
根据一个众所周知的笑话,书店中的所有回忆录都应位于“科幻小说”部分。但就我而言,这是真的!很久以前,
3D会说话的头像-这是Max Planck伸出的舌头,眨着铜胸像;实时复制您的面部表情的猴子;这是英特尔副总裁相当知名的3D模型,在他的参与下,视频完全是自动创建的,还有更多……但是首先要考虑的是。
合成视频:MPEG-4兼容的3D Talking Heads-该项目的全名,于2000-2003年在英特尔下诺夫哥罗德研究和开发中心进行。该开发是一套三项主要技术,可以在与合成三维语音人物的创建和动画有关的许多应用程序中一起使用或分别使用。
- 视频序列中人脸表情和动作的自动识别和跟踪。同时,不仅评估了头部在所有平面上的旋转角度和倾斜角度,而且还评估了对话过程中嘴唇和牙齿的外部和内部轮廓,眉毛的位置,眼睛覆盖的程度,甚至是凝视的方向。
- 根据从第一点以及从任何其他来源使用识别和跟踪算法获得的动画参数,对几乎任意的三维头部模型进行实时实时自动动画处理。
- 使用原型的两张照片(正视图和侧视图)或一个视频序列(一个人的头从一个肩膀转向另一个肩膀)自动创建特定人的头部的逼真的3D模型。
另一个好处是,考虑到2000年代初期存在的硬件性能和软件功能的局限性,技术或更确切地说,是实时实时渲染“会说话的人”的一些技巧。
这三个半点之间的链接以及与Intel的链接都是四个字母和一个数字:MPEG-4。
MPEG-4
很少有人知道1998年出现的MPEG-4标准除了对普通的真实视频和音频流进行编码外,还对合成对象及其动画的信息(即所谓的合成视频)进行了编码。这样的对象之一是人脸,更确切地说,是定义为三角表面的头-3D空间中的网格。MPEG-4在一个人的脸上定义了84个特殊点-特征点(FP):嘴唇,眼睛,眉毛,鼻尖等的角和中点。
面部动画参数(FAP)应用于这些特殊点(或在转弯和倾斜的情况下整体应用于整个模型),描述了与中立状态相比位置和面部表情的变化。
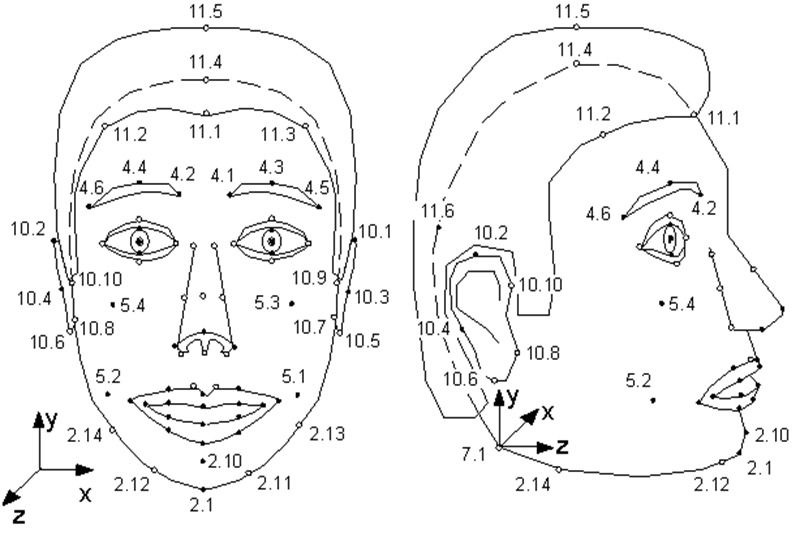
MPEG-4规范的插图。模型的奇异点。如您所见,模型可以嗅和摆动她的耳朵。
也就是说,显示讲话角色的合成视频每一帧的描述看起来像一小部分参数,MPEG-4解码器必须通过这些参数为模型设置动画。
哪个型号? MPEG-4有两个选项。该模型要么由编码器创建,然后在序列开始时一次传输到解码器,要么解码器具有自己的专有模型,该模型在动画中使用。
同时,该模型的唯一MPEG-4要求:VRML中的存储格式和特殊点的存在。也就是说,模型可以是使用FAP进行动画制作的人的真实感副本,也可以是任何其他人甚至是说话的水壶的模型的真实感副本-主要是他除了鼻子外还拥有嘴巴和眼睛。

我们的MPEG-4兼容模型之一是最令人着迷的,
除了主要对象“面部”之外,MPEG-4还描述了独立对象“上颚”,“下颚”,“舌头”,“眼睛”,并且还设置了特殊点。但是,如果某些模型没有这些对象,则解码器根本不会使用相应的FAP。

-模型,模型,为什么你有这么大的眼睛和牙齿? -更好地使自己动起来!
个性化动画模型从哪里来?如何获得FAP?最后,您如何基于这些FAP实现逼真的动画和渲染?MPEG-4并未对所有这些问题给出任何答案-就像任何视频压缩标准都没有说明拍摄过程及其所编码电影的内容一样。
进展如何?直到前所未有的奇迹!
当然,模型和动画都可以由专业美术师手动创建,花费数十个小时并获得数十万美元。但这极大地缩小了技术范围,使其在工业规模上不适用。该技术有很多潜在用途,实际上会将高分辨率视频帧压缩到几个字节(哦,可惜没有任何视频)。首先,建立网络-使用合成角色进行游戏,教育和交流(视频会议)。
当20年前仍可以使用调制解调器访问Internet时,此类应用尤其重要,而千兆级无限制Internet似乎就像是远距传输。但是,正如生活所表明的那样,在2020年,互联网通道的带宽在许多情况下仍然是个问题。即使没有这种问题,例如,我们在谈论本地使用,合成字符也有很多功能。例如,在影片中“复活”上个世纪著名演员,或者给人们机会看一眼现在流行但仍然没有体现的语音助手。但是首先,从演讲者的真实视频到合成视频的过渡过程应该变成自动的,或者至少在最少的人为参与下进行。
这正是下诺夫哥罗德英特尔实施的。这个想法首先是由英特尔一次开发的MPEG处理库实现的一部分出现的,然后不仅发展为成熟的衍生产品,而且还发展成为一个真正的令人惊叹的大片。
而且,完全是“俄罗斯制造的”-这个项目似乎是整个俄罗斯英特尔公司唯一的一个项目,英特尔美国公司没有策展人。在访问下诺夫哥罗德期间,贾斯汀·拉特纳(贾斯汀·拉特纳(Justin Ratner),英特尔实验室研究部负责人)很喜欢这个主意,并批准了

合成人Valery Fedorovich Kuryakin,制片人,导演,编剧,在某些地方是项目的替身演员-当时是英特尔开发小组的负责人。
首先,在一个只有三个到七个人同时工作的小项目中将这些不同的技术组合在一起是很棒的。在那些年里,世界上至少已有十几家从事人脸识别和跟踪以及“会说话的人”的创作和动画制作的公司。当然,所有这些人在某些领域都取得了成就:有些人具有出色的模型质量,有些人显示了非常逼真的动画,有些人在识别和跟踪方面取得了成功。但是没有一家公司能够提供使您完全自动创建合成视频的整套技术,其中与原型非常相似的模型可以完美地复制其面部表情和动作。
英特尔3D Talking Heads项目是第一个,也是当时唯一的基于MPEG-4综合配置文件所有元素的视频通信全周期实施。

2003型号的合成克隆生产项目的传送者
;其次,当时存在的硬件与项目中实施的技术解决方案以及使用计划的完美结合。因此,在项目开始时,我的口袋里有诺基亚3310,台式机上有Pentium III-500MHz,并且对于具有128 Mb RAM的Pentium 4-1.7GHz服务器测试了对实时工作性能至关重要的算法。
同时,我们希望我们的模型能很快在移动设备上运行,并且质量不会比当时(2001年)发行的真实感计算机动画电影“最终幻想”的英雄们差。

成本为1.37亿美元在约1000台Pentium III计算机的渲染场上制作的电影。来自www.thefinalfantasy.com的海报
但是让我们看看发生了什么。
人脸识别和跟踪,FAP获取。
这项技术有两种版本:
- 实时模式(在已经提到的奔腾4-1.7GHz处理器上为每秒25帧),当跟踪直接站在与计算机相连的摄像机前面的人时;
- ( 1 ), .
同时,实时监测人脸位置/状态变化的动力学-我们可以大致估算出所有平面中头部的旋转角度和倾斜角度,嘴巴张开和伸展程度以及眉毛抬起的大致程度,并可以识别眨眼。对于某些应用程序,这样的粗略估计就足够了,但是如果您需要准确地跟踪一个人的面部表情,则需要更复杂的算法,这意味着速度较慢。
在离线模式下,我们的技术不仅可以评估整个头部的位置,而且可以在对话过程中绝对准确地识别和跟踪嘴唇和牙齿的外部和内部轮廓,眉毛的位置,眼睛的覆盖程度,甚至瞳孔的位移-凝视的方向。
为了进行识别和跟踪,使用了众所周知的计算机视觉算法的组合,其中一些已经在新发布的OpenCV库中实现-例如,Optical Flow,以及基于对相应物体形状的先验知识的我们自己的原始方法。特别是在我们改进的可变形模板方法版本中,项目参与者为此获得了专利。
该技术以功能库的形式实现,该功能库接收以人脸为输入的视频帧并输出相应的FAP。
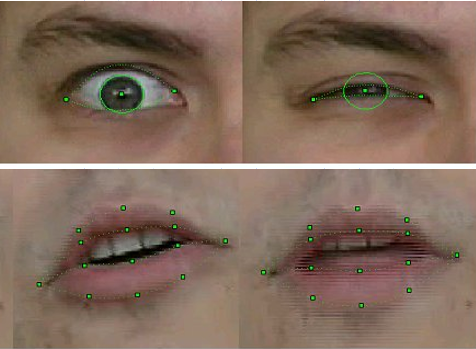
识别和跟踪FP样本2003的质量
当然,这项技术并不完善。如果框架中的人有胡子,眼镜或深皱纹,则识别和跟踪将失败。但是经过三年的工作,质量已大大提高。如果在用于运动识别模型的第一个版本中,拍摄视频时必须在面部的相应FP点上贴上特殊标记-通过办公室打孔器获得的白皮书圆圈,那么在该项目的最后,当然不需要这种类型。此外,我们设法稳定地跟踪了牙齿的位置和凝视的方向-这是当时网络摄像头的视频分辨率,在这种分辨率下很难区分这些细节!

这不是水痘,而是识别技术“童年”的镜头。英特尔首席工程师,当时-英特尔新手亚历山大·鲍维林(Alexander Bovyrin)教授合成模型来阅读诗歌
动画
如多次提到的那样,MPEG-4中模型的动画完全由FAP确定。如果没有几个问题,一切都会很简单。
首先,以2D提取来自视频序列的FAP,并且模型为3D的事实,并且需要以某种方式完成第三个坐标。也就是说,个人资料中的欢迎笑容(用户应该能够看到此个人资料,否则在3D中几乎没有感觉)不应变成不祥的笑容。
其次,正如前面所说的,FAP描述了特殊点的运动,模型中大约有80个点,而整体上至少一个有点现实的模型由数千个顶点组成(在我们的例子中是从四个到八千个),需要使用算法来根据FP偏移量计算模型中所有其他点的位移。
也就是说,很明显,当头部以相同的角度旋转时,所有的点都会旋转,但是当微笑时,即使举到耳朵上,从口腔角的移动产生的“发炎”也应逐渐消失,而不是耳朵移动脸颊。而且,对于任何具有任何嘴巴宽度和周围网格几何形状的模型,它都应该自动且现实地发生。为了解决这些问题,在项目中创建了动画算法。它们基于伪肌肉模型,该模型简单地描述了控制面部表情的肌肉。
然后,对于每个模型和每个FAP,预先自动确定“影响区域”-涉及相应动作的顶点,并在考虑到解剖结构和几何形状的情况下计算其运动-保持表面的光滑度和连通性。也就是说,动画由两部分组成-初步,离线执行,在其中创建网格顶点的某些系数并将其输入到表格中;以及在线,其中考虑到表格中的数据,将实时动画应用于模型。

对于3D模型及其创建者而言,微笑并不容易
创建特定人的3D模型。
在一般情况下,从其二维图像重建三维对象的任务非常困难。也就是说,解决该问题的算法是人类很早就知道的,但实际上,由于许多因素,其结果远非期望的结果。这在重建人脸形状的情况下尤其明显-在这里您可以回想起我们第一个使用八角形眼睛的模型(原始照片中睫毛的阴影未成功)或鼻子轻微分叉(无法恢复多年处方的原因)。
但是对于MPEG-4会说话的人来说,该任务大大简化了,因为人的面部特征集(鼻子,嘴巴,眼睛等)对所有人来说都是相同的,而且我们所有人(以及计算机视觉程序)所采用的外部差异人们彼此“几何”-这些特征的大小/比例和位置以及“纹理”-颜色和浮雕。因此,在项目中实施的合成MPEG-4视频校准配置文件之一,假设解码器具有“抽象人”的通用模型,该模型针对使用照片或视频序列的特定人进行了个性化设置。
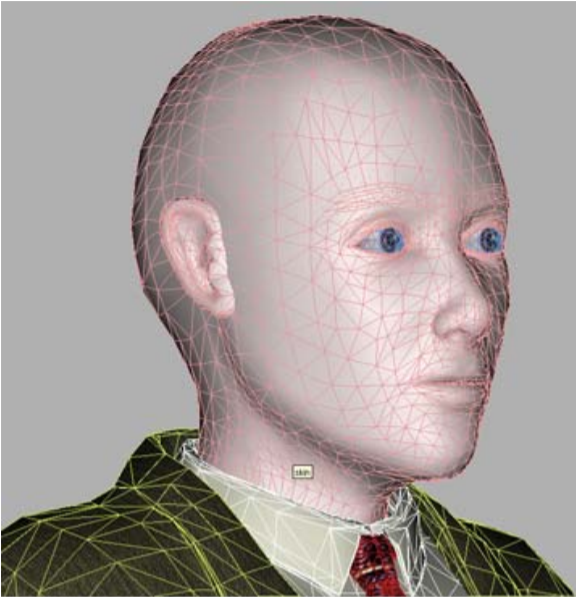
我们的“真空中的球形人”-个性化模型
也就是说,发生3D网格的全局和局部变形以匹配其照片/视频中突出显示的原型面部特征的比例,然后将原型的“纹理”应用于模型-即从相同的输入图像创建的纹理。结果是一个综合模型。每个模型都要做一次,当然要脱机,当然也不是那么容易。
首先,需要对输入图像进行配准或校正-使它们进入与3D模型的坐标系一致的一个坐标系。此外,在输入图像上,必须检测奇异点,并基于其位置使3D模型变形,例如,使用径向基函数的方法然后,使用全景拼接算法,从两个或多个输入图像生成纹理,即以正确的比例“混合”它们以获得最大的视觉信息,并补偿即使在拍摄的照片中也始终存在的照明和色调差异使用相同的相机设置(并非总是如此),并且在组合这些照片时非常明显。

这不是恐怖电影的剧照,而是Pat Gelsinger的3D模型的纹理,该模型是在2003年英特尔开发者论坛上展示该项目时得到他的许可而创建的。
英特尔的项目参与者自己实施了基于两张照片对模型进行个性化处理的技术的初始版本。但是,在达到一定的质量水平并意识到其功能的局限性之后,决定将这部分工作移交给在这方面有经验的莫斯科国立大学研究小组。在丹尼斯·伊凡诺夫(Denis Ivanov)的领导下,莫斯科国立大学研究人员的工作成果是“头部校准环境”应用程序,该应用程序执行了上述所有操作,以从其全貌和完整的照片中创建人的个性化模型。
唯一的微妙之处是,该应用程序未与我们的项目中开发的上述面部识别单元集成在一起,因此必须手动标记照片中起作用的特殊点。当然,不是所有的84个,而是主要的,并且鉴于应用程序具有适当的用户界面,此操作仅花费了几秒钟。
此外,还实现了从视频序列重建模型的全自动版本,其中一个人的头从一个肩膀转向另一个肩膀。但是,您可能会猜到,从视频中提取的纹理的质量明显比当时分辨率为4K(3-5兆像素)的数码相机的照片创建的纹理要差,这意味着生成的模型看起来吸引力不大。因此,还有一个中间版本,使用了几张不同的头部旋转角度的照片。

第一排是虚拟人,第二排是真实的人。
取得的效果如何?最终模型的质量不应通过静态评估,而应通过与原始视频的相似性直接在合成视频上进行评估。但是“相似和不相似”这两个术语不是数学上的,它们取决于特定人的感知,并且很难理解我们的合成模型及其动画与原型有何不同。有些人喜欢,有些不喜欢。但是三年的工作结果是,当在各种展览中展示结果时,观众不得不解释真正的视频在哪个窗口出现在他们面前,以及在哪个窗口中-合成的。
可视化。
为了演示上述所有技术的结果,创建了一个特殊的MPEG-4合成视频播放器。播放器接收到具有模型的VRML文件,具有FAP的流(或文件)以及具有真实视频和音频的流(文件)作为输入,以便与支持“画中画”模式的合成视频同步显示。在演示合成视频时,用户只需简单地以任意角度旋转鼠标,就可以放大模型并从各个角度查看模型。

尽管该播放器是为Windows编写的,但是考虑到将来可能移植到其他操作系统(包括移动操作系统)。因此,没有任何扩展名的“经典” OpenGL 1.1被选为3D库。
同时,玩家不仅展示了模型,而且还尝试改进模型,而不是像现在的照片模型那样修饰它,相反,是使模型尽可能逼真。也就是说,玩家的渲染单元保留在最简单的Phong照明框架内,没有着色器,但是对性能的要求很高,因此会自动创建合成模型:模拟皱纹,睫毛,能够逼真的缩小和扩大瞳孔;将合适尺寸的眼镜放在模型上;并且还使用最简单的射线追踪,计算了说话时舌头和牙齿的照明(阴影)。
当然,现在这些方法不再适用,但是记住它们很有趣。因此,对于模拟皱纹的合成,即在面部肌肉收缩期间可见的面部皮肤小弯曲,模型网格的三角形相对较大的尺寸不允许创建真实的褶皱。因此,应用了一种凹凸贴图技术-法线贴图。无需更改模型的几何形状,而是更改了在正确位置指向表面的法线的方向,并且在每个点处照明的漫反射分量对法线的依赖性产生了所需的效果。

这是综合现实主义。
但是玩家并没有就此止步。为了方便使用技术并将其转移到外部世界,创建了英特尔面部动画库对象库,其中包含用于动画(3D转换)和模型可视化的函数,因此任何想要(并具有FAP源代码)的人都可以调用多个函数-“创建场景”,“ CreateActor”,“ Animate”可以进行动画处理并在其应用程序中显示其模型。
结果
参与这个项目给我个人带来了什么?当然,有机会与有趣的人就有趣的技术进行合作。他们将我带入了该项目,因为我了解用于渲染3D模型和优化x86性能的方法和库。但是,自然不可能将自己局限于3D,因此我们不得不转向其他尺寸。要编写一个播放器,有必要处理VRML解析(没有为此目的而准备的库),掌握Windows中线程的本机工作,确保每秒25个同步的多个线程的联合工作,不要忘记用户交互,甚至是考虑和实现接口。后来,通过参与人脸跟踪算法的改进,对该列表进行了补充。并且需要不断集成其他团队成员编写的组件并将其与玩家简单地结合在一起,并且向外界介绍该项目大大提高了我的沟通和协调能力。
英特尔参与该项目带来了什么?因此,我们的团队创造了一种产品,可以很好地测试和演示英特尔平台和产品的功能。此外,无论是硬件(CPU和GPU还是软件),我们的负责人(无论是实际的还是综合的)都为OpenCV库的改进做出了贡献。
此外,我们可以肯定地说该项目在历史上留下了明显的痕迹-作为其工作的结果,该项目的参与者在有关计算机视觉和计算机图形学的专业会议,俄语(GraphiCon)和国际会议上撰写了文章并提出了报告。
英特尔已在全球数十个展览,论坛和大会上展示了3D Talking Heads演示应用程序。
在这段时间里,技术当然有了很大进步,使自动创建合成动画和动画化变得更加容易。有英特尔实感腔深度定义,以及基于大数据的神经网络学习了如何生成人的真实图像,甚至是不存在的图像。
但是,尽管如此,在公共领域发布的3D Talking Heads项目的发展情况一直持续到现在。
看看我们将近二十岁的合成MPEG-4扬声器,您会: