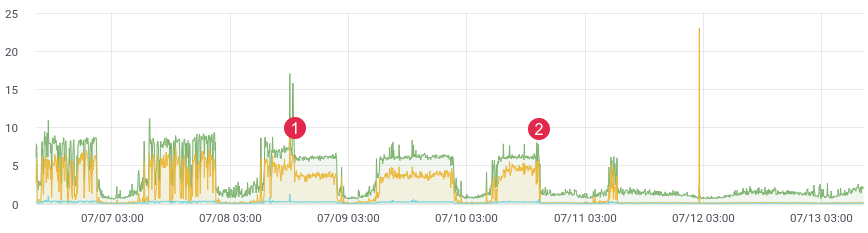
大约延迟/时间。
可能每个人都面临着在生产环境中分析代码的任务。 Facebook的xhprof做得很好。例如,您分析了1/1000个请求,然后看到了图片。每次发行后,该产品都会运行,并说“发行前更好,更快”。您没有历史数据,也无法证明任何事情。如果可以的话怎么办?
不久前,我们重写了代码中有问题的部分,并期望性能得到很大提高。我们编写了单元测试,进行了负载测试,但是代码在活动负载下将如何运行?毕竟,我们知道负载测试并不总是显示真实数据,并且在部署之后,您需要快速从代码中获取反馈。如果您收集数据,那么在发布后,您只需10到15分钟即可了解战斗环境中的情况。
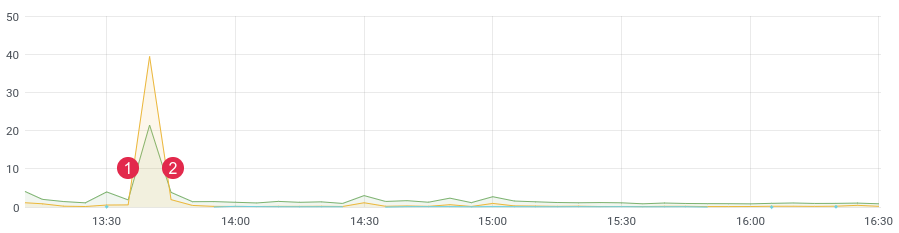
大约 延迟/时间。(1)部署,(2)回滚
叠放
对于我们的任务,我们采用了列式ClickHouse数据库(缩写为kx)。速度,线性可伸缩性,数据压缩和无死锁是选择此文件的主要原因。现在,它是该项目的主要基地之一。
在第一个版本中,我们将消息写到队列中,并且已经由消费者将消息写到ClickHouse中。延迟达到3-4个小时(是的,ClickHouse缓慢插入一个由一个记录)。时间过去了,有必要改变一些东西。如此延迟地响应警报毫无意义。然后,我们编写了Crown命令,该命令从队列中选择了所需数量的消息,并将一批消息发送到数据库,然后将其标记为在队列中已处理。头几个月,一切都很好,直到出现问题为止。事件太多,重复的数据开始出现在数据库中,队列未达到预期的目的(它们成为数据库),并且Crown命令停止处理ClickHouse中的记录。在此期间,该项目中又增加了几十个表,这些表必须以kx批量编写。处理速度下降。解决方案尽可能简单快捷。这促使我们用redis中的列表编写代码。想法是这样的:我们将消息写到列表的末尾,使用Crown命令,我们形成一个包装并将其发送到队列。然后,使用者解析队列并将一堆消息写入kx。
我们有:ClickHouse,Redis和一个队列(任何-Rabbitmq,kafka,beanstalkd ...)
Redis和列表
直到某个时候,Redis才被用作缓存,但是这种情况正在改变。该库具有强大的功能,对于我们的任务,仅需要3个命令:rpush,lrange和ltrim。
我们将使用rpush命令将数据写入列表的末尾。在Crown命令中,使用lrange读取数据并发送到队列,如果我们设法发送到队列,则需要使用ltrim删除选定的数据。
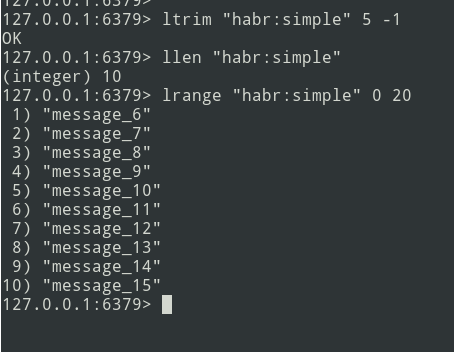
从理论到实践。让我们创建一个简单的列表。

我们有三个消息的列表,让我们添加更多...
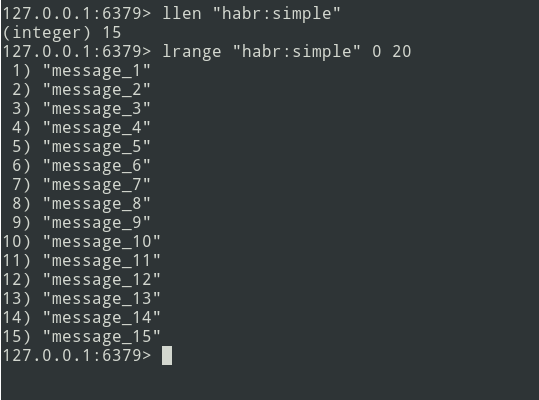
新消息添加到列表的末尾。使用lrange命令,选择批次(将其设为= 5条消息)。
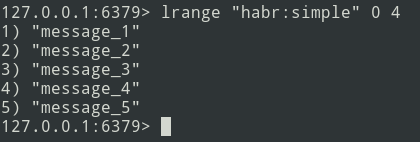
接下来,我们将包发送到队列。现在,您需要从Redis中删除此捆绑包,以免再次发送它。
有一个算法,让我们开始实施。
实作
让我们从ClickHouse表开始。我并没有太在意并用String类型定义了一切。
create table profile_logs
(
hostname String, // ,
project String, //
version String, //
userId Nullable(String),
sessionId Nullable(String),
requestId String, //
requestIp String, // ip
eventName String, //
target String, // URL
latency Float32, // (latency=endTime - beginTime)
memoryPeak Int32,
date Date,
created DateTime
)
engine = MergeTree(date, (date, project, eventName), 8192);该事件将是这样的:
{
"hostname": "debian-fsn1-2",
"project": "habr",
"version": "7.19.1",
"userId": null,
"sessionId": "Vv6ahLm0ZMrpOIMCZeJKEU0CTukTGM3bz0XVrM70",
"requestId": "9c73b19b973ca460",
"requestIp": "46.229.168.146",
"eventName": "app:init",
"target": "/",
"latency": 0.01384348869323730,
"memoryPeak": 2097152,
"date": "2020-07-13",
"created": "2020-07-13 13:59:02"
}结构已定义。要计算延迟,我们需要一个时间段。我们使用microtime函数来确定:
$beginTime = microtime(true);
//
$latency = microtime(true) - $beginTime;为了简化实现,我们将使用laravel框架和laravel-entry库。添加模型(表profile_logs):
class ProfileLog extends \Bavix\Entry\Models\Entry
{
protected $fillable = [
'hostname',
'project',
'version',
'userId',
'sessionId',
'requestId',
'requestIp',
'eventName',
'target',
'latency',
'memoryPeak',
'date',
'created',
];
protected $casts = [
'date' => 'date:Y-m-d',
'created' => 'datetime:Y-m-d H:i:s',
];
}让我们编写一个tick方法(我做了一个ProfileLogService服务),它将消息写入Redis。我们获取当前时间(我们的beginTime)并将其写入$ currentTime变量:
$currentTime = \microtime(true);如果是第一次调用事件滴答声,则将其写入滴答数组并结束方法:
if (empty($this->ticks[$eventName])) {
$this->ticks[$eventName] = $currentTime;
return;
}如果再次调用了滴答声,那么我们使用rpush方法将消息写入Redis:
$tickTime = $this->ticks[$eventName];
unset($this->ticks[$eventName]);
Redis::rpush('events:profile_logs', \json_encode([
'hostname' => \gethostname(),
'project' => 'habr',
'version' => \app()->version(),
'userId' => Auth::id(),
'sessionId' => \session()->getId(),
'requestId' => \bin2hex(\random_bytes(8)),
'requestIp' => \request()->getClientIp(),
'eventName' => $eventName,
'target' => \request()->getRequestUri(),
'latency' => $currentTime - $tickTime,
'memoryPeak' => \memory_get_usage(true),
'date' => $tickTime,
'created' => $tickTime,
]));$ this-> ticks 变量不是静态的。您需要将服务注册为单例。
$this->app->singleton(ProfileLogService::class);批大小($ batchSize)是可配置的,建议指定一个较小的值(例如10,000个项目)。如果出现问题(例如,ClickHouse不可用),队列将开始失败,并且您需要调试数据。
让我们写一个Crown命令:
$batchSize = 10000;
$key = 'events:profile_logs'
do {
$bulkData = Redis::lrange($key, 0, \max($batchSize - 1, 0));
$count = \count($bulkData);
if ($count) {
// json, decode
foreach ($bulkData as $itemKey => $itemValue) {
$bulkData[$itemKey] = \json_decode($itemValue, true);
}
// ch
\dispatch(new BulkWriter($bulkData));
// redis
Redis::ltrim($key, $count, -1);
}
} while ($count >= $batchSize);您可以立即将数据写入ClickHouse,但是问题在于kronor在单线程模式下工作。因此,我们将采取另一种方式-使用命令将形成数据包,并将其发送到队列中,以便在ClickHouse中进行后续多线程记录。使用者的数量可以调节-这将加快消息的发送速度。
让我们继续写一个消费者:
class BulkWriter implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
protected $bulkData;
public function __construct(array $bulkData)
{
$this->bulkData = $bulkData;
}
public function handle(): void
{
ProfileLog::insert($this->bulkData);
}
}
}因此,开发了打包,发送到队列和使用者的包-您可以开始分析:
app(ProfileLogService::class)->tick('post::paginate');
$posts = Post::query()->paginate();
$response = view('posts', \compact('posts'));
app(ProfileLogService::class)->tick('post::paginate');
return $response;如果一切都正确完成,那么数据应该在Redis中。我们将混淆Crown命令并将包发送到队列,然后使用者将它们插入数据库。
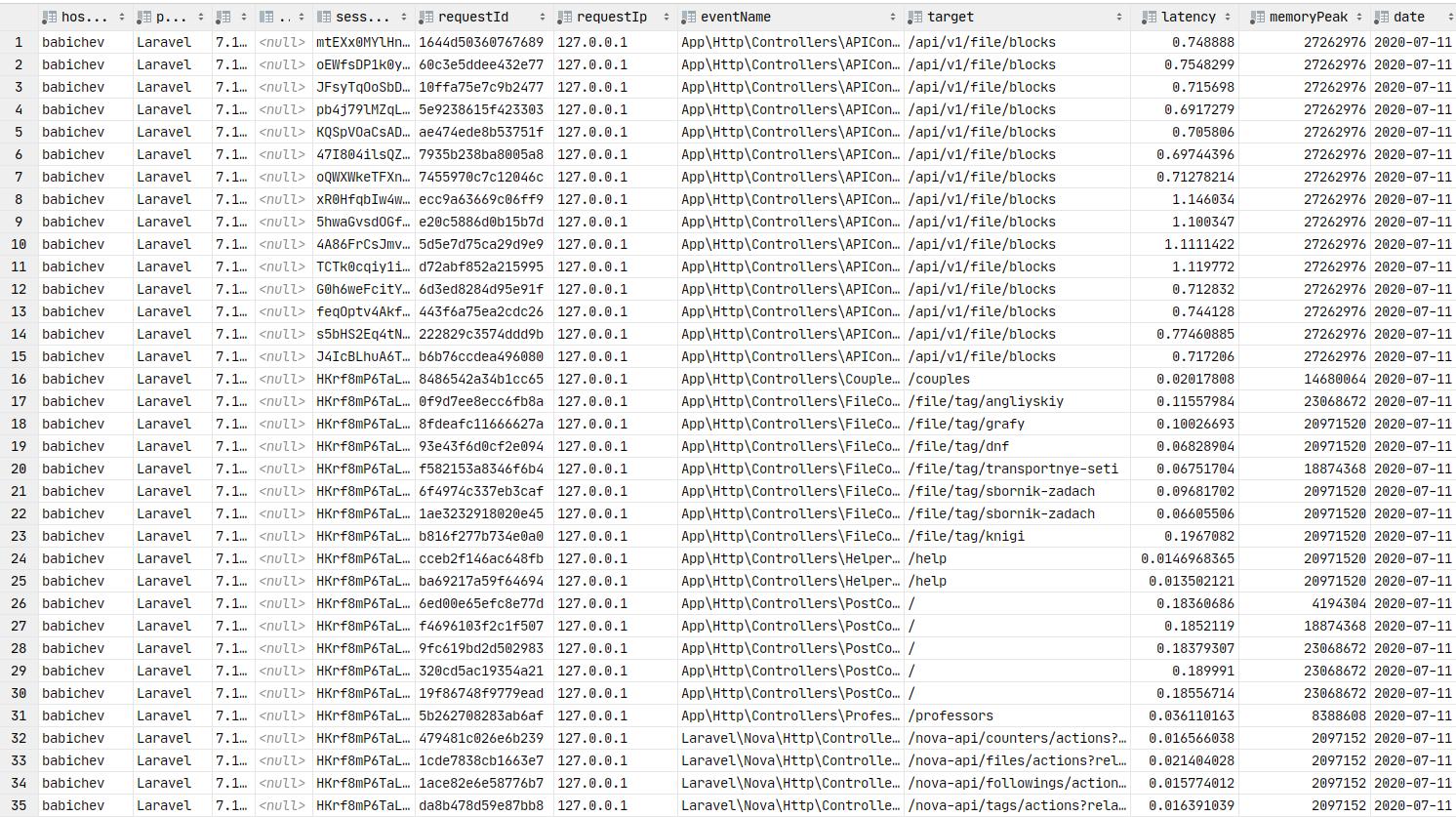
数据库中的数据。您可以构建图形。
格拉法纳
现在,让我们继续进行数据的图形表示,这是本文的关键要素。您需要安装grafana。让我们跳过类似debain的程序集的安装过程,您可以使用指向文档的链接。通常,安装步骤归结为易于安装grafana。
在ArchLinux上,安装如下所示:
yaourt -S grafana
sudo systemctl start grafana服务已启动。URL:http://本地主机:3000
现在,您需要安装ClickHouse数据源插件:
sudo grafana-cli plugins install vertamedia-clickhouse-datasource如果您已安装grafana 7+,则ClickHouse将无法正常工作。您需要更改配置:
sudo vi /etc/grafana.ini让我们找到这行:
;allow_loading_unsigned_plugins =让我们用这个替换它:
allow_loading_unsigned_plugins=vertamedia-clickhouse-datasource保存并重新启动服务:
sudo systemctl restart grafana做完了现在我们可以去格拉法纳。
登录名:admin /密码:默认情况下为admin。

成功授权后,单击齿轮。在打开的弹出窗口中,选择“数据源”,添加一个ClickHouse连接。
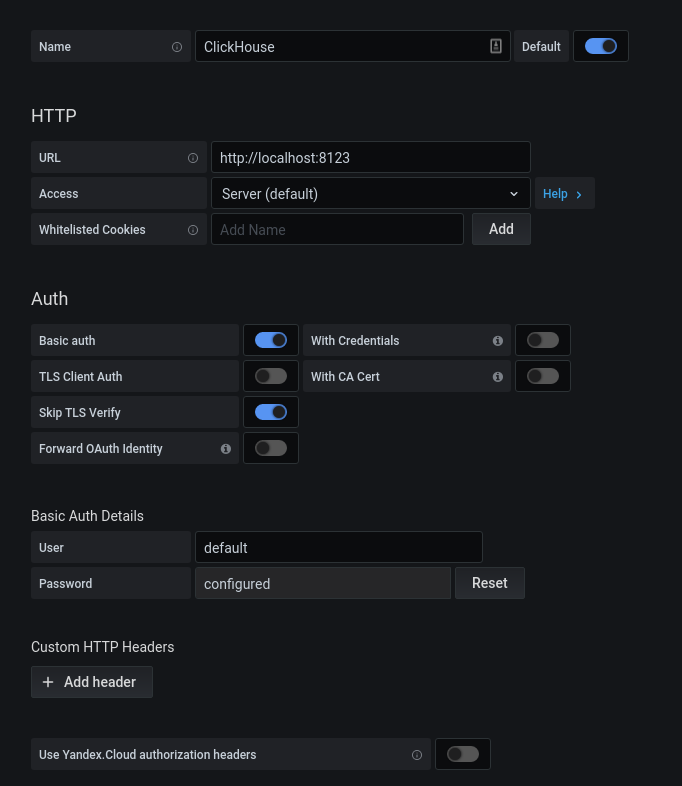
我们填写配置kx。单击“保存并测试”按钮,我们将收到有关成功连接的消息。
现在,让我们添加一个新的仪表板:
添加一个面板:

选择用于处理日期的基础和相应的列:
让我们继续进行查询:
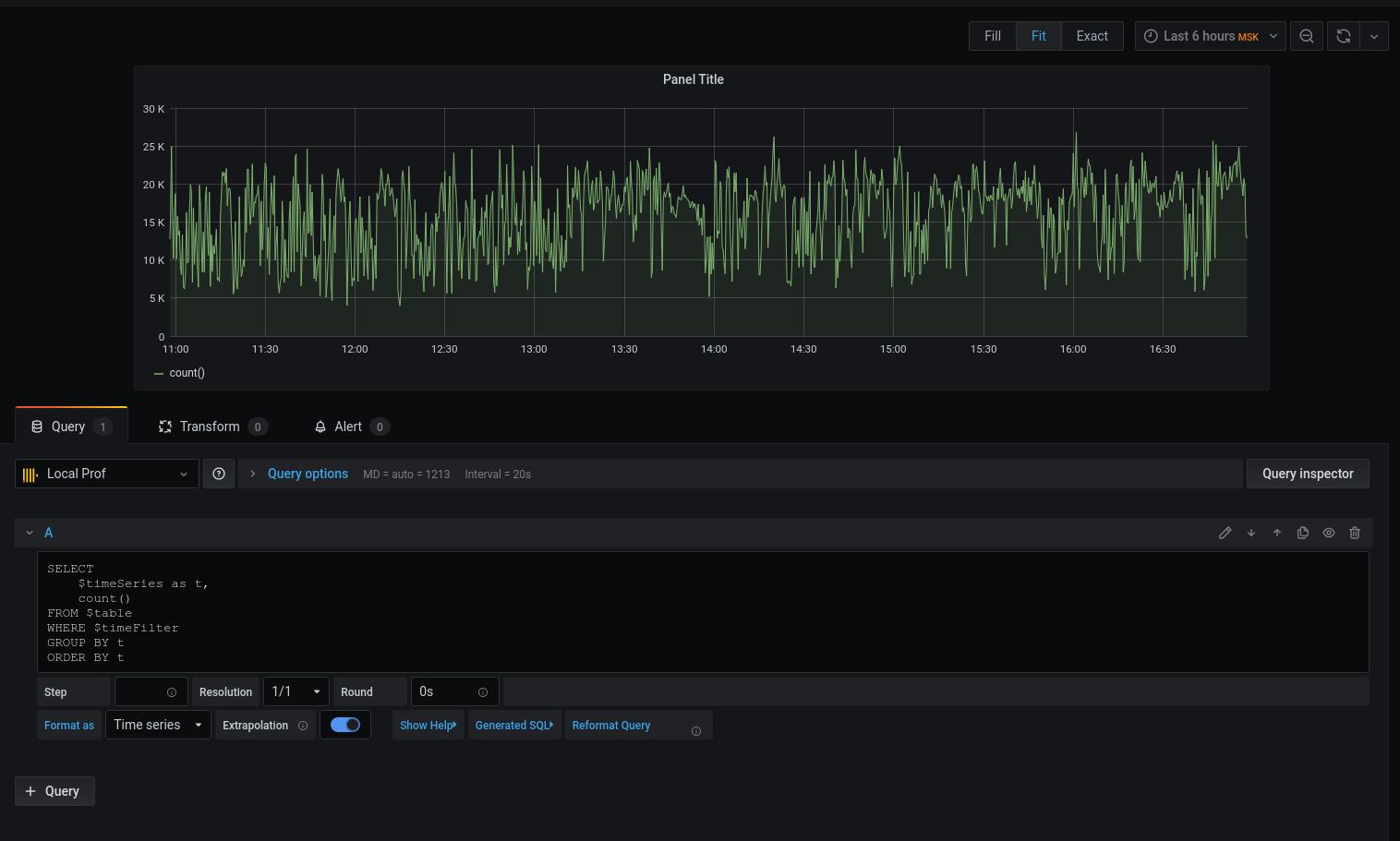
我们得到了一个图形,但是我想要细节。让我们打印将日期与时间四舍五入到五分钟间隔开始的平均延迟时间:
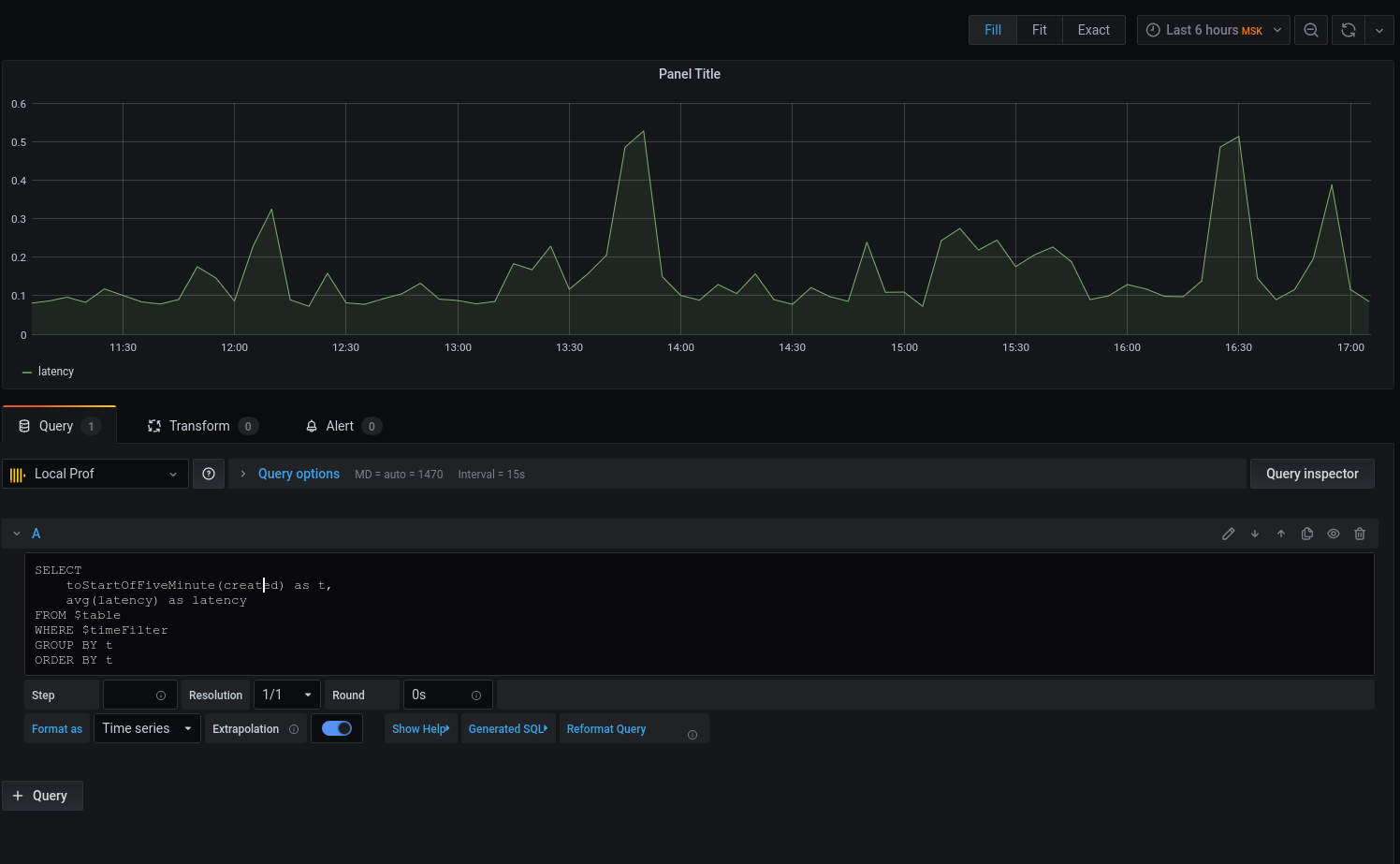
现在,选定的数据显示在图表上,我们可以将其重点放在上面。对于警报,请配置触发器,按事件分组等等。
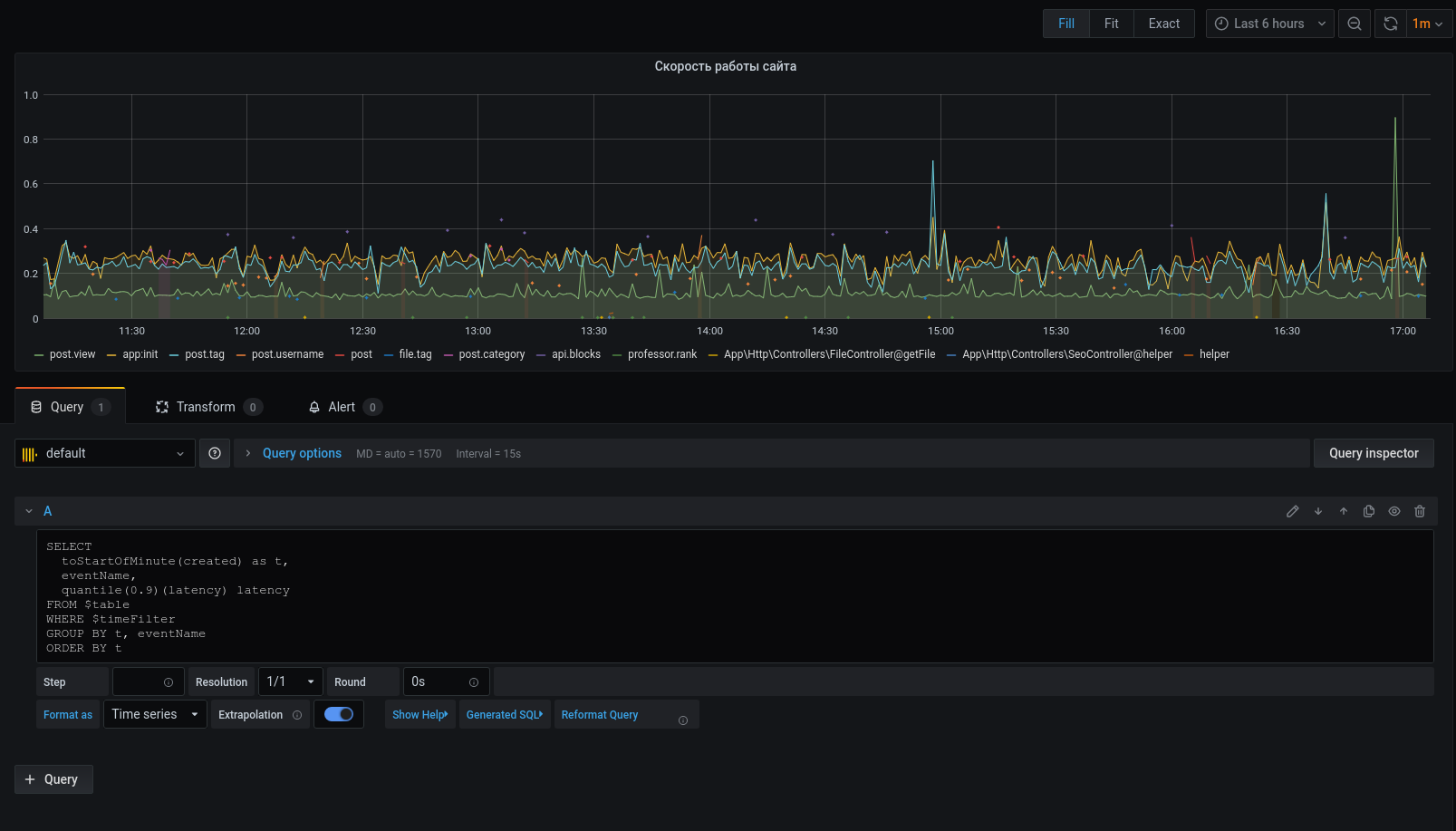
分析器绝不是工具的替代品:(Badoo)的xhprof(facebook),xhprof(tideways)和liveprof。只是对它们的补充。
所有源代码是关于github上-探查模型,服务,BulkWriteCommand,BulkWriterJob和中间件(1,2)。
安装软件包:
composer req bavix/laravel-prof设置连接(config / database.php),添加clickhouse:
'bavix::clickhouse' => [
'driver' => 'bavix::clickhouse',
'host' => env('CH_HOST'),
'port' => env('CH_PORT'),
'database' => env('CH_DATABASE'),
'username' => env('CH_USERNAME'),
'password' => env('CH_PASSWORD'),
],
工作开始:
use Bavix\Prof\Services\ProfileLogService;
// ...
app(ProfileLogService::class)->tick('event-name');
//
app(ProfileLogService::class)->tick('event-name');要将批次发送到队列,您需要向cron添加命令:
* * * * * php /var/www/site.com/artisan entry:bulk您还需要运行使用者:
php artisan queue:work --sleep=3 --tries=3建议配置主管。配置(5个使用者):
[program:bulk_write]
process_name=%(program_name)s_%(process_num)02d
command=php /var/www/site.com/artisan queue:work --sleep=3 --tries=3
autostart=true
autorestart=true
user=www-data
numprocs=5
redirect_stderr=true
stopwaitsecs=3600
UPD:
1. ClickHouse可以从kafka队列中本地提取数据。谢谢,sdm