在Ya.Subbotnik Pro上的演讲中,我记得在“标准现代项目”的组装和架构中完成了什么以及如何完成,以及获得了什么结果。
-在过去的一年半里,我一直在Serp建筑团队工作。我们在那里开发运行时并在React和TypeScript中汇编新代码。
让我们谈谈本演讲将要解决的常见痛苦。当您想在React中制作一个小项目时,您只需要使用一组称为三个字母的标准工具-CRA。这包括构建脚本,用于运行测试的脚本,设置开发环境,并且一切都已经为生产完成。一切都非常简单地通过NPM脚本完成,每个人都可能知道有React经验的人。
但是,假设项目变大,它有很多代码,很多开发人员,生产功能(如翻译)出现了,Create React App对此一无所知。或者,您有某种复杂的CI / CD管道。然后想法开始弹出,以使用Create React App作为基础并针对您自己的项目对其进行自定义。但是,目前还不清楚在弹出之后还有什么等待着。因为当您执行弹出操作时,它表示这是非常危险的操作,因此无法将其退回,如此之类的,非常可怕。那些按下弹出按钮的人知道,那里有很多配置,您需要了解。通常,存在很多风险,目前尚不清楚该怎么办。
我会告诉你我们的情况如何。首先,关于我们的项目。我们的前端项目是每个人都看过的Serp,搜索引擎结果页,Yandex搜索结果页。自2018年以来,我们不再移动React和TypeScript。去年,已经在Serpa上编写了大约12 MB的代码。有几种样式以及很多TS和SCSS代码。在2018年初的时候,我没有写过多少书,只有很少的书,有非常大的跳跃。
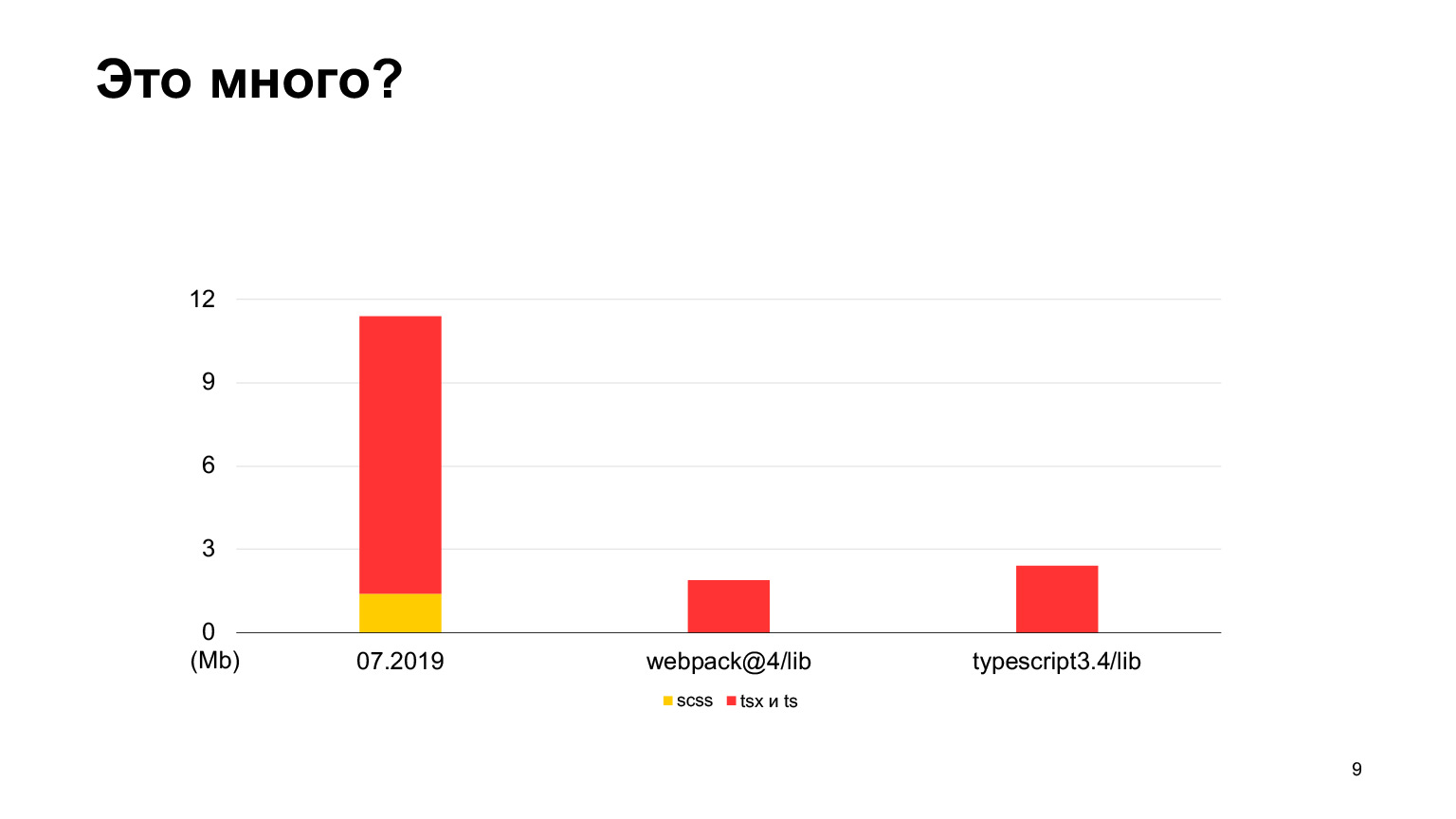
让我们看看这是否是很多代码。与webpack-4源代码相比,webpack-4中的代码要少得多。甚至TypeScript存储库的代码也更少。
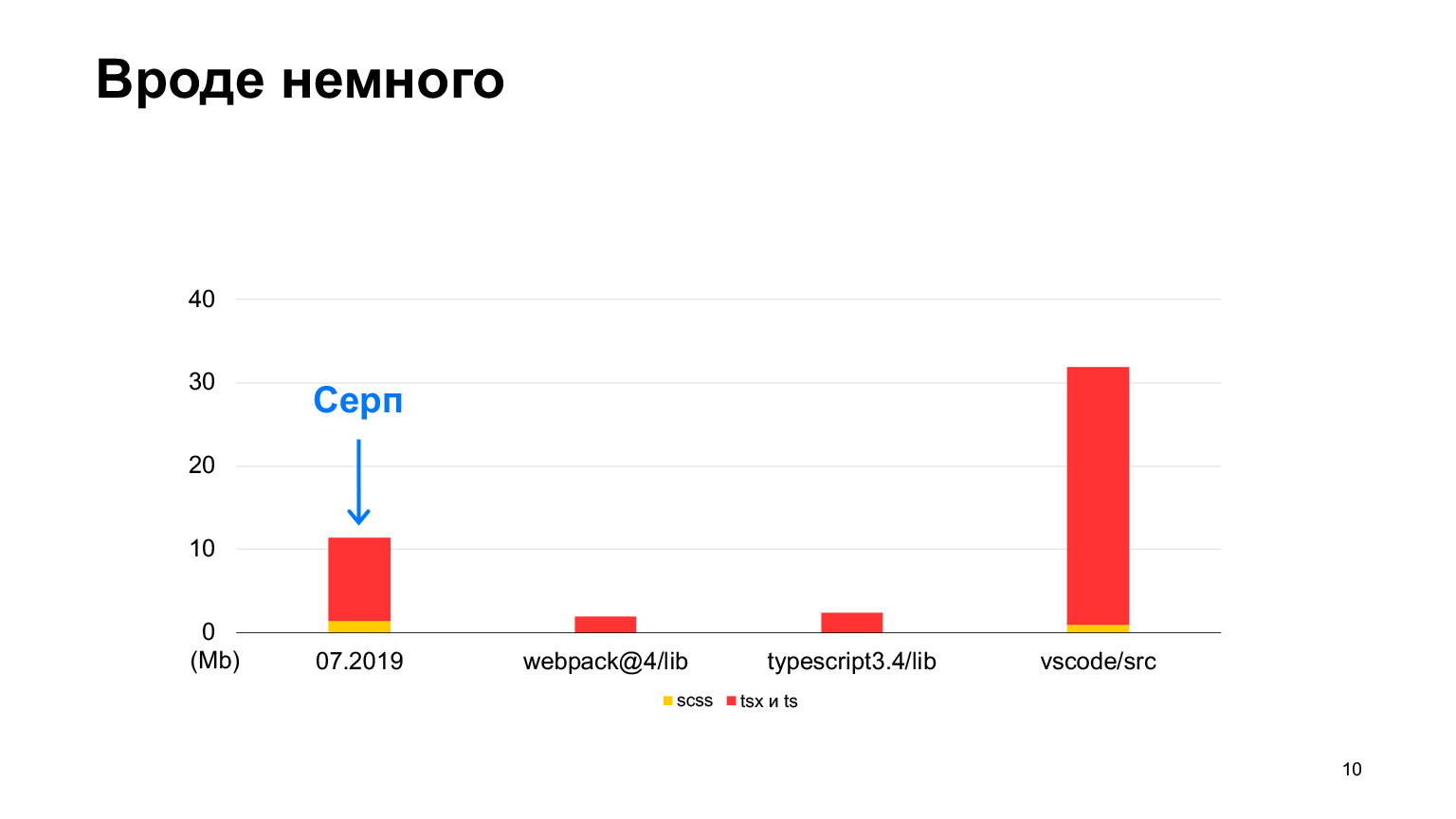
但是vs代码具有更多代码,这是一个很好的项目,具有多达30 MB的TypeScript代码。是的,它也是用TypeScript编写的,Sickle似乎更小。我们从2018年开始,在2019年有12兆字节,我们的70名开发人员都在工作,每周进行100次倾倒请求。在一年中,他们将这个大小增加了三倍,并接收了正好30兆字节。我本月进行了测量,现在总共有30 MB的代码,这已经超过了vs代码。
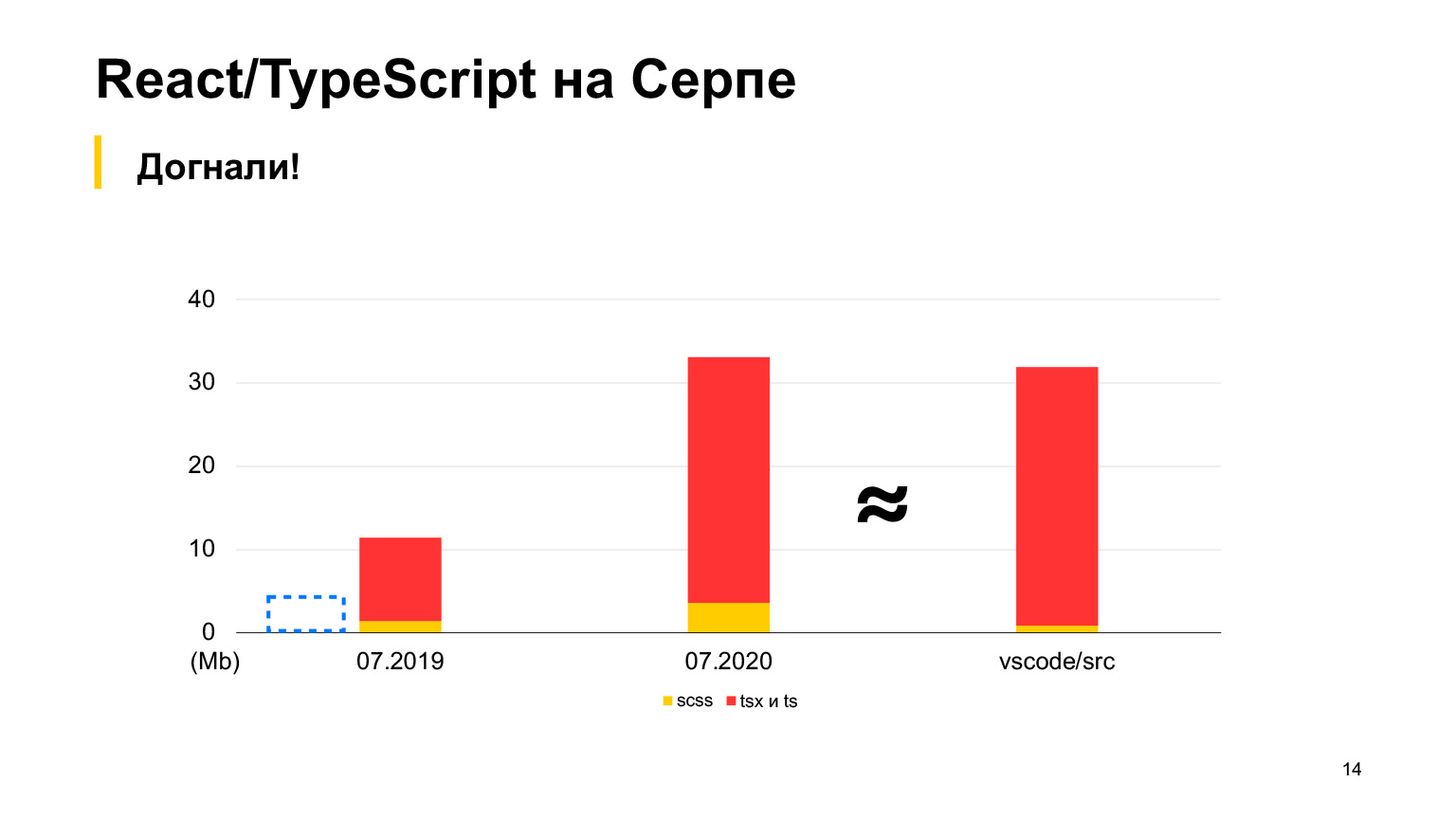
大致相等,但略多一些。这是我们项目的顺序。
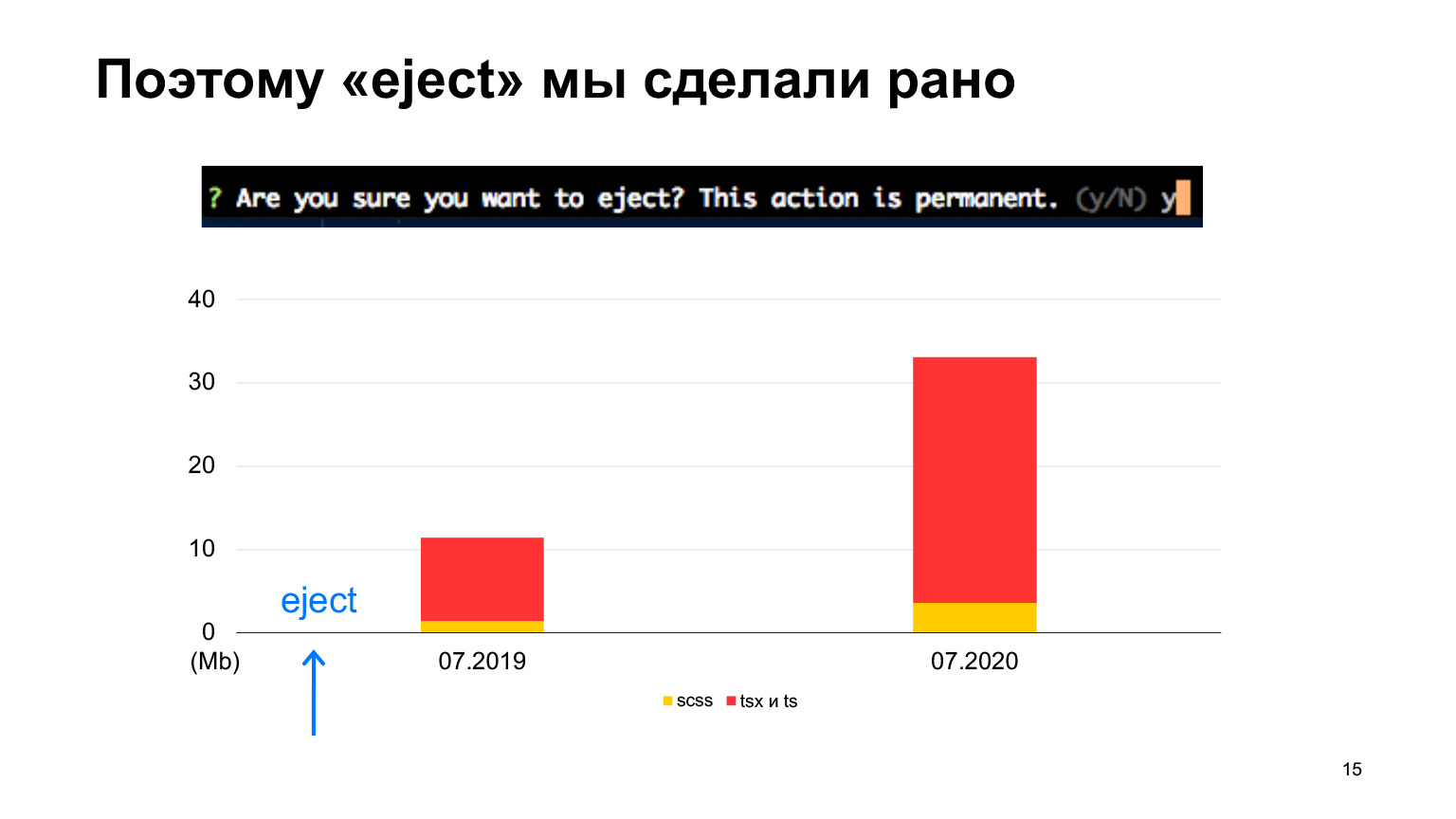
我们确实在一开始就弹出了,因为我们立即知道我们将有很多代码,并且很可能Create Create App中的初始配置对我们不起作用。但是,我们以创建React App的相同方式开始。
这就是故事的主题。我们想分享我们的经验,告诉您如何使用Create React App来使Yandex Serp正常工作。也就是说,我们如何在浏览器中快速加载和初始化,以及如何不减慢构建速度,设置,插件和用于此目的的其他东西。当然,我们取得的成果将在最后。

我们是如何推理的?最初的想法是,我们的Sickle是需要非常快速地呈现的页面,因为基本上有非常简单的文本结果,因此我们需要服务器端模板,因为这是获得快速呈现的唯一方法。也就是说,我们必须在客户端上开始初始化之前就绘制一些内容。
同时,我想最小化静态变量的大小,以免加载多余的东西,并且初始化也很快。也就是说,我们既要进行第一次渲染又要进行快速初始化。

Create React App为我们提供了什么?不幸的是,它没有提供任何有关服务器渲染的信息。
它直接表明Create React App不支持服务器渲染。另外,Create React App对于整个应用程序只有一个条目。也就是说,默认情况下,将为您所有种类繁多的页面收集一个大文件包。好多显然,在30兆字节中,大约有一半是TS类型的,但是仍然有很多代码直接进入浏览器。
同时,Create React App具有一些好的设置,例如,webpack运行时在单独的块中进行。它是单独加载的,可以缓存,因为它不会正常更改。
另外,来自node_modules的模块也收集在单独的块中。它们也很少更改,因此它们也被浏览器缓存,这很棒,必须保存。但是同时,Create React App中的翻译也没有。
让我们汇总一下我们的平台功能列表的外观列表。首先,正如我所说,我们希望向北进行快速渲染。此外,我们希望每个搜索结果都有一个单独的条目文件。

例如,如果Serpa有一个计算器,那么我们希望提供与计算器捆绑销售的产品,而与翻译器捆绑销售的产品则不需要快速交付。如果将所有这些收集在一个大包中,那么即使其中的一半不在特定问题上,也将始终如一。
此外,我想在单独的块中提供通用模块,以免加载已经加载的模块。
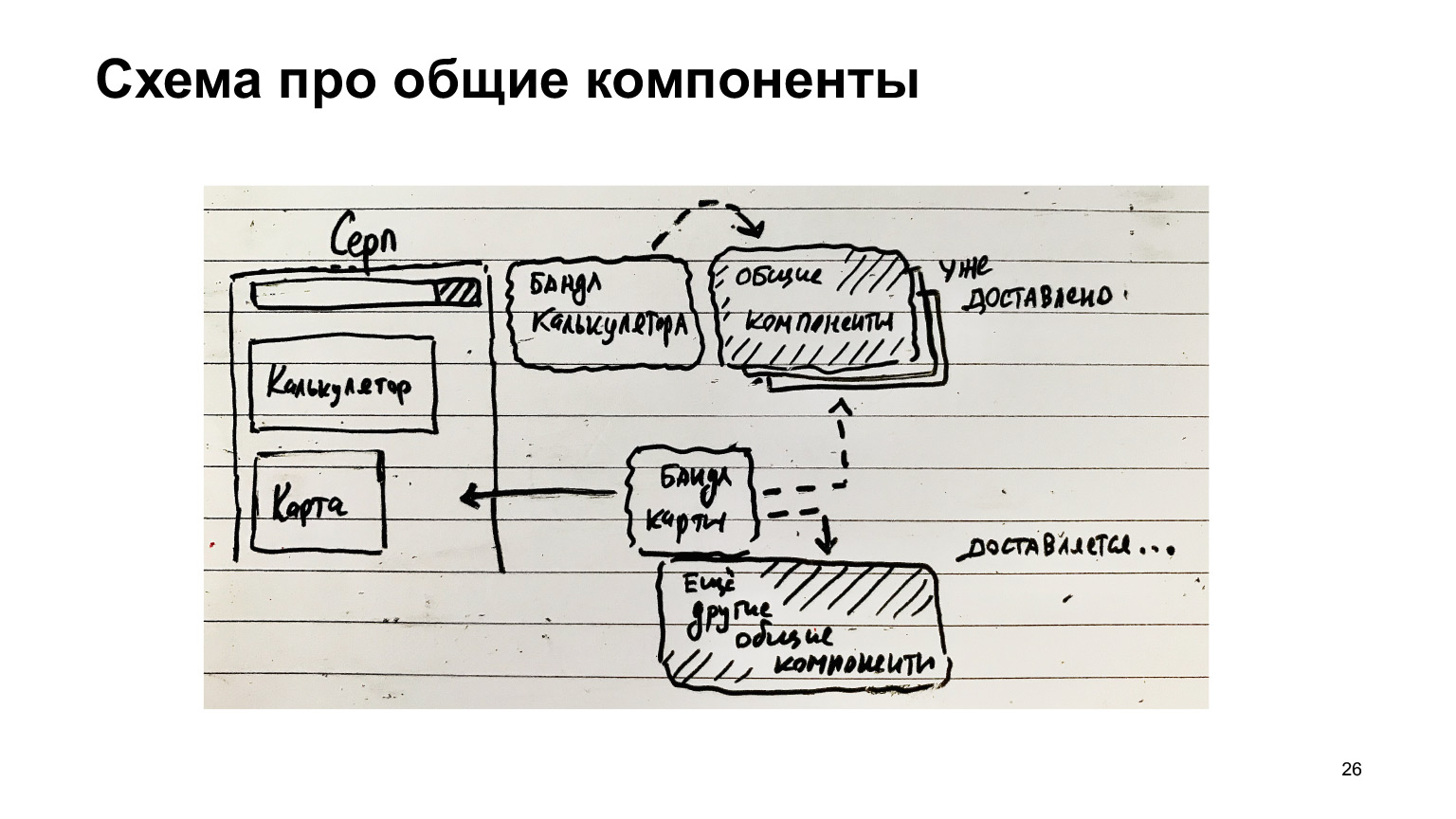
这是镰刀的另一个例子。它有一个计算器,有一个计算器包。有一些共同的组成部分。它们已交付给客户。然后出现了另一个功能-地图。拖动一堆地图,并拖动其他常用组件(减去已交付的组件)。
如果将公共组件分开收集,那么优化的机会就很大,仅交付所需的东西,仅交付差异商品。以及页面上始终最受欢迎的模块,例如,整个基础架构始终需要的webpack运行时,必须始终加载它。
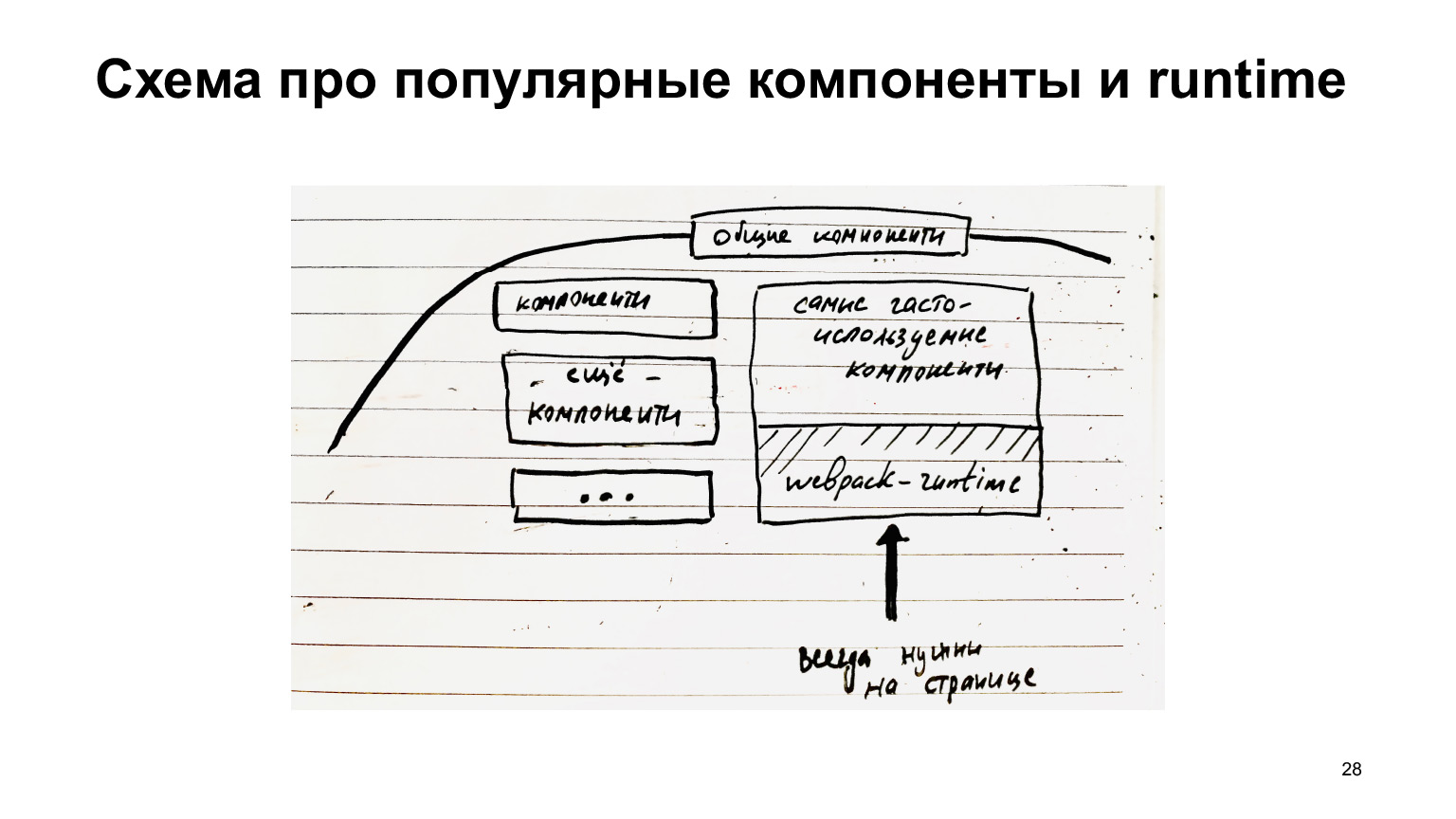
因此,将其收集在单独的块中是有意义的。即,这些通用组件也可以分解为不总是需要的那些组件和总是需要的那些组件。可以将它们收集在一个单独的文件中,并始终进行加载和缓存,因为这些常用组件(例如按钮/链接)不会经常更改,因此通常可以从缓存中获利。

同时,您需要决定如何组装翻译。

这里的一切都足够清楚。如果我们去土耳其语Serp,我们只想下载土耳其语翻译,而不要下载所有其他翻译,因为这是额外的代码。
我们做了什么?首先,关于服务器代码。关于这一点,我们将有两个方向-生产的建设和开发的启动。
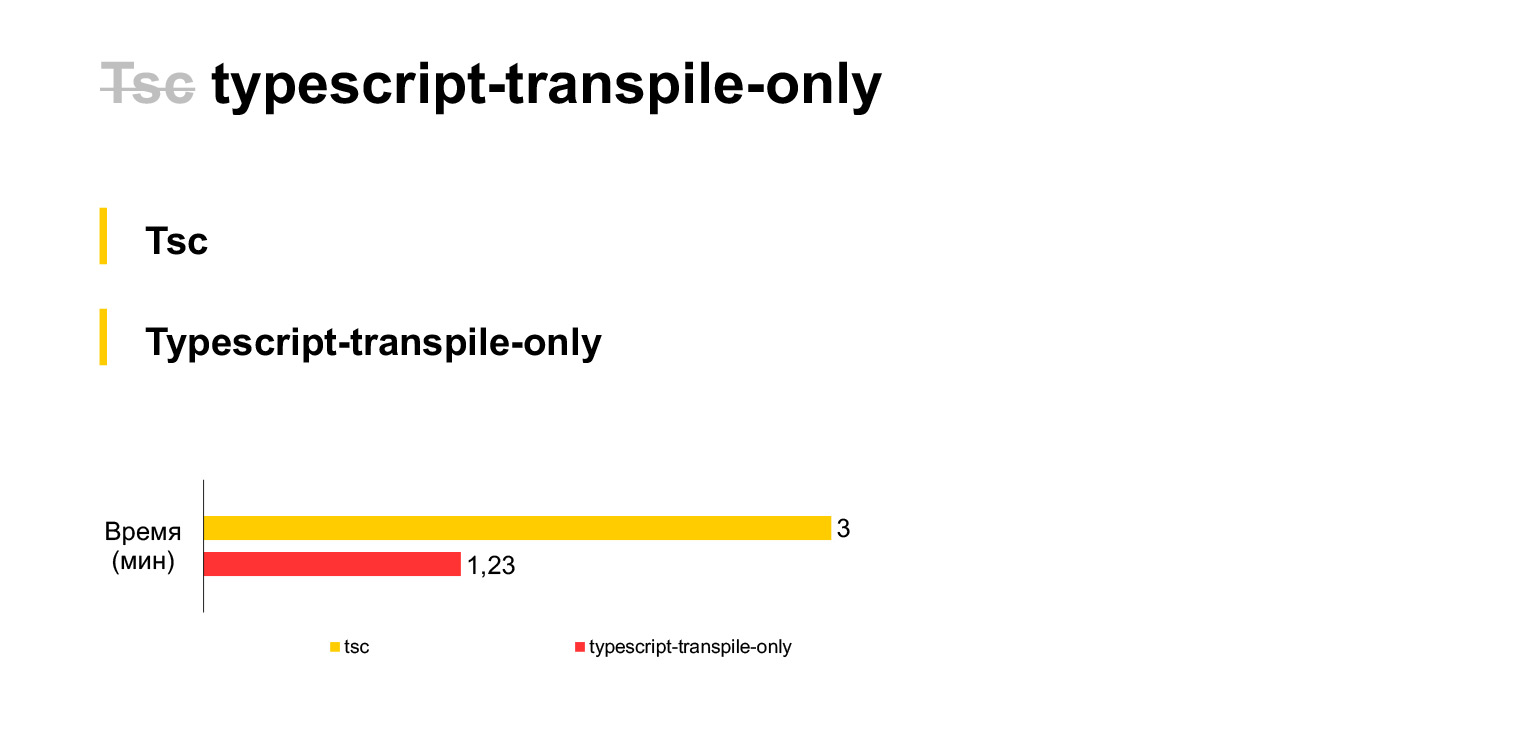
通常,您需要首先对TypeScript做这样一个单独的声明。正如我所听到的那样,通常项目使用babel。但是我们立即决定使用标准的TypeScript编译器,因为我们相信新的TypeScript功能会更快地实现它。因此,我们立即放弃了babel并使用了tsc。
因此,这是我们当前的代码大小,即30兆字节,是在三分钟内在笔记本电脑上编译的。有点。如果放弃类型检查并在每次编译过程中使用tsc分支(不幸的是,TSC没有设置会禁用类型检查的设置,则必须进行分支),那么您可以节省两次时间。编译我们的代码仅需一分半钟。
为什么我们不能编译时进行类型检查?例如,因为我们可以在预提交的钩子中检查它们。制作仅执行类型检查的短绒棉纱,而无需进行类型检查即可完成装配本身。我们做出了这个决定。
我们如何在dev中运行?开发人员通常还会在Webpack中使用babel捆绑包,但是我们会使用ts-node之类的工具。

这是一个非常简单的工具。为了运行它,在输入JavaScript文件中编写这样的require(ts节点)就足够了,并且稍后将覆盖整个TS代码的require-s。而且,如果在此过程中将TS代码加载到该过程中,则会即时对其进行编译。非常简单的事情。
当然,如果在该过程中尚未加载文件,则必须重新编译该文件,因此开销很小。但是实际上,这种开销很小,并且通常可以接受。
此外,此清单中还有一些更有趣的行。首先是忽略样式,因为我们不需要样式来进行服务器端模板化。我们只需要获取HTML。因此,我们也使用这样的模块-忽略样式。此外,我们完全像在TSC中一样,关闭了类型检查(仅可传输),以加快ts-node的工作。
转到客户端代码。我们如何在webpack中收集ts代码?我们使用ts-loader和transpileOnly选项,即大致相同的包。代替babel-loader,或多或少地使用了标准的ts-loader和transpileOnly工具。
不幸的是,增量构建在ts-loader中不起作用。也就是说,毕竟ts-loader并不是一个标准的工具,它不是由执行TypeScript的同一个人制作的。因此,此处不支持所有编译器选项。例如,不支持增量构建。
增量构建是一件事,在开发中可能非常有用。同样,您可以将这些缓存添加到管道中。通常,当您所做的更改很小时,您将无法完全重新编译所有内容(所有TypeScript),而只能重新编译。它非常有效。
通常,为了不进行增量构建,我们使用缓存加载器。这是webpack的标准解决方案。一切都非常清楚。在Webpack构建期间尝试连接时,TypeScript代码由编译器处理,然后添加到缓存中,并且下次在源文件中没有任何更改的情况下,缓存加载器将不会运行ts-loader,而是将从缓存中获取它。也就是说,这里的一切都很简单。
它可以用于任何东西,但是专门用于TypeScript,这是一件方便的事,因为ts-loader是相当重的加载器,因此cache-loader在这里非常合适。

但是缓存加载器有一个缺点-它与文件修改时间一起使用。这是源代码的片段。它对我们没有用。

我们必须基于文件内容中的哈希值来分叉并重做缓存算法,因为它不适合在管道中使用缓存加载器。
事实是,当您要在多个请求之间重用构建结果时,此机制将无法工作。因为如果装配是很久以前的。然后,您尝试发出一个新的请求,该请求不会更改上次收集的文件。
但是他们的mtime是最近的。因此,缓存加载器会认为文件已更新,但实际上不是,因为这不是修改时间,而是签出时间。如果您这样操作,则将比较内容中的哈希值。内容未更改,将使用旧结果。
这里应该注意,如果我们使用的是babel,默认情况下babel-loader内部有一个缓存机制,并且它是根据内容的哈希而不是mtime生成的。因此,也许我们会多想一点,并展望babel。
现在介绍块的组装。

让我们谈谈默认情况下webpack的功能。如果我们有输入索引文件,则将组件连接到该文件。它们还具有组件等。此外,还连接了通用模块:例如React,React-dom和lodash。
因此,默认情况下,众所周知,webpack是一个包,但以防万一,我重复一遍,将所有依赖项收集到一个大包中。
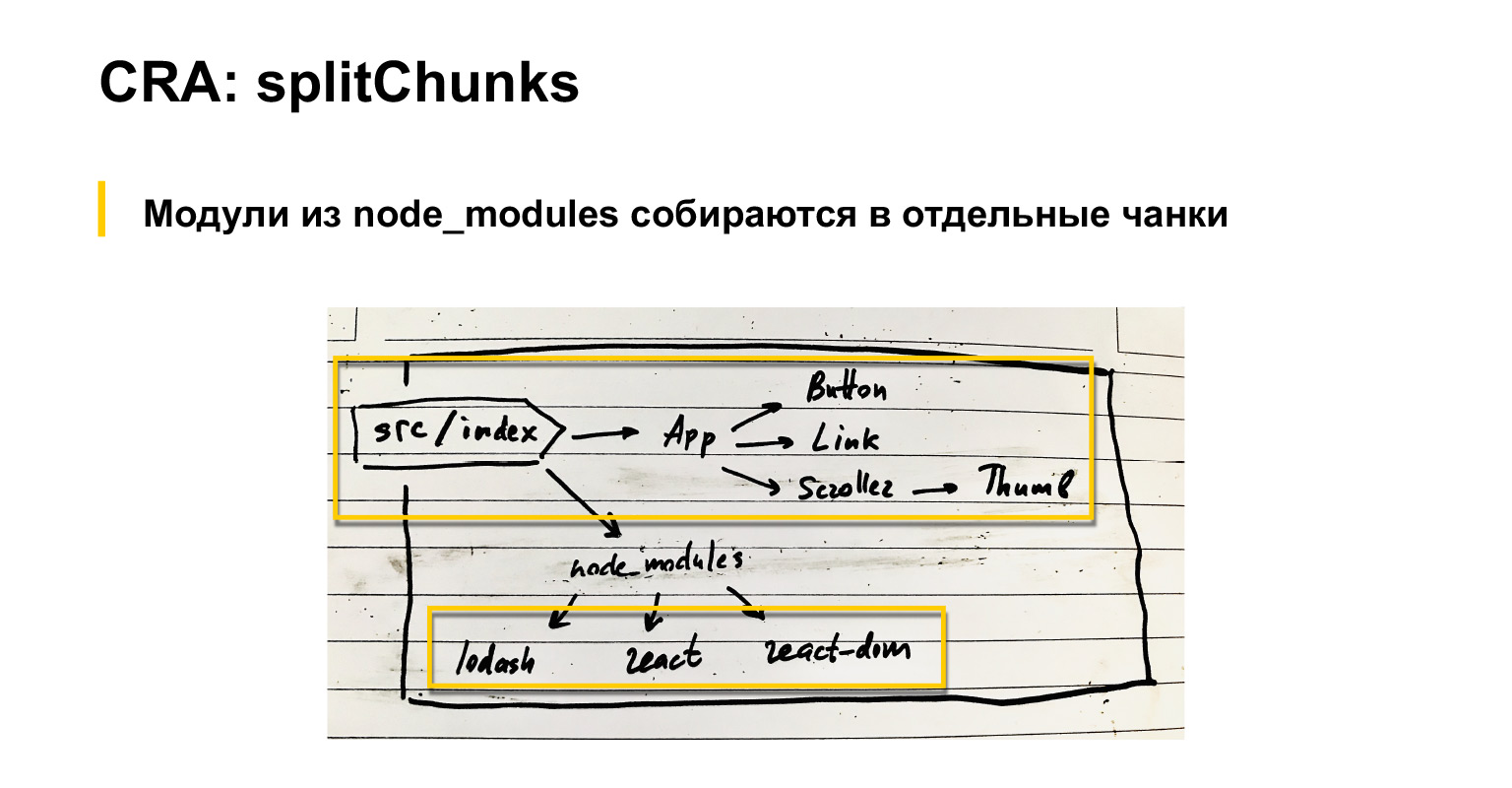
同时,通过node_modules连接的所有组件都可以作为外部组件进行组装,装入单独的脚本,也可以通过在webpack中设置特殊的optimization.splitChunks设置在单独的块中。我认为,即使默认情况下,这些供应商模块也被收集在单独的块中。 CRA对此splitChunks进行了略微调整。

让我们记住什么是runtimeChunks。我提到过他这种类型的代码包含确保脚本在客户端上运行的加载脚本和功能的“头”。然后是一个数组(或缓存),它实际上包含模块。

我为什么要告诉你这个?因为Create React App仍然使用将运行时块收集到一个单独文件中的设置。该文件不会卡在原始的正常捆绑包中,而是卡在单独的文件中。它可以缓存在浏览器中。
那么在Create React App中什么对我们不起作用?

默认情况下在此使用的splitChunks仅将node_modules收集到单独的块中。但是,实际上,在项目级别有一些通用组件,通用库。我也想将它们收集在单独的块中,因为它们也许也很少变化。为什么我们只将自己限制在node_modules中?
另外,对于runtimeChunks,我们也可以说,就像我们最初讨论的那样,除了运行时本身之外,还可以将始终需要的模块收集到同一块中。相同的按钮/链接。 Serp上总是有链接。我一直想收集链接。也就是说,不仅是webpack运行时,还包括一些超级流行的组件。
在Create React App中不存在。我们如何与我们合作?

我们对splitChunks进行了调整,使我们禁用了所有标准行为,并要求不仅收集node_modules中的内容,而且还收集项目的常见组件以及项目的库代码,src / lib中的内容到公共代码中。 ,src /组件包含。
此外,我们将通过动态导入连接的东西(通常称为异步块)收集到单独的块中。
在这里,您需要注意两个选项。一个是强制执行,另一个是初始执行。通常,forceforce设置非常方便,它会禁用splitChunks中的任何复杂的启发式方法。
默认情况下,splitChunks尝试了解需要多少模块,并在拆分时将这些统计信息考虑在内。但是很难做到这一点,并且对模块的需求可能会不时变化,并且模块将在块之间“跳转”。从常规块到功能包,再返回。也就是说,这是一种非常不可预测的行为,因此我们将其禁用。
也就是说,我们总是说满足测试领域条件的所有内容都进入了通用块。我们不需要任何启发式方法。
但是大块:最初也是一件好事,这是因为这些同步模块(通过动态导入连接的模块)可以在不同的地方以不同的方式连接。也就是说,您可以通过动态导入或常规导入来连接同一模块。
初始值允许以两种方式构建同一模块。也就是说,它既可以异步又可以同步进行组装,因此可以同时使用。方便。这会稍微扩大所收集的静力学的大小,但允许您使用任何导入。
顺便说一下,从文档中很难理解。最近,我重新阅读了webpack文档,而关于初始文档的内容却没有任何写法。

这就是我们对splitChunks所做的。现在,我们对runtimeChunks做了什么。我们要在其中添加更多超级流行的组件,而不是只在runtimeChunks中收集运行时。
我们已经编写了自己的名为MainChunkPlugin的插件。它的设置非常琐碎。这里只是需要收集的模块列表,我们认为它们很受欢迎。
只需使用我们的A / B测试工具和各种离线工具,我们就可以了解搜索结果中最常使用的组件。那就是他们被写成这样的简单清单的地方。最后,我们的插件从列表中收集这些组件,库以及收集此标准optimization.splitChunks的webpack运行时。

顺便说一下,这里是一段粘合运行时的代码。同样也不是一件容易的事,它表明编写插件并不是那么容易,但是让我们看看它提供了什么。

还应注意,通常来说,webpack具有执行此操作的标准机制,称为DLLPlugin。它还允许您根据依赖项列表收集单独的块。但是它有许多缺点。例如,它不包括runtimeChunks。也就是说,runtimeChunks始终会有一个单独的块,并且DLLPlugin将组装一个块。这不是很方便。
DLLPlugin也需要单独的程序集。也就是说,如果我们想使用DLLPlugin使用冲击力最大的组件来构建单独的块,则必须运行两个程序集。
也就是说,一个人用清单文件组装了这个单独的块,而其余的组装将仅通过清单文件减去就可以收集其他所有内容,而不会收集已经使用流行组件进入该块的内容。这会减慢构建速度,因为DLLPlugin实现在本地花费了我们七秒钟的时间。好多啊。由于它具有严格的顺序执行,因此无法进行优化。
另外,在某个时刻,我们需要使用流行的组件(不带CSS,只有JS)来构建我们的这一主要块。 DLLPlugin不会这样做。它总是收集通过需求通过需求获得的任何东西。也就是说,如果包含CSS,它也总是会命中。这对我们来说不舒服。但是,如果这对您来说不是问题,并且您不想编写此类棘手的代码,则DLLPlugin是一个非常普通的解决方案。他解决了主要问题。也就是说,它在一个单独的文件中提供了最受欢迎的组件。可以使用。
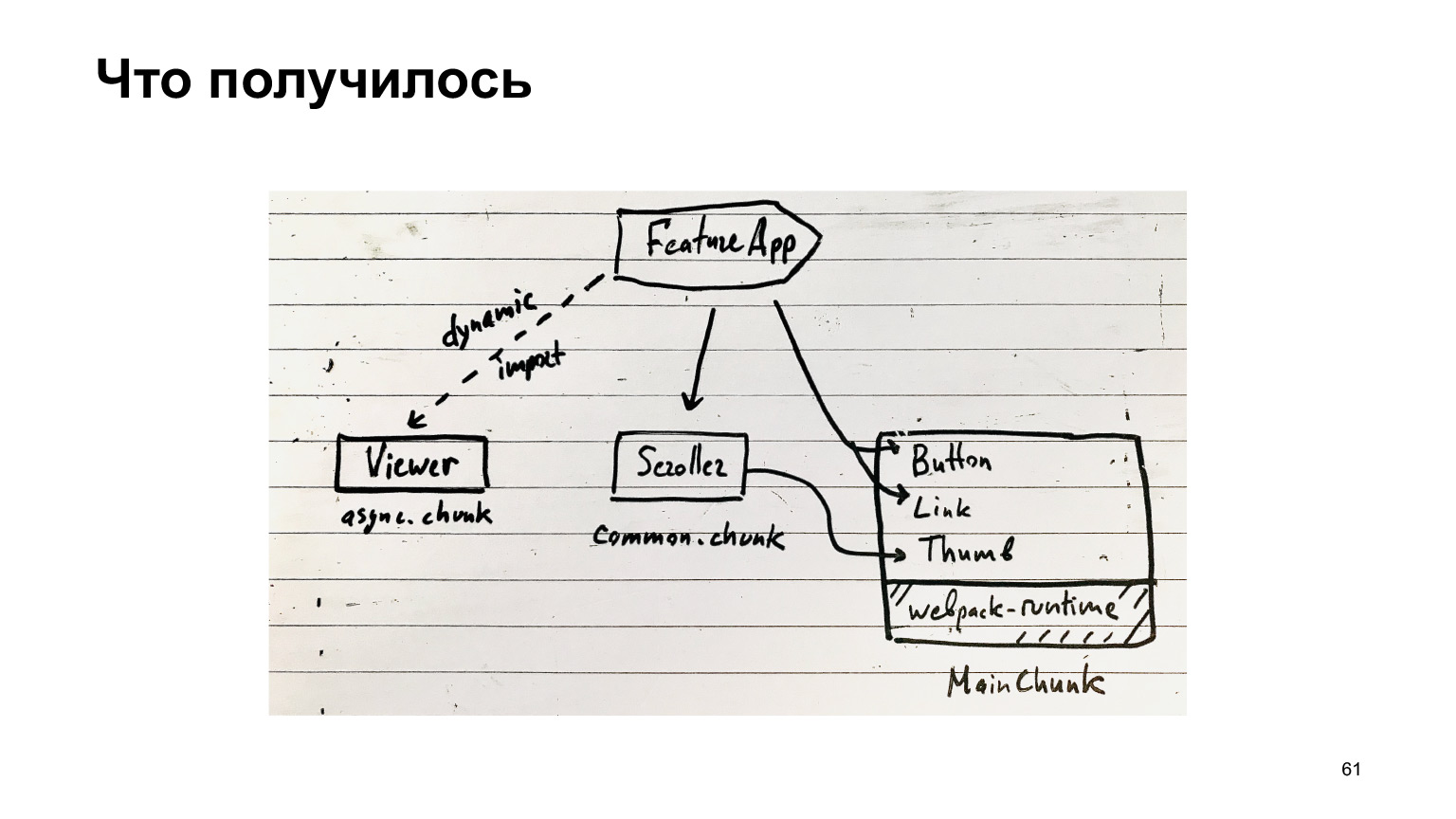
那我们做了什么?我们的功能可以使用MainChunk中的超级流行组件,这些组件由同名的特殊插件组装而成。此外,还有一些通用块,其中包括各种通用组件,还有一些异步块,它们是通过动态导入加载的。
其余代码在功能包中。原则上,这是您的块结构。
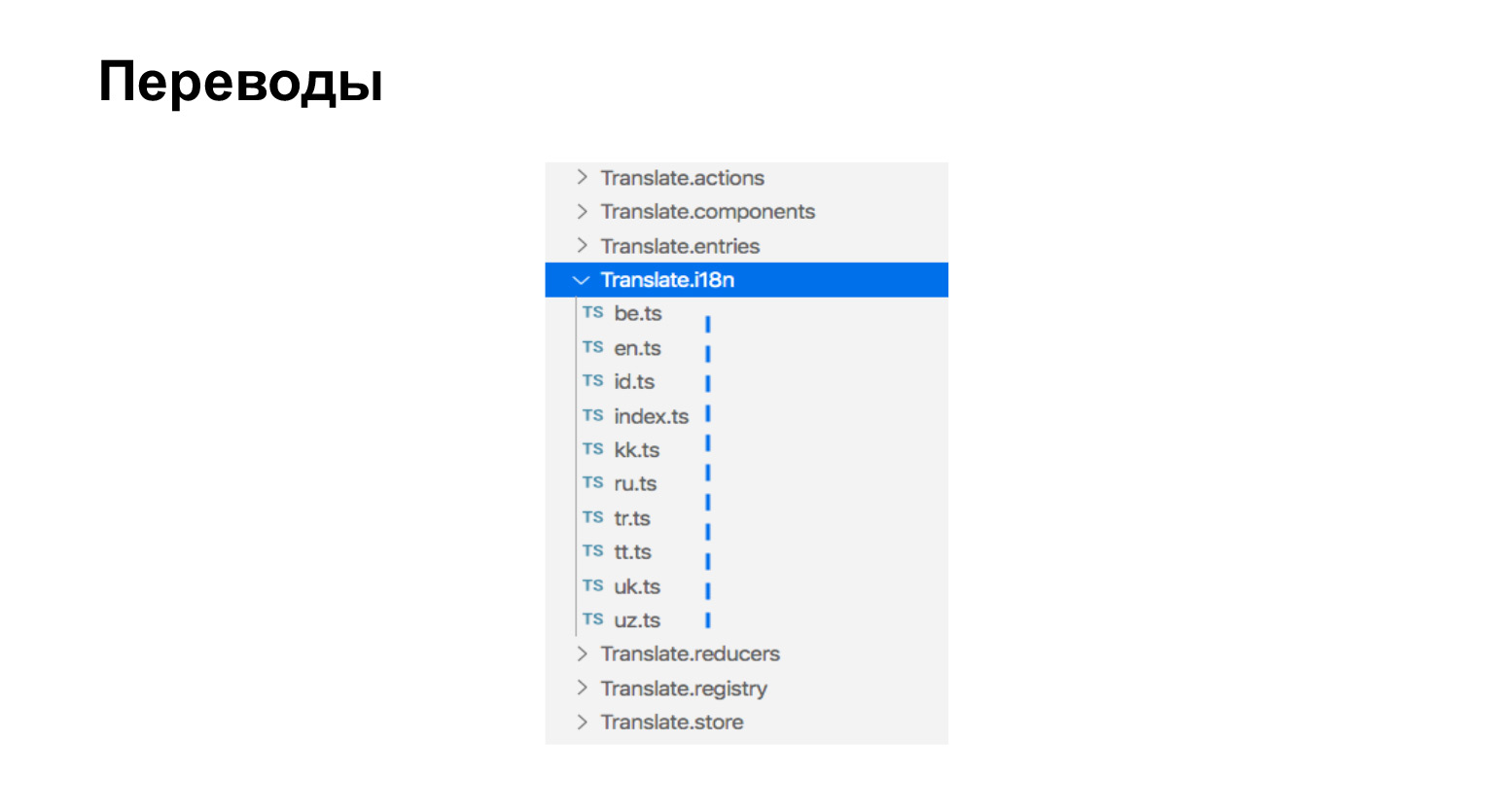
关于组装翻译。我们的翻译只是ts文件,位于需要翻译的组件旁边。这里有9种语言,这里有9个文件。

翻译看起来像这样。它只是一个包含关键短语和翻译短语含义的对象。

这是将翻译连接到组件的方式,然后使用特殊的帮助器。

如何收集这些翻译?我们认为:我们需要收集翻译,在Internet上浏览,他们写什么,如何做。
他们在互联网上说:使用多重编译。也就是说,不必运行一个webpack构建,而是针对每种语言运行webpack构建。但是,他们说,一切都会好起来的,因为有一个缓存加载器,所有与TypeScript一起使用的通用功能,或者您拥有的任何东西,都将被缓存,因此不会太长。
不要气,,不要以为这将是九次真正的webpack运行。事实并非如此,这将是好的。
唯一需要纠正的是添加ReplacementPlugin模块,该模块代替连接所有语言的索引文件,将其替换为特定的语言。一切都很琐碎,是的,输出需要固定。事实证明,现在我们需要为每种语言收集单独的捆绑包。

该配方的图表如下。有一位翻译。他连接了翻译的翻译。他连接了各种语言,我们没有收集这种结构,而是为每种语言复制了这种结构,得到了一种单独的语言,然后将每种语言收集为单独的汇编。
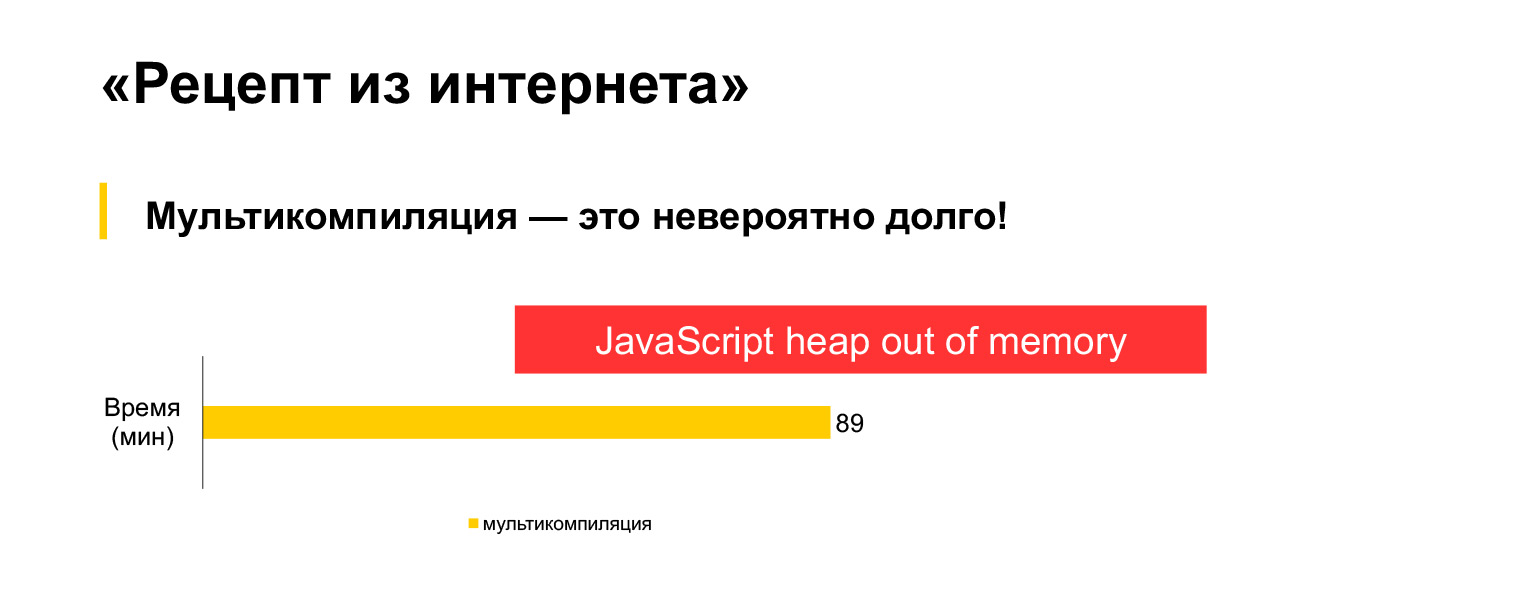
不幸的是,它不起作用。我尝试为当前的30MB代码运行此多编译选项,并等待了一个半小时,但出现此错误。

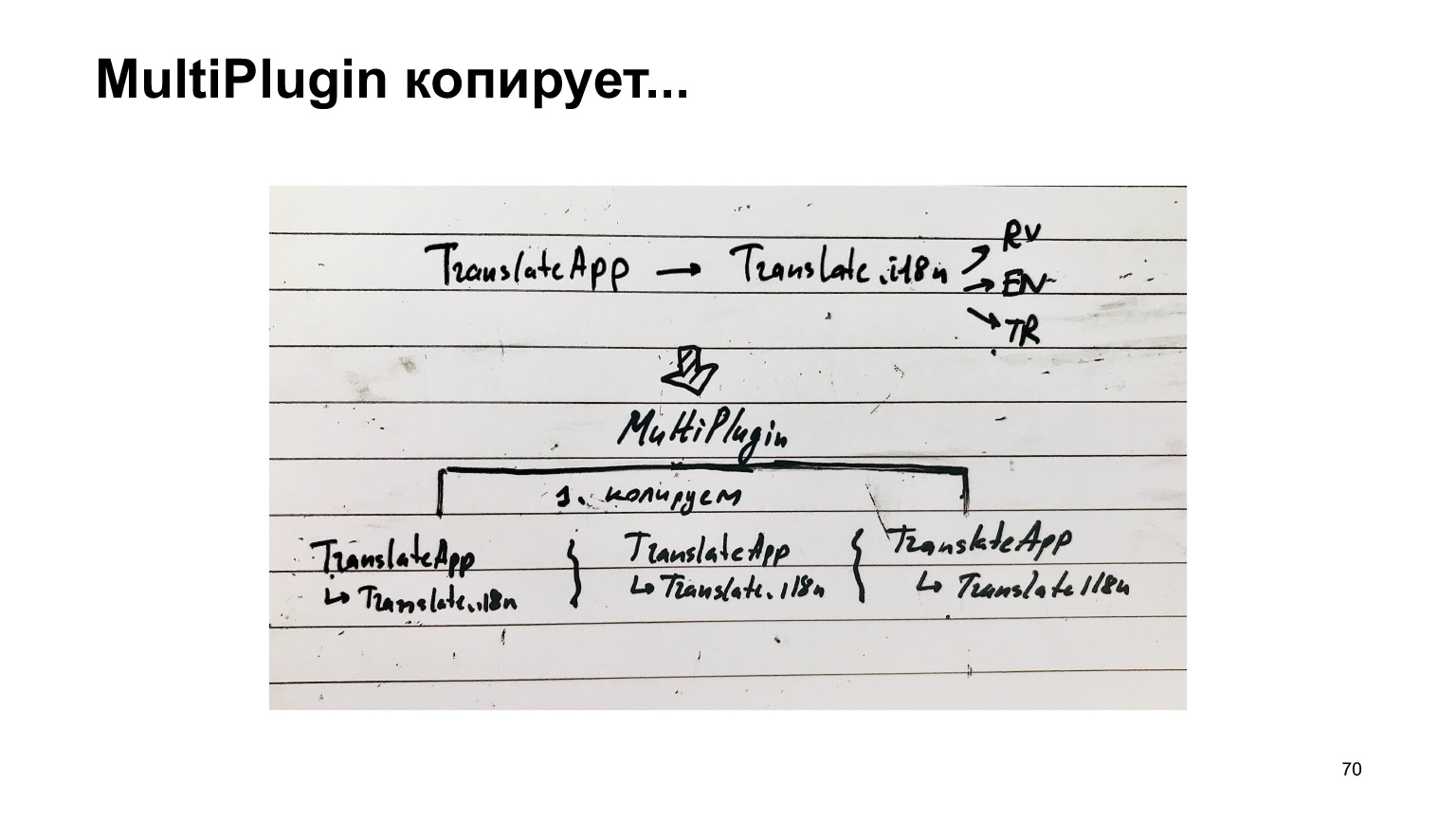
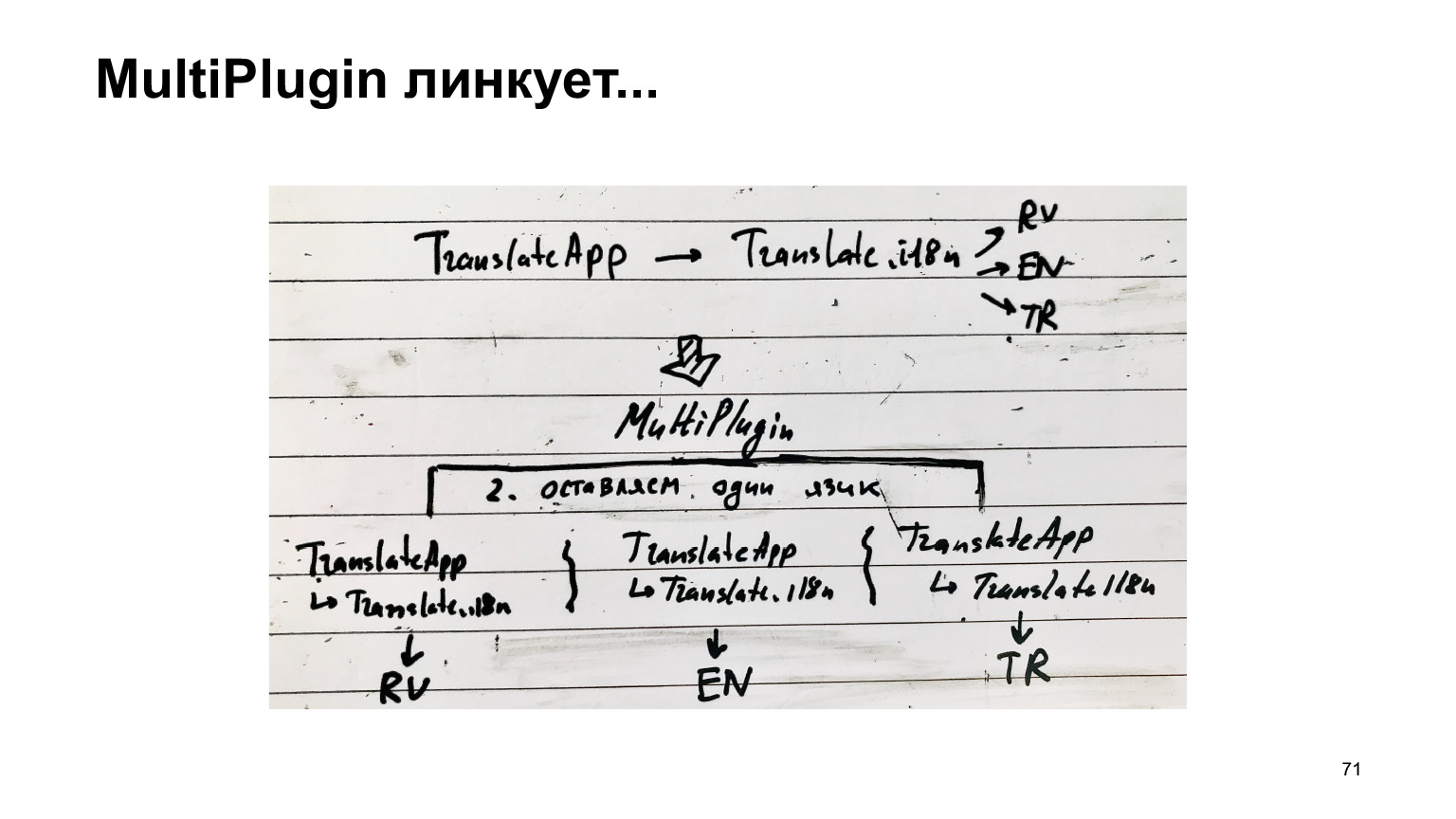
这是很长而且不可能的。我们对此做了什么?我们制作了另一个插件。我们采用相同的结构,并在即将将输出文件保存到磁盘时将自己投入到webpack的工作中。我们复制这种结构的次数要有多种语言,然后将一种语言粘合到每种语言。然后我们才创建文件。

同时,不会重复webpack绕过编译依赖项的主要工作。也就是说,我们进入了最后一个阶段,因此我们希望它会很快。

但是插件代码却变得很复杂。这实际上是我们插件的八分之一。我只是在说明这有多难。在那儿,我们经常在那里发现一些小的,令人不快的错误。但是实现它并不容易。但这很好。
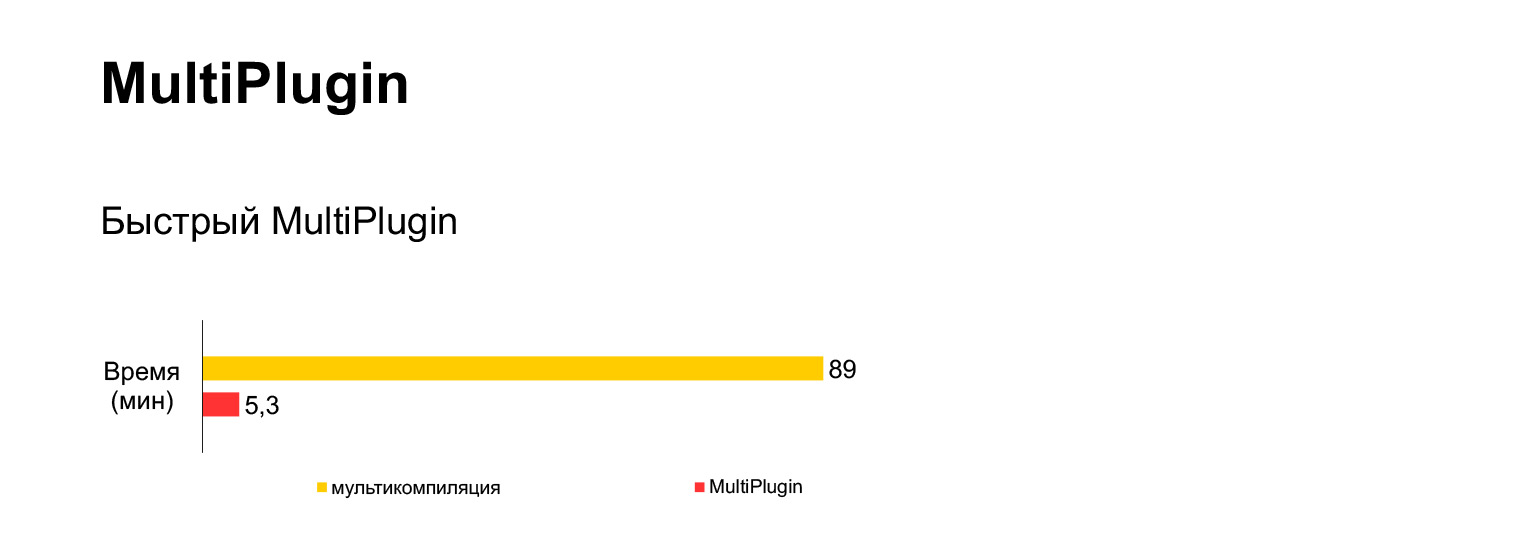
也就是说,使用这个插件可以使我们得到五分钟的组装时间,而不是一个半小时的错误。
现在交付和初始化。

交付和初始化很简单。我猜,就像在其他资源中一样,我们在不同的资源中加载什么,我们使用预加载。然后,我们包括CSS,JS,实际上是组件的HTML,并加载这些资源,但没有异步。
我们做了实验。如果使用异步,那么交互作用的开始时间将被延迟,这是我们不希望的。因此,只需在页面末尾使用预加载和加载即可。总的来说,没什么特别的。

同时,我们内联其他所有内容。也就是说,这是我们的MainChunk,我们内联了它的CSS。一般组件,样式,一般来说,幻灯片上写的所有内容,我们都会内联。这也是一系列实验,显示“内联”在首次渲染和开始交互时给出了最佳结果。
现在到数字。要谈论数字,您需要说两个关于指标的词。

我们有一个专门的速度团队,旨在使所有前端代码有效地工作。通常,这涉及服务器端模板,加载资源以及客户端上的初始化。
我们有大量的指标,这些指标从生产发送到我们的特殊日志系统。我们可以在A / B实验中控制它。我们拥有离线工具,总的来说,我们非常积极地关注这一切。
当我们在React和TypeScript中实现我们的新代码时,我们就使用了这些工具。

现在,让我们在离线工具的帮助下进行跟踪(因为我无法将使用我们所有指标的诚实在线实验组合在一起)。让我们看看如果我们从当前的当前解决方案回滚到这些关键指标上的Create React App,会发生什么。
该工具的工作非常简单。采取了一部分请求,在这种情况下,采取了具有React中功能的请求,因为尚未在React中重写所有Serp。然后轰炸我们的模板,收集测量值,将其插入一个特殊的实用程序中,该实用程序将比较并找到这些结果和指标。在这种情况下,仅保留具有统计意义的结果。总的来说,那里一切都合理。
让我们看看发生了什么。

实际上,禁用MultiPlugin会收集所有翻译,而不是仅收集所需的翻译,因此没有统计上的显着变化。
起初我有点不高兴,然后我意识到实际上这不是问题,因为现在我们没有很多功能,很多功能都翻译成React。因此,当有更多这样的功能时,这些明显的变化肯定会出现。只是现在有些功能主要在俄罗斯显示,并且没有翻译。组件中包含的代码量大大超过了翻译量。因此,所有翻译都在进行中是不可察觉的。
如果进行了诚实的实验,也许在更诚实的实验中会引起注意。但是脱机工具没有显示这些更改。

如果禁用MainChunkPlugin,则开始交互的时间将减慢,HTML加载也将减慢很多。因此,这件事很有必要。
为什么加载HTML会变慢,因为所有以前由单独的资源加载到此单独块中的代码现在都已内联到HTML中。就像我们内联所有内容,但交互性也变慢了。原则上,期望很高。
现在的问题是:如果将所有内容打包在一起,不对通用组件使用任何块,将会发生什么?事实证明,这根本不是一张幸福的图画。

第一个渲染速度大大降低。交互性也几乎翻了一番。由于所有代码开始在单独的资源中交付,因此这使HTML变得更小。但是,如您所见,交互性没有帮助。
和组装。最后一张幻灯片。
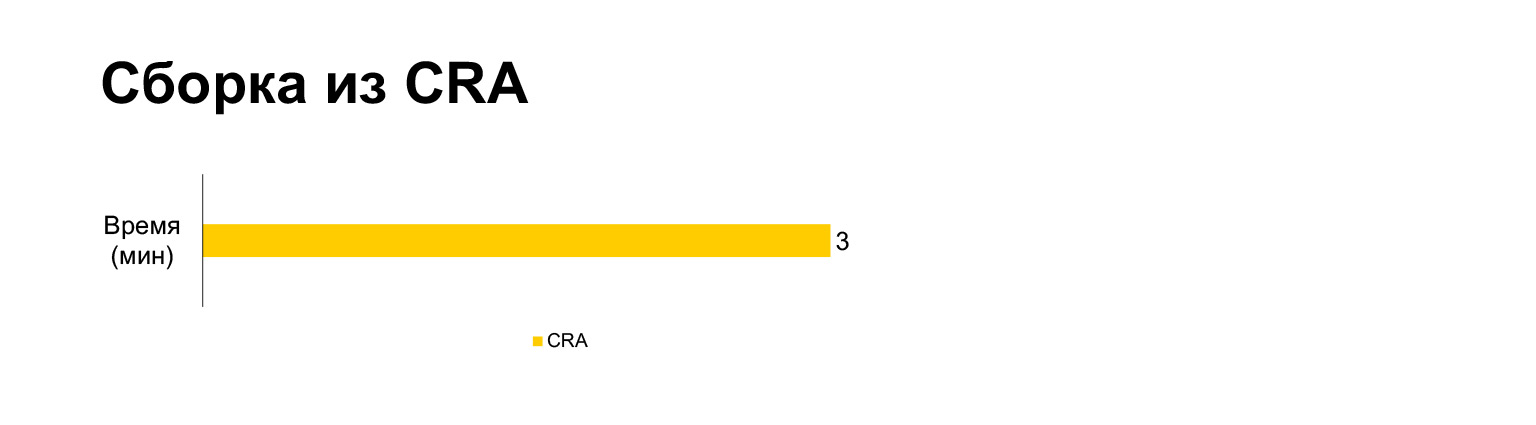
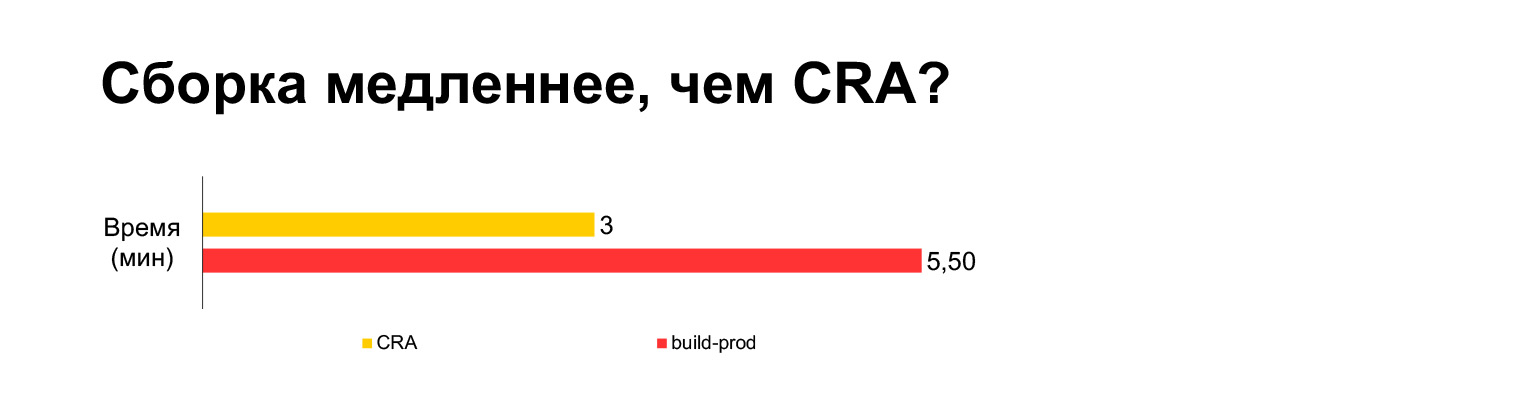
在笔记本电脑上,当前项目的Create React App生成时间需要三分钟。带着我们所有的钟声-五分钟。长?
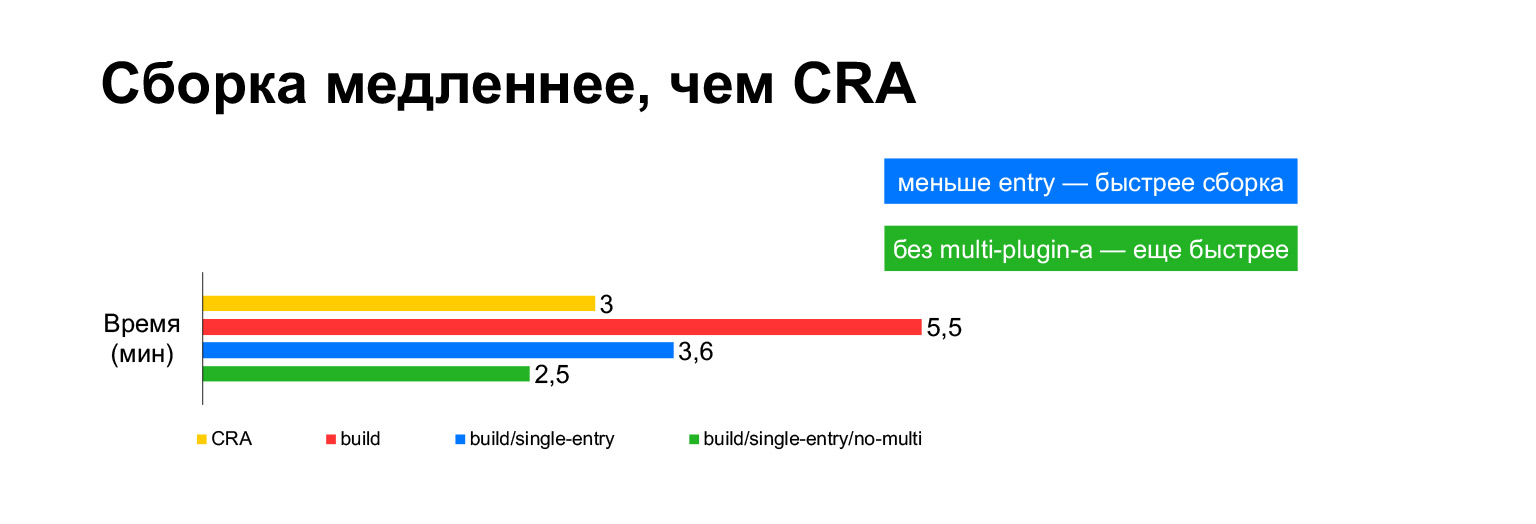
但是,实际上,如果将它们捆绑在一起,结果是三分钟。没有MultiPlugin的构建比创建React App还要快。但是正如我在前一张幻灯片中所示,我们不能拒绝对原始构建脚本的这些修改,因为如果没有这些修改,速度指标将变得非常糟糕。
现在,让我们看看从该报告中学到的有用知识。

Babel不是使用TypeScript的唯一方法。可以使用TSC,ts-node和ts-loader。效果很好。
但是,不必每次构建时都执行TypeScript检查,类型检查。这会减慢很多速度-您记得两次。因此,最好将这些东西放在单独的检查中,例如,预先提交钩子。
最好将经常使用的组件收集在一个单独的块中。还希望将公共组件收集在单独的块中,因为这允许仅加载需要的内容,仅加载差异。
最重要的是,如果没有在所有页面上使用所有代码,则需要将其拆分为单独的条目,收集单独的捆绑包,并在用户看到相应类型的搜索结果时进行加载。仅下载您需要的文件。如您所见,这将带来最大的效果。很明显的事情,但是我不确定是否每个人都这样做,因为他们仍然保留在Create React App中。
多次编译非常长。不要相信有人说多重编译是可以的,并且内部的缓存可以处理所有这些事情。使用预加载和内联也会产生结果。
关于镰刀的几个链接:
- clck.ru/PdRdh和clck.ru/PdRjb-关于在React中重写Serp的两个报告,这是第一阶段,关于我们如何进行此操作以及为什么开始这样做。第二份报告是关于我们如何从管理的角度计划和完成所有这些工作的阶段。
- clck.ru/PdRnr-报告有关我们的速度指标。它适用于那些突然想知道还有什么功能的在线工具。
谢谢大家。