
在当今的大数据世界中,Apache Spark是开发批处理任务的事实上的标准。此外,它还用于创建以微批处理概念运行的流应用程序,并小批量处理和发送数据(Spark结构化流)。传统上,它使用YARN(或在某些情况下为Apache Mesos)作为资源管理器,成为整个Hadoop堆栈的一部分。到2020年,由于缺乏像样的Hadoop发行版,大多数公司的传统用法受到质疑-HDP和CDH的开发已停止,CDH的开发不足且成本高昂,其余Hadoop提供商或已不复存在或前途不明。因此,社区和大公司之间的日益增长的兴趣是使用Kubernetes推出Apache Spark-已成为私有和公共云中容器编排和资源管理的标准,它解决了YARN上Spark任务的资源调度不便的问题,并提供了一个稳定开发的平台,其中包含许多并为各种规模和规模的公司提供开源发行版。此外,在流行的浪潮中,大多数人已经设法购买了他们的几个装置,并增加了使用它的专业知识,这简化了迁移过程。它解决了YARN上Spark任务的尴尬资源调度问题,并为各种规模和规模的公司提供了一个稳定发展的平台,其中包含许多商业和开源发行版。另外,在流行的浪潮中,大多数人已经设法购买了他们的几个装置并增加了使用它的专业知识,这简化了搬迁。它解决了YARN上Spark任务的笨拙调度问题,并为各种规模和不同规模的公司提供了一个稳定发展的平台,其中包含许多商业和开源发行版。另外,在流行的浪潮中,大多数人已经设法购买了他们的几个装置并增加了使用它的专业知识,这简化了搬迁。
从版本2.3.0开始,Apache Spark获得了对Kubernetes集群中运行任务的官方支持,今天,我们将讨论这种方法的当前成熟度,在实现过程中会遇到的各种用例和陷阱。
首先,我们将考虑基于Apache Spark开发任务和应用程序的过程,并重点介绍需要在Kubernetes集群上运行任务的典型情况。在准备本文时,将OpenShift用作分发工具包,并将提供与其命令行实用程序(oc)相关的命令。对于其他Kubernetes发行版,可以使用标准Kubernetes命令行实用程序(kubectl)的相应命令或其类似物(例如,对于oc adm策略)。
第一个用例是提交火花
在开发任务和应用程序的过程中,开发人员需要运行任务以调试数据转换。从理论上讲,存根可以用于这些目的,但是在有限系统的真实(尽管测试)实例的参与下进行的开发已经越来越快地表现出了这类问题。如果我们在终端系统的实际实例上进行调试,则可能出现两种情况:
- 开发人员以独立模式在本地运行Spark任务;
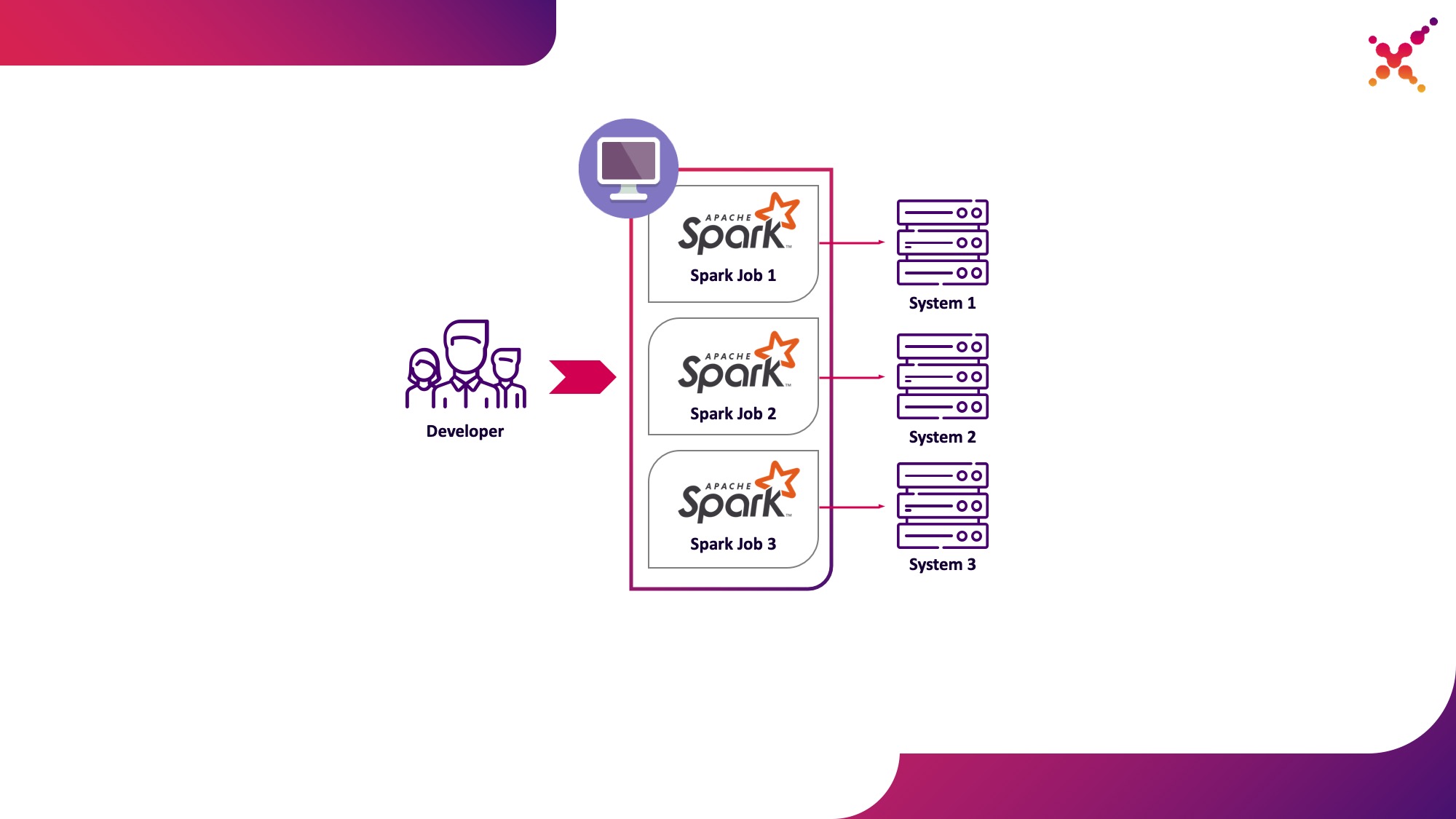
- 开发人员在测试循环中在Kubernetes集群上运行Spark任务。

第一种选择权是存在的,但存在许多缺点:
- 对于每个开发人员,要求提供从工作场所访问他所需的最终系统的所有副本的权限;
- 工作机器需要足够的资源来运行开发的任务。
第二个选项没有这些缺点,因为使用Kubernetes集群可以让您分配必要的资源池来运行任务,并为它提供对最终系统实例的必要访问权限,并使用Kubernetes角色模型为开发团队的所有成员灵活地提供对它的访问权限。让我们将其突出显示为第一个用例-在测试循环中从Kubernetes集群上的本地开发计算机运行Spark任务。
让我们仔细看看配置Spark在本地运行的过程。要开始使用Spark,您需要安装它:
mkdir /opt/spark
cd /opt/spark
wget http://mirror.linux-ia64.org/apache/spark/spark-2.4.5/spark-2.4.5.tgz
tar zxvf spark-2.4.5.tgz
rm -f spark-2.4.5.tgz
我们收集了使用Kubernetes的必要软件包:
cd spark-2.4.5/
./build/mvn -Pkubernetes -DskipTests clean package
完整的构建需要花费大量时间,并且构建Docker映像并在Kubernetes集群上运行它们,实际上,您只需要“ assembly /”目录中的jar文件,因此只能构建此子项目:
./build/mvn -f ./assembly/pom.xml -Pkubernetes -DskipTests clean package
要在Kubernetes中运行Spark任务,您需要创建一个Docker映像作为基础映像。这里有两种方法:
- 生成的Docker映像包含Spark任务的可执行代码;
- 创建的映像仅包含Spark和必要的依赖关系,可执行代码被远程托管(例如,在HDFS中)。
首先,让我们构建一个包含Spark任务测试示例的Docker映像。为了构建Docker映像,Spark有一个名为“ docker-image-tool”的工具。让我们研究一下它的帮助:
./bin/docker-image-tool.sh --help
它可以用来创建Docker映像并将其上传到远程注册表,但是默认情况下它有几个缺点:
- 可以一次创建3个Docker映像-适用于Spark,PySpark和R;
- 不允许您指定图像名称。
因此,我们将使用此实用程序的修改版本,如下所示:
vi bin/docker-image-tool-upd.sh
#!/usr/bin/env bash
function error {
echo "$@" 1>&2
exit 1
}
if [ -z "${SPARK_HOME}" ]; then
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
. "${SPARK_HOME}/bin/load-spark-env.sh"
function image_ref {
local image="$1"
local add_repo="${2:-1}"
if [ $add_repo = 1 ] && [ -n "$REPO" ]; then
image="$REPO/$image"
fi
if [ -n "$TAG" ]; then
image="$image:$TAG"
fi
echo "$image"
}
function build {
local BUILD_ARGS
local IMG_PATH
if [ ! -f "$SPARK_HOME/RELEASE" ]; then
IMG_PATH=$BASEDOCKERFILE
BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
img_path=$IMG_PATH
--build-arg
datagram_jars=datagram/runtimelibs
--build-arg
spark_jars=assembly/target/scala-$SPARK_SCALA_VERSION/jars
)
else
IMG_PATH="kubernetes/dockerfiles"
BUILD_ARGS=(${BUILD_PARAMS})
fi
if [ -z "$IMG_PATH" ]; then
error "Cannot find docker image. This script must be run from a runnable distribution of Apache Spark."
fi
if [ -z "$IMAGE_REF" ]; then
error "Cannot find docker image reference. Please add -i arg."
fi
local BINDING_BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
base_img=$(image_ref $IMAGE_REF)
)
local BASEDOCKERFILE=${BASEDOCKERFILE:-"$IMG_PATH/spark/docker/Dockerfile"}
docker build $NOCACHEARG "${BUILD_ARGS[@]}" \
-t $(image_ref $IMAGE_REF) \
-f "$BASEDOCKERFILE" .
}
function push {
docker push "$(image_ref $IMAGE_REF)"
}
function usage {
cat <<EOF
Usage: $0 [options] [command]
Builds or pushes the built-in Spark Docker image.
Commands:
build Build image. Requires a repository address to be provided if the image will be
pushed to a different registry.
push Push a pre-built image to a registry. Requires a repository address to be provided.
Options:
-f file Dockerfile to build for JVM based Jobs. By default builds the Dockerfile shipped with Spark.
-p file Dockerfile to build for PySpark Jobs. Builds Python dependencies and ships with Spark.
-R file Dockerfile to build for SparkR Jobs. Builds R dependencies and ships with Spark.
-r repo Repository address.
-i name Image name to apply to the built image, or to identify the image to be pushed.
-t tag Tag to apply to the built image, or to identify the image to be pushed.
-m Use minikube's Docker daemon.
-n Build docker image with --no-cache
-b arg Build arg to build or push the image. For multiple build args, this option needs to
be used separately for each build arg.
Using minikube when building images will do so directly into minikube's Docker daemon.
There is no need to push the images into minikube in that case, they'll be automatically
available when running applications inside the minikube cluster.
Check the following documentation for more information on using the minikube Docker daemon:
https://kubernetes.io/docs/getting-started-guides/minikube/#reusing-the-docker-daemon
Examples:
- Build image in minikube with tag "testing"
$0 -m -t testing build
- Build and push image with tag "v2.3.0" to docker.io/myrepo
$0 -r docker.io/myrepo -t v2.3.0 build
$0 -r docker.io/myrepo -t v2.3.0 push
EOF
}
if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
usage
exit 0
fi
REPO=
TAG=
BASEDOCKERFILE=
NOCACHEARG=
BUILD_PARAMS=
IMAGE_REF=
while getopts f:mr:t:nb:i: option
do
case "${option}"
in
f) BASEDOCKERFILE=${OPTARG};;
r) REPO=${OPTARG};;
t) TAG=${OPTARG};;
n) NOCACHEARG="--no-cache";;
i) IMAGE_REF=${OPTARG};;
b) BUILD_PARAMS=${BUILD_PARAMS}" --build-arg "${OPTARG};;
esac
done
case "${@: -1}" in
build)
build
;;
push)
if [ -z "$REPO" ]; then
usage
exit 1
fi
push
;;
*)
usage
exit 1
;;
esac
在它的帮助下,我们构建了一个基本的Spark映像,其中包含一个用于使用Spark计算Pi编号的测试任务(此处{docker-registry-url}是您的Docker映像注册表的URL,{repo}是注册表中的存储库的名称,与OpenShift中的项目一致) ,{image-name}是图像的名称(例如,如果使用三级图像分隔,例如在Red Hat OpenShift集成图像注册表中,则{tag}是该版本图像的标签):
./bin/docker-image-tool-upd.sh -f resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile -r {docker-registry-url}/{repo} -i {image-name} -t {tag} build
使用控制台实用程序登录OKD集群(此处{OKD-API-URL}是OKD集群API URL):
oc login {OKD-API-URL}
让我们在Docker Registry中获取当前用户的授权令牌:
oc whoami -t
登录到OKD集群的内部Docker注册表(使用使用上一条命令获得的令牌作为密码):
docker login {docker-registry-url}
将构建的Docker映像上传到Docker Registry OKD:
./bin/docker-image-tool-upd.sh -r {docker-registry-url}/{repo} -i {image-name} -t {tag} push
让我们检查一下组合图像在OKD中是否可用。为此,请在浏览器中打开一个URL,其中包含相应项目的图像列表(此处{project}是OpenShift集群中项目的名称,{OKD-WEBUI-URL}是OpenShift Web控制台的URL)-https:// {OKD-WEBUI-URL} /控制台/项目/ {项目} /浏览/图片/ {图片名称}。
要运行任务,必须以root用户身份运行pod的特权来创建服务帐户(稍后我们将讨论这一点):
oc create sa spark -n {project}
oc adm policy add-scc-to-user anyuid -z spark -n {project}
运行spark-submit将Spark任务发布到OKD集群,并指定创建的服务帐户和Docker映像:
/opt/spark/bin/spark-submit --name spark-test --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar
此处:--
name是将参与形成Kubernetes容器名称的任务的名称;
--class-任务启动时调用的可执行文件的类;
--conf-Spark配置参数;
spark.executor.instances要运行的Spark执行程序的数量。
spark.kubernetes.authenticate.driver.serviceAccountName-启动Pod时使用的Kubernetes服务帐户的名称(用于定义与Kubernetes API交互时的安全上下文和功能);
spark.kubernetes.namespace-驱动程序和执行程序容器将在其中运行的Kubernetes命名空间;
spark.submit.deployMode-Spark启动方法(“ cluster”用于标准的spark-submit,“ client”用于Spark Operator和更高版本的Spark);
spark.kubernetes.container.image用于运行容器的Docker映像。
spark.master-Kubernetes API的URL(指定了外部,以便从本地计算机进行调用);
local://是Docker映像中Spark可执行文件的路径。
转到相应的OKD项目并研究创建的Pod-https:// {OKD-WEBUI-URL} /控制台/项目/ {project} /浏览/ Pod。
为了简化开发过程,可以使用另一个选项,在该选项中创建一个通用的基本Spark映像,供所有任务启动,并将可执行文件的快照发布到外部存储(例如Hadoop)中,并在调用spark-submit作为链接时指定。在这种情况下,您可以运行不同版本的Spark任务,而无需重建Docker映像,例如使用WebHDFS发布映像。我们发送一个创建文件的请求(此处{host}是WebHDFS服务的主机,{port}是WebHDFS服务的端口,{path-hdfs上的路径是HDFS上文件的所需路径):
curl -i -X PUT "http://{host}:{port}/webhdfs/v1/{path-to-file-on-hdfs}?op=CREATE
这将收到以下形式的响应(此处{location}是必须用于下载文件的URL):
HTTP/1.1 307 TEMPORARY_REDIRECT
Location: {location}
Content-Length: 0
将Spark可执行文件加载到HDFS中(此处{path-to-local-file}是当前主机上Spark可执行文件的路径):
curl -i -X PUT -T {path-to-local-file} "{location}"
之后,我们可以使用上传到HDFS的Spark文件进行spark-submit(这里{class-name}是需要启动以完成任务的类的名称):
/opt/spark/bin/spark-submit --name spark-test --class {class-name} --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} hdfs://{host}:{port}/{path-to-file-on-hdfs}
应该注意的是,为了访问HDFS并确保任务的运行,您可能需要更改Dockerfile和entrypoint.sh脚本-向Dockerfile添加指令以将依赖库复制到/ opt / spark / jars目录中,并将HDFS配置文件包含在入口点的SPARK_CLASSPATH中。 sh。
第二个用例-Apache Livy
此外,当任务被开发并且需要测试获得的结果时,出现了在CI / CD流程中启动它并跟踪其执行状态的问题。当然,您可以使用本地spark-submit调用来运行它,但这会使CI / CD基础结构复杂化,因为它需要在CI服务器代理/运行程序上安装和配置Spark,并设置对Kubernetes API的访问权限。对于这种情况,目标实现选择使用Apache Livy作为REST API,以运行Kubernetes集群中托管的Spark任务。它可用于使用常规cURL请求在Kubernetes集群上启动Spark任务,该请求可轻松地基于任何CI解决方案实施,并且其在Kubernetes集群中的位置解决了与Kubernetes API交互时的身份验证问题。
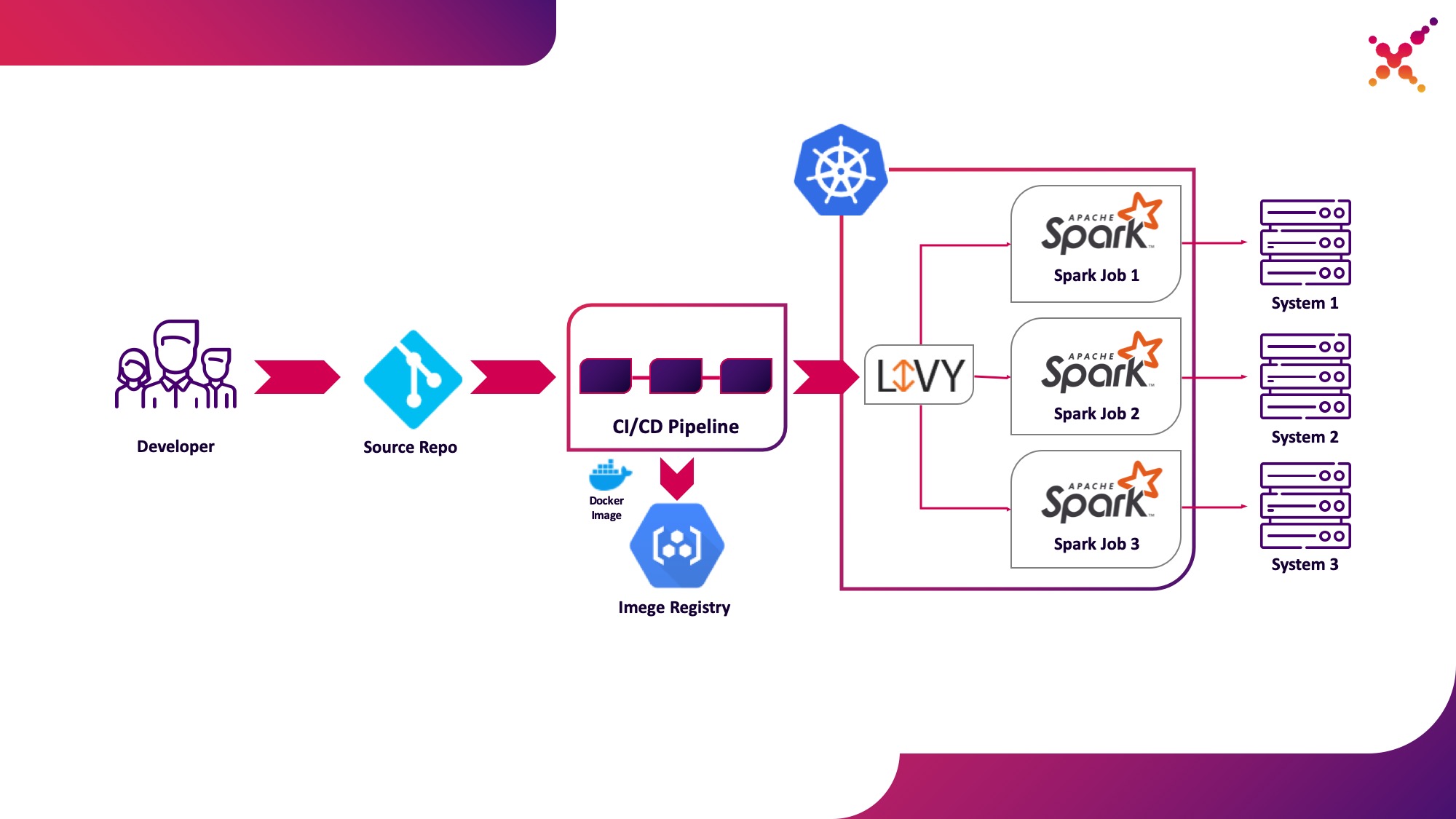
让我们将其突出显示为第二个用例-在测试循环中在Kubernetes集群上将Spark任务作为CI / CD流程的一部分运行。
关于Apache Livy的一些知识-它充当HTTP服务器,提供Web界面和RESTful API,使您可以通过传递必要的参数来远程运行spark-submit。传统上,它是作为HDP发行版的一部分提供的,但也可以使用适当的清单和一组Docker映像(例如一个github.com/ttauveron/k8s-big-data-experiments/tree/master)部署到OKD或任何其他Kubernetes安装中/livy-spark-2.3。对于我们的情况,构建了一个类似的Docker映像,包括来自以下Dockerfile的Spark版本2.4.5:
FROM java:8-alpine
ENV SPARK_HOME=/opt/spark
ENV LIVY_HOME=/opt/livy
ENV HADOOP_CONF_DIR=/etc/hadoop/conf
ENV SPARK_USER=spark
WORKDIR /opt
RUN apk add --update openssl wget bash && \
wget -P /opt https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz && \
tar xvzf spark-2.4.5-bin-hadoop2.7.tgz && \
rm spark-2.4.5-bin-hadoop2.7.tgz && \
ln -s /opt/spark-2.4.5-bin-hadoop2.7 /opt/spark
RUN wget http://mirror.its.dal.ca/apache/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip && \
unzip apache-livy-0.7.0-incubating-bin.zip && \
rm apache-livy-0.7.0-incubating-bin.zip && \
ln -s /opt/apache-livy-0.7.0-incubating-bin /opt/livy && \
mkdir /var/log/livy && \
ln -s /var/log/livy /opt/livy/logs && \
cp /opt/livy/conf/log4j.properties.template /opt/livy/conf/log4j.properties
ADD livy.conf /opt/livy/conf
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ADD entrypoint.sh /entrypoint.sh
ENV PATH="/opt/livy/bin:${PATH}"
EXPOSE 8998
ENTRYPOINT ["/entrypoint.sh"]
CMD ["livy-server"]
可以构建生成的映像并将其上传到您现有的Docker存储库,例如内部OKD存储库。要部署它,使用以下清单({registry-url}是Docker映像注册表的URL,{image-name}是Docker映像的名称,{tag}是Docker映像的标记,{livy-url}是可访问服务器的所需URL。 Livy;如果将Red Hat OpenShift用作Kubernetes发行版,则使用“ Route”清单,否则使用相应的NodePort类型的Ingress或Service清单):
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: livy
name: livy
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
component: livy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
component: livy
spec:
containers:
- command:
- livy-server
env:
- name: K8S_API_HOST
value: localhost
- name: SPARK_KUBERNETES_IMAGE
value: 'gnut3ll4/spark:v1.0.14'
image: '{registry-url}/{image-name}:{tag}'
imagePullPolicy: Always
name: livy
ports:
- containerPort: 8998
name: livy-rest
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/log/livy
name: livy-log
- mountPath: /opt/.livy-sessions/
name: livy-sessions
- mountPath: /opt/livy/conf/livy.conf
name: livy-config
subPath: livy.conf
- mountPath: /opt/spark/conf/spark-defaults.conf
name: spark-config
subPath: spark-defaults.conf
- command:
- /usr/local/bin/kubectl
- proxy
- '--port'
- '8443'
image: 'gnut3ll4/kubectl-sidecar:latest'
imagePullPolicy: Always
name: kubectl
ports:
- containerPort: 8443
name: k8s-api
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: spark
serviceAccountName: spark
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: livy-log
- emptyDir: {}
name: livy-sessions
- configMap:
defaultMode: 420
items:
- key: livy.conf
path: livy.conf
name: livy-config
name: livy-config
- configMap:
defaultMode: 420
items:
- key: spark-defaults.conf
path: spark-defaults.conf
name: livy-config
name: spark-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: livy-config
data:
livy.conf: |-
livy.spark.deploy-mode=cluster
livy.file.local-dir-whitelist=/opt/.livy-sessions/
livy.spark.master=k8s://http://localhost:8443
livy.server.session.state-retain.sec = 8h
spark-defaults.conf: 'spark.kubernetes.container.image "gnut3ll4/spark:v1.0.14"'
---
apiVersion: v1
kind: Service
metadata:
labels:
app: livy
name: livy
spec:
ports:
- name: livy-rest
port: 8998
protocol: TCP
targetPort: 8998
selector:
component: livy
sessionAffinity: None
type: ClusterIP
---
apiVersion: route.openshift.io/v1
kind: Route
metadata:
labels:
app: livy
name: livy
spec:
host: {livy-url}
port:
targetPort: livy-rest
to:
kind: Service
name: livy
weight: 100
wildcardPolicy: None
在应用和成功启动Pod之后,可通过以下链接获得Livy图形界面:http:// {livy-url} / ui。使用Livy,我们可以使用REST请求(例如,邮递员)发布我们的Spark任务。下面提供了一个带有请求的集合的示例(在“ args”数组中,可以传递带有正在运行的任务才能运行的变量的配置参数):
{
"info": {
"_postman_id": "be135198-d2ff-47b6-a33e-0d27b9dba4c8",
"name": "Spark Livy",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "1 Submit job with jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar\", \n\t\"className\": \"org.apache.spark.examples.SparkPi\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-1\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t}\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
},
{
"name": "2 Submit job without jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"hdfs://{host}:{port}/{path-to-file-on-hdfs}\", \n\t\"className\": \"{class-name}\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-2\",\n\t\"proxyUser\": \"0\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t},\n\t\"args\": [\n\t\t\"HADOOP_CONF_DIR=/opt/spark/hadoop-conf\",\n\t\t\"MASTER=k8s://https://kubernetes.default.svc:8443\"\n\t]\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
}
],
"event": [
{
"listen": "prerequest",
"script": {
"id": "41bea1d0-278c-40c9-ad42-bf2e6268897d",
"type": "text/javascript",
"exec": [
""
]
}
},
{
"listen": "test",
"script": {
"id": "3cdd7736-a885-4a2d-9668-bd75798f4560",
"type": "text/javascript",
"exec": [
""
]
}
}
],
"protocolProfileBehavior": {}
}
让我们执行来自集合的第一个请求,转到OKD界面并检查任务是否已成功启动-https:// {OKD-WEBUI-URL} / console / project / {project} / browser / pods。在这种情况下,会话将出现在Livy界面(http:// {livy-url} / ui)中,在其中,您可以使用Livy API或图形界面来跟踪任务的进度并研究会话日志。
现在让我们展示一下Livy的工作原理。为此,让我们使用Livy服务器检查pod内的Livy容器的日志-https:// {OKD-WEBUI-URL} / console / project / {project} /浏览/ pods / {livy-pod-name}?Tab =日志。从他们中您可以看到,当在名为“ livy”的容器中调用Livy REST API时,将执行火花提交,类似于我们上面使用的提交(此处{livy-pod-name}是使用Livy服务器创建的容器的名称)。该集合还提供了第二个请求,该请求允许您使用Livy服务器在远程托管Spark可执行文件的情况下运行任务。
第三种用例-Spark运算符
现在,该任务已经过测试,出现了定期运行它的问题。定期在Kubernetes集群中运行任务的本机方式是CronJob实体,您可以使用它,但是目前,在Kubernetes中使用运算符来控制应用程序非常流行,对于Spark来说,它有一个相当成熟的运算符,除其他外,它还用于企业级解决方案中(例如Lightbend FastData平台)。我们建议使用它-当前的稳定版本Spark(2.4.5)在Kubernetes中配置启动Spark任务的选项非常有限,而在下一个主要版本(3.0.0)中宣布了对Kubernetes的完全支持,但其发布日期仍然未知。 Spark Operator通过添加重要的配置选项(例如,通过在Spark Pod中配置对Hadoop的访问权限来安装ConfigMap,并能够按计划定期运行任务。
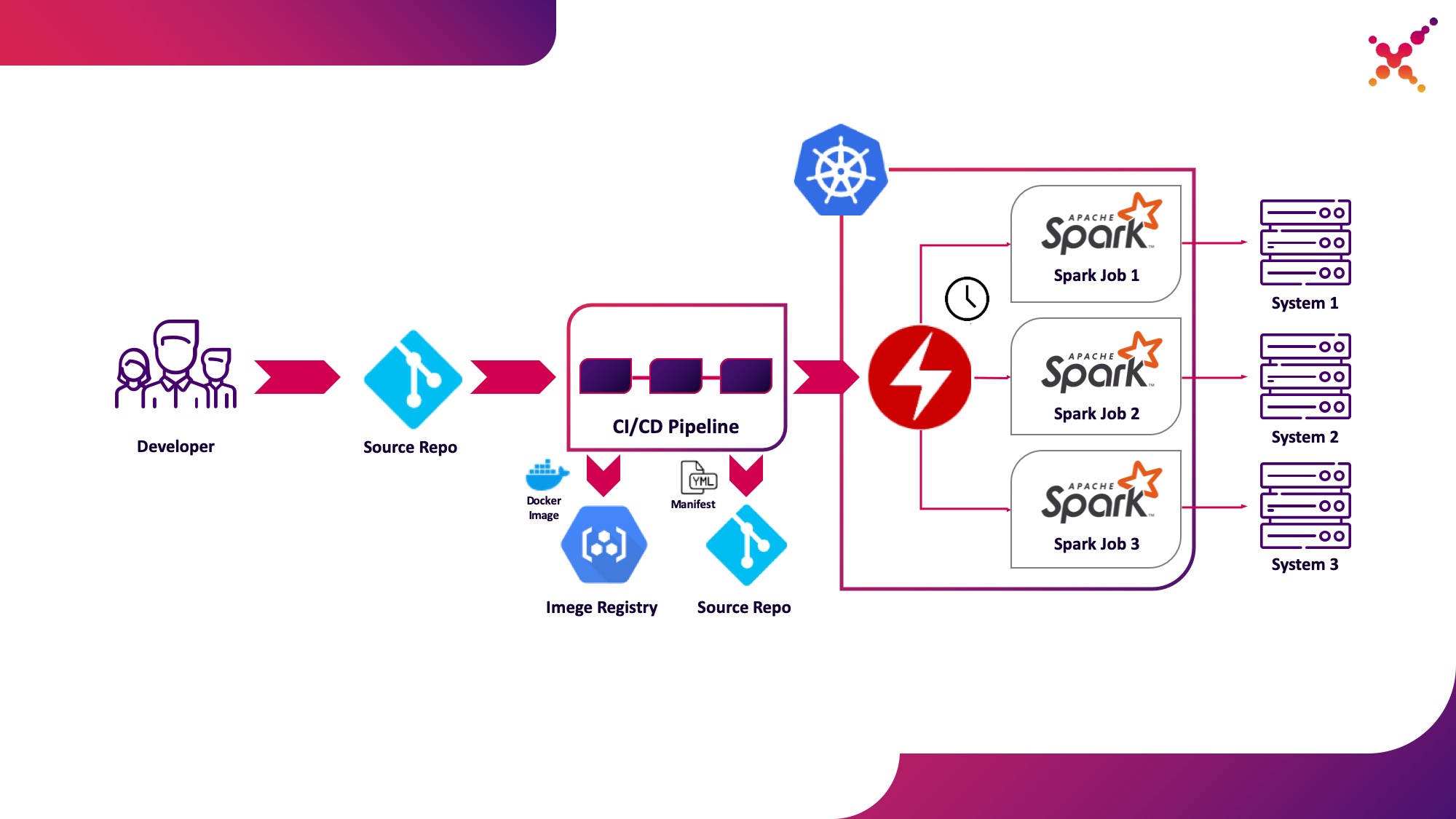
让我们将其突出显示为第三个用例-在生产循环中在Kubernetes集群上定期运行Spark任务。
星火运营商是开源的,开发的谷歌云平台的一部分- github.com/GoogleCloudPlatform/spark-on-k8s-operator。它的安装可以通过3种方式完成:
- 作为Lightbend FastData Platform / Cloudflow安装的一部分;
- 带舵:
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator helm install incubator/sparkoperator --namespace spark-operator
- (https://github.com/GoogleCloudPlatform/spark-on-k8s-operator/tree/master/manifest). — Cloudflow API v1beta1. , Spark Git API, , «v1beta1-0.9.0-2.4.0». CRD, «versions»:
oc get crd sparkapplications.sparkoperator.k8s.io -o yaml
如果正确设置了运算符,则带有Spark运算符的活动吊舱(例如,Cloudflow空间中的cloudflow-fdp-sparkoperator用于安装Cloudflow)将出现在相应的项目中,并且相应的名为“ sparkapplications”的Kubernetes资源类型将出现。您可以使用以下命令检查可用的Spark应用程序:
oc get sparkapplications -n {project}
要使用Spark Operator运行任务,您需要做三件事:
- 创建一个包含所有必需库以及配置和可执行文件的Docker映像。在目标图片中,这是在CI / CD阶段创建并在测试群集上进行测试的图像;
- 将Docker映像发布到可从Kubernetes集群访问的注册表中;
- «SparkApplication» . (, github.com/GoogleCloudPlatform/spark-on-k8s-operator/blob/v1beta1-0.9.0-2.4.0/examples/spark-pi.yaml). :
- «apiVersion» API, ;
- «metadata.namespace» , ;
- «spec.image» Docker ;
- «spec.mainClass» Spark, ;
- «spec.mainApplicationFile» jar ;
- 字典“ spec.sparkVersion”必须指示所使用的Spark版本;
- “ spec.driver.serviceAccount”字典必须在适当的Kubernetes命名空间中包含一个服务帐户,该帐户将用于启动应用程序;
- 词典“ spec.executor”应指示分配给应用程序的资源量;
- “ spec.volumeMounts”字典必须指定将在其中创建本地Spark任务文件的本地目录。
生成清单的示例(此处{spark-service-account}是Kubernetes集群中用于运行Spark任务的服务帐户):
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 0.1
coreLimit: "200m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: {spark-service-account}
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
此清单指定了一个服务帐户,在发布清单之前,您需要为其创建必要的角色绑定,这些角色绑定为Spark应用程序与Kubernetes API交互(如果需要)提供必要的访问权限。在我们的案例中,应用程序需要创建Pod的权限。让我们创建所需的角色绑定:
oc adm policy add-role-to-user edit system:serviceaccount:{project}:{spark-service-account} -n {project}
还要注意的是,此清单的规范可以指定hadoopConfigMap参数,该参数允许您使用Hadoop配置指定ConfigMap,而不必先将相应文件放在Docker映像中。它也适用于定期启动任务-使用“ schedule”参数,可以指定此任务的启动时间表。
之后,我们将清单保存到spark-pi.yaml文件,并将其应用于我们的Kubernetes集群:
oc apply -f spark-pi.yaml
这将创建一个“ sparkapplications”类型的对象:
oc get sparkapplications -n {project}
> NAME AGE
> spark-pi 22h
这将创建一个带有应用程序的容器,其状态将显示在创建的“ sparkapplications”中。可以使用以下命令查看它:
oc get sparkapplications spark-pi -o yaml -n {project}
完成任务后,POD将转换为“已完成”状态,该状态也将更新为“ sparkapplications”。可以在浏览器中或使用以下命令查看应用程序日志(此处{sparkapplications-pod-name}是正在运行的任务的pod的名称):
oc logs {sparkapplications-pod-name} -n {project}
还可以使用专用的sparkctl实用程序来管理Spark任务。要安装它,我们将克隆存储库及其源代码,安装Go并构建此实用程序:
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
cd spark-on-k8s-operator/
wget https://dl.google.com/go/go1.13.3.linux-amd64.tar.gz
tar -xzf go1.13.3.linux-amd64.tar.gz
sudo mv go /usr/local
mkdir $HOME/Projects
export GOROOT=/usr/local/go
export GOPATH=$HOME/Projects
export PATH=$GOPATH/bin:$GOROOT/bin:$PATH
go -version
cd sparkctl
go build -o sparkctl
sudo mv sparkctl /usr/local/bin
让我们检查正在运行的Spark任务的列表:
sparkctl list -n {project}
让我们为Spark任务创建一个描述:
vi spark-app.yaml
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
让我们使用sparkctl运行所描述的任务:
sparkctl create spark-app.yaml -n {project}
让我们检查正在运行的Spark任务的列表:
sparkctl list -n {project}
让我们检查已启动的Spark任务的事件列表:
sparkctl event spark-pi -n {project} -f
让我们检查正在运行的Spark任务的状态:
sparkctl status spark-pi -n {project}
总之,我想考虑在Kubernetes中运行当前稳定版本的Spark(2.4.5)的已发现的缺点:
- , , — Data Locality. YARN , , ( ). Spark , , , . Kubernetes , . , , , , Spark . , Kubernetes (, Alluxio), Kubernetes.
- — . , Spark , Kerberos ( 3.0.0, ), Spark (https://spark.apache.org/docs/2.4.5/security.html) YARN, Mesos Standalone Cluster. , Spark, — , , . root, , UID, ( PodSecurityPolicies ). Docker, Spark , .
- 使用Kubernetes运行Spark任务仍正式处于实验模式,并且将来使用的工件(配置文件,Docker基本映像和启动脚本)可能会发生重大变化。实际上,在准备材料时,已经测试了版本2.3.0和2.4.5,其行为存在显着差异。
我们将等待更新-最近发布了一个新版本的Spark(3.0.0),该版本对Spark在Kubernetes上的工作进行了切实的更改,但保留了对该资源管理器的实验性支持状态。也许接下来的更新将真正使完全建议放弃YARN并在Kubernetes上运行Spark任务成为可能,而不必担心系统的安全性并且不需要独立地优化功能组件。
鳍。