激励方式
计算机视觉任务的普遍接受的方法是将图像用作3D数组(高度,宽度,通道数)并对其进行卷积。这种方法有几个缺点:
- 并非所有像素都相等。例如,如果我们有一个分类任务,那么对象本身对我们来说比背景重要。有趣的是,作者并未说Attention已经在计算机视觉任务中使用。
- 对于相距较远的像素,卷积效果不佳。有些方法具有卷积膨胀和全局平均池,但是它们本身并不能解决问题。
- 在非常深的神经网络中,卷积效率不够。
结果,作者提出以下建议:将图像转换为某种视觉标记,并将其提交给转换器。

- 首先,使用常规主干来获取特征图
- 接下来,将特征图转换为可视标记
- 令牌被馈送到变压器
- 变压器输出可用于分类问题
- 而且,如果将变压器的输出与特征图结合起来,则可以得到分段任务的预测
在类似方向的作品中,作者仍然提到Attention,但是请注意,通常将Attention应用于像素,因此,它大大增加了计算复杂度。他们还谈论提高神经网络效率的工作,但他们认为,近年来,它们提供的改进越来越少,因此必须寻求其他方法。
视觉变压器
现在,让我们仔细看看模型是如何工作的。
如上所述,主干获取特征图,并将它们传递到可视转换器层。
每个视觉转换器都由三部分组成:标记器,转换器和投影仪。
分词器

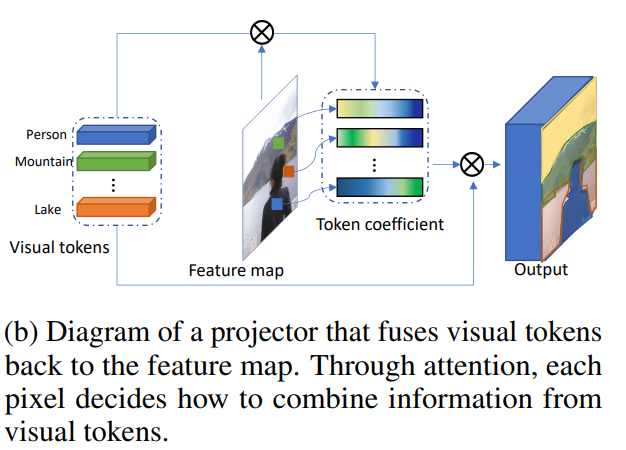
令牌生成器检索可视令牌。实际上,我们使用一个特征图,在(H * W,C)中进行重塑,然后从中获得

标记。标记系数的可视化如下所示:

位置编码
通常,转换器不仅需要令牌,还需要有关其位置的信息。

首先,我们进行下采样,然后乘以训练权重并与标记连接。要调整通道数,可以添加一维卷积。
变压器
最后是变压器本身。

结合视觉标记和功能图
这就是投影仪。

动态令牌化
在转换器的第一层之后,我们不仅可以提取新的视觉标记,还可以使用从先前步骤中提取的那些视觉标记。经过训练的权重用于组合它们:

使用视觉转换器构建计算机视觉模型
此外,作者描述了该模型如何应用于计算机视觉问题。变压器块具有三个超参数:特征图C中的通道数,可视标记Ct中的通道数和可视标记L
的数量。如果在模型的各个块之间转换时通道数被认为是不合适的,则使用1D和2D卷积来获得所需的通道数。
为了加快计算速度并减小模型的大小,请使用组卷积。
作者在文章中附加了**伪代码**块。完整的代码有望在将来发布。
图片分类
我们采用ResNet并在此基础上创建可视变压器ResNet(VT-ResNet)。
我们离开了阶段1-4,但是我们没有放置最后的阶段,而是放置了视觉变形器。
骨干出口-14 x 14功能图,取决于VT-ResNet深度的通道数512或1024。从特征图中创建了1024个通道的8个可视标记。变压器的输出到达顶部进行分类。

语义分割
对于此任务,将全景特征金字塔网络(FPN)作为基本模型。
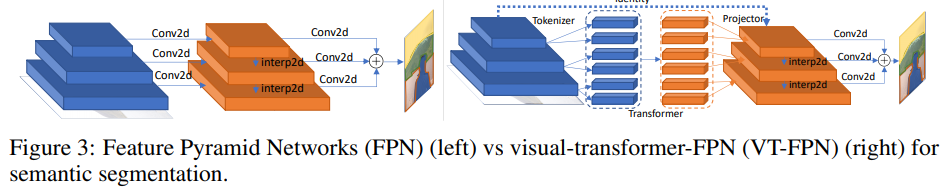
在FPN中,卷积在高分辨率图像上起作用,因此模型很重。作者用视觉转换器代替了这些操作。同样,有8个令牌和1024个通道。
实验
ImageNet分类
使用RMSProp训练400个纪元。他们以0.01的学习率开始,在5个预热阶段增加到0.16,然后将每个阶段乘以0.9875。使用批次归一化和批次大小2048,标签平滑,自动增减,随机深度生存概率0.9,落差0.2,EMA 0.99985。
这是我为了找到所有这些结果而必须进行的实验...
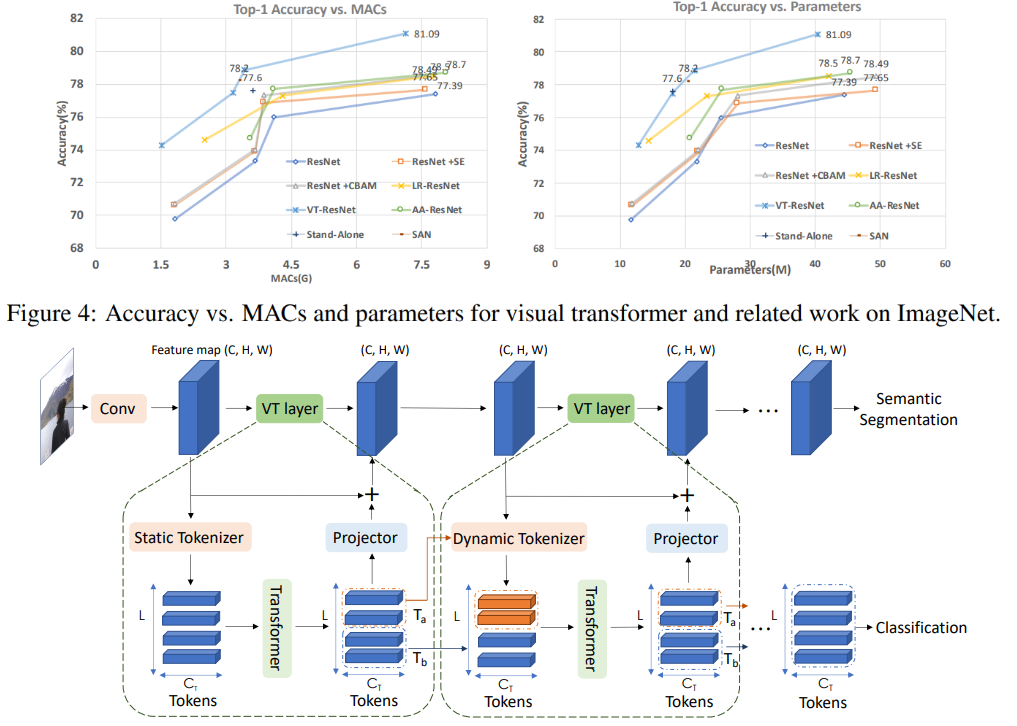
在此图上,您可以看到该方法在减少计算数量和模型大小的情况下提供了更高的质量。
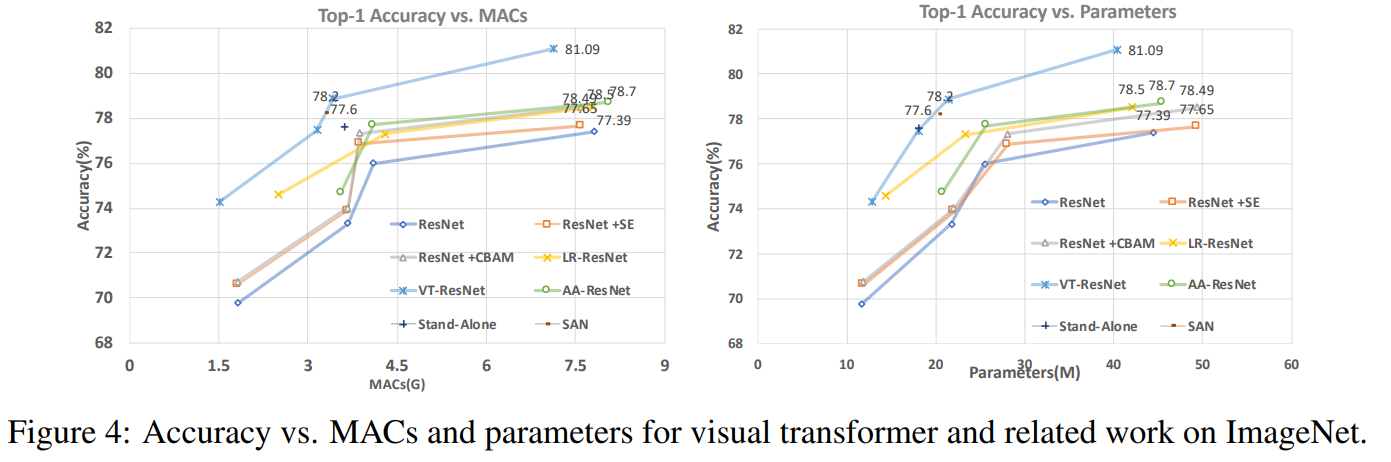
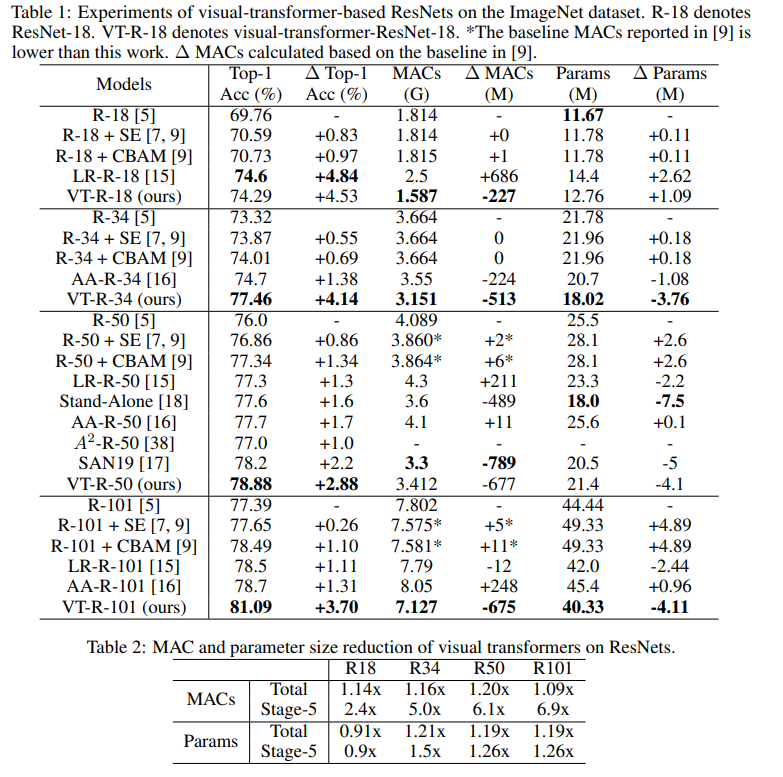
比较模型的文章标题:
ResNet + CBAM-卷积块注意模块ResNet + SE-
压缩和激励网络
LR-ResNet-用于图像识别的本地关系网络
StandAlone-视觉模型中的独立自我注意力
AA-ResNet-注意力增强卷积网络
SAN-探索用于图像识别的自我注意力
消融研究
为了加快实验速度,我们采用了VT-ResNet- {18,34}并训练了90个纪元。
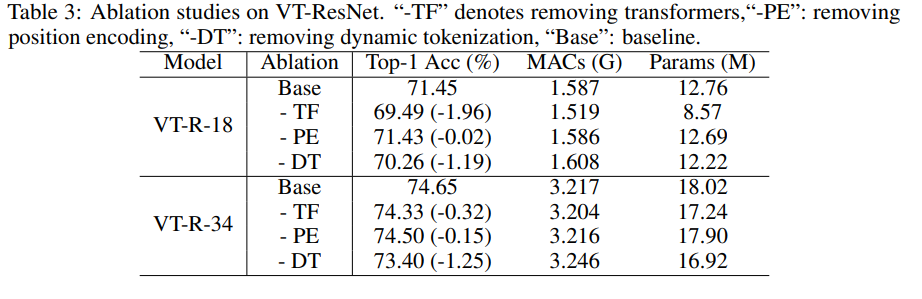
使用变压器而不是卷积会获得最大的收益。动态令牌化而不是静态令牌化也大大提高了性能。位置编码仅稍有改善。
细分结果

如您所见,该指标仅增长了一点,但是该模型消耗的MAC减少了6.5倍。
该方法的潜在未来
实验表明,该方法可以创建效率更高的模型(就计算成本而言),同时可以实现更高的质量。拟议的架构成功地完成了计算机视觉的各种任务,并希望其应用将有助于改善使用计算机视觉的系统-AR / VR,自动驾驶汽车等。
该评论由MTS的主要开发者Andrey Lukyanenko编写。