介绍
本文介绍了一种稳定的非递归自适应合并排序算法,称为Quadsort。
四重交换
Quadsort基于四重交换。传统上,大多数排序算法都是基于二进制交换,其中使用第三个临时变量对两个变量进行排序。通常看起来像这样:
if (val[0] > val[1])
{
tmp[0] = val[0];
val[0] = val[1];
val[1] = tmp[0];
}在四重交换中,使用四个替换变量(交换)进行排序。第一步,将四个变量部分地分类为四个交换变量,第二步,将它们完全重新分类为四个原始变量。
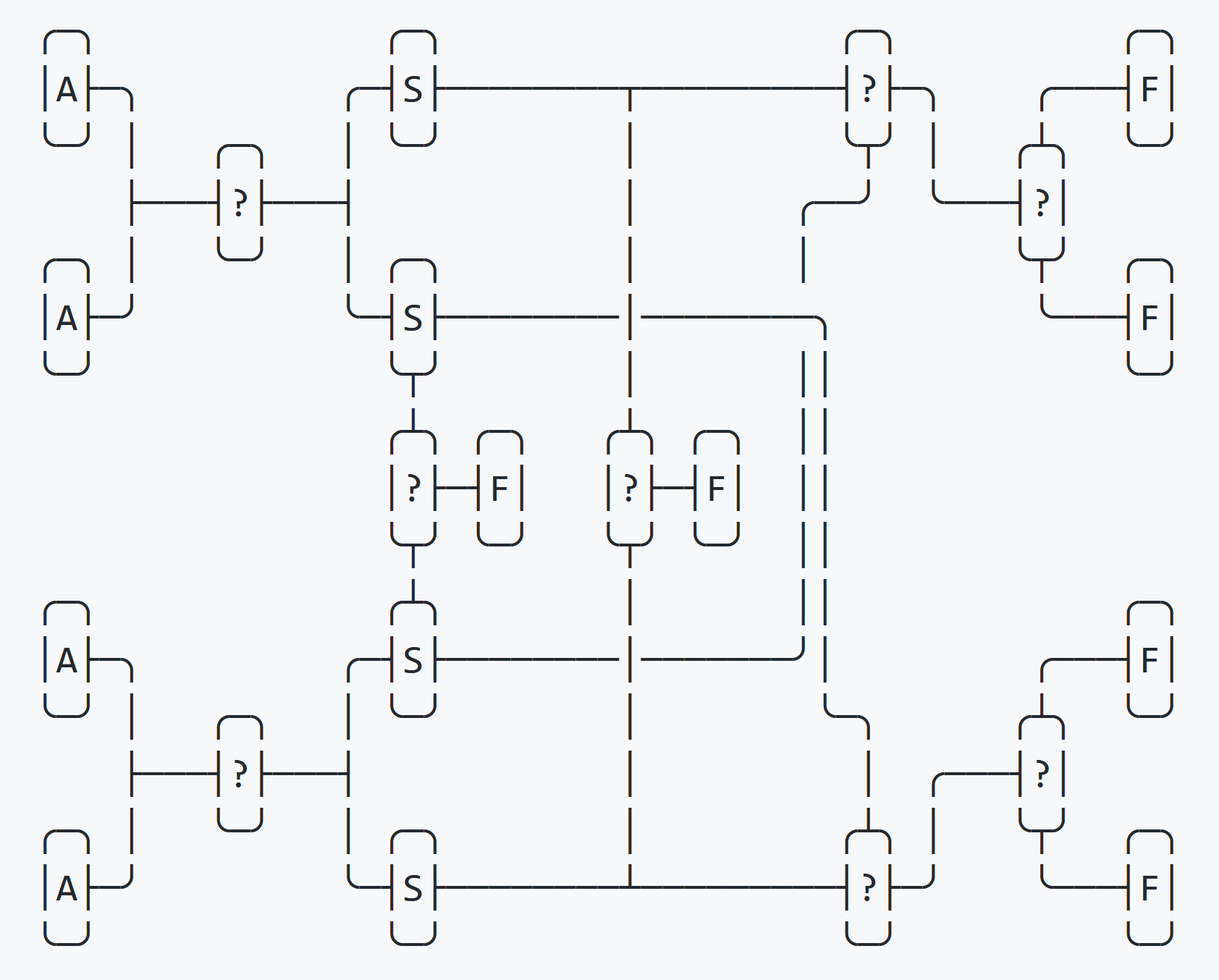
上图显示了此过程。
在第一轮排序之后,一个if检查确定四个交换变量是否按顺序排序。如果是这样,则交换立即结束。然后,它检查交换变量是否按相反顺序排序。如果是这样,则排序立即结束。如果两个测试均失败,则最终位置是已知的,剩下两个测试以确定最终顺序。
这消除了对顺序有一个冗余的比较。同时,为随机序列创建了另一个比较。但是,在现实世界中,我们很少比较真正的随机数据。因此,当数据有序而不是混乱时,这种概率转移是有益的。
通过消除浪费的交换,整体性能也得到了改善。在C语言中,基本的四重交换如下所示:
if (val[0] > val[1])
{
tmp[0] = val[1];
tmp[1] = val[0];
}
else
{
tmp[0] = val[0];
tmp[1] = val[1];
}
if (val[2] > val[3])
{
tmp[2] = val[3];
tmp[3] = val[2];
}
else
{
tmp[2] = val[2];
tmp[3] = val[3];
}
if (tmp[1] <= tmp[2])
{
val[0] = tmp[0];
val[1] = tmp[1];
val[2] = tmp[2];
val[3] = tmp[3];
}
else if (tmp[0] > tmp[3])
{
val[0] = tmp[2];
val[1] = tmp[3];
val[2] = tmp[0];
val[3] = tmp[1];
}
else
{
if (tmp[0] <= tmp[2])
{
val[0] = tmp[0];
val[1] = tmp[2];
}
else
{
val[0] = tmp[2];
val[1] = tmp[0];
}
if (tmp[1] <= tmp[3])
{
val[2] = tmp[1];
val[3] = tmp[3];
}
else
{
val[2] = tmp[3];
val[3] = tmp[1];
}
}如果无法将数组完美地分为四个部分,则使用传统的二进制交换对1-3个元素的尾部进行排序。
上述的四重交换以四重实施。
四重合并
在第一阶段,如上所述,四元交换将数组预排序为四个元素的块。
第二阶段使用类似的方法来检测有序和逆序,但是在4、16、64或更多元素的块中,该阶段的处理方式类似于传统的合并排序。
可以表示如下:
main memory: AAAA BBBB CCCC DDDD
swap memory: ABABABAB CDCDCDCD
main memory: ABCDABCDABCDABCD第一行使用四重交换来创建四个块,每个块包含四个排序的元素。第二行使用四边形合并将两个八个重排项目的块合并到交换内存中。在最后一行中,这些块被合并回主存储器,然后剩下一个由16个排序元素组成的块。下面是可视化。

这些操作实际上需要将交换内存加倍。稍后再详细介绍。
跳跃
另一个区别是,由于合并操作的成本增加,因此检查四个块是正向还是反向是有益的。
如果四个块按顺序排列,则合并操作将被跳过,因为这没有意义。但是,这需要附加的if检查,对于随机排序的数据,随着块大小的增加,这种if检查变得越来越不可能。幸运的是,这种检查的频率在每个周期增加了四倍,而潜在收益在每个周期增加了三倍。
如果四个块的顺序相反,则执行稳定的就地交换。
如果四个块中只有两个是有序的或者是相反的,则合并本身的比较是不必要的,随后将被省略。数据仍然需要复制到交换内存,但这是一个较少的计算过程。
这使四分算法可以使用
n比较而不是n * log n比较按向前和向后的顺序对序列进行排序。
边界检查
传统合并排序的另一个问题是浪费资源进行不必要的边界检查。看起来像这样:
while (a <= a_max && b <= b_max)
if (a <= b)
[insert a++]
else
[insert b++]为了进行优化,我们的算法将序列A的最后一个元素与序列B的最后一个元素进行比较。如果序列A的最后一个元素小于序列B的最后一个元素,那么我们知道测试
b < b_max将始终为假,因为序列A是第一个完全合并的对象。
同样,如果序列A的最后一个元素大于序列B的最后一个元素,我们知道测试
a < a_max将始终为假。看起来像这样:
if (val[a_max] <= val[b_max])
while (a <= a_max)
{
while (a > b)
[insert b++]
[insert a++]
}
else
while (b <= b_max)
{
while (a <= b)
[insert a++]
[insert b++]
}融合尾巴
对65个元素的数组进行排序时,最终会得到64个元素的排序数组和最后一个一个元素的排序数组。如果整个顺序正确,则不会导致额外的交换(交换)操作。无论如何,为此,程序必须选择最佳阵列大小(64、256或1024)。
另一个问题是数组的非最佳大小会导致不必要的交换操作。要解决这两个问题,当块大小达到数组大小的1/8时,将终止四重合并过程,并使用尾部合并对其余数组进行排序。尾部融合的主要优势在于,它可以将四元组交换量减少到n / 2,而不会显着影响性能。
大O
| 名称 | 最好 | 中间 | 最差 | 稳定 | 记忆 |
|---|---|---|---|---|---|
| 四元组 | ñ | n日志n | n日志n | 是 | ñ |
当数据已经排序或反向排序时,quadsort进行n次比较。
快取
由于quadsort使用n / 2交换,因此缓存使用情况不如就地排序理想。但是,对随机数据进行分类会导致次优交换。根据我的基准,quadsort总是比就地排序更快,只要该阵列不会溢出L1缓存即可,该缓存在现代处理器上可能高达64KB。
沃尔夫排序
Wolfsort是一种radixsort / quadsort混合排序算法,可在处理随机数据时提高性能。这基本上是一个概念证明,仅适用于无符号的32位和64位整数。
可视化
下面的可视化文件运行四个测试。第一次测试基于随机分布,第二次基于上升分布,第三次基于下降分布,第四次基于具有随机尾部的上升分布。
上半部分显示交换,下半部分显示主内存。跳过,交换,合并和复制操作的颜色各不相同。
基准:quadsort,std :: stable_sort,timsort,pdqsort和wolfsort
以下基准测试是在WSL gcc配置版本7.4.0(Ubuntu 7.4.0-1ubuntu1〜18.04.1)上运行的。源代码由团队编译
g++ -O3 quadsort.cpp。每个测试运行一百次,并且仅报告最佳运行。
横坐标是执行时间。
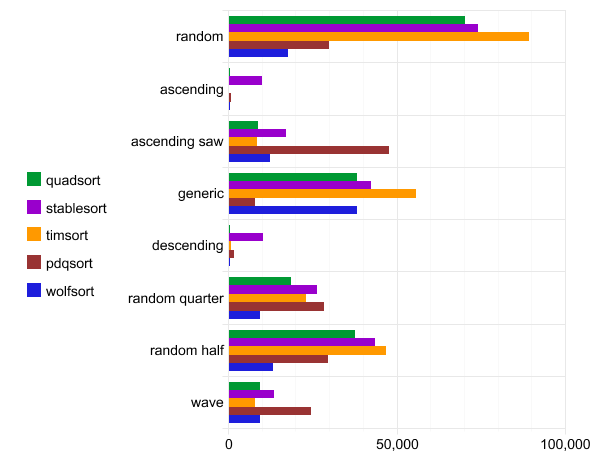
Quadsort数据表,STD :: :: stable_sort,timsort,pdqsort和Wolfsort
| quadsort | 1000000 | i32 | 0.070469 | 0.070635 | ||
| stablesort | 1000000 | i32 | 0.073865 | 0.074078 | ||
| timsort | 1000000 | i32 | 0.089192 | 0.089301 | ||
| pdqsort | 1000000 | i32 | 0.029911 | 0.029948 | ||
| wolfsort | 1000000 | i32 | 0.017359 | 0.017744 | ||
| quadsort | 1000000 | i32 | 0.000485 | 0.000511 | ||
| stablesort | 1000000 | i32 | 0.010188 | 0.010261 | ||
| timsort | 1000000 | i32 | 0.000331 | 0.000342 | ||
| pdqsort | 1000000 | i32 | 0.000863 | 0.000875 | ||
| wolfsort | 1000000 | i32 | 0.000539 | 0.000579 | ||
| quadsort | 1000000 | i32 | 0.008901 | 0.008934 | () | |
| stablesort | 1000000 | i32 | 0.017093 | 0.017275 | () | |
| timsort | 1000000 | i32 | 0.008615 | 0.008674 | () | |
| pdqsort | 1000000 | i32 | 0.047785 | 0.047921 | () | |
| wolfsort | 1000000 | i32 | 0.012490 | 0.012554 | () | |
| quadsort | 1000000 | i32 | 0.038260 | 0.038343 | ||
| stablesort | 1000000 | i32 | 0.042292 | 0.042388 | ||
| timsort | 1000000 | i32 | 0.055855 | 0.055967 | ||
| pdqsort | 1000000 | i32 | 0.008093 | 0.008168 | ||
| wolfsort | 1000000 | i32 | 0.038320 | 0.038417 | ||
| quadsort | 1000000 | i32 | 0.000559 | 0.000576 | ||
| stablesort | 1000000 | i32 | 0.010343 | 0.010438 | ||
| timsort | 1000000 | i32 | 0.000891 | 0.000900 | ||
| pdqsort | 1000000 | i32 | 0.001882 | 0.001897 | ||
| wolfsort | 1000000 | i32 | 0.000604 | 0.000625 | ||
| quadsort | 1000000 | i32 | 0.006174 | 0.006245 | ||
| stablesort | 1000000 | i32 | 0.014679 | 0.014767 | ||
| timsort | 1000000 | i32 | 0.006419 | 0.006468 | ||
| pdqsort | 1000000 | i32 | 0.016603 | 0.016629 | ||
| wolfsort | 1000000 | i32 | 0.006264 | 0.006329 | ||
| quadsort | 1000000 | i32 | 0.018675 | 0.018729 | ||
| stablesort | 1000000 | i32 | 0.026384 | 0.026508 | ||
| timsort | 1000000 | i32 | 0.023226 | 0.023395 | ||
| pdqsort | 1000000 | i32 | 0.028599 | 0.028674 | ||
| wolfsort | 1000000 | i32 | 0.009517 | 0.009631 | ||
| quadsort | 1000000 | i32 | 0.037593 | 0.037679 | ||
| stablesort | 1000000 | i32 | 0.043755 | 0.043899 | ||
| timsort | 1000000 | i32 | 0.047008 | 0.047112 | ||
| pdqsort | 1000000 | i32 | 0.029800 | 0.029847 | ||
| wolfsort | 1000000 | i32 | 0.013238 | 0.013355 | ||
| quadsort | 1000000 | i32 | 0.009605 | 0.009673 | ||
| stablesort | 1000000 | i32 | 0.013667 | 0.013785 | ||
| timsort | 1000000 | i32 | 0.007994 | 0.008138 | ||
| pdqsort | 1000000 | i32 | 0.024683 | 0.024727 | ||
| wolfsort | 1000000 | i32 | 0.009642 | 0.009709 |
应当注意,pdqsort不是稳定的排序,因此它以正常顺序(一般顺序)处理数据时速度更快。
以下基准测试是在WSL gcc版本7.4.0(Ubuntu 7.4.0-1ubuntu1〜18.04.1)上运行的。源代码由团队进行编译
g++ -O3 quadsort.cpp。每个测试运行一百次,并且仅报告最佳运行。它可以测量从675到100,000个元素的阵列的性能。
下图的X轴是基数,Y轴是执行时间。

Quadsort数据表,STD :: :: stable_sort,timsort,pdqsort和Wolfsort
| quadsort | 100000 | i32 | 0.005800 | 0.005835 | ||
| stablesort | 100000 | i32 | 0.006092 | 0.006122 | ||
| timsort | 100000 | i32 | 0.007605 | 0.007656 | ||
| pdqsort | 100000 | i32 | 0.002648 | 0.002670 | ||
| wolfsort | 100000 | i32 | 0.001148 | 0.001168 | ||
| quadsort | 10000 | i32 | 0.004568 | 0.004593 | ||
| stablesort | 10000 | i32 | 0.004813 | 0.004923 | ||
| timsort | 10000 | i32 | 0.006326 | 0.006376 | ||
| pdqsort | 10000 | i32 | 0.002345 | 0.002373 | ||
| wolfsort | 10000 | i32 | 0.001256 | 0.001274 | ||
| quadsort | 5000 | i32 | 0.004076 | 0.004086 | ||
| stablesort | 5000 | i32 | 0.004394 | 0.004420 | ||
| timsort | 5000 | i32 | 0.005901 | 0.005938 | ||
| pdqsort | 5000 | i32 | 0.002093 | 0.002107 | ||
| wolfsort | 5000 | i32 | 0.000968 | 0.001086 | ||
| quadsort | 2500 | i32 | 0.003196 | 0.003303 | ||
| stablesort | 2500 | i32 | 0.003801 | 0.003942 | ||
| timsort | 2500 | i32 | 0.005296 | 0.005322 | ||
| pdqsort | 2500 | i32 | 0.001606 | 0.001661 | ||
| wolfsort | 2500 | i32 | 0.000509 | 0.000520 | ||
| quadsort | 1250 | i32 | 0.001767 | 0.001823 | ||
| stablesort | 1250 | i32 | 0.002812 | 0.002887 | ||
| timsort | 1250 | i32 | 0.003789 | 0.003865 | ||
| pdqsort | 1250 | i32 | 0.001036 | 0.001325 | ||
| wolfsort | 1250 | i32 | 0.000534 | 0.000655 | ||
| quadsort | 675 | i32 | 0.000368 | 0.000592 | ||
| stablesort | 675 | i32 | 0.000974 | 0.001160 | ||
| timsort | 675 | i32 | 0.000896 | 0.000948 | ||
| pdqsort | 675 | i32 | 0.000489 | 0.000531 | ||
| wolfsort | 675 | i32 | 0.000283 | 0.000308 |
基准:quadsort和qsort(mergesort)
以下基准测试是在WSL gcc版本7.4.0(Ubuntu 7.4.0-1ubuntu1〜18.04.1)上运行的。源代码由团队编译
g++ -O3 quadsort.cpp。每个测试运行一百次,并且仅报告最佳运行。
quadsort: sorted 1000000 i32s in 0.119437 seconds. MO: 19308657 ( )
qsort: sorted 1000000 i32s in 0.133077 seconds. MO: 21083741 ( )
quadsort: sorted 1000000 i32s in 0.002071 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.007265 seconds. MO: 3000004 ()
quadsort: sorted 1000000 i32s in 0.019239 seconds. MO: 4007580 ( )
qsort: sorted 1000000 i32s in 0.071322 seconds. MO: 20665677 ( )
quadsort: sorted 1000000 i32s in 0.076605 seconds. MO: 19242642 ( )
qsort: sorted 1000000 i32s in 0.038389 seconds. MO: 6221917 ( )
quadsort: sorted 1000000 i32s in 0.002305 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.009659 seconds. MO: 4000015 ()
quadsort: sorted 1000000 i32s in 0.022940 seconds. MO: 9519209 ( )
qsort: sorted 1000000 i32s in 0.042135 seconds. MO: 13152042 ( )
quadsort: sorted 1000000 i32s in 0.034456 seconds. MO: 6787656 ( )
qsort: sorted 1000000 i32s in 0.098691 seconds. MO: 20584424 ( )
quadsort: sorted 1000000 i32s in 0.066240 seconds. MO: 11383441 ( )
qsort: sorted 1000000 i32s in 0.118086 seconds. MO: 20572142 ( )
quadsort: sorted 1000000 i32s in 0.038116 seconds. MO: 15328606 ( )
qsort: sorted 1000000 i32s in 4.471858 seconds. MO: 1974047339 ( )
quadsort: sorted 1000000 i32s in 0.060989 seconds. MO: 15328606 ()
qsort: sorted 1000000 i32s in 0.043175 seconds. MO: 10333679 ()
quadsort: sorted 1023 i32s in 0.016126 seconds. (random 1-1023)
qsort: sorted 1023 i32s in 0.033132 seconds. (random 1-1023)MO表示对一百万个项目执行的比较次数。
上面的基准测试通过相同的通用接口将quadsort与glibc qsort()进行了比较,并且没有任何已知的不公平优势,例如内联。
random order: 635, 202, 47, 229, etc
ascending order: 1, 2, 3, 4, etc
uniform order: 1, 1, 1, 1, etc
descending order: 999, 998, 997, 996, etc
wave order: 100, 1, 102, 2, 103, 3, etc
stable/unstable: 100, 1, 102, 1, 103, 1, etc
random range: time to sort 1000 arrays ranging from size 0 to 999 containing random data基准:quadsort和qsort(快速排序)
此特定测试使用Cygwin的qsort()实现完成,该实现在后台使用quicksort。源代码由团队进行编译
gcc -O3 quadsort.c。每次测试执行一百次,仅报告最佳运行。
quadsort: sorted 1000000 i32s in 0.119437 seconds. MO: 19308657 ( )
qsort: sorted 1000000 i32s in 0.133077 seconds. MO: 21083741 ( )
quadsort: sorted 1000000 i32s in 0.002071 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.007265 seconds. MO: 3000004 ()
quadsort: sorted 1000000 i32s in 0.019239 seconds. MO: 4007580 ( )
qsort: sorted 1000000 i32s in 0.071322 seconds. MO: 20665677 ( )
quadsort: sorted 1000000 i32s in 0.076605 seconds. MO: 19242642 ( )
qsort: sorted 1000000 i32s in 0.038389 seconds. MO: 6221917 ( )
quadsort: sorted 1000000 i32s in 0.002305 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.009659 seconds. MO: 4000015 ()
quadsort: sorted 1000000 i32s in 0.022940 seconds. MO: 9519209 ( )
qsort: sorted 1000000 i32s in 0.042135 seconds. MO: 13152042 ( )
quadsort: sorted 1000000 i32s in 0.034456 seconds. MO: 6787656 ( )
qsort: sorted 1000000 i32s in 0.098691 seconds. MO: 20584424 ( )
quadsort: sorted 1000000 i32s in 0.066240 seconds. MO: 11383441 ( )
qsort: sorted 1000000 i32s in 0.118086 seconds. MO: 20572142 ( )
quadsort: sorted 1000000 i32s in 0.038116 seconds. MO: 15328606 ( )
qsort: sorted 1000000 i32s in 4.471858 seconds. MO: 1974047339 ( )
quadsort: sorted 1000000 i32s in 0.060989 seconds. MO: 15328606 ()
qsort: sorted 1000000 i32s in 0.043175 seconds. MO: 10333679 ()
quadsort: sorted 1023 i32s in 0.016126 seconds. (random 1-1023)
qsort: sorted 1023 i32s in 0.033132 seconds. (random 1-1023)在此基准测试中,很清楚为什么快速排序通常比传统合并更可取,因为它对按升序排列,均匀分布的数据和按降序排列的数据进行的比较较少。但是,在大多数测试中,它的表现都比四分法差。Quicksort对波次数据也表现出极慢的分类速度。随机数据测试表明,对小型数组进行排序时,四分之一的速度是其两倍以上。
Quicksort在常规和稳定测试中速度更快,但这仅是因为它是一种不稳定的算法。
也可以看看: