让我们记住我们前进的计划:
1部分。我们决定了技术任务和解决方案的体系结构,并使用golang编写了一个应用程序。
第2部分(您现在在这里)。我们将应用程序发布到生产环境中,使其可扩展并测试负载。
第三部分让我们尝试找出为什么我们需要将消息存储在缓冲区中而不是文件中,并比较kafka,rabbitmq和yandex队列服务之间的原因。
第4部分我们将部署Clickhouse集群,编写流以从那里的缓冲区传输数据,并在datalens中设置可视化。
第5部分让我们将整个基础结构设置为适当的形状-使用gitlab ci配置ci / cd,使用consul和prometheus连接监视和服务发现。

好吧,让我们继续我们的任务。
我们投入生产
在第1部分中,我们组装了应用程序,对其进行了测试,还将映像上传到专用容器注册表中,以供部署。
总的来说,下一步应该是显而易见的-我们创建虚拟机,设置负载平衡器,并注册一个DNS名称以代理cloudflare。但是,我担心此选项与我们的职权范围不符。我们希望能够在负载增加的情况下扩展我们的服务,并从中丢弃无法服务请求的损坏节点。
为了进行扩展,我们将使用计算云中可用的实例组。它们使您可以从模板创建虚拟机,使用运行状况检查监视其可用性,还可以在负载增加的情况下自动增加节点数。更多细节在这里。
只有一个问题-虚拟机要使用哪个模板?当然,您可以安装linux,对其进行配置,制作映像并将其上传到Yandex.Cloud中的映像存储。但是对我们来说,这是一段漫长而艰难的旅程。在查看创建虚拟机时可用的各种映像时,我们遇到了一个有趣的实例-容器优化映像(https://cloud.yandex.ru/docs/cos/concepts/)。它允许您在网络模式主机中运行单个docker容器。也就是说,在创建虚拟机时,将针对容器优化的映像大致指定以下规格:
spec:
containers:
- name: api
image: vozerov/events-api:v1
command:
- /app/app
args:
- -kafka=kafka.ru-central1.internal:9092
securityContext:
privileged: false
tty: false
stdin: false
restartPolicy: Always在启动虚拟机之后,将在本地下载并启动此容器。
该方案非常有趣:
- 当cpu使用率超过60%时,我们将创建一个具有自动缩放比例的实例组。
- 作为模板,我们指定一个虚拟机,该虚拟机具有容器优化的映像和用于运行Docker容器的参数。
- 我们创建了一个负载均衡器,它将查看我们的实例组并在添加或删除虚拟机时自动更新。
- 该应用程序将作为一个实例组以及由平衡器本身进行监视,这将使无法访问的虚拟机失去平衡。
听起来像是个计划!
让我们尝试使用terraform创建一个实例组。整个描述位于instance-group.tf中,我将对要点进行评论:
- 服务帐户ID将用于创建和删除虚拟机。顺便说一下,我们将不得不创建它。
service_account_id = yandex_iam_service_account.instances.id - spec.yml, , . registry , - — docker hub. , —
metadata = { docker-container-declaration = file("spec.yml") ssh-keys = "ubuntu:${file("~/.ssh/id_rsa.pub")}" } - service account id, container optimized image, container registry . registry , :
service_account_id = yandex_iam_service_account.docker.id - Scale policy. :
autoscale { initialsize = 3 measurementduration = 60 cpuutilizationtarget = 60 minzonesize = 1 maxsize = 6 warmupduration = 60 stabilizationduration = 180 }
. — fixed_scale , auth_scale.
:
initial size — ;
measurement_duration — ;
cpu_utilization_target — , ;
min_zone_size — — , ;
max_size — ;
warmup_duration — , , ;
stabilization_duration — — , .
. 3 (initial_size), (min_zone_size). cpu (measurement_duration). 60% (cpu_utilization_target), , (max_size). 60 (warmup_duration), cpu. 120 (stabilization_duration), 60% (cpu_utilization_target).
— https://cloud.yandex.ru/docs/compute/concepts/instance-groups/policies#auto-scale-policy - Allocation policy. , , — .
allocationpolicy { zones = ["ru-central1-a", "ru-central1-b", "ru-central1-c"] } - :
deploy_policy { maxunavailable = 1 maxcreating = 1 maxexpansion = 1 maxdeleting = 1 }
max_creating — ;
max_deleting — ;
max_expansion — ;
max_unavailable — RUNNING, ;
— https://cloud.yandex.ru/docs/compute/concepts/instance-groups/policies#deploy-policy - :
load_balancer { target_group_name = "events-api-tg" }
创建实例组时,还可以为负载均衡器创建目标组。它将针对关联的虚拟机。如果删除,则将节点从平衡中删除,并且在创建时,将在通过状态检查后将它们添加到平衡中。
看来一切都是基本的-让我们为实例组以及实际上是组本身创建一个服务帐户。
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_iam_service_account.instances -target yandex_resourcemanager_folder_iam_binding.editor
... skipped ...
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_compute_instance_group.events_api_ig
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.该组已创建-您可以查看和检查:
vozerov@mba:~/events/terraform (master *) $ yc compute instance-group list
+----------------------+---------------+------+
| ID | NAME | SIZE |
+----------------------+---------------+------+
| cl1s2tu8siei464pv1pn | events-api-ig | 3 |
+----------------------+---------------+------+
vozerov@mba:~/events/terraform (master *) $ yc compute instance list
+----------------------+---------------------------+---------------+---------+----------------+-------------+
| ID | NAME | ZONE ID | STATUS | EXTERNAL IP | INTERNAL IP |
+----------------------+---------------------------+---------------+---------+----------------+-------------+
| ef3huodj8g4gc6afl0jg | cl1s2tu8siei464pv1pn-ocih | ru-central1-c | RUNNING | 130.193.44.106 | 172.16.3.3 |
| epdli4s24on2ceel46sr | cl1s2tu8siei464pv1pn-ipym | ru-central1-b | RUNNING | 84.201.164.196 | 172.16.2.31 |
| fhmf37k03oobgu9jmd7p | kafka | ru-central1-a | RUNNING | 84.201.173.41 | 172.16.1.31 |
| fhmh4la5dj0m82ihoskd | cl1s2tu8siei464pv1pn-ahuj | ru-central1-a | RUNNING | 130.193.37.94 | 172.16.1.37 |
| fhmr401mknb8omfnlrc0 | monitoring | ru-central1-a | RUNNING | 84.201.159.71 | 172.16.1.14 |
| fhmt9pl1i8sf7ga6flgp | build | ru-central1-a | RUNNING | 84.201.132.3 | 172.16.1.26 |
+----------------------+---------------------------+---------------+---------+----------------+-------------+
vozerov@mba:~/events/terraform (master *) $三个名称不正确的节点属于我们的组。我们检查应用程序是否适用于他们:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://130.193.44.106:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:04 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://84.201.164.196:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:09 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://130.193.37.94:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:15 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $顺便说一句,您可以使用ubuntu登录名进入虚拟机,并查看容器日志及其启动方式。
还为平衡器创建了一个目标组,可以将请求发送到该目标组:
vozerov@mba:~/events/terraform (master *) $ yc load-balancer target-group list
+----------------------+---------------+---------------------+-------------+--------------+
| ID | NAME | CREATED | REGION ID | TARGET COUNT |
+----------------------+---------------+---------------------+-------------+--------------+
| b7rhh6d4assoqrvqfr9g | events-api-tg | 2020-04-13 16:23:53 | ru-central1 | 3 |
+----------------------+---------------+---------------------+-------------+--------------+
vozerov@mba:~/events/terraform (master *) $让我们已经创建了一个平衡器并尝试向其发送流量!load-balancer.tf中描述了此过程,重点:
- 我们指示平衡器将侦听哪个外部端口,以及在哪个端口上将请求发送到虚拟机。我们指出外部地址的类型-ip v4。目前,负载平衡器在传输级别运行,因此它只能平衡tcp / udp连接。因此,您将不得不在自己的虚拟机或可以处理https的外部服务(例如cloudflare)上使用ssl进行安装。
listener { name = "events-api-listener" port = 80 target_port = 8080 external_address_spec { ipversion = "ipv4" } } healthcheck { name = "http" http_options { port = 8080 path = "/status" } }
健康检查。在这里,我们指定用于检查节点的参数-通过端口8080上的http url / status进行检查。如果检查失败,则计算机将失去平衡。
有关负载均衡器的更多信息-cloud.yandex.ru/docs/load-balancer/concepts。有趣的是,您可以在平衡器上连接DDOS保护服务。然后,已经清除的流量将进入您的服务器。
我们创建:
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_lb_network_load_balancer.events_api_lb
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.我们取出创建的平衡器的ip并测试工作:
vozerov@mba:~/events/terraform (master *) $ yc load-balancer network-load-balancer get events-api-lb
id:
folder_id:
created_at: "2020-04-13T16:34:28Z"
name: events-api-lb
region_id: ru-central1
status: ACTIVE
type: EXTERNAL
listeners:
- name: events-api-listener
address: 130.193.37.103
port: "80"
protocol: TCP
target_port: "8080"
attached_target_groups:
- target_group_id:
health_checks:
- name: http
interval: 2s
timeout: 1s
unhealthy_threshold: "2"
healthy_threshold: "2"
http_options:
port: "8080"
path: /status现在我们可以在其中留下消息了:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:42:57 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":1}
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:42:58 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":2}
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:43:00 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":3}
vozerov@mba:~/events/terraform (master *) $太好了,一切正常。最后的联系仍然存在,以便我们可以通过https访问-我们将cloudflare与代理连接起来。如果您决定不使用cloudflare,则可以跳过此步骤。
vozerov@mba:~/events/terraform (master *) $ terraform apply -target cloudflare_record.events
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.通过HTTPS测试:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' https://events.kis.im/post
HTTP/2 200
date: Mon, 13 Apr 2020 16:45:01 GMT
content-type: application/json
content-length: 41
set-cookie: __cfduid=d7583eb5f791cd3c1bdd7ce2940c8a7981586796301; expires=Wed, 13-May-20 16:45:01 GMT; path=/; domain=.kis.im; HttpOnly; SameSite=Lax
cf-cache-status: DYNAMIC
expect-ct: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
server: cloudflare
cf-ray: 5836a7b1bb037b2b-DME
{"status":"ok","partition":0,"Offset":5}
vozerov@mba:~/events/terraform (master *) $一切都终于开始了。
测试负载
我们可能剩下的最有趣的步骤是-对我们的服务进行负载测试并获得一些数字-例如,一个请求的处理时间的95%。测试我们的节点组的自动扩展也将是一件很不错的事情。
在开始测试之前,值得做一件简单的事情-将我们的应用程序节点添加到prometheus中,以跟踪请求的数量和一个请求的处理时间。由于我们尚未添加任何服务发现(我们将在本系列的第5条中进行此操作),因此我们只需在监视服务器上编写static_configs。您可以通过yc计算实例列表以标准方式找到其ip,然后将以下设置添加到/etc/prometheus/prometheus.yml:
- job_name: api
metrics_path: /metrics
static_configs:
- targets:
- 172.16.3.3:8080
- 172.16.2.31:8080
- 172.16.1.37:8080我们机器的IP地址也可以从yc计算实例列表中获取。通过systemctl重新启动prometheus,重新启动prometheus,并转到端口9090(84.201.159.71:9090)上可用的Web界面,检查是否已成功轮询节点。
让我们从grafana文件夹中添加一个仪表板到grafana中。我们使用端口3000(84.201.159.71:3000)并使用用户名/密码-admin / Password去Grafana。接下来,添加本地prometheus并导入仪表板。实际上,此时,准备工作已完成-您可以在我们的安装中提出要求。
为了进行测试,我们将使用yandex储箱(https://yandex.ru/dev/tank/)和用于重载的插件。yandex.net这将使我们可视化坦克收到的数据。您需要工作的所有内容都在原始git存储库的load文件夹中。
关于那里的一些信息:
- token.txt-具有来自过载.yandex.net的API密钥的文件-您可以通过在服务上注册来获取它。
- load.yml-战车的配置文件,有一个测试域-events.kis.im,rps加载类型以及3分钟内每秒15,000个请求的数量。
- data-用于生成ammo.txt格式的配置的特殊文件。在其中,我们编写了请求的类型,URL,用于显示统计信息的组以及需要发送的实际数据。
- makeammo.py-用于从数据文件生成ammo.txt文件的脚本。有关脚本的更多信息-yandextank.readthedocs.io/en/latest/ammo_generators.html
- ammo.txt-生成的弹药文件,将用于发送请求。
为了进行测试,我在Yandex.Cloud外部放置了一个虚拟机(以确保一切正常),并为其创建了DNS记录load.kis.im。我在此处滚动了docker,因为我们将使用图片https://hub.docker.com/r/direvius/yandex-tank/启动坦克。
好吧,让我们开始吧。将我们的文件夹复制到服务器,添加令牌并启动坦克:
vozerov@mba:~/events (master *) $ rsync -av load/ cloud-user@load.kis.im:load/
... skipped ...
sent 2195 bytes received 136 bytes 1554.00 bytes/sec
total size is 1810 speedup is 0.78
vozerov@mba:~/events (master *) $ ssh load.kis.im -l cloud-user
cloud-user@load:~$ cd load/
cloud-user@load:~/load$ echo "TOKEN" > token.txt
cloud-user@load:~/load$ sudo docker run -v $(pwd):/var/loadtest --net host --rm -it direvius/yandex-tank -c load.yaml ammo.txt
No handlers could be found for logger "netort.resource"
17:25:25 [INFO] New test id 2020-04-13_17-25-25.355490
17:25:25 [INFO] Logging handler <logging.StreamHandler object at 0x7f209a266850> added
17:25:25 [INFO] Logging handler <logging.StreamHandler object at 0x7f209a20aa50> added
17:25:25 [INFO] Created a folder for the test. /var/loadtest/logs/2020-04-13_17-25-25.355490
17:25:25 [INFO] Configuring plugins...
17:25:25 [INFO] Loading plugins...
17:25:25 [INFO] Testing connection to resolved address 104.27.164.45 and port 80
17:25:25 [INFO] Resolved events.kis.im into 104.27.164.45:80
17:25:25 [INFO] Configuring StepperWrapper...
17:25:25 [INFO] Making stpd-file: /var/loadtest/ammo.stpd
17:25:25 [INFO] Default ammo type ('phantom') used, use 'phantom.ammo_type' option to override it
... skipped ...就是这样,进程正在运行。在控制台中,它看起来像这样:

并且我们正在等待过程完成,并正在观察响应时间,请求数量,当然还有我们虚拟机组的自动扩展。您可以通过Web界面监视一组虚拟机;在一组虚拟机的设置中,有一个“监视”选项卡。
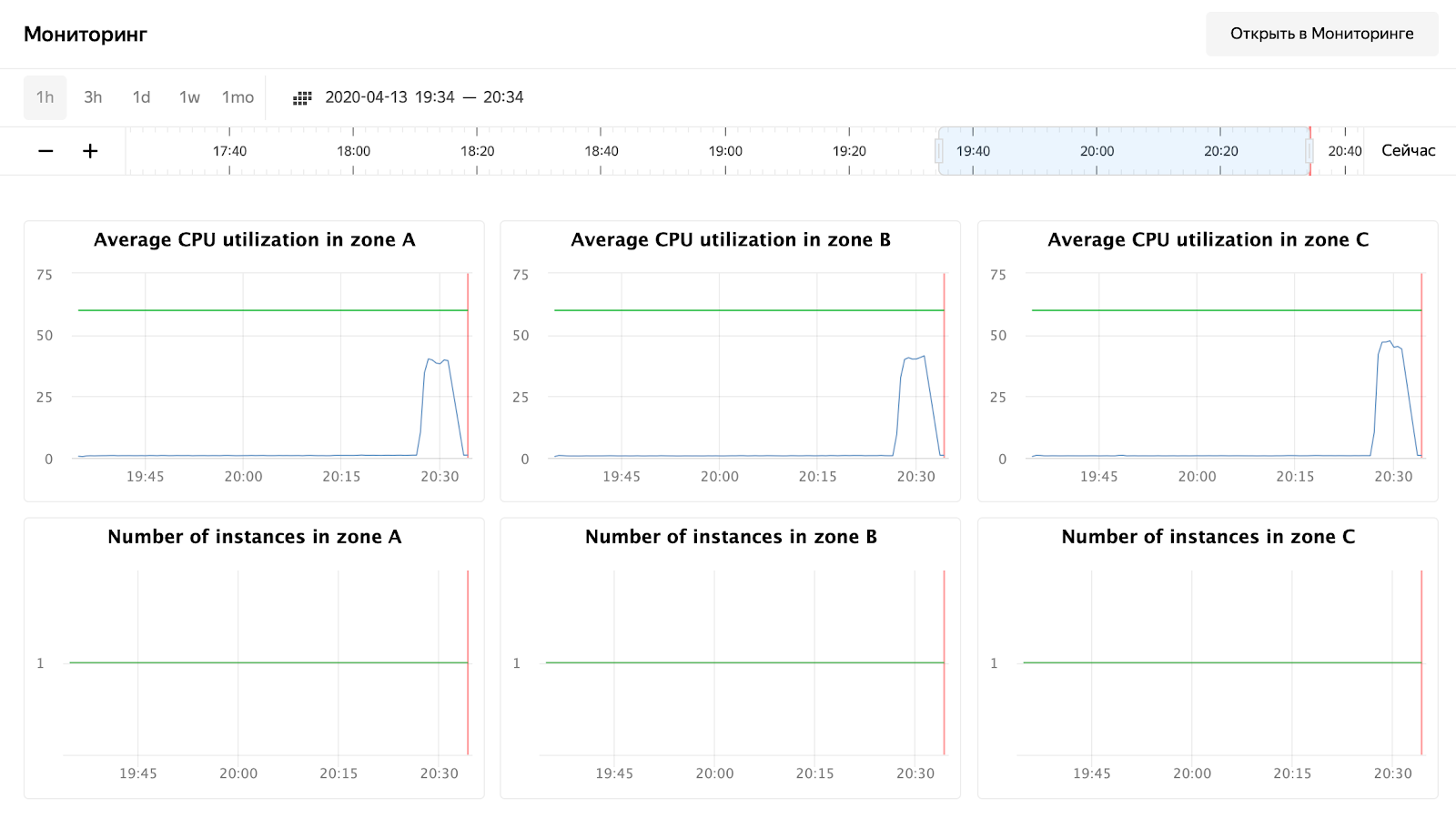
如您所见,我们的节点甚至没有加载高达50%的CPU,因此必须重复执行自动缩放测试。现在,让我们看一下Grafana中请求的处理时间:
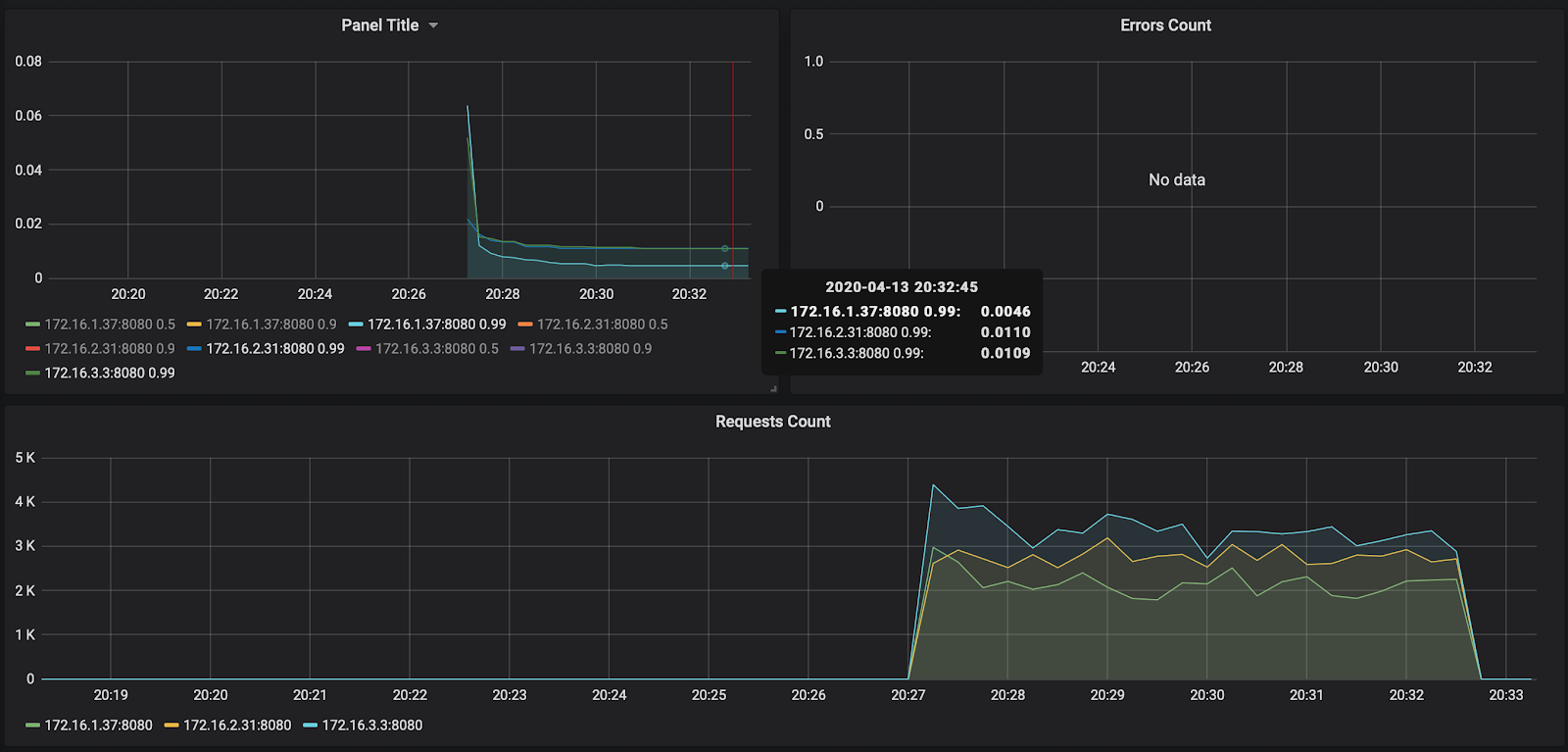
请求的数量(每个节点大约3000个)未加载到10,000个。响应时间令人满意-每个请求大约11毫秒。唯一脱颖而出的人-172.16.1.37-有一半的时间来处理请求。但这也是合乎逻辑的-它与存储消息的kafka处于同一ru-central1-a可用区中。
顺便说一句,可以通过以下链接获得有关首次启动的报告:https : //overload.yandex.net/265967。
因此,让我们运行一个更有趣的测试-添加实例:2000以每秒获得15,000个请求,并将测试时间增加到10分钟。生成的文件将如下所示:
overload:
enabled: true
package: yandextank.plugins.DataUploader
token_file: "token.txt"
phantom:
address: 130.193.37.103
load_profile:
load_type: rps
schedule: const(15000, 10m)
instances: 2000
console:
enabled: true
telegraf:
enabled: false细心的读者会注意到我将地址更改为平衡器的IP-这是由于cloudflare开始阻止我接受来自一个ip的大量请求。我必须直接在Yandex.Cloud平衡器上设置水箱。启动后,您可以看到以下图片:
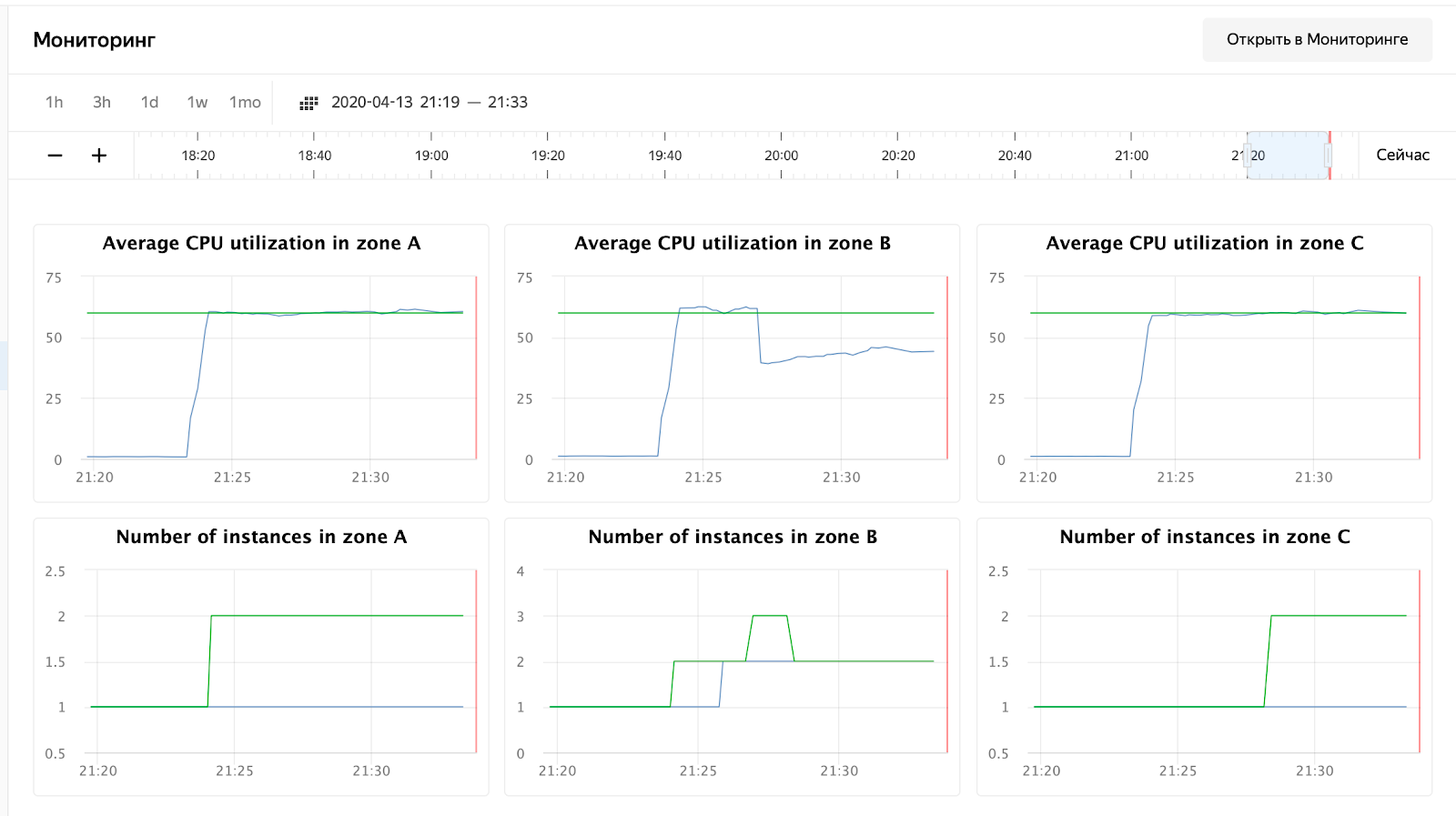
CPU使用率增加了,调度程序决定增加B区中的节点数,他这样做了。在实例组日志中可以看到:
vozerov@mba:~/events/load (master *) $ yc compute instance-group list-logs events-api-ig
2020-04-13 18:26:47 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 1m AWAITING_WARMUP_DURATION -> RUNNING_ACTUAL
2020-04-13 18:25:47 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 37s OPENING_TRAFFIC -> AWAITING_WARMUP_DURATION
2020-04-13 18:25:09 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 43s CREATING_INSTANCE -> OPENING_TRAFFIC
2020-04-13 18:24:26 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 6s DELETED -> CREATING_INSTANCE
2020-04-13 18:24:19 cl1s2tu8siei464pv1pn-ozix.ru-central1.internal 0s PREPARING_RESOURCES -> DELETED
2020-04-13 18:24:19 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 0s PREPARING_RESOURCES -> DELETED
2020-04-13 18:24:15 Target allocation changed in accordance with auto scale policy in zone ru-central1-a: 1 -> 2
2020-04-13 18:24:15 Target allocation changed in accordance with auto scale policy in zone ru-central1-b: 1 -> 2
... skipped ...
2020-04-13 16:23:57 Balancer target group b7rhh6d4assoqrvqfr9g created
2020-04-13 16:23:43 Going to create balancer target group
调度程序还决定增加其他区域中的服务器数量,但我超出了外部ip地址的限制:)顺便说一句,可以通过请求技术支持,指定配额和所需值来增加它们。
结论
这篇文章并不容易-无论是在数量上还是在信息量上。但是我们经历了最困难的阶段,并做了以下工作:
- 提出了监测和卡夫卡。
- , .
- load balancer’ cloudflare ssl .
下次,让我们比较和测试rabbitmq / kafka / yandex队列服务。
敬请关注!
*这种材料是在开放车间REBRAIN&Yandex.Cloud的录像:我们对Yandex的云接受每秒10,000个请求- https://youtu.be/cZLezUm0ekE
如果你有兴趣在网上逛这样的事件,并要求实时的问题,连接到通过REBRAIN频道DevOps。
在此特别感谢Yandex.Cloud举办这次活动的机会。链接到他们
如果您需要迁移到云或对基础架构有疑问,请随时提出请求。
附言:我们每月有2次免费审核,也许您的项目就在其中。