部分第2部分
在本文中,您将学习:
- 关于ImageNet大规模视觉识别挑战赛(ILSVRC)
- 关于存在的CNN架构:
- LeNet-5
- 亚历克斯网
- 虚拟网
- GoogLeNet
- ResNet
- 关于新的网络体系结构出现了什么问题,后续的问题如何解决:
- 消失梯度问题
- 爆炸梯度问题
劳工委员会
ImageNet大规模视觉识别挑战赛是一项年度竞赛,研究人员在其中比较他们的网格以对照片中的对象进行检测和分类。
这项竞赛是以下方面发展的动力:
-神经网络体系结构
-
迄今为止使用的个人方法和实践此图显示了分类算法如何随时间演变:
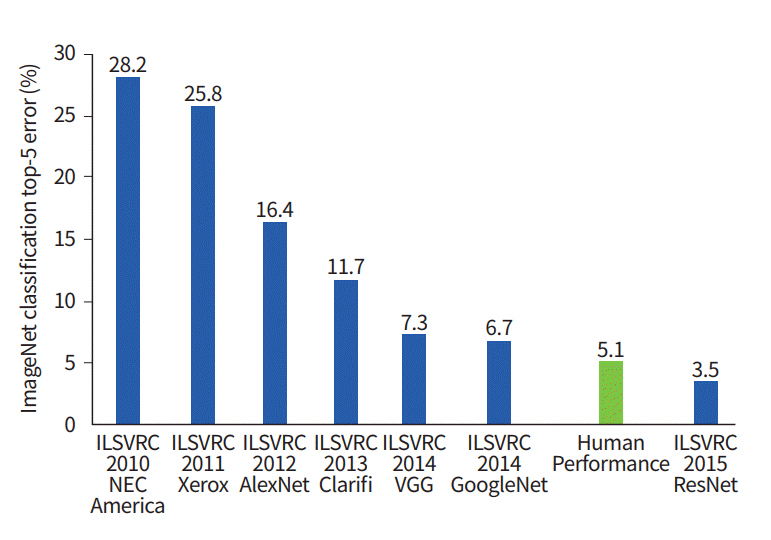
在x轴上-年份和算法(自2012年以来-卷积神经网络)。
y轴是前5位误差中样本中误差的百分比。
前5个错误是评估模型的一种方式:模型返回一定的概率分布,并且如果前5个概率中存在类别的真实值(类别标签),则认为模型的答案正确。因此,(1-top-1误差)是熟悉的精度。
CNN架构
LeNet-5
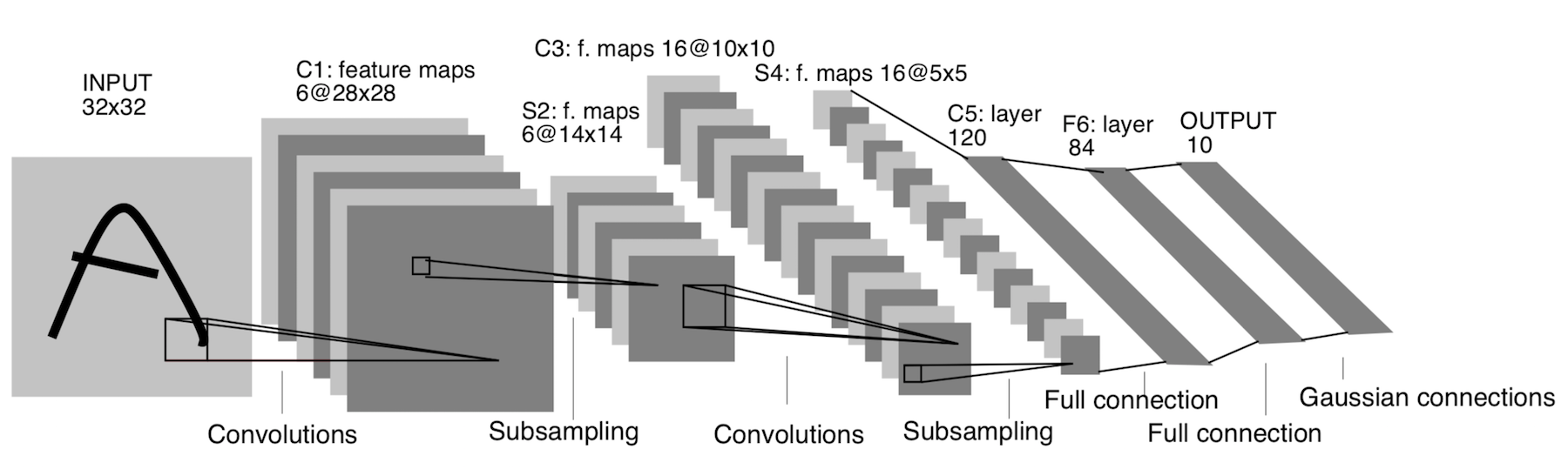
它已经出现在1998年!它旨在识别手写字母和数字。这里的二次采样是指池化层。
体系结构:
CONV 5x5,步幅= 1
POOL 2x2,步幅= 2
CONV 5x5,步幅= 1
POOL 5x5,步幅= 2
FC(120,84)
FC(84,10)
现在,此体系结构仅具有历史意义。这种架构很容易在任何现代深度学习框架中手动实现。
亚历克斯网

图片不重复。之所以这样描述架构,是因为AlexNet架构当时不适合一个GPU设备,因此一半的网络运行在一个GPU上,而另一个则在另一个GPU上运行。
它出现在2012年。ILSVRC的突破始于她-她击败了当时所有的最新模型。之后,人们意识到神经网络确实有效:)
架构更具体地讲:

如果仔细观察AlexNet架构,您会发现14年来(自LeNet-5出现以来)几乎没有发生任何变化,除了层数。
重要:
:
- Local Response Norm — , . batch-normalization.
- - , — - FLOPs, .
- FC 4096 , (Fully-connected) 4096 .
- Max Pool 3x3s2 , 3x3, = 2.
- 像Conv 11x11s4,96这样的记录表示卷积层具有11x11xNc过滤器,step = 4,此类过滤器的数量为96。现在,此类过滤器的数量为下一层(相同Nc)的通道数量。我们假设初始图像具有三个通道(R,G和B)。
虚拟网
建筑:
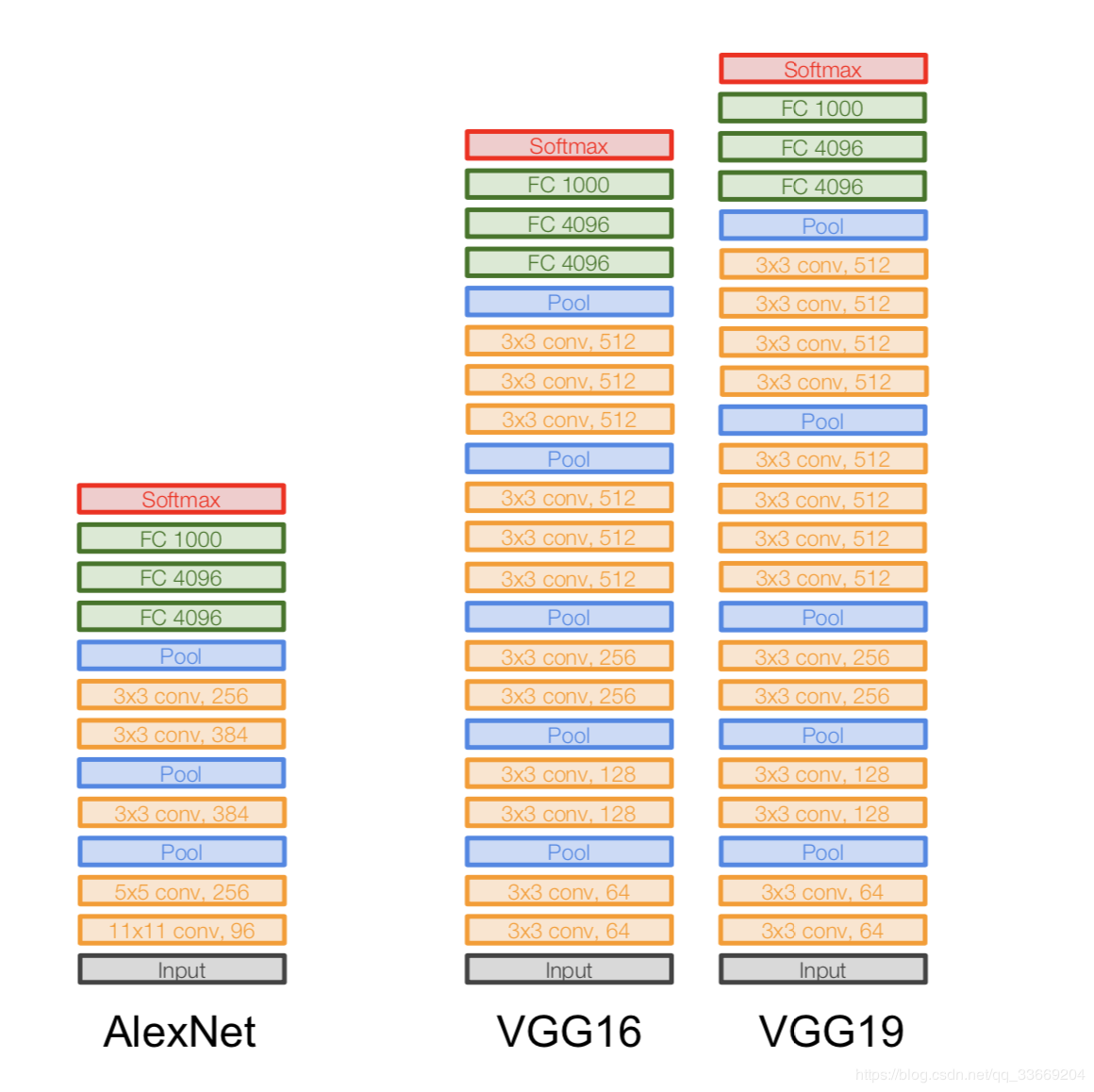
2014年推出。
两个版本-VGG16和VGG19。基本思想是使用小尺寸(3x3)而不是大尺寸(11x11和5x5)。使用大卷积的直觉很简单-我们想从相邻像素中获取更多信息,但最好是更频繁地使用小滤镜。
这就是为什么:
- . , . .. , , .
- => .
- — , — , — , .
重要提示:
-在针对错误反向传播算法训练神经网络时,重要的是在正向传播的所有阶段(卷积,池)保留对象表示(对于我们而言,原始图像)(正向传递是将图像馈送到输入并移至输出时,结果)。就存储器而言,对象的这种表示可能是昂贵的。看一下:
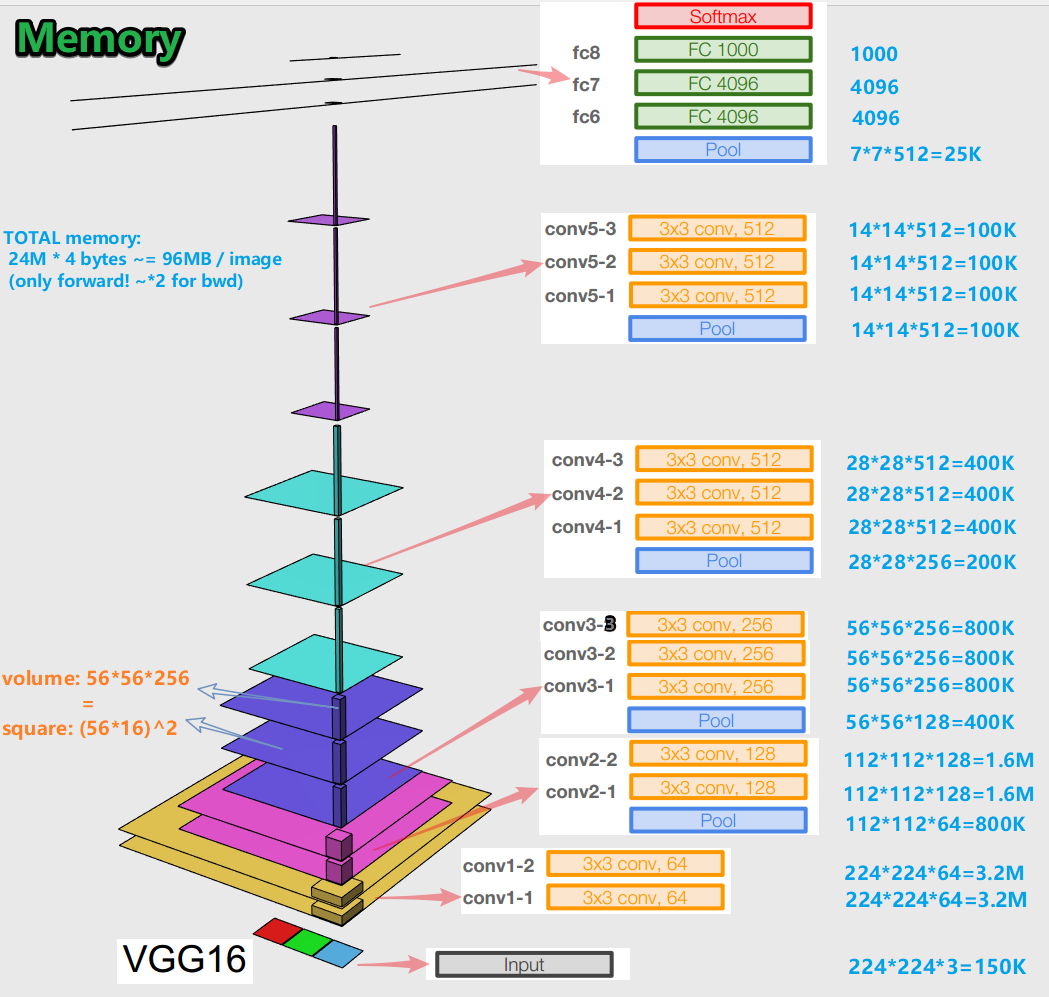
原来每张图像大约有96 MB,这只是用于向前传递。对于后向传递(图片中的bwd)-在计算梯度时-大约是两倍。出现了一个有趣的图景:最大数量的训练参数位于完全连接的层中,并且在卷积和池化层之后,对象表示占据了最大的内存。 C-协同作用。
-该网络在16层变化中具有1.38亿个训练参数,在19层变化中具有1.43亿个参数。
GoogLeNet
建筑:
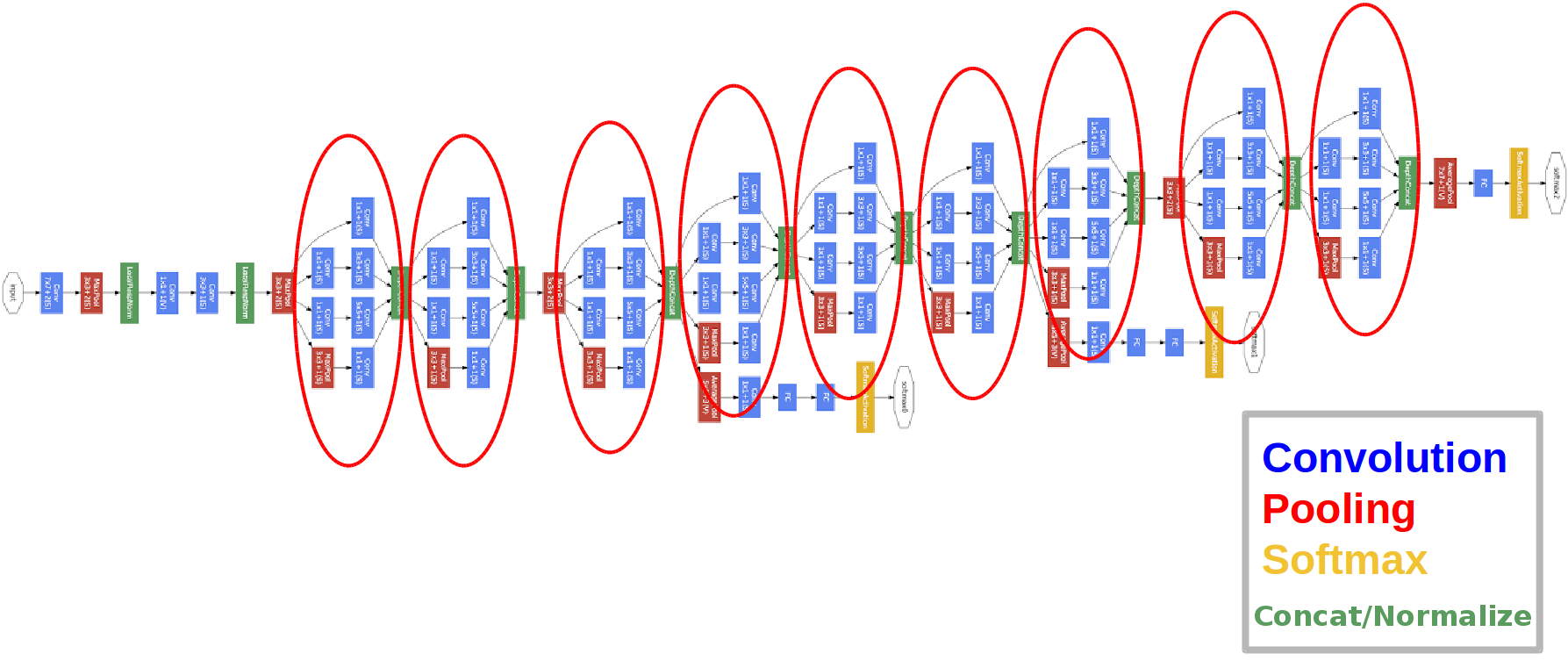
2014年推出。
红色圆圈是所谓的“盗用模块”。
让我们仔细看一下:
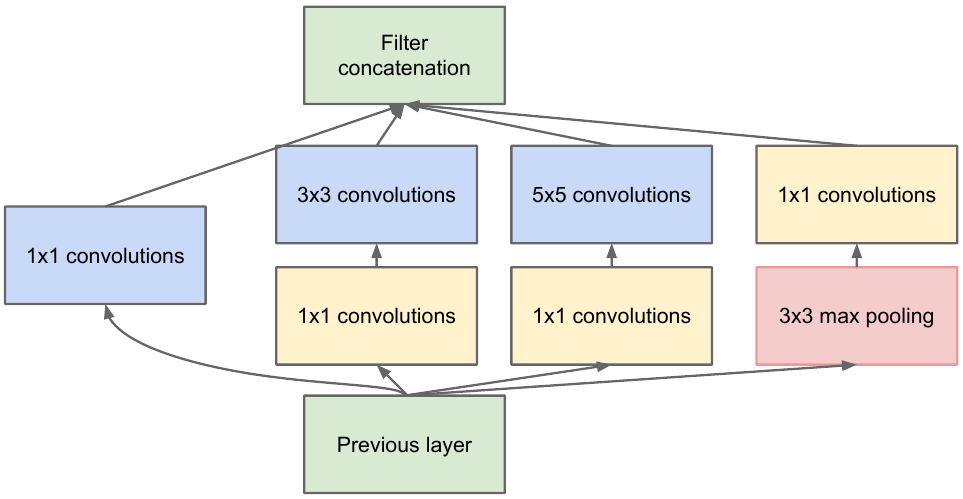
我们从上一层获取要素地图,对它应用许多具有不同过滤器的卷积,然后将结果卷积起来。直觉很简单:我们想使用不同大小的过滤器来获得特征图的不同表示。使用卷积1x1是为了在每个这样的起始块之后不增加太多通道数。那些。当要素图具有大量通道时,并且他们希望在不更改要素图的高度和宽度的情况下减少此数量,请使用1x1卷积。
网络中还有三个分类器块,这就是它们的外观(对我们来说是右边的一个):

通过这种构造,在误差的反向传播过程中,梯度“更好”从输出层到达输入层。
为什么我们需要两个额外的网络输出?都是关于所谓的消失梯度问题:
最重要的是,当反向传播错误时,梯度趋于平凡地趋于零。网络越深,它越容易受到这种现象的影响。为什么会发生?当我们向后传递时,我们从输出转到输入,计算复杂函数的梯度。复数函数的导数(链式规则))本质上是乘法。因此,在从输出到输入的途中将一些值相乘,我们会遇到接近零的数字,结果实际上神经网络的权重实际上没有更新。S型激活功能具有固定的输出范围,这部分是问题。好了,通过使用ReLu激活功能可以部分解决此问题。为什么要部分?因为没有人能保证训练后的参数值和所有特征图中输入对象的表示形式。
重要:
- 该网络有22层(这比以前的网络要多一些)。
- 训练后的参数数量等于五百万,比前两个网络少几倍。
- 1x1捆绑包的外观。
- 使用起始块。
- 现在是1x1卷积,而不是完全连接的层,这会降低深度,并因此降低完全连接的层和所谓的全局avegare池的尺寸(您可以在此处阅读更多)。
- 该体系结构具有3个输出(权衡最终答案)。
ResNet
架构(ResNet-34变体):
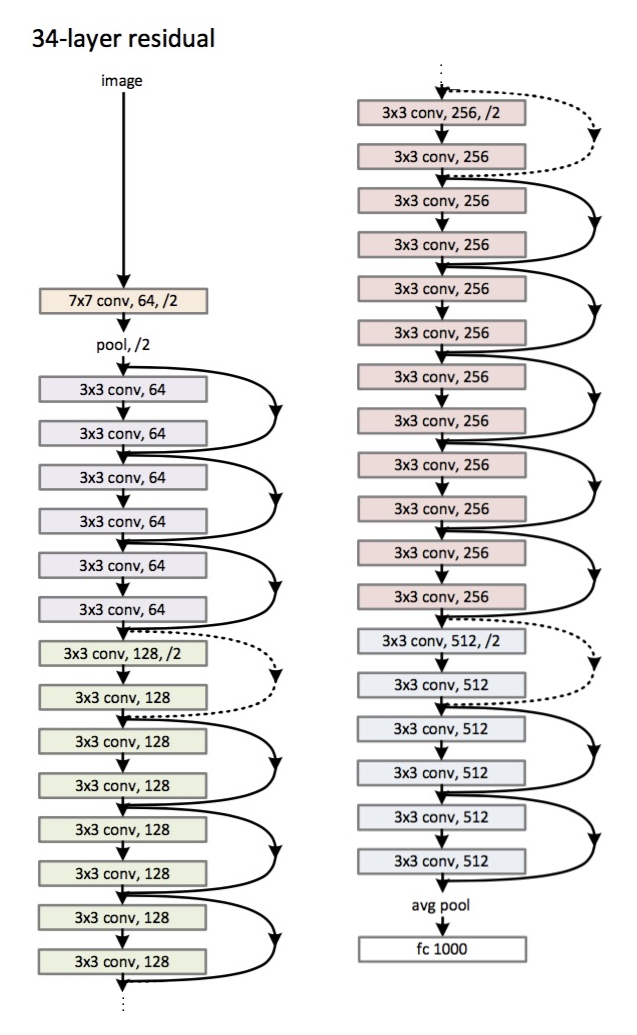
在2015年推出。
主要的创新是大量的层和所谓的剩余块。这些块用于解决衰落梯度问题。这些残差块之间的连接称为快捷方式(图片中的箭头)。现在,使用这些快捷方式,渐变将达到所有必需的参数,从而训练网络:)
重要:
- 代替完全连接的层-平均全局池。
- 残留块。
- 在识别ImageNet数据集上的图像方面,网络已经超越了人类(前5个错误)。
- 第一次使用批标准化。
- 使用了初始化权重的技术(直觉:通过权重的某种初始化,网络可以更快更好地收敛(学习))。
- 最大深度为152层!
较小的离题
衰落梯度的问题与所有深度神经网络有关。
还有它的对立面-爆炸梯度问题,它也与所有深层神经网络有关。名称的底线很清楚-渐变变得太大,导致NaN(不是数字,无穷大)。解决方案很明显-限制渐变的值,否则-减小其值(规格化)。此技术称为“剪切”。
结论
在2019年,出现了一篇有关新架构家族的文章-EfficientNet。
我建议按照相关的机器学习各种任务和领域的最新发展趋势在这里。在此资源上,您可以选择一个任务(例如,图像分类)和一个数据集(例如,ImageNet),并查看某些体系结构的质量以及有关它们的其他信息。例如,FixEfficientNet-L2网格在ImageNet数据集上的图像分类(最高1级准确性)中名列第一。
在接下来的文章中,我们将讨论转移学习,对象检测和分段。