您可以手动完成此操作,但是也有一些框架和库可以使此过程更快,更轻松。我们将讨论
其中之一,featuretools,以及使用它的实践经验。

最时尚的管道
你好!我是Alexander Loskutov,我在Leroy Merlin担任数据分析师,或者,现在流行起来,是数据科学家。我的职责包括处理数据,从分析查询和卸载开始,以训练模型结束,例如将其包装在服务中,设置代码的交付和部署以及监视其工作。
撤消预测是我正在研究的产品之一。
产品目标:预测客户取消在线订单的可能性。借助这种预测,我们可以确定应该先致电哪个客户下订单以确认订单,而根本不致电谁。首先,通过电话进行呼叫和确认客户订单的事实减少了取消的可能性,其次,如果我们打电话而对方拒绝,则可以节省资源。员工将腾出更多的时间来收集订单。另外,这种方式将产品保留在货架上,并且如果此时商店中的顾客需要它,他将能够购买。这将减少在以后取消的订单中收集的,没有出现在货架上的货物数量。
先驱者
对于产品试点,我们仅接受后付订单以在多家商店提货。
现成的解决方案的工作原理是这样的:接到订单后,借助Apache NiFi,我们可以获取有关订单的信息,例如提取货物数据。然后,所有这些都通过Apache Kafka消息代理传递到用Python编写的服务。该服务计算订单的特征,然后为其使用机器学习模型,从而给出了取消的可能性。之后,根据业务逻辑,无论是否需要立即致电客户,我们都会准备一个答案(例如,如果订单是在商店内部的员工帮助下进行的,或者订单是在晚上进行的,则您不应致电)。
看来,是什么阻止了连续打电话给所有人?事实是,我们的电话资源有限,因此了解谁应该打电话以及谁不打电话就可以接他们的订单非常重要。
模型开发
我参与了服务,模型以及模型功能的计算,这将进一步讨论。
在训练过程中计算特征时,我们使用三个数据源。
- 带有订单元信息的板块:订单号,时间戳,客户设备,交付方式,付款方式。
- 收据中带有位置的板块:订单号,商品,价格,数量,库存商品数量。每个位置在单独的行上。
- 表格-商品参考书:文章,带有商品类别,度量单位,描述的几个字段。
使用标准的Python方法和pandas库,您可以轻松地将所有表组合成一个大表,然后使用groupby,您可以计算各种属性,例如按订单,按产品的历史记录,按产品类别等的聚合。但是这里存在一些问题。
- 计算的并行性。标准groupby在一个线程中工作,并且在大数据(最多1000万行)上,一百个功能被认为是不可接受的太长,而其余核心的容量则处于空闲状态。
- 代码量:每个这样的请求都需要分别编写,检查正确性,然后仍然需要收集所有结果。这需要花费时间,尤其是考虑到某些计算的复杂性-例如,计算收据中某项商品的最新历史记录并汇总订单的这些特征。
- 如果您手工编写所有代码,则可能会犯错误。
当然,“我们用手工编写所有内容”的好处是完全的行动自由,您可以发挥自己的想象力。
问题出现了:如何优化这部分工作。一种解决方案是使用featuretools库。
在这里,我们已经在继续本文的实质,即图书馆本身及其使用的实践。
为什么选择功能工具?
让我们以板块的形式考虑各种机器学习框架(图片本身是从这里真实地被窃取的,可能并没有在其中全部显示出来,但仍然可以看到):
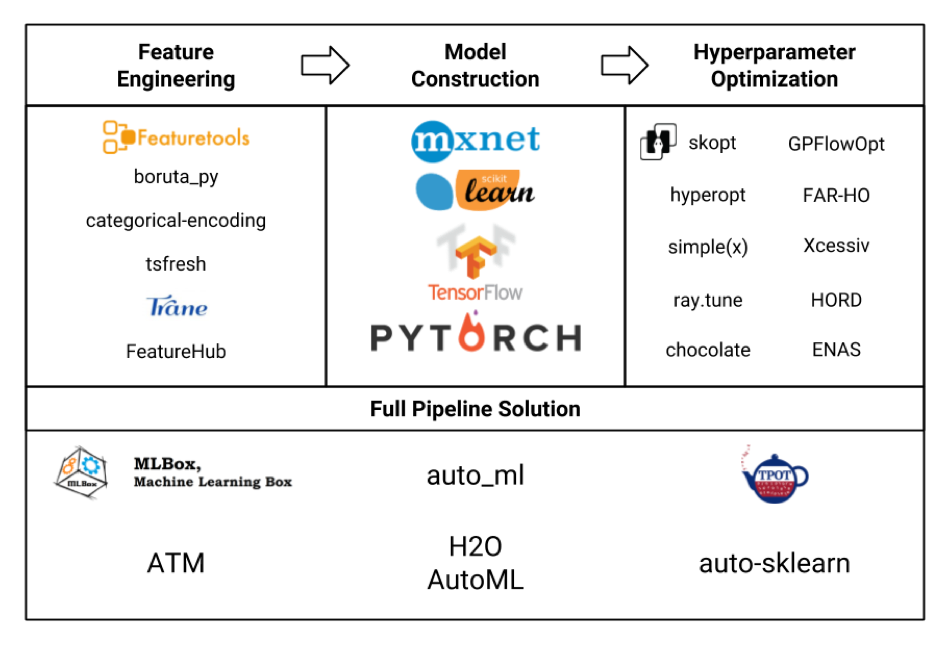
我们主要对Feature Engineering模块感兴趣。如果我们查看所有这些框架和软件包,结果发现featuretools是其中最复杂的,甚至包括tsfresh之类的其他一些库的功能。
另外,featuretools的优点(根本不做广告!)包括:
- 开箱即用的并行计算
- 开箱即用的许多功能
- 定制的灵活性-可以考虑相当复杂的事情
- 考虑不同表之间的关系(关系)
- 更少的代码
- 犯错误的可能性较小
- 本身,一切都是免费的,无需注册和短信(但带有pypi)
但这不是那么简单。
- 该框架需要一些学习,完全掌握将花费相当长的时间。
- 它没有这么大的社区,尽管最受欢迎的问题仍然很好。
- 使用本身也需要注意,以免不必要地增加特征空间,也不会增加计算时间。
训练
我将提供一个功能部件配置示例。
接下来,将有一个带有简要说明的代码,其中更详细地介绍了功能工具,其类,方法,功能,您可以在框架网站的文档中阅读其他内容。如果您对实际应用的示例感兴趣,并演示了一些实际任务中的有趣可能性,那么请在注释中写下,也许我会写下另一篇文章。
所以。
首先,您需要创建EntitySet类的对象,该对象包含具有数据的表并了解它们之间的关系。
让我提醒您,我们有三个包含数据的表:
- orders_meta(订单元信息)
- orders_items_lists(有关订单项的信息)
- 项目(文章及其属性的引用)
我们编写(此外,仅使用3个存储的数据):
import featuretools as ft
es = ft.EntitySet(id='orders') # EntitySet
# pandas.DataFrame- (ft.Entity)
es = es.entity_from_dataframe(entity_id='orders_meta',
dataframe=orders_meta,
index='order_id',
time_index='order_creation_dt')
es = es.entity_from_dataframe(entity_id='orders_items',
dataframe=orders_items_lists,
index='order_item_id')
es = es.entity_from_dataframe(entity_id='items',
dataframe=items,
index='item',
variable_types={
'subclass': ft.variable_types.Categorical
})
#
# -,
# -
relationship_orders_items_list = ft.Relationship(es['orders_meta']['order_id'],
es['orders_items']['order_id'])
relationship_items_list_items = ft.Relationship(es['items']['item'],
es['orders_items']['item'])
#
es = es.add_relationship(relationship_orders_items_list)
es = es.add_relationship(relationship_items_list_items)

万岁!现在,我们有了一个可以让我们计算各种符号的对象。
我将提供一个用于计算相当简单的特征的代码:对于每个订单,我们将计算商品价格和数量的各种统计数据,并按时间计算几个特征,并按顺序排列最频繁的商品和商品类别(对数据执行各种转换的函数在featuretools中称为原语) ...
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'],
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)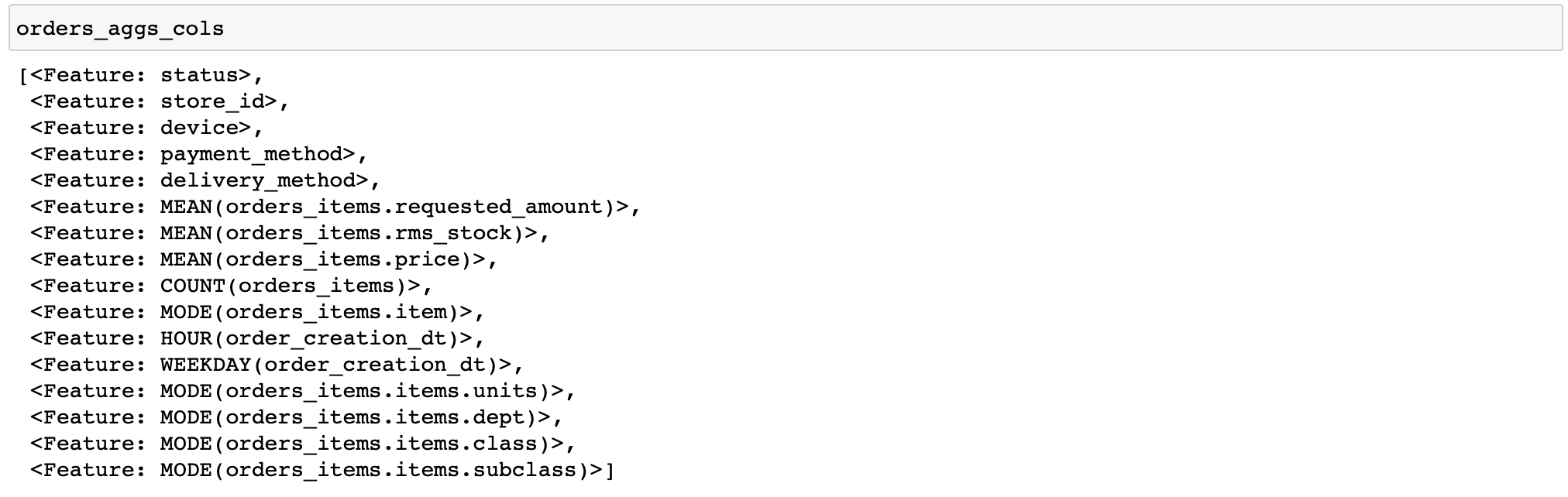

此处的表中没有布尔列,因此未应用任何原语。通常,featuretools本身分析数据类型并仅应用适当的功能是很方便的。
另外,我只手动指定了几个订单进行计算。这使您可以快速调试计算(如果配置错误,该怎么办)。
现在,让我们向功能中添加更多聚合,即百分位数。但是Featuretools没有内置的基元来计算它们。因此,您需要自己编写。
from featuretools.variable_types import Numeric
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
def percentile05(x: pandas.Series) -> float:
return numpy.percentile(x, 5)
def percentile25(x: pandas.Series) -> float:
return numpy.percentile(x, 25)
def percentile75(x: pandas.Series) -> float:
return numpy.percentile(x, 75)
def percentile95(x: pandas.Series) -> float:
return numpy.percentile(x, 95)
percentiles = [percentile05, percentile25, percentile75, percentile95]
custom_agg_primitives = [make_agg_primitive(function=fun,
input_types=[Numeric],
return_type=Numeric,
name=fun.__name__)
for fun in percentiles]
并将它们添加到计算中:
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'] + custom_agg_primitives,
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)然后一切都一样。到目前为止,一切都非常简单和容易(当然,相对而言)。
如果我们要保存特征计算器并在模型执行阶段即在服务中使用它,该怎么办?
战斗中的功能工具
这是主要困难开始的地方。
要计算收到订单的特征,您将不得不再次创建EntitySet来执行所有操作。如果对于大型表,将pandas.DataFrame对象放入EntitySet中似乎很正常,然后从一行开始对DataFrame执行类似的操作(表中有更多带有检查项的操作,但平均每个检查有3.3个位置,这是不够的)-不是很多。毕竟,此类对象的创建和计算在其帮助下不可避免地会产生额外的开销,即不可移动的操作数量,例如在创建任何大小的对象时进行内存分配和初始化或在同时计算多个功能时进行并行化处理本身。
因此,在我们的产品功能工具中,在“一次订购一次”的操作方式下,效率最高,平均服务响应时间为75%(取决于硬件,平均为150-200 ms),因此效率最高。为了进行比较:使用现成功能的Catboost计算预测需要3%的服务响应时间,即不超过10毫秒。
此外,使用自定义原语还有另一个陷阱。事实是,我们不能简单地将包含我们创建的图元的类的对象保存在pickle中,因为后者不会被腌制。
那么,为什么不使用内置的save_features()函数,该函数可以保存FeatureBase对象的列表,包括我们创建的基元呢?
它将保存它们,但是如果我们不提前再次创建它们,以后将无法使用load_features()函数读取它们。也就是说,从理论上讲,我们应该从磁盘读取的原语,我们首先会再次创建,这样就不再使用它们。
看起来像这样:
from __future__ import annotations
import multiprocessing
import pickle
from typing import List, Optional, Any, Dict
import pandas
from featuretools import EntitySet, dfs, calculate_feature_matrix, save_features, load_features
from featuretools.feature_base.feature_base import FeatureBase, AggregationFeature
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
# -
# ,
#
#
# ( ),
# ,
class AggregationFeaturesCalculator:
def __init__(self,
target_entity: str,
agg_primitives: List[str],
custom_primitives_params: Optional[List[Dict[str, Any]]] = None,
max_depth: int = 2,
drop_contains: Optional[List[str]] = None):
if custom_primitives_params is None:
custom_primitives_params = []
if drop_contains is None:
drop_contains = []
self._target_entity = target_entity
self._agg_primitives = agg_primitives
self._custom_primitives_params = custom_primitives_params
self._max_depth = max_depth
self._drop_contains = drop_contains
self._features = None # ( ft.FeatureBase)
@property
def features_are_built(self) -> bool:
return self._features is not None
@property
def features(self) -> List[AggregationFeature]:
if self._features is None:
raise AttributeError('features have not been built yet')
return self._features
#
def build_features(self, entity_set: EntitySet) -> None:
custom_primitives = [make_agg_primitive(**primitive_params)
for primitive_params in self._custom_primitives_params]
self._features = dfs(
entityset=entity_set,
target_entity=self._target_entity,
features_only=True,
agg_primitives=self._agg_primitives + custom_primitives,
trans_primitives=[],
drop_contains=self._drop_contains,
max_depth=self._max_depth,
verbose=False
)
# ,
#
@staticmethod
def calculate_from_features(features: List[FeatureBase],
entity_set: EntitySet,
parallelize: bool = False) -> pandas.DataFrame:
n_jobs = max(1, multiprocessing.cpu_count() - 1) if parallelize else 1
return calculate_feature_matrix(features=features, entityset=entity_set, n_jobs=n_jobs)
#
def calculate(self, entity_set: EntitySet, parallelize: bool = False) -> pandas.DataFrame:
if not self.features_are_built:
self.build_features(entity_set)
return self.calculate_from_features(features=self.features,
entity_set=entity_set,
parallelize=parallelize)
#
# ,
# save_features()
#
@staticmethod
def save(calculator: AggregationFeaturesCalculator, path: str) -> None:
result = {
'target_entity': calculator._target_entity,
'agg_primitives': calculator._agg_primitives,
'custom_primitives_params': calculator._custom_primitives_params,
'max_depth': calculator._max_depth,
'drop_contains': calculator._drop_contains
}
if calculator.features_are_built:
result['features'] = save_features(calculator.features)
with open(path, 'wb') as f:
pickle.dump(result, f)
#
@staticmethod
def load(path: str) -> AggregationFeaturesCalculator:
with open(path, 'rb') as f:
arguments_dict = pickle.load(f)
# ...
if arguments_dict['custom_primitives_params']:
custom_primitives = [make_agg_primitive(**custom_primitive_params)
for custom_primitive_params in arguments_dict['custom_primitives_params']]
features = None
#
if 'features' in arguments_dict:
features = load_features(arguments_dict.pop('features'))
calculator = AggregationFeaturesCalculator(**arguments_dict)
if features:
calculator._features = features
return calculator在load()函数中,您必须创建将不使用的原语(声明custom_primitives变量)。但是,如果没有此操作,则在调用load_features()函数的位置进行的进一步功能加载将失败,并出现RuntimeError:模块“ featuretools.primitives.base.aggregation_primitive_base”中的Primitive“ percentile05”。
事实证明不是很合乎逻辑,但是可以工作,并且您可以保存已经绑定到某种数据格式的计算器(因为功能绑定到为其计算的EntitySet,尽管没有值本身)和只保存给定基元列表的计算器。
也许将来会对此进行纠正,并且可以方便地保存任意一组FeatureBase对象。
那为什么要使用它呢?
因为从开发时间的角度来看,它很便宜,而现有负载下的响应时间却适合我们的SLA(5秒)。
但是,您应该意识到,对于必须快速响应频繁接收到的请求的服务,使用功能工具而不使用诸如异步调用之类的其他“蹲坐”将是有问题的。
这是我们在学习和推理阶段使用功能工具的经验。
该框架非常适合作为快速计算大量训练功能的工具,它大大减少了开发时间并减少了出错的可能性。
是否在退出阶段使用它取决于您的任务。