在演讲中,我分享了使用Alembic(一种成熟的管理迁移工具)的经验。为什么选择Alembic,如何使用Alembic来准备迁移,如何(自动或手动)运行迁移,如何解决不可逆更改的问题,为什么要测试迁移,测试可以揭示哪些问题以及如何实现它们-我试图回答所有这些问题。同时,我分享了一些生活技巧,使在Alembic进行迁移变得轻松而愉快。
自报告发布之日起,GitHub上的代码已稍作更新,还有更多示例。如果您想完全按照幻灯片中显示的方式查看代码,请点击此处链接到该时间的提交。
- 你好!我的名字叫亚历山大,我在埃达迪尔工作。今天,我想告诉您,我们如何与迁移一起生活,以及您如何与他们一起生活。也许这可以帮助您轻松生活。
什么是迁移?
在开始之前,有必要先讨论一下总体上的迁移。例如,您有一个应用程序,并创建了几个平板电脑,以便它们可以正常工作,然后转到它们。然后,您推出一个新版本,其中的某些内容已发生更改-第一个板块已更改,第二个板块未更改,而第三个板块之前未出现,但它已经出现。

然后出现该应用程序的新版本,其中删除了一些板,其余的都没有任何反应。这是什么?我们可以说这是可以通过迁移描述的状态。当我们从一种状态迁移到另一种状态时,这是一种升级,当我们想返回时-降级。
什么是迁移?

一方面,这是更改数据库状态的代码。另一方面,这是我们开始的过程。

迁移应具备哪些属性?重要的是,我们在应用程序版本之间切换的状态是原子的。例如,如果我们希望我们有两个表,但只出现一个表,则这可能会导致生产结果不是很好。
我们必须回滚所做的更改,这一点很重要,因为如果您推出一个新版本,它不会生效,并且您无法回滚,那么通常一切都会很糟糕。
对版本进行排序也很重要,以便您可以链接它们的滚动方式。
工具类
我们如何实现这些迁移?
我想到的第一个想法是:迁移是SQL,为什么不带查询的SQL文件并用它制作SQL文件。还有其他几个模块可以使我们的生活更轻松。

如果我们看看内部发生了什么,那么确实有几个请求。可能是CREATE TABLE,ALTER等。在downgrade_v1.sql文件中,我们将其全部取消。

你为什么不这样做呢?主要是因为您需要用手进行操作。不要忘了写开始,然后提交更改。编写代码时,您将需要记住所有依赖关系以及以什么顺序执行操作。这是一项相当常规,困难且耗时的工作。
您无法防止意外启动错误的文件。您需要手动运行所有文件。如果您有15次迁移,这并不容易。您将需要调用一些psql 15次,这不会很酷。
最重要的是,您永远不知道数据库处于什么状态。您需要在纸上的某个地方写下您下载的文件,哪些没有。听起来也不是很好。

有一个yoyo-migrations模块。它支持最常见的数据库并使用原始查询。

如果我们看看他提供给我们的东西,看起来就像这样。我们看到相同的SQL。右边已经有导入yoyo库的Python代码。

因此,我们已经可以完全自动地开始迁移。换句话说,有一个命令可以创建新的迁移并将其添加到链中,以便我们可以编写SQL代码。使用命令,您可以应用一个或多个迁移,可以回滚,这已经向前迈了一步。

优点是您不再需要在纸上写下对数据库执行的请求,已启动的文件以及发生某些情况时需要回滚的位置。您具有某种万无一失的保护:您将不再能够运行为其他目的而设计的迁移,以便在数据库的其他两个状态之间进行转换。一个很大的优点:这个事情在单独的事务中完成每个迁移。这也提供了这样的保证。

缺点很明显。您仍然有原始SQL。例如,如果您的Python中有庞大的数据产生逻辑,那么您就不能使用它,因为您只有SQL。
此外,您会发现很多无法自动化的例行工作。有必要跟踪表之间的所有关系-什么可以写在什么地方,什么还不可能。通常,存在明显的缺点。
另一个值得关注的模块,今天的整个讨论是Alembic。

它具有与yoyo相同的功能,并且还有更多。它不仅监视您的迁移并知道如何创建它们,而且还允许您编写非常复杂的业务逻辑,连接整个数据生产以及Python中的任何功能。提取数据并在内部进行处理。如果您不想,就不必。
在大多数情况下,他可以为您自动编写代码。当然,并非总是如此,但是在您不得不用手书写大量内容之后,这听起来是个不错的选择。
他有很多很棒的东西。例如,SQLite不完全支持ALTER TABLE。而且Alembic的功能使您可以轻松地绕过两行,而您甚至都不会考虑它。
在前面的幻灯片中,有一个Django-migrations模块。这也是一个非常好的迁移模块。其原理在功能上可与Alembic相媲美。唯一的区别是它是特定于框架的,而Alembic不是。
SQL炼金术
由于Alembic基于SQLAlchemy,因此我建议通过SQLAlchemy进行一些操作以记住或了解它是什么。

到目前为止,我们已经研究了原始查询。原始查询还不错。这可能很好。当您有一个高负载的应用程序时,也许这正是您所需要的。无需浪费时间将某些对象转换为某种查询。
不需要其他库。您只需要驾驶员,就是这样,它可以正常工作。但是,例如,如果您编写复杂的查询,就不会那么容易:好吧,您可以获取一个常数,调出常数,然后编写大型的多行代码。但是,如果您有10-20个这样的请求,将已经很难阅读。然后,您将无法以任何方式重用它们。您有很多文本,当然还有用于处理字符串,f字符串等的函数,但这听起来并不好。他们很难读。
例如,如果您有一个要在其中查询和复杂结构的类,那么缩进是一个很大的难题。如果您想进行原始迁移,则查找grep的唯一方法就是使用它。而且您也没有用于动态查询的动态工具。
例如,一项超级简单的任务。您有一个实体,它在一个盘子里有15个场。您要发出PATCH请求。这似乎非常简单。尝试在原始查询上编写此代码。它看起来不会很漂亮,并且拉取请求不太可能被批准。

有一个替代方法-查询构建器。它肯定有缺点,因为它允许您将查询表示为Python中的对象。
您将不得不在生成请求的时间和内存上为此付出代价。但是有优点。当您编写大型,复杂的应用程序时,您需要抽象。查询构建器可以为您提供这些抽象。这些查询可以分解;稍后再看。它们可以被重用,扩展,包装在已经被称为与业务逻辑相关的友好名称的函数中。
建立动态查询非常容易。如果您需要更改某些内容,请编写迁移代码的统计分析就足够了。非常方便。
为什么仍要使用SQLAlchemy?为什么值得停下来?

这不仅是关于迁移的问题,而且是一个普遍的问题。因为当我们拥有Alembic时,立即使用整个堆栈是有意义的,因为SQLAlchemy不仅适用于同步驱动程序。也就是说,Django是一个非常酷的工具,但是Alchemy可以与asyncpg和aiopg一起使用。正如Selivanov所说,Asyncpg允许您每秒读取一百万行-从数据库读取并传输到Python。当然,使用SQLAlchemy会少一些,会有一些开销。但无论如何。
SQLAlchemy有大量的驱动程序,它知道如何使用。有Oracle和PostgreSQL,只有每种口味和颜色的一切。而且,它们已经开箱即用,如果您需要单独的东西,那么我最近发现那里甚至有Elasticsearch。是的,仅用于阅读,但是-您了解吗? -SQLAlchemy中的Elasticsearch。
有一个很好的文档,一个很大的社区。有很多图书馆。重要的是,它并不指示您使用框架和库。当您要完成需要完成的狭窄任务时,它可以成为一种工具。
那么它由什么组成呢?
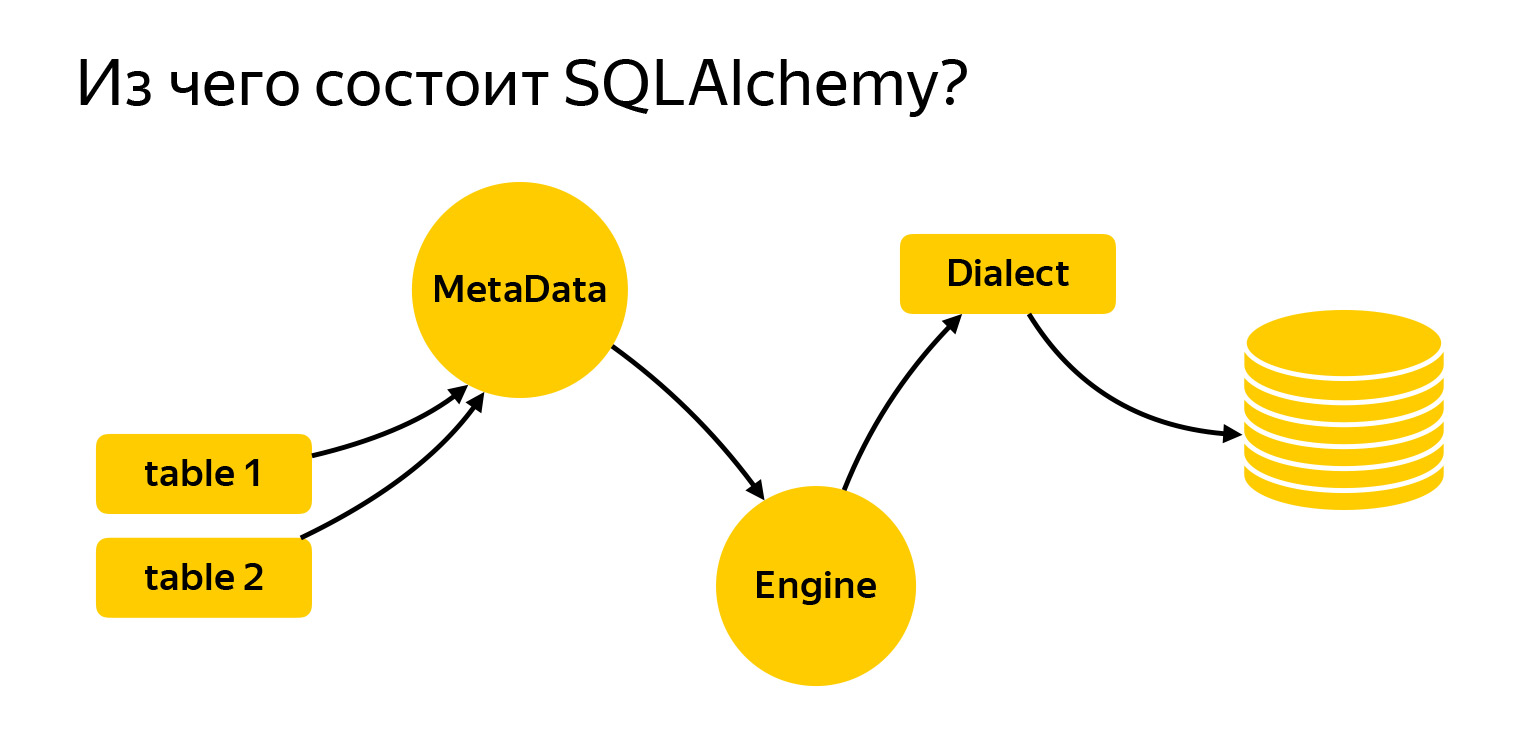
我带来了我们今天将与之合作的主要实体。这些是表。要编写请求,需要告知Alchemy它是什么以及我们正在使用什么。接下来是MetaData注册表。 Engine是连接到数据库并通过Dialect与之通信的事物。
让我们仔细看看它是什么。

MetaData是一种对象,是一个容器,您将在其中添加表,索引以及通常具有的所有实体。一方面,这是一个对象,它根据您编写的代码反映了您希望如何查看数据库。另一方面,MetaData可以转到数据库,获取实际存在的快照,然后构建此对象模型本身。
而且,MetaData对象具有一项非常有趣的功能。它允许您定义索引和约束的默认命名模板。这在编写迁移时非常重要,因为每个数据库(无论是PostgreSQL,MySQL,MariaDB)对如何调用索引都有自己的见解。
一些开发人员也有自己的愿景。 SQLAlchemy允许您一劳永逸地设置标准。我必须开发一个需要与SQLite和PostgreSQL一起使用的项目。非常方便。

看起来像这样:从SQLAlchemy导入MetaData对象,并在创建它时使用naming_convention参数指定模板,模板的键指定索引和约束的类型:ix-正则索引,uq-唯一索引,fk-外键,pk-首要的关键。
在naming_convention参数的值中,您可以指定一个模板,该模板由索引类型/约束(ix / uq / fk等)和表名组成,并用下划线分隔。在某些模板中,您也可以列出所有列。例如,不必对主键执行此操作,只需指定表名即可。
当您开始制作新项目时,只需将命名模板添加到其中就可以了。从那时起,所有迁移都使用相同的索引和约束名称生成。
由于另一个原因,这很重要:当您决定在对象模型中不再需要该索引并删除它时,Alembic将知道它的名称并正确生成迁移。这已经是可靠性的一定保证,一切都会按预期进行。
您必须遇到的另一个非常重要的实体是表,该对象描述了表所包含的内容。

该表具有名称,具有数据类型的列,并且它必须引用MetaData注册表,因为MetaData是您描述的所有内容的注册表。并且有带有数据类型的列。
由于我们已经描述了,SQLAlchemy现在可以并且知道很多。如果我们在此处指定了外键,她仍然会知道我们的表如何相互连接。她会知道需要执行的顺序。

SQLAlchemy也具有引擎。重要提示:我们所说的关于请求的内容可以单独使用,而Engine可以单独使用。您可以一起使用所有内容,没有人禁止。也就是说,引擎知道如何直接连接到服务器,并为您提供完全相同的接口。不,当然,不同的驱动程序会尝试遵守DBAPI,Python中有一个PEP会提出建议。但是Engine为所有数据库提供了完全相同的界面,非常方便。

最后一个重要的里程碑是方言。引擎就是这样与不同的数据库进行通信的。这里有不同的语言,不同的人和不同的方言。
让我们看看这是干什么的。

这就是常规插入的外观。如果要添加新行,即前面所述的板,其中有一个ID和电子邮件字段,在这里我们指定电子邮件,执行插入操作,并立即取回我们插入的所有内容。
如果我们要添加多行怎么办?没问题。

您可以在此处简单地传输听写列表。看起来像是一些超级简单笔的完美代码。数据进入,通过某种验证,某种JSON模式,就是这样,进入了数据库。超级容易。
一些查询非常复杂。有时甚至可以通过打印来查看请求,有时您必须对其进行编译。这并不困难。炼金术可以完成所有这些工作。在这种情况下,我们已经编译了请求,您可以看到实际上将要飞入数据库的内容。

数据请求看起来非常简单。从字面上看,两行甚至可以写成一行。

让我们回到有关如何例如为15个字段编写PATCH请求的问题。在这里,您应该只写字段名称,其键和值。这就是所需要的。没有文件,没有字符串构建,什么都没有。听起来很方便。
也许我每天在工作中使用的最重要的Alchemy功能是查询分解和扩展。

假设您正在PostgreSQL中编写一个接口,则您的应用程序必须以某种方式授权一个人并使他能够执行CRUD。好吧,分解不多。
当您编写使用数据版本控制,一堆不同抽象的非常复杂的应用程序时,将生成的查询可能包含大量子查询。子查询与子查询结合在一起。有不同的任务。有时查询分解有很大帮助,它可以将逻辑和代码设计区分开。
为什么会这样工作?例如,当您调用users_table.select()方法时,它将返回一个对象。当对结果对象调用任何其他方法时,例如where(),它将返回一个全新的对象。所有查询对象都是不可变的。因此,您可以在任何喜欢的东西之上进行构建。
从阿勒比比奇迁移
因此,我们已经处理了SQLAlchemy,现在终于可以编写Alembic迁移了。

使用Alembic入门并不困难,特别是如果您已经如前所述描述了表并指定了MetaData对象。您只需pip安装alembic,将其称为alembic init alembic。 alembic-模块的名称,这是命令行,您将拥有它。 init是一个命令。最后一个参数是要放入的文件夹。
当您调用此命令时,您将有几个文件,我们现在将对其进行详细介绍。

alembic.ini中将进行常规配置。 script_location正是您想要的位置。接下来,将有一个模板,用于您将生成的迁移的名称以及用于连接到数据库的信息。

还有一个用于新迁移的模板。您说:“我想要一个新的迁移”,Alembic将根据某个模板创建它。您可以自定义所有这些,这非常简单。您进入该文件并编辑所需的内容。可以在此处指定的所有变量都在文档中。这是第一部分。顶部有某种注释,以便您轻松查看那里发生的情况。然后在每次迁移中都有一组变量-版本,down_revision。今天我们将与他们合作。进一步-其他元信息。

最重要的方法是升级和降级。在这里,Alembic将替代MetaData对象在您的模式描述与数据库中的内容之间发现的任何差异。

env.py是Alembic中最有趣的文件。它控制命令执行的进度,并允许您自定义它。您可以在此文件中连接MetaData对象。如前所述,MetaData对象是数据库中所有实体的注册表。
您将在此处连接此MetaData对象。从那时起,Alembic知道这里是我的模型,这里是我的盘子。他知道自己在做什么。接下来,Alembic拥有一个离线或在线调用Alembic的代码。我们现在还将考虑所有这一切。
这正是您需要在项目中连接MetaData的那一行。不用担心,如果不是很清楚,我将所有内容收集到一个项目中,并将其发布在GitHub上。您可以克隆它并看到它,感受一下一切。

什么是在线模式?在联机模式下,Alembic连接到alembic.ini文件的sqlalchemy.url参数中指定的数据库,并开始运行迁移。
我们为什么要看这段代码? Alembic可以非常灵活地进行定制。
想象一下,您有一个需要在不同数据库模式中运行的应用程序。例如,您希望一次运行许多应用程序实例,并且每个实例都生活在自己的方案中。这既方便又必要。
它根本不会花费您任何费用。调用context.begin_transaction()方法后,您可以编写命令“ SET search_path = SCHEMA”,该命令将告诉PostgreSQL使用其他默认模式。就这样。从现在开始,您的应用程序将生活在一个完全不同的方案中,迁移将迁移到一个不同的方案中。这是一个单行的问题。

还有一个离线模式。请注意,此处Alembic不使用Engine。您只需在此处将链接传递给他。当然,您也可以传输引擎,但是它无法在任何地方连接。它只是生成原始查询,然后可以在某个地方执行。

因此,您拥有Alembic和一些带有表的MetaData。最后,您想为自己生成迁移。您执行此命令,基本上就是这样。 Alembic将进入数据库并查看其中的内容。是否有他的特殊标签“ alembic_versions”,可以告诉您迁移已在该数据库中推出?将看到那里存在什么表。将在数据库中看到您需要什么数据。它将分析所有这些内容,仅基于此模板生成一个新文件,然后进行迁移。当然,您绝对应该查看迁移中生成的内容,因为Alembic并不总是生成所需的内容。但大多数情况下它都能正常工作。

我们产生了什么?有一个用户标志。当我们生成迁移时,我指出了初始消息。迁移将使用先前在alembic.ini中指定的其他模板命名为initial.py。
另外,这里还提供有关此迁移拥有的ID的信息。 down_revision = None-这是第一次迁移。
下一张幻灯片将是最重要的部分:升级和降级。

在升级中,我们看到正在创建一个板。在降级中,此标志被删除。默认情况下,Alembic专门添加此类注释,以便您去那里进行编辑,至少删除这些注释。为了以防万一,我们检查了迁移情况,确保一切适合您。这是一个团队的事。您已经有迁移。

之后,您很可能希望应用此迁移。再简单不过了。您只需要说:Alembic升级头。他将绝对运用一切。
如果我们说“ head”,它将尝试更新为最新的迁移。如果我们命名特定的迁移,它将进行更新。
还有一个降级命令-例如,如果您改变主意。所有这些都是在事务中完成的,并且工作非常简单。

因此,您有了迁移,您知道如何运行它们。例如,您有一个应用程序,并且在询问以下问题:我有配置项,正在运行测试,甚至不知道是否要自动运行迁移?也许最好用手来做?
这里有不同的观点。可能值得遵循以下规则:如果您不具有从数据库访问汽车的便捷访问能力,那么自动执行此操作当然更好。
如果您具有访问权限,那么您就可以在云中运行一项服务,并且可以从一台随身携带的笔记本电脑上去那里,然后您就可以自己做,从而给自己带来更多的控制权。
通常,有许多工具可以自动执行此操作。例如,在相同的Kubernetes中。有init容器可以执行此操作,您可以在其中运行这些命令。您可以将启动命令直接添加到Docker来执行此操作。
您只需要考虑:如果您自动应用迁移,则需要考虑例如回滚但不能回滚时会发生什么。例如,您有一个500 GB的数据板。您认为:好的,业务逻辑不再需要此数据,您可以删除它。他们把它丢了。或更改了列的类型,这随数据丢失而改变。例如,有一排很长的线,但是却变短了。或有些东西不见了。或者您已删除一列。即使您愿意,也无法回滚。
一次我制作了用于本地的产品,这些产品通过exe文件直接放在机器上。理解之后:是的,您编写了迁移,它已经投入生产,人们已经安装了它。在接下来的五年中,根据SLA,它可能对他们有用,而您想要更改某些内容,则可能会更好。此刻,您正在考虑如何应对不可逆转的变化。

这里也没有火箭科学。这样做的想法是,您可以避免尽可能多地使用这些列或表。停止联系他们。例如,您可以在ORM中使用特殊的修饰符标记字段。他会在日志中说您似乎不想触及该字段,但您仍在指他。只需在待办事项列表中创建一个任务并将其删除即可。
您(如果有的话)将有时间回滚。如果一切顺利,您将在以后的积压中冷静地执行此任务。进行另一次迁移,实际上将删除所有内容。
现在最重要的问题是:为什么以及如何测试迁移?

这是由我问过的一些人完成的。但是最好这样做。这是一条用痛苦,血液和汗水写成的规则。在生产中使用迁移总是有风险的。您永远不知道它会如何结束。在配置了CI的情况下,即使是在完全正常运行的生产环境中进行很好的迁移也可能会引起麻烦。
事实是,在测试迁移时,您甚至可以下载例如阶段或生产的某些部分。生产可能很大,您不能完全下载它进行测试或其他任务。通常,开发基地不是真正的生产基地。这些年来,他们没有太多的积累。

当我们迁移某些东西时,这可能是损坏的数据,也可能是使数据进入不一致状态的旧软件。如果有人忘记添加外键,它也可能是隐含的依赖项。他认为它是连接的,但例如,他的同事对此一无所知。这些字段也很偶然地被称为,它们之间是完全不清楚的。
然后有人决定直接向生产中添加某种索引,因为“它现在变慢了,但是如果开始运行得更快呢?”也许我在夸大其词,但实际上人们有时有时会在数据库中更改某些内容。
当然,架构迁移中的工具也有错误。老实说,我还没有遇到过。通常存在前三个问题。在有关如何传输数据的假设中可能还有更多错误。
当您有一个非常大的对象模型时,很难牢记所有内容。很难不断编写最新文档。最新的文档是您的代码,它并不总是具有完全书面的业务逻辑:什么以及如何工作,谁想到了什么。

我们可以检查什么?至少是迁移开始的事实。这已经很棒。而且代码中没有愚蠢的错别字。我们可以检查是否存在有效的downgrade()方法,downgrade()方法删除SQLAlchemy创建的所有数据类型。
SQLAlchemy做很多很好的事情。例如,当您描述一个表并指定一个Enum列类型时,SQLAlchemy将自动在PostgreSQL中为该枚举创建一个数据类型。但是,将不会自动生成在downgrade()方法中删除此数据类型的代码。
您需要记住并检查一下:当您想回滚并重新应用迁移时,尝试在upgrade()方法中创建现有数据类型的尝试将引发异常。最重要的是,如果迁移更改了任何数据,则需要在升级中检查数据是否正确更改。而且非常重要的是检查它们在降级时是否可以正确回滚而没有副作用。

在继续测试之前,让我们看看如何为编写测试做最好的准备。我已经看到许多解决方法。有人创建了一个底座,板,然后编写了一个夹具,将其清理干净,使用某种自动应用的夹具。但是,保护您100%并在完全隔离的空间中运行测试的理想方法是创建一个单独的数据库。
有一个很棒的sqlalchemy_utils模块可以创建和删除数据库。在PostgreSQL中,他还检查:如果其中一个客户端入睡并且没有断开连接,则他不会因“有人正在使用数据库,我无法执行任何操作,无法删除它”的错误而崩溃。取而代之的是,他将冷静地查看谁与他们建立了连接,断开这些客户端的连接并冷静地删除基础。
建立数据库并将迁移应用于每个测试并不总是一个快速的过程。这可以通过以下方式解决:PostgreSQL支持从模板创建新数据库,因此您可以将数据库准备分为两个固定装置。
第一个夹具运行一次以运行所有测试(作用域=会话),创建数据库并对其进行迁移。第二个夹具(scope = function)基于第一个夹具的基准直接为每个测试创建基准。
从模板创建数据库非常快速,并节省了为每个测试应用迁移的时间。

如果我们只是在谈论如何临时创建数据库,那么我们可以编写这样的装置。这里发生了什么?我们将生成一个随机名称。我们以防万一,在pytest的末尾添加了一个,以便当我们通过Postico进入localhost时,我们可以了解测试是由什么创建的,不是由测试创建的。
然后,我们从该链接生成有关连接到数据库的信息,该人向其显示了一个新的数据库,该数据库已经存在。我们创建它,然后将其发送给测试。一个人使用此数据库后,我们将其删除。

我们还可以准备引擎以连接到该数据库。也就是说,在此固定装置中,我们将之前的固定装置用作依赖项。我们创建一个引擎并将其发送到测试。

那么我们可以编写哪些测试?第一次测试只是我同事的一项杰出发明。自从出现以来,我想我已经忘记了迁移方面的问题。
这是一个非常简单的测试。您一次将其添加到您的项目。它在GitHub上的项目中...您可以将其拖给您,添加并忘记大约80%的问题。
它做的很简单:它获取所有迁移的列表,并开始遍历它们。调用升级,降级,升级。

例如,我们有五个迁移。让我们看看它是如何工作的。这是第一次迁移。我们已经实现了。回滚第一个迁移,然后再次运行。这里发生了什么?实际上,我们在这里看到一个人正确地实现了downgrade()方法,因为例如不可能两次创建表。
我们看到,如果一个人创建了某些类型的数据,他也将其删除了,因为没有错别字,并且总的来说,它至少可以以某种方式起作用。
然后测试继续进行。他进行了第二次迁移,立即运行,向后退一步,再次向前。这与您进行迁移一样多。
该测试的目的是发现更改数据结构时的基本错误和问题。
楼梯从空旷的地方开始,通常非常快。也就是说,此测试更多地是关于数据结构的。这与更改迁移中的数据无关。但总体而言,它可以很好地挽救您的生命。
如果您想快速解决问题,就是这样。这条规则是。根据经验:将其插入您的项目中,对您来说变得更加容易。

这个测试看起来像这样。我们获得所有修订,生成Alembic配置。这是我们之前看到的alembic.ini文件,这里是get_alembic_config函数,它将读取该文件,并向其中添加临时库,因为在此我们指定了库的路径。之后,我们可以使用Alembic命令。
先前执行的命令-Alembic升级头-也可以安全地导入。不幸的是,这张幻灯片并不适合所有进口,但请相信我。它只是从alembic.com导入升级而来。您在那里翻译配置,说到升级的地方。然后说:降级。
使用降级,迁移将回滚到down_revision,即以前的版本或“ -1”。
“ -1”是告诉Alembic回滚当前迁移的另一种方法。当第一次迁移开始时,它非常相关,它的down_revision为None,而Alembic API不允许将None传递给downgrade命令。
然后,再次运行upgrade命令。
现在让我们谈谈如何用数据测试迁移。

数据迁移通常看起来很简单,但最不利。看来您可以写一个选择,插入,从一个表中获取数据,然后以略有不同的格式将其传输到另一个表中,这会更简单吗?
关于此测试,还有一点要说,与之前的测试不同,它的开发非常昂贵。当我进行大型迁移时,有时我花了六个小时才能查看所有不变量,可以描述所有内容。但是当我已经在进行这些迁移时,我很平静。

此测试如何进行?这个想法是,我们将所有迁移应用到我们现在要测试的迁移中。我们将要更改的一组数据插入数据库。我们可以考虑插入可以隐式更改的其他数据。然后我们升级。我们检查数据是否正确更改,执行降级并检查数据正确更改。

该代码看起来像这样。也就是说,也有一个通过修订的参数化,有一组参数。我们在这里接受我们的引擎,接受我们要开始测试的迁移。
然后是rev_head,这是我们要测试的内容。然后是三个回调。这些是我们在某处定义的回调,完成后将调用它们。我们可以检查那里发生了什么。
在哪里可以看到示例?
我将所有内容打包到GitHub上的示例中。那里确实没有很多代码,但是很难将其添加到幻灯片中。我试图忍受最基本的。您可以转到GitHub并查看其在项目本身中的工作方式,这是最简单的方法。
还有什么值得注意的?在启动期间,Alembic在启动它的文件夹中寻找alembic.ini配置文件。当然,您可以使用环境变量ALEMBIC_CONFIG指定路径,但这并不总是很方便且显而易见。
另一个问题:在alembic.ini中指定了用于连接数据库的信息,但是通常您需要能够依次使用多个数据库。例如,将迁移部署到阶段,然后进行生产。通常,您可以在SQLALCHEMY_URL环境变量中指定连接信息,但这对于软件的最终用户来说不是很明显。
最终用户使用“ $ project $ -db”实用程序比“ alembic”更加直观。
当您查看项目中的示例时,请查看staff-db实用程序。它是Alembic的薄包装,也是为您定制Alembic的另一种方法。默认情况下,它将在项目中相对于其位置查找alembic.ini文件。从用户称呼她的任何文件夹中,她自己都可以找到配置文件。另外,staff-db添加了一个参数--db-url,您可以使用它指定连接数据库的信息。而且,重要的是,可以通过传递公认的--help选项来查看它。毕竟,该实用程序的名称很直观。
所有可执行的项目命令均以“ staff”模块的名称开头:运行REST API的staff-api和管理基本状态的staff-db。了解此模式后,客户端将写下您的程序的名称,即使他忘记了全名,也可以通过按TAB键查看所有可用的实用程序。我有一切,谢谢。