
从架构的角度来看,IoT平台需要解决以下任务:
- 接收,接收和处理的数据量要求高带宽,存储和计算能力。
- 设备可以分布在广泛的地理区域
- 公司要求其架构不断发展,以便可以向客户提供新服务。
物联网平台的功能之一是对象和信号之间的独立性,这允许并行计算,从而提高了生产率。
来自传感器的数据是从PLC,DCS,微控制器等来源收集的,可以存储在时域中,以避免由于连接问题而造成数据丢失。数据可以是时间序列(事件),半结构化数据(日志和二进制文件)或非结构化数据(图像)。经常收集时间序列数据和事件(从每秒到几分钟)。然后将它们通过网络发送并存储在集中式数据湖和时间序列数据库TSDB中。 Data Lake可以是基于云的,本地数据中心或第三方存储。
可以使用基于简单或智能设定点的规则检查机制,使用称为“热路径”的数据流分析立即处理数据。高级分析可以包括数字孪生,机器学习,深度学习或基于物理的分析。这样的系统可以处理来自不同传感器的大量数据(从十分钟到一个月)。该数据存储在中间存储器中。这种分析称为“冷路径”,通常由调度程序启动,或者在数据可用且需要大量计算资源时启动。高级分析通常需要其他信息,例如受监视的车辆模型和操作属性,这些信息可以在资产注册表中找到。资产注册表包含有关资产类型的信息,包括其名称,序列号,符号名称,位置,操作能力,其组成的零件的历史记录以及它在制造过程中扮演的角色。在资产注册表中,我们可以存储每个资产的尺寸,逻辑名称,度量单位和边界范围的列表。在工业领域,此静态信息对于正确的分析模型至关重要。在工业领域,此静态信息对于正确的分析模型至关重要。在工业领域,此静态信息对于正确的分析模型至关重要。
开发自定义平台的原因:
- 投资回报:预算少;
- 技术:无论供应商如何使用技术;
- 数据保密;
- 集成:需要与新的或过时的平台建立一定程度的集成;
- 其他限制。
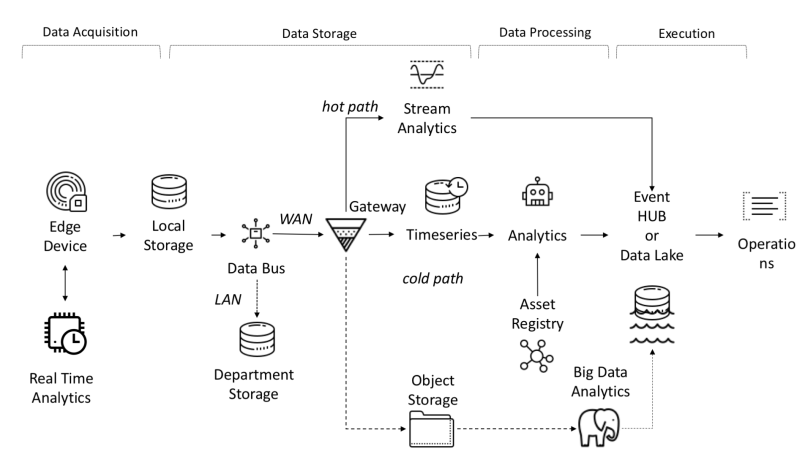
I-IoT中的端到端数据流
Edge平台的自定义实现示例
该图显示了以下平台链接的实现:
- 数据源:例如,选择具有激活的OPC服务器的Simatic PLCSIM Advanced控制器模拟器,如上一篇文章所述;
- 选择安装了node-red-contrib-opcua插件的流行Node-Red平台作为边界网关;
- MQTT经纪人Mosquitto用作流中其他链接之间的数据传输的调度程序;
- Apache Kafka用作分布式流平台,可使用kafka-streams进行热路径分析。
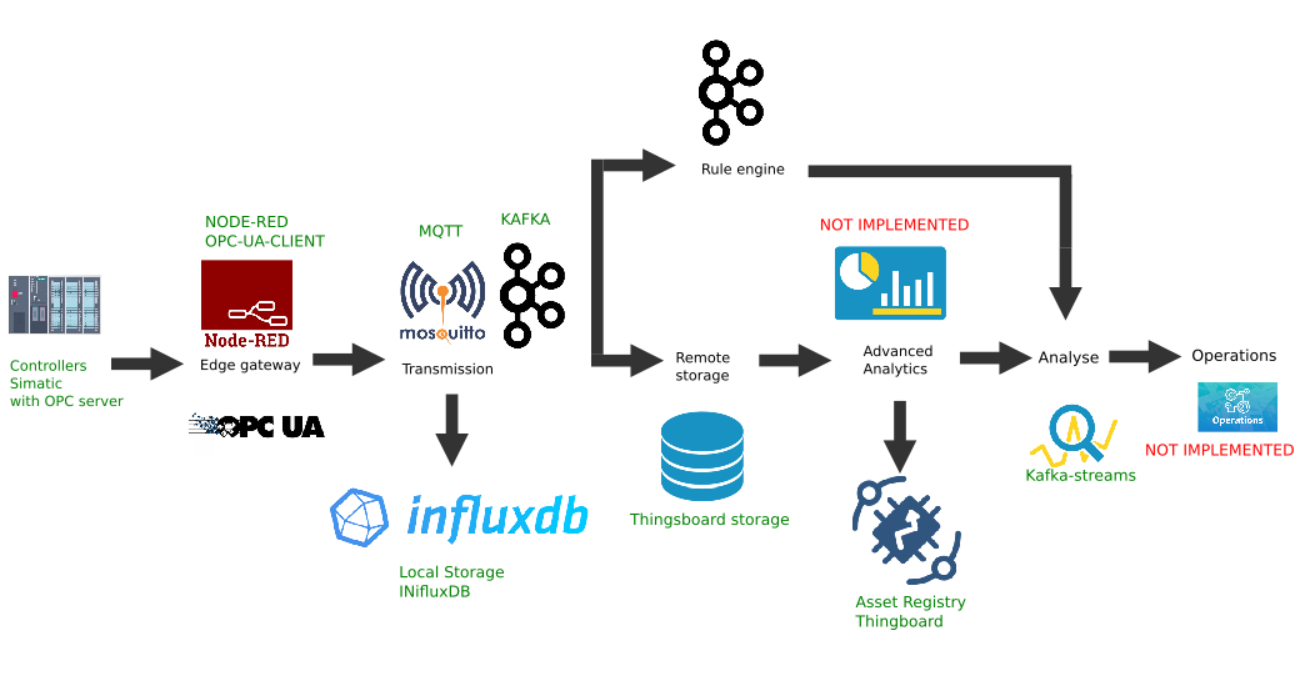
节点红色边缘网关
作为边缘计算网关,我们将使用Node-red,这是一个具有许多不同插件的简单自定义平台。工业适配器的角色由node-red-contrib-opcua插件扮演。对于通过订阅方法从控制器进行的多个数据收集,将使用以下节点:OpcUa浏览器和OpcUa客户端。在OPC浏览器节点中,配置了OPC服务器的URL(端点)和主题,该主题指定可读数据块的名称空间和名称,例如:ns = 3; s =“ HMI_Alarms_Area”。在OPC客户端节点中,还指定了OPC服务器的url,将SUBSCRIBE和数据更新间隔设置为Action。
节点红色主流
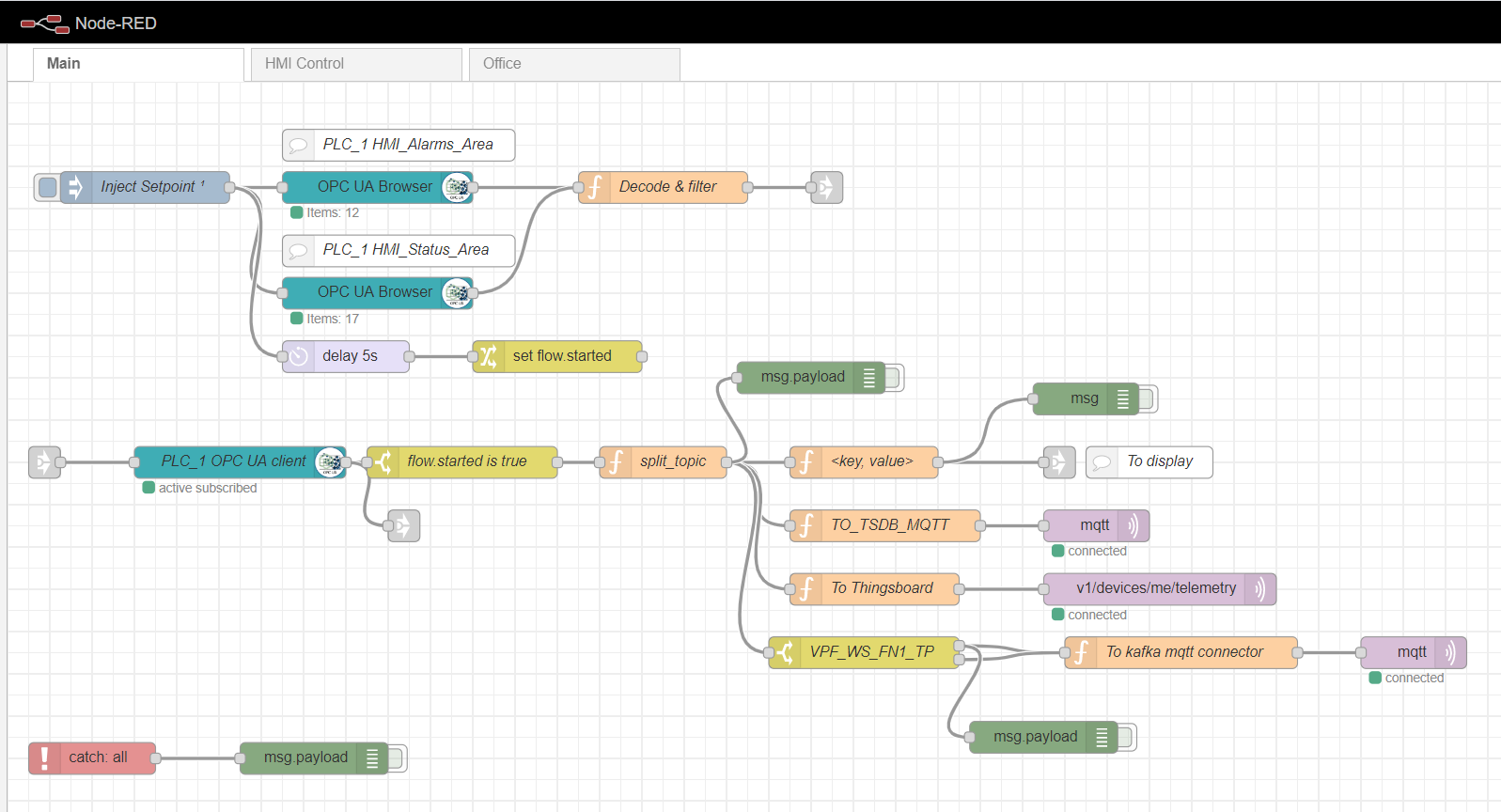
设置OPC浏览器节点

OPC-client

为了订阅读取多个数据,必须根据OPC协议准备并从控制器下载标签。为此,首先,将注入节点与唯一的一次复选框一起使用,这将触发一次读取OPC浏览器节点中指定的数据块。然后,数据由解码和过滤功能处理。之后,OPC客户端节点订阅并从控制器读取更改的数据。流的进一步处理取决于特定的实现和要求。在我的示例中,我处理数据以进一步将其发送到不同主题的MQTT代理。
HMI控件和Office选项卡是基于Scadavis.io和如本文前面所述的节点红色仪表板的简单HMI实现。
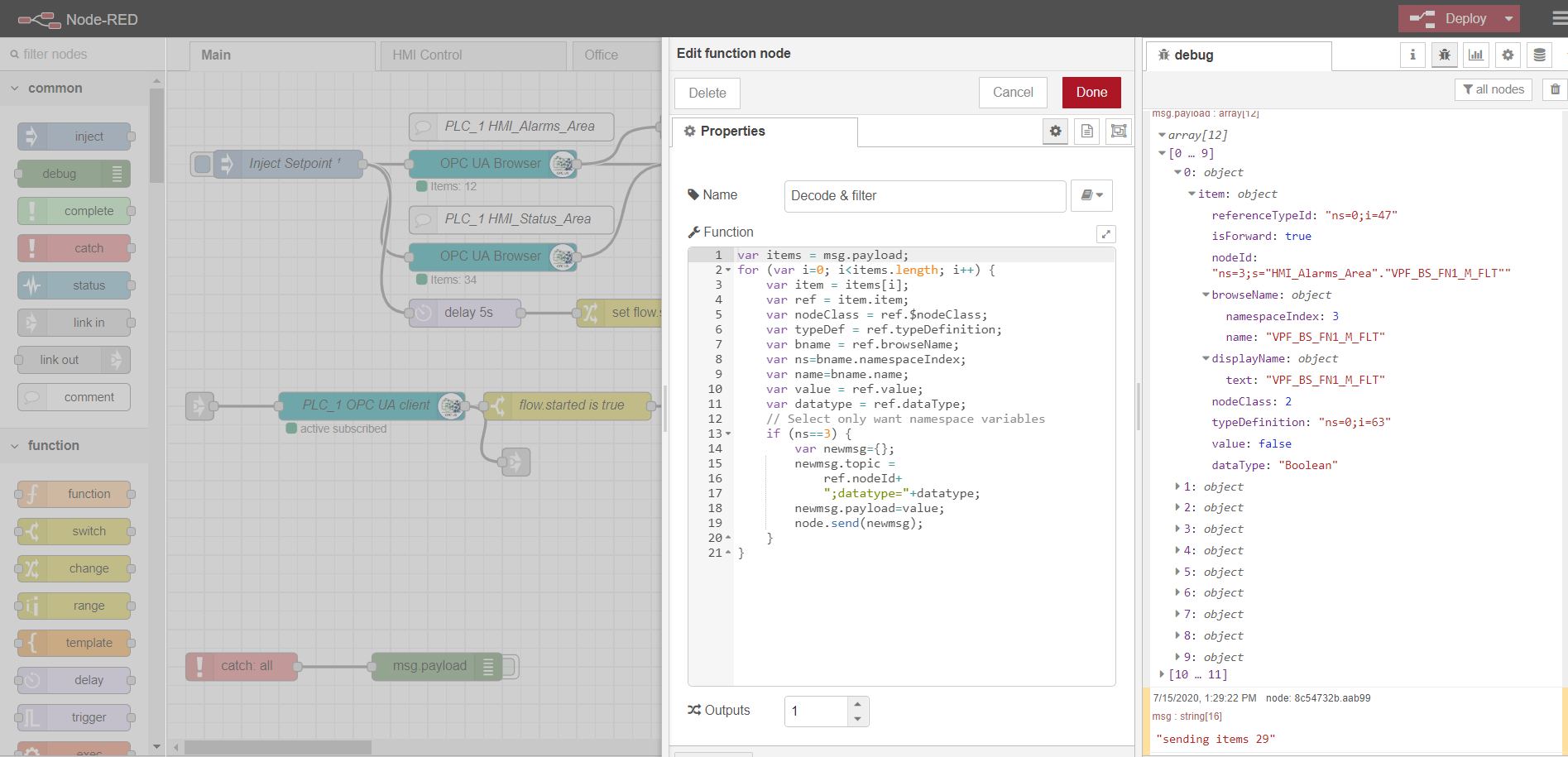
解析来自OPC浏览器节点的数据的示例:
var items = msg.payload;
for (var i=0; i<items.length; i++) {
var item = items[i];
var ref = item.item;
var nodeClass = ref.$nodeClass;
var typeDef = ref.typeDefinition;
var bname = ref.browseName;
var ns=bname.namespaceIndex;
var name=bname.name;
var value = ref.value;
var datatype = ref.dataType;
// Select only want namespace variables
if (ns==3) {
var newmsg={};
newmsg.topic =
ref.nodeId+
";datatype="+datatype;
newmsg.payload=value;
node.send(newmsg);
}
}
MQTT经纪人
任何实现都可以用作代理。就我而言,Mosquitto代理已经安装和配置了。代理执行在Edge网关和其他平台参与者之间传输数据的功能。有一些带有负载平衡和分布式体系结构的示例(例如此处)。在这种情况下,我们将限制自己使用数据加密而不加密的mqtt代理。
时间序列数据的本地存储
在NoSql时间序列数据库中记录和存储时间序列数据非常方便。InfluxData堆栈可以很好地达到我们的目的。我们需要这个堆栈中的四个服务:
InfluxDB是一个开源时间序列数据库,它是TICK(Telegraf,InfluxDB,Chronograf,Kapacitor)堆栈的一部分。专为高负载数据处理而设计,并提供类似于SQL的查询语言InfluxQL以与数据进行交互。
Telegraf是一个用于从外部物联网系统,传感器等收集指标和事件并将其发送到InfluxDB的代理。它被配置为从mqtt主题收集数据。
Kapacitor是InfluxDB 1.x的内置数据引擎,并且是InfluxDB平台的集成组件。可以将该服务配置为监视各种设置和警报,以及安装用于将事件发送到外部系统(例如Kafka,电子邮件等)的处理程序。
Chronograf是InfluxDB平台的用户界面和管理组件。用于通过实时可视化快速创建仪表板。
堆栈的所有组件都可以在本地运行或设置Docker容器。
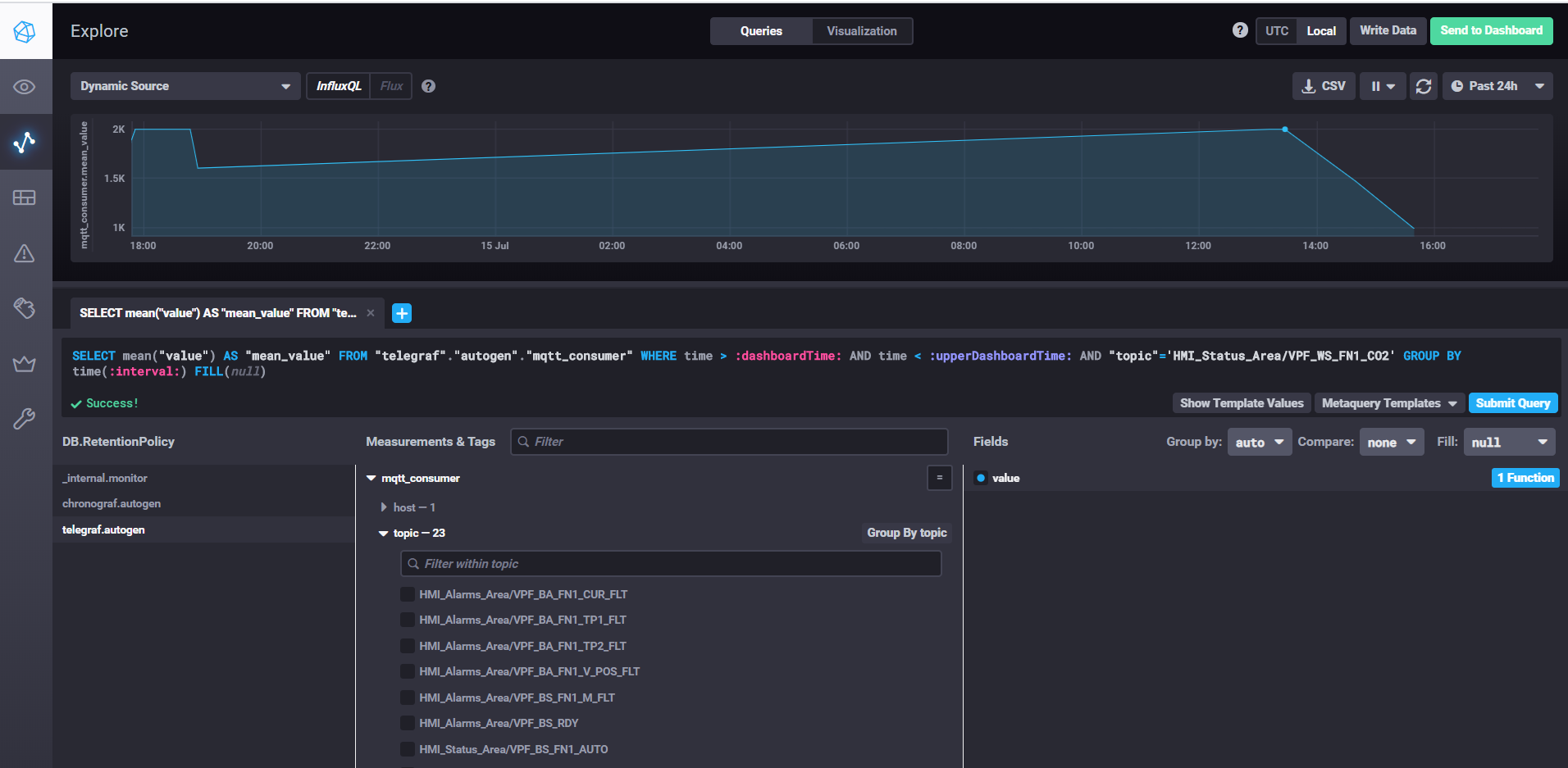
使用Chronograf获取数据并自定义仪表板
要启动InfluxDB,只需运行influxd命令,即可在influxdb.conf设置中指定存储位置和其他属性,默认情况下,数据存储在.influxdb目录的用户目录中。
要启动telegraf,您需要运行命令telegraf -config telegraf.conf,您可以在其中指定设置中指标和事件的来源,在我们的mqtt示例中,它看起来像这样:
# # Read metrics from MQTT topic(s)
[[inputs.mqtt_consumer]]
servers = ["tcp://192.168.1.107:1883"]
qos = 0
topics = ["HMI_Status_Area/#", "HMI_Alarms_Area/#"]
data_format = "value"
data_type = "float"
在服务器属性中,指定mqtt代理的URL,如果足以写入数据而无需确认,则qos可以保留0。在topics属性中,指定我们将从中读取数据的主题的mqtt掩码。例如,HMI_Status_Area /#表示我们阅读了所有带有HMI_Status_Area前缀的主题。因此,每个主题的telegraf将在数据库中创建自己的指标,并在其中写入数据。
要启动kapacitor,需要运行kapacitord -config kapacitor.conf命令。这些属性可以保留为默认值,并且可以使用chronograf进行进一步的设置。
要启动chronograf,只需运行同名的chronograf命令。 Web界面将在localhost上可用:8888 /
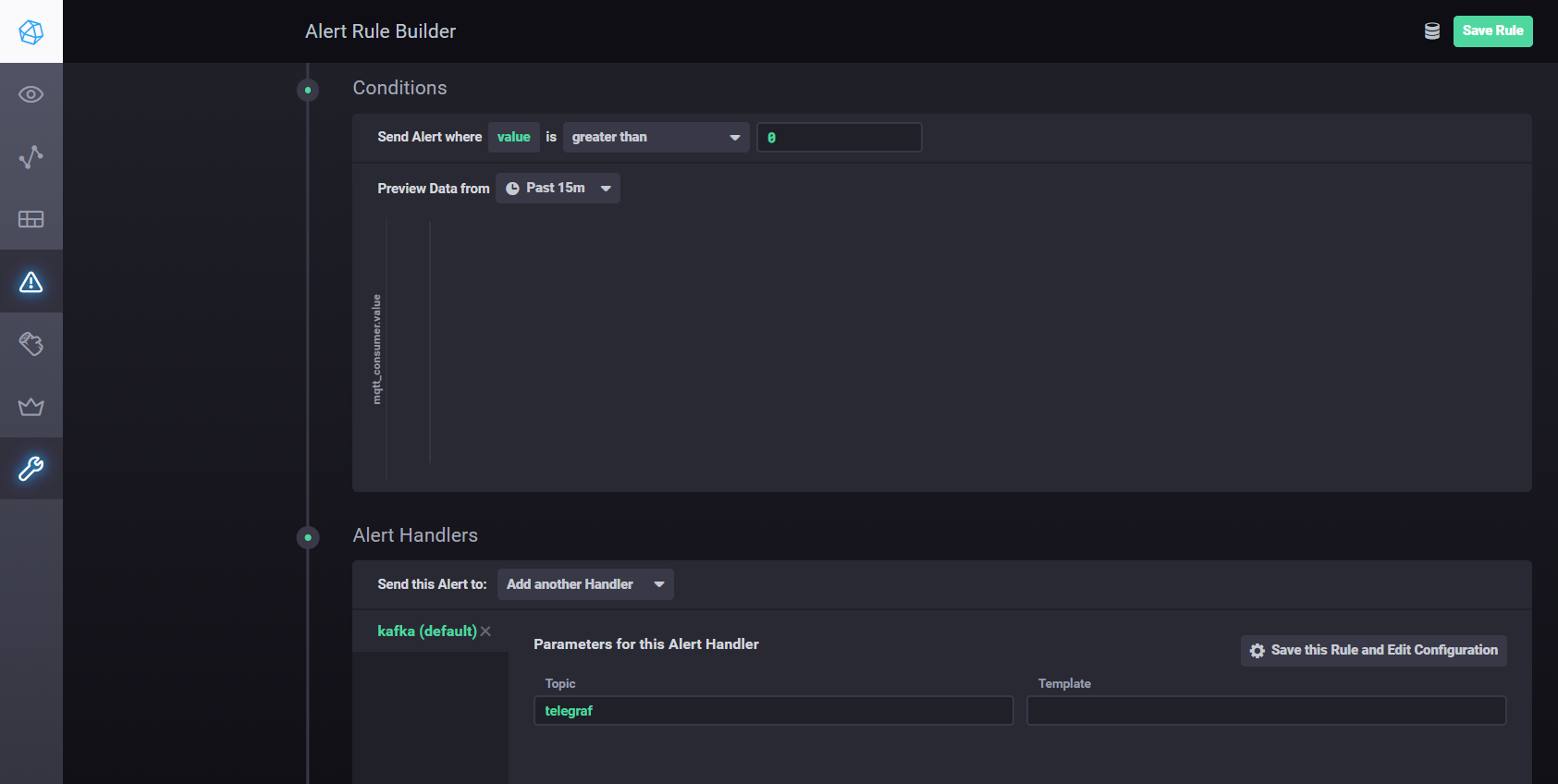
要使用Kapacitor配置设置和警报,您可以使用手册。简而言之-您需要转到Chronograf的Alerting选项卡,并使用Build Alert Rule按钮创建一个新规则,界面直观,所有操作均可视化完成。设置将处理结果发送到kafka等 您需要在“条件”部分添加处理程序
Kapacitor处理程序设置
使用Apache Kafka进行分布式流
对于建议的体系结构,有必要将数据收集与处理分开,以提高可伸缩性和层独立性。我们可以使用队列来实现此目标。实现可以是Java消息服务(JMS)或高级消息队列协议(AMQP),但是在这种情况下,我们将使用Apache Kafka。大多数分析平台都支持Kafka,它具有很高的性能和可伸缩性,并且具有良好的Kafka-streams库。
您可以使用Node-red node-red-contrib-kafka-manager插件与Kafka进行交互。但是,考虑到收集与数据处理的分离,我们将安装MQTT插件,该插件订阅了Mosquitto主题。 MQTT插件在这里可用。
要配置连接器,请将kafka-connect-mqtt-1.1-SNAPSHOT.jar和org.eclipse.paho.client.mqttv3-1.0.2.jar库(或其他版本)复制到kafka / libs /目录中。然后,在/ config目录中,您需要创建一个具有以下内容的属性文件mqtt.properties:
name=mqtt
connector.class=com.evokly.kafka.connect.mqtt.MqttSourceConnector
tasks.max=1
kafka.topic=streams-measures
mqtt.client_id=mqtt-kafka-123456789
mqtt.clean_session=true
mqtt.connection_timeout=30
mqtt.keep_alive_interval=60
mqtt.server_uris=tcp://192.168.1.107:1883
mqtt.topic=mqtt
先前启动了zookeeper-server和kafka-server之后,我们可以使用以下命令启动连接器:
connect-standalone.bat …\config\connect-standalone.properties …\config\mqtt.properties
从mqtt主题(mqtt.topic = mqtt),数据将被写入Kafka主题流度量(kafka.topic =流度量)。
举一个简单的例子,您可以使用kafka-streams库创建一个Maven项目。
使用kafka-streams,您可以实施各种服务和方案以进行热分析和流数据处理。
在一段时间内将当前温度与设定值进行比较的示例。
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("streams-measures");
KStream<Windowed<String>, String> max = source
.selectKey((String key, String value) -> {
return getKey(key, value);
}
)
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)))
.reduce((String value1, String value2) -> {
double v1=getValue(value1);
double v2=getValue(value2);
if ( v1 > v2)
return value1;
else
return value2;
}
)
.toStream()
.filter((Windowed<String> key, String value) -> {
String measure = tagMapping.get(key.key());
double parsedValue = getValue(value);
if (measure!=null) {
Double threshold = excursion.get(measure);
if (threshold!=null) {
if(parsedValue > threshold) {
log.info(String.format("%s : %s; Threshold: %s", key.key(), parsedValue, threshold));
return true;
}
return false;
}
} else {
log.severe("UNKNOWN MEASURE! Did you mapped? : " + key.key());
}
return false;
}
);
final Serde<String> STRING_SERDE = Serdes.String();
final Serde<Windowed<String>> windowedSerde = Serdes.serdeFrom(
new TimeWindowedSerializer<>(STRING_SERDE.serializer()),
new TimeWindowedDeserializer<>(STRING_SERDE.deserializer(), TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)).size()));
// the output
max.to("excursion", Produced.with(windowedSerde, Serdes.String()));
资产登记处
实际上,资产注册表不是Edge平台的结构组件,而是云IoT环境的一部分。但是此示例显示了Edge和Cloud如何相互作用。
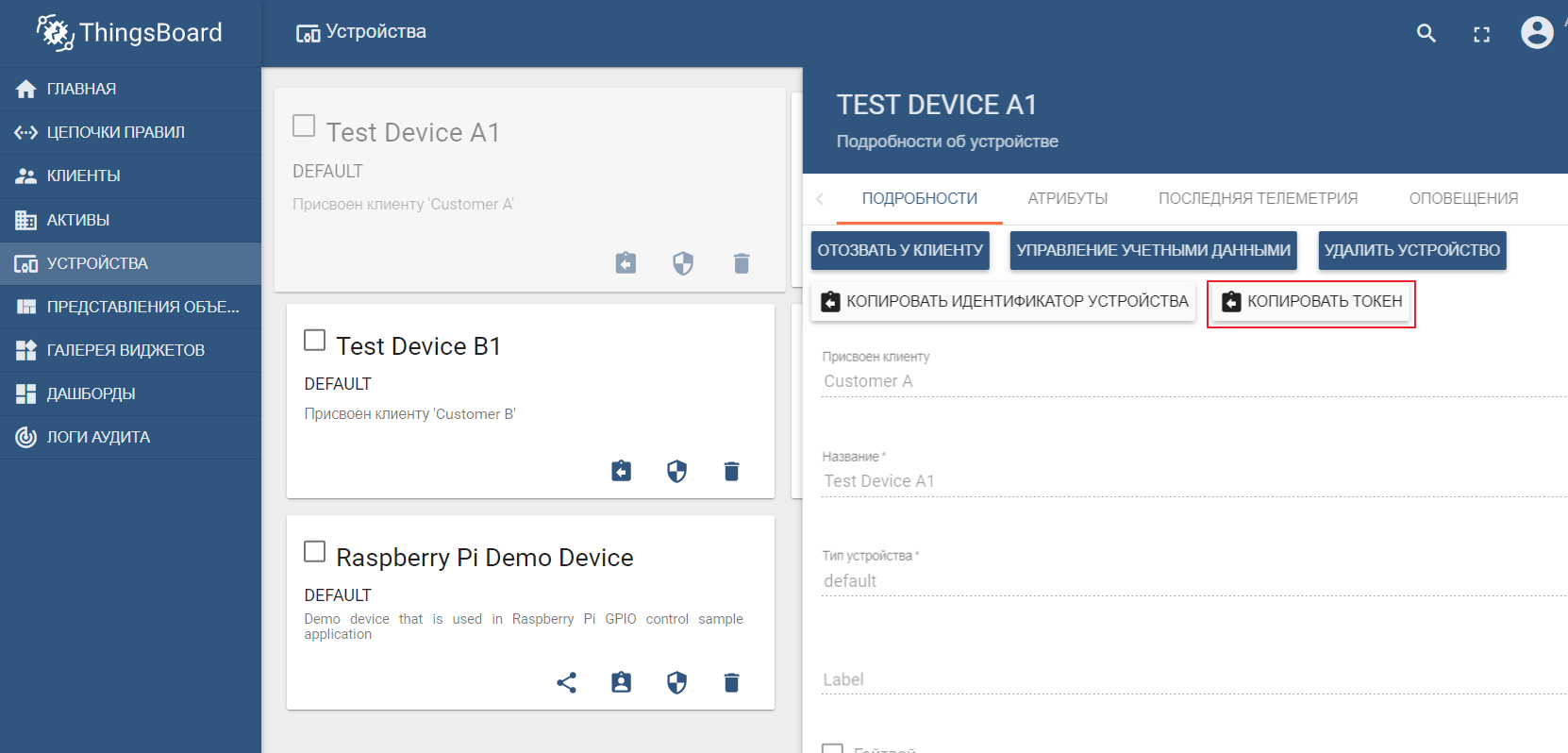
作为资产注册表,我们将使用流行的ThingsBoard IoT平台,该平台的界面也非常直观。可以通过演示数据进行安装。该平台可以在本地,泊坞窗中安装,也可以使用现成的云环境安装。
演示数据集包括可以向其发送值的测试设备(您可以轻松创建一个新设备)。默认情况下,ThingsBoard以其自己的mqtt代理启动,您需要将其连接并发送数据以json格式。假设我们要从TEST DEVICE A1将数据发送到ThingsBoard。为此,我们需要使用A1_TEST_TOKEN作为登录名连接到本地主机:1883上的ThingBoard代理,可以从设备设置中复制该登录名。然后,我们可以将数据发布到主题v1 / devices / me /遥测:{“温度”:26}
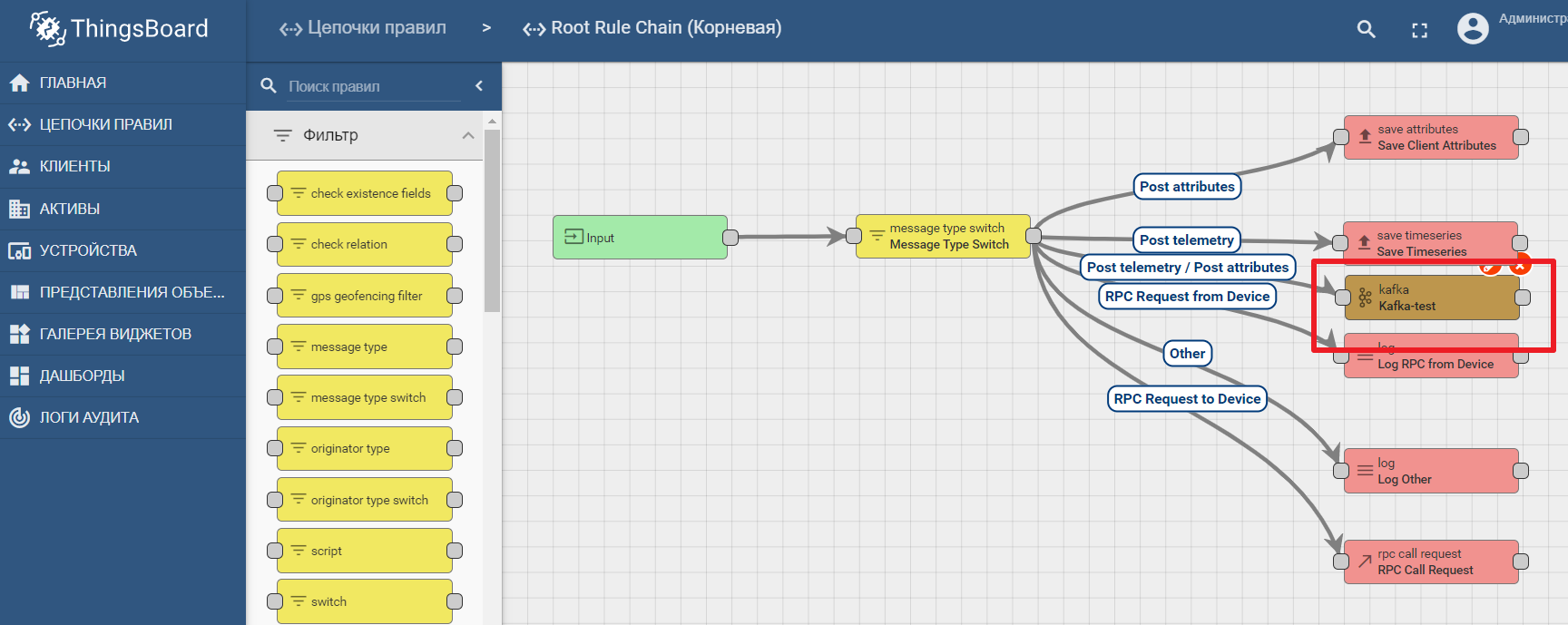
平台文档包含用于在Kafka中设置数据传输和处理分析的手册-使用Kafka,Kafka Streams和ThingsBoard的IoT数据分析
在Thingsboard中使用kafka节点的示例
结论
现代IT技术和开放协议使设计任何复杂的系统成为可能。边缘平台是工业环境和基于云的物联网平台之间的连接点。它可以分解为宏组件,边缘网关在其中扮演着关键角色,负责将数据从设备转发到IoT数据中心。开放数据流工具可实现高效的分析和边缘计算。