
解决Python中的数据科学问题并不容易
为什么?现有工具不太适合解决与时间序列有关的问题,并且这些工具很难彼此集成。 Scikit-learn的方法假定数据以表格格式构建,并且每一列均包含独立且均等分布的随机变量-与时间序列数据无关的假设。包含用于机器学习和按时间序列工作的模块的软件包(例如statsmodels)并不是很好的朋友。此外,现有程序包中没有许多具有时间序列的重要操作,例如将数据按时间间隔分为训练和测试集。
为了解决类似的问题,创建了sktime。

GitHub上的Sktime库徽标
Sktime是Python中的开放源代码机器学习工具包,专门用于处理时间序列。该项目是由英国经济与社会研究理事会,消费者数据研究和艾伦·图灵研究所开发并资助的社区。
Sktime扩展了scikit-learn API,用于解决时间序列问题。它包含所有必需的算法和转换工具,可有效解决时间序列回归,预测和分类问题。该库包含其他流行库中找不到的特殊机器学习算法和时间序列的转换方法。
Sktime旨在与scikit学习一起使用,可以轻松地将算法修改为相关的时间序列问题,并构建复杂的模型。怎么运行的?许多时间序列问题以一种或另一种方式彼此关联。可以用来解决一个问题的算法通常可以用于解决与之相关的另一个问题。这个想法叫做减少。例如,可以将时间序列回归模型(使用序列预测输出值)重新用于时间序列预测问题(预测输出值-将来将要接收的值)。
该项目的主要思想是:“ Sktime使用时间序列提供易于理解和集成的机器学习。它具有与scikit-learn和模型共享工具兼容的算法,并由清晰的学习任务分类,清晰的文档和友好的社区提供支持。”
在本文中,我将重点介绍sktime的一些独特功能。
正确的时间序列数据模型
Sktime使用熊猫数据框形式的时间序列的嵌套数据结构。
典型数据框中的每一行都包含独立且均等分布的随机变量-案例和列-不同变量。对于sktime方法, Pandas数据框中的每个单元格现在可以包含整个时间序列。这种格式对于多维,面板和异构数据非常灵活,并且允许在Pandas和scikit-learn中重用方法。
在下表中,每一行都是一个观察值,其中包含X列中的时间序列数组和Y列中的类值。sktime评估器和转换器擅长于使用这种时间序列。
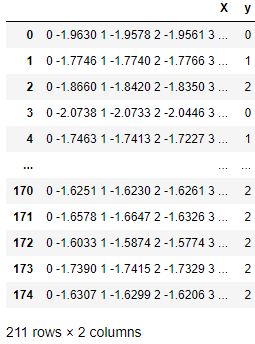
本地sktime兼容时间序列数据结构。
下表中,scikit-learn方法要求将X系列的每个元素移到单独的列中。尺寸很高-251列!此外,通过使用表格值的学习算法会忽略列的时间顺序(但由时间序列分类和回归算法使用)。
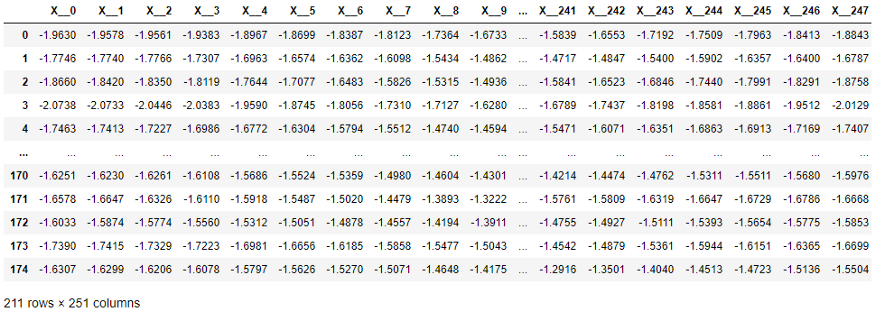
scikit-learn所需的时间序列数据结构。
对于建模多个关节序列的任务,与sktime兼容的本地时间序列数据结构是理想的。在scikit-learn期望的表格数据上训练的模型将陷入很多功能。
sktime可以做什么?
根据GitHub页面,sktime当前提供以下功能:
- 用于时间序列分类,回归分析和预测的现代算法(从工具箱移植
tsml到Java); - 时间序列转换器:单个系列的转换(例如,去趋势或反季节化),作为特征的系列的转换(例如,特征的提取)以及用于共享多个转换器的工具。
- 变压器和模型的管道;
- 建立模型;
- 模型的集合,例如用于分类和时间序列回归的完全可定制的随机森林,用于多维问题的集合。
API Sktime
正如前面提到的,sktime支持基本的API scikit学习方法课
fit,predict和transform。
对于评估者类(或模型),sktime提供了一种
fit训练模型的方法和一种predict生成新预测的方法。sktime中的
评估器扩展了scikit-learn的协变量和分类器,提供了这些方法的类似物,它们可以与时间序列一起使用。
对于类sktime变压器提供的方法
fit和transform用于将所述一系列数据。有几种类型的转换可用:
- , , ;
- , (, );
- (, );
- , , , (, ).
下一个示例是GitHub的预测指南的改编版。此示例中的系列(Box-Jenkins航空公司数据集)显示了1949年至1960年期间每月国际飞机乘客的数量。
首先,加载数据并将其分为训练和测试套件,然后绘制图表。在sktime中,有两个方便的功能可轻松执行这些任务-
temporal_train_test_splitfor由一组数据和时间分开,这些数据和时间plot_ys是根据测试和训练样本绘制的。
from sktime.datasets import load_airline
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.utils.plotting.forecasting import plot_ys
y = load_airline()
y_train, y_test = temporal_train_test_split(y)
plot_ys(y_train, y_test, labels=["y_train", "y_test"])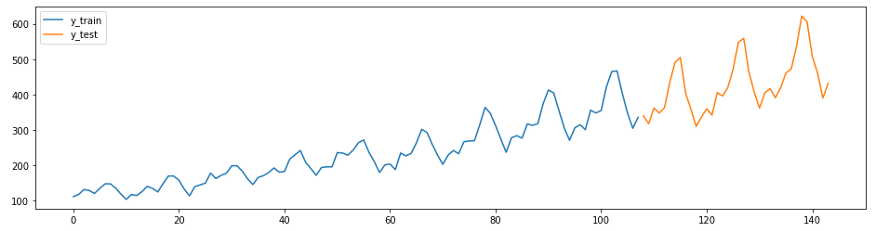
在进行复杂的预测之前,将您的预测与使用朴素贝叶斯算法获得的值进行比较很有用。一个好的模型应该超过这些值。在sktime中,有一种
NaiveForecaster使用不同策略创建基线预测的方法。
下面的代码和图表显示了两个幼稚的预测。预测器c
strategy = “last”将始终预测该系列的最后一个值。
预报器
strategy = “seasonal_last”预测给定季节的序列的最后一个值。示例中的季节性设置为“sp=12”,即12个月。
from sktime.forecasting.naive import NaiveForecaster
naive_forecaster_last = NaiveForecaster(strategy="last")
naive_forecaster_last.fit(y_train)
y_last = naive_forecaster_last.predict(fh)
naive_forecaster_seasonal = NaiveForecaster(strategy="seasonal_last", sp=12)
naive_forecaster_seasonal.fit(y_train)
y_seasonal_last = naive_forecaster_seasonal.predict(fh)
plot_ys(y_train, y_test, y_last, y_seasonal_last, labels=["y_train", "y_test", "y_pred_last", "y_pred_seasonal_last"]);
smape_loss(y_last, y_test)
>>0.231957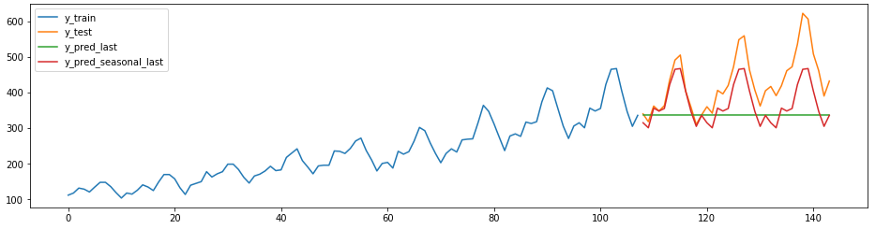
以下预测代码片段显示了如何轻松,正确,以最少的精力将现有的sklearn回归变量用于预测任务。下面是一个方法,
ReducedRegressionForecaster从sktime该预测了一系列使用模型sklearnRandomForestRegressor。在后台,sktime将训练数据分成12个窗口,以便回归器可以继续训练。
from sktime.forecasting.compose import ReducedRegressionForecaster
from sklearn.ensemble import RandomForestRegressor
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.performance_metrics.forecasting import smape_loss
regressor = RandomForestRegressor()
forecaster = ReducedRegressionForecaster(regressor, window_length=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=['y_train', 'y_test', 'y_pred'])
smape_loss(y_test, y_pred)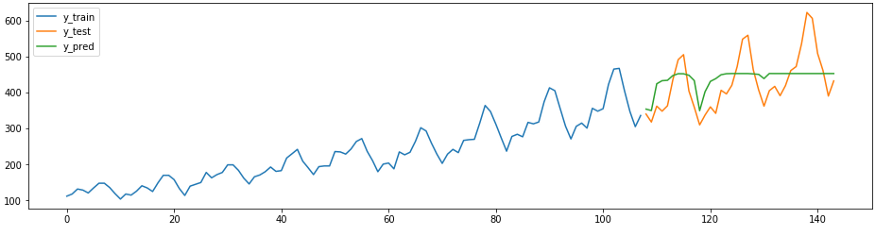
例如,在sktime中也有自己的预测方法
AutoArima。
from sktime.forecasting.arima import AutoARIMA
forecaster = AutoARIMA(sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]);
smape_loss(y_test, y_pred)
>>0.07395319887252469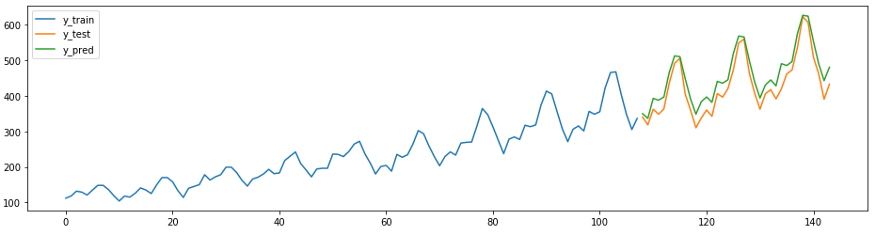
要深入了解sktime预测功能,请在此处查看教程。
时间序列分类
它也
sktime可以用于将时间序列分类为不同的组。
在下面的代码示例中,单个时间序列的分类与scikit-learn中的分类一样容易。唯一的区别是我们上面讨论的嵌套时间序列数据结构。
from sktime.datasets import load_arrow_head
from sktime.classification.compose import TimeSeriesForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = load_arrow_head(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
classifier = TimeSeriesForestClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy_score(y_test, y_pred)
>>0.8679245283018868摘自pypi.org/project/sktime的一个示例
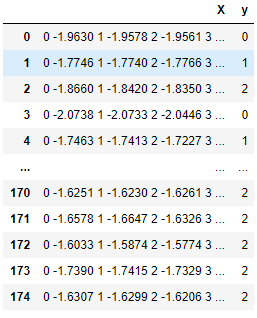
传递给TimeSeriesForestClassifier的数据
要了解有关系列分类的更多信息,请参见sktime的单变量和多变量分类指南。
额外的Sktime资源
要了解有关Sktime的更多信息,请参见以下链接以获取文档和示例。
- 详细的API描述:sktime.org
- sktime GitHub ( );
- ;
- Sktime: Markus Löning, Anthony Bagnall, Sajaysurya Ganesh, Viktor Kazakov, Jason Lines, Franz Király (2019): “sktime: A Unified Interface for Machine Learning with Time Series”
. .