
自我识别
我的名字叫亚历山大(Alexander),我正在为罗斯银行(Rosbank)集团的内部审计而发展数据和技术分析的方向。我和我的团队使用机器学习和神经网络来识别风险,这是内部审计审计的一部分。在我们的军械库中,有一台服务器〜300 GB RAM和4个处理器,每个处理器具有10个内核。对于算法编程或建模,我们使用Python。
介绍
我们面临着分析银行产品注册过程中银行员工拍摄的客户照片(人像)的任务。我们的目标是从这些照片中找出以前未发现的风险。为了识别风险,我们生成并检验了一组假设。在本文中,我将描述我们提出的假设以及如何检验它们。为了简化对素材的理解,我将使用肖像风格的标准《蒙娜丽莎》。

校验和
首先,我们采用了一种无需机器学习和计算机视觉的方法,只是比较文件的校验和。为了生成它们,我们从hashlib库中采用了广泛使用的md5算法。
Python *实现:
#
with open(file,'rb') as f:
#
for chunk in iter(lambda: f.read(4096),b''):
#
hash_md5.update(chunk)
形成校验和时,我们立即使用字典检查重复项。
#
for file in folder_scan(for_scan):
#
ch_sum = checksum(file)
#
if ch_sum in list_of_uniq.keys():
# , , dataframe
df = df.append({'id':list_of_uniq[chs],'same_checksum_with':[file]}, ignore_index = True)
就计算量而言,该算法非常简单:在我们的服务器上,不超过3秒钟即可处理1000张图像。
该算法有助于我们识别数据中的重复照片,从而找到可能改善银行业务流程的地方。
重点(计算机视觉)
尽管校验和方法取得了积极的成果,但我们完全理解,如果图像中的至少一个像素发生变化,则其校验和将大不相同。作为第一个假设的逻辑发展,我们假设可以更改图像的位结构:重新保存(即重新压缩jpg),调整大小,裁剪或旋转。
为了演示,让我们沿着红色轮廓修剪边缘,然后将“蒙娜丽莎”向右旋转90度。

在这种情况下,必须通过图像的视觉内容搜索重复项。为此,我们决定使用OpenCV库,这是一种构造图像关键点并查找关键点之间的距离的方法。实际上,关键点可以是角,颜色渐变或表面点动。为了我们的目的,出现了最简单的方法之一-蛮力匹配。为了测量图像关键点之间的距离,我们使用了汉明距离。下图显示了在原始图像和修改后的图像上搜索关键点的结果(绘制了图像中最接近的20个关键点)。
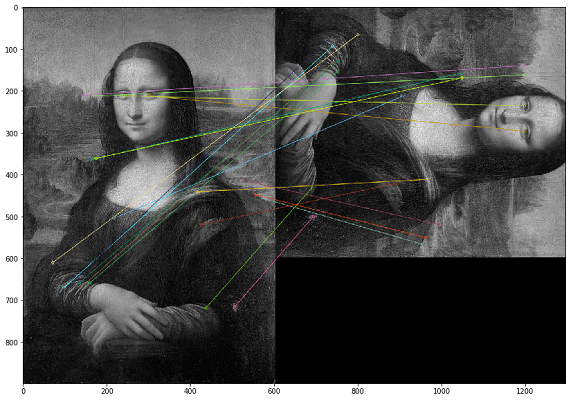
重要的是要注意,我们正在用黑白滤镜分析图像,因为这可以优化脚本的运行时间,并且对关键点进行了更加明确的解释。如果一个图像使用棕褐色滤镜,而另一幅图像使用彩色原件,那么当我们将其转换为黑白滤镜时,无论色彩处理和滤镜如何,都会识别关键点。
比较两个图像的示例代码*
img1 = cv.imread('mona.jpg',cv.IMREAD_GRAYSCALE) #
img2 = cv.imread('mona_ch.jpg',cv.IMREAD_GRAYSCALE) #
# ORB
orb = cv.ORB_create()
# ORB
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# Brute-Force Matching
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True)
# .
matches = bf.match(des1,des2)
# .
matches = sorted(matches, key = lambda x:x.distance)
# 20
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches[:20],None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plt.imshow(img3),plt.show()
在测试结果时,我们意识到在翻转图像的情况下,关键点内像素的顺序会发生变化,并且这些图像不会被识别为相同的图像。作为一种补偿措施,您可以自己镜像每个图像并分析两倍的体积(甚至三倍),这在计算能力方面要昂贵得多。
该算法具有很高的计算复杂度,并且最大的负载是通过计算点之间的距离的操作而产生的。由于我们必须将每个图像进行比较,因此,如您所知,这种笛卡尔集的计算需要大量的计算周期。在一次审核中,类似的计算耗时一个多月。
这种方法的另一个问题是测试结果的可解释性差。我们得到图像关键点之间距离的系数,然后出现一个问题:“应该选择哪个系数阈值足以考虑重复的图像?”
使用计算机视觉,我们能够找到第一个校验和测试未涵盖的案例。实际上,这些文件实际上是保存过度的jpg文件。我们没有在分析的数据集中发现更复杂的图像变化情况。
校验和VS关键点
开发了两种根本不同的方法来查找重复项并在多个检查中重复使用它们,我们得出的结论是,对于我们的数据,校验和在更短的时间内给出了更明显的结果。因此,如果我们有足够的时间进行检查,则可以按要点进行比较。
搜索异常图像
在分析了关键点的测试结果之后,我们注意到一名员工拍摄的照片具有接近相同数量的接近关键点。这是合乎逻辑的,因为如果他在工作场所与客户沟通并在同一房间拍照,那么他所有照片的背景将是相同的。这种观察使我们相信,我们可以找到与该员工的其他照片不同的异常照片,这些照片可能是在办公室外拍摄的。
回到蒙娜丽莎的例子,事实证明其他人将在相同背景下出现。但是,不幸的是,我们没有找到这样的例子,因此在本节中,我们将显示没有例子的数据指标。为了在检验该假设的框架中提高计算速度,我们决定放弃关键点并使用直方图。
第一步是将图像转换为可以测量的对象(直方图),以便通过图像直方图之间的距离比较图像。基本上,直方图是提供图像概述的图形。这是在横轴(X轴)上具有像素值的图像,在纵轴(Y轴)上具有图像中相应像素数的图形。直方图是解释和分析图像的简便方法。使用图片的直方图,您可以直观了解对比度,亮度,强度分布等。
对于每个图像,我们使用OpenCV中的calcHist函数创建直方图。
histo = cv2.calcHist([picture],[0],None,[256],[0,256])
在给定的三幅图像示例中,我们沿水平轴(所有类型的像素)使用256个因子对其进行了描述。但是我们也可以重新排列像素。我们的团队在这部分中没有进行很多测试,因为使用256个因子时结果非常好。如有必要,我们可以直接在calcHist函数中更改此参数。
一旦为每个图像创建了直方图,我们就可以简单地为每个为客户拍照的员工从图像中训练DBSCAN模型。这里的技术要点是为我们的任务选择DBSCAN参数(epsilon和min_samples)。
使用DBSCAN之后,我们可以进行图像聚类,然后应用PCA方法可视化生成的聚类。

从分析图像的分布可以看出,我们有两个明显的蓝色簇。事实证明,员工在不同的日子可以在不同的办公室工作-在其中一个办公室拍摄的照片将创建一个单独的群集。
绿点是例外照片,背景与这些簇不同。
通过对照片的详细分析,我们发现了许多假阴性照片。最常见的情况是爆破照片或其中大部分区域被委托人的面部占据的照片。事实证明,这种分析方法需要人工干预才能验证结果。
使用这种方法,您可以在照片中发现有趣的异常现象,但是需要花费时间来手动分析结果。由于这些原因,我们很少在审计过程中进行此类测试。
照片中有脸吗?(人脸检测)
因此,我们已经从各个方面测试了我们的数据集,并且继续发展测试的复杂性,我们继续进行下一个假设:照片中是否存在潜在客户的面孔?我们的任务是学习如何识别图片中的人脸,为图片的输入赋予功能以及在输出中获取人脸数量。
这种实现已经存在,我们决定从Google的FaceNet模块中为任务选择MTCNN(多任务级联卷积神经网络)。
FaceNet是由卷积层组成的深度机器学习架构。FaceNet为每个面孔返回一个128维向量。实际上,FaceNet是几个神经网络和一组用于准备和处理这些网络的中间结果的算法。我们决定通过此神经网络更详细地描述人脸搜索的机制,因为有关这一点的材料并不多。
步骤1:预处理
MTCNN要做的第一件事是创建多种尺寸的照片。
MTCNN将尝试在每张照片中以固定大小的正方形识别人脸。在不同尺寸的同一张照片上使用此识别将增加我们正确识别照片中所有面孔的机会。

可能无法以正常图像尺寸识别脸部,但是可以在固定尺寸正方形的不同尺寸图像中识别出脸部。该步骤在算法上无需神经网络即可执行。
步骤2:P-Net
在创建了照片的不同副本之后,第一个神经网络P-Net开始发挥作用。该网络使用12x12内核(块),它将从左上角开始扫描所有照片(相同照片的副本,但尺寸不同),并以2像素的增量沿图片移动。

扫描了所有不同大小的图片后,MTCNN再次将每张照片标准化并重新计算块坐标。
P-Net给出了块的坐标以及相对于每个块所包含的面的置信度(此面的精确度)。您可以使用threshold参数使块具有一定的信任级别。
同时,我们不能简单地选择具有最高信任级别的块,因为图片可能包含多个面孔。
如果一个块与另一个块重叠并覆盖几乎相同的区域,则该块将被删除。可以在网络初始化期间控制此参数。

在此示例中,黄色块将被删除。基本上,P-Net的结果是低精度块。下面的示例显示了P-Net的真实结果:

步骤3:R-Net
R-Net选择了由于P-Net的工作而形成的最合适的模块,而P-Net在团队中很可能是一个人。R-Net具有与P-Net类似的体系结构。在这一阶段,形成完全连接的层。R-Net的输出也类似于P-Net的输出。

步骤4:O-Net
O-Net网络是MTCNN网络的最后一部分。除了最后两个网络之外,它还为每个脸部(眼睛,鼻子,嘴唇的角)形成五个点。如果这些点完全落入块中,则确定为最有可能包含此人。其他点用蓝色标记:

结果,我们得到了最后一块,表明这是一张脸的事实的准确性。如果未找到人脸,那么我们将获得零个人脸块。
通过我们的服务器上的这样的网络平均处理1000张照片需要6分钟。
我们在检查中反复使用了该神经网络,它帮助我们自动识别了客户照片中的异常。
关于使用FaceNet,我要补充一点,如果您开始分析伦勃朗的画布而不是蒙娜丽莎,结果将类似于下图,并且您将必须解析已识别人员的整个列表:

结论
这些假设和测试方法表明,对于任何数据集,您都可以执行有趣的测试并查找异常情况。现在,许多审核员都在尝试开发类似的做法,因此我想展示计算机视觉和机器学习的实际使用示例。
我还要补充一点,我们认为人脸识别是测试的下一个假设,但是到目前为止,数据和过程细节还没有为在测试中使用该技术提供合理的基础。
总的来说,这就是我想告诉您的有关测试照片的方式。
希望您能提供良好的分析和标记数据!
*示例代码取自开源。