你好!很难找到从未遇到过严重故障的微控制器程序员。通常,它不会以任何方式进行处理,而只是挂在制造商的启动文件中提供的处理程序的无限循环中。同时,程序员尝试直观地找到失败的原因。我认为这不是解决问题的最佳方法。
在本文中,我想描述一种分析具有Cortex M3 / M4内核的流行微控制器严重故障的方法。尽管“技术”一词可能太大了。相反,我仅以一个示例为例,说明如何分析严重故障的发生并显示在类似情况下可以采取的措施。我将使用IAR软件和STM32F4DISCOVERY调试板,因为许多有抱负的程序员都拥有这些工具。但是,这是完全不相关的,该示例可以适用于该系列的任何处理器和任何开发环境。

陷入HardFault
在尝试分析HatdFault之前,您需要进行研究。有很多方法可以做到这一点。我立即想到通过将无条件跳转指令的地址设置为偶数来尝试将处理器从Thumb状态切换到ARM状态。
一个小题外话。如您所知,Cortex M3 / M4系列的微控制器使用Thumb-2汇编指令集,并且始终在Thumb模式下工作。不支持ARM模式。如果您尝试设置最低有效位被清除的无条件跳转地址(BX reg)的值,则会发生UsageFault异常,因为处理器将尝试将其状态切换为ARM。您可以在[1]中阅读有关此内容的更多信息(第2.8节“指令集”;第4.3.4节“汇编语言:调用和无条件分支”)。
首先,我建议在C / C ++中模拟无条件跳转到偶数地址。为此,我将创建func_hard_fault函数,然后在将指针地址减一之后尝试通过指针调用它。可以按照以下步骤进行:
void func_hard_fault(void);
void main(void)
{
void (*ptr_hard_fault_func) (void); //
ptr_hard_fault_func = reinterpret_cast<void(*)()>(reinterpret_cast<uint8_t *>(func_hard_fault) - 1); //
ptr_hard_fault_func(); //
while(1) continue;
}
void func_hard_fault(void) //,
{
while(1) continue;
}
让我们看看调试器我做了什么。

用红色突出显示了RON R1地址中的当前跳转指令,该地址包含偶数跳转地址。结果:

使用汇编程序插入可以更简单地执行此操作:
void main(void)
{
//
asm("LDR R1, =0x0800029A"); //- f
asm("BX r1"); // R1
while(1) continue;
}
好了,我们到了HardFault,任务完成了!
硬故障分析
我们到哪里去了HardFault?
在我看来,最重要的是找出我们从哪里到达HardFault。这并不难做到。首先,让我们为HardFault情况编写自己的处理程序。
extern "C"
{
void HardFault_Handler(void)
{
}
}现在让我们谈谈如何弄清楚我们如何到达这里。 Cortex M3 / M4处理器内核具有上下文保存[1](第9.1.1节堆栈)之类的奇妙功能。简单来说,当发生任何异常时,R0-R3,R12,LR,PC,PSR寄存器的内容都存储在堆栈中。

在这里,对我们而言最重要的寄存器将是PC寄存器,其中包含有关当前正在执行的指令的信息。由于在异常发生时将寄存器值压入堆栈,因此它将包含最后执行指令的地址。其余寄存器对于分析而言不太重要,但是可以从中获取有用的东西。 LR是最后一个转换的返回地址,R0-R3,R12是可以告诉移动方向的值,PSR只是程序状态的通用寄存器。
我建议找出处理程序中寄存器的值。为此,我编写了以下代码(在制造商的文件之一中看到了类似的代码):
extern "C"
{
void HardFault_Handler(void)
{
struct
{
uint32_t r0;
uint32_t r1;
uint32_t r2;
uint32_t r3;
uint32_t r12;
uint32_t lr;
uint32_t pc;
uint32_t psr;
}*stack_ptr; // (SP)
asm(
"TST lr, #4 \n" // 3 ( )
"ITE EQ \n" // 3?
"MRSEQ %[ptr], MSP \n" //,
"MRSNE %[ptr], PSP \n" //,
: [ptr] "=r" (stack_ptr)
);
while(1) continue;
}
}
结果,我们有了所有保存的寄存器的值:
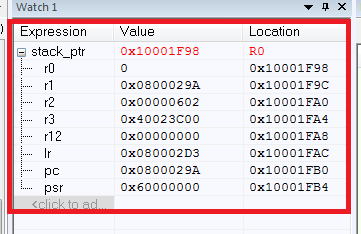
这里发生了什么?首先,我们获得了堆栈指针stack_ptr,这里的所有内容都很清楚。汇编程序的插入会出现困难(如果需要了解Cortex的汇编说明,那么我建议[2])。
为什么我们不只通过MRS MSP stack_ptr保存堆栈?事实是,Cortex M3 / M4内核有两个堆栈指针[1](项目3.1.3堆栈指针R13)-主MSP堆栈指针和PSP进程堆栈指针。它们用于不同的处理器模式。我不会深入研究它的作用以及它是如何工作的,但我会给出一些解释。
要找出处理器工作模式(用于此MSP或PSP),您需要检查通信寄存器的第三位。该位确定使用哪个堆栈指针从异常中返回。如果该位置1,则为MSP,否则为PSP。通常,大多数用C / C ++编写的应用程序仅使用MSP,并且可以省略此检查。
那么底线是什么?有了已保存寄存器的列表,我们可以轻松地从PC寄存器确定程序在HardFault中的位置。PC指向地址0x0800029A,这是我们的“中断”指令的地址。另外,不要忘记其他寄存器的值的重要性。
硬故障的原因
实际上,我们也可以找出造成HardFault的原因。两个寄存器可以帮助我们。硬故障状态寄存器(HFSR)和可配置故障状态寄存器(CFSR; UFSR + BFSR + MMFSR)。 CFSR寄存器由三个寄存器组成:使用故障状态寄存器(UFSR),总线故障状态寄存器(BFSR),内存管理故障地址寄存器(MMFSR)。您可以在[1]和[3]中阅读有关它们的信息。
我建议看看这些寄存器在我的情况下将产生什么:

首先,将HFSR FORCED位置1。这意味着发生了无法处理的故障。为了进一步诊断,应检查其余的故障状态寄存器。
其次,将CFSR INVSTATE位置1。这意味着发生了UsageFault,因为处理器试图执行非法使用EPSR的指令。
什么是EPSR? EPSR-执行程序状态寄存器。这是一个内部PSR寄存器-一个特殊的程序状态寄存器(我们记得,它存储在堆栈中)。该寄存器的第二十四位指示处理器的当前状态(Thumb或ARM)。这可以确定我们失败的原因。让我们尝试数一下:
volatile uint32_t EPSR = 0xFFFFFFFF;
asm(
"MRS %[epsr], PSP \n"
: [epsr] "=r" (EPSR)
);
作为执行的结果,我们得到的值EPSR =0

。事实证明该寄存器显示ARM的状态,并且我们找到了失败的原因?并不是的。实际上,根据[3](第23页),使用特殊的MSR命令读取该寄存器总是返回零。我不太清楚为什么会这样工作,因为该寄存器已经是只读的,但是在这里它不能被完全读取(只能通过xPSR使用某些位)。也许这些是一些体系结构上的限制。
结果,不幸的是,所有这些信息几乎没有给普通的MK程序员任何帮助。这就是为什么我将所有这些寄存器仅视为对存储上下文分析的补充。
但是,例如,如果故障是由于被零除引起的(通过将CCR寄存器的DIV_0_TRP位置1允许此故障),则CFSR寄存器中的DIVBYZERO位将被置位,这将向我们指出这种故障的原因。
下一步是什么?
在分析了故障原因之后该怎么办?以下过程似乎是一个不错的选择:
- 将所有已分析寄存器的值打印到调试控制台(printf)。仅当您具有JTAG调试器时才能执行此操作。
- 将故障信息保存到内部或外部闪存(如果有)。也可以在设备屏幕上显示PC寄存器的值(如果有)。
- 重新加载处理器NVIC_SystemReset()。

资料来源
- 姚明 有关ARM Cortex-M3的权威指南。
- Cortex-M3设备通用用户指南。
- STM32 Cortex-M4 MCU和MPU编程手册。