
图片来自Unsplash网站。通过萨沙•故事
Scikit学习是最广泛使用的Python的机器学习的图书馆之一。其简单,标准的界面允许进行数据预处理,训练,优化和模型评估。
该项目由David Cournapeau设计,是Google夏季代码计划的一部分,于2010年发布。自成立以来,该图书馆已发展成为构建机器学习模型的丰富基础设施。新功能使您可以解决更多任务并提高可用性。在本文中,我将介绍您可能不知道的十个最有趣的功能。
1.内置数据集
在scikit-learn API中,您可以找到包含生成的数据和实际数据的嵌入式数据集。您仅需一行代码即可使用它们。如果您只是学习或想要快速测试某些东西,则此类数据非常有用。
此外,使用特殊工具,您可以自己生成用于回归
make_regression(),聚类make_blobs()和分类任务的综合数据make_classification()。
每种方法都会生成已经分解为X(特征)和Y(目标变量)的数据,以便可以将它们直接用于训练模型。
# Toy regression data set loading
from sklearn.datasets import load_boston
X,y = load_boston(return_X_y = True)
# Synthetic regresion data set loading
from sklearn.datasets import make_regression
X,y = make_regression(n_samples=10000, noise=100, random_state=0)2.访问第三方公共数据集
如果您想直接通过scikit-learn访问各种公共数据集,请查看方便的功能,该功能可让您直接从openml.org导入数据。该站点包含超过21,000个可用于机器学习项目的不同数据集。
from sklearn.datasets import fetch_openml
X,y = fetch_openml("wine", version=1, as_frame=True, return_X_y=True)3.准备用于分类基准模型的分类器
为项目创建机器学习模型时,首先创建一个基线模型是明智的。这是一个总是预测最普通类别的虚拟模型。这将为您提供基准,以对更复杂的模型进行基准测试。此外,您可以确定其工作质量,例如,它所产生的不仅仅是一组随机选择的数据。
scikit-learn库具有一个
DummyClassifier()用于分类问题和DummyRegressor()用于回归的库。
from sklearn.dummy import DummyClassifier
# Fit the model on the wine dataset and return the model score
dummy_clf = DummyClassifier(strategy="most_frequent", random_state=0)
dummy_clf.fit(X, y)
dummy_clf.score(X, y)4.自己的可视化API
Scikit-learn具有内置的可视化API,使您无需导入任何其他库即可可视化模型的工作方式。它提供以下选项:依赖图,误差矩阵,ROC曲线和Precision-Recall。
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = RandomForestClassifier(random_state=0)
clf.fit(X_train, y_train)
metrics.plot_roc_curve(clf, X_test, y_test)
plt.show()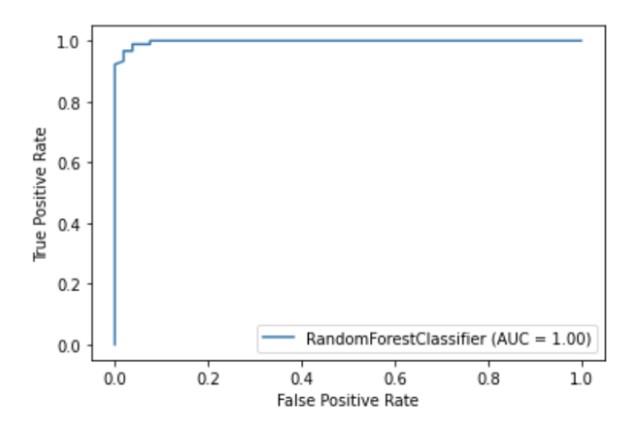
作者的插图
5.内置的特征选择方法
改善模型质量的方法之一是仅使用训练中最有用的功能,或删除信息最少的功能。此过程称为功能选择。
Scikit-learn有许多用于执行特征选择的方法,其中一种是
SelectPercentile()。此方法根据指定的统计估计方法选择信息最丰富的特征的X百分位数。
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectPercentile, chi2
X,y = load_wine(return_X_y = True)
X_trasformed = SelectPercentile(chi2, percentile=60).fit_transform(X, y)6.机器学习过程中连接各个阶段的管道
除了能够使用大量的机器学习算法之外,scikit-learn还提供了许多用于预处理和数据转换的功能。为了确保在scikit-learn中的机器学习过程中的可重复性和可访问性,创建了Pipeline,它将训练模型的不同步骤和预处理阶段结合在一起。
管道将工作流的所有阶段存储为单个对象,可以由fit和预测方法调用。在管道对象上运行fit方法时,将自动执行预处理和模型训练步骤。
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Chain together scaling the variables with the model
pipe = Pipeline([('scaler', StandardScaler()), ('rf', RandomForestClassifier())])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)7. ColumnTransformer可以针对不同功能更改不同的预处理方法
许多数据集包含不同类型的要素,这需要几个不同的阶段进行预处理。例如,您可能会遇到分类数据和数字数据的混合,并且可能要缩放数字列,并使用一键编码将分类特征转换为数字。
scikit-learn管道配备了ColumnTransformer函数,该函数使您可以通过建立索引或指定列名来轻松指示特定列的最合适的预处理方法。
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))8.轻松获取管道的HTML图像
管道通常会变得非常复杂,尤其是在处理真实数据时。因此,使用scikit-learn显示管道步骤的HTML图非常方便。
from sklearn import set_config
set_config(display='diagram')
lr
作者的插图
9.绘图功能,可视化决策树
该功能
plot_tree()允许您创建决策树模型中存在的步骤的概述。
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
plt.show()10.许多扩展scikit-learn功能的第三方库
有许多与scikit-learn兼容并扩展它们的第三方库。
例如,Category Encoders库(可为分类特征提供更多选择的预处理方法)或ELI5库(可用于更详细的模型解释)。
两种资源也可以通过scikit-learn管道直接访问。
# Pipeline using Weight of Evidence transformer from category encoders
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import category_encoders as ce
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('woe', ce.woe.WOEEncoder())])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))感谢您的关注!