在本文中,我将向您介绍BigQuery的主要功能,并通过具体示例展示其功能。您可以编写基本查询,然后对演示数据进行尝试。
什么是SQL以及它具有哪些方言
SQL(结构化查询语言)是用于处理数据库的结构化查询语言。有了它的帮助,您可以接收,添加到数据库并修改大量数据。Google BigQuery支持两种方言:标准SQL和传统SQL。
选择哪种方言取决于您的偏好,但是Google推荐使用Standard SQL,这有很多优点:
- 处理嵌套字段和重复字段时的灵活性和功能性。
- 支持DML和DDL语言,使您可以更改表中的数据以及在GBQ中操作表和视图。
- 处理大量数据比Legasy SQL快。
- 支持所有当前和将来的BigQuery更新。
您可以在帮助中详细了解方言之间的区别。
默认情况下,Google BigQuery查询针对旧版SQL运行。
有几种切换到标准SQL的方法:
- 在BigQuery界面的查询编辑窗口中,选择“显示选项”,然后取消选中“使用旧版SQL”选项旁边的框

- 在查询之前添加#standardSQL行,并在新行上开始查询

从哪里开始
为了使您可以在阅读本文的同时练习运行查询,我为您准备了一个包含演示数据的表。将电子表格中的数据加载到您的Google BigQuery项目中。
如果您还没有GBQ项目,请创建一个。为此,您需要在Google Cloud Platform中有一个有效的结算帐户。您将需要链接卡,但是在您不知情的情况下,也不会从卡中扣除资金,此外,注册后,您将获得300美元,为期12个月,您可以将其用于存储和处理数据。
Google BigQuery功能
构建查询时,最常用的函数组是聚合函数,日期函数,字符串函数和窗口函数。现在更多地了解它们。
汇总功能
聚合函数使您可以在整个表中获取汇总值。例如,计算平均支票,每月总收入或突出显示购买次数最多的用户细分。
以下是本节中最受欢迎的功能:
| 旧版SQL | 标准SQL | 该功能做什么 |
|---|---|---|
| AVG(字段) | AVG([DISTINCT](字段)) | 返回字段列的平均值。在标准SQL中添加DISTINCT子句时,仅针对字段列中具有唯一(非重复)值的行计算平均值 |
| 最大(场) | 最大(场) | 返回字段列中的最大值 |
| MIN(场) | MIN(场) | 返回字段列中的最小值 |
| SUM(字段) | SUM(字段) | 从字段列返回值的总和 |
| COUNT(字段) | COUNT(字段) | 返回列字段中的行数 |
| EXACT_COUNT_DISTINCT(字段) | COUNT([DISTINCT](字段)) | 返回字段列中唯一行的数量 |
有关所有功能的列表,请参见“帮助:旧版SQL和标准SQL”。
让我们看看列出的函数如何与示例数据演示一起工作。让我们计算交易的平均收入,最高和最低金额的购买,总收入以及所有交易的数量。为了检查购买是否重复,我们还将计算唯一交易的数量。为此,我们编写了一个查询,其中指出了Google BigQuery项目,数据集和表的名称。
#legasy SQL
SELECT
AVG(revenue) as average_revenue,
MAX(revenue) as max_revenue,
MIN(revenue) as min_revenue,
SUM(revenue) as whole_revenue,
COUNT(transactionId) as transactions,
EXACT_COUNT_DISTINCT(transactionId) as unique_transactions
FROM
[owox-analytics:t_kravchenko.Demo_data]#standard SQL
SELECT
AVG(revenue) as average_revenue,
MAX(revenue) as max_revenue,
MIN(revenue) as min_revenue,
SUM(revenue) as whole_revenue,
COUNT(transactionId) as transactions,
COUNT(DISTINCT(transactionId)) as unique_transactions
FROM
`owox-analytics.t_kravchenko.Demo_data`结果,我们得到以下结果:
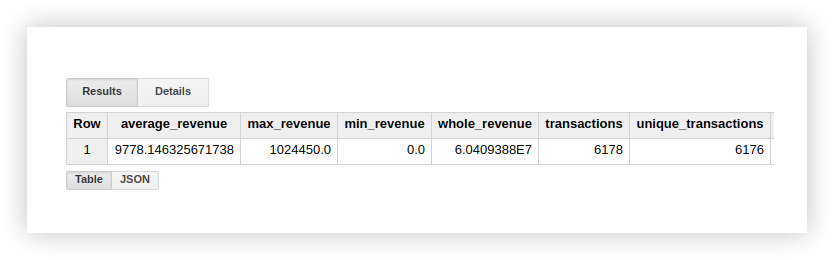
您可以使用标准Google Sheets函数(SUM,AVG和其他)或数据透视表在原始表中使用演示数据检查计算结果。
从上面的屏幕快照中可以看到,事务数和唯一事务数是不同的。
这表明在我们的表中有2个事务具有重复的transactionId:
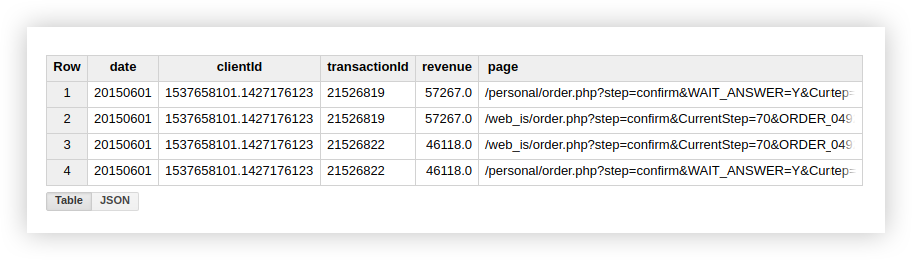
因此,如果您对唯一事务感兴趣,请使用计算唯一行的函数。另外,您可以在使用聚合函数之前使用GROUP BY子句对数据进行分组以消除重复项。
处理日期的功能(日期功能)
这些功能使您可以处理日期:更改日期格式,选择所需的部分(日,月或年),将日期移动一定的时间间隔。
在以下情况下,它们可能对您有用:
- 设置端到端分析时-将不同来源的日期和时间转换为单一格式。
- 创建自动更新的报告或触发的邮件时。例如,当您需要最近2个小时,一周或一个月的数据时。
- 创建同类群组报告时,需要在几天,几周,几个月的时间内获取数据。
最常用的日期函数:
| 旧版SQL | 标准SQL | 该功能做什么 |
|---|---|---|
| 当前日期 () | 当前日期 () | 以%YYYY-%MM-%DD的格式返回当前日期 |
| DATE(时间戳) | DATE(时间戳) | 从%YYYY-%MM-%DD%H:%M:%S格式转换日期。格式为%YYYY-%MM-%DD |
| DATE_ADD(时间戳,间隔,间隔单位) | DATE_ADD(timestamp, INTERVAL interval interval_units) | timestamp, interval.interval_units.
Legacy SQL YEAR, MONTH, DAY, HOUR, MINUTE SECOND, Standard SQL — YEAR, QUARTER, MONTH, WEEK, DAY |
| DATE_ADD(timestamp, — interval, interval_units) | DATE_SUB(timestamp, INTERVAL interval interval_units) | timestamp, interval |
| DATEDIFF(timestamp1, timestamp2) | DATE_DIFF(timestamp1, timestamp2, date_part) | timestamp1 timestamp2.
Legacy SQL , Standard SQL — date_part (, , , , ) |
| DAY(timestamp) | EXTRACT(DAY FROM timestamp) | timestamp. 1 31 |
| MONTH(timestamp) | EXTRACT(MONTH FROM timestamp) | timestamp. 1 12 |
| YEAR(timestamp) | EXTRACT(YEAR FROM timestamp) | timestamp |
有关所有功能的列表,请参见旧版SQL和标准SQL帮助。
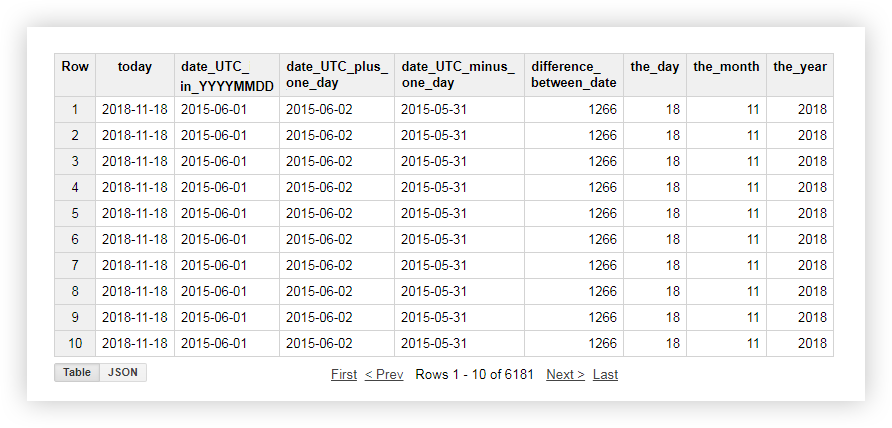
让我们看一下数据演示,上述每个函数的工作方式。例如,我们获得当前日期,将原始表中的日期转换为%YYYY-%MM-%DD格式,然后减去并增加一天。然后,我们计算原始表中当前日期与日期之间的差,并将当前日期分别划分为年,月和日。为此,您可以复制下面的示例查询,并用自己的名称替换项目,数据集和数据表的名称。
#legasy SQL
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day,
DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day,
DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date,
DAY( CURRENT_DATE() ) AS the_day,
MONTH( CURRENT_DATE()) AS the_month,
YEAR( CURRENT_DATE()) AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data]
#standard SQL
SELECT
today,
date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day,
DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day,
DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date,
EXTRACT(DAY FROM today ) AS the_day,
EXTRACT(MONTH FROM today ) AS the_month,
EXTRACT(YEAR FROM today ) AS the_year
FROM (
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD
FROM
`owox-analytics.t_kravchenko.Demo_data`)
申请后,您将收到以下报告:
使用字符串的函数(字符串函数)
字符串函数允许您形成字符串,提取和替换子字符串,计算字符串的长度以及原始字符串中子字符串的序号。
例如,在他们的帮助下,您可以:
- 通过传递到页面URL的UTM标签在报表中进行过滤。
- 如果来源和活动的名称写在不同的寄存器中,则将数据统一化。
- 替换报告中的错误数据,例如,如果发送的广告系列名称有错字。
使用字符串的最流行功能:
| 旧版SQL | 标准SQL | 该功能做什么 |
|---|---|---|
| CONCAT('str1','str2')或'str1'+'str2' | CONCAT('str1','str2') | 将多个字符串'str1'和'str2'连接成一个字符串 |
| 'str1'包含'str2' | REGEXP_CONTAINS('str1', 'str2') 'str1' LIKE ‘%str2%’ | true 'str1' ‘str2’.
Standard SQL ‘str2’ re2 |
| LENGTH('str' ) | CHAR_LENGTH('str' )
CHARACTER_LENGTH('str' ) |
'str' ( ) |
| SUBSTR('str', index [, max_len]) | SUBSTR('str', index [, max_len]) | max_len, index 'str' |
| LOWER('str') | LOWER('str') | 'str' |
| UPPER(str) | UPPER(str) | 'str' |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | 返回字符串'str1'中第一次出现的字符串'str2'的索引,否则-0 |
| 替换('str1','str2','str3') | 替换('str1','str2','str3') | 将字符串'str1'子字符串'str2'替换为子字符串'str3' |
更多详细信息-在帮助中:Legacy SQL和Standard SQL。
让我们看看演示数据的示例如何使用所描述的功能。假设我们有3个单独的列,分别包含日,月和年的值:
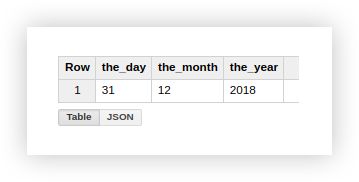
使用这种格式的日期不是很方便,因此我们将其合并为一个列。为此,请使用下面的SQL查询,并且不要忘记添加项目,数据集和Google BigQuery表的名称。
#legasy SQL
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1,
the_day+'-'+the_month+'-'+the_year AS mix_string2
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
mix_string1,
mix_string2
#standard SQL
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
mix_string1
执行请求后,我们会在一列中收到日期:

通常,在站点上加载特定页面时,URL包含用户选择的变量的值。这可以是付款或交付方式,交易号,客户要在其上取货的实体商店的索引等。使用SQL查询,您可以从页面地址中提取这些参数。
让我们看一下如何以及为什么这样做的两个例子。
例子1。假设我们想知道用户从实体商店提取商品的购买次数。为此,您需要计算从URL包含子字符串shop_id(物理商店的索引)的页面发送的交易数量。我们使用以下查询进行此操作:
#legasy SQL
SELECT
COUNT(transactionId) AS transactions,
check
FROM (
SELECT
transactionId,
page CONTAINS 'shop_id' AS check
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
check
#standard SQL
SELECT
COUNT(transactionId) AS transactions,
check1,
check2
FROM (
SELECT
transactionId,
REGEXP_CONTAINS( page, 'shop_id') AS check1,
page LIKE '%shop_id%' AS check2
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
check1,
check2
从结果表中,我们看到从包含shop_id的页面发送了5502笔交易(check = true):
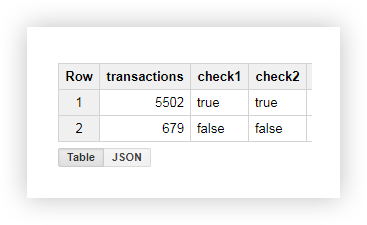
示例2。假设您为每种投放方式分配了delivery_id,并将此参数的值写入页面URL。要找出用户选择了哪种交付方式,请在单独的列中选择delivery_id。
为此,我们使用以下查询:
#legasy SQL
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
LENGTH(page_lower_case) AS page_length,
INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
[owox-analytics:t_kravchenko.Demo_data])))
ORDER BY
page_lower_case ASC
#standard SQL
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
CHAR_LENGTH(page_lower_case) AS page_length,
STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
`owox-analytics.t_kravchenko.Demo_data`)))
ORDER BY
page_lower_case ASC
结果,我们在Google BigQuery中获得了下表:

用于处理数据子集的函数或窗口函数(窗口函数)
这些功能类似于我们上面讨论的聚合功能。它们的主要区别在于,不对使用查询选择的整个数据集执行计算,而是对部分数据(子集或窗口)执行计算。
使用窗口函数,您可以按组聚合数据,而无需使用JOIN运算符组合多个查询。例如,通过广告活动计算平均收入,按设备计算交易次数。通过在报告中添加另一个字段,您可以轻松地找到例如黑色星期五的广告活动的收入份额或通过移动应用程序进行的交易份额。
与每个函数一起,必须在请求中写入一个OVER表达式,该表达式定义了窗口边界。OVER包含3个可以使用的组件:
- PARTITION BY-定义用于将源数据划分为子集的属性,例如PARTITION BY clientId,DayTime。
- ORDER BY-定义子集中行的顺序,例如ORDER BY hour DESC。
- WINDOW FRAME-允许您根据特定特征处理子集中的行。例如,您可以计算的不是窗口中所有行的总和,而是仅计算当前行之前的前五行。
下表总结了最常用的窗口函数:
| 旧版SQL | 标准SQL | 该功能做什么 |
|---|---|---|
| AVG(字段)
COUNT(字段) COUNT(DISTINCT字段) MAX() MIN() SUM() |
AVG([DISTINCT](字段))
COUNT(字段) COUNT([DISTINCT](字段)) MAX(字段) MIN(字段) SUM(字段) |
, , , field .
DISTINCT , () |
| 'str1' CONTAINS 'str2' | REGEXP_CONTAINS('str1', 'str2') 'str1' LIKE ‘%str2%’ | true 'str1' ‘str2’.
Standard SQL ‘str2’ re2 |
| DENSE_RANK() | DENSE_RANK() | |
| FIRST_VALUE(field) | FIRST_VALUE (field[{RESPECT | IGNORE} NULLS]) | field .
field . RESPECT IGNORE NULLS , NULL |
| LAST_VALUE(field) | LAST_VALUE (field [{RESPECT | IGNORE} NULLS]) | field .
field . RESPECT IGNORE NULLS , NULL |
| LAG(field) | LAG (field[, offset [, default_expression]]) | field .
Offset , . . Default_expression — , , |
| LEAD(field) | LEAD (field[, offset [, default_expression]]) | field .
Offset , . . Default_expression — , , |
您可以在旧版SQL和标准SQL的帮助中看到所有功能的列表:聚合分析功能,导航功能。
示例1.假设我们要分析买家在工作时间和非工作时间的活动。为此,有必要将交易分为两组并计算我们感兴趣的指标:
- 第1组-在工作时间9:00到18:00之间购物。
- 第2组-在工作时间00:00至9:00和18:00至00:00之外进行购买。
除了工作时间和非工作时间之外,另一个用于形成窗口的标志是clientId,即对于每个用户,我们将有两个窗口:
| 子集(窗口) | clientId | 白天 |
|---|---|---|
| 1个窗口 | clientId 1 | 工作时间 |
| 2窗 | clientId 2 | 非工作时间 |
| 3窗 | clientId 3 | 工作时间 |
| 4窗 | clientId 4 | 非工作时间 |
| N窗 | clientId N | 工作时间 |
| N + 1个窗口 | clientId N +1 | 非工作时间 |
让我们为演示数据计算每个用户在工作时间和非工作时间的平均,最大,最小和总收入,交易数和唯一交易数。下面的查询将帮助我们做到这一点。
#legasy SQL
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
#standard SQL
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
让我们使用clientId ='102041117.1428132012'的用户之一的示例来查看结果。在该用户的原始表中,我们具有以下数据:
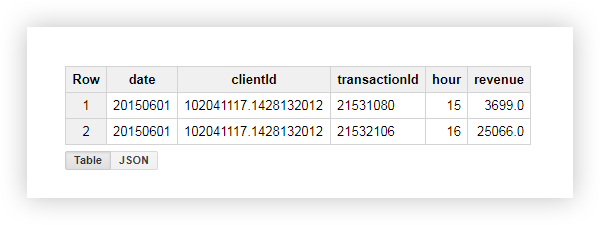
通过应用查询,我们收到了一个报告,其中包含该用户的平均,最小,最大和总收入以及交易次数。如您在下面的屏幕快照中所见,该用户在工作时间内完成了这两项交易:

示例2。现在让任务复杂一些:
- 让我们根据执行时间在窗口中放下所有事务的序列号。回想一下,我们根据用户和工作时间/非工作时间定义了窗口。
- 让我们在窗口中显示下一个/上一个交易(相对于当前交易)的收入。
- 让我们在窗口中显示第一个和最后一个交易的收入。
为此,我们使用以下查询:
#legasy SQL
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
#standard SQL
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
让我们使用一个我们已经熟悉的用户示例(clientId ='102041117.1428132012')检查计算结果:

从上面的屏幕截图中,我们看到:
- 第一次交易是在15:00,第二次交易是在16:00。
- 在15:00进行当前交易之后,在16:00进行了一笔交易,其收入为25066(column lead_revenue)。
- 在当前交易时间4:00 pm之前,在3:00 pm有一笔交易,收入为3699(lag_revenue列)。
- 窗口中的第一笔交易是15:00的交易,其收入为3699(列first_revenue_by_hour)。
- 请求逐行处理数据,因此,对于有问题的交易,它将是窗口中的最后一个,并且last_revenue_by_hour和Revenue列中的值将相同。
结论
在本文中,我们从“聚集”函数,“日期”函数,“字符串”函数,“窗口”函数一节中介绍了最受欢迎的函数。但是,Google BigQuery具有更多有用的功能,例如:
- 转换功能-允许您将数据转换为特定格式。
- 表通配符功能-允许您从数据集中访问多个表。
- 正则表达式函数-允许您描述搜索查询的模型,而不是其确切值。
如果有必要在注释中写出相同的细节,请写在注释中。