我想分享在我们公司中实现时尚神经网络的经验。当我们决定建立自己的服务台时,一切就开始了。为什么以及为什么要自己阅读,您可以阅读我的同事Alexei Volkov(脸)在这里。
我将向您介绍系统的最新创新:一个神经网络,可帮助调度员获得第一线的支持。如果有兴趣,欢迎来猫。

澄清任务
对于任何支持调度员来说,头疼都是迅速决定分配给传入的客户请求。以下是请求:
下午好。
我的理解正确:为了将日历共享给特定用户,您需要在要共享日历的用户的PC上打开对日历的访问权限,然后输入要授予访问权限的用户的邮件?
根据规定,调度员必须在两分钟内做出响应:注册申请,确定紧急程度并任命负责单位。调度员从公司的44个部门中进行选择。
调度员的说明描述了大多数常见查询的解决方案。例如,提供对数据中心的访问是一个简单的请求。但是服务请求包括许多任务:安装软件,分析情况或网络活动,找出解决方案账单的详细信息,检查各种访问权限。有时很难从负责人向谁发送问题的请求中理解:
Hi Team,
The sites were down again for few minutes from 2020-07-15 14:59:53 to 2020-07-15 15:12:50 (UTC time zone), now they are working fine. Could you please check and let us know why the sites are fluctuating many times.
Thanks
在某些情况下,应用程序转到了错误的部门。该请求已被处理,然后重新分配给其他执行者或发送回调度程序。这提高了解决方案的速度。解决请求的时间写在与客户的协议(SLA)中,我们有责任在截止日期之前完成。
在系统内部,我们决定为调度员创建助手。主要目标是添加提示,以帮助员工更快地对应用程序做出决定。
最重要的是,我不想屈服于新奇的趋势,而将聊天机器人置于第一线的支持。如果您曾经尝试写信给这种技术支持人员(他们对此并没有犯错),那么您就会明白我的意思。
首先,他对您的理解很差,根本不回答非典型要求,其次,很难找到一个活着的人。
总的来说,我们绝对不打算用聊天机器人代替调度员,因为我们希望客户仍然与现场人员进行交流。
起初,我想到了便宜又开朗的尝试,并尝试了关键字方法。我们手动编译了一个关键字词典,但这还不够。该解决方案仅适用于简单的应用程序,没有问题。
在我们的服务台工作期间,我们积累了坚实的请求历史记录,在此基础上,我们可以识别出类似的传入请求并将其立即分配给正确的执行者。武装了Google一段时间后,我决定更深入地研究自己的选择。
学习理论
原来,我的任务是经典分类任务。在输入处,该算法接收应用程序的原始文本,在输出处,该算法将其分配给先前已知的类之一-即公司的部门。
有很多解决方案。这是一个“神经网络”,一个“朴素贝叶斯分类器”,“最近邻居”,“逻辑回归”,“决策树”,“提升”以及许多其他选项。
没有时间尝试所有技术。因此,我选择了神经网络(我一直想尝试使用它们)。后来证明,这种选择是完全合理的。
因此,我从这里开始潜入神经网络。研究学习算法神经网络:有老师(监督学习),没有老师(无监督学习),有老师的部分参与(半监督学习)或“强化学习”。
作为我任务的一部分,提出了与老师一起教书的方法。有足够的数据用于培训:超过10万个已解决的应用程序。
选择实施
我选择了Encog机器学习框架库进行实施。它带有示例的可访问且易于理解的文档。此外,Java的实现也离我很近。
简而言之,工作机制如下所示:
- 神经网络的框架是预先配置的:通过突触连接连接的多层神经元。

- 具有预定结果的一组训练数据被加载到存储器中。
- . «». «» .
- «» : , , .
- 3 4 . , . , - .
我尝试了该框架的各种示例,但我意识到该库可以应对输入中带有数字的数字。因此,根据碗和花瓣的大小(Fisher's Irises)定义一类鸢尾花的例子效果很好。 但是我有一些文字。这意味着字母必须以某种方式转换为数字。因此,我进入了第一个准备阶段-“矢量化”。
矢量化的第一种选择:按字母
将文本转换为数字的最简单方法是将字母放在神经网络的第一层。结果是33个字母神经元:ABVGDEOZHZYKLMNOPRSTUFHTSCHSHSCHYEYUYA。
每个字母都分配有一个数字:单词中字母的存在被视为1,而字母的缺失被视为零。
然后,该编码中的单词“ hello”将具有一个向量:

这样的向量已经可以提供给神经网络进行训练了。毕竟,这个数字是001001000100000011010000000000000 = 1216454656深入研究
理论之后,我意识到分析字母没有特殊之处。它们没有任何语义含义。例如,提案的每个文本中都将包含字母“ A”。考虑到该神经元始终处于打开状态,不会对结果产生任何影响。像所有其他元音一样。在应用程序的文本中,将有大多数字母。此选项不合适。
向量化的第二种变体:按字典
如果您不接受字母,但接受单词呢?假设达尔的解释词典。并将单词中存在的单词计数为1,将单词不存在的计数为0。
但是在这里,我遇到了单词数。向量将变得非常大。具有200k输入神经元的神经元将花费很多时间,并且将需要大量的内存和CPU时间。您必须制作自己的字典。另外,弗拉基米尔·伊万诺维奇·达尔(Vladimir Ivanovich Dal)不了解其文字中的IT特定性。
我再次转向理论。为了缩短处理文本时的词汇量,请使用N-gram的机制-N个元素的序列。
想法是将输入文本分为几个部分,从中组成字典,然后将原始文本中是否存在短语作为1或0馈入神经网络。也就是说,代替字母(例如字母),不仅字母,而且整个短语都将被视为0或1。
最受欢迎的是单字组,双字组和三字组。以短语“欢迎使用DataLine”为例,我将向您介绍每种方法。
- Unigram-文本分为单词:“ good”,“ welcome”,“ v”,“ DataLine”。
- Bigram-我们将其分为成对的单词:“ welcome”,“ welcome to”,“ to DataLine”。
- Trigram-同样,每个词3个:“ welcome to”,“ welcome to DataLine”。
- N克-您明白了。多少N,连续多少字。
- N-. , . 4- N- : «»,« », «», «» . . .
我决定将自己限制在unigram。但是,不仅是一个会标,而且事实证明,这个词仍然太多了。 “ Porter's Stemmer”算法
应运而生,早在1980年就被用于统一单词。
该算法的本质:从单词中删除后缀和结尾,仅保留基本的语义部分。例如,单词“重要”,“重要”,“重要”,“重要”,“重要”,“重要”被带到基础“重要”。也就是说,词典中将只有6个单词,而不是6个单词。这是一个显着的减少。
另外,我从字典中删除了所有数字,标点符号,介词和稀有单词,以免造成“噪音”。结果,对于100k文本,我们得到了一个3k单词的字典。您已经可以使用此功能。
神经网络训练
所以我已经有:
- 3k单词字典。
- 矢量化的字典表示形式。
- 神经网络的输入和输出层的大小。根据该理论,在第一层(输入)上提供了一个字典,而最后一层(输出)是解决方案类的数量。我有44个-按公司部门的数量。
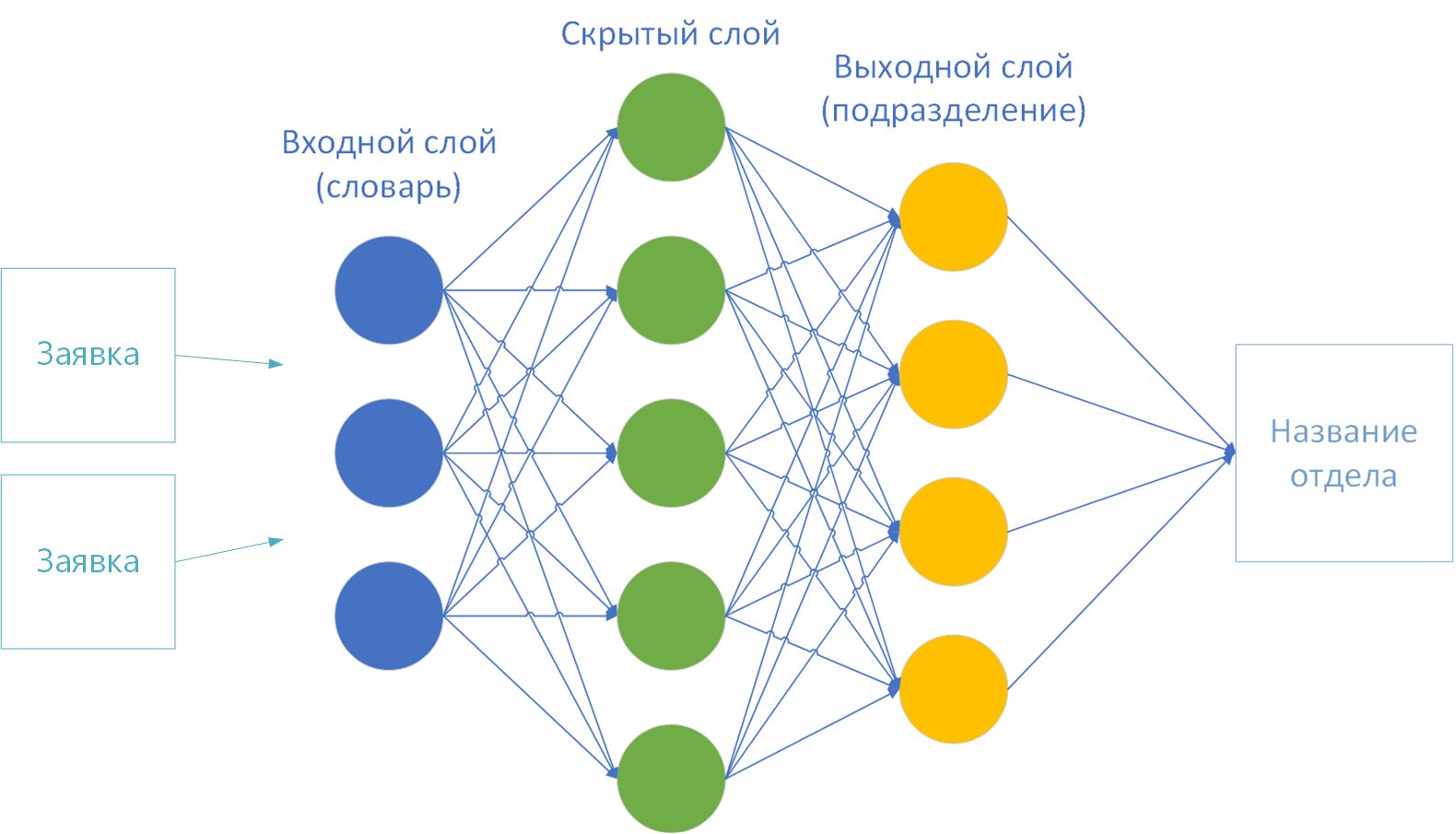
要训练神经网络,几乎没有什么选择:
- 教学法。
- 激活功能。
- 隐藏层数。
我如何选择参数。始终根据经验为每个特定任务选择参数。这是最长且最乏味的过程,因为它需要大量的实验。
因此,我获取了11k应用程序的参考样本,并使用各种参数进行了神经网络的计算:
- 在10k时,我训练了一个神经网络。
- 在1k时,我检查了已经训练好的网络。
也就是说,以10k的速度建立词汇并学习。然后我们展示训练有素的神经网络1k未知文本。结果是错误的百分比:猜测单位与文本总数的比率。
结果,我对未知数据的准确性达到了约70%。
根据经验,我发现如果选择了错误的参数,训练可以无限期地继续。几次,神经元进入了一个无休止的计算周期,并把工作机器挂了一夜。为了防止这种情况,我自己接受了100次迭代的限制,或者直到网络错误停止减少为止。
这里是最终参数:
教学方法。 Encog提供多种选择:反向传播,ManhattanPropagation,QuickPropagation,ResilientPropagation,ScaledConjugateGradient。
这些是确定突触权重的不同方法。有些方法工作更快,有些更精确,最好在文档中阅读更多。弹性传播对我来说效果很好。
激活功能。需要根据输入和阈值的加权和的结果来确定输出处的神经元的值。
我从16个选项中进行选择。我没有足够的时间检查所有功能。因此,我认为是最受欢迎的:各种实现中的S形和双曲线正切。
最后,我选择了ActivationSigmoid。
隐藏层数... 从理论上讲,隐藏层越多,计算的时间就越长,难度就越大。我从一层开始:计算很快,但是结果不准确。我选择了两个隐藏层。对于三层,它被认为更长了,结果与两层的结果没有太大的不同。
在此我完成了实验。您可以准备生产工具。
来生产!
进一步的技术问题。
- 我搞砸了Spark,以便可以通过REST与神经元通信。
- 指导将计算结果保存到文件中。并非每次重新启动服务时都要重新计算。
- 添加了直接从服务台读取实际数据以进行培训的功能。以前对csv文件进行过培训。
- 添加了重新计算神经网络的功能,以将重新计算附加到调度程序。
- 将所有东西收集在一个厚罐中。
- 我问我的同事,要有比开发机器功能更强大的服务器。
- Zaploil和zadulil每周重算一次。
- 我将按钮固定在服务台中的正确位置,并写信给同事们如何使用这个奇迹。
- 我收集了有关神经元选择和人选择了什么的统计信息(以下统计信息)。
这就是测试应用程序的样子:
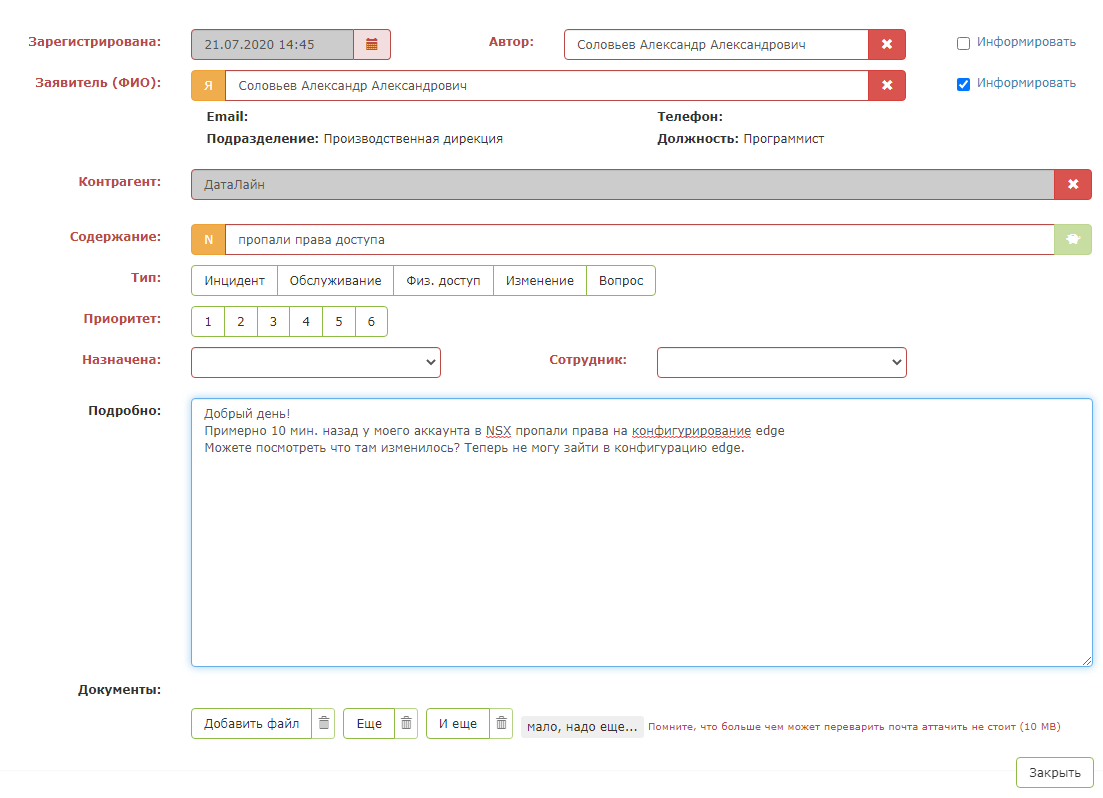
但是,一旦按下“神奇的绿色按钮”,就会发生神奇的事情:卡中的字段被填满。调度程序仍然需要确保系统正确提示并保存请求。
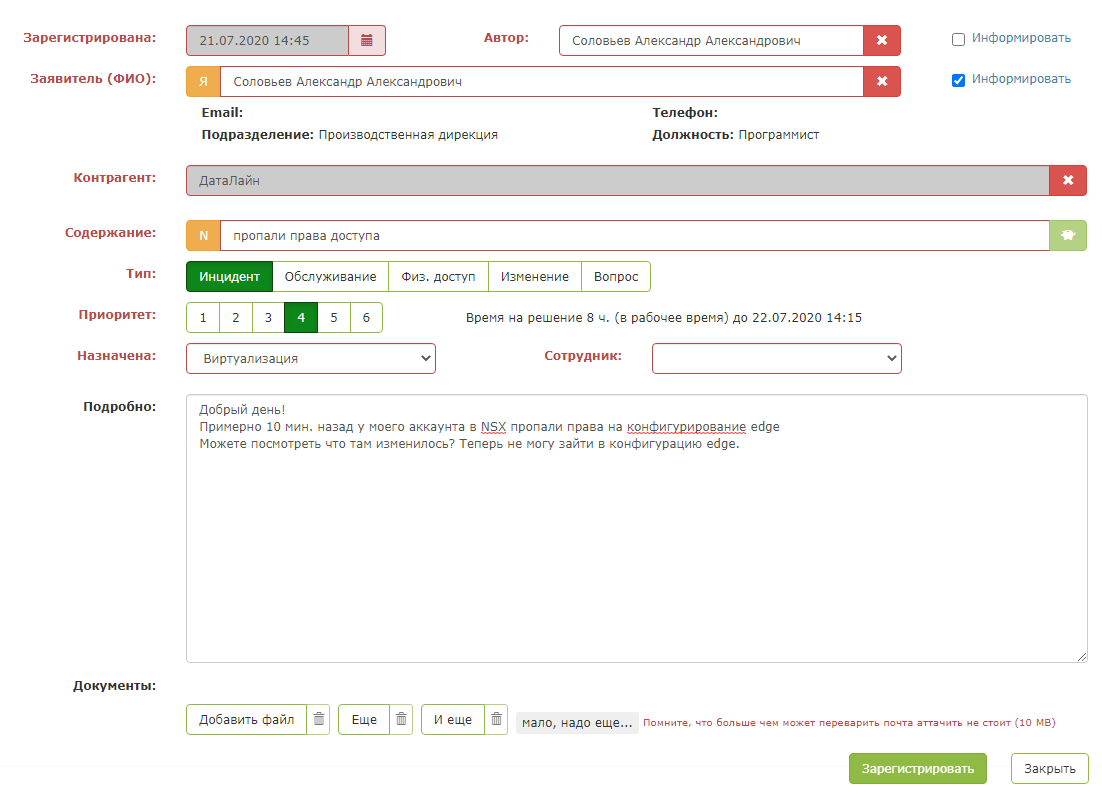
结果是调度员的智能助手。
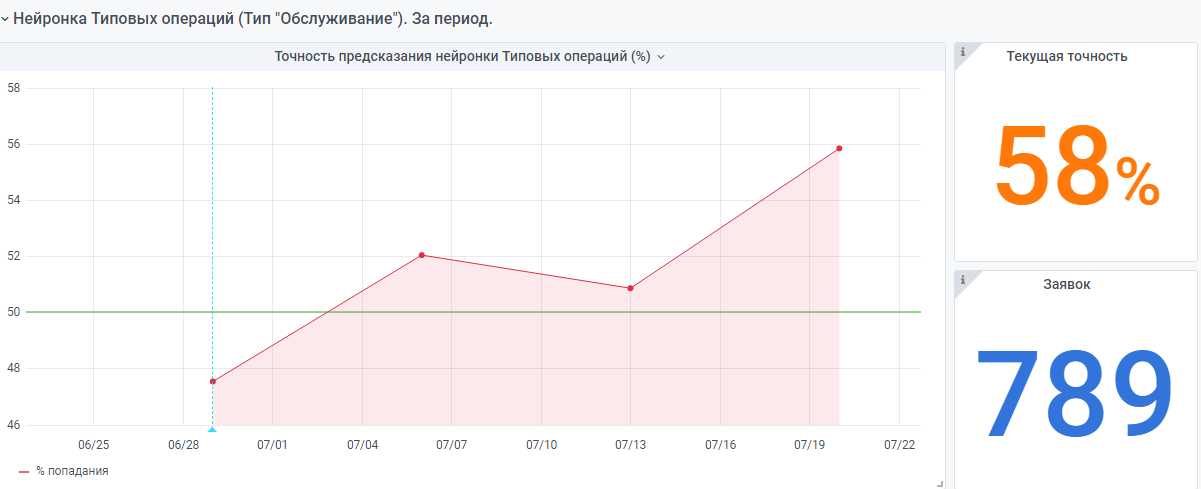
例如,从年初开始统计。
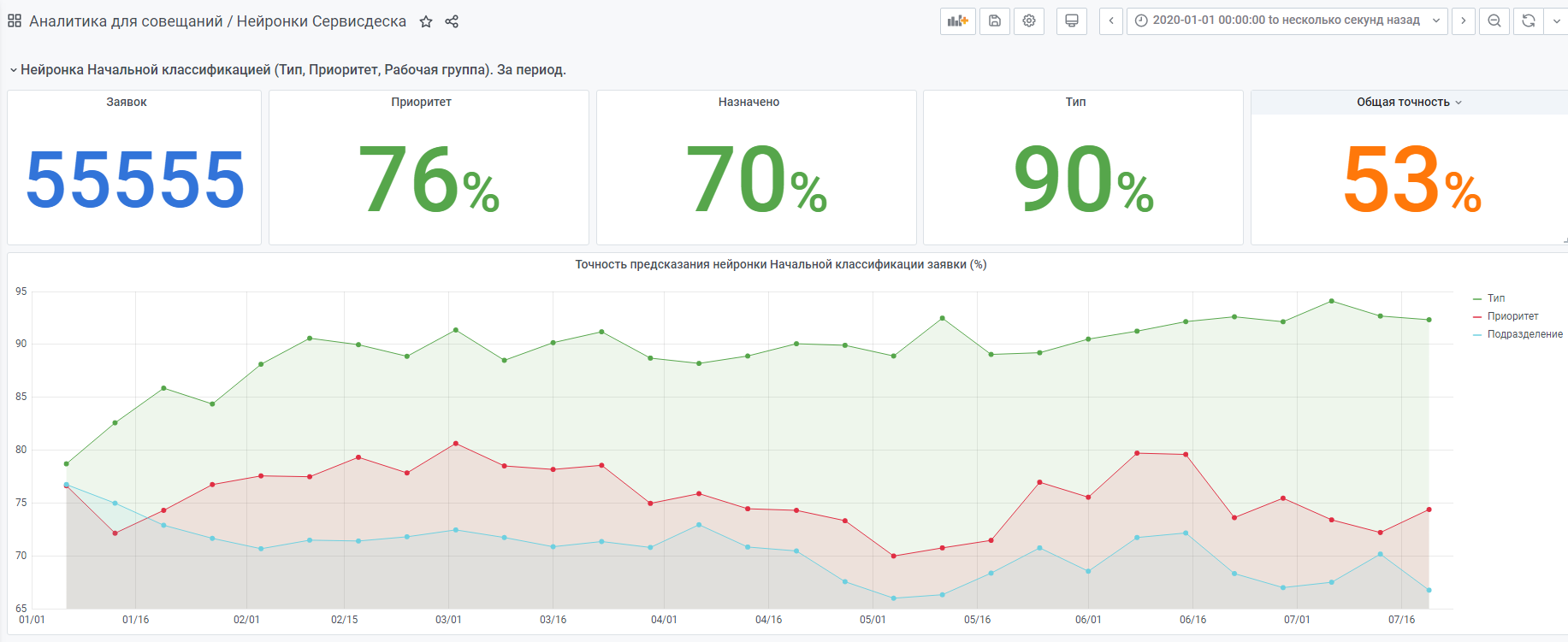
根据同样的原理,还有一个“非常年轻”的神经网络。但是数据仍然很少,她仍然在积累经验。
如果我的经验能帮助某人创建自己的神经网络,我将感到很高兴。
如果您有任何疑问,我将很乐意回答。