
为什么油工需要NLP?您如何使用计算机来理解专业术语?是否可以向机器解释什么是“压力”,“油门响应”,“环形”?新员工和语音助手之间如何连接?我们将在有关将数字助理引入支持石油生产的软件中的文章中尝试回答这些问题,该软件有助于地质开发人员的日常工作。
我们研究所正在为石油行业开发我们自己的软件(https://rn.digital/),为了使用户喜欢它,您不仅需要在其中实现有用的功能,还需要始终考虑界面的便利性。当今UI / UX的趋势之一是向语音界面的过渡。毕竟,无论怎么说,一个人最自然,最方便的互动形式就是言语。因此,决定在我们的软件产品中开发和实施语音助手。
除了改进UI / UX组件之外,助手的引入还使您可以减少新员工使用软件的“门槛”。我们程序的功能广泛,可能需要一天以上的时间才能解决。“询问”助理以执行所需命令的能力将减少花在解决任务上的时间,并减少新工作的压力。
由于公司安全服务对于将数据传输到外部服务非常敏感,因此我们考虑基于开放源代码解决方案开发一个助手,该助手可让我们在本地处理信息。
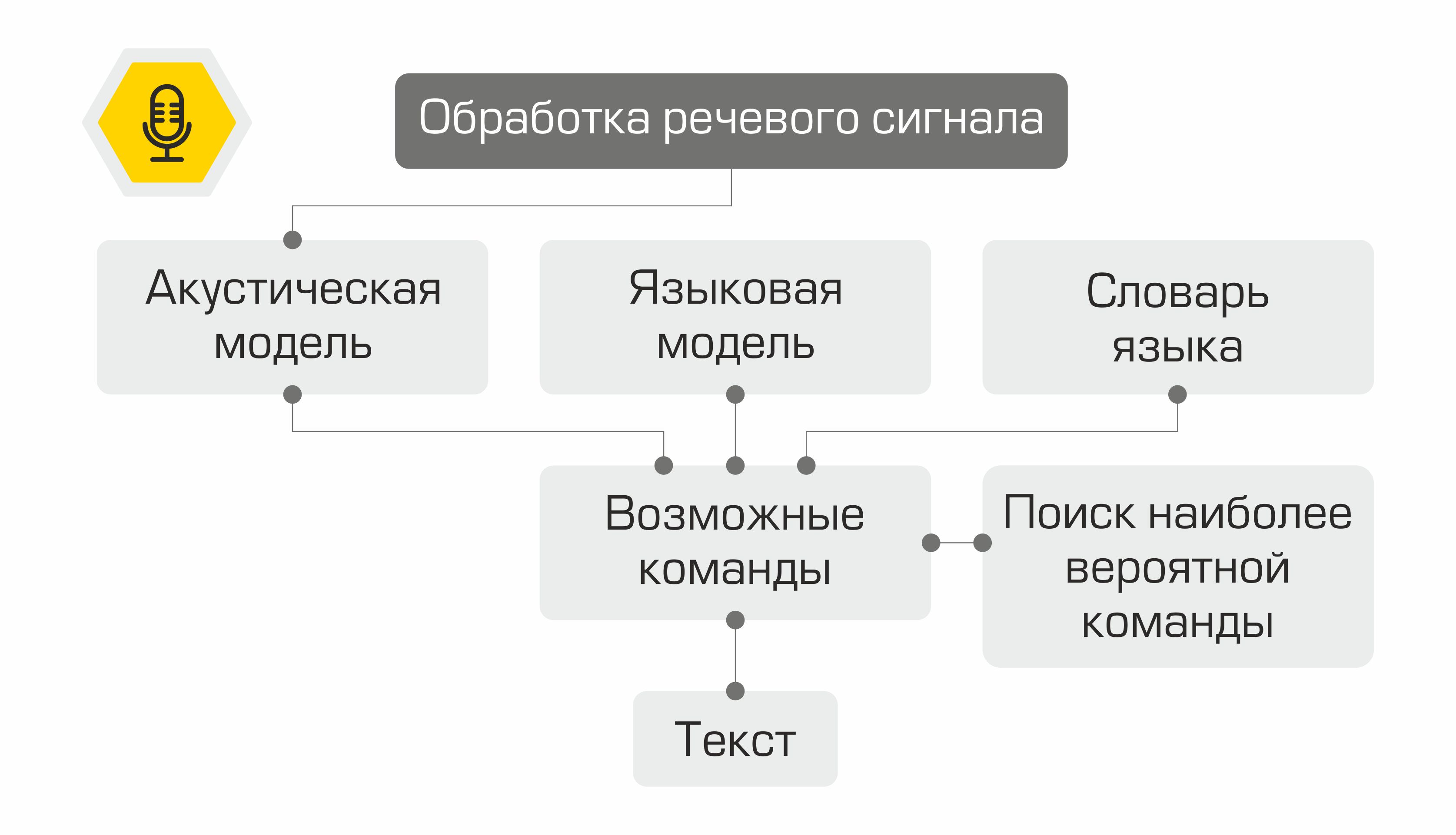
从结构上讲,我们的助手包括以下模块:
- 语音识别(ASR)
- 语义对象的分配(自然语言理解,NLU)
- 命令执行
- 语音合成(文字转语音,TTS)
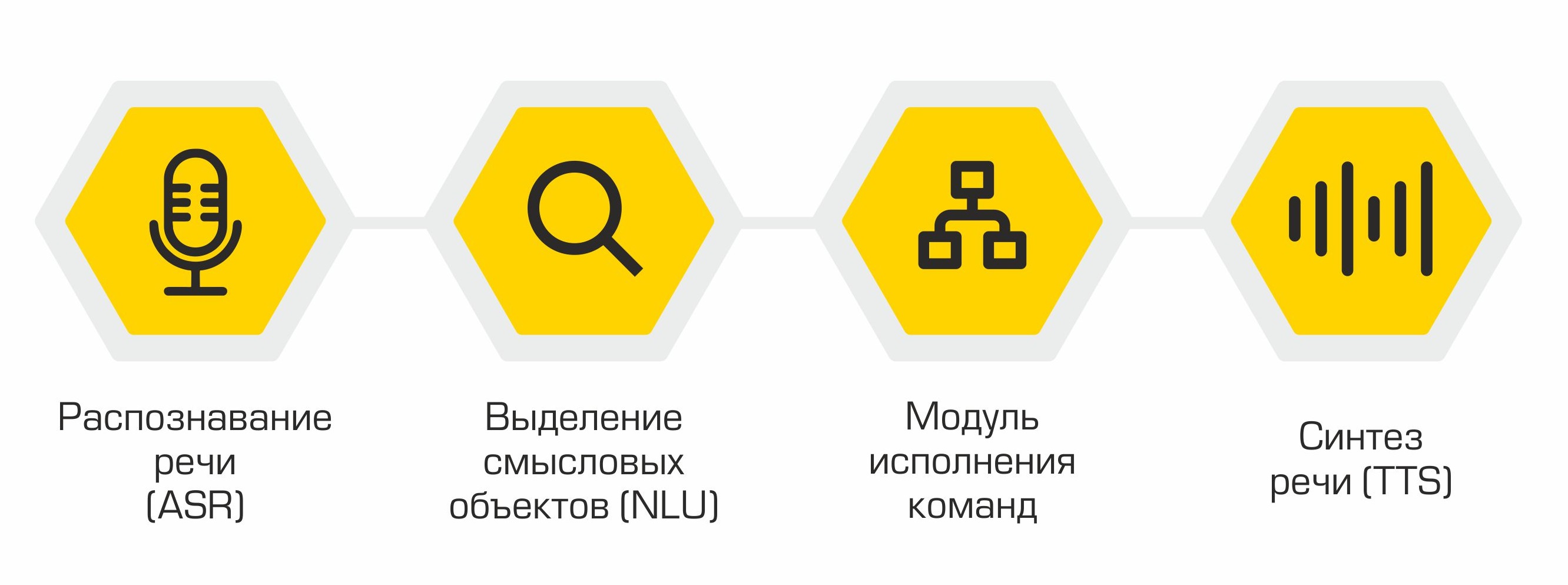
助手的原理:从文字(用户)到动作(在软件中)!
每个模块的输出用作系统中下一个组件的入口点。因此,用户的语音将转换为文本,然后发送到机器学习算法进行处理,以确定用户的意图。根据此意图,在命令执行模块中激活所需的类,从而满足用户的要求。操作完成后,命令执行模块将有关命令执行状态的信息发送到语音合成模块,语音合成模块再通知用户。
每个帮助程序模块都是一个微服务。因此,如果需要的话,用户可以完全不用语音技术,而可以通过聊天机器人的形式直接转向助手的“大脑”-突出显示语义对象的模块。
语音识别
语音识别的第一阶段是语音信号处理和特征提取。音频信号的最简单表示是波形图。它反映了任何给定时间的能量。但是,此信息不足以确定口头声音。对我们来说重要的是要知道不同频率范围内包含多少能量。为此,使用傅立叶变换,从示波图过渡到频谱。
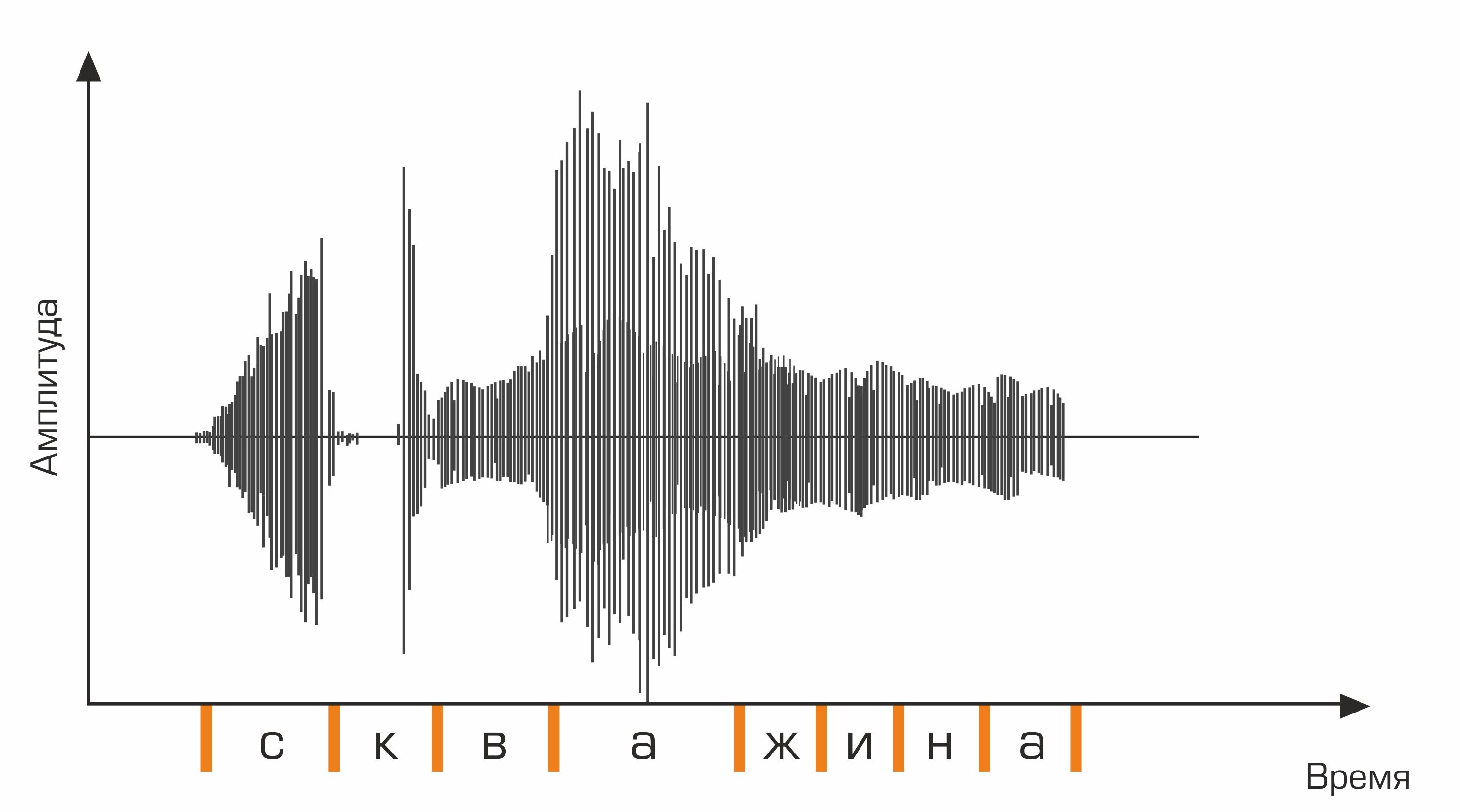
这是一个示波器图。
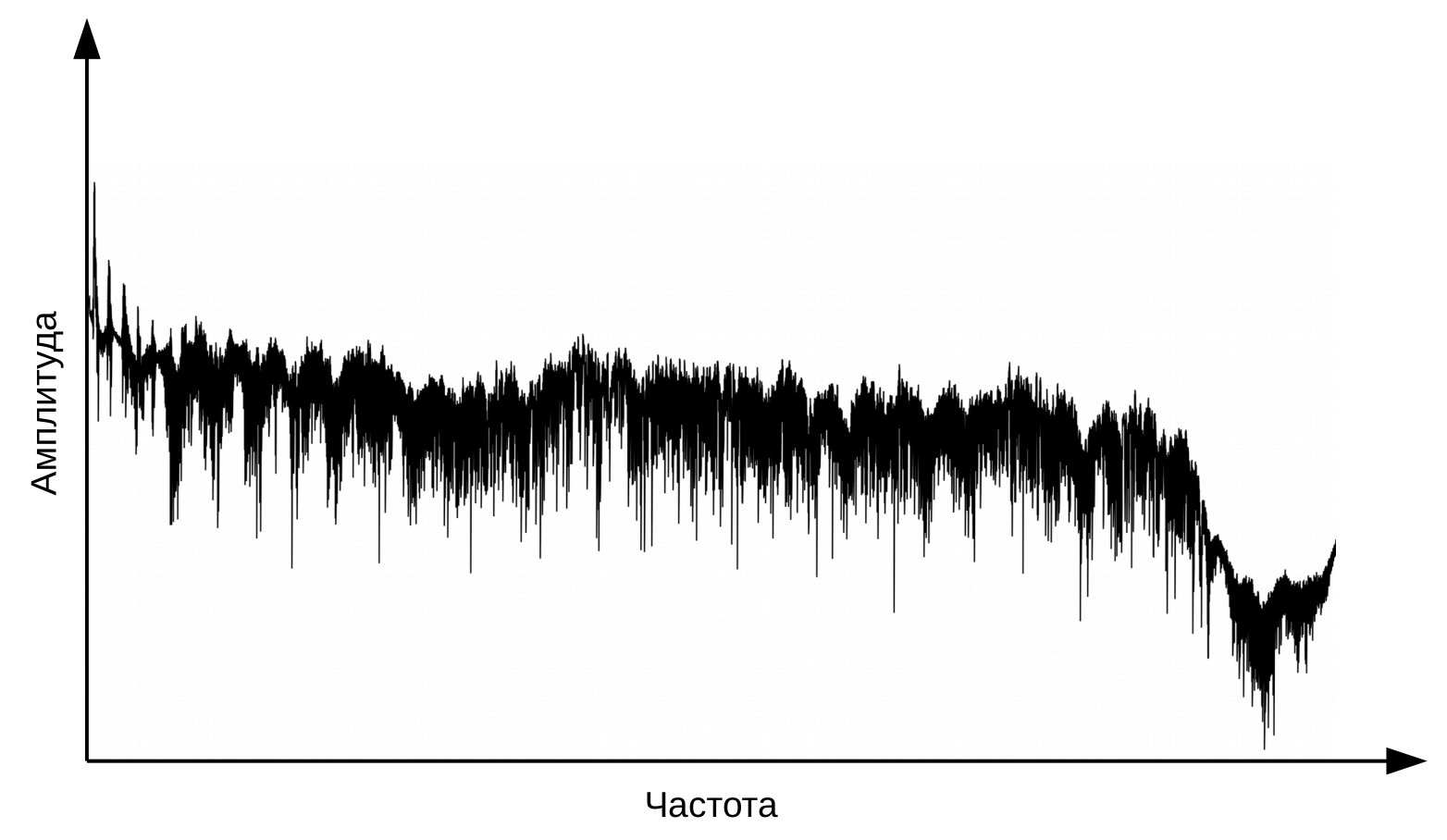
这是每个时刻的频谱。
在这里有必要澄清一下,当振动的气流通过喉(源)和声道(过滤器)时会形成语音。对于音素的分类,我们仅需要有关过滤器配置的信息,即有关嘴唇和舌头的位置的信息。此信息可以通过使用频谱对数的傅立叶逆变换从频谱到倒频谱(倒频谱-单词频谱的字谜)的过渡来区分。同样,x轴不是频率,而是时间。术语“频率”用于区分倒谱的时域和原始音频信号(Oppenheim,Schafer。Digital Signal Processing,2018)。
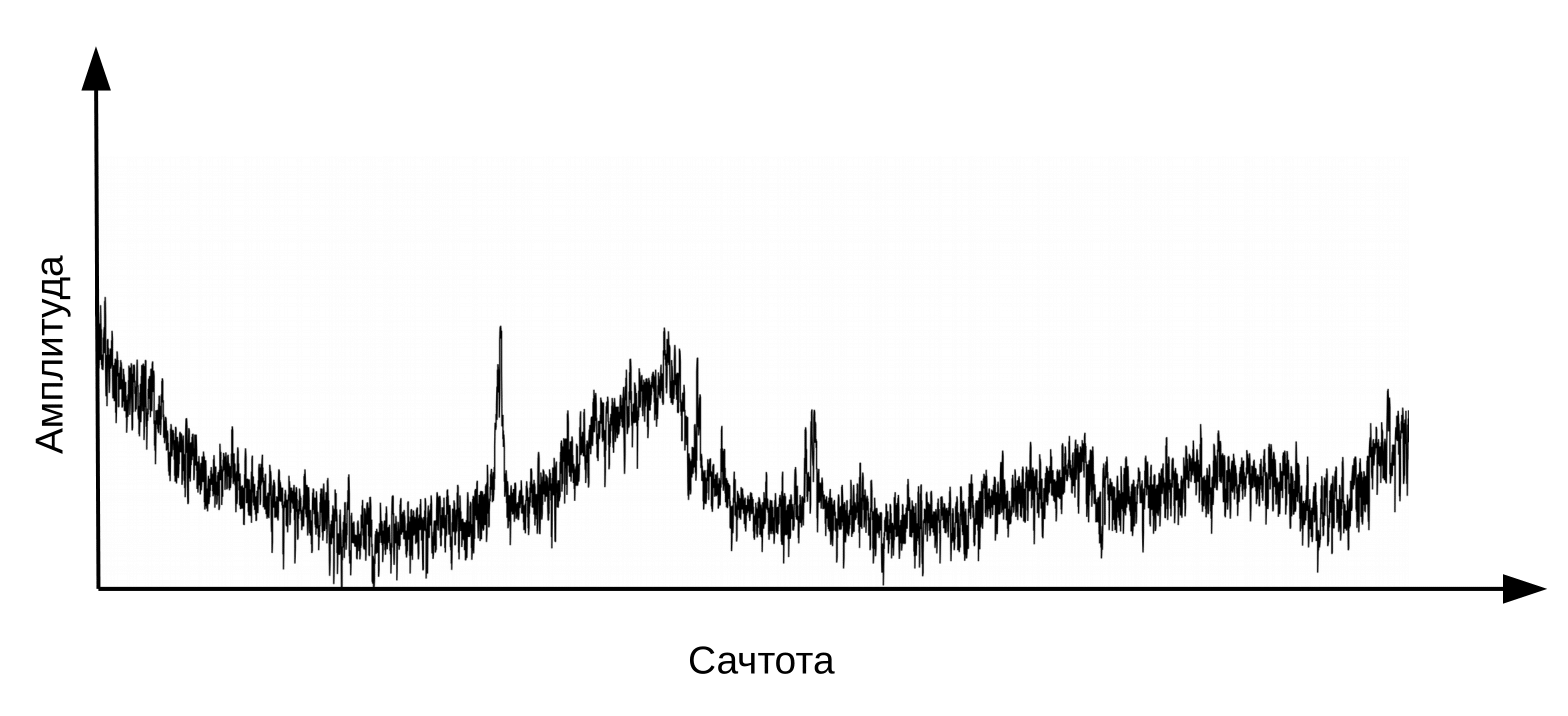
倒频谱,或简称为“频谱对数的频谱”。是的,常见的是一个术语,而不是一个错字
有关声道位置的信息可在前12个倒谱系数中找到。这12个倒频谱系数补充有描述音频信号变化的动态特征(增量和增量-增量)。 (Jurafsky,Martin。语音和语言处理,2008年)。所得的值向量称为MFCC向量(梅尔频率倒谱系数),是语音识别中最常用的声学特征。
标志接下来会发生什么?它们用作声学模型的输入。它显示了哪个语言单元最有可能“产生”这样的MFCC向量。在不同的系统中,这样的语言单元可以是音素,音素甚至单词的一部分。因此,声学模型将MFCC向量序列转换为最可能的音素序列。
此外,对于音素序列,必须选择适当的单词序列。这就是语言词典的作用所在,其中包含系统识别的所有单词的转录。编译此类词典是一个费力的过程,需要特定语言的语音和语音学方面的专业知识。转录字典中的一行示例:
skv aa zh yn ay
在下一步中,语言模型将确定该句子在该语言中的先验概率。换句话说,该模型可以估算出这样的句子在某种语言中出现的可能性。良好的语言模型将确定短语“绘制石油价格”比句子“绘制九种石油价格”更有可能。
声学模型,语言模型和发音词典的组合创建了一个假设的“网格”-所有可能的单词序列,使用动态编程算法可以从中找到最可能的单词序列。它的系统会将其作为公认的文本提供。
语音识别系统操作的示意图
重新发明 轮子并从头开始编写语音识别库是不切实际的,因此我们的选择落在了kaldi框架上。该库的优势无疑是其灵活性,允许在必要时创建和修改系统的所有组件。另外,Apache License 2.0允许您在商业开发中自由使用该库。
自由分布的音频数据集VoxForge被用作训练声学模型的数据。要将音素序列转换为单词,我们使用了CMU Sphinx库提供的俄语词典。由于该词典不包含特定于石油行业的术语的发音,因此使用该实用程序g2p-seq2seq训练了音素到音素模型,以快速创建新单词的转录。语言模型在VoxForge的音频转录本和我们创建的数据集上都经过了训练,该数据集包含石油和天然气行业的术语,字段名称和采矿公司。
语义对象的选择
因此,我们识别出用户的语音,但这只是一行文字。您如何告诉计算机该怎么办?最早的语音控制系统使用严格受限的命令集。识别出这些短语之一后,就可以调用相应的操作了。从那时起,自然语言处理和理解技术(分别为NLP和NLU)得到了飞跃发展。如今,经过大量数据训练的模型已经能够很好地理解语句的含义。
要从已识别短语的文本中提取含义,必须解决两个机器学习问题:
- 用户团队分类(意图分类)。
- 命名实体的分配(命名实体识别)。
在开发模型时,我们使用了基于Apache License 2.0分发的开源Rasa库。
为了解决第一个问题,有必要将文本表示为可以由机器处理的数值向量。对于此类转换,使用了StarSpace神经模型,该模型允许将请求文本和请求类“嵌套”到一个公共空间中。

StarSpace神经模型
在训练过程中,神经网络学习比较实体,以最小化请求向量和正确类别的向量之间的距离,并最大化与不同类别向量的距离。在测试期间,为查询x选择类y,以便:
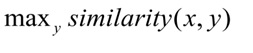
余弦距离用作矢量相似度的度量:
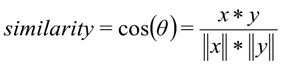
其中
x是用户的请求,y是请求类别。
标记了3000个查询以训练用户意图分类器。我们总共从8个班级毕业。我们使用目标变量分层方法将样本按70/30的比例分为训练样本和测试样本。分层使我们能够保留培训和测试中班级的原始分布。训练模型的质量同时通过几个标准进行了评估:
- 召回率-此类中所有请求正确分类的请求的比例。
- 正确分类的请求的份额(准确性)。
- 精度-正确分类的请求相对于系统归于此类的所有请求的比例。
- F1 – .
另外,系统误差矩阵用于评估分类模型的质量。 y轴是语句的真实类,x轴是算法预测的类。
在对照样本上,模型显示以下结果:
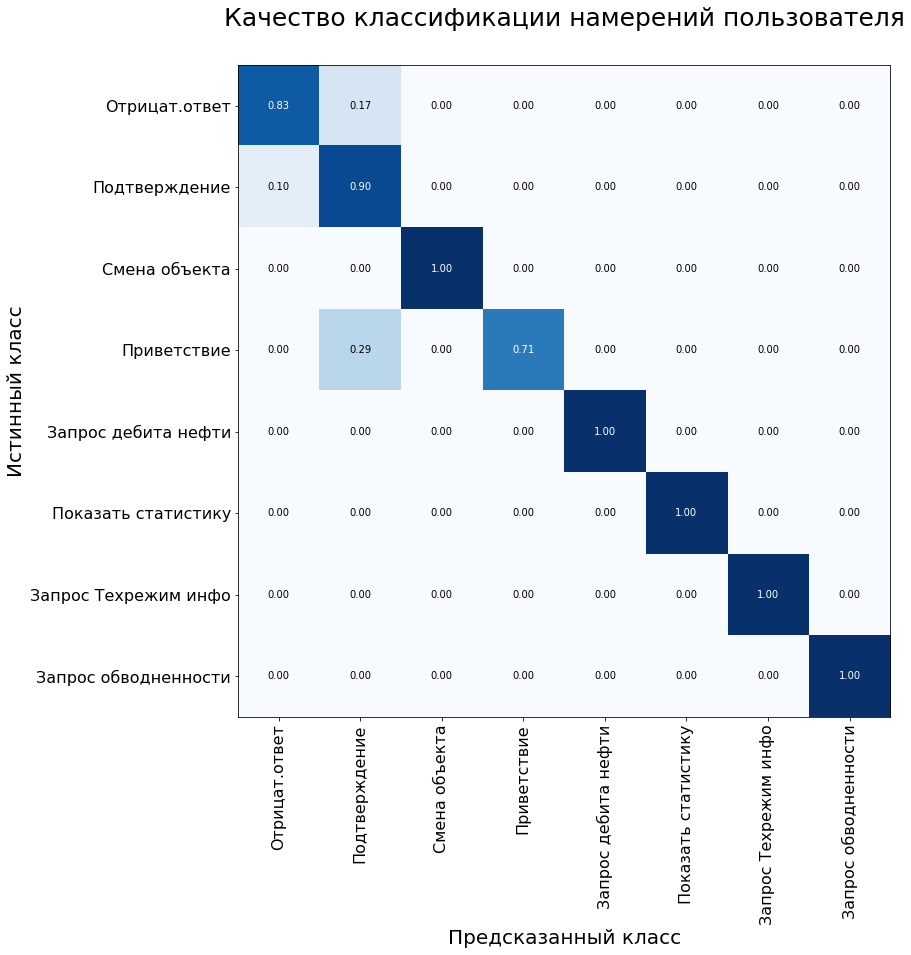
测试数据集上的模型度量:准确性-92%,F1-90%。
第二项任务-选择命名实体-是识别表示特定对象或现象的单词和短语。此类实体可以是,例如,矿床或采矿公司的名称。
为了解决这个问题,使用了条件随机场算法,它是一种马尔可夫场。 CRF是一个判别模型,即它对条件概率P进行建模(Y | X)来自观察X(单词)的潜在状态Y(单词类别)。 为了满足用户的要求,我们的助理需要突出三种命名实体:字段名称,井名称和开发对象名称。为了训练模型,我们准备了一个数据集并进行了注释:样本中的每个单词都被分配了一个相应的类。训练集中有关命名实体识别问题的示例。

但是,事实证明并非如此简单。专业术语在现场开发人员和地质学家中非常普遍。人们不难理解“注入器”是一口注入井,“ Samotlor”很可能表示萨莫特尔油田。对于在有限数量的数据上训练的模型,仍然很难绘制出这样的平行线。为了解决此限制,Rasa库的这一出色功能有助于创建同义词字典。
##同义词:Samotlor
-Samotlor
-Samotlor-
俄罗斯最大的油田
添加同义词也使我们可以稍微扩展样本。整个数据集的数量为2000个请求,我们按70/30的比例将其分为训练和测试。使用F1指标评估模型的质量,在对照样品上进行测试时,模型的质量为98%。
命令执行
根据上一步中定义的用户请求类,系统会激活软件内核中的相应类。每个类至少具有两种方法:直接执行请求的方法和为用户生成响应的方法。
例如,将命令分配给“ request_production_schedule”类时,将创建RequestOilChart类的对象,该对象从数据库中卸载有关石油生产的信息。专用的命名实体(例如,井和字段名称)用于填充查询中的插槽以访问数据库或软件内核。助手在准备好的模板的帮助下进行回答,模板中的空间填充了上传数据的值。

辅助原型工作的示例。
语音合成

串联语音合成的工作方式
在屏幕上显示前一阶段生成的用户通知文本,也用作口头语音合成模块的输入。使用RHVoice库进行语音生成... GNU LGPL v2.1许可证允许该框架用作商业软件的组件。语音合成系统的主要组件是语言处理器,用于处理输入文本。文本被规范化:数字被简化为书面形式,缩写被解码,等等。然后,使用发音词典为文本创建转录,然后将其传输到声学处理器的输入。该组件负责从语音数据库中选择声音元素,连接所选元素并处理声音信号。
全部放在一起
因此,语音助手的所有组件均已准备就绪。剩下的只是按照正确的顺序“收集”并测试它们。如前所述,每个模块都是微服务。 RabbitMQ框架用作连接所有模块的总线。该图通过一个典型的用户请求示例清楚地说明了助手的内部工作:
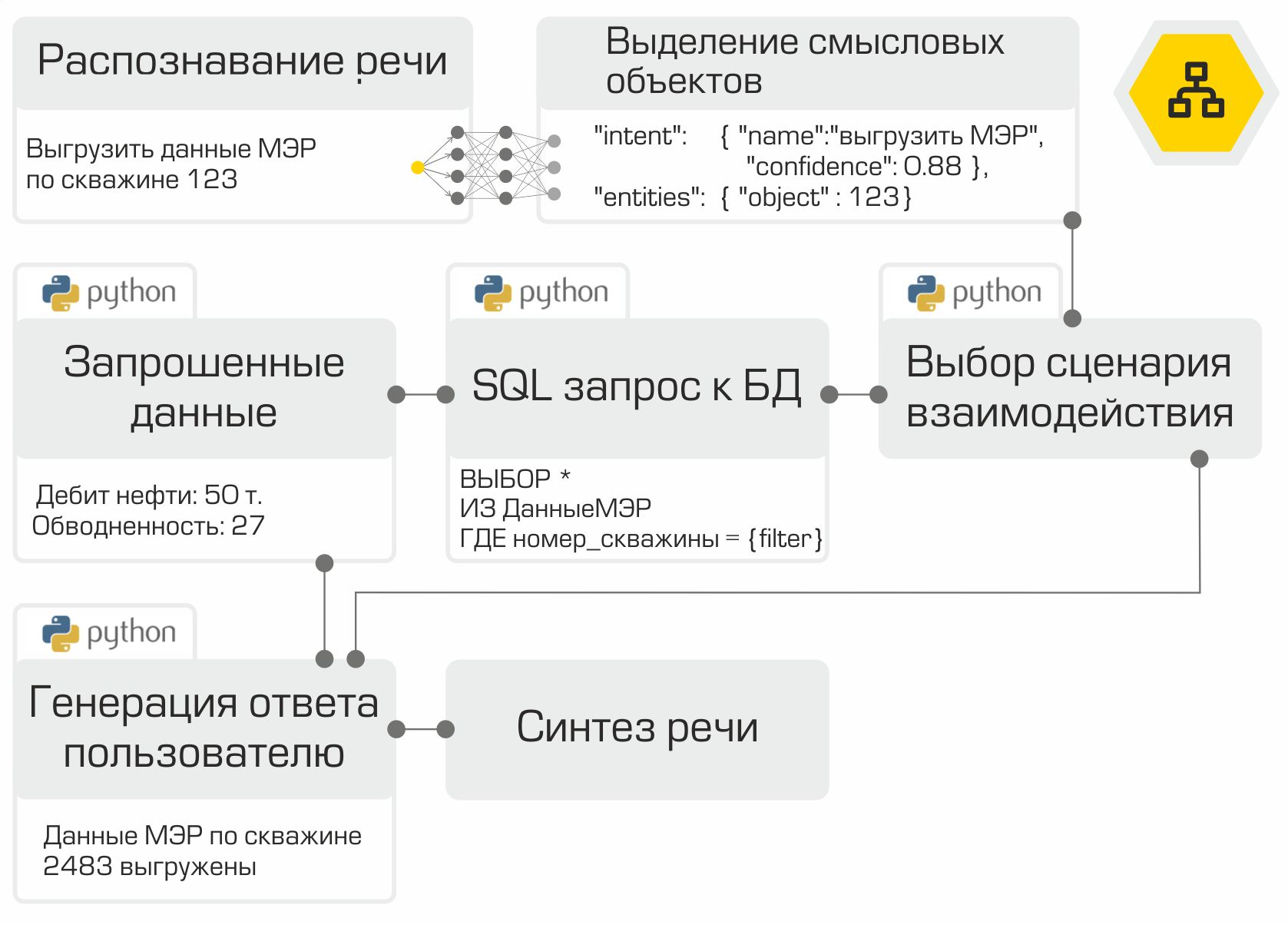
创建的解决方案允许将整个基础结构放置在公司的网络中。本地信息处理是该系统的主要优势。但是,您必须为自主权付费,因为您必须自己收集数据,训练和测试模型,而不能使用数字助理市场中顶级供应商的力量。
目前,我们正在将助手集成到正在开发的产品之一中。
仅用一个短语搜索您的油井或您最喜欢的灌木丛将多么方便!
在下一阶段,计划收集和分析来自用户的反馈。还计划扩展助手识别和执行的命令。
本文中描述的项目远非我们公司使用机器学习方法的唯一示例。因此,例如,数据分析用于自动选择地质和技术措施的候选井,其目的是刺激石油生产。在即将发表的文章中,我们将告诉您如何解决这个很酷的问题。订阅我们的博客不要错过!