 你好居住者!我们已经发布了处理和生成自然语言文本的实用指南。本书配备了创建应用的NLP系统所需的所有工具和技术,以确保虚拟助手(聊天机器人),垃圾邮件过滤器,论坛主持人程序,情感分析器,知识库构建程序,智能自然语言文本分析器或几乎可以想象的任何其他NLP应用程序。
你好居住者!我们已经发布了处理和生成自然语言文本的实用指南。本书配备了创建应用的NLP系统所需的所有工具和技术,以确保虚拟助手(聊天机器人),垃圾邮件过滤器,论坛主持人程序,情感分析器,知识库构建程序,智能自然语言文本分析器或几乎可以想象的任何其他NLP应用程序。
这本书是针对中级到高级Python开发人员的。本书的很大一部分对已经知道如何设计和开发复杂系统的读者很有用,因为它包含许多推荐的解决方案示例,并揭示了最现代的NLP算法的功能。尽管使用Python进行的面向对象编程知识可以帮助您构建更好的系统,但是并不需要使用本书中的信息。
你会在书中找到什么
I . , . , , , , , . -, , 2–4, . , 90%- 1990- — .
, . , , , ( ). , - , . , .
. II . «» , : , , .
, , . , , . « » , , .
III, , , .
, . , , , ( ). , - , . , .
. II . «» , : , , .
, , . , , . « » , , .
III, , , .
反馈神经网络:递归神经网络
第7章演示了使用卷积神经网络分析片段或整个句子,通过在它们上应用共享权重过滤器(执行卷积)来跟踪句子中相邻单词的可能性。成群出现的单词也可以在捆绑中找到。该网也抵抗这些单词的位置的小偏移。同时,相邻的概念会严重影响网络。但是,如果您需要从宏观角度看待正在发生的事情,请考虑较长时间的关系,一个涵盖了供应中3-4个以上代币的窗口?如何将过去事件的概念引入网络?记忆?
对于前馈神经网络的每个训练示例(或无序示例批次)和输出(或输出批次),需要基于反向传播方法为单个神经元调整神经网络权重。我们已经证明了这一点。但是,下一个示例的训练阶段的结果大部分与输入数据的顺序无关。卷积神经网络试图通过捕获局部关系来捕获这些顺序关系,但是还有另一种方式。
在卷积神经网络中,每个训练示例作为一组单词标记传递到网络。如图2所示,单词向量以(单词向量的长度×示例中的单词数)的形式被分组为矩阵。 8.1。

但是,可以从第5章(图8.2)将单词向量的序列轻松地传递到正常的前馈神经网络,对吗?
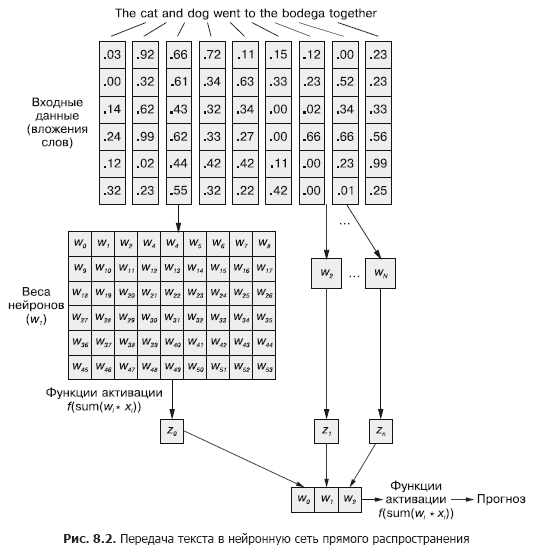
当然,这是一个完美可行的模型。通过这种传输输入数据的方法,前馈神经网络将能够响应令牌的联合出现,这正是我们所需要的。但是同时,它将以相同的方式对所有联合事件做出反应,而不管它们之间是否被长文本分隔开或彼此相邻。另外,前馈神经网络(如CNN)在处理变长文档方面很差。如果超出网络宽度,他们将无法处理文档末尾的文本。
前馈神经网络在对整个数据样本及其对应标签的关系进行建模时表现最佳。句子开头和结尾的单词对输出信号的影响与中间单词相同,尽管事实是它们不太可能在语义上相互关联。
在例如苛刻的否定标记和修饰语(形容词和副词)(例如“否”或“好”)的情况下,这种均匀性(影响的均匀性)显然会引起问题。在前馈神经网络中,否定词会影响句子中所有单词的含义,即使它们与实际应影响的位置相距甚远。
一维卷积是一种通过跨窗口解析多个单词来解决令牌之间的这些关系的方法。在第7章中讨论的下采样层是专门为适应单词顺序的细微变化而设计的。在本章中,我们将探讨一种不同的方法,该方法将帮助我们朝着神经网络内存的概念迈出第一步。与其将一门语言分解为大量的数据,我们将着眼于随着时间的推移逐个标记地研究其顺序结构。
8.1。神经网络记忆
当然,句子中的单词很少彼此完全独立。它们的出现受到文档中其他词的出现的影响或影响。例如:被盗的汽车驶入竞技场,而小丑车驶入竞技场。
读到结尾时,您对这两个句子可能会有完全不同的印象。它们中短语的构造是相同的:形容词,名词,动词和介词短语。但是从读者的角度来看,替换其中的形容词会从根本上改变正在发生的事情的本质。
如何建立这种关系的模型?如果句子中的形容词不是它们的直接定义,那么如何理解竞技场甚至sped的含义可能会略有不同?
如果有一种方法可以记住之前发生的事情(特别是要记住在步骤t + 1的步骤t发生的事情),则可以识别出某些令牌出现在与其他令牌相关的一系列模式中时出现的模式。递归神经网络(RNN)使神经网络可以记住序列的过去单词。
如您在图中所见。在图8.3中,与隐藏层分离的一个递归神经元向网络添加了一个递归循环,以在时间t“重用”隐藏层的输出。将时间t的输出添加到时间t +1的下一个输入。网络在时间步t +1处理此新输入,以在时间t +1生成隐藏层输出。此输出在时间t +1然后它会被网络重用,并在时间步长t + 2等中包含在输入信号中
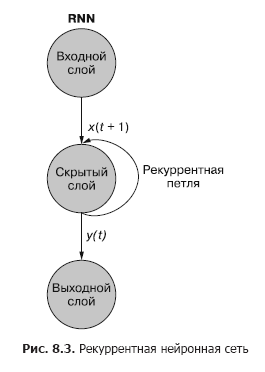
虽然通过时间影响状态的想法有些混乱,但基本概念很简单。在时间步长t的常规前馈神经网络输入处的每个信号的结果,与在时间步长t + 1馈入网络输入的下一个数据一起,用作附加输入信号。网络不仅接收有关当前情况的信息,而且还接收之前发生的情况的信息。 ...
. , . , . , . , . , , . . , .
t . , t = 0 — , t + 1 — . () . , . — .
t, — t + 1.
递归神经网络可以如图所示。 8.3:圆圈对应于前馈神经网络的整个层,由一个或多个神经元组成。网络通常提供隐藏层的输出,但随后将其作为自己的(隐藏层)输入以及正常的下一时间步长输入进行反馈。该图将该反馈回路描述为从层的输出引回到输入的弧。
说明此过程的一种更简单(也是更常用)的方法是使用网络部署。图8.4显示了一个上下颠倒的网络,其中两次扫描了时间变量(t)-步骤t +1和t + 2的层。
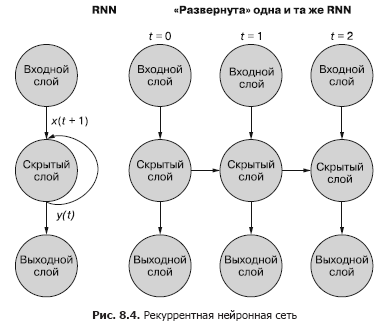
每个时间步长对应于一列神经元形式的同一神经网络的扩展版本。就像在任何给定时间观看脚本或神经网络的各个视频帧一样。右边的网表示左边网的未来版本。在时间(t),隐藏层的输出信号与右侧下一个时间步长(t + 1)的输入数据一起反馈到隐藏层的输入。再来一次。该图显示了此部署的两次迭代,即t = 0,t = 1和t = 2的三列神经元。
此图中的所有垂直路径都是完全相似的,它们显示相同的神经元。它们在不同的时间点反映相同的神经网络。该视觉表示对于在错误的反向传播过程中演示信息在网络上的向前和向后移动很有用。但是请记住,当查看这三个部署的网络时:它们是具有相同权重集的同一网络的不同快照。
在部署循环神经网络之前,让我们仔细研究一下循环神经网络的原始表示,并显示输入信号和权重之间的关系。该RNN的各个层如图1所示。 8.5和8.6。

如在常规前馈网络中一样,所有潜伏状态神经元具有一组权重应用于每个输入向量的每个元素。但是在此方案中,出现了另一组可训练的权重,这些权重被应用于上一时间步长中隐藏神经元的输出信号。通过训练,网络在逐个令牌输入序列令牌时会选择先前事件的适当权重(重要性)。
«», t = 0 t – 1. «» , , . t = 0 . , .
回到数据上,假设您有一组文档,每个文档都是带有标签的示例。并没有像上一章(图8.7)那样,将每个单词的整个词向量集传递给卷积神经网络(图8.7),而是将示例数据一次传递给RNN(图8.8)。

我们为第一个标记传递单词向量,并获得递归神经网络的输出。然后,我们传输第二个令牌,并与之一起传输第一个令牌的输出信号!之后,我们将传输第三个令牌以及来自第二个令牌的输出信号!等等。现在,在我们的神经网络中,有因果关系的“之前”和“之后”概念,尽管有些含糊,但还是有时间概念(见图8.8)。
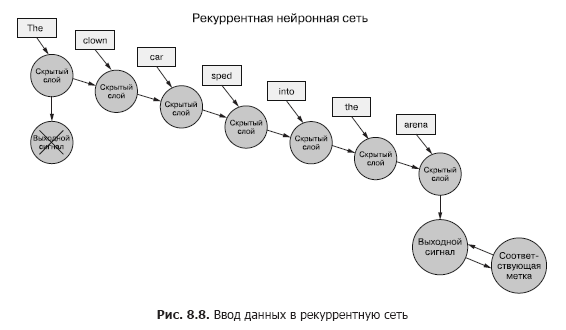
现在我们的网络已经在记住一些东西!好吧,在一定程度上。还有一些事情需要解决。首先,在这种结构中如何发生错误的反向传播?
8.1.1。时间错误的反向传播
在上面讨论的所有网络中,都有一个目标标签(目标变量),RNN也不例外。但是我们没有为每个标记标记的概念,并且每个示例文本的所有标记只有一个标记。我们只有样本文件的标签。
我们正在谈论将令牌作为每个时间步长输入到网络,但递归神经网络也可以处理任何时间序列数据。令牌可以是任何离散的或连续的:气象站读数,注释,句子中的符号等。
在这里,我们首先将最后一步的网络输出与提示进行比较。这就是我们现在(现在)所说的错误,即我们的网络正在尝试将其最小化。但是与前几章略有不同。给定的数据样本被分成较小的部分,这些部分按顺序馈入神经网络。但是,我们没有直接将输出用于这些子示例,而是将其发送回网络。
到目前为止,我们仅对最终输出信号感兴趣。序列中的每个令牌都馈入网络,并根据最后一个时间步(令牌)的输出计算损失(图8.9)。
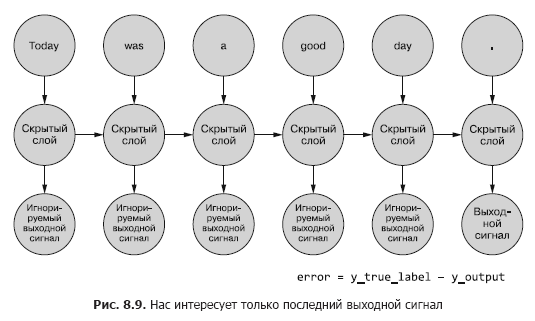
对于给定的示例,有必要确定是否存在错误,要更新的权重以及确定的权重。在第5章中,我们向您展示了如何通过普通网络反向传播错误。而且我们知道权重校正的数量取决于其(此权重)对误差的贡献。我们可以将令牌从样本序列馈送到网络的输入,根据其输出信号计算上一个时间步的误差。这就是在时间上反向传播错误的想法似乎使一切困惑的地方。
但是,人们可以简单地将其视为一个有时限的过程。在每个时间步长上,从t = 0处的第一个开始,将令牌一次馈入位于前面的隐藏神经元的输入-图2中的下一列。 8.9。同时,网络将扩展,显示网络的下一列,该列已准备好接收序列中的下一个令牌。潜在的神经元一次展开,例如音乐盒或机械钢琴。最后,将示例的所有元素馈入网络后,将不再需要部署任何内容,我们将获得我们感兴趣的目标变量的最终标签,该标签可用于计算误差和调整权重。对于此展开的网络,我们一直走到计算图的最下方。
目前,我们认为输入数据通常是静态的。您可以遍历整个图形,哪个输入信号输入哪个神经元。并且由于我们知道哪种神经元是如何工作的,因此可以像常规前馈神经网络一样,沿着相同的路径沿着链传播错误。
为了将错误传播回上一层,我们将使用链式规则。代替上一层,我们将错误传播到过去的同一层,好像所有部署的网络变体都不同(图8.10)。这不会改变计算数学。

错误从最后一步传播回来。计算相对于较新时间步长的较早时间步长的梯度。在此示例中,计算完所有独立的基于令牌的梯度,直到步骤t = 0,然后将这些变化汇总并应用于一组权重。
8.1.2。何时更新
我们已经将奇怪的RNN变成了类似于常规前馈神经网络的东西,因此更新权重应该不会太困难。但是,有一个警告。诀窍是权重根本不会在神经网络的另一个分支中更新。每个分支在不同的时间点代表相同的网络。每个时间步的权重都相同(见图8.10)。
解决此问题的一种简单方法是计算每个时间步长的权重校正,但会延迟更新。在前馈网络中,权重的所有更新都是在计算特定输入信号的所有梯度之后立即计算的。此处完全相同,但是更新被推迟到特定输入样本数据的初始(零)时间步长为止。
梯度的计算应基于它们对误差做出贡献的权重值。这是最压倒性的部分:时间步长t的权重在某种程度上造成了错误。并且相同的权重在时间步t + 1处获得另一个输入信号,这意味着它对误差的贡献不同。
您可以计算每个时间步长的权重的各种变化,将其汇总,然后将分组的变化应用于隐藏层的权重,作为训练阶段的最后一步。
, . , , . , , . , .
真正的魔术。在时间上向后传播误差的情况下,可以在一个时间步长t上根据一个方向(根据其在时间步长t对输入信号的响应)校正单个权重,然后在时间步长t-1上在另一个方向进行校正(根据他如何在时间步t-1)对一个采样数据的输入信号做出反应!请记住,神经网络通常基于最小化损失函数,而不管中间步骤的复杂性如何。网络共同优化了这一复杂功能。由于权重更新仅对样本数据应用一次,因此对于特定的输入信号和特定的神经元,网络(当然,如果完全收敛)最终将在最佳权重下停止。
前面步骤的结果仍然很重要
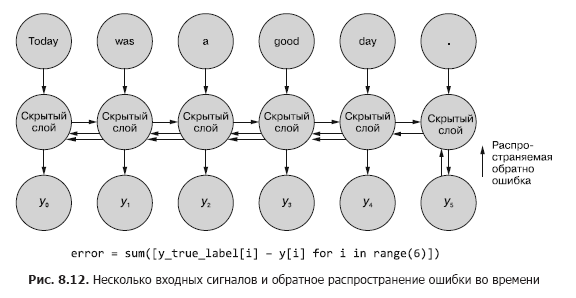
有时在所有中间时间步长生成的值的整个序列很重要。在第9章中,我们将举例说明特定时间步长t的输出与最后一个时间步长的输出一样重要的情况。在图。 8.11展示了一种用于收集任何时间步长的错误数据并将其传播回以校正网络所有权重的方法。

此过程类似于n个时间步长的时间错误的通常反向传播。在这种情况下,我们会同时从多个来源传播错误。但是,与第一个示例一样,权重调整是累加的。该误差从开始时的最后一个时间步长到第一个时间步长(每个权重的变化之和)传播。然后,在倒数第二个时间步长处计算出的误差会发生相同的情况,将所有变化加总到t =0。重复此过程,直到达到零时间步长且误差向后传播,就好像它是唯一的一样。然后,将累积更改立即全部应用到相应的隐藏层。
在图。图8.12显示了误差如何从每个输出信号传播回t = 0,然后在最终校正权重之前进行汇总。这是本节的主要思想。与常规前馈神经网络一样,仅在针对给定输入信号(或一组输入信号)计算整个反向传播步骤的权重变化后,才更新权重。对于RNN,错误传播包括直到时间t = 0的更新。
较早地更新权重会使梯度计算失真,并在较早的时间点传播反向误差。请记住,梯度是相对于特定权重计算的。如果此权重更新得太早,例如在时间步t处更新,则在时间步t-1处计算梯度时,权重值(请注意,这是网络中权重的相同位置)将改变。并且,当根据时间步t-1的输入信号计算梯度时,计算将失真。实际上,在这种情况下,将对“不应该怪”的东西处以罚款(或奖励)!
关于作者
霍布森巷(Hobson Lane)拥有20年的构建自主系统的经验,这些系统可以为人们的利益做出重要决策。在Talentpair,Hobson教授机器以比大多数招聘经理更少的偏见方式阅读和理解简历。在Aira,他帮助建立了他们的第一个聊天机器人,旨在为盲人解释世界。霍布森(Hobson)对AI的开放性和社区主导型的定位充满热情。他为开源项目(例如Keras,scikit-learn,PyBrain,PUGNLP和ChatterBot)做出了积极的贡献。他目前参与Total Total的开放式研究和教育项目,包括创建一个开源虚拟助手。他发表了许多文章,并在AIAA,PyCon,PAIS和IEEE并获得了机器人技术和自动化领域的多项专利。
Hannes Max Hapke是一名电气工程师,是一名机器学习工程师。在高中时,当他研究微控制器上计算神经网络的方法时,他对神经网络产生了兴趣。在大学后期,他将神经网络原理应用于可再生能源发电厂的高效管理。 Hannes对自动化软件开发和机器学习管道充满热情。他与人合着了针对招聘,能源和医疗保健行业的深度学习模型和机器学习管道。 Hannes在包括OSCON,Open Source Bridge和Hack University在内的各种会议上发表了有关机器学习的演讲。
科尔·霍华德(Cole Howard)是一位机器学习从业者,NLP从业者和作家。作为模式的永恒追求者,他发现自己在人工神经网络领域。他的发展包括用于Internet交易的大型推荐系统和用于超高维机器智能系统(深度神经网络)的高级神经网络,它们在Kaggle比赛中排名第一。他在Open Source Bridge和Hack University会议上就卷积神经网络,递归神经网络及其在自然语言处理中的作用进行了演讲。
关于封面插图
« -, ». (Balthasar Hacquet) Images and Descriptions of Southwestern and Eastern Wends, Illyrians and Slavs (« - , »), () 2008 . (1739–1815) — , , — , - . .
200 . , , . , . , .
200 . , , . , . , .
»有关这本书的更多详细信息,请访问出版商的网站
»目录
»摘录
给居住者优惠券25%的折扣-NLP
在为该书的纸质版本付款后,会向该电子邮件发送一本电子书。