但是数据科学家的工作与数据相关,最重要和最耗时的时刻之一就是在将数据提交给神经网络或以某种方式进行分析之前对其进行处理。
在本文中,我们的团队将介绍如何通过分步说明和代码快速轻松地处理数据。我们试图使代码足够灵活以应用于不同的数据集。
许多专业人士可能不会在本文中找到任何与众不同的东西,但是初学者将能够学习新的东西,并且长期以来梦想制作一个单独的笔记本以进行快速,结构化的数据处理的任何人都可以自行复制代码并对其进行格式化,或者下载一个现成的笔记本。来自Github的笔记本。
我们得到了数据集。接下来做什么?
因此,标准:您需要了解我们正在处理的全局。为此,我们将使用pandas来简单地定义不同的数据类型。
import pandas as pd # pandas
import numpy as np # numpy
df = pd.read_csv("AB_NYC_2019.csv") # df
df.head(3) # 3 , , 
df.info() # 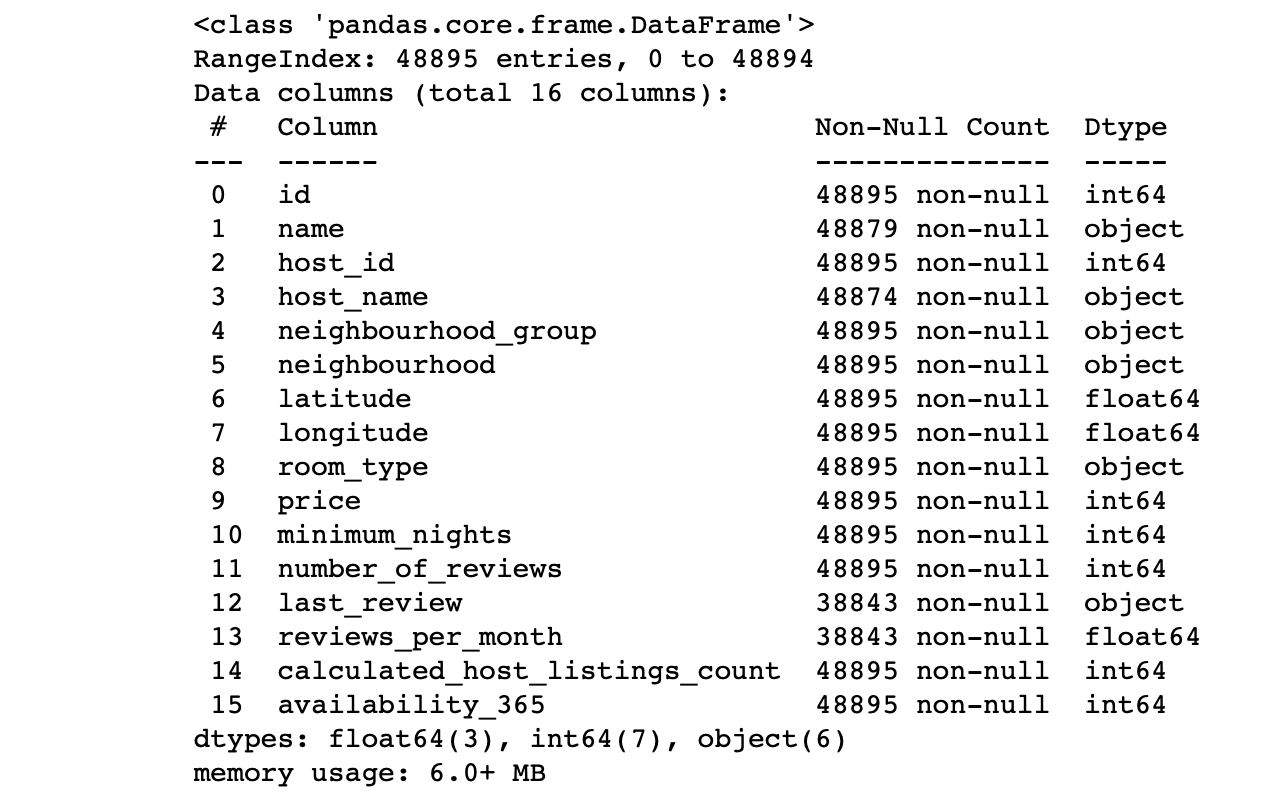
我们看一下这些列的值:
- 每列中的行数是否与总行数相对应?
- 每列中数据的本质是什么?
- 我们希望目标针对哪个列进行预测?
这些问题的答案将使您能够分析数据集并大致规划下一步的计划。
我们还可以使用pandas describe()来更深入地查看每列中的值。但是,此函数的缺点是它不提供有关具有字符串值的列的信息。我们稍后会处理。
df.describe()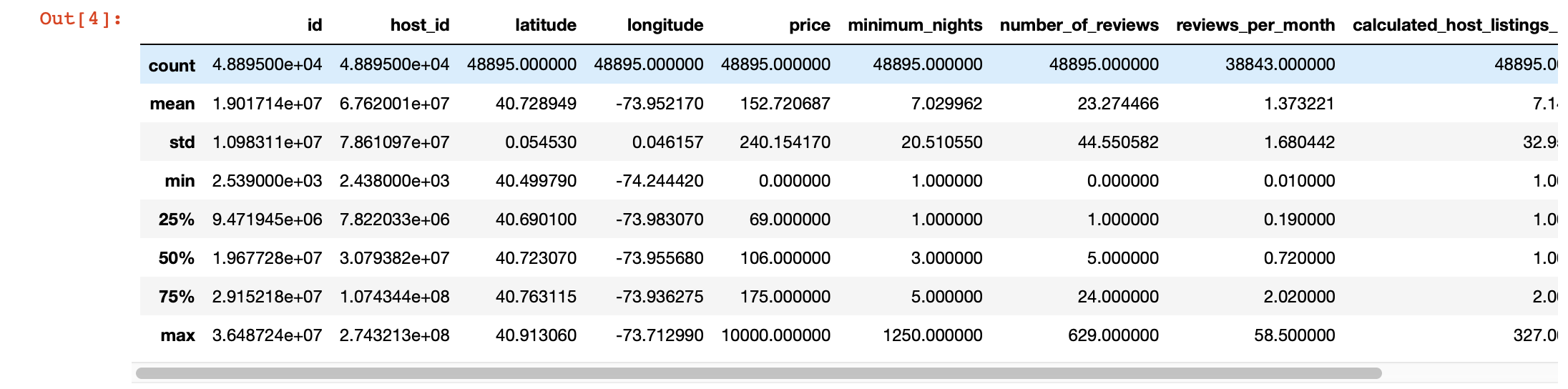
魔术可视化
让我们看一下我们根本没有价值的地方:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis')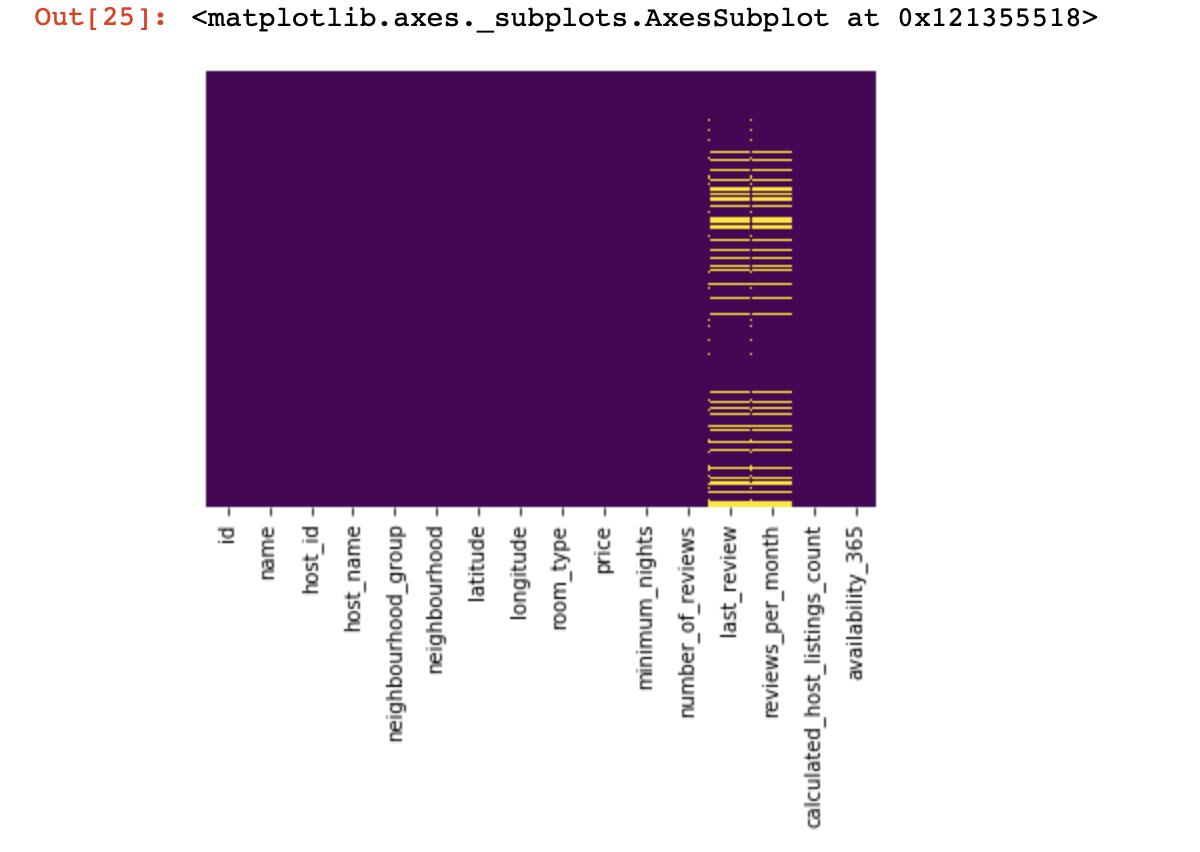
从上面看只是一眼,现在我们将开始更多有趣的事情,让我们
尝试查找并删除所有行中只有一个值的列(如果可能的话,它们不会以任何方式影响结果):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] # , , 现在,我们从重复的行(包含与现有行之一相同的顺序包含相同信息的行)中保护自己和项目的成功:
df.drop_duplicates(inplace=True) # , .
# .我们将数据集分为两部分:一个具有定性值,另一个具有定量值
在这里,我们需要做一点澄清:如果定性和定量数据中缺少数据的行彼此之间没有很强的相关性,则有必要决定我们要牺牲什么-所有丢失数据的行,仅其中一部分或某些列。如果这两行是相关的,那么我们有权将数据集一分为二。否则,您首先需要处理与定性和定量项都不相关的缺失数据行,然后才将数据集分为两部分。
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])我们这样做是为了使我们更容易处理这两种不同类型的数据-稍后我们将了解它在很大程度上简化了我们的生活。
我们使用定量数据
我们应该做的第一件事是确定定量数据中是否有“间谍栏”。之所以将这些列称为“原因”,是因为它们假装为定量数据,而它们本身又是定性数据。
我们如何定义它们?当然,这完全取决于您要分析的数据的性质,但是通常此类列可能只有很少的唯一数据(在3-10个唯一值的范围内)。
print(df_numerical.nunique())定义间谍列之后,我们将其从定量数据移至定性数据:
spy_columns = df_numerical[['1', '2', '3']]# - dataframe
df_numerical.drop(labels=['1', '2', '3'], axis=1, inplace = True)#
df_categorical.insert(1, '1', spy_columns['1']) # -
df_categorical.insert(1, '2', spy_columns['2']) # -
df_categorical.insert(1, '3', spy_columns['3']) # - 最后,我们将定量数据与定性数据完全分开,现在您可以正确使用它们了。首先是了解我们在哪里有空值(NaN,在某些情况下将0视为空值)。
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())在此阶段,重要的是要理解零在哪几列中可能表示缺失值:这与数据的收集方式有关吗?还是可能与数据值有关?这些问题需要根据具体情况回答。
因此,如果我们仍然决定不包含零的数据,则应使用NaN替换零,以便以后处理丢失的数据会更容易:
df_numerical[[" 1", " 2"]] = df_numerical[[" 1", " 2"]].replace(0, nan)现在让我们看看缺少数据的地方:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # df_numerical.info()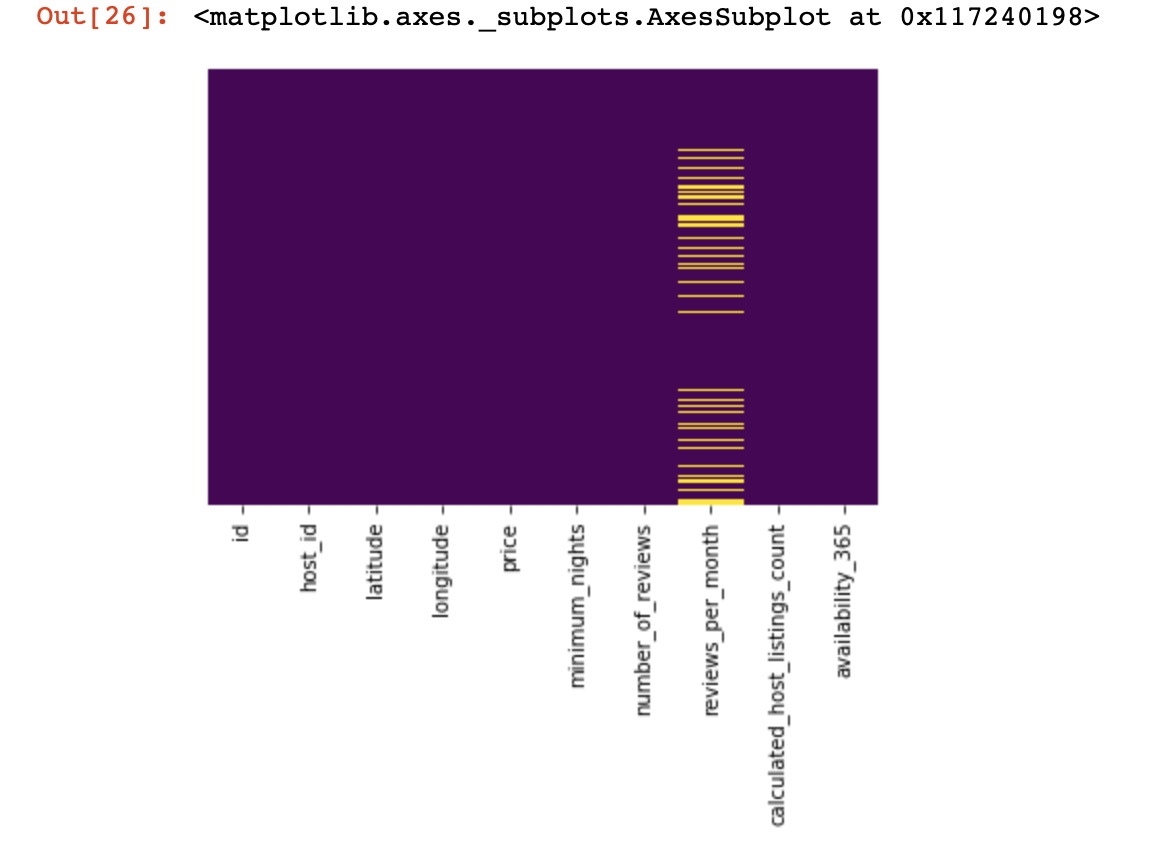
在这里,缺少的列内的那些值应标记为黄色。有趣的是,现在就开始-如何使用这些值来表现?删除具有这些值或列的行吗?还是用其他填充这些空值?
这是一个粗略的图表,可以帮助您确定使用空值基本上可以做什么:
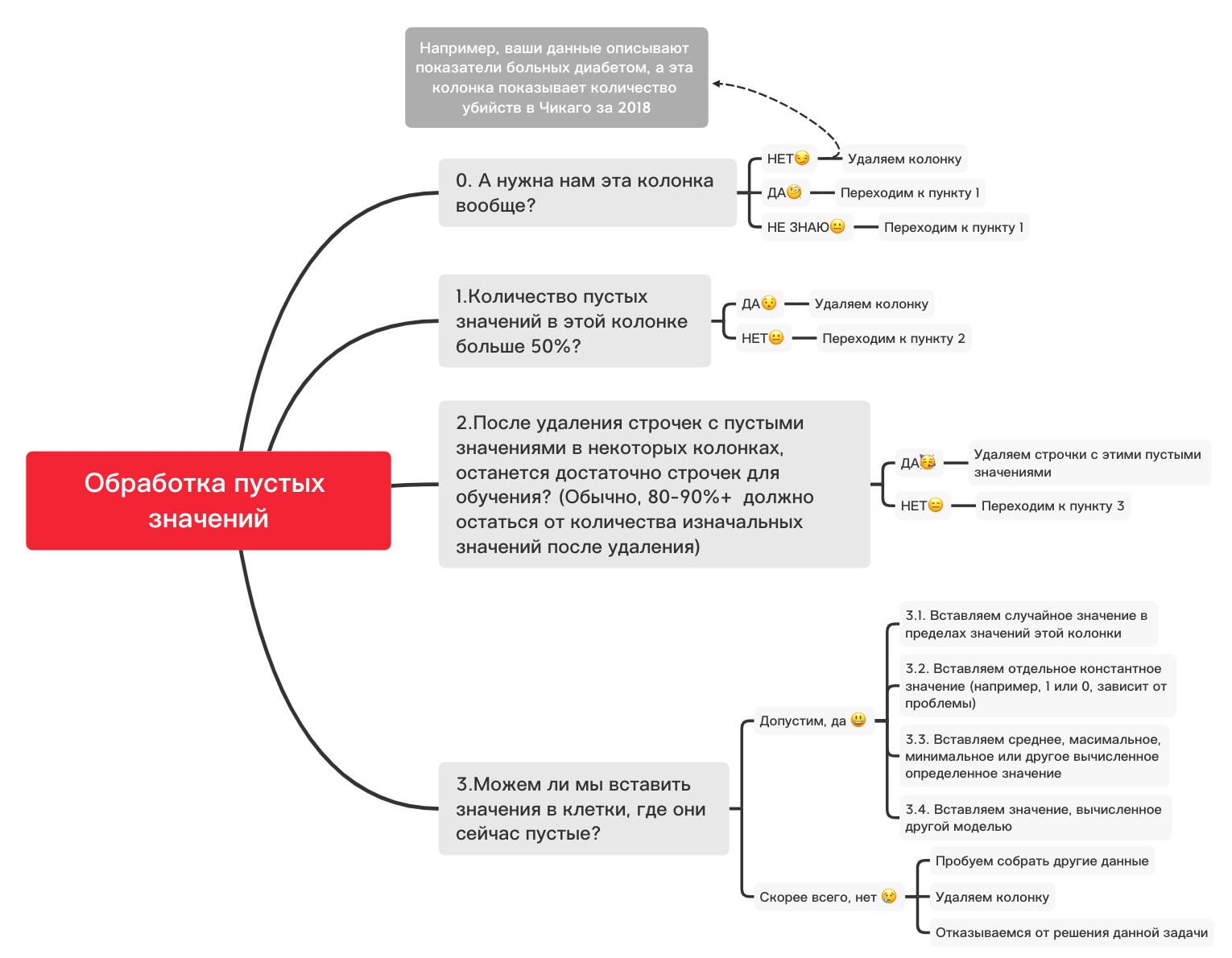
0。删除不必要的列
df_numerical.drop(labels=["1","2"], axis=1, inplace=True)1.此栏中是否有超过50%的空白值?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["1","2"], axis=1, inplace=True)#, - 50 2.删除空值的行
df_numerical.dropna(inplace=True)# , 3.1。插入随机值
import random # random
df_numerical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True) # 3.2。插入常数值
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='constant', fill_value="< >") # SimpleImputer
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.3。插入平均值或最频繁的值
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) # mean most_frequent
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.4。插入由另一个模型计算出的值
有时可以使用sklearn库或其他类似库中的模型使用回归模型来计算值。我们的团队将专门撰写一篇文章,介绍如何在不久的将来完成此工作。
因此,尽管关于定量数据的叙述会被打断,但由于关于如何针对不同任务进行数据准备和预处理还有许多其他细微差别,因此本文已经考虑了定量数据的基本知识,现在是时候返回定性数据了。我们从定量分析中退了几步。您可以根据需要更改此笔记本,针对不同的任务进行调整,以便数据预处理非常快!
定性数据
基本上,对于高质量数据,使用一热编码方法以便将其从字符串(或对象)格式化为数字。在继续这一点之前,让我们使用上面的图和代码来处理空值。
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis')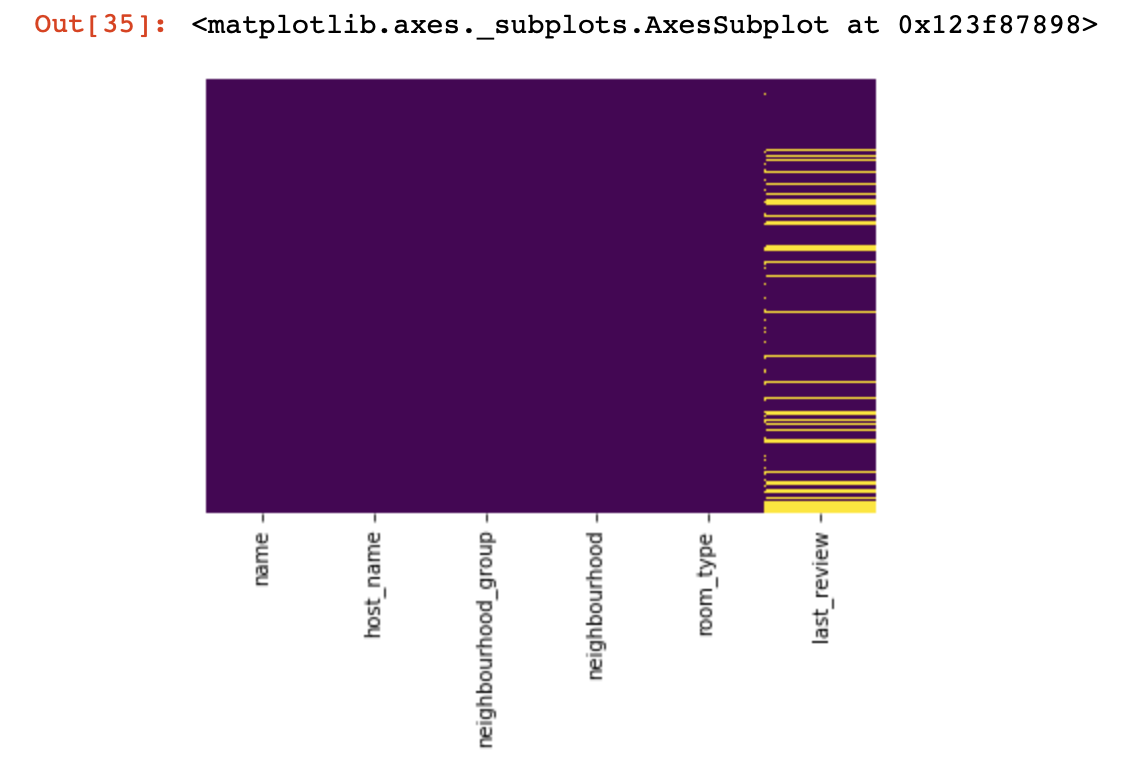
0.删除不必要的列
df_categorical.drop(labels=["1","2"], axis=1, inplace=True)1.此栏中是否有超过50%的空白值?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["1","2"], axis=1, inplace=True) #, -
# 50% 2.删除空值的行
df_categorical.dropna(inplace=True)# ,
# 3.1。插入随机值
import random
df_categorical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True)3.2。插入常数值
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="< >")
df_categorical[["_1",'_2','_3']] = imputer.fit_transform(df_categorical[['1', '2', '3']])
df_categorical.drop(labels = ["1","2","3"], axis = 1, inplace = True)因此,最后,我们处理了质量数据中的空值。现在是时候对数据库中的值进行一次热编码了。这种方法非常常用,因此您的算法可以训练出良好的数据。
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["1","2","3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))因此,最后我们完成了定性和定量数据的单独处理-是时候将它们组合起来了
new_df = pd.concat([df_numerical,df_categorical], axis=1)将数据集合并为一个后,最后可以使用sklearn库中的MinMaxScaler进行数据转换。这将使我们的值范围从0到1,这将在将来训练模型时有所帮助。
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)现在,这些数据已准备就绪,可用于神经网络,标准ML算法等等!
在本文中,我们没有考虑与时间序列相关的数据的工作,因为对于此类数据,应根据您的任务使用略有不同的处理技术。将来,我们的团队将在该主题上撰写单独的文章,并希望它能够为您的生活带来有趣,新颖和有用的东西,例如本文。