因此,当成千上万台受控服务器之一上发生异常的资源消耗(CPU,内存,磁盘,网络等)时,就需要弄清楚“谁该怪谁该做什么”。
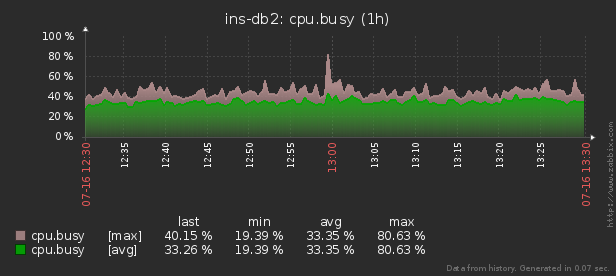
有一个pidstat实用程序,用于“当前”实时监视Linux服务器资源使用情况。也就是说,如果负载峰值是周期性的,则可以在控制台中将其“阴影化”。但是我们想在事后分析这些数据,试图找到造成资源最大负载的过程。
也就是说,我希望能够通过分组并详细了解这些类型的范围来查找先前收集的数据不同的精美报告:
在本文中,让我们考虑如何将其经济地放置在数据库中以及如何通过使用窗口函数来构建最有效的这些数据报告。分组集。
首先,让我们看看如果我们“尽一切可能”可以提取什么样的数据:
pidstat -rudw -lh 1| 时间 | UID | PID | %usr | %系统 | % 客人 | % 中央处理器 | 中央处理器 | minflt /秒 | majflt / s | VSZ | Rss | %MEM | kB_rd / s | kB_wr / s | kB_ccwr / s | cswch / s | nvcswch / s | 命令 |
| 1594893415 | 0 | 1个 | 0.00 | 13.08 | 0.00 | 13.08 | 52 | 0.00 | 0.00 | 197312 | 8512 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 7.48 | / usr / lib / systemd / systemd --switched-root --system --deserialize 21 |
| 1594893415 | 0 | 九 | 0.00 | 0.93 | 0.00 | 0.93 | 40 | 0.00 | 0.00 | 0 | 0 | 0.00 | 0.00 | 0.00 | 0.00 | 350.47 | 0.00 | rcu_sched |
| 1594893415 | 0 | 十三 | 0.00 | 0.00 | 0.00 | 0.00 | 1个 | 0.00 | 0.00 | 0 | 0 | 0.00 | 0.00 | 0.00 | 0.00 | 1.87 | 0.00 | 迁移/ 11.87 |
所有这些值都分为几类。其中一些不断变化(CPU和磁盘活动),其他很少变化(内存分配),并且Command不仅在同一进程中很少变化,而且在不同的PID上定期重复。
基础结构
为简单起见,让我们将每个节省的“类”限制为一个度量标准:%CPU,RSS和Command。
由于我们预先知道Command是定期重复执行的,因此我们将其简单地移动到一个单独的表字典中,其中MD5哈希将充当UUID密钥:
CREATE TABLE diccmd(
cmd
uuid
PRIMARY KEY
, data
varchar
);对于数据本身,这种类型的表适合我们:
CREATE TABLE pidstat(
host
uuid
, tm
integer
, pid
integer
, cpu
smallint
, rss
bigint
, cmd
uuid
);我想提请您注意一个事实,因为%CPU总是以2个小数位的精度出现在我们这里,并且肯定不会超过100.00,所以我们可以轻松地将其乘以100并将其放入
smallint。一方面,这将使我们摆脱操作过程中会计准确性问题的困扰,另一方面,与4字节或8字节相比,最好只存储2real字节double precision。
您可以在文章“在大容量文件上节省很多钱”中阅读有关有效地将记录打包到PostgreSQL存储中的方法的更多信息,以及在“写在子灯下:1台主机,1天,1 TB”中阅读有关增加数据库吞吐量以进行写入的更多信息。
“免费”存储NULL
为了节省数据库的磁盘子系统的性能和数据库的大小,我们将尝试以NULL的形式表示尽可能多的数据-它们的存储实际上是“免费的”,因为在记录头中只需要一点点。
关于代表在PostgreSQL中记录的内部机制的更多信息可以在尼古拉Shaplov的谈话在PGConf.Russia 2016年发现“里面有什么吧:在低级别的数据存储。” 幻灯片#16专门用于空存储。让我们仔细看看数据的类型:
- CPU / DSK
不断变化,但经常变为零-因此,将NULL而不是0写入base会非常有益。 - RSS / CMD它
很少更改-因此,我们将在同一PID中写入NULL而不是重复。
事实是这样的,如果您在特定PID的上下文中查看它:

很明显,如果我们的进程开始执行另一个命令,则已用内存的值也可能与以前不同-因此,我们同意在更改CMD时,RSS的值也将是不管先前的值如何修复。
也就是说,具有填充的CMD值的条目也具有RSS值。让我们记住这一刻,它将仍然对我们有用。
整理漂亮的报告
现在,让我们进行一个查询,该查询将向我们显示特定时间间隔内特定主机的资源使用方。
但是,让我们立即使用最少的资源进行操作-类似于有关SELF JOIN和window函数的文章。
使用传入参数
为了不在SQL查询期间的多个地方指定报告参数的值(或$ 1 / $ 2),我们从唯一的JSON字段中选择CTE,这些参数通过键位于其中:
--
WITH args AS (
SELECT
json_object(
ARRAY[
'dtb'
, extract('epoch' from '2020-07-16 10:00'::timestamp(0)) -- timestamp integer
, 'dte'
, extract('epoch' from '2020-07-16 10:01'::timestamp(0))
, 'host'
, 'e828a54d-7e8a-43dd-b213-30c3201a6d8e' -- uuid
]::text[]
)
)
检索原始数据
由于我们没有发明任何复杂的聚合,因此分析数据的唯一方法是读取数据。为此,我们需要一个明显的索引:
CREATE INDEX ON pidstat(host, tm);-- ""
, src AS (
SELECT
*
FROM
pidstat
WHERE
host = ((TABLE args) ->> 'host')::uuid AND
tm >= ((TABLE args) ->> 'dtb')::integer AND
tm < ((TABLE args) ->> 'dte')::integer
)
分析键分组
对于每个找到的PID,确定其活动间隔,并从该间隔的第一条记录中获取CMD。
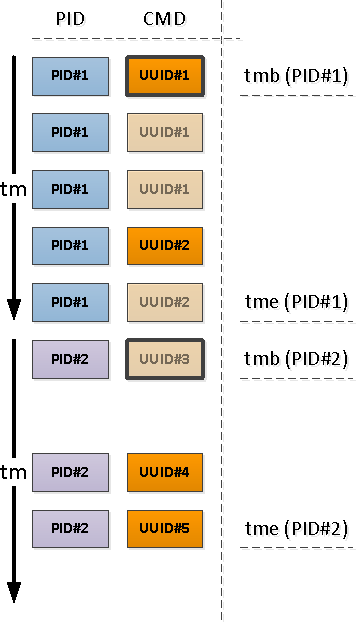
为此,我们将通过
DISTINCT ON和窗口函数使用唯一化:
--
, pidtm AS (
SELECT DISTINCT ON(pid)
host
, pid
, cmd
, min(tm) OVER(w) tmb --
, max(tm) OVER(w) tme --
FROM
src
WINDOW
w AS(PARTITION BY pid)
ORDER BY
pid
, tm
)
流程活动限制
请注意,相对于时间间隔的开始,遇到的第一个记录可能是已经填充了CMD字段(上图中的PID#1)的记录,也可能是NULL,表示按时间顺序填充的“高于”值的延续(PID#2) )。
由于先前的操作而导致没有CMD的PID的开始时间早于我们的时间间隔的开始,这意味着需要找到这些“开始”:

因为我们确定活动的下一个部分以填充的CMD值开头(并且存在填充的RSS,这意味着),条件索引将在这里为我们提供帮助:
CREATE INDEX ON pidstat(host, pid, tm DESC) WHERE cmd IS NOT NULL;-- ""
, precmd AS (
SELECT
t.host
, t.pid
, c.tm
, c.rss
, c.cmd
FROM
pidtm t
, LATERAL(
SELECT
*
FROM
pidstat -- , SELF JOIN
WHERE
(host, pid) = (t.host, t.pid) AND
tm < t.tmb AND
cmd IS NOT NULL --
ORDER BY
tm DESC
LIMIT 1
) c
WHERE
t.cmd IS NULL -- ""
)
如果我们想要(也想要)知道段活动的结束时间,那么对于每个PID,我们将必须使用“双向”来确定下限。
我们已经在PostgreSQL Antipatterns中使用了类似的技术:Registry Navigation。

--
, pstcmd AS (
SELECT
host
, pid
, c.tm
, NULL::bigint rss
, NULL::uuid cmd
FROM
pidtm t
, LATERAL(
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
tm < coalesce((
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
cmd IS NOT NULL
ORDER BY
tm
LIMIT 1
), x'7fffffff'::integer) -- MAX_INT4
ORDER BY
tm DESC
LIMIT 1
) c
)
帖子格式的JSON转换
请注意,我们
precmd/pstcmd仅选择了影响后续行的字段,以及所有不断变化的CPU / DSK-不。因此,原始表和这些CTE中的记录格式对我们而言是不同的。没问题!
- row_to_json-将每个包含字段的记录转换为json对象
- array_agg-收集'{...}'中的所有条目:: json []
- array_to_json-将array-from-JSON转换为JSON-array'[...]':: json
- json_populate_recordset-从JSON数组生成给定结构的选择
在这里,我们使用单个呼叫我们将找到的“开始”和“结束”粘贴到一个公共堆中,并添加到原始记录集中:json_populate_recordset而不是多个呼叫json_populate_record,因为它有时会更快。
--
, uni AS (
TABLE src
UNION ALL
SELECT
*
FROM
json_populate_recordset( --
NULL::pidstat
, (
SELECT
array_to_json(array_agg(row_to_json(t))) --
FROM
(
TABLE precmd
UNION ALL
TABLE pstcmd
) t
)
)
)
填补重复中的空白
让我们使用文章“ SQL HowTo:使用窗口函数构建链”中讨论的模型。首先,让我们选择“重复”组:
--
, grp AS (
SELECT
*
, count(*) FILTER(WHERE cmd IS NOT NULL) OVER(w) grp -- CMD
, count(*) FILTER(WHERE rss IS NOT NULL) OVER(w) grpm -- RSS
FROM
uni
WINDOW
w AS(PARTITION BY pid ORDER BY tm)
)
此外,根据CMD和RSS,这些组将彼此独立,因此它们可能看起来像这样:
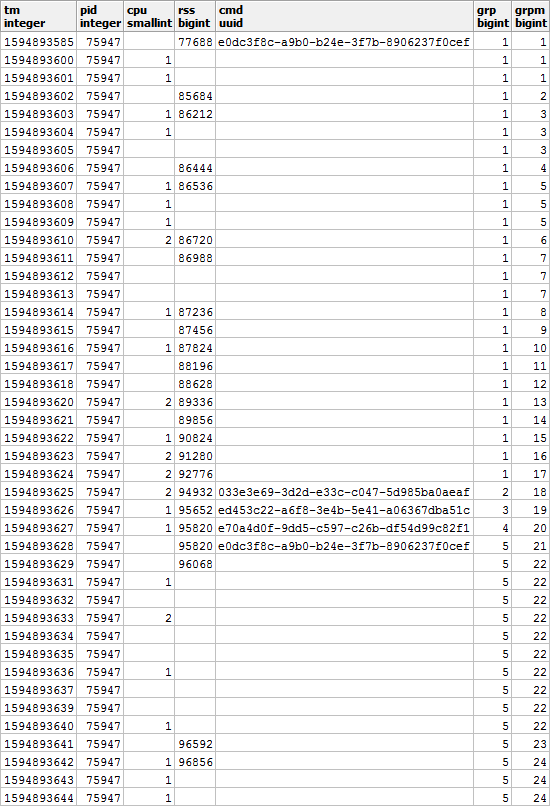
填补RSS中的空白并计算每个网段的持续时间,以便正确考虑随时间的负载分布:
--
, rst AS (
SELECT
*
, CASE
WHEN least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) >= greatest(tm, ((TABLE args) ->> 'dtb')::integer) THEN
least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) - greatest(tm, ((TABLE args) ->> 'dtb')::integer) + 1
END gln --
, first_value(rss) OVER(PARTITION BY pid, grpm ORDER BY tm) _rss -- RSS
FROM
grp
WINDOW
w AS(PARTITION BY pid, grp ORDER BY tm)
)
使用分组集进行多重分组
由于我们希望既可以看到整个过程的摘要信息,也可以看到按活动的不同部分进行的详细描述,所以我们将使用GROUPING SETS一次按几组键进行分组:
--
, gs AS (
SELECT
pid
, grp
, max(grp) qty -- PID
, (array_agg(cmd ORDER BY tm) FILTER(WHERE cmd IS NOT NULL))[1] cmd -- " "
, sum(cpu) cpu
, avg(_rss)::bigint rss
, min(tm) tmb
, max(tm) tme
, sum(gln) gln
FROM
rst
GROUP BY
GROUPING SETS((pid, grp), pid)
)
用例(array_agg(... ORDER BY ..) FILTER(WHERE ...))[1]使我们能够在分组时从整个集合中获得第一个非空(即使不是第一个非空)值,而无需进行其他移动。一次获取目标样本的多个部分的选项非常方便用于生成带有详细信息的各种报告,因此不需要重建所有详细数据,而是将其与主样本一起进入UI。
用字典代替JOIN
为所有找到的段创建一个CMD“字典”:
您可以在文章“ PostgreSQL反模式:让我们用字典找到沉重的联接”中阅读有关“掌握”技术的更多信息。
-- CMD
, cmdhs AS (
SELECT
json_object(
array_agg(cmd)::text[]
, array_agg(data)
)
FROM
diccmd
WHERE
cmd = ANY(ARRAY(
SELECT DISTINCT
cmd
FROM
gs
WHERE
cmd IS NOT NULL
))
)
现在我们改用它
JOIN,获得最终的“美丽”数据:
SELECT
pid
, grp
, CASE
WHEN grp IS NOT NULL THEN -- ""
cmd
END cmd
, (nullif(cpu::numeric / gln, 0))::numeric(32,2) cpu -- CPU ""
, nullif(rss, 0) rss
, tmb --
, tme --
, gln --
, CASE
WHEN grp IS NULL THEN --
qty
END cnt
, CASE
WHEN grp IS NOT NULL THEN
(TABLE cmdhs) ->> cmd::text --
END command
FROM
gs
WHERE
grp IS NOT NULL OR -- ""
qty > 1 --
ORDER BY
pid DESC
, grp NULLS FIRST;
最后,让我们确保执行时整个查询非常轻巧:

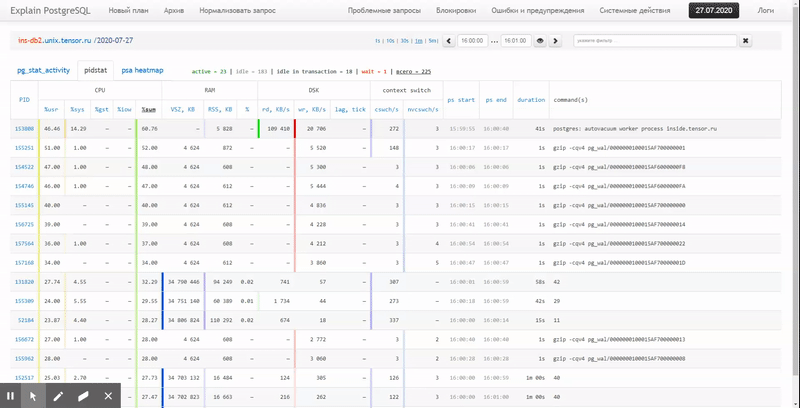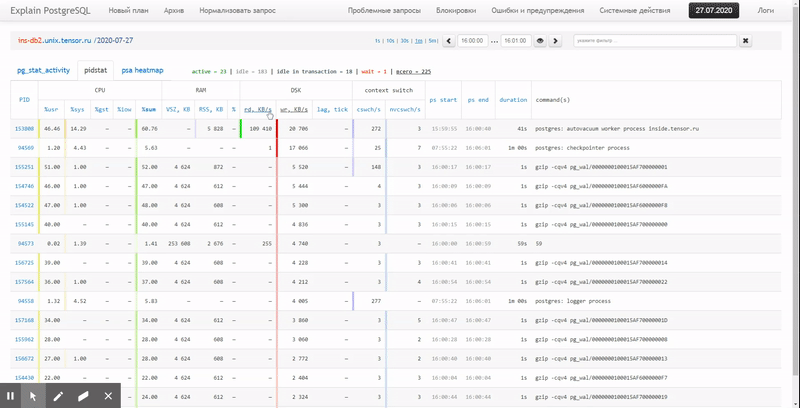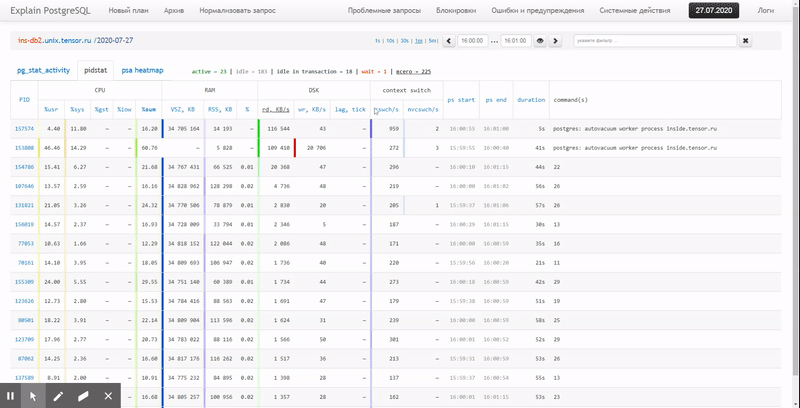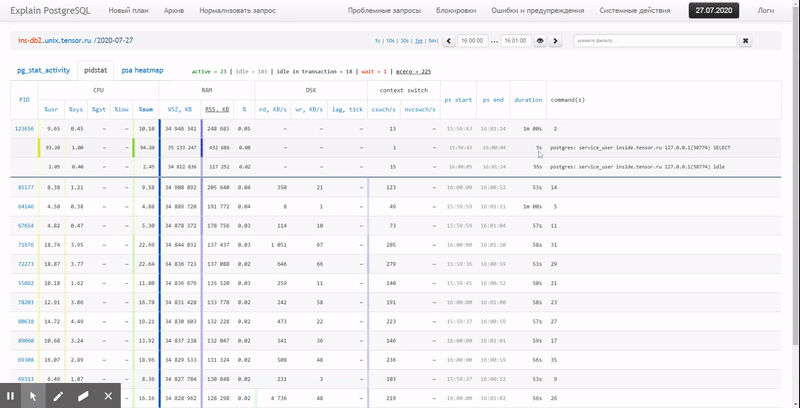
[请看
explorer.tensor.ru ]仅读取了44ms和33MB的数据!