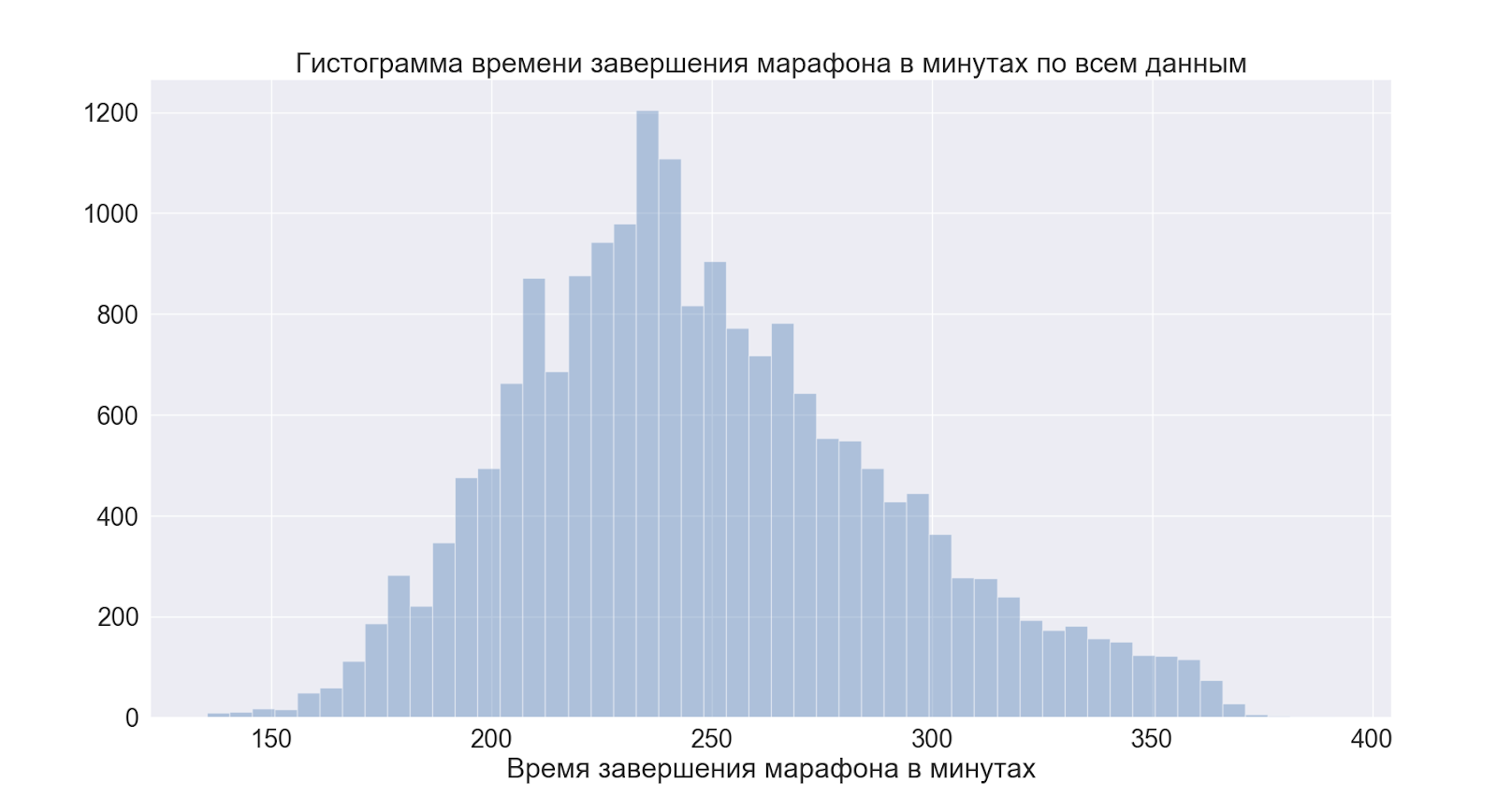
我们可以看到高峰在4点之前-对于那些喜欢“运行良好” =“运行4小时”的人来说,这是一个条件标记,数据证实了谣言。
接下来,让我们看看情况在一年中平均如何变化。
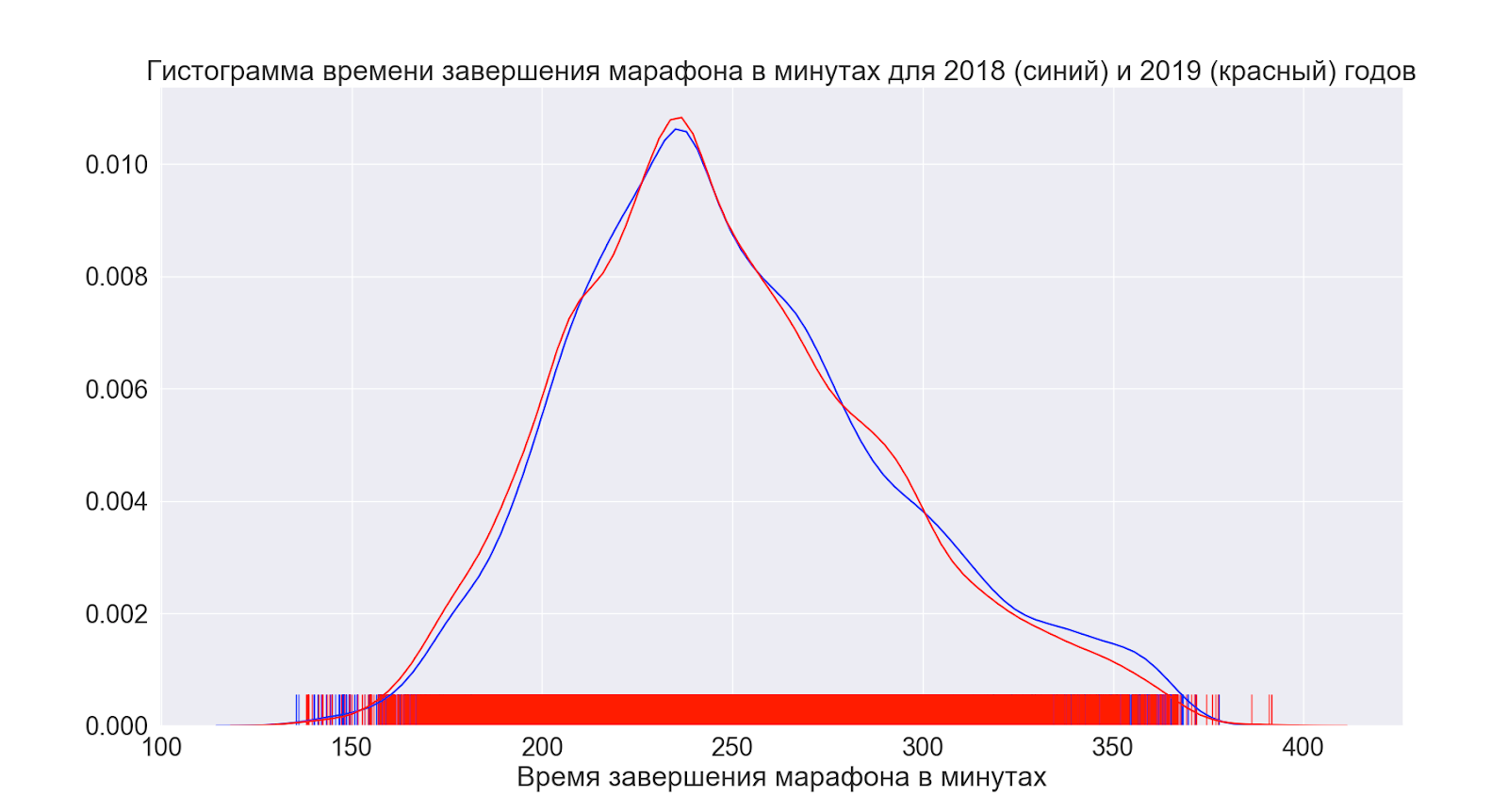
如我们所见,实际上,什么都没有改变-分布看起来几乎是相同的。
接下来,考虑按性别的分布:

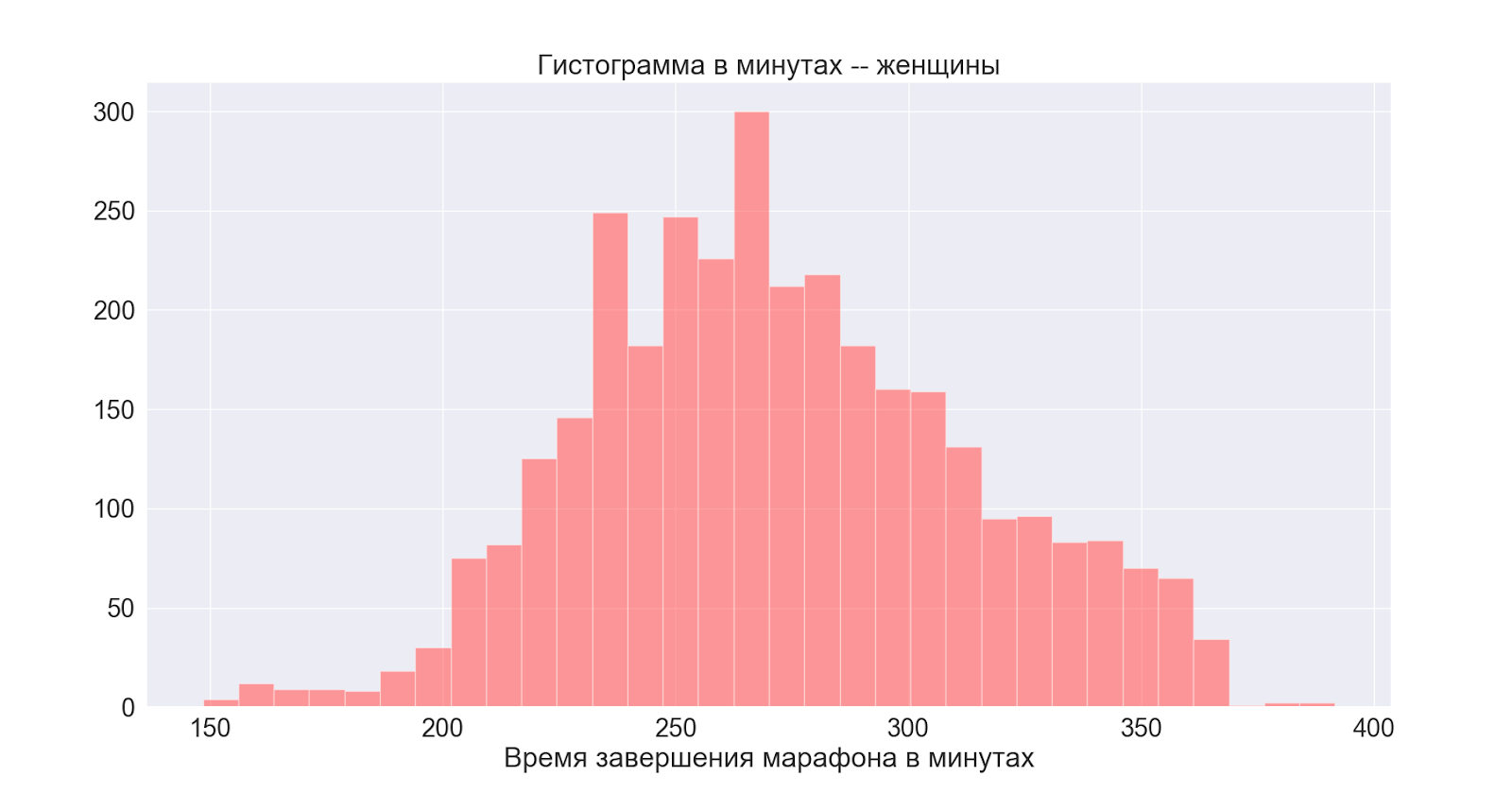
通常,两个分布都是正态的,中心稍有不同-我们看到男性的高峰也在主要(一般)分布上表现出来。
另外,让我们继续进行对我来说最有趣的小组:
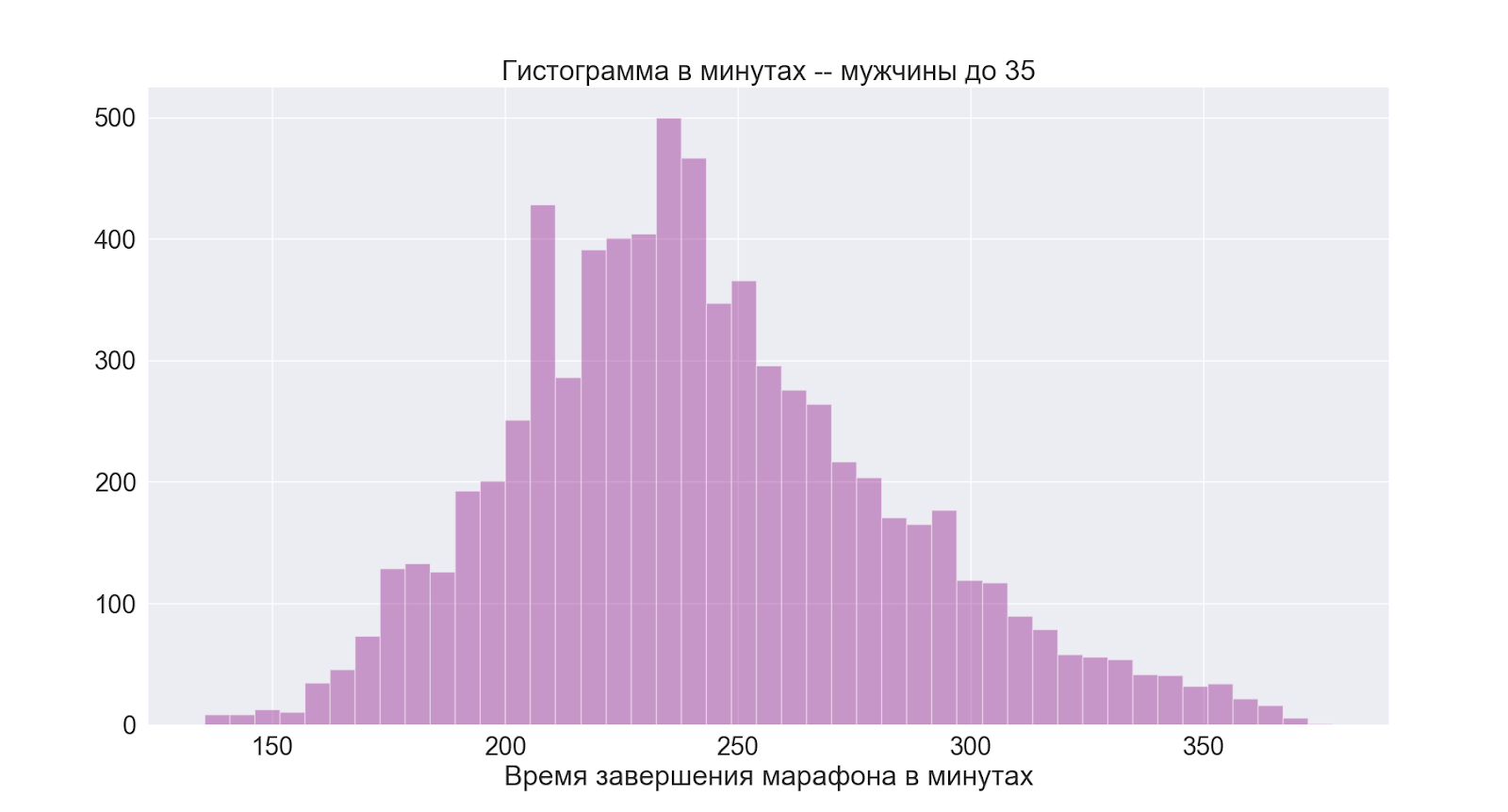
如我们所见,情况基本上与整个男性小组相同。
由此得出的结论是,对于我来说,4小时也是一个不错的平均时间。
研究参与者的进步2018→2019
有趣的是:出于某种原因,我认为现在我可以快速收集数据,并且可以更深入地分析,在其中寻找模式数小时,依此类推。事实恰恰相反,数据收集比分析本身更困难-根据经典,使用网络,原始数据,清理,格式化,转换等工作要比分析和可视化花费更长的时间。不要忘记,小事情会占用一些时间-但其中有很多(小事情),最后它们会占用您整个晚上。
另外,我想看看两次参加比赛的人如何通过比较各年之间的数据来改善他们的成绩,从而能够建立以下各项:
- 两年共有14人参加,但从未结束
- 89人在18 m处奔跑,但在19 m处失败
- 反之亦然124
- 能够同时运行两次的人平均将结果提高了4分钟
但这一切都变得非常有趣:
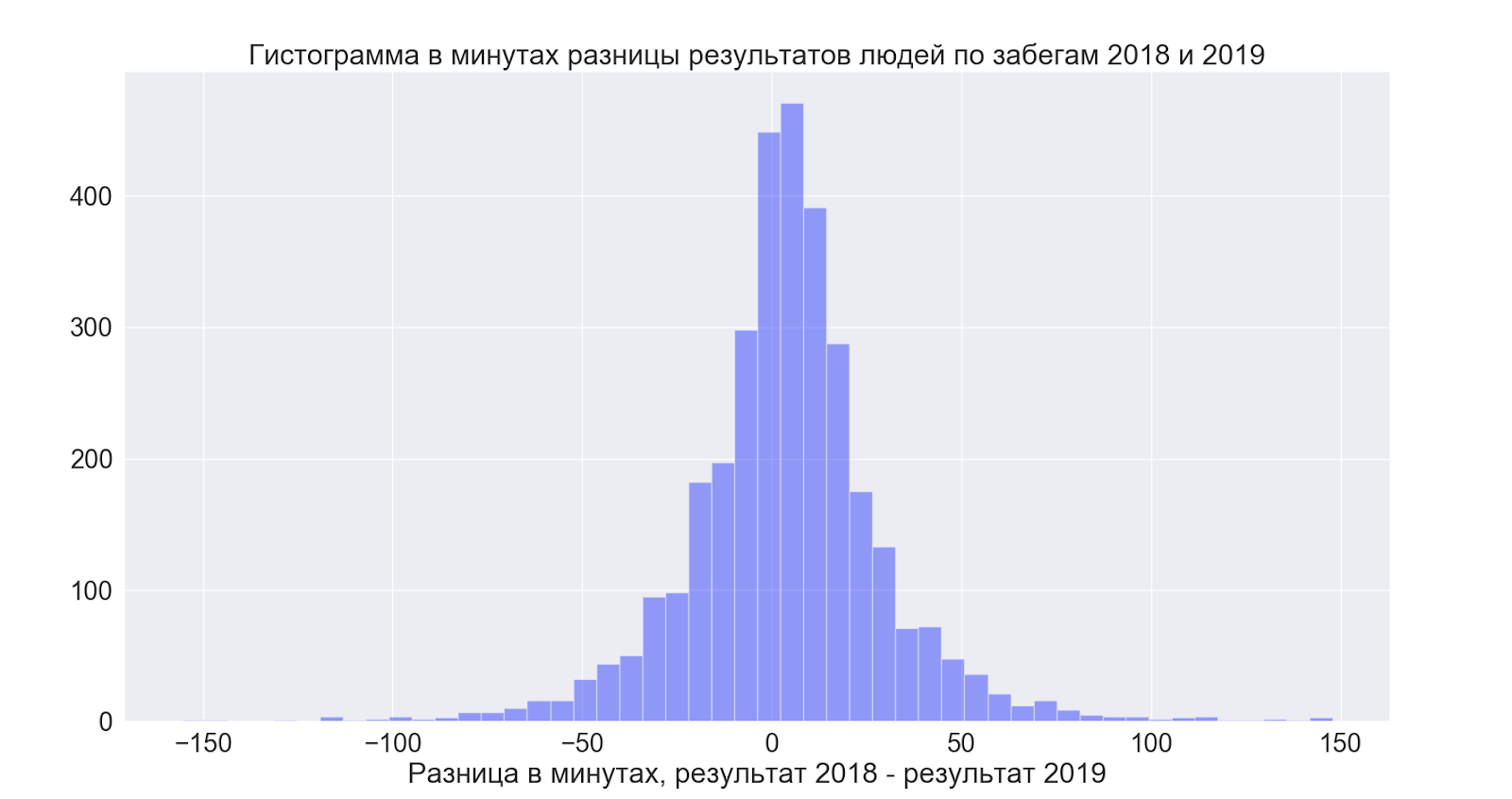
也就是说,平均而言,人们会略微改善结果-但总的来说,传播是令人难以置信的,而且在两个方向上都是如此-也就是说,希望它会更好-但从数据来看,结果总的来说是您想要的!
结论
我从分析的数据中为自己得出以下结论
- 总体而言,4小时是一个不错的平均目标。
- 主要的跑步者群体已经处于竞争激烈的时代(与我同组)。
- 平均而言,人们会略微改善结果,但总的来说,从数据来看,他们是如何到达那里的。
- 整个比赛的平均成绩在两年中大致相同。
- 从沙发上谈论马拉松比赛非常舒服。
