-简而言之,我们会有什么计划?首先,我们将讨论为什么要学习Python。然后,让我们看看CPython解释器如何更深入地工作,如何管理内存,Python中的类型系统如何工作,字典,生成器和异常。我认为大约需要一个小时。
为什么选择Python?
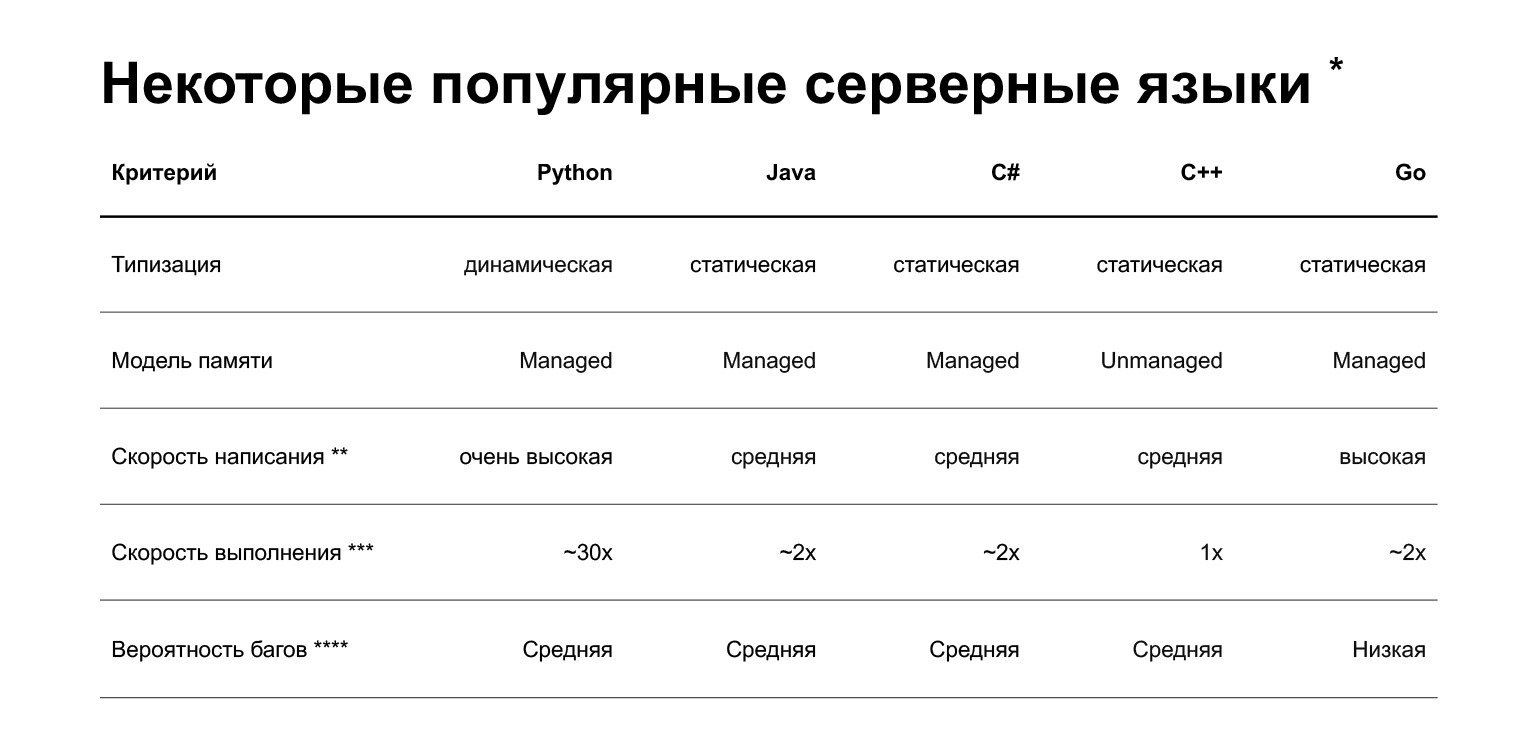
* Insights.stackoverflow.com/survey/2019
**非常主观
***研究
解释****研究解释
让我们开始吧。为什么选择Python?幻灯片显示了后端开发中当前使用的几种语言的比较。简而言之,Python有什么优势?您可以在上面快速编写代码。当然,这是非常主观的-编写出色的C ++或Go的人可以对此进行争论。但是平均而言,用Python编写的速度更快。
缺点是什么?第一个可能也是主要的缺点是Python较慢。它可能比其他语言慢30倍,这是有关此主题的一项研究。但是它的速度取决于任务。有两类任务:
-CPU绑定,CPU绑定任务,CPU绑定。
-I / O绑定,任务受输入输出限制:通过网络还是在数据库中。
如果您正在解决CPU受限的问题,那么可以,Python会慢一些。如果I / O是绑定的,并且这是一大类任务,那么要了解执行速度,您需要运行基准测试。也许将Python与其他语言进行比较,您甚至不会注意到性能差异。
另外,Python是动态类型的:解释器在编译时不检查类型。在版本3.5中,出现了类型提示,使您可以静态地指定类型,但是它们不是很严格。也就是说,您将在生产中而不是在编译阶段捕获一些已经存在的错误。后端的其他流行语言-Java,C#,C ++,Go-具有静态类型:如果您在代码中传递了错误的对象,则编译器会通知您。
更深入地说,Python如何在出租车产品开发中使用?我们正在朝着微服务架构迈进。我们已经有160个微服务,即杂货店-35个,其中15个使用Python,20个-加号。也就是说,我们现在仅使用Python或plus编写代码。
我们如何选择语言?首先是负载需求,也就是说,我们看看Python是否可以处理它。如果他愿意,那么我们将研究团队开发人员的能力。
现在我想谈谈口译员。CPython如何工作?
口译设备
可能会出现问题:为什么我们需要知道口译员的工作方式。这个问题是有效的。您可以轻松编写服务,而无需了解幕后花絮。答案可能如下:
1.优化高负载。假设您有一个Python服务。它有效,负载低。但是有一天,任务就来了-写一支笔,准备承受沉重的负担。您无法摆脱这一点,也无法用C ++重写整个服务。因此,您需要针对高负载优化服务。了解口译员的工作方式将对此有所帮助。
2.调试复杂的案例。假设服务正在运行,但是内存开始“泄漏”。在Yandex.Taxi,我们最近才遇到这样的案例。该服务每小时消耗8 GB的内存并崩溃。我们需要弄清楚。关于语言,Python。需要了解内存管理在Python中如何工作的知识。
3.如果要编写复杂的库或复杂的代码,这很有用。
4.总体而言,了解您正在使用的工具而不是仅仅作为用户,这是一种很好的形式。 Yandex对此表示赞赏。
5.他们在面试中询问有关此问题,但这不是重点,而是您的总体IT前景。

让我们简要回顾一下什么类型的翻译器。我们有编译器和解释器。您可能知道,编译器是将源代码直接转换为机器代码的东西。相反,解释器首先将其转换为字节码,然后执行它。 Python是一种解释型语言。
字节码是从原始代码中获得的一种中间代码。它不受平台约束,可以在虚拟机上运行。为什么是虚拟的?这不是真正的汽车,而是某种抽象。

有哪些类型的虚拟机?注册并堆叠。但是在这里我们必须记住的不是Python,而是Python是一个堆栈计算机。接下来,我们将看到堆栈是如何工作的。
还有一个警告:这里我们只讨论CPython。 CPython是参考Python实现,正如您可能猜到的那样,用C编写。用作同义词:当我们谈论Python时,我们通常谈论CPython。
但是,还有其他口译员。有PyPy,它使用JIT编译,速度提高了大约五倍。很少使用。老实说我没见过。有JPython,有IronPython,它可以为Java虚拟机和Dotnet机器转换字节码。这超出了今天的演讲范围-老实说,我还没有遇到过。因此,让我们看一下CPython。

让我们看看发生了什么。您有一个源,一行,要执行它。口译员做什么?字符串只是字符的集合。为了对其进行有意义的处理,首先需要将代码转换为令牌。令牌是一组字符,标识符,数字或某种迭代形式的分组。实际上,解释器将代码转换为令牌。

此外,从这些标记构建了抽象语法树AST。另外,请不要担心,这些只是其中的一些树,您可以在这些树上进行操作。假设在我们的例子中有BinOp,一个二进制操作。运算-求幂,运算数:要提高的数字和提高的能力。
此外,您已经可以使用这些树来构建一些代码。我错过了很多步骤,还有一个优化步骤,其他步骤。然后将这些语法树转换为字节码。
让我们在这里更详细地了解。顾名思义,字节码是由字节组成的代码。在Python中,从3.6开始,字节码是两个字节。

第一个字节是运算符本身,称为操作码。第二个字节是oparg参数。看来我们是从上面来的。也就是说,一个字节序列。但是Python在Disassembler中有一个名为dis的模块,通过它我们可以看到更易于理解的表示形式。
它是什么样子的?源的行号-最左边的行号。第二列是地址。就像我说的那样,Python 3.6中的字节码占用两个字节,因此所有地址都是偶数,我们看到的
是0、2、4 ... Load.name,Load.const-这些都是代码选项本身,也就是说,这些操作的代码Python应该执行。 0、0、1、1是oparg,即这些操作的参数。接下来看它们如何完成。
(...)让我们看看字节码是如何在Python中执行的,它有什么结构。

如果您不知道C,那就没关系。脚注仅供一般理解。
Python有两种结构可以帮助我们执行字节码。第一个是CodeObject,您可以查看其摘要。实际上,结构较大。这是没有上下文的代码。这意味着该结构实际上包含我们刚刚看到的字节码。如果函数包含对常量的引用,常量的名称等,则它包含此函数中使用的变量的名称。

下一个结构是FrameObject。这已经是执行上下文,即已经包含变量值的结构。引用全局变量;执行栈,稍后再讨论,还有许多其他信息。假设指令执行的次数。
例如:如果您想多次调用一个函数,那么您将拥有相同的CodeObject,并且将为每次调用创建一个新的FrameObject。它会有自己的参数,自己的堆栈。因此它们是相互联系的。

什么是主解释器循环,字节码如何执行?您看到我们有了oparg的这些操作码列表。这是怎么做的?像任何解释器一样,Python都有一个执行该字节码的循环。也就是说,一帧进入它,Python只是按顺序遍历字节码,查看它是哪种oparg,然后使用一个巨大的开关进入其处理程序。例如,此处仅显示一个操作码。例如,我们在这里有一个二进制减法,即一个二进制减法,假设将在该位置执行“ AB”。
让我们解释一下二进制减法的工作原理。很简单,这是最简单的代码之一。 TOP函数从堆栈中获取最高值,从最高值中弹出该值,而不仅仅是将其弹出堆栈,然后调用PyNumber_Subtract函数。结果:斜杠SET_TOP函数被推回堆栈。如果不清楚堆栈,下面将举一个示例。

关于GIL的简要介绍。 GIL是Python中的进程级互斥量,它在主解释器循环中采用此互斥量。然后,字节码才开始执行。这样做是为了一次仅一个线程在执行字节码,以保护解释器的内部结构。
进一步说,Python中的所有对象都有许多对它们的引用。如果两个线程更改了此链接数,则解释器将中断。因此,有一个GIL。在异步编程
的讲座中将告诉您这一点。这对您有多重要?不使用多线程,因为即使您创建多个线程,那么通常您将只运行其中一个,字节码将在其中一个线程中执行。因此,请使用多处理程序或sish扩展程序或其他方法。

一个简短的例子。您可以从Python安全地探索此框架。有一个带下划线功能get_frame的sys模块。您可以得到一个框架,看看那里有什么变量。有一条指令。这更多用于教学,在现实生活中我没有使用它。
让我们尝试看看Python虚拟机堆栈如何工作以进行理解。我们有一些非常简单的代码,它不了解它的作用。
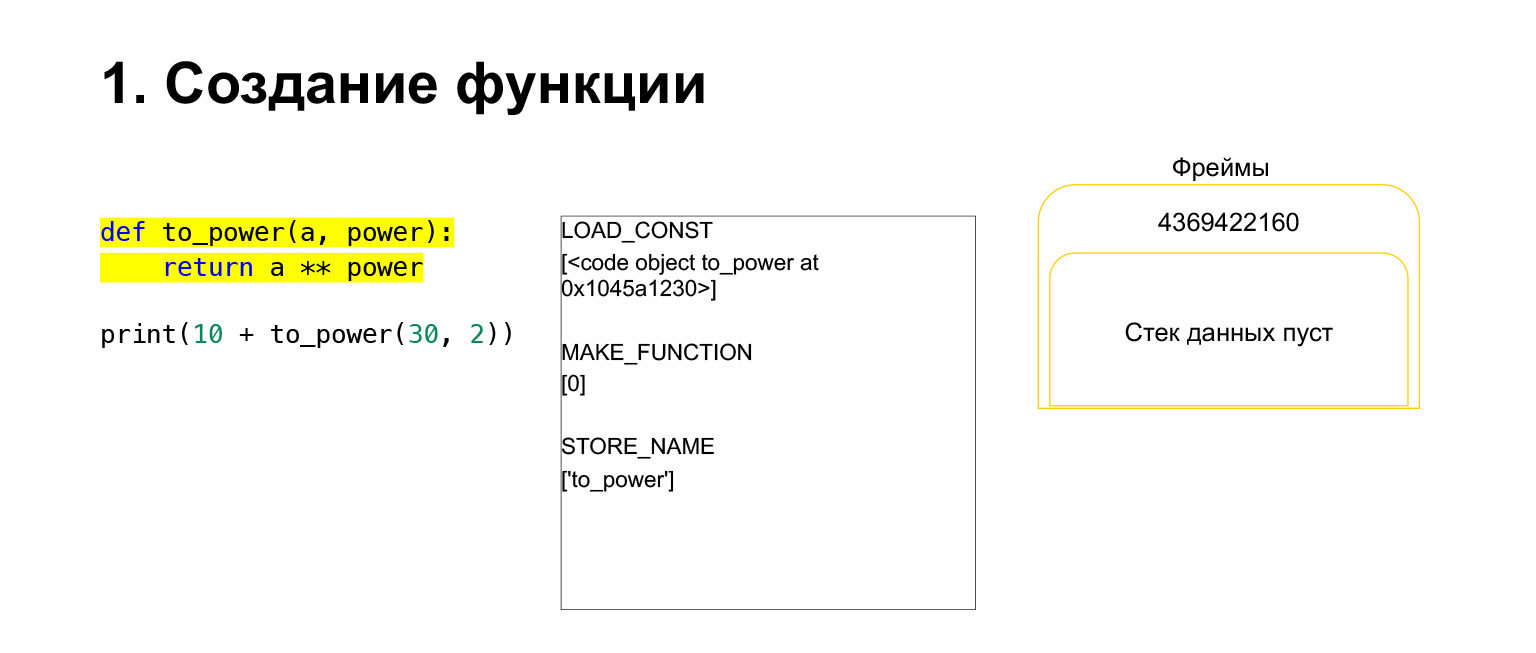
左侧是代码。我们正在检查的部分以黄色突出显示。在第二列中,我们有这部分的字节码。第三列包含带有堆栈的框架。也就是说,每个FrameObject都有其自己的执行堆栈。
Python做什么?它只是按顺序进行,中间列中的字节码执行并与堆栈一起使用。
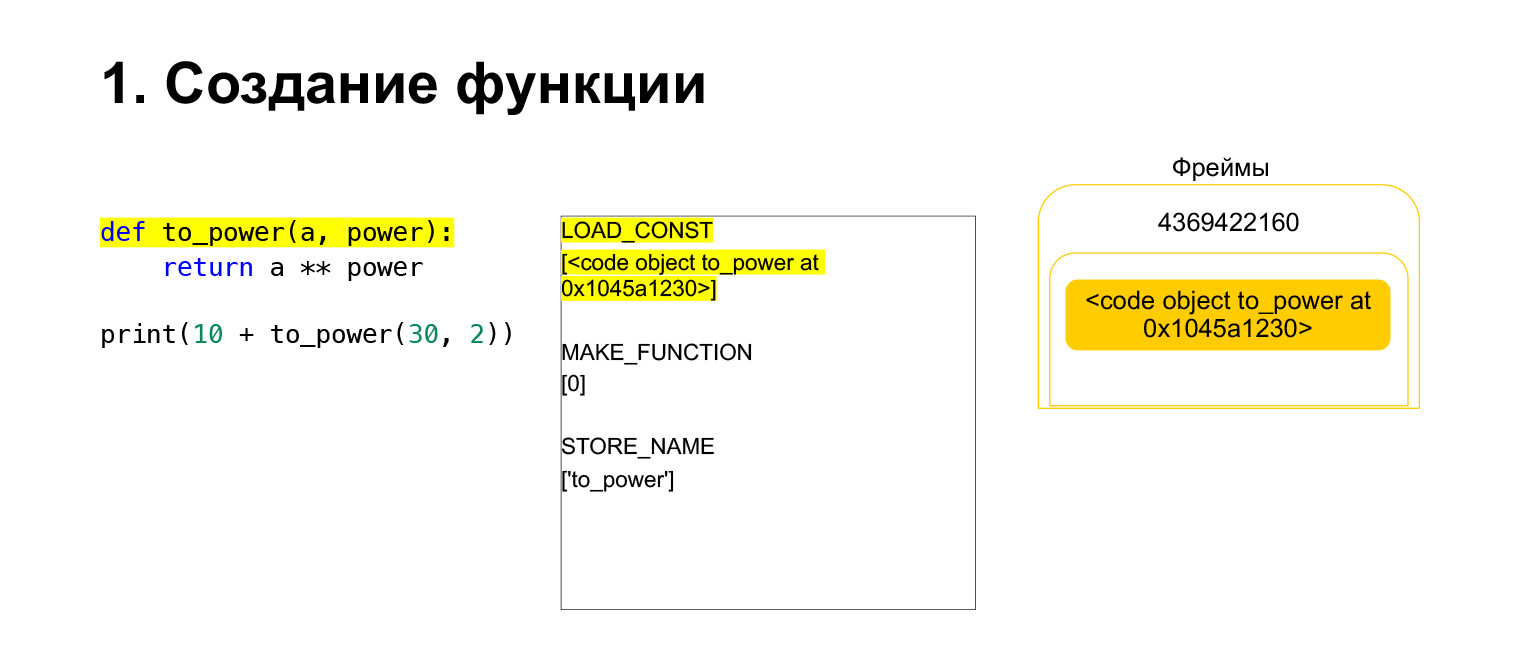
我们已经运行了名为LOAD_CONST的第一个操作码。它加载一个常数。我们跳过了这一部分,在那里创建了一个CodeObject,并且在常量中的某个地方有一个CodeObject。 Python使用LOAD_CONST将其加载到堆栈中。现在,我们在此框架的堆栈上有一个CodeObject。我们可以继续前进。
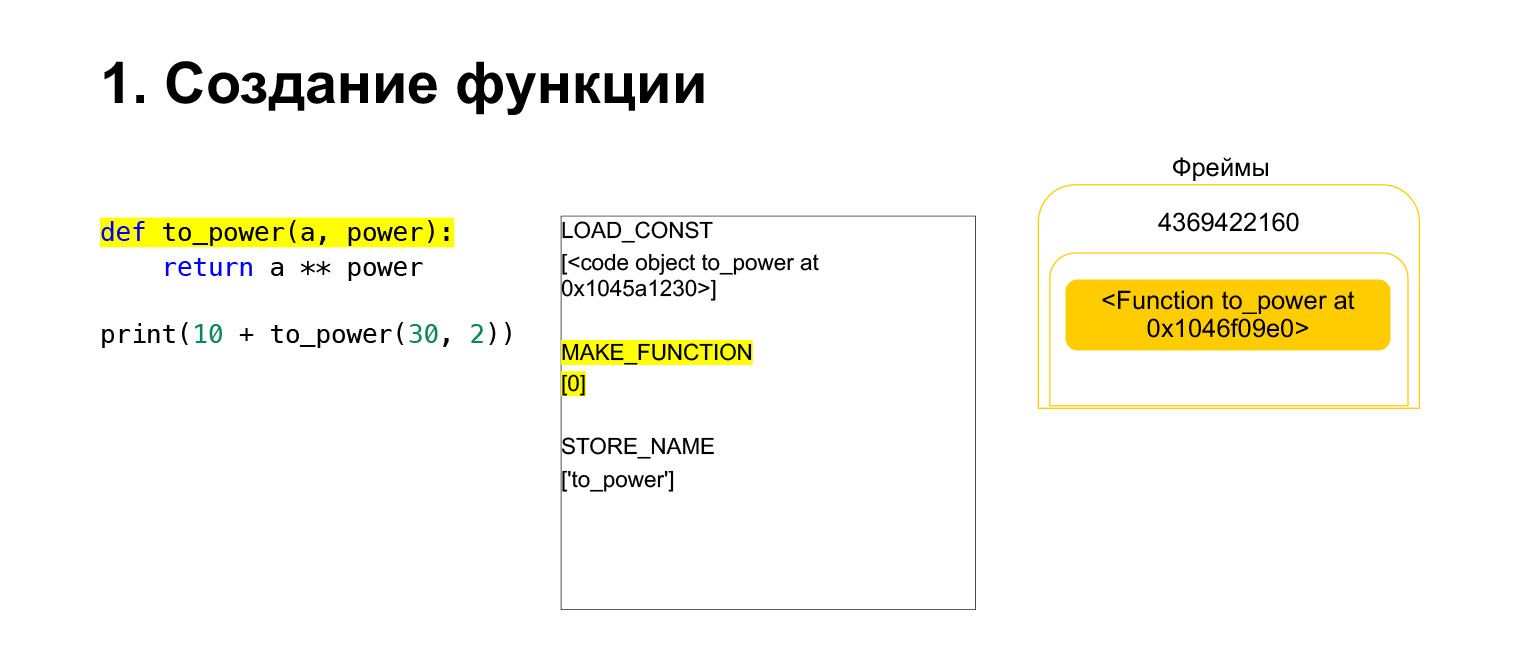
然后,Python执行操作码MAKE_FUNCTION。 MAKE_FUNCTION显然是一个函数。它期望您在堆栈上有一个CodeObject。它执行一些操作,创建一个函数,然后将函数推回堆栈。现在您有了FUNCTION而不是框架堆栈上的CodeObject。现在,此函数需要放置在to_power变量中,以便您可以引用它。
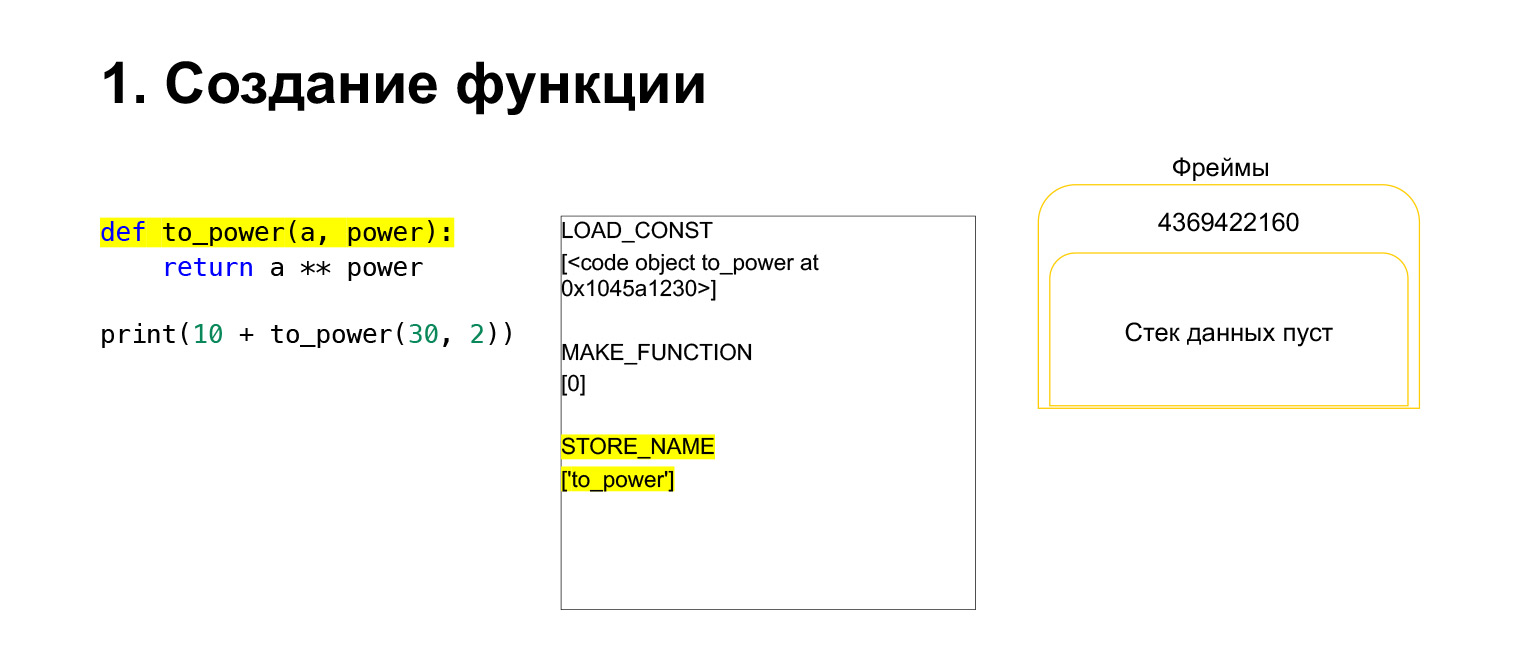
执行操作码STORE_NAME,将其放置在to_power变量中。我们在堆栈上有一个函数,现在它是to_power变量,您可以引用它。
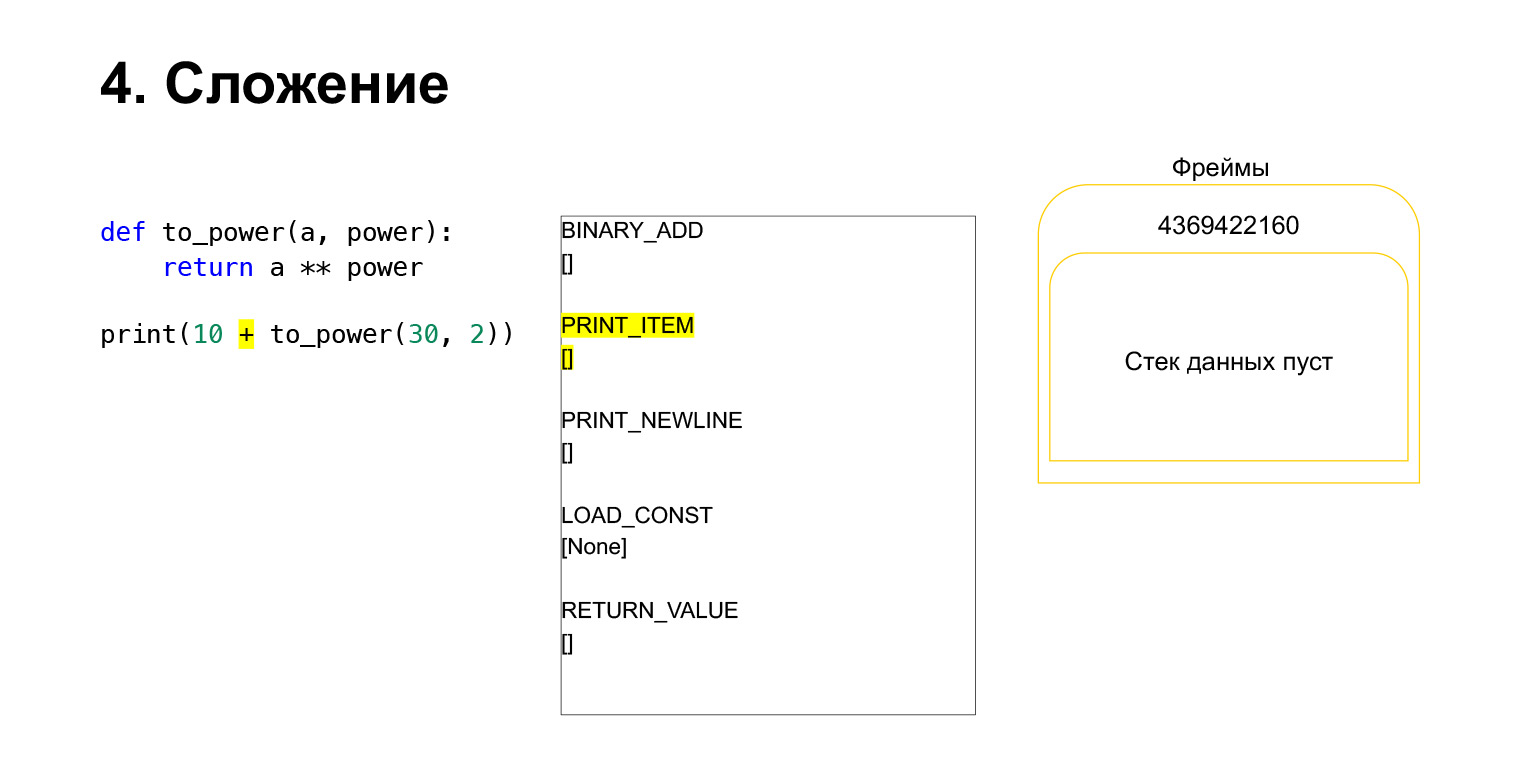
接下来,我们要打印10 +此函数的值。
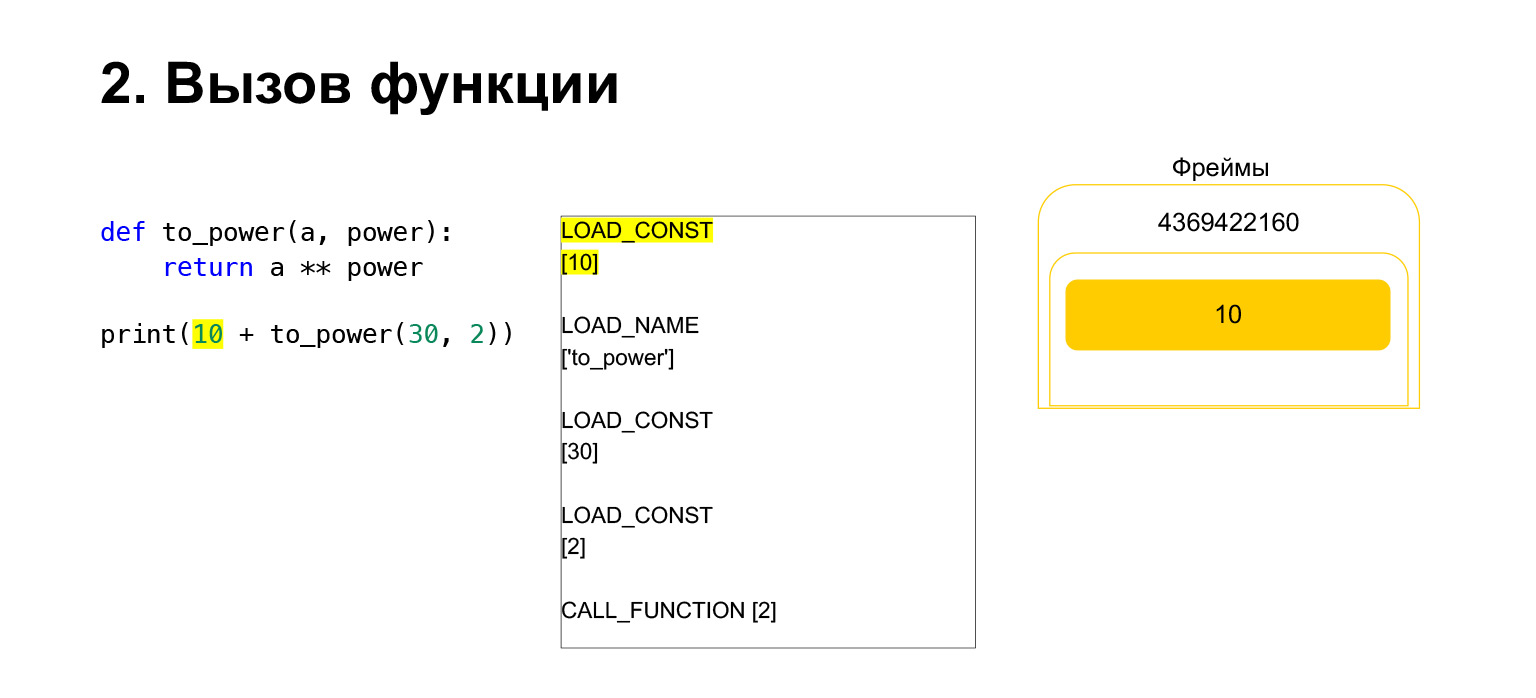
Python做什么?这被转换为字节码。我们拥有的第一个操作码是LOAD_CONST。我们将前十名加载到堆栈中。一堆出现在堆栈上。现在我们需要执行to_power。

该功能如下执行。如果它具有位置参数-我们现在将不讨论其他内容-那么第一个Python会将函数本身放在堆栈中。然后,它放入所有参数,并使用函数参数的参数编号调用CALL_FUNCTION。
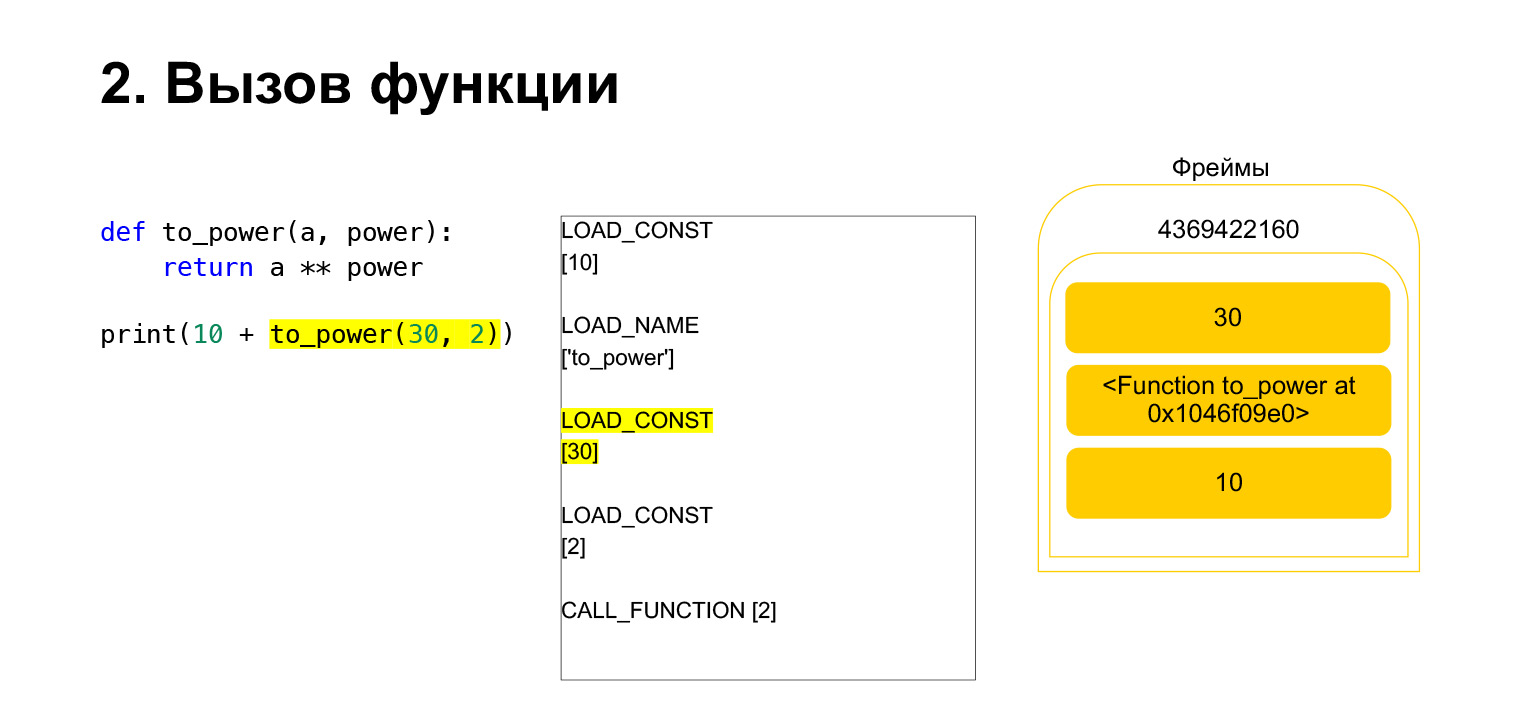
我们将第一个参数加载到堆栈上,这是一个函数。
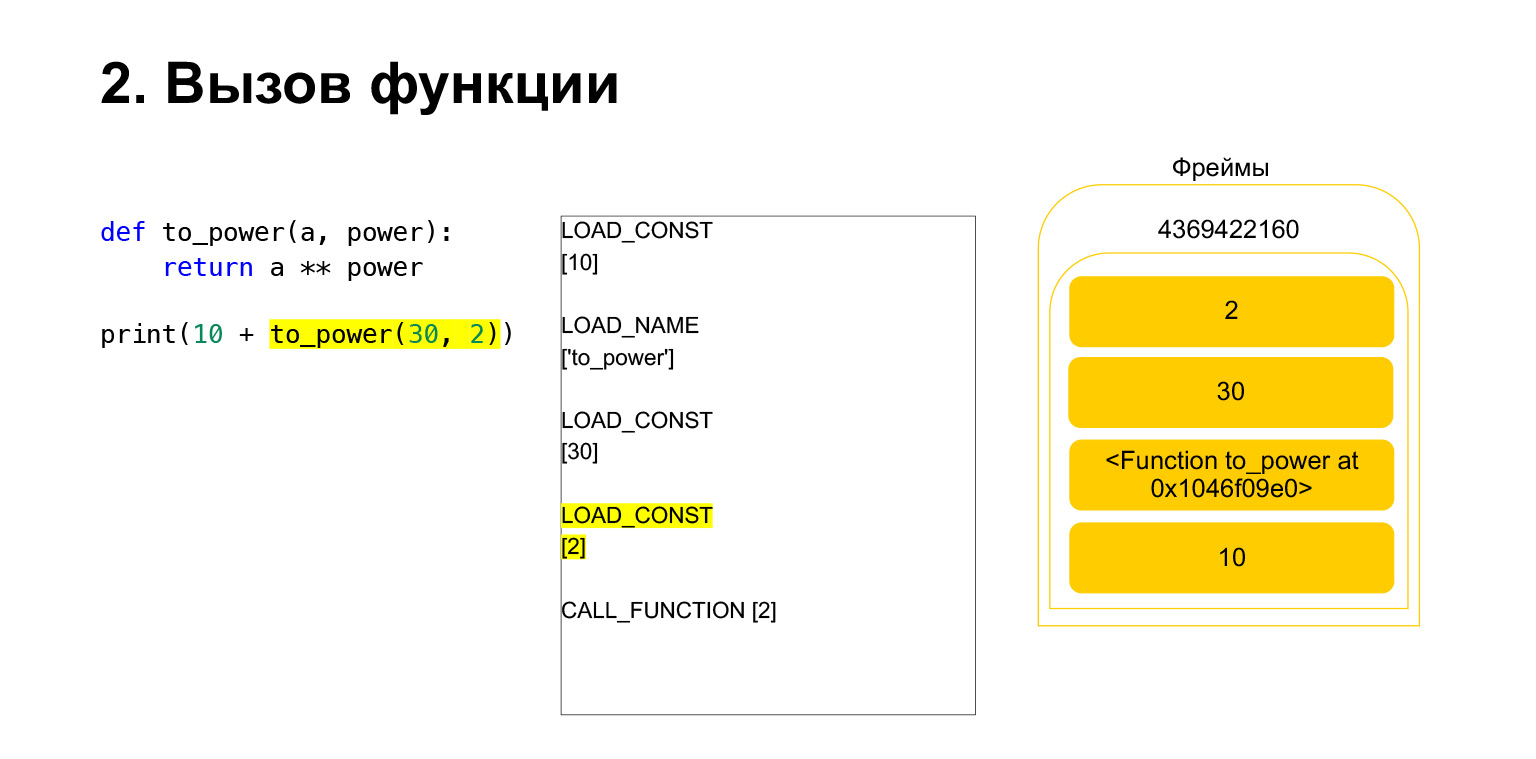
我们在堆栈上又加载了两个参数-30和2。现在我们在堆栈上有一个函数和两个参数。堆栈的顶部在顶部。 CALL_FUNCTION正在等待我们。我们说:CALL_FUNCTION(2),也就是说,我们有一个带有两个参数的函数。 CALL_FUNCTION期望在堆栈上具有两个参数,后跟一个函数。我们有:2,30和功能。
操作码正在进行中。
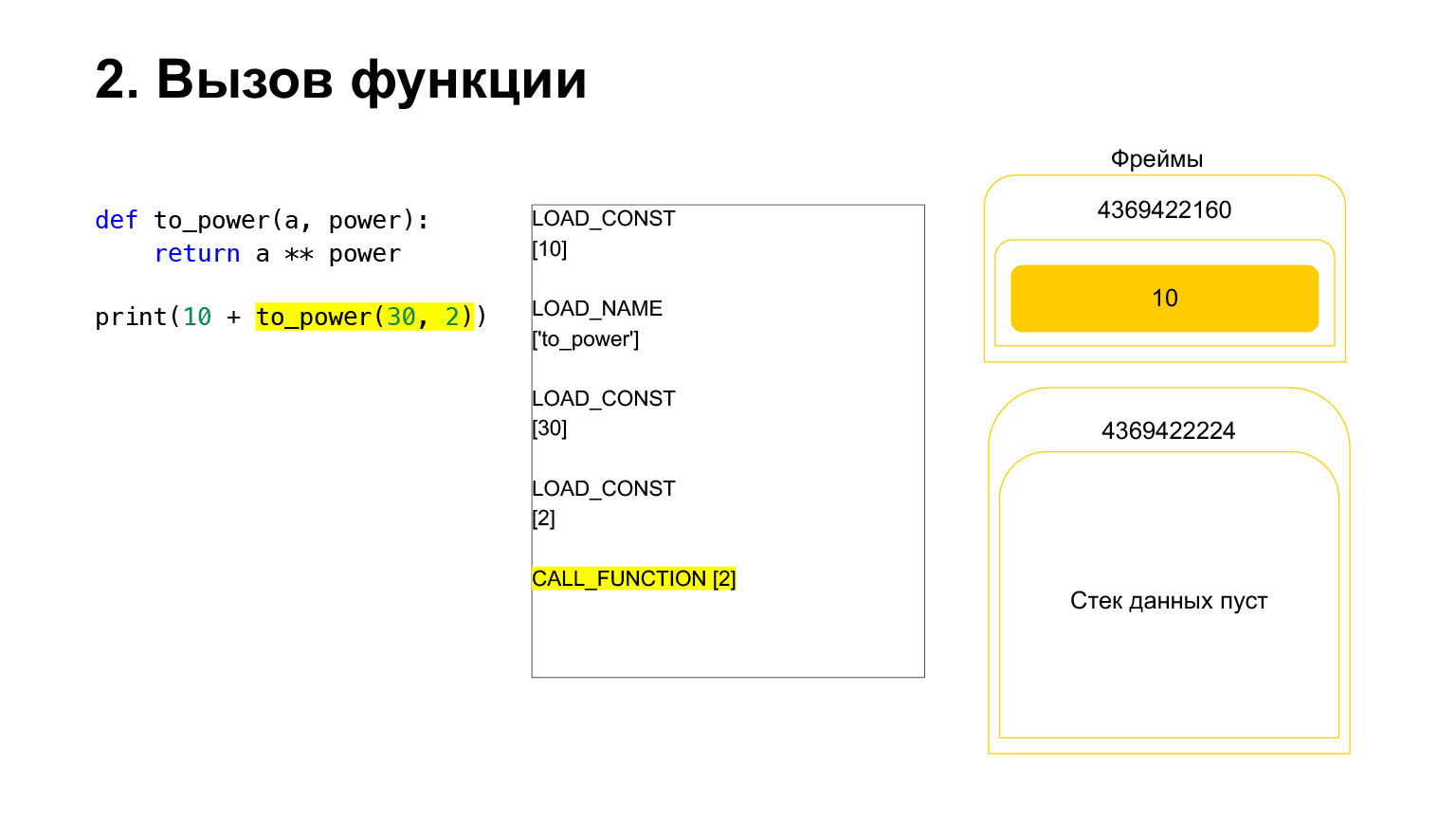
因此,对于我们来说,该堆栈离开了,将创建一个新函数,现在将在其中执行执行。
框架具有自己的堆栈。已经为其功能创建了一个新框架。它仍然是空的。
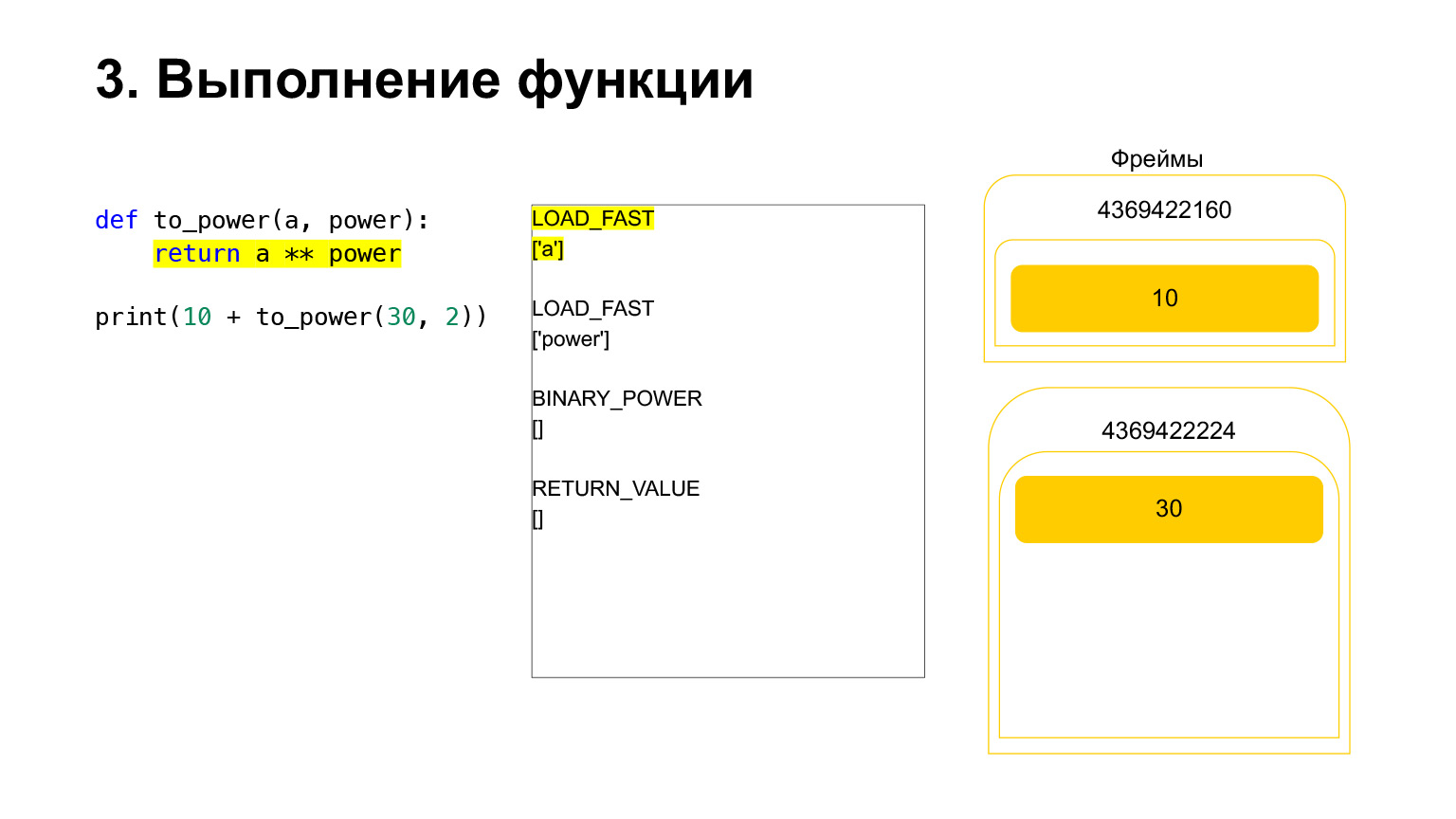
进一步执行。在这里已经很容易了。我们需要提高A的力量。我们将变量A-30的值加载到堆栈上,变量power-2的值,
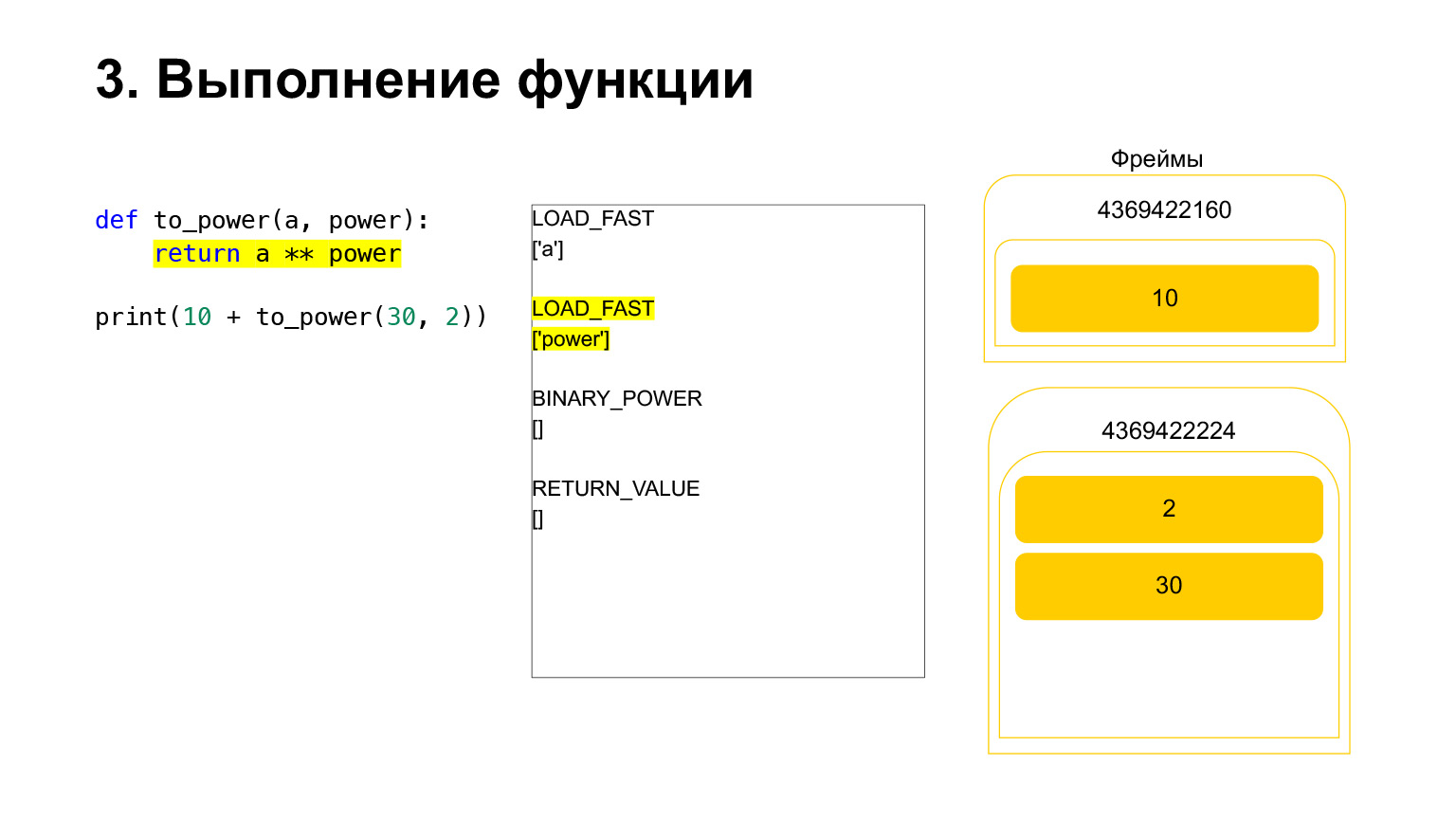
然后执行操作码BINARY_POWER。
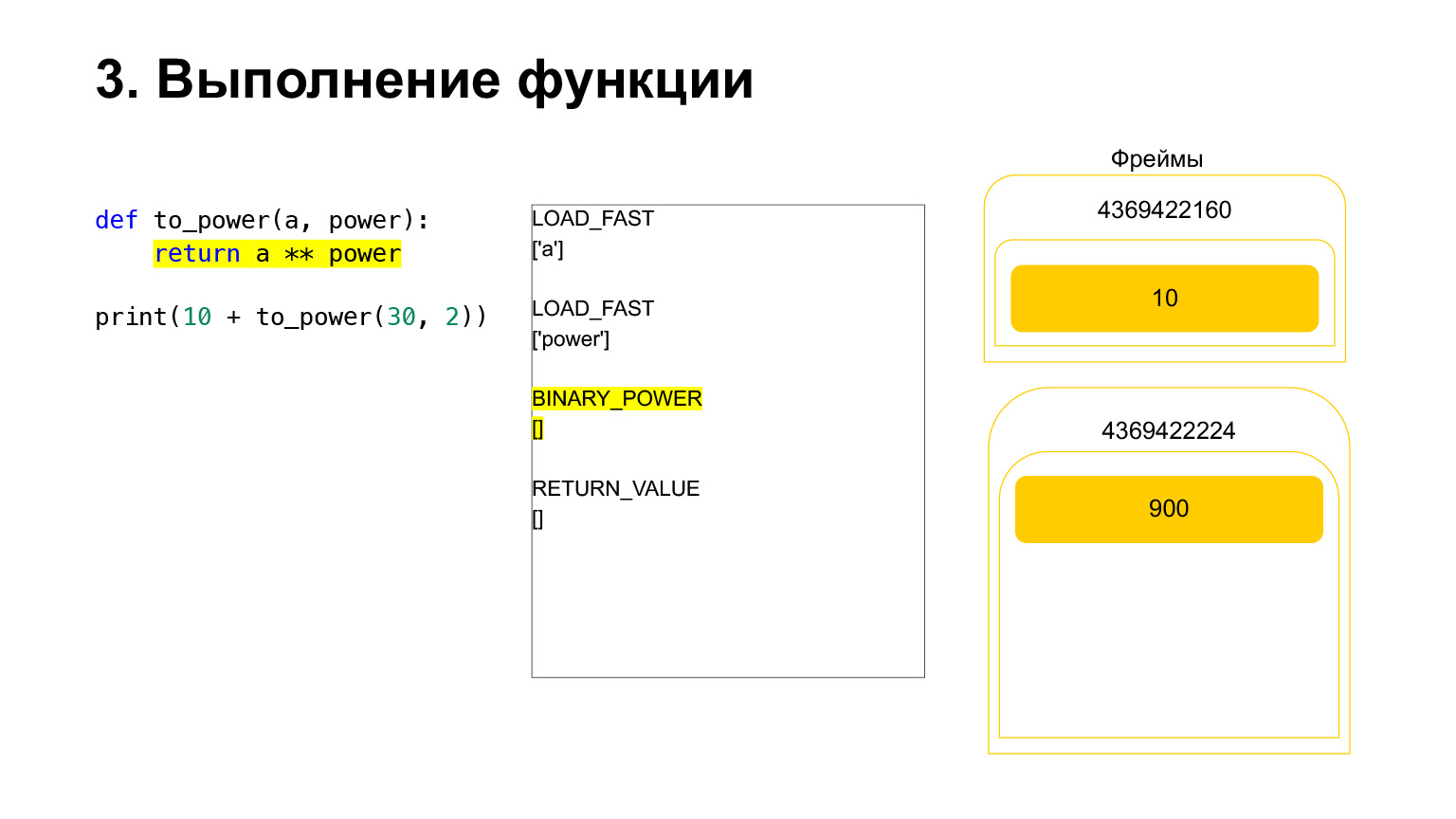
我们将一个数字提高到另一个的幂,然后将其放回堆栈。结果是函数堆栈上的900。
下一个操作码RETURN_VALUE将把值从堆栈返回到前一帧。

这就是执行的方式。该函数已完成,如果没有引用,并且前一个函数的框架上有两个数字,则该框架很可能会清除。

然后,一切都差不多。加法发生。
(...)让我们谈谈类型和PyObject。
打字

一个对象是一个sic结构,其中有两个主要字段:第一个是对该对象的引用数,第二个是对象的类型,当然,是对对象类型的引用。
其他对象通过将其封装而继承自PyObject。也就是说,如果我们看一个浮点数,一个浮点数,那里的结构是PyFloatObject,那么它就有一个HEAD(它是PyObject结构)以及另外的数据,即double ob_fval,该浮点数本身的值存储在其中。

这就是对象的类型。我们只是看了PyObject中的类型,它是一个表示类型的结构。实际上,这也是一个C结构,其中包含指向实现该对象行为的函数的指针。也就是说,那里有一个非常大的结构。它具有指定的函数,例如,如果您想添加此类型的两个对象,则会调用该函数。或者您想减去,调用该对象或创建它。您必须在此结构中指定对类型所做的任何事情。

例如,让我们看一下int,Python中的整数。也是一个非常简短的版本。我们可能对什么感兴趣?整数有tp_name。您可以看到这里有tp_hash,我们可以得到hash int。如果我们在int上调用hash,则将调用此函数。 tp_call我们有零(未定义),这意味着我们不能调用int。 tp_str-字符串转换未定义。 Python具有可以转换为字符串的str函数。
它没有出现在幻灯片上,但大家都已经知道int仍然可以打印。为什么这里是零?由于也有tp_repr,Python具有两个字符串传递函数:str和repr。更详细的转换为字符串。它实际上是定义的,只是没有出现在幻灯片上,如果您实际上导致了字符串,它将被调用。
最后,我们看到tp_new-创建该对象时调用的函数。 tp_init我们为零。我们都知道int不是可变类型,是不可变的。创建之后,没有必要对其进行更改,初始化,因此为零。

我们还以Bool为例。如您所知,Python中的Bool实际上是从int继承的。也就是说,您可以添加Bool,彼此共享。当然,这不可能完成,但是有可能。
我们看到有一个tp_base-指向基础对象的指针。除了tp_base以外的所有内容都是唯一被覆盖的内容。也就是说,它具有自己的名称,自己的表示功能,不是要写的数字,而是对或错。以数字表示,一些逻辑功能在那里被覆盖。 Docstring是它自己的东西,也是它的创造。其他一切都来自int。

我将简要介绍一下列表。在Python中,列表是一个动态数组。动态数组是这样工作的数组:您预先用某个维度初始化内存区域。在此处添加元素。一旦元素的数量超过此大小,就以一定的余量扩展它,即不是以一为单位,而是以一个以上的值扩展一倍,以便有一个很好的观点。
在Python中,大小增长为0、4、8、16、25,即根据某种公式,该公式允许我们渐近地对常量进行插入。您会看到列表中插入功能的节选。也就是说,我们正在调整大小。如果没有调整大小,则会抛出错误并分配元素。在Python中,这是用C实现的普通动态数组。
(...)让我们简要地讨论一下字典。它们在Python中无处不在。
辞典
我们都知道,在对象中,类的整个组成都包含在字典中。很多事情都基于它们。哈希表中Python中的字典。
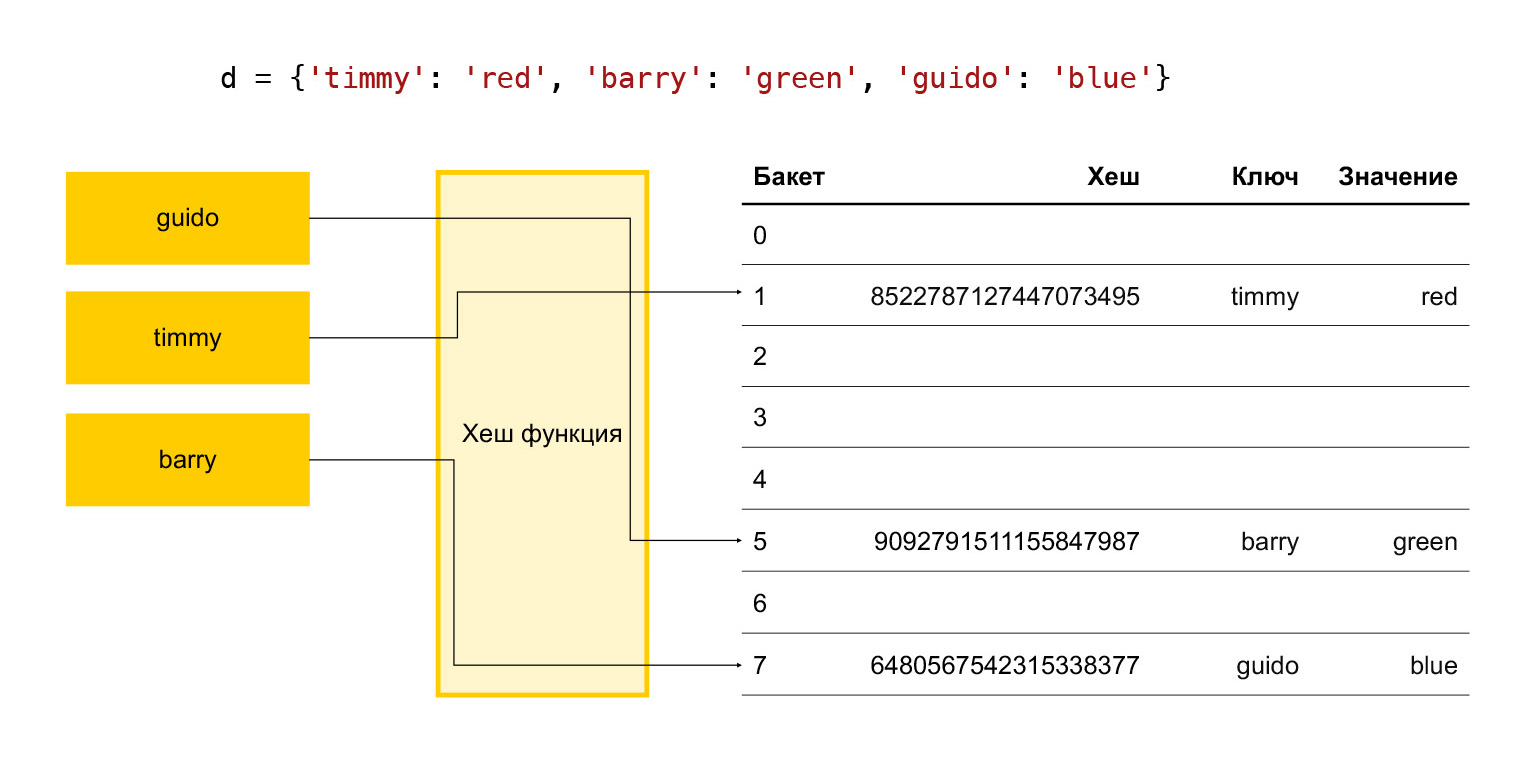
简而言之,哈希表如何工作?有一些键:timmy,Barry,guido。我们希望将它们放入字典中,我们通过哈希函数运行每个键。原来是一个哈希。我们使用此哈希找到存储桶。存储桶只是元素数组中的一个数字。最终进行模除法。如果水桶是空的,我们只需将所需的物品放入其中。如果它不是空的,并且那里已经有某个元素,那么这就是冲突,我们选择下一个存储桶,看看它是否空闲。依此类推,直到找到免费的存储桶。
因此,为了使添加操作在足够的时间内发生,我们需要不断保持一定数量的存储桶空闲。否则,当接近此数组的大小时,我们将搜索很长时间的空闲存储桶,并且所有操作都会变慢。
因此,根据经验,Python中有三分之一的数组元素始终是自由的。如果它们的数量超过三分之二,则数组将扩展。这是不好的,因为浪费了三分之一的元素,所以没有任何有用的存储。

幻灯片链接
因此,从3.6版开始,Python就做到了这一点。在左侧,您可以查看以前的情况。我们有一个稀疏数组,用于存储这三个元素。从3.6开始,他们决定将这样的稀疏数组设置为常规数组,但同时将存储桶元素的索引存储在单独的索引数组中。
如果我们看一下索引数组,则在第一个存储桶中没有None,在第二个存储桶中有来自该数组的索引为1的元素
,依此类推。首先,这减少了内存使用,其次,我们也免费提供了它有序数组。也就是说,我们有条件地使用通常的sish追加将元素添加到此数组中,并且该数组会自动排序。
Python使用了一些有趣的优化。为了使这些哈希表起作用,我们需要进行元素比较操作。想象一下,我们将一个元素放入哈希表中,然后我们想要一个元素。我们拿哈希值,去桶。我们看到:桶满了,里面有东西。但这是我们需要的元素吗?放置时可能发生了碰撞,而该物品实际上可以放入另一个桶中。因此,我们必须比较密钥。如果密钥错误,我们将使用与下一个存储桶搜索机制相同的机制来解决冲突。让我们继续前进。

幻灯片链接
因此,我们需要具有键比较功能。通常,对象比较功能可能非常昂贵。因此,使用了这种优化。首先,我们比较商品ID。众所周知,CPython中的ID是内存中的位置。
如果ID相同,则它们是相同的对象,当然,它们是相等的。然后我们返回True。如果不是,请查看哈希。如果我们没有以某种方式覆盖哈希,那么哈希运算应该是一个非常快的操作。我们从这两个对象中获取哈希值并进行比较。如果它们的哈希值不相等,则对象肯定不相等,因此我们返回False。
而且只有在极不可能的情况下-如果我们的哈希值相等,但我们不知道它是否是同一对象,则只有我们比较这些对象本身。
有趣的小事情:您不能在迭代期间将任何东西插入键。这是错误的。

引擎盖下有一个名为version的变量,用于存储字典的版本。当您更改字典,版本时,Python会理解这一点并向您抛出错误。

在更实际的示例中,词典可以用来做什么?在出租车中,我们有订单,并且订单的状态可以更改。更改状态时,您必须执行某些操作:发送短信,记录订单。
这种逻辑是用Python编写的。为了不写“如果订单状态如此之类,那么就这样做”这样的巨字,有一个特定的决定,其中关键是订单状态。到VALUE处有一个元组,其中包含在转换到此状态时必须执行的所有处理程序。这是一种常见的做法,实际上,它是对sish开关的替代。

按类型还有更多的东西。我会告诉你一成不变的。这些是不可变的数据类型,并且可变的分别是可变的类型:指令,类,类实例,工作表,也许还有其他东西。几乎所有其他内容都是字符串,只是数字-它们是不可变的。什么是可变类型?首先,它们使代码更易于理解。也就是说,如果您在代码中看到某个东西是一个元组,您是否理解它不会进一步改变,这使您更容易阅读代码?了解接下来会发生什么。在元组ds中,您不能键入项目。您将理解这一点,这将有助于您和所有将为您阅读代码的人们的阅读。
因此,有一条规则:如果您不做任何更改,最好使用不可变类型。它还可以加快工作速度。元组使用两个常量:pit_tuple,tap_tuple,max和CC。重点是什么?对于大小最大为20的所有元组,将使用特定的分配方法,这会使分配速度更快。每种类型最多可以有两千个这样的对象。这比工作表快得多,因此,如果使用元组,则速度会更快。
也有运行时检查。显然,如果您尝试将某物插入对象,但它不支持此功能,则将出现错误,并有所了解您做错了什么。字典中的键只能是哈希值在生命周期内不变的对象。只有不可变的对象满足此定义。只有它们可以是字典键。

在C语言中看起来像什么?例。左边是元组,右边是常规列表。当然,在这里,并不是所有的差异都是可见的,只有我想展示的那些差异。在tp_hash字段的list中,我们没有NotImplemented,即list没有哈希。元组中有一些函数实际上会向您返回哈希值。这就是为什么tuple除其他外可以成为dict键而list不能为之的原因。
接下来要强调的是项目分配函数sq_ass_item。在list中,在tuple中它是零,也就是说,您自然不能为tuple分配任何东西。

还有一件事。在我们询问之前,Python不会复制任何内容。这也应该记住。如果要复制某些内容,请使用具有copy.deepcopy功能的复制模块。有什么不同?如果对象是容器对象(例如同级列表),则copy复制对象。此对象中的所有引用都插入到新对象中。 Deepcopy递归地复制此容器内及外部的所有对象。
或者,如果您想快速复制列表,则可以使用单个冒号切片。您将获得一个副本,这样的快捷方式很简单。
(...)接下来,让我们谈谈内存管理。
内存管理

让我们来看看我们的sys模块。它具有让您查看是否正在使用任何内存的功能。如果启动解释器并查看内存变化的统计信息,您将看到创建了很多对象,包括小的对象。这些只是当前创建的那些对象。
实际上,Python在运行时创建了许多小对象。而且,如果我们使用标准的malloc函数来分配它们,我们将很快发现自己的事实是我们的内存是零散的,因此内存分配很慢。

这意味着需要使用自己的内存管理器。简而言之,它是如何工作的? Python为自己分配了称为竞技场的内存块,每个内存块256 KB。在内部,他将自己切成4 KB的池,这就是内存页的大小。在池内部,我们有大小不同的块,从16到512字节。
当我们尝试为一个对象分配少于512个字节时,Python会以自己的方式选择一个适合于该对象的块,并将该对象放置在该块中。
如果对象被释放,删除,则该块被标记为空闲。但是它没有提供给操作系统,在下一个位置,我们可以将该对象写入同一块中。这大大加快了内存分配。

释放内存。之前我们看到了PyObject结构。她有这个参考-参考计数。它的工作非常简单。当您引用此对象时,Python将增加引用计数。一旦有了对象,对它的引用就会消失,然后取消分配引用计数。
黄色突出显示的内容。如果refcnt不为零,那么我们正在那里做某事。如果refcnt为零,那么我们将立即释放该对象。我们没有在等待任何垃圾收集器,什么也没有,但是现在我们清除内存。
如果遇到del方法,它只是删除变量与对象的绑定。当实际上从内存中删除对象时,就会调用您可以在类中定义的__del__方法。您将在对象上调用del,但如果它仍然具有引用,则该对象将不会在任何地方删除。它的终结器__del__不会被调用。尽管它们被称为非常相似。
关于如何查看链接数量的简短演示。有我们最喜欢的sys模块,它具有getrefcount函数。您可以看到一个对象的链接数。

我会告诉你更多。一个对象。链接数是从中获取的。有趣的细节:变量A指向TaxiOrder。您获得链接数,将得到“ 2”打印。看来是为什么呢?我们有一个对象引用。但是,当您调用getrefcount时,此对象将包装在函数内部的参数周围。因此,您已经有两个对该对象的引用:第一个是变量,第二个是函数参数。因此,将打印“ 2”。
其余的都是微不足道的。我们给该对象分配另一个变量,得到3。然后我们删除该绑定,得到2。然后我们删除对该对象的所有引用,同时调用finalizer,这将打印我们的行。

(...)CPython还有一个有趣的功能,它无法建立,并且似乎在文档中的任何地方都没有提及。经常使用整数。每次重新创建它们都是浪费的。因此,最常用的数字是Python开发人员选择的范围从–5到255,它们是Singleton。也就是说,它们仅创建一次,位于解释器中的某个位置,当您尝试获取它们时,将获得对同一对象的引用。我们把A和B分别打印出来,比较它们的地址。正确。例如,我们有105个对该对象的引用,仅因为现在有那么多引用。
如果我们采用更大的数字(例如1408),则这些对象对我们而言不相等,并且分别有两个引用。其实一个。
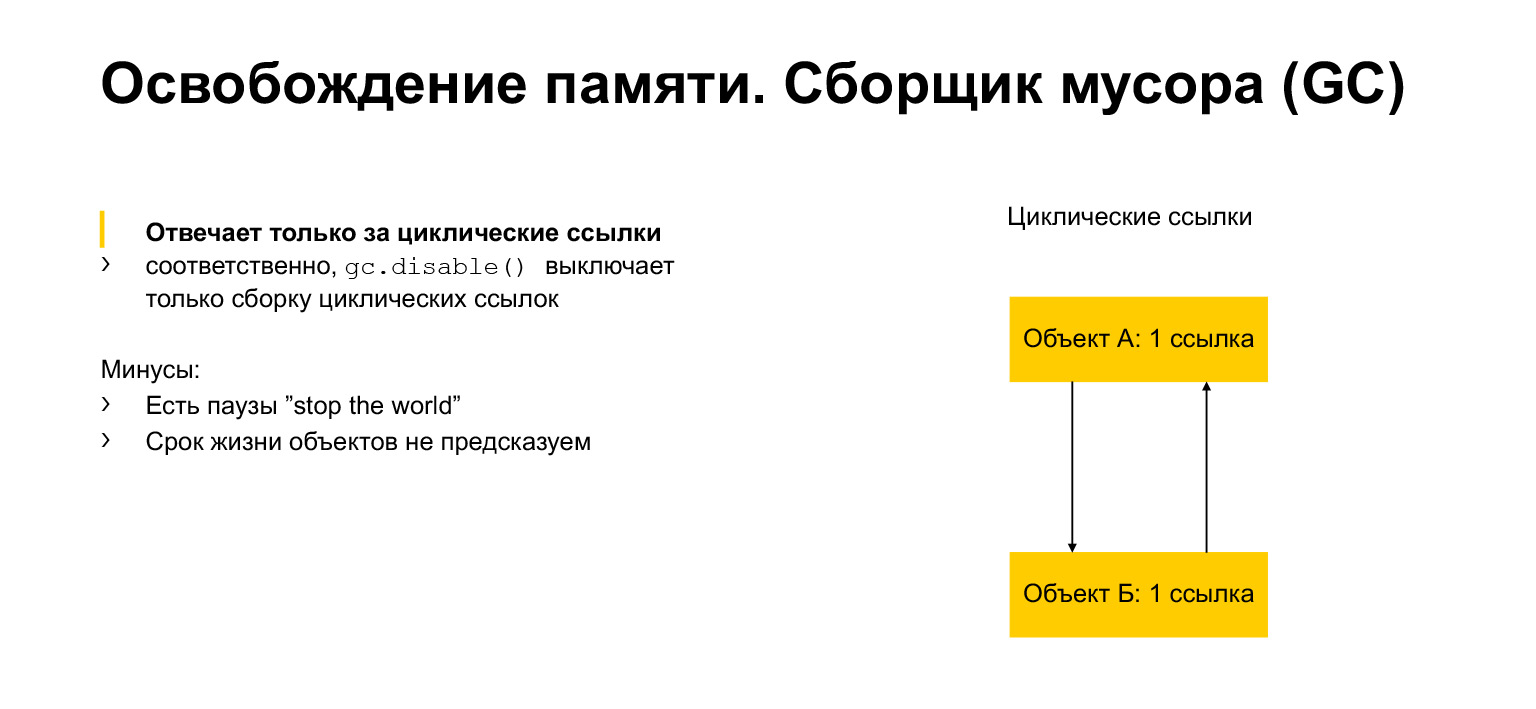
我们讨论了一些有关内存分配和释放的问题。现在让我们谈谈垃圾收集器。这是为了什么似乎我们有许多链接。一旦没有人引用该对象,我们可以将其删除。但是我们可以有循环链接。例如,对象可以引用自身。或者,如示例中所示,可能有两个对象,每个对象都引用一个邻居。这称为循环。然后,这些对象将永远无法引用另一个对象。但是同时,例如,它们是程序另一部分无法实现的。我们需要删除它们,因为它们不可访问,无用,但是它们具有链接。这正是垃圾收集器模块的用途。它检测周期并删除这些对象。
他如何工作?首先,我将简要介绍代,然后介绍算法。
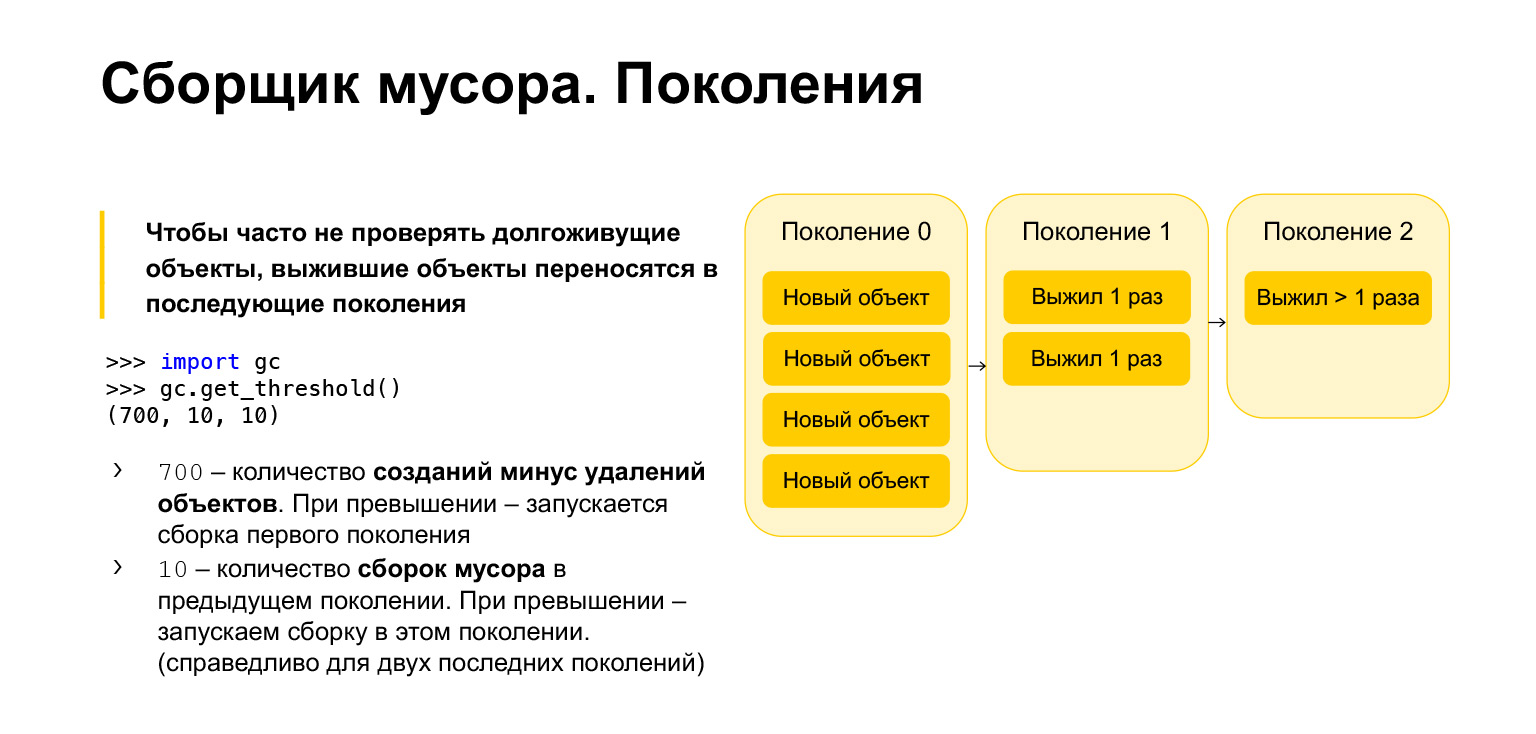
为了优化Python中垃圾收集器的速度,它是分代的,也就是说,它使用了几代。一共有三代。他们需要什么?显然,与长期存在的对象相比,最近创建的那些对象更可能是不必要的。假设您在函数过程中创建了一些东西。最有可能的是,退出功能时将不需要它。带有临时变量的循环也是如此。与已经存在很长时间的物体相比,所有这些物体需要更频繁地清洁。
因此,所有新对象都将归零。定期清洁这一代。 Python具有三个参数。每个世代都有其自己的参数。您可以获取它们,导入垃圾收集器,调用get_threshold函数并获取这些阈值。
默认情况下,有700、10、10。什么是700?这是对象创建数减去删除数。一旦超过700,就会开始新一代垃圾回收。 10、10是上一代垃圾回收的数量,之后我们需要在当前一代中开始垃圾回收。
也就是说,当我们清除零代时,将在第一代中开始构建。在清洁第一代产品10次之后,我们将开始第二代产品的构建。因此,对象代代相传。如果他们生存下来,他们将移居第一代。如果他们在第一代垃圾回收中幸存下来,那么他们将被转移到第二代。从第二代开始,它们不再移动到任何地方,而是永远存在。
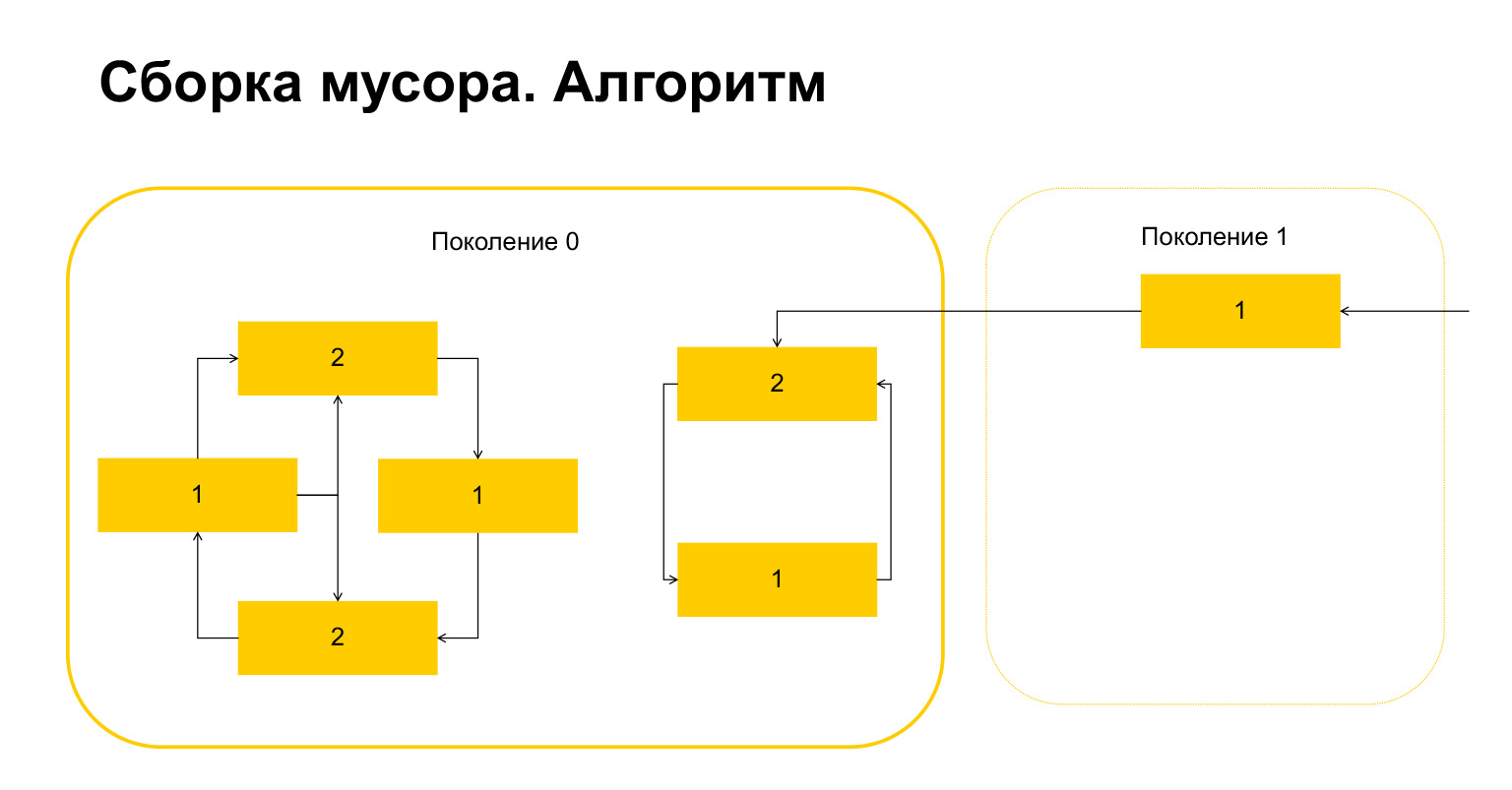
垃圾收集如何在Python中工作?假设我们从第0代开始垃圾收集。我们有一些对象,它们有循环。左侧有一组互相引用的对象,右侧的一组也互相引用。重要的细节-第1代也引用了它们。Python如何检测循环?首先,为每个对象创建一个临时变量,并将对该对象的引用数写入其中。这反映在幻灯片上。我们在顶部有两个指向该对象的链接。但是,从外部引用了第1代的对象。 Python记住了这一点。然后(重要!)它遍历这一代中的每个对象,并删除,减少该代中引用数的计数器。
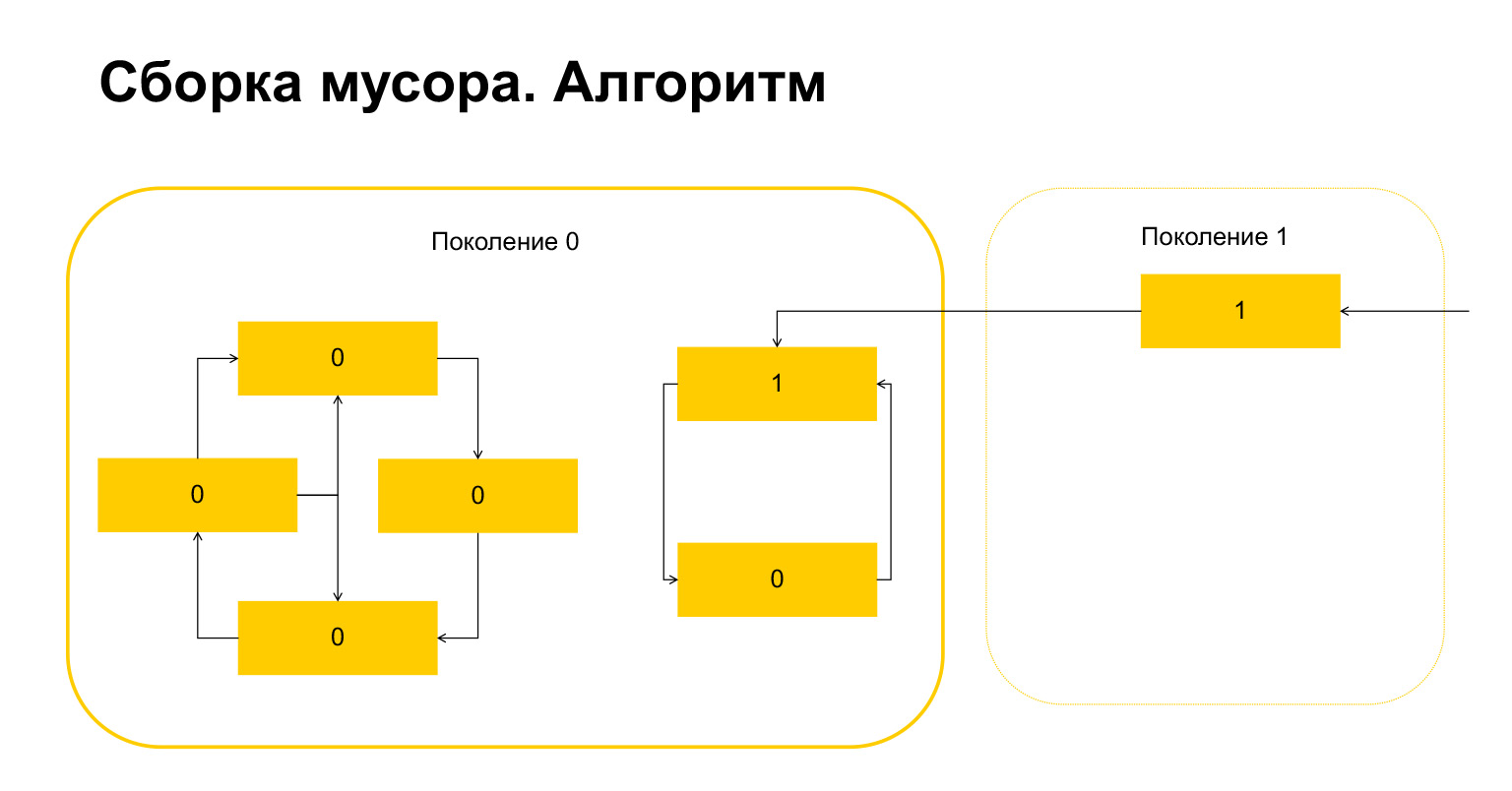
这是发生了什么事。对于一代人中仅相互引用的对象,此变量通过构造自动变为零。只有从外部引用的对象才具有单位。
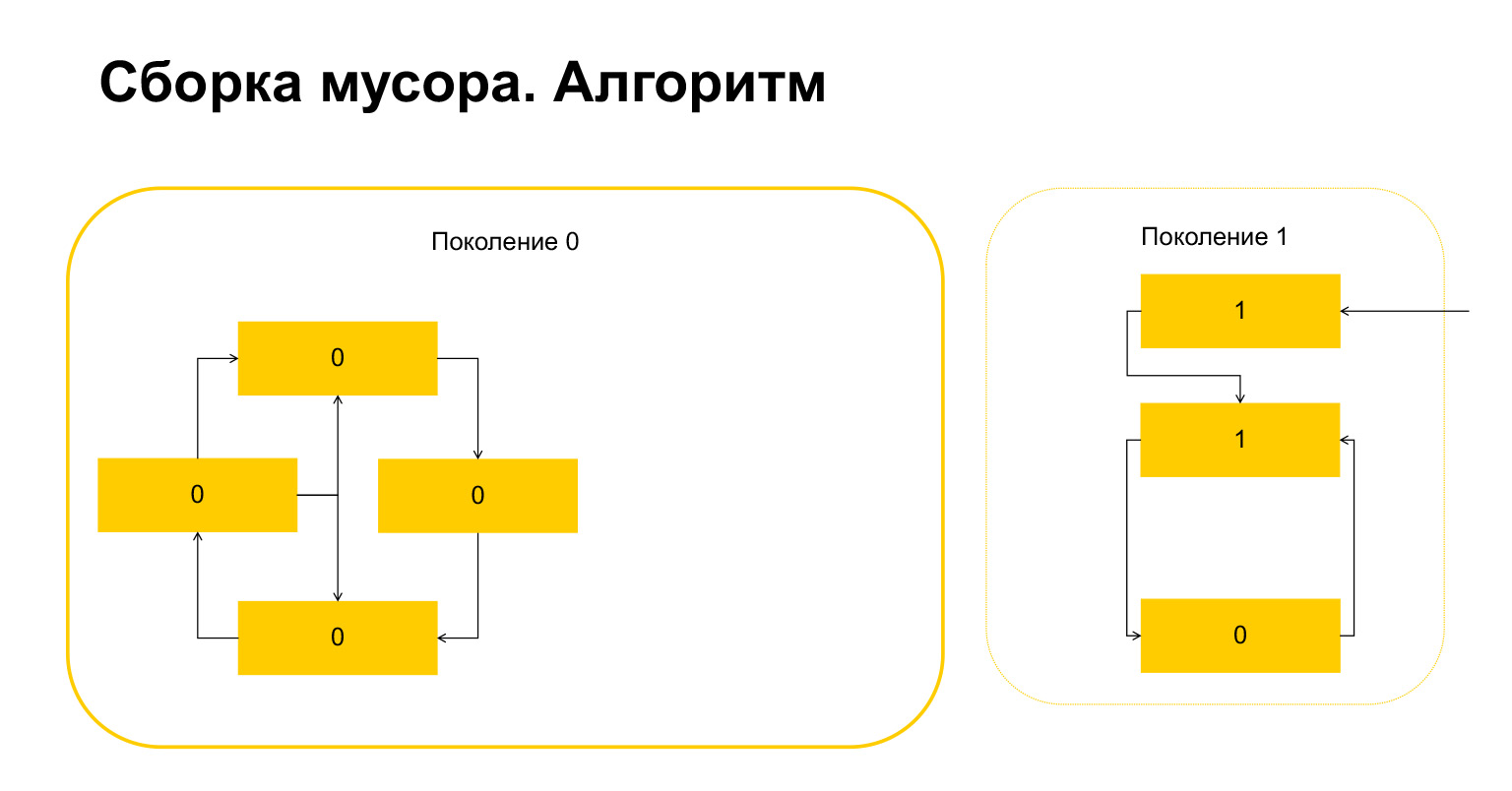
Python接下来会做什么?由于这里有一个,他了解这些对象是从外部引用的。而且我们不能删除该对象或该对象,因为否则我们将以无效情况结束。因此,Python将这些对象转移到第1代,然后删除,清除第0代中剩下的所有内容。关于垃圾收集器的一切。
(...) 继续。我将简单介绍发电机。
发电机

不幸的是,这里不会介绍发电机,但是让我们尝试告诉您什么是发电机。相对而言,这是一种函数,它使用单词yield来记住其执行的上下文。此时,它返回一个值并记住上下文。然后,您可以再次引用它并获得它给出的值。
你能用发电机做什么?您可以产生一个生成器,这将向您返回值,请记住上下文。您可以退还发电机。在这种情况下,将抛出StopIteration执行,其中的值将包含该值,在本例中为Y。
鲜为人知的事实:您可以向生成器发送一些值。也就是说,您在生成器上调用send方法,并且Z(请参见示例)将是生成器将调用的yield表达式的值。如果要控制生成器,则可以传递值。
您也可以在此处抛出异常。同样的事情:拿一个生成器对象,扔掉它。你在那里丢了一个错误。您将有一个错误代替上一个产量。并关闭-您可以关闭发电机。然后引发GeneratorExit的执行,并且期望生成器不产生任何其他结果。

在这里,我只想谈谈它在CPython中的工作方式。实际上,生成器中有一个执行框架。我们记得,FrameObject包含所有上下文。由此看来,上下文是如何保存的很明显。也就是说,生成器中只有一个框架。

当执行生成器函数时,Python如何知道您不需要执行它,而是创建一个生成器?我们查看的CodeObject具有标志。当您调用函数时,Python会检查其标志。如果存在CO_GENERATOR标志,则表示不需要执行该函数,而只需创建一个生成器。他创造了它。 PyGen_NewWithQualName函数。

执行如何?生成器首先从GENERATOR_FUNCTION调用GENERATOR_Object。然后,您可以使用next调用GENERATOR_Object以获得下一个值。下次通话如何发生?它的帧取自生成器,并存储在变量F中。并发送到EvalFrameEx解释器的主循环。与正常功能一样执行。YIELD_VALUE映射代码用于返回,暂停生成器的执行。它会记住框架中的所有上下文并停止执行。这是倒数第二个话题。
(...)快速回顾什么是异常以及如何在Python中使用它们。
例外情况

异常是处理错误情况的一种方法。我们有一个try块。我们可以尝试编写那些可能引发异常的东西。假设我们可以使用单词单词引发一个错误。借助except的帮助,我们可以捕获某些类型的异常,在这种情况下为SomeError。使用except,我们捕获了没有表达的所有异常。 else块的使用频率较低,但它存在并且仅在未引发任何异常的情况下才会执行。无论如何,finally块将执行。
异常在CPython中如何工作?除了执行堆栈外,每个框架还具有一堆块。最好使用一个例子。


块堆栈是在其上写入块的堆栈。每个块都有一个类型,Handler,一个Handler。处理程序是为了处理该块而跳至的字节码地址。它是如何工作的?假设我们有一些代码。我们创建了一个try块,我们有一个except块,其中捕获了RuntimeError异常,还有一个finally块,无论如何都应该这样做。
所有这些都退化为该字节码。在try块上字节码的开头,我们看到两个两个操作码SETUP_FINALLY,其参数分别为40和12。这是处理程序的地址。当执行SETUP_FINALLY时,在块堆栈上放置一个块,该块上显示:要处理我,一种情况下转到40号地址,另一种情况转到12号地址。
堆栈下的12位除外,该行包含else RuntimeError。这意味着当我们遇到异常时,我们将查看块堆栈以查找具有SETUP_FINALLY类型的块。找到其中有一个到地址12的转换的块,然后转到那里。然后,我们将异常与类型进行了比较:我们检查异常的类型是否为RuntimeError。如果相等,则执行它;如果不相等,则跳到其他地方。
FINALLY是块堆栈中的下一个块。如果有其他异常,它将为我们执行。然后,搜索将继续在该块堆栈上进行,我们将进入下一个SETUP_FINALLY块。会有一个处理程序告诉我们,例如地址40。我们跳到地址40-您可以从代码中看到这是一个finally块。

它在CPython中非常简单地工作。我们拥有所有可以引发异常的函数,它们返回一个值代码。如果一切正常,则返回0;如果出错,则返回-1或NULL,具体取决于函数的类型。
在C上使用这样的侧边栏。我们看到分裂是如何发生的。并进行检查,如果B等于零并且我们不想除以零,那么我们会记住该异常并返回NULL。因此发生了错误。因此,在调用堆栈上更高的所有其他函数也应该抛出NULL。我们将在主解释器循环中看到这一点,并跳转到这里。

这是堆栈展开。一切如我所说:我们遍历整个块堆栈,并检查其类型为SETUP_FINALLY。如果是这样,跳过Handler,非常简单。实际上,这就是全部。
链接
通用解释器:
docs.python.org/3/reference/executionmodel.html
github.com/python/cpython
leanpub.com/insidethepythonvirtualmachine/read
内存管理:
arctrix.com/nas/python/gc
rushter.com/blog/python -memory-managment
instagram-engineering.com/dismissing-python-garbage-collection-at-instagram-4dca40b29172
stackify.com/python-garbage-collection
例外:
bugs.python.org/issue17611