在本文中,您将学习
- 什么是CNN及其运作方式
- 什么是功能图
- 什么是最大池
- 各种深度学习任务的损失函数
小介绍
本系列文章旨在直观地了解深度学习的工作原理,任务是什么,网络体系结构,为什么一个比另一个更好。本着“如何实施”的精神,几乎没有什么特别的事情。进入每个细节都会使材料对于大多数观众来说过于复杂。关于计算图的工作方式或通过卷积层的反向传播的工作方式已经编写。而且,最重要的是,它的编写比我要解释的要好得多。
在上一篇文章中,我们讨论了FCNN-它是什么以及问题是什么。这些问题的解决方案在于卷积神经网络的体系结构。
卷积神经网络(CNN)
卷积神经网络。看起来像这样(vgg-16架构):
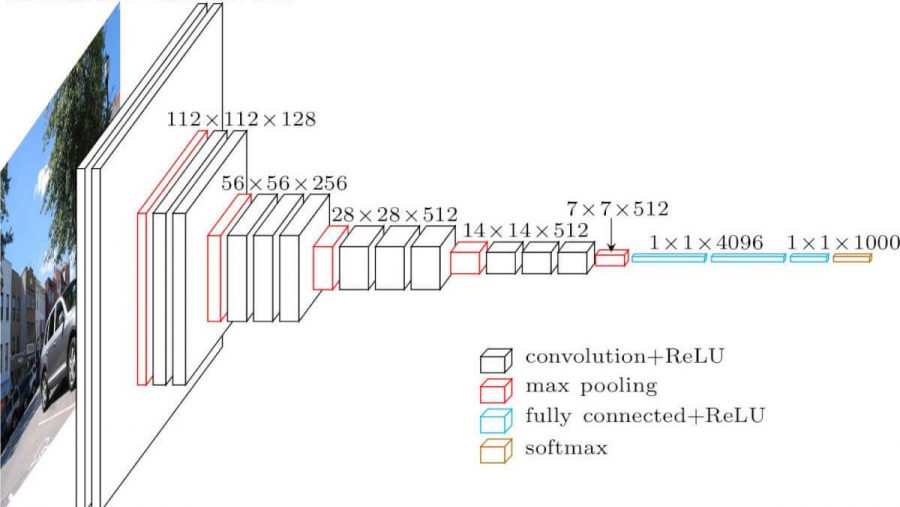
与全网状网络有什么区别?现在,隐藏层具有卷积操作。
这就是卷积的样子:

我们只需要拍摄一张图像(目前为单通道),然后使用由训练参数组成的卷积内核(矩阵),在图像上``叠加''一个内核(通常为3x3),并对击中内核的图像的所有像素值进行逐元素乘法。然后总结所有这些(您还需要添加bias参数-偏移量),我们得到一些数字。此数字是输出层的元素。我们通过一些步骤(跨步)将这个核心移到我们的图像上,并获得下一个元素。由这些元素构成一个新的矩阵,然后将下一个卷积内核应用于它(在将激活函数应用于它之后)。在输入图像是三通道的情况下,卷积核也是三通道-过滤器。
但是这里的一切并不是那么简单。卷积后得到的矩阵称为特征图,因为它们存储了先前矩阵的某些特征,但形式不同。实际上,一次使用多个卷积滤波器。这样做是为了将尽可能多的特征“带”到下一个卷积层。在卷积的每一层中,输入图像中的特征以越来越多的抽象形式呈现。
还有一些注意事项:
- 折叠后,我们的特征图会变小(在宽度和高度上)。有时,为了减小较弱的宽度和高度,或者根本不减小宽度(相同的卷积),使用了零填充方法-在输入要素图的“沿轮廓”处填充零。
- 在最近的卷积层之后,分类和回归任务使用几个完全连接的层。
为什么比FCNN更好
- 现在,我们可以在层之间使用更少的可训练参数
- 现在,当我们从图像中提取特征时,我们不仅要考虑单个像素,还要考虑其附近的像素(识别图像中的某些图案)
最大池
看起来像这样:
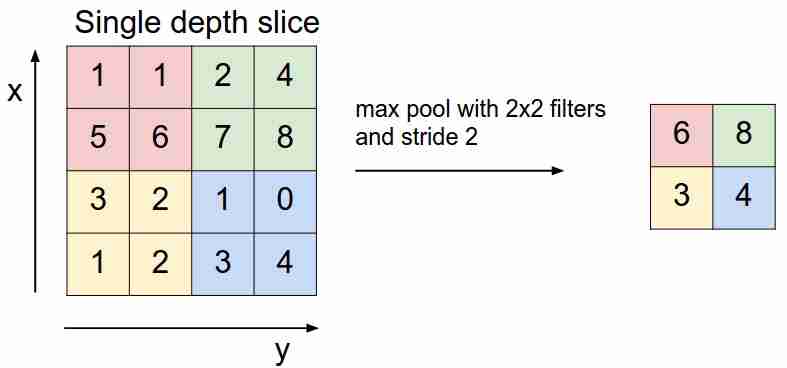
我们使用过滤器“滑动”特征图,并仅选择最重要的特征(就输入信号而言,作为某些值),从而减小了特征图的尺寸。当我们平均掉入过滤器的值时,还有平均池(加权池),但实际上最大池池更适用。
- 该层没有可训练的参数
损失函数
我们将网络X馈入输入,到达输出,计算损失函数的值,执行反向传播算法-这就是现代神经网络的学习方式(到目前为止,我们仅讨论监督学习)。
根据神经网络解决的任务,使用不同的损失函数:
- 回归问题。通常,他们使用均方误差(MSE)函数。
- 分类问题。它们主要使用交叉熵损失。
我们暂未考虑其他任务-将在以下文章中讨论。为什么要为此类任务提供确切的功能?在这里,您需要输入最大似然估计和数学。谁在乎-我在这里写过。
结论
我还想提请您注意神经网络体系结构中使用的两件事,包括卷积问题-辍学(您可以在此处阅读)和批处理规范化。我强烈建议阅读。
在下一篇文章中,我们将分析CNN架构,我们将理解为什么一个比另一个更好。