
在过去的三年中,Nvidia一直在开发图形芯片,其中除了用于着色器的常用内核外,还安装了其他一些内核。这些内核称为张量内核,已经在全球成千上万的台式机,笔记本电脑,工作站和数据中心中找到。但是它们的作用是什么?图形卡甚至需要它们吗?
今天,我们将解释张量是什么,以及在图形和深度学习世界中如何使用张量内核。
简短的数学课
为了了解张量内核在做什么以及它们可以用于什么,我们首先弄清楚张量是什么。所有微处理器,无论它们执行什么任务,都对数字执行数学运算(加法,乘法等)。
有时需要对这些数字进行分组,因为它们彼此之间具有一定的含义。例如,当芯片处理数据以渲染图形时,它可以将单个整数值(例如+2或+115)作为缩放因子,或将一组浮点数(+ 0.1,-0.5,+ 0.6)作为3D空间中点的坐标。在第二种情况下,点位置需要所有三个数据项。
张量是一个数学对象,描述了彼此相关的其他数学对象之间的关系。它们通常显示为数字数组,其尺寸如下所示。

最简单的张量类型的维数为零,由单个值组成;否则,它称为标量。随着维数的增加,我们会遇到其他常见的数学结构:
- 1维=向量
- 2维=矩阵
严格来说,标量是张量0 x 0,向量是1 x 0,矩阵是1 x 1,但是为了简单起见并参考GPU的张量核,我们将仅考虑矩阵形式的张量。
对矩阵执行的最重要的数学运算之一是乘法(或乘积)。让我们看看如何将具有四行和四列数据的两个矩阵彼此相乘:
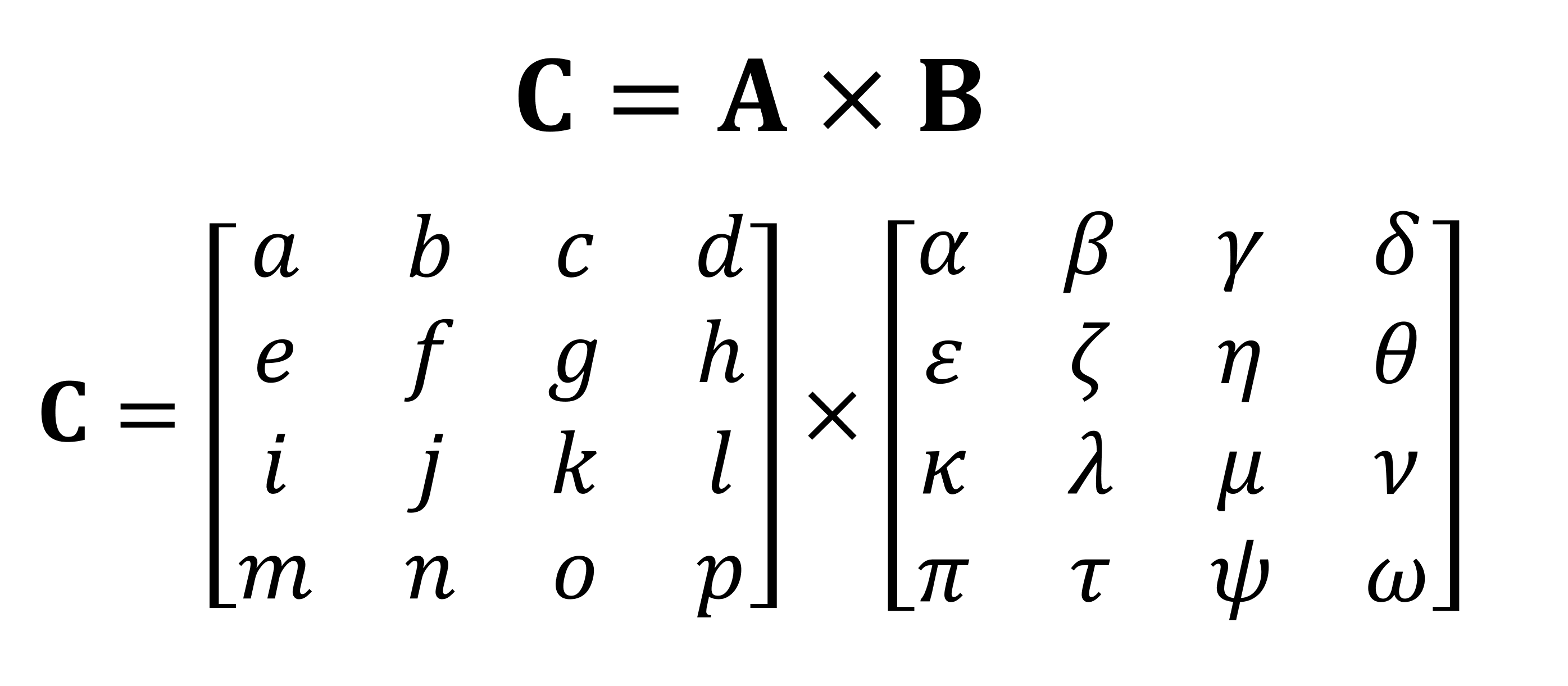
乘法的最终结果将始终是第一个矩阵中的行数和第二个矩阵中的列数相同。您如何将这两个数组相乘?像这样:
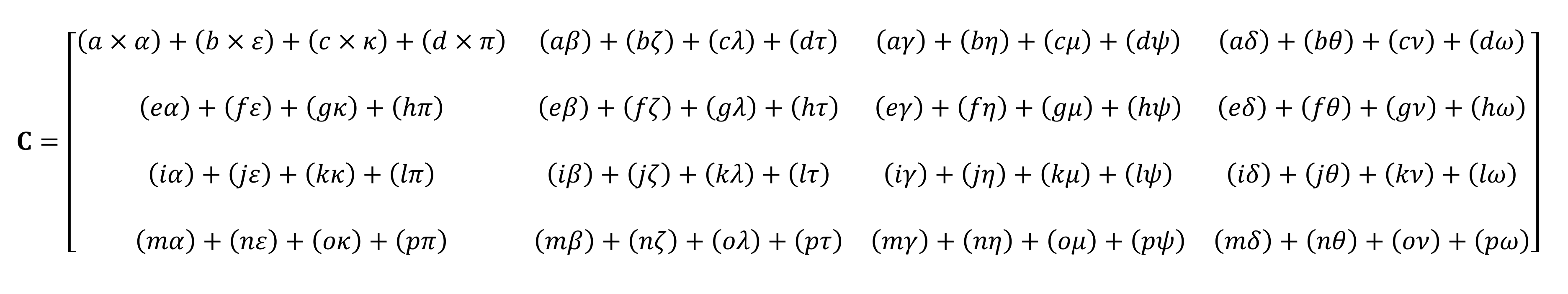
正如您所看到的那样,将不可能用手指数一下。矩阵的“简单”乘积的计算由一堆小的乘法和加法组成。由于任何现代中央处理器都可以执行这两种操作,因此每个台式机,笔记本电脑或平板电脑都可以执行最简单的张量。
但是,上面显示的示例包含64个乘法和48个加法。每个小乘积给出的值需要先存储在某个位置,然后才能将其添加到其他三个小乘积中,以便最终张量值可以在以后存储。因此,尽管矩阵乘法在数学上很简单,但是它们在计算上却很昂贵。 -必须使用大量寄存器,并且高速缓存必须能够应付大量读写操作。

最早引入AVX扩展的Intel Sandy Bridge架构
多年来,AMD和Intel处理器具有各种扩展(MMX,SSE和现在的AVX-所有这些都是SIMD,单指令多数据),允许处理器同时处理多个数字浮点; 这正是矩阵乘法所需要的。
但是处理器的一种特殊类型的专门设计成处理SIMD操作:图形处理单元(GPU)。
比普通计算器更聪明?
在图形世界中,有必要同时传输和处理矢量形式的大量信息。由于具有并行处理能力,GPU非常适合张量处理;所有现代GPU都支持称为GEMM(通用矩阵乘法)的功能。
这是一个“胶合”运算,其中两个矩阵相乘,然后将结果与另一个矩阵累加。矩阵格式有重要的限制,它们都与每个矩阵的行数和列数有关。

GEMM行和列要求:矩阵A(mxk),矩阵B(kxn),矩阵C(mxn)
用于在矩阵上执行运算的算法通常在矩阵为正方形时效果最佳(例如,一个10 x 10的数组可以工作)优于50 x 2),并且尺寸很小。但是,如果在专为此类操作设计的设备上进行处理,它们的性能仍然会更好。
2017年12月,英伟达发布了带有GPU的显卡,该显卡采用了新的Volta架构。它面向专业市场,因此该芯片未在GeForce型号中使用。它的独特之处在于它是第一个仅具有用于张量计算的内核的GPU。

带有GV100 Volta芯片的Nvidia Titan V图形卡。是的,您可以在其上运行Crysis Nvidia的
张量内核设计为每个时钟周期使用4个x 4矩阵(包含FP16值(16位浮点数))或FP16加FP32的矩阵运行64个GEMM。这样的张量很小,因此在处理实际数据集时,内核将处理大型矩阵的一小部分,从而得出最终答案。
不到一年后,Nvidia发布了Turing架构。这次,张量核心也被安装在GeForce模型中消费者层面。对该系统进行了改进,以支持其他数据格式,例如INT8(8位整数值),但其他方面与Volta相同。

今年早些时候,Ampere架构在A100数据中心GPU中首次亮相,这次Nvidia提高了性能(每周期256 GEMM,而不是64),增加了新的数据格式,并能够非常快速地处理稀疏张量(具有许多矩阵的矩阵)。零)。
程序员可以非常轻松地访问Volta,Turing和Ampere芯片的张量核心:代码只需要使用一个告诉API和驱动程序使用张量核心的标志,数据类型必须由这些核心支持,并且矩阵尺寸必须是8的倍数。执行时设备将照顾所有这些情况。
这一切都很棒,但是在处理GEMM方面,Tensor核心要比常规GPU核心好多少?
当Volta推出时,Anandtech在三张Nvidia卡上进行了数学测试:新的Volta,最强大的Pascal阵容,以及旧的Maxwell卡。
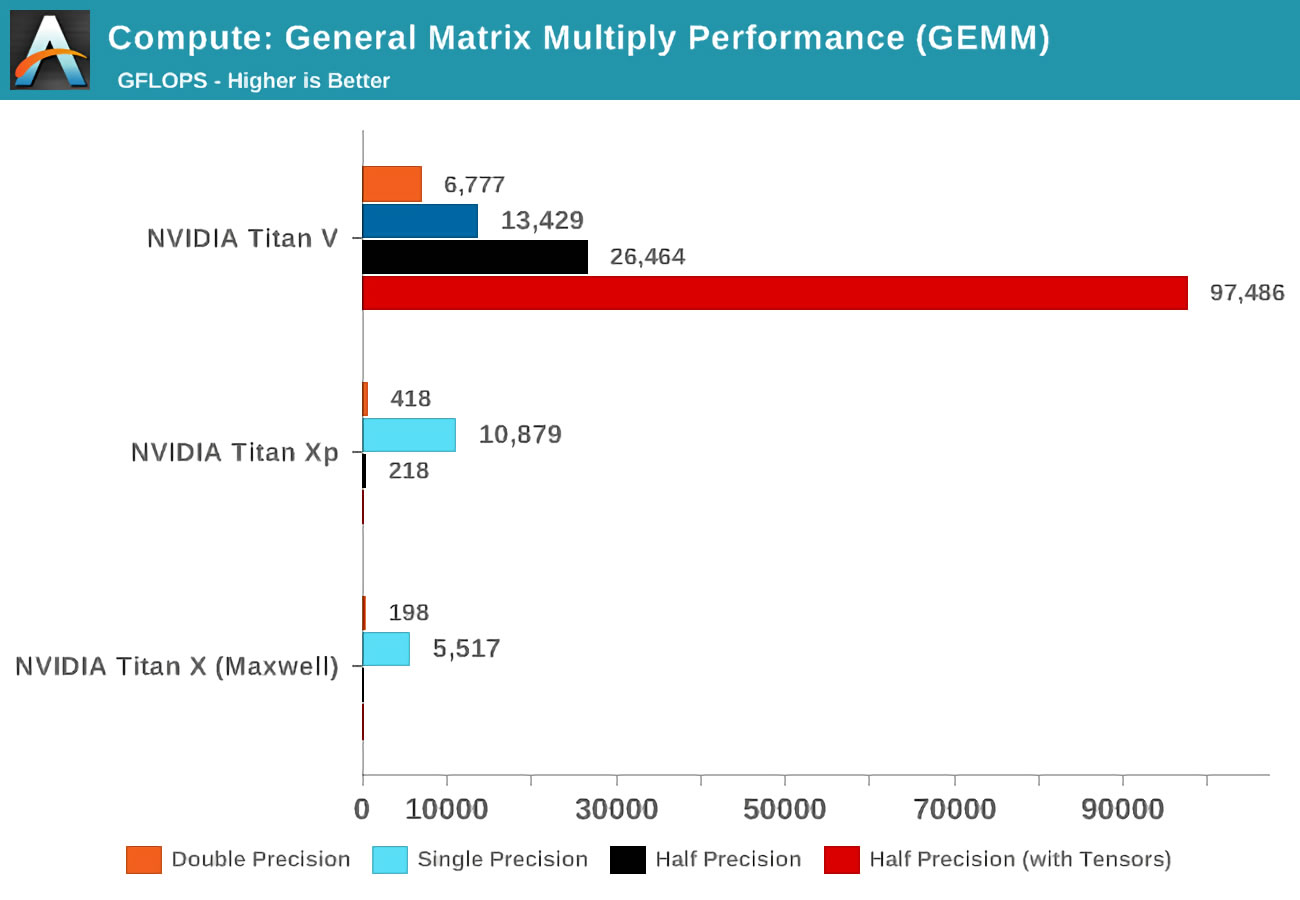
精度(precision) 的概念是指矩阵中用于浮点数的位数:double(double)表示64,single(single)-32,依此类推。水平轴是每秒执行的最大浮点操作数,或简称FLOP(请记住,一个GEMM为3 FLOP)。
只要看一下使用张量内核而不是所谓的CUDA内核的结果!显然,他们在这项工作中非常了不起,但是我们可以用张量内核做什么?
使一切变得更好的数学
张量计算在物理学和工程学中非常有用,它用于解决流体力学,电磁学和天体物理学中的各种复杂问题,但是用于处理此类数字的计算机通常在中央处理单元的大集群中执行矩阵运算。
张量流行的另一个领域是机器学习,尤其是其“深度学习”小节。其含义归结为处理称为神经网络的巨型数组中的巨大数据集。不同数据值之间的连接被分配了一定的权重-一个数字表示特定连接的重要性。
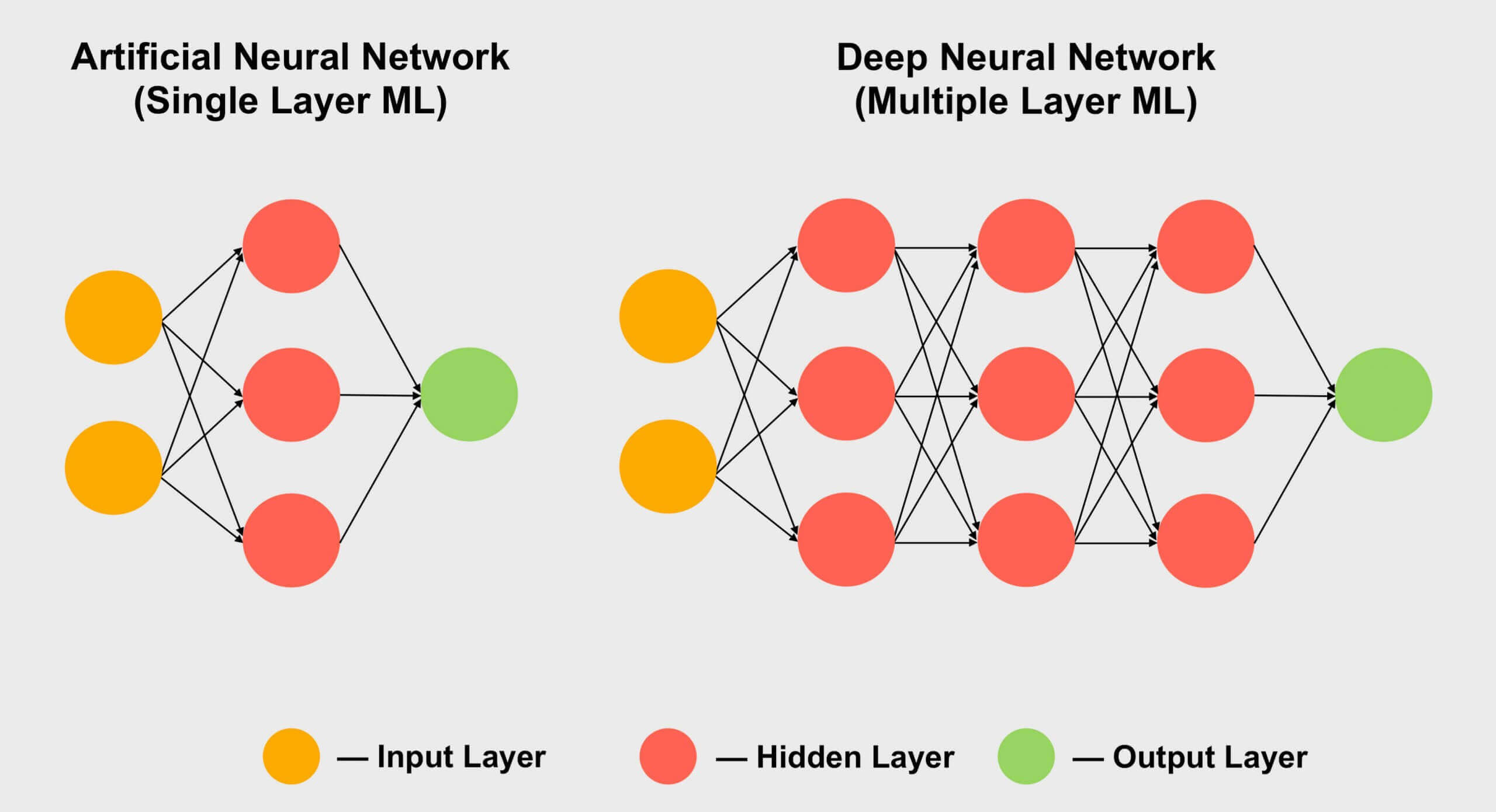
因此,当我们需要弄清这数百个甚至数千个连接如何相互作用时,我们需要将网络中的每个数据乘以所有可能的连接权重。换句话说,将两个矩阵相乘,这就是经典的张量数学!

水冷却系统覆盖的Google TPU 3.0芯片
这就是为什么所有深度学习超级计算机都使用GPU的原因,而且几乎总是Nvidia。但是,有些公司甚至从张量内核开发了自己的处理器。以谷歌为例,该公司于2016年宣布开发其首个TPU(张量处理单元),但这些芯片是如此专业化,以至于除使用矩阵进行运算外,它们都无法做其他任何事情。
消费类GPU(GeForce RTX)中的Tensor内核
但是,如果我购买Nvidia GeForce RTX图形卡,而不是作为天体物理学家解决黎曼流形问题,或者不是尝试卷积神经网络深度的专家……怎么办?我如何使用张量内核?
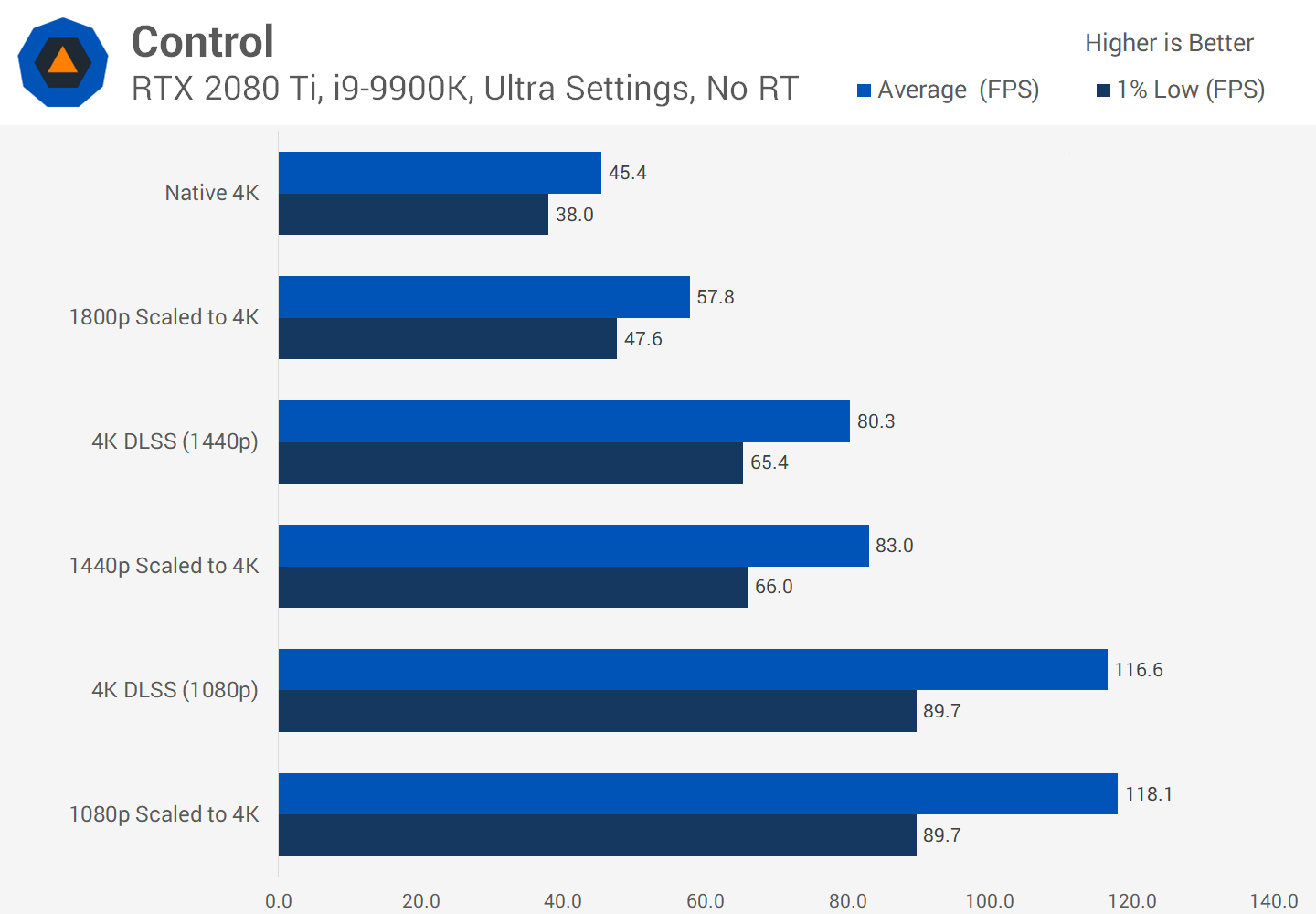
通常,它们不适用于常规视频渲染,编码或解码,因此您似乎在无用的功能上浪费了金钱。然而,Nvidia已经建成张芯到其消费类产品在2018年(图灵的GeForce RTX),同时实施DLSS -深度学习超级采样。

原理很简单:以较低的分辨率渲染帧,完成后,提高最终结果的分辨率,使其与监视器的“原始”屏幕尺寸匹配(例如,以1080p渲染,然后将尺寸调整为1400p)。由于处理了更少的像素,并且屏幕仍然产生漂亮的图像,因此提高了性能。
控制台多年来一直具有此功能,许多现代PC游戏也提供此功能。在育碧的《刺客信条:奥德赛》中,您可以将渲染分辨率降低到显示器分辨率的50%。不幸的是,结果看起来并不那么漂亮。这是具有最大图形设置的4K游戏的外观:

在更高的分辨率下,纹理看起来更漂亮,因为它们保留了更多细节。但是,将这些像素显示在屏幕上需要大量的处理。现在,看看使用渲染器将图像拉伸到4K时,将渲染设置为1080p(先前像素数的25%)时会发生什么。

由于使用jpeg压缩,因此差异可能不会立即注意到,但是您可以看到角色的装甲和远处的岩石看上去模糊。让我们放大图像的一部分以进行仔细查看:

左侧的图像以4K渲染;右边的图像是1080p拉伸到4K。在运动上,差异更加明显,因为所有细节的柔和很快变成了模糊的混乱。由于显卡驱动程序的锐化效果,部分锐度可以得到恢复,但是如果我们根本不需要这样做,那会更好。
这是DLSS发挥作用的地方-在第一个版本中Nvidia这项技术分析了一些精选的游戏;它们在高分辨率和低分辨率下运行,带有或不带有抗锯齿功能。在所有这些模式下,都会生成一组图像,然后将其加载到公司的超级计算机中,该计算机使用神经网络来确定如何最好地将1080p图像转换为理想的高分辨率图像。

我必须说DLSS 1.0并不完美:细节经常丢失,并且某些地方出现了奇怪的闪烁。此外,它本身未使用图形卡的张量核心(在Nvidia网络上运行),并且每个支持DLSS的游戏都需要进行单独的Nvidia研究才能生成放大算法。

2020年初发布2.0版时,对其进行了重大改进。最重要的是,Nvidia的超级计算机现在仅用于创建通用的放大算法-新版的DLSS使用神经模型(GPU张量核)处理来自渲染帧的数据来处理像素。

DLSS 2.0 的功能给我们留下了深刻的印象,但是到目前为止,很少有游戏支持它。在撰写本文时,只有十二个。并且有充分的理由,越来越多的开发人员希望在其未来的游戏中实现它。
规模的任何增加都可以显着提高生产率,因此您可以确信DLSS将继续发展。
尽管DLSS的视觉效果并不总是完美的,但通过释放渲染资源,开发人员可以在更多平台上添加更多视觉效果或提供一层图形。
例如,在“支持RTX的”游戏中,DLSS通常与光线跟踪一起发布。 GeForce RTX卡包含称为RT核的附加计算块,它们是专用的逻辑块,用于加速射线三角相交和边界体积层次(BVH)的遍历。这两个过程是非常耗时的过程,这些过程确定光线与场景中其他对象的交互方式。
我们发现,光线追踪这是一个非常耗时的过程,因此要确保游戏中的帧速率达到可接受的水平,开发人员必须限制场景中执行的光线和反射次数。该过程会产生颗粒状图像,因此必须应用降噪算法,这会增加处理复杂性。预期张量内核将通过使用AI消除噪声来改善此过程的性能,但这尚未实现:大多数现代应用程序仍使用CUDA内核来完成此任务。另一方面,由于DLSS 2.0成为一种非常实用的放大技术,因此可以在场景中跟踪光线后有效使用Tensor Kernels来提高帧速率。
还有其他计划利用GeForce RTX卡的Tensor Core,例如改善角色动画或组织模拟。但是,与DLSS 1.0一样,要在数百款使用GPU上使用专用矩阵计算的游戏之前还需要很长时间。
有希望的开始
因此,情况就是这样-张量内核,出色的硬件单元,但是,仅在某些消费级卡中才可以找到它们。将来会有什么变化吗?由于Nvidia已经在其Ampere架构中显着改善了每个Tensor Core的性能,因此很有可能将它们安装在中低端型号中。
尽管AMD和Intel的GPU中还没有这样的内核,但也许将来我们会看到它们。 AMD拥有一个可以以稍微降低性能为代价来锐化或增强成品框架中细节的系统,因此该公司可能会坚持使用该系统,尤其是由于它不需要开发人员进行集成,因此足以在驱动程序中启用它。
还有一种观点认为,图形芯片中晶体上的空间最好用于其他着色器内核上-这就是Nvidia在创建其Turing芯片的预算版本时所做的。在诸如GeForce GTX 1650之类的产品中,该公司已经完全放弃了张量核心,并用其他FP16着色器替换了它们。
但是现在,如果您想提供超快速的GEMM处理并充分利用它,则有两种选择:购买一堆巨大的多核CPU或仅购买一个带有张量核的GPU。
也可以看看: